预约演示
更新于:2024-09-19
Lutetium (177Lu) zadavotide guraxetan
更新于:2024-09-19
概要
基本信息
非在研机构- |
权益机构- |
最高研发阶段临床2期 |
首次获批日期- |
最高研发阶段(中国)- |
特殊审评- |

结构/序列
使用我们的ADC技术数据为新药研发加速。
登录
或

关联
5
项与 Lutetium (177Lu) zadavotide guraxetan 相关的临床试验NCT06259123
Neoadjuvant [177Lu]Lu-PSMAI&T Radioligand Therapy (PSMA-RLT) for Patients With Oligometastatic Prostate Cancer Diagnosed Using [68Ga]Ga-PSMA-11 PET Imaging Followed by Radical Prostatectomy: A Prospective Phase II Pilot Study
NCT06220188
[177Lu]Lu-PSMAI&T Radioligand Therapy (PSMA-RLT) for Patients With Prostate Cancer and Biochemical But Not Radio-morphological Local Recurrence After Primary Therapy With Curative Intent: A Prospective Phase II Pilot Study
NCT05893381
A Phase II Randomized Trial of Lu-PSMA and Stereotactic Radiotherapy Versus Radiotherapy Alone for Oligometastatic Prostate Cancer (LUST)
100 项与 Lutetium (177Lu) zadavotide guraxetan 相关的临床结果
登录后查看更多信息
100 项与 Lutetium (177Lu) zadavotide guraxetan 相关的转化医学
登录后查看更多信息
100 项与 Lutetium (177Lu) zadavotide guraxetan 相关的专利(医药)
登录后查看更多信息
17
项与 Lutetium (177Lu) zadavotide guraxetan 相关的文献(医药)2024-07-01Revista Española de Medicina Nuclear e Imagen Molecular (English Edition)
Reliability and readability analysis of ChatGPT-4 and Google Bard as a patient information source for the most commonly applied radionuclide treatments in cancer patients
Article
作者: Serdengeçti, Mustafa ; Bayrakcı, Özkan ; Alagöz, Engin ; Şan, Hüseyin ; Çağdaş, Berkay
2024-01-01Theranostics
[161Tb]Tb-PSMA-617 radioligand therapy in patients with mCRPC: preliminary dosimetry results and intra-individual head-to-head comparison to [177Lu]Lu-PSMA-617
Article
作者: Schaefer-Schuler, Andrea ; Bartholomä, Mark ; Rosar, Florian ; Stemler, Tobias ; Maus, Stephan ; Ezziddin, Samer ; Burgard, Caroline ; Petrescu, Christine ; Blickle, Arne ; Petto, Sven
2024-01-01Theranostics
Exploring the role of combined external beam radiotherapy and targeted radioligand therapy with [177Lu]Lu-PSMA-617 for prostate cancer - from bench to bedside
Article
作者: Eder, Matthias ; Freitag, Martin T ; Meyer, Philipp T ; Niedermann, Gabriele ; Uhlmann, Lisa ; Domogalla, Lisa-Charlotte ; Spohn, Simon K B ; Arbuznikova, Daria ; Eder, Ann-Christin ; Mix, Michael ; Grosu, Anca L ; Klotsotyra, Aikaterini ; Steinacker, Nils ; Gratzke, Christian ; Zamboglou, Constantinos
1
项与 Lutetium (177Lu) zadavotide guraxetan 相关的新闻(医药)2024-05-12
·药渡
抗体药物偶联物临床结果临床2期临床1期
100 项与 Lutetium (177Lu) zadavotide guraxetan 相关的药物交易
登录后查看更多信息
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 寡转移性前列腺癌 | 临床2期 | 奥地利 | 2024-02-01 | |
| 复发性前列腺癌 | 临床2期 | 奥地利 | 2024-01-15 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
登录后查看更多信息
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
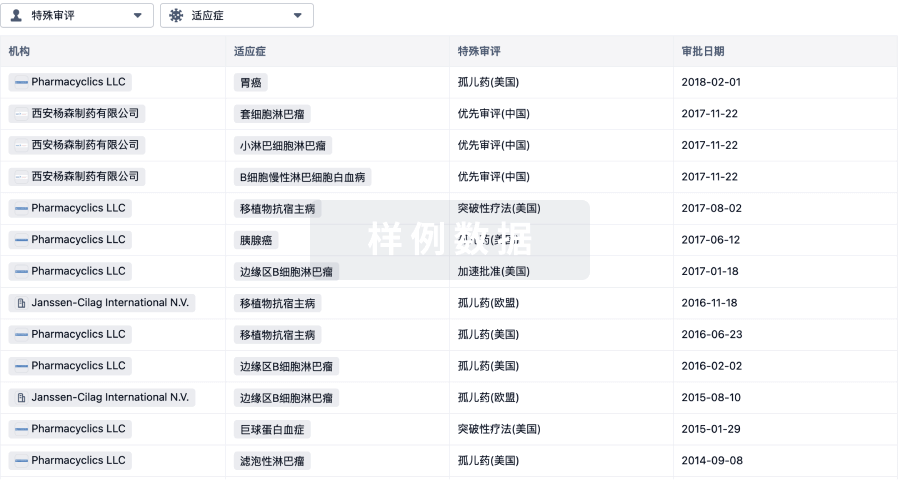
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用