预约演示
更新于:2026-03-14
NLRPS Inhibitors(Shanghai Tuojie)
NLRP3抑制剂(拓界生物)
更新于:2026-03-14
概要
基本信息
原研机构 |
在研机构- |
非在研机构 |
权益机构- |
最高研发阶段无进展药物发现 |
首次获批日期- |
最高研发阶段(中国)无进展 |
特殊审评- |
关联
100 项与 NLRP3抑制剂(拓界生物) 相关的临床结果
登录后查看更多信息
100 项与 NLRP3抑制剂(拓界生物) 相关的转化医学
登录后查看更多信息
100 项与 NLRP3抑制剂(拓界生物) 相关的专利(医药)
登录后查看更多信息
78
项与 NLRP3抑制剂(拓界生物) 相关的新闻(医药)2026-03-13
NLRP3炎症小体是一种关键的多蛋白复合物,在先天免疫反应中起着核心作用,负责识别病原体相关分子模式和损伤相关分子模式,并激活下游的炎症反应。然而,NLRP3炎症小体的过度激活与多种炎症性疾病和自身免疫性疾病密切相关。
NLRP3炎症小体的激活过程
在探讨抑制剂的作用机制之前,有必要了解NLRP3炎症小体的正常激活过程。NLRP3的激活通常分为两个步骤:启动和激活。启动步骤涉及转录因子NF-κB的激活,导致NLRP3和炎症细胞因子前体(如pro-IL-1β和pro-IL-18)的上调。
激活步骤则涉及NLRP3与ASC和pro-caspase-1的组装,形成炎症小体复合物,最终导致caspase-1的激活和炎症细胞因子的成熟与释放。
NLRP3炎症小体抑制剂的作用点
NLRP3炎症小体抑制剂可以通过多种机制干预上述激活过程。
干扰NLRP3寡聚化
一些小分子抑制剂,如OLT1177(dapansutrile),能够直接结合NLRP3,阻止其寡聚化,从而抑制NLRP3炎症小体的组装和激活。这类抑制剂通过破坏NLRP3的结构完整性,阻止其与ASC的结合,进而抑制caspase-1的激活。
抑制NLRP3 ATPase结构域
NLRP3的ATPase结构域对其激活至关重要。某些抑制剂,如INF4E和CY-09,通过抑制NLRP3 ATPase的活性,阻止NLRP3的构象变化,从而抑制其激活。这类抑制剂通过干扰NLRP3的能量代谢,影响其与其他蛋白的相互作用,最终抑制炎症小体的形成。
阻断ASC聚合
ASC是NLRP3炎症小体中的关键衔接蛋白。一些抑制剂通过阻断ASC的聚合,防止其形成功能性的炎症小体复合物。例如,某些化合物能够与ASC结合,阻止其与NLRP3和pro-caspase-1的相互作用,从而抑制炎症小体的激活。
抑制钾离子外流
钾离子外流是NLRP3激活的共同信号之一。某些抑制剂通过抑制细胞膜上的钾离子通道,如P2X7受体,减少钾离子的外流,从而抑制NLRP3的激活。这类抑制剂通过调节细胞内的离子平衡,影响NLRP3的激活信号,进而抑制炎症反应。
中和炎症细胞因子
除了直接抑制NLRP3炎症小体的激活外,一些生物制剂如IL-1β和IL-18的抗体或受体拮抗剂,能够中和已释放的炎症细胞因子,从而减轻炎症反应。这类抑制剂通过阻断炎症细胞因子的生物学活性,减轻组织损伤和炎症症状。
已知的NLRP3炎症小体抑制剂
目前,已有多种NLRP3炎症小体抑制剂进入临床试验或已获批用于治疗特定疾病。例如:
Anakinra:一种重组人IL-1受体拮抗剂,用于治疗类风湿性关节炎和自身炎症性疾病。
Canakinumab:一种抗IL-1β的单克隆抗体,用于治疗周期性发热综合征和痛风。
Rilonacept:一种IL-1陷阱,用于治疗自身炎症性疾病。
OLT1177(dapansutrile):一种口服的NLRP3抑制剂,正在临床试验中用于治疗多种炎症性疾病。
临床结果ASCO会议
2026-02-27
·衍因科技
2026年初的全球医药圈,礼来(Eli Lilly and Company)的光芒无人能及。
凭借替尔泊肽(Tirzepatide)在降糖、减重领域的现象级爆发,这家药企不仅历史性突破万亿美元市值,登顶全球药企榜首,更成为整个行业的“风向标”——它每一次出手,都被视为对未来医疗趋势的精准预判。
就在2026开年不到两个月,礼来再次震惊业界:继12亿美元收购Ventyx Biosciences后,又砸下24亿美元,将专注于体内CAR-T疗法的Orna Therapeutics收入麾下。
要知道,体内CAR-T至今尚无任何一款产品上市,仍是处于早期阶段的“潜力技术”。市值第一的药企甘愿押下重注,到底是盲目跟风的泡沫狂欢,还是布局十年后的精准卡位?
结合衍因科技对前沿生物疗法的长期追踪,我们一文读懂这场医药巨头的豪赌背后,藏着怎样的行业真相。
编者按:作为聚焦前沿生物医疗领域的科技企业,我们持续追踪基因细胞疗法的技术迭代与行业动态。本文将结合礼来24亿收购案,拆解体内CAR-T的技术优势、行业格局与发展挑战,解读医药巨头布局逻辑,为读者呈现这场关乎未来医疗格局的行业变革。
Part 01
24亿收购的核心:Orna到底强在哪?
很多人疑惑,礼来为何偏偏选中Orna?答案,藏在一项颠覆性技术里。
根据收购协议,礼来支付的24亿美元(含首付款+临床里程碑付款),核心瞄准的并非成熟药品,而是Orna一款即将进入临床试验的体内CAR-T项目——ORN-252,以及其独有的“环状RNA+LNP递送”双技术平台。
先给大家通俗解读下:我们常听说的CAR-T疗法,大多是“体外改造”模式(比如诺华的Kymriah)——医生先从患者体内采集T细胞,送到专业实验室进行基因改造、扩增,耗时数周后再输回患者体内,过程复杂、成本高昂,单剂费用动辄上百万美元。
而Orna的思路,相当于“原地改造”,直接颠覆了传统流程:通过一次简单输注,将编码CAR的环状RNA(oRNA)用新型脂质纳米颗粒(LNP)包裹,直接送入患者体内,让患者自身的普通T细胞,在体内“变身”为能精准识别并攻击异常细胞的CAR-T细胞。
关键优势有两个:一是环状RNA比传统线性mRNA更稳定,能在体内实现更持久的治疗蛋白表达,减少给药次数;二是LNP递送平台(源自Orna收购的ReNAgade Therapeutics),能精准靶向T细胞,降低脱靶风险——这正是体内CAR-T最核心的技术壁垒。
更值得关注的是,ORN-252的首要适应症并非癌症,而是红斑狼疮、类风湿关节炎等B细胞驱动的自身免疫性疾病。这一步棋,恰恰踩中了临床痛点:传统体外CAR-T成本高、毒副作用明显,无法大规模应用于良性自身免疫病患者,而体内CAR-T的低成本、便捷性,直接打开了这片万亿级市场的想象空间。
Part 02
礼来的“豪赌”,从不是一时兴起
24亿美元看似疯狂,但梳理礼来近年的布局就会发现,这绝非盲目扩张,而是基于精准战略眼光的必然选择——替尔泊肽带来的巨额现金流,正在被它快速转化为“未来十年的护城河”。
1. 王炸产品打底:替尔泊肽撑起万亿市值
礼来的底气,首先来自替尔泊肽的持续爆发。这款GIP/GLP-1双受体激动剂,2022年获批糖尿病适应症(Mounjaro),2023年获批减重适应症(Zepbound),到2025年,年度销售额已直逼甚至超越传统“药王”,直接推动礼来成为全球首家万亿市值纯制药企业。
但礼来从没想过“躺赢”——替尔泊肽的成功,让它手握充足现金流,也让它更加明确:不能只做“减重公司”,必须向更高壁垒、更前沿的领域突破,而免疫学正是它的核心发力方向。
2. 两步布局铺垫:从口服小分子到前沿基因疗法
礼来对免疫学的布局,早已形成清晰的梯度:
2023年,礼来以24亿美元收购DICE Therapeutics,核心瞄准其口服IL-17抑制剂管线——打破传统免疫疾病“只能注射”的局限,用口服小分子填补管线空白,对抗诺华等巨头的竞争;
2026年初,收购Ventyx Biosciences(12亿美元),拿下NLRP3抑制剂管线——NLRP3是炎症信号通路的关键节点,覆盖心血管、神经退行性、自身免疫等多个领域,进一步完善免疫管线布局;
而收购Orna,正是礼来布局的第三步:从传统抗体药物、口服小分子,升级到最前沿的基因细胞疗法,实现免疫学领域的“全链条覆盖”。
从这一系列操作不难看出,礼来的每一笔大额并购,都精准踩在“解决临床痛点”和“抢占高潜力赛道”上——这也是它能持续领跑行业的核心逻辑。
Part 03
不止礼来!体内CAR-T已成行业“军备竞赛”
礼来的押注,绝非孤例。2026年,被业界称为“体内CAR-T元年”,全球头部药企早已纷纷入局,形成激烈的军备竞赛格局——这背后,是整个行业对“下一代CAR-T”的共识。
我们整理了近期巨头的核心动作,一目了然:
阿斯利康:以约10亿美元收购比利时体内CAR-T公司EsoBiotec,快速补齐基因递送技术短板;
百时美施贵宝(BMS):砸下15亿美元收购Orbital Therapeutics,聚焦体内CAR-T的递送系统优化;
艾伯维、吉利德、强生:通过与Capstan、Umoja、Kelonia等初创公司合作,快速储备体内CAR-T技术,避免掉队。
如此多巨头在同一年涌入同一赛道,在医药行业历史上并不多见。这释放了一个明确信号:资本和技术界已基本验证“体内递送CAR指令至T细胞”的可行性,接下来3-5年,将是临床验证疗效和安全性的关键窗口期——谁能率先突破,谁就能掌握未来免疫治疗的话语权。
Part 04
未来可期,但这些挑战仍需突破
尽管巨头纷纷入局,体内CAR-T的前景被广泛看好,但我们必须清醒地认识到:这仍是一项“未成熟”的技术,距离大规模临床应用,还有几道难关要过。
对体内CAR-T而言,最大的挑战的是“精准递送”与“安全性”:
一方面,LNP技术虽因新冠疫苗趋于成熟,但新冠疫苗主要递送至肌肉细胞或抗原呈递细胞,而体内CAR-T需要精准递送至T细胞内部,一旦脱靶,可能引发严重不良反应;
另一方面,环状RNA的稳定性虽优于线性mRNA,但如何实现“可控表达”——既保证CAR-T细胞能有效发挥作用,又避免过度表达引发细胞因子风暴等致命风险,仍需大量临床数据验证。
而对礼来而言,24亿美元更像是一场“低风险期权”:成功了,就能手握颠覆自身免疫病治疗格局的利器,与现有免疫抗体药物形成完美互补,进一步巩固行业地位;即便失败,24亿美元相较于其每年数百亿美元的营收,也完全在可承受范围之内。
Part 05
巨头入局,改写医疗的暗流已至
回到最初的问题:礼来押注的体内CAR-T,真的是未来方向吗?
从礼来近年的战略成功率(替尔泊肽、DICE收购等)来看,它的每一次布局都经过深思熟虑,绝非追逐热点;从行业趋势来看,体内CAR-T解决了传统CAR-T“成本高、流程复杂”的核心痛点,无论是肿瘤还是自身免疫病领域,都有着不可替代的优势。
2026年,随着Orna等公司的临床数据陆续公布,体内CAR-T的技术价值将被进一步验证。但无论结果如何,当礼来这样的医药巨轮全力驶入这片赛道,就意味着改变人类医疗版图的暗流已经涌动。
对患者而言,这或许是摆脱疾病困扰的新希望;对行业而言,这是一场关乎未来话语权的竞争;而对我们而言,唯有持续追踪前沿,才能读懂这场医药变革的真正意义。
关注衍因科技,持续为你解读全球前沿生物医疗趋势,解锁更多科技背后的价值。
欢迎添加“小助手”领取试用
点击文末“阅读原文”,开启试用体验
衍因科技是中国领先的分子生物学科研平台,致力于成为全球AI for R&D Cloud领导者。
公司专注于开发基于AI大模型的企业级生物科研协作平台——衍因智研云,推行“3 +1 + N”的科研AI First战略框架,集成了生物信学套件、科研知识库套件、实验室协作套件、基因尺度大模型平台和多个智能助手。目前,衍因科技已为数百家生物医药企业、高等院校和科研机构提供服务,助力他们高效开展科研实验和数据分析,显著提升科研效率与成果质量。
免疫疗法细胞疗法并购信使RNA寡核苷酸
2026-02-16
引言
在“AI for Science”的浪潮下,药物研发正在经历一场从“筛选发现”到“从头设计(De Novo Design)”的范式转变。
传统的药物发现往往依赖于对现有化合物库的高通量筛选,但这在估计高达 1060 量级的庞大化学空间面前犹如大海捞针。近年来,生成式人工智能(Generative AI)作为一种强大的计算引擎,使得在广阔的化学空间中高效探索并生成具有特定属性的新颖分子成为可能。
近日,重庆大学薛伟伟教授团队与上海第二工业大学陈英军在期刊 ACS Chemical Neuroscience 上发表综述文章 “Machine Learning for De Novo Molecular Generation: A Comprehensive Review”。
该综述系统地梳理了机器学习驱动的分子生成领域,从分子表征、模型架构到评估框架进行了全景式解析,并特别关注了中枢神经系统(CNS)药物设计这一高难度领域的应用挑战。
( 影响因子: 3.93;JCR: Q2;中科院: 3区;TOP期刊: 否 )
摘要配图
图 1 本综述的整体结构与研究框架
01 分子表征:计算化学的“语言”
将分子的化学结构转化为计算机可读的格式,是所有计算流程的基石。文章总结了目前主流的三种分子表征方式及其优劣:
1D 字符串表示 (String-Based): 如经典的 SMILES 和近年来为解决语法有效性而提出的 SELFIES。这类表示计算效率高,兼容自然语言处理(NLP)模型,但缺乏3D构象信息。
2D 图表示 (Graph-Based): 将原子视为节点,化学键视为边。这是分子最自然的拓扑表达,具有旋转不变性,非常适合图神经网络(GNN),但同样忽略了空间立体信息。
3D 几何表示 (3D Geometry): 如点云(Point Clouds)和体素网格。对于基于结构的药物设计(SBDD)至关重要,能捕捉物理真实性,但计算成本高昂,且需处理旋转平移等变性(E(3)-equivariance)问题。
表 1 分子表征方法对比
02 生成模型分类学:六大流派各显神通
文章深入剖析了当前最先进的生成模型架构,不仅仅是描述原理,更批判性地分析了各自的“算法故障模式”:
表 2 生成模型架构的对比分析
图 2 模型示意图
1. 变分自编码器 (VAEs):
优势: 拥有平滑的连续潜空间,适合进行分子性质的梯度优化。
局限: 存在“有效性-质量权衡”问题,生成的分子往往结构较为模糊或单一。
表 3 分子生成中变分自编码器(VAE)方法与应用综述
2. 生成对抗网络 (GANs):
优势: 能生成高保真度的分子结构。
局限: 训练不稳定,容易出现“模式坍塌(Mode Collapse)”,即生成大量重复的分子;在结合强化学习时易发生“奖励黑客(Reward Hacking)”现象。
表 4 分子生成中生成对抗网络(GAN)方法综述
3. 循环神经网络 (RNNs) & Transformer:
优势: 基于序列生成,数据效率高。Transformer尤其擅长捕捉长程依赖(如大环分子的闭合)。
局限: 容易出现“化学幻觉”,即生成语法正确但化学上不合理的结构。
表 5 分子生成中循环神经网络(RNN)方法综述
表 6 基于 Transformer 的分子生成方法综述
4. 扩散模型 (Diffusion Models):
地位: 目前3D分子生成的SOTA(最先进)方法。
原理: 受非平衡统计物理启发,通过逆向去噪过程生成分子。
挑战: 采样速度慢,计算成本高。
表 7 分子生成中扩散模型方法综述
5. 其他模型: 包括归一化流(Normalizing Flows)和基于能量的模型(EBMs),以及结合多种架构优势的混合模型(如VAE+GAN,或Transformer+遗传算法)。
03 核心战场:CNS药物设计的挑战
本综述的一个独特视角是特别关注了中枢神经系统(CNS) 药物的生成。
CNS药物研发是药物化学的“皇冠明珠”,因为药物必须穿过血脑屏障(BBB)。这意味着生成模型不能仅仅优化结合亲和力,还必须在极窄的物理化学性质窗口内进行多参数优化(MPO):
严格的约束: 需同时满足低分子量、低极性表面积(TPSA)、适当的脂溶性(LogP)等。
安全性: 需规避P-糖蛋白(P-gp)外排和神经毒性。
策略: 文章指出,针对CNS领域,基于RNN的迁移学习和基于Transformer的双靶点配体设计展现出了巨大潜力。
图 3 药物发现中核心生成模型的代表性应用示例。
(a) 分布学习:抗菌类甲硝唑衍生物示例,IC50 = 6.85 μM(金黄色葡萄球菌)。
(b) 定向生成:NLRP3 抑制剂示例,IC50 = 44.43 nM。
04 现实差距与挑战
尽管算法日新月异,但在实际药物研发中大规模部署生成模型仍面临严峻挑战:
评估指标的虚幻: 传统的QED(药物相似性)和SA(合成可及性)分数往往只是粗糙的过滤器。很多模型在这些指标上得分很高,但生成的分子在药物化学家眼中却毫无意义。
合成可行性 (Synthesizability): 这是最大的痛点。虽然有CASP(计算机辅助合成规划)工具,但模型生成的许多“完美”分子在实验室中根本无法合成。
Oracle瓶颈: 生成模型依赖于预测器(Oracle)的反馈。如果预测器本身不准确(例如结合亲和力预测),模型就会陷入“垃圾进,垃圾出”的循环。
域外生成 (OOD): 真正的创新需要模型跳出训练数据的分布,探索未知的化学空间,但目前大多数模型仍倾向于插值而非外推。
表 8 评价指标与基准测试平台汇总
05 未来展望
文章最后指出了几个极具前景的发展方向:
大型语言模型 (LLMs): 利用海量文本数据进行预训练(如MolT5, ChemLLM),实现通过自然语言描述来生成分子。
物理感知人工智能 (Physics-Informed AI): 将数据驱动的方法与第一性原理(如DFT、MD模拟)相结合,提高生成的物理真实性。
自主实验室 (Self-driving Labs): 构建“设计-合成-测试”的闭环自动化系统,最大程度减少人工干预,加速科学发现。
06 结语
从早期的SMILES生成到如今基于扩散模型的3D结构设计,AI分子生成技术已经取得了长足的进步。然而,要真正实现从“计算生成”到“临床药物”的跨越,我们不仅需要更强大的算法,更需要深入理解化学与生物学的本质,建立更可靠的评估体系,并拥抱“干湿结合”的未来。
收稿日期:2025 年 11 月 3 日
修回日期:2026 年 1 月 28 日
录用日期:2026 年 2 月 2 日
论文信息:
Chen, Y., & Xue, W. (2025). Machine Learning for De Novo Molecular Generation: A Comprehensive Review. ACS Chemical Neuroscience.
https://doi.org/10.1021/acschemneuro.5c00861
100 项与 NLRP3抑制剂(拓界生物) 相关的药物交易
登录后查看更多信息
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 自身免疫性疾病 | 药物发现 | 中国 | 2020-11-20 | |
| 炎症 | 药物发现 | 中国 | 2020-11-20 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
| 研究 | 分期 | 人群特征 | 评价人数 | 分组 | 结果 | 评价 | 发布日期 |
|---|
No Data | |||||||
登录后查看更多信息
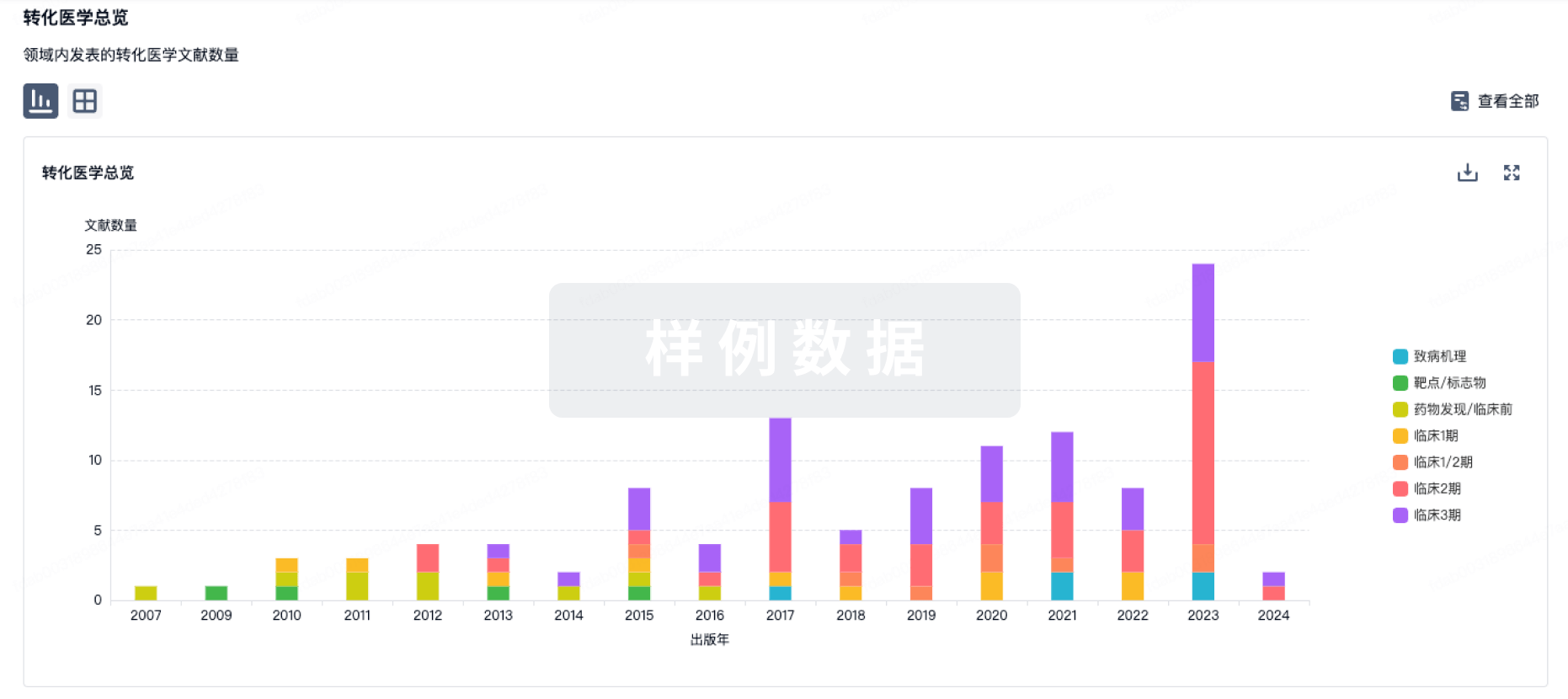
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用