预约演示
更新于:2026-06-06
PPI modulator (Gt Apeiron)
PPI 调节剂 (湃隆生物)
更新于:2026-06-06
概要
基本信息
原研机构 |
在研机构 |
非在研机构- |
权益机构- |
最高研发阶段临床前 |
首次获批日期- |
最高研发阶段(中国)临床前 |
特殊审评- |
关联
100 项与 PPI 调节剂 (湃隆生物) 相关的临床结果
登录后查看更多信息
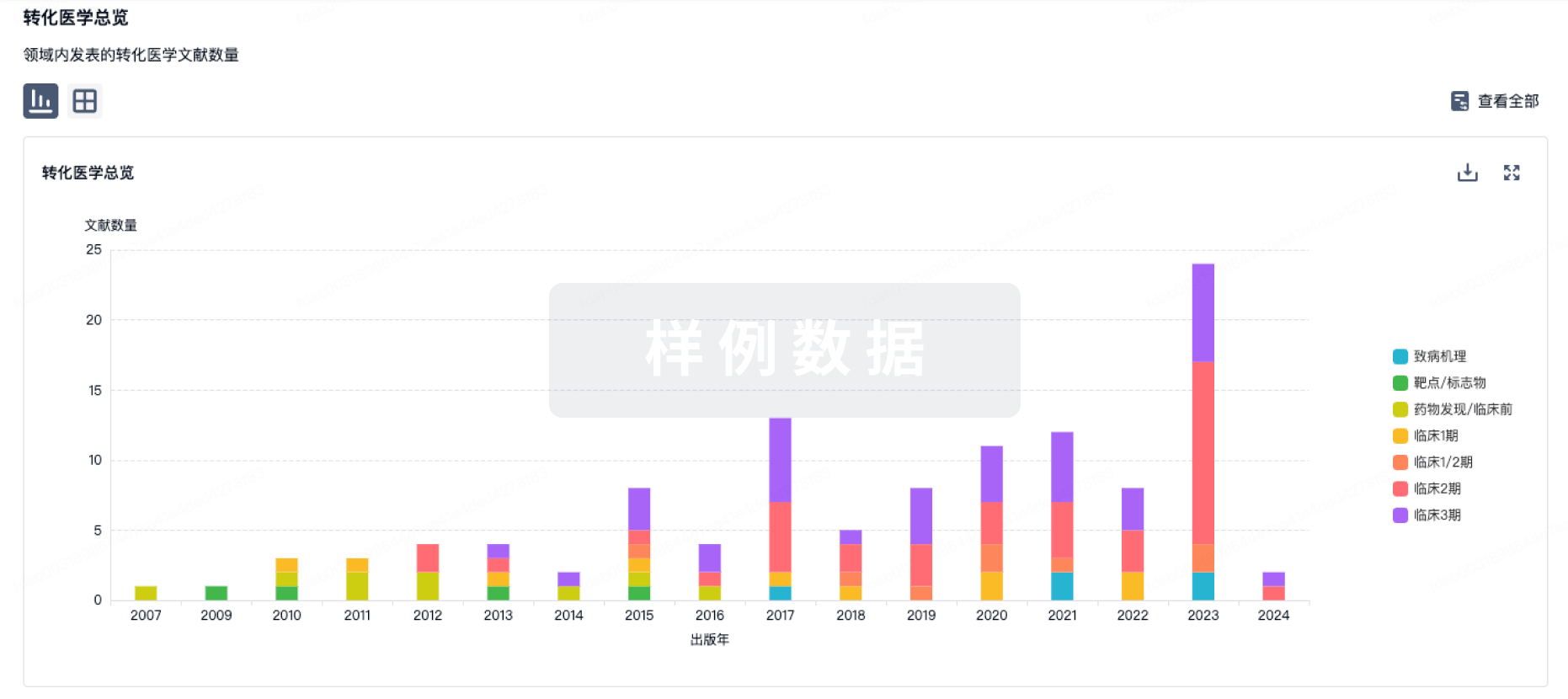
100 项与 PPI 调节剂 (湃隆生物) 相关的转化医学
登录后查看更多信息
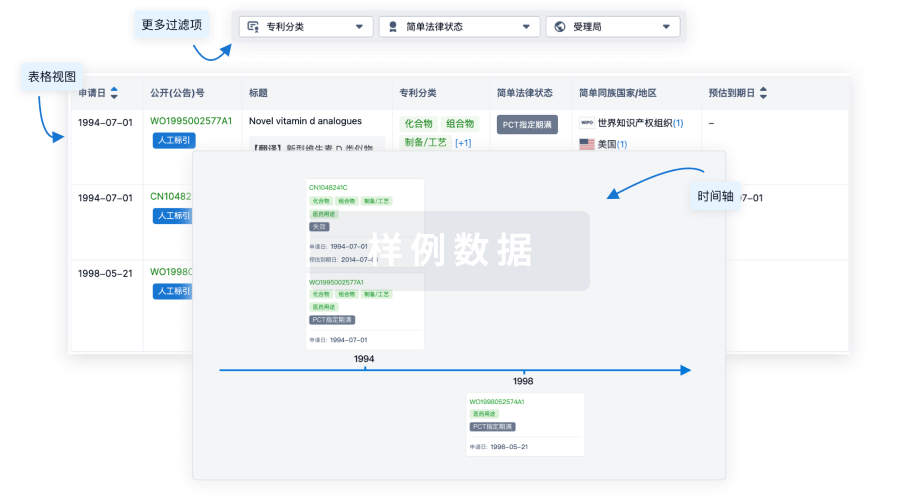
100 项与 PPI 调节剂 (湃隆生物) 相关的专利(医药)
登录后查看更多信息
4
项与 PPI 调节剂 (湃隆生物) 相关的新闻(医药)2026-03-15
Sun, Q.; Wang, H.; Xie, J.; Wang, L.; Mu, J.; Li, J.; Ren, Y.; Lai, L. Computer-Aided Drug Discovery for Undruggable Targets. Chem. Rev. 2025, 125 (13), 6309–6365. https://doi.org/10.1021/acs.chemrev.4c00969.0 摘要
难以成药靶标是指具有重要治疗意义但难以通过传统药物设计方法进行有效干预的一类靶标。这类靶标通常具有一些特殊特征,例如结构高度动态、缺乏明确的配体结合口袋、活性位点高度保守,以及其功能主要通过蛋白质−蛋白质相互作用进行调控。近年来,计算模拟技术和人工智能的发展正在深刻改变药物设计的研究格局,并催生出多种新的策略以克服这些困难。
该综述综述了针对难以成药靶标开展药物设计的最新计算方法进展,并结合若干成功案例进行说明,同时讨论当前仍然存在的挑战以及未来的发展方向。 重点关注四类主要靶标类型:内在无序蛋白、蛋白质别构调控、蛋白质−蛋白质相互作用以及蛋白降解机制,同时也对新兴靶标类型进行了介绍。
此外,还讨论了人工智能驱动方法如何改变这一领域的发展,从蛋白质−配体复合物结构预测和虚拟筛选,到针对难以成药靶标的从头配体生成等方面均取得显著进展。计算方法与实验技术的进一步整合有望带来新的突破,从而克服难以成药靶标带来的挑战。随着该领域持续发展,这些进展有望拓展可成药靶标空间,为过去难以治疗的疾病提供新的治疗机会。4 靶向蛋白质-蛋白质相互作用的药物设计4.1 蛋白质-蛋白质相互作用作为药物靶点
蛋白质-蛋白质相互作用(protein-protein interactions,PPIs)指两个或多个蛋白之间形成的特异性物理接触,这些相互作用通常由氢键、疏水作用以及静电相互作用等驱动。PPIs在多种生物学过程中发挥核心作用,例如细胞信号传导、细胞增殖、分化、凋亡以及侵袭等。大量研究与统计分析表明,人类数据库中大约包含19000种蛋白质,它们之间可形成约130000至650000对蛋白质相互作用。此外,PPIs在多种疾病的发生发展中也发挥关键作用。例如,一些特定的PPIs与多种癌症的进展密切相关,同时也参与阿尔茨海默病和心血管疾病的发生。因此,PPIs被认为是极具吸引力的治疗靶点,并为新型治疗策略的开发提供了巨大的潜力。
然而,由于PPIs界面通常具有平坦、面积大且高度疏水的特征,小分子药物往往难以有效靶向这些界面,因此PPIs长期以来被认为是不可成药或难以成药的靶点。首先,PPIs界面的面积通常在1500至3000 Ų之间,远大于典型小分子与靶标之间约300至1000 Ų的接触面积。其次,这些界面通常具有较高的疏水性,其核心区域通常由芳香族残基构成,并且相对于其他区域更为保守。这些核心残基使蛋白之间形成较高的结合亲和力,从而增加了小分子药物竞争结合的难度。第三,PPIs界面通常缺乏传统酶或受体靶点中常见的凹形结合口袋,而更多呈现为平坦结构,仅包含较少的沟槽或口袋,因此小分子难以实现稳定结合。此外,与传统靶点不同,PPIs通常缺乏可供参考的内源性小分子配体,这进一步增加了药物设计的难度。
在过去,针对PPIs的药物开发主要集中在抗体药物。由于抗体具有较大的结合界面以及较高的靶标特异性,已经成功应用于多个PPI靶点并实现商业化。然而,抗体药物存在生产成本高、口服生物利用度差、可能引发免疫反应以及通常无法穿透细胞膜等问题,这些因素限制了其应用范围。相比之下,肽类分子能够模拟PPI界面的复杂结构特征,并能够根据不同PPI采用多种结构形式,因此被认为是具有潜力的候选分子。与抗体相比,肽类分子的生产与修饰更为简单,但其在生理条件下稳定性较差,容易受到蛋白酶降解,体内半衰期较短且口服生物利用度较低。近年来,通过环肽设计以及引入非天然氨基酸等策略,在一定程度上提高了肽类分子的稳定性和功能表现。
此外,随着深度学习技术的发展,研究者已经能够直接根据PPI界面设计具有高亲和力的小型蛋白结合体,从而生成新的蛋白质配体。然而,这些创新设计要转化为实际应用仍需要进一步的发展和优化。近年来,小分子药物在药物开发中越来越受到重视,因为其具有明显优势,包括更好的药代动力学性质以及更强的细胞膜穿透能力,能够有效靶向细胞内PPIs。同时,小分子药物在生产、储存和运输方面也更加经济便捷。尽管小分子靶向PPIs的设计面临诸多挑战,但随着筛选技术的进步、结构解析方法的改进以及计算模拟能力的提升,小分子PPI调节剂的发现和优化取得了显著进展。目前已有6种小分子PPI调节剂(图10)获得美国食品药品监督管理局(FDA)批准,包括Venetoclax、Maraviroc、Tirofiban、Tacrolimus、Sirolimus和Tafamidis,分别用于治疗慢性淋巴细胞白血病、获得性免疫缺陷综合征、急性冠状动脉综合征、肝移植、肾移植以及转甲状腺素蛋白淀粉样变性。此外,还有超过27种靶向PPIs的小分子调节剂处于临床研究阶段。4.2 PPI调节剂的分类
靶向PPIs的小分子调节剂根据其结合位点和功能作用可以大致分为四类:正构抑制剂、正构稳定剂、别构抑制剂以及别构稳定剂。这些不同类别具有各自的特点和研究难点,也反映出不同的发展阶段和治疗潜力。
正构抑制剂是目前研究最为广泛的一类。其作用机制是直接结合PPI界面中的某一个蛋白,从而阻断两个蛋白之间的相互作用。由于正构抑制剂的作用机制相对明确,已经发展出多种设计与优化策略,因此成为PPI调控研究的重点方向。然而,由于PPI界面通常平坦且缺乏明显结构特征,发现具有高效力和高选择性的正构抑制剂仍然具有较大挑战。
正构稳定剂同样结合在PPI界面上,但其作用方式不同。这类分子能够同时与两个蛋白发生相互作用,从而稳定或增强蛋白之间的相互作用。目前正构稳定剂的研究仍相对较少,许多相关发现往往是偶然获得。其设计难度较高,因为分子需要能够同时识别并结合两个蛋白。不过,这类分子通常不需要与内源性配体竞争强亲和力结合,并且能够结合于瞬时或特异的界面,从而提高选择性并减少脱靶效应。
别构抑制剂和别构稳定剂则通过另一种方式调控PPIs。这类分子并不直接结合在PPI界面上,而是结合于蛋白上的别构位点。通过结合这些位点,分子可以诱导蛋白发生构象变化,从而破坏或稳定PPI。因此,别构调节剂不需要直接作用于平坦的PPI界面,是调控PPIs的一种有效策略。然而,其主要挑战在于识别合适的别构位点,因为这些位点通常比正构位点更难预测。由于第3节已经对靶向别构位点的药物设计策略和挑战进行了详细讨论,该节将主要关注正构抑制剂和正构稳定剂的研究进展。
表4|用于预测热点位点的计算工具4.3 PPI中可成药位点的识别策略
尽管PPI界面通常面积较大且看似缺乏明显结构特征,Clackson和Wells最早发现,在人生长激素与其受体的相互作用中,仅有少数残基对蛋白之间的相互作用起关键作用。这些残基被称为“热点位点”(hot spots),随后大量研究证实这一现象在PPI中普遍存在。在实验上,热点位点通常通过丙氨酸扫描突变(alanine scanning mutagenesis)进行识别。如果将某个残基突变为丙氨酸后结合自由能变化
大于2 kcal/mol,则该残基被认为是热点位点。对已有热点数据的分析表明,色氨酸、精氨酸和酪氨酸是PPI界面中最重要的贡献残基,分别占21%、13.3%和12.3%,而缬氨酸、丙氨酸和甘氨酸等残基很少出现在热点区域。
由于热点残基对结合自由能贡献最大,因此如果小分子能够结合这些位点,就有可能显著影响蛋白之间的相互作用并调控下游功能。热点区域的面积通常约为600 Ų,仅占整个界面的约9%。此外,热点区域的理化特性使其具有较低的构象变化能垒,因此具有较高的柔性,并能够与配体形成氢键、
堆积、疏水作用以及静电相互作用等多种相互作用,这些特点使得设计靶向PPI的小分子成为可能。例如,Arkin等人发现一种小分子能够结合细胞因子IL-2的热点区域,并诱导形成一个在游离状态下不存在的沟槽结构。Bruncko等人在Bcl-xL与化合物43b结合时也观察到比原始BH3复合物更深的沟槽。
需要注意的是,丙氨酸扫描只能从能量贡献角度识别热点残基,而真正的可成药位点还需要具备适合小分子结合的拓扑结构。共识位点(consensus site)是指能够结合多种化学探针的蛋白区域,通常具有凹形结构并与药物结合位点重叠。研究表明,共识位点与热点位点高度相关,可视为热点的一部分。总体而言,识别热点位点是设计靶向PPI小分子的基础。当前已经开发出多种热点预测的计算方法,大体可以分为三类:基于能量的方法、基于分子动力学的方法以及基于机器学习的方法(表4)。
最早且最著名的基于能量的方法包括FOLDX和Robetta,这两种方法均用于虚拟丙氨酸扫描。其基本思路是利用侧链重排算法将界面残基逐一突变为丙氨酸,同时保持其他结构不变,然后分别计算原始蛋白和突变蛋白在结合态和未结合态下的能量变化,从而得到结合自由能的变化。FOLDX的能量函数包括范德华作用、氢键、溶剂化效应、熵变化以及库仑静电相互作用,而Robetta的能量函数则包含隐式溶剂化、Lennard-Jones相互作用、
堆积以及氢键等项。这些方法在数据库数据上进行了训练,其预测结果与实验数据具有较好一致性。例如,Robetta在测试集中的平均误差为1.06 kcal/mol,并能够正确识别79%的热点位点,而FoldX的标准差为0.88 kcal/mol。
FTMap是另一种常用的在线工具,用于识别共识位点。该方法利用经验能量函数将不同的小分子探针分子对接到蛋白表面,通过快速傅里叶变换相关算法在蛋白表面采样数十亿个可能的结合位置,并使用包含非极性包埋、成对相互作用、电荷作用以及范德华相互作用的能量函数进行评估。排名前2000的对接构象随后用于能量最小化和聚类分析,其中包含多个低能量簇的区域被认为是共识位点。此外,还有一些基于贝叶斯网络或界面分析的方法,例如PP_Site和PCRPi。大多数上述方法基于分子力学原理。近年来,Monteleone等人开发了基于量子力学片段分子轨道(fragment molecular orbital,FMO)方法的FMO-PPI,该方法能够从定点突变实验中成功识别热点,并提供蛋白-蛋白界面相互作用性质和强度的详细信息。
分子动力学模拟同样基于能量计算,并能够提供结构随时间变化的动态信息,因此可以更好地处理PPI界面的柔性并解释相互作用机制。基于分子力学/泊松-玻尔兹曼表面积(MM/PBSA)或分子力学/广义Born表面积(MM/GBSA)的自由能分解分析是一种常见策略,可用于计算单个残基对结合能的贡献并识别界面中的关键残基。此外,还可以将蛋白置于含有多种化学探针分子的溶液中,通过MD模拟探针与蛋白表面的相互作用。当系统达到平衡后,探针分子会在可结合区域聚集,从而揭示共识位点。尽管PPI界面通常较为平坦,但在小分子结合时可能发生构象变化并形成潜在结合口袋。因此,通过结合MD模拟的大规模构象采样以及传统口袋检测算法,也可以识别可成药位点。
这些方法在PPI药物设计的早期阶段被广泛应用。例如,Jiang等人利用MM-PBSA自由能分解分析研究了Nrf2与Keap1之间的关键结合残基,并发现两个重要的亚口袋。Ozdemir等人通过对Cdc42-GRD2复合物在突变前后的全原子MD模拟进行比较,分析了能量差异,从而阐明了两者相互作用的分子机制,并为后续药物设计提供了思路。
随着实验突变数据的不断积累,机器学习方法也逐渐被用于热点识别。这类方法通常利用基于序列、结构或进化信息的多种特征作为输入,并在已有热点数据上训练分类模型。由于目前可用数据量仍然有限,大多数方法采用传统机器学习模型,例如朴素贝叶斯、支持向量机、逻辑回归、决策树以及神经网络等。著名的KFC工具利用残基大小、残基类型、界面接触点以及原子接触等结构特征作为输入,并结合两个决策树模型进行预测,其召回率达到58%。随后升级的KFC2利用支持向量机模型并引入8种新的结构特征,将真正例识别率提高到0.85。其他代表性方法列于表4。值得注意的是,近期研究开始利用自动化机器学习框架AutoGluon自动选择合适模型进行热点预测。4.4 PPI小分子调节剂的化学空间
为了适应PPI界面独特的结构特征,靶向PPI的小分子调节剂在化学性质上与传统小分子药物存在显著差异。传统药物通常遵循Lipinski“五规则”,即
、分子量小于500、氢键供体数量小于10、氢键受体数量小于5。Lagorce等人对多个数据库中收集的数千个PPI抑制剂进行了理化性质和ADMET性质分析,发现PPI抑制剂的水溶性明显低于靶向酶、离子通道和GPCR的药物分子,同时约70%的PPI抑制剂违反了Lipinski五规则。
此外,在分子量与
的关系图中,“黄金三角”区域中的分子通常具有较好的膜通透性和较低的清除率,而几乎所有PPI抑制剂都位于该区域之外,其分子量明显大于传统药物(图11)。Morelli等人还利用两种配体效率指标分析了PPI抑制剂,即结合效率指数(binding efficiency index,BEI)和表面效率指数(surface efficiency index,SEI)。其中BEI为
与分子量之比,SEI表示单位极性表面积上的结合自由能。研究比较了92种上市药物和2P2I数据库中的39种PPI抑制剂,发现传统药物的BEI和SEI平均值分别为25.8和14.5,而PPI抑制剂仅为11.7和7.2。这些较低的数值表明PPI抑制剂通常具有更大的分子量和极性表面积,这在药物开发中通常是不利的。
此外,PPI抑制剂通常同时占据多个小口袋,这些口袋平均体积约为55 ų,而传统药物通常结合于一个平均体积约260 ų的大型口袋。对1500个PPI抑制剂的分析进一步明确了PPI抑制剂的化学空间,其典型性质包括:200 < 分子量 < 900、−1 < cLogP < 9.5、2 < 氢键受体数 < 12、0 < 氢键供体数 < 6、20 < 极性表面积 < 185、1 < 可旋转键数 < 15。
目前商业化化合物库主要针对传统药物靶点设计,其中许多分子并不位于PPI调节剂所需的化学空间内。因此,为提高PPI药物设计的成功率,有必要建立专门针对PPI调节剂的化合物库。一种简单方法是对现有化合物库进行理化性质筛选,将符合条件的分子收集到新的库中。此外,还可以利用机器学习模型区分PPI调节剂与非PPI调节剂。例如,Neugebauer等人利用分子组成、分子轮廓、官能团数量以及分子性质等描述符训练决策树模型,该模型基于25个PPI抑制剂和1137个FDA批准药物建立,在测试集上获得超过0.9的真正例识别率。
Bosc等人基于2P2IDB和iPPI-DB数据库训练了随机森林、支持向量机和决策树等多种模型,其中表现最好的支持向量机模型AUC超过0.8。随后利用这些模型从ZINC数据库中预测潜在的PPI调节剂,并经过理化性质筛选和聚类分析,建立了包含10314个分子的PPI调节剂富集化合物库Fr-PPIChem。针对免疫检查点CD47及其受体SIRPα的高通量实验表明,与普通化合物库相比,Fr-PPIChem库中活性分子的比例提高了46倍。这一研究表明,通过机器学习构建富集PPI调节剂的化合物库具有重要意义,也为未来PPI药物设计提供了有效策略。
图11|靶向蛋白质-蛋白质相互作用的小分子调节剂与其他类型靶点药物分子的特征比较。 (A)溶解度预测。包括酶类(浅蓝)、离子通道(蓝色)、GPCR(紫色)、核受体(黄色)、别构调节剂(棕色)、PPI抑制剂(iPPIs,橙色)、口服上市药物(OMD,浅绿色)以及天然产物来源上市药物(NPD,深绿色)。(B)Lipinski五规则(RO5)违反数量的直方图分布。(C)各数据集在“黄金三角”中的分布示意图。位于黄金三角区域内的分子(蓝色点)通常具有更好的膜通透性以及较低的体内清除率。图转载自文献493,经许可使用。版权归David Lagorce等人所有(2017),依据Creative Commons Attribution 4.0 International License发布:http://creativecommons.org/licenses/by/4.0/。4.5 小分子PPI调节剂的设计策略
早期针对蛋白质−蛋白质相互作用(PPI)的小分子设计主要依赖高通量实验筛选。然而,由于未充分考虑PPI调节剂所处的特殊化学空间,这类方法的命中率通常较低。随着结构生物学数据的不断积累以及“热点(hot spots)”概念的提出,基于理性设计的小分子PPI药物开发逐渐成为可行策略。一般而言,理性设计首先需要获得蛋白质复合物的三维结构,其次识别界面上的关键热点残基,随后依据这些结构信息进行分子设计或虚拟筛选。
目前用于设计小分子PPI调节剂的计算策略主要包括四类:基于查询(query)的设计策略、基于片段的策略、基于分子力学或药效团模型的策略以及基于机器学习的策略。基于查询的策略通过模拟蛋白质界面关键相互作用来构建小分子结构。由于界面热点通常呈离散分布,基于片段的策略通过片段连接、片段优化或片段自组装等方法,将多个已知低亲和力片段组合,从而获得更有效的化合物。基于分子力学或药效团模型的策略则结合分子动力学模拟、分子对接以及药效团模型,从已有化合物库中筛选潜在分子。机器学习策略则利用多种模型从已有PPI调节剂数据中学习规律,并将这些模式应用于新的化合物数据集中,以提高筛选效率和预测能力。4.5.1 基于查询的设计策略
在该策略中,query通常指供体蛋白中对结合起关键作用的热点残基。基于查询的方法大体可分为两类:基于锚点(anchor)的设计方法以及蛋白质二级结构模拟方法。
锚点是query中的某个关键残基,该残基通常深埋于受体蛋白内部,并与相对稳定的结合口袋发生作用,因此可以作为设计的起始点。在此基础上可以采用三种扩展方式。第一种方法通过对锚点侧链进行子结构搜索以寻找新的骨架结构,然后在此骨架基础上进一步扩展,以增强与其他热点残基的相互作用,从而提高结合亲和力。第二种方法利用de novo分子设计软件或虚拟化合物库构建工具,对锚点结构进行延伸。第三种方法则通过寻找锚点的生物电子等排体(bioisosteres),以模拟其与受体蛋白之间的关键相互作用。
锚点策略已被应用于多种PPI体系的调节剂设计,其中最成功的案例之一是p53/MDM2体系。研究发现,p53 α螺旋上的三个疏水残基F19、W23和L26形成一个关键热点区域,其中W23深嵌入MDM2的凹形结合口袋中。因此研究人员以W23作为锚点进行子结构搜索,最终得到螺环氧吲哚(spirooxindole)骨架。在该结构中,吲哚环用于模拟W23侧链的结合模式,而两个疏水取代基则用于模拟F19和L26侧链的相互作用。初始获得的抑制剂对p53/MDM2相互作用的抑制常数为
。经过多轮优化后,化合物MI-888的
提高至44 nM,并已进入抗肿瘤药物的临床试验阶段。
在多数PPI体系中,三种关键二级结构元件——α螺旋、β转角以及β折叠——在相互作用中发挥主要作用。因此,寻找能够模拟这些结构关键相互作用的小分子,往往是一种更加直接且有效的策略。构建此类模拟分子通常有两种思路。第一种是拓扑模拟(topographical mimetics),即模拟目标二级结构中热点残基的空间取向及其组成特征。第二种方法则侧重于复制这些相互作用的生物学功能,而不必严格保持结构上的相似性。
近年来,Celis等人开发了一种基于query匹配的PPI抑制剂发现计算框架。该方法首先将热点残基映射到相应的二级结构上以构建query,然后通过比较分子形状相似性,从虚拟化合物库中筛选候选小分子(图12)。随后利用该框架设计了针对p53/MDM2和GKAP/SHANK1-PDZ体系的抑制剂。实验结果验证了该方法的有效性。例如,从p53中提取包含三个热点残基的短肽序列“ETFSDLWKLLPEN”作为query,通过FastROCS工具进行结构相似性搜索并结合分子对接筛选候选分子。最终得到的化合物A1在竞争荧光各向异性实验和
-
HSQC实验中均表现出与MDM2结合并与p53竞争的能力。
图12|展示了查询引导的蛋白质-蛋白质相互作用(PPI)抑制剂发现机制示意图,其中小分子可能通过模拟不同的二级结构来发挥作用。4.5.2 基于片段的策略
PPI界面通常包含多个分散的小型结合口袋,而通过随机实验筛选获得的小分子往往只能结合其中一个亚口袋,从而导致结合亲和力较弱。基于片段的药物设计(fragment-based drug design,FBDD)通过将多个分子片段连接在一起,使分子能够同时占据多个口袋,从而有效提高结合能力(图13)。初始片段既可以通过实验筛选获得,也可以借助分子对接等虚拟筛选方法得到。然而,FBDD高度依赖结构信息的准确性,需要确认小分子片段确实结合在目标位点上,并确保在片段连接后分子构象不会发生显著变化。
FBDD不仅在传统药物靶点的设计中取得成功,也被广泛应用于PPI调节剂的开发,例如Bcl-xL/Bad、IL-2/IL-2Rα以及TNF-α/TNFR1抑制剂的设计。Zhao等人利用Glide程序将片段库中的分子对接到BRD4(I)结合位点,并通过X射线晶体学鉴定出9个结合片段。随后结合晶体结构提供的相互作用信息,并将候选片段的结合模式与已知高活性化合物JQ1进行比较,通过片段生长策略最终获得活性提高超过10倍的化合物。
Li等人提出了一种结合多配体同时对接(multiple ligand simultaneous docking,MLSD)和片段连接的药物再利用策略。该方法首先将多个分子片段同时对接到热点位点上,然后将命中片段连接形成模板分子,再以该模板在已获批药物库中进行相似性搜索。通过这一策略,Raloxifene和Bazedoxifene被识别为IL-6/GP130相互作用的潜在抑制剂。癌细胞实验表明,这两种化合物能够结合GP130并选择性抑制IL-6诱导的STAT3磷酸化。
基于片段的方法同样可用于PPI稳定剂的设计,其中多数策略依赖实验获得的初始片段。例如Guillory等人将接头蛋白14-3-3与致癌转录因子TAZ的复合物结构浸泡在片段混合物中,通过X射线晶体结构解析识别出能够同时与两种蛋白结合的片段,从而为PPI稳定剂的设计提供了起始结构。4.5.3 基于分子力学与药效团的策略
分子对接、分子动力学(MD)模拟以及药效团建模是药物设计中常用的虚拟筛选技术。分子对接能够预测小分子的结合位点及其结合构象,并提供计算得到的结合能信息。对于尚未深入研究的PPI靶点,可以根据预测得到的热点残基构建药效团模型,从化合物库中筛选潜在分子。MD模拟则能够揭示蛋白质结构的动态变化,不仅可用于识别热点残基,还可对蛋白质初始构象进行广泛采样。此外,MD模拟还可用于评估小分子-蛋白质复合物的稳定性并探索相关信号机制,因此在虚拟筛选过程中具有重要价值。
例如Khanna等人采用多构象策略对uPA/uPAR体系进行虚拟筛选。研究对两个已知的uPAR晶体结构进行MD模拟,构建包含50种构象的构象集合,并利用AutoDock4将小分子对接到这些构象中。经过聚类分析后选择排名靠前的化合物进行实验验证,初步筛选得到的分子具有
的结合能力。随后通过进一步的MD模拟以及MM/PBSA自由能计算分析其结合机制。
Xu等人提出了一种结合分子对接和MD模拟的通用虚拟筛选框架(图14)。研究通过虚拟丙氨酸突变扫描和MM/PBSA能量分解确定热点残基,并利用基于MTDH-SND1复合物
MD轨迹的口袋检测算法MDPocket确定MTDH上的潜在结合位点。随后利用AutoDock Vina进行分子对接,并通过MD模拟对结果进一步筛选。在测试的10个候选分子中,有7个表现出小于
的
值。
上述抑制剂的设计通常基于单一蛋白结构进行虚拟筛选,而PPI稳定剂的设计则需要同时考虑两种蛋白之间的相互作用。一种方法是分别以PPI中两种蛋白结构进行多轮对接,然后综合比较两者的对接评分以筛选潜在稳定剂。另一种方法则直接以PPI复合物结构作为对接输入,并将结合口袋限制在两种蛋白的界面处。例如Sijbesma等人基于14-3-3与碳水化合物反应元件结合蛋白(ChREBP)的复合物结构构建结合口袋,并采用诱导契合对接方法考虑口袋中侧链构象的变化。在对471个化合物进行对接并进行人工筛选后,选择13个分子进行实验测试,其中两种化合物分别使ChREBP与14-3-3之间的结合亲和力提高约10倍和4倍。
此外,Chen等人提出了一种类似的计算流程用于设计PPI稳定剂。该流程首先利用实验或预测得到的复合物结构,在PPI界面识别潜在结合位点。可以使用如Fpocket等口袋预测算法定位可成药口袋,并结合MD模拟进一步发现界面上隐藏或瞬时出现的结合口袋。在确定合适的结合位点后,再通过分子对接和MM/GBSA自由能计算对候选分子进行筛选,从而获得潜在的PPI稳定剂。
图13|基于片段的药物发现的一般流程。4.5.4 基于机器学习的策略
随着结构表征技术和化学生物学方法的快速发展,出现了许多专门收集小分子PPI调节剂数据的数据库,例如iPPIDB、2P2IDB、TIMBAL以及DLiP-PPI library。这些数据库包含数千条小分子PPI调节剂的活性数据,为机器学习模型的训练提供了重要基础。目前数据库中涉及的PPI体系主要包括Bcl2/Bax、MDM2/p53、RBD/hACE2、Bromo/Histone、CD4/gp120、XIAP/Smac、RAS/SOS1以及Keap1/Nrf2等。
早期模型如SMMPPI、PPI-ML、pdCSM-PPI和SELPPI通常以分子指纹、拓扑特征或理化性质作为输入特征,并利用支持向量机、随机森林等传统机器学习算法建立分类或回归模型。这类模型主要用于预测某一分子是否可能成为PPI抑制剂,或估计其具体活性。近年来提出的HiGPPIM模型则引入图神经网络,用于提取更加复杂的分子图结构特征。
然而,上述模型通常高度依赖已知小分子的结构数据,因此在面对新的PPI靶点时适用性有限。更合理的策略是同时将蛋白质信息纳入模型中。例如MultiPPIMI模型同时使用分子的SMILES表示以及参与PPI的蛋白质序列作为输入。该模型通过图神经网络提取分子图特征,并利用大规模预训练蛋白语言模型ESM2从蛋白质序列中提取特征,从而提高模型的泛化能力(图15)。此外,还开发了一些针对PPI体系的三维分子生成模型,例如iPPIGAN。
现有机器学习方法几乎都集中于PPI抑制剂的预测,其分类准确率通常超过0.8。这主要是因为目前可用于训练的数据中,抑制剂数量远多于稳定剂,而稳定剂相关数据仅有数百条。在这些方法中,仅HiGPPIM模型被用于区分PPI稳定剂与PPI抑制剂,其分类准确率达到0.94。尽管这些模型表现出较好的预测能力,但现有研究在构建训练集和测试集时通常未严格控制分子相似性,这可能导致模型过拟合。此外,这些模型的预测结果仍缺乏系统性的实验验证,因此其在实际应用中的表现仍有待进一步探索。
图14|结合分子对接与分子动力学(MD)模拟的通用虚拟筛选框架。4.6 讨论与展望
蛋白质-蛋白质相互作用(PPI)调节剂的设计,核心基础在于识别结合界面上的热点残基。目前,热点预测技术已显著成熟,在诸多案例中广泛应用,为PPI药物发现奠定了坚实基础。当热点残基位置邻近且能形成合适结合位点时,可设计正构调节剂靶向这些区域;然而,若界面缺乏明确热点,或热点分布过于分散以致无法形成有效结合位点,变构调节剂往往通过诱导构象变化间接调控PPI,表现出更优效果。
正构调节剂的设计方法主要包括基于查询的策略、基于片段的策略、基于分子力学或药效团的方法,以及基于机器学习的策略。其中,基于查询的策略主要用于设计抑制剂,后三种方法则同时适用于抑制剂与稳定剂的开发。就计算手段设计稳定剂而言,相关研究仍较有限——由于缺少清晰的设计原则,目前稳定剂的发现仍主要依赖高通量筛选等实验方法。此外,稳定剂数据的匮乏也制约了机器学习方法的应用,现有模型多聚焦于抑制剂。鉴于稳定剂在由突变或功能丧失引发的疾病中具备重要治疗潜力,未来应加强对稳定剂的探索,开展更多计算尝试,并深化对其作用机制的理解。
其次,当前用于PPI调节剂的机器学习方法仍处于早期阶段,泛化能力有限,且缺乏实验验证。解决这一问题的关键在于利用实验数据对模型进行迭代优化,以提升其性能与可靠性。最后,尽管已明确PPI调节剂与传统药物分子在理化性质上存在显著差异,但针对这一独特化学空间的认知与利用仍显不足。多数研究仍使用常规商业化合物库,部分原因在于针对PPI调节剂的专用库稀缺且成本高昂。因此,未来需优先借助先进合成技术开发PPI调节剂的专用化合物库,丰富其化学多样性,进而提高筛选命中率。5 靶向蛋白质降解的药物设计5.1 蛋白质降解概述
蛋白质的合成与降解是生命活动中至关重要的过程。在真核细胞中,细胞内蛋白质降解的主要途径是泛素-蛋白酶体系统(ubiquitin-proteasome system,UPS)。该系统由泛素激活酶(E1)、泛素结合酶(E2)、泛素连接酶(E3)、泛素分子、26S蛋白酶体以及目标蛋白共同组成。近年来,靶向蛋白质降解(targeted protein degradation,TPD)已成为药物研发的重要方向并受到广泛关注。根据作用机制和化学结构的不同,降解剂通常可分为两类:双功能分子降解剂以及分子胶降解剂。
双功能分子降解剂的典型代表是蛋白降解靶向嵌合体(proteolysis-targeting chimera,PROTAC)。PROTAC由E3连接酶配体和目标蛋白(protein of interest,POI)配体组成,两者通过柔性或刚性的连接臂连接。该结构设计能够将目标蛋白与E3连接酶拉近,从而促进POI的泛素化并随后被蛋白酶体降解。与传统小分子抑制剂不同,PROTAC依赖“事件驱动”的降解机制,而非“占位驱动”的结合机制。这种策略显著降低了对靶点作用模式的依赖性。PROTAC只需要能够结合POI的配体,而不必是传统意义上的抑制剂,因此能够拓展对以往难以成药蛋白的调控能力。
分子胶(molecular glue)是一类能够诱导两个蛋白靠近的小分子,通过促进蛋白之间的相互作用,实现对蛋白折叠、定位或降解过程的精确调控。分子胶降解剂(molecular glue degraders,MGDs)主要通过诱导E3连接酶与底物蛋白之间形成新的蛋白−蛋白相互作用,从而实现靶向蛋白降解。与通常形成三元复合物的PROTAC不同,MGD首先与E3连接酶形成二元复合物,在此基础上形成新的蛋白-小分子界面以结合目标蛋白(图16)。这种独特机制使得MGD在不依赖靶蛋白特定结合口袋的情况下,也能够降解一些传统上难以成药的靶点。此外,由于缺少连接臂结构,MGD通常具有更小的分子量以及更有利的药代动力学性质。
PROTAC通常来源于理性设计,而分子胶降解剂往往最初通过偶然发现获得,因此其理性设计难度更大。不过近年来该领域仍取得了显著进展。例如,通过对CRBN配体进行特定修饰,可以实现对不同底物蛋白的选择性降解。目前已报道多种靶向GSPT1、IKZF1/3、IKZF2、CK1α、ZBTB16、WEE1以及VAV-1的降解剂,其中部分已进入临床研究阶段。
除泛素-蛋白酶体系统外,还存在其他能够实现蛋白降解的策略,用于靶向传统上难以成药的蛋白。例如LYTAC可用于降解膜蛋白和分泌蛋白,而ATTEC和AUTAC则可通过溶酶体途径实现蛋白降解。该综述后续部分主要关注TPD领域的研究进展以及最新的计算辅助TPD技术,并重点讨论其在难成药靶点中的应用。
表5|靶向难成药靶点的代表性降解剂。5.2 难成药靶点的降解策略
KRAS长期以来被认为是难以成药的靶点,直到Shokat团队发现KRAS
突变体可以通过共价方式进行调控,这一突破推动了Adagrasib和Sotorasib等药物的开发。LC-2是首个能够诱导内源性KRAS
发生泛素化并实现降解的PROTAC,其
处于亚微摩尔范围(表5)。该分子由共价KRAS
抑制剂MRTX849与VHL配体连接而成。与MRTX849相比,LC-2在部分细胞系中的抗增殖活性较弱,这部分归因于MRTX849的共价结合模式限制了PROTAC“事件驱动”降解机制的优势。基于非共价pan-KRAS抑制剂BI-2865,也开发了pan-KRAS降解剂。Ciulli团队将BI-2865衍生物与VHL配体连接,构建出高效降解剂ACBI3,可选择性靶向17种常见KRAS突变中的13种。由于采用非共价结合的warhead,该类pan-KRAS降解剂在细胞和动物模型中均表现出优于KRAS抑制剂的效果。
SHP2由于其PTP结构域带有正电荷且在PTP家族中高度保守,一直被视为难成药靶点。SHP2-D26是首个针对SHP2设计的PROTAC,利用VHL配体实现降解,在KYSE520和MV4-11细胞系中的
分别为6.0 nM和2.6 nM,并在抑制癌细胞生长方面优于对照SHP2抑制剂。此外,还开发了利用CRBN配体的降解剂,例如以沙利度胺为配体设计的SP4543和ZBS-29,以及以泊马度胺为配体的R1-5C。
信号转导与转录激活因子(STAT)家族是参与细胞生长、分化和凋亡等多种生物过程的重要转录因子,也是癌症、炎症及自身免疫疾病的潜在治疗靶点。然而目前尚无直接靶向STAT蛋白的获批药物。Wang团队在STAT降解剂研究方面取得重要进展,例如基于磷酪氨酸模拟抑制剂和CRBN配体设计的STAT3降解剂SD-36,该分子在细胞模型中对STAT3具有高度选择性(相较其他STAT蛋白选择性超过100倍)。随后又开发了STAT5选择性降解剂AK-2292以及STAT6选择性降解剂AK-1690。近期报道的新型STAT3降解剂SD-436在结构上改变了STAT3 warhead的连接位点,将其转移至pro-(R)苯基。临床阶段STAT3降解剂KT-333(NCT05225584)采用与SD-436相同的连接位点,但与SD-36和SD-436不同,KT-333通过招募CRL2
复合物而非CRL4
实现STAT3降解。
c-Myc是一种在结构上高度无序的转录因子,在多种生物学过程中发挥关键作用,并在多种癌症中过度表达,因此成为重要的抗癌靶点。然而,小分子直接抑制c-Myc一直十分困难,使其长期被认为是难成药靶点。TPD策略的出现为c-Myc干预提供了新的可能。例如A80.2HCl能够同时结合GSPT1和c-Myc,并招募CRBN实现降解,在纳摩尔浓度即可诱导c-Myc降解,同时恢复pRB1蛋白水平并重新建立CDKi耐药细胞系的敏感性。三萜内酯衍生物WBC100则通过E3连接酶CHIP介导c-Myc降解。三萜内酯来源于雷公藤(Tripterygium wilfordii)根部提取的二萜三环氧化合物,具有免疫抑制、抗炎、抗增殖和抗肿瘤等作用,同时也是NF-κB活化的抑制剂。因此WBC100可能通过多种机制发挥抗肿瘤作用。目前WBC100正在中国开展急性髓系白血病治疗的I期临床试验(CTR20243277)。
雄激素受体(androgen receptor,AR)是经过验证的抗肿瘤靶点,目前临床上已使用多种靶向AR配体结合结构域(LBD)的抑制剂。基于AR-LBD结合配体开发的AR PROTAC ARV-766目前正在临床试验阶段(NCT05067140)。然而缺失LBD的构成型活化AR变体会导致对新一代激素疗法(NHA)以及相关PROTAC(如恩杂鲁胺)的耐药。AR的N端结构域(NTD)属于内在无序结构区域,难以被小分子靶向。天然产物EPI-001的发现改变了这一状况,该分子能够与AR-NTD共价结合,从而抑制AR的转录活性并产生抗肿瘤作用。在此基础上进一步开发了针对无序区域配体的PROTAC,例如基于EPI-002设计的BWA-522。该分子采用刚性连接臂并具有良好的口服生物利用度,在实验模型中表现出微摩尔水平的抗增殖活性,为基于IDP配体的PROTAC设计提供了重要起点。
Bcl-2蛋白家族在肿瘤生长和转移过程中发挥重要作用。通过抑制或降解抗凋亡蛋白如Bcl-2、Mcl-1和Bcl-xL,为肿瘤治疗提供了新的策略。然而这些靶点涉及蛋白质−蛋白质相互作用,其界面面积较大,使小分子抑制剂设计面临挑战。Zhou团队开发了首个选择性Bcl-xL降解剂DT2216,该分子基于VHL配体和双重Bcl-2/Bcl-xL抑制剂ABT-263设计。在细胞实验中,DT2216对Bcl-xL的降解
为63 nM,同时对Bcl-2及其他Bcl家族蛋白几乎没有降解作用。在体内实验中,DT2216能够有效抑制多种异种移植肿瘤的生长,同时不会引起明显的血小板毒性。此外还开发了Bcl-xL/Bcl-2双重降解剂753b,该分子对癌细胞具有较高选择性且对正常血小板毒性较低,是具有潜力的抗癌候选药物。
CRBN E3泛素连接酶调节剂(CELMoDs)的一个重要特点是能够降解多种新底物,尤其是含有β发夹环(G-loop)的C2H2锌指转录因子。Lenalidomide通过CRL4
复合物诱导多发性骨髓瘤细胞中关键淋巴转录因子IKZF1和IKZF3的降解,从而发挥抗癌作用。进一步的蛋白质组学研究表明,沙利度胺类似物还可介导CRL4
依赖的更多C2H2锌指蛋白降解,包括ZNF692、ZFP91、ZNF276、ZNF653、ZNF827、SALL4以及WIZ。结构研究表明,CELMoDs与沙利度胺结合结构域结合后,可诱导CRBN从开放构象转变为闭合构象,而新底物IKZF蛋白仅能稳定结合于该闭合构象,从而体现出别构调控在CELMoD活性中的关键作用。不同CELMoD化合物在降解底物上的偏好存在差异,说明通过微小结构调整即可实现特定底物的选择性降解。
代表性的CELMoD化合物如CC-122和CC92480均以IKZF1和IKZF3为靶点,目前正处于癌症治疗的临床试验阶段(表5)。IKZF1与IKZF2的G-loop仅在一个氨基酸残基上存在差异:IKZF1为Q146,而IKZF2为H141。泊马度胺能够有效降解IKZF1,但不能诱导IKZF2降解,不过仍能促进CRBN与IKZF2的接近。以泊马度胺为起点进一步优化后开发出选择性IKZF2降解剂NVP-DKY709,该分子不影响IKZF1/3,可在体内诱导IKZF2降解并降低Treg抑制功能,目前正在实体瘤的I期临床试验中。
此外,Lenalidomide还能诱导WIZ转录因子的降解。基于这一发现开发的优化降解剂dWIZ-1能够在红系祖细胞中有效诱导胎儿血红蛋白(HbF)表达,为镰状细胞贫血提供潜在的治疗策略。与此同时,通过组合化学构建的CELMoD化合物库进一步扩展了CRBN配体的化学多样性,并扩大了CRBN可降解蛋白质组的范围。
图17|靶向降解剂de novo设计的概念框架。5.3 计算蛋白降解剂设计
随着靶向蛋白降解领域的持续发展,计算方法已成为加速 PROTAC(蛋白水解靶向嵌合体)及分子胶设计的核心环节。借助物理驱动与数据驱动方法,研究者能够高效探索更广阔的化学空间,筛选出具有潜力的降解剂候选分子,并在实验验证前预测三元复合物的稳定性。下文将围绕数据库构建、连接子设计及相互作用建模三方面,阐述计算技术在其中的作用,及其推动下一代蛋白降解剂设计的潜力与贡献(见图17)。5.3.1 蛋白降解剂数据库
数据库在发展数据驱动的新型降解剂设计中发挥着关键作用。目前,专门针对 PROTAC 的结构化数据库主要有三个:成熟的 PROTAC-DB 与 PROTACpedia,以及近年建立的 PROTAC-Databank。尽管这些资源在收集和组织 PROTAC 相关数据方面发挥了重要作用,但与通用蛋白质数据库相比,整体规模仍然有限,这对希望充分挖掘 PROTAC 潜力的研究者构成了挑战,尤其在结构与机器学习(ML)应用所需的层面。
PROTAC-DB 是一个持续维护的数据库,整合来自文献的数据并辅以计算特征。在其最新版本(3.0)中,收录了 6111 个 PROTAC 分子、569 种弹头(warhead)、107 种 E3 配体以及 2753 个连接子,并提供详细的生物活性数据,如 DC50、细胞活性,以及渗透性等药代动力学参数。PROTACpedia 则是一个协作型数据库,注册用户可提交结构并访问完整数据集。两者虽有部分条目重叠,但所提供的实验信息可能存在差异,且其数据集规模小于 PROTAC-DB。相比之下,PROTAC-Databank 目前记录的 PROTAC 分子数量较少(3645 个),但其独特之处在于收录了 4142 组靶标-弹头与 E3 连接酶-E3 配体的复合物结构。这种结构导向使 PROTAC-Databank 在计算建模与深度学习应用中尤为宝贵。此外,该数据库基于 DC50 与最大降解速率(Dmax)等指标,为 PROTAC-靶标-E3 连接酶配对引入了降解效率标签,为评估降解性能提供了统一框架。这一标注体系便于其与机器学习流程集成,例如更新的 DeepPROTACs 2.0 模型便利用基于图的架构来预测 PROTAC 降解效率。通过以适配计算工具的格式提供详细结构与生物数据,PROTAC-Databank 有望推动 PROTAC 分子的设计与机制解析。
与 PROTAC 不同,分子胶目前尚缺乏专门的结构化数据库。已报道的分子胶数量相对较少,且作用机制多样,这阻碍了此类资源的建立。部分分子胶诱导的蛋白-蛋白相互作用(MGPPIs)可在通用蛋白-蛋白对接数据集中找到,如 Docking Benchmark 5.5(DB5.5)。这些资源虽可作为评估对接算法的基准,但在为 MGPPIs 建模或训练专用于分子胶的深度学习模型时,仍缺乏所需的特定性与细节。此外,分子胶功效缺乏标准化标签或指标,也限制了这些数据在理性设计中的应用。PROTAC 与分子胶在数据库建设上的差距,凸显了新兴治疗方式在数据可得性方面的普遍挑战。对 PROTAC 而言,将结构、生物与降解数据整合到如 PROTAC-Databank 这样的统一库中,是向前迈出的重要一步,为开发复杂的机器学习驱动设计工具奠定了基础。对分子胶来说,缺乏类似资源则表明,需要系统生成与组织数据,以支持计算与实验发现。随着这些数据库在规模与多样性上不断扩展,它们不仅将提升预测与优化蛋白降解剂特性的能力,还将通过以数据为中心的方法,改变蛋白降解剂设计的整体格局。5.3.2 PROTAC 连接子设计
PROTAC 连接子的设计面临显著挑战,使其有别于传统小分子药物。不同于常规分子,PROTAC 连接子必须具备可调的柔性、多样的构象可能性以及独特的理化性质,才能发挥功能。即便已知一对合适的配体,要构建出有效的连接子并形成功能性 PROTAC 分子依然困难重重:其一,所设计的连接子需呈现特殊性质,而现有相关数据极为稀少;其二,连接子必须能与配体复杂的三维构象相匹配。
Gharbi 等人总结指出,早期用于 PROTAC 连接子设计的模型包括传统的片段连接方法,如 DeLinker 和 Link-INVENT。这些方法依赖成熟的基于图的算法与生成框架来连接分子片段。然而,PROTAC 连接子因长度更长、配体间初始距离大于典型药物发现中的连接子,带来了独特挑战。即使在这些模型经 PROTAC 专属数据集重新训练后,其表现仍显不足,这凸显了 PROTAC 与常规小分子在设计策略上的根本差异,也表明需要开发专为 PROTAC 连接子定制的模型。
为缓解限制 PROTAC 机器学习模型训练的数据稀缺问题,PROTAC-RL 模型提出新方案:先在一个称为类 PROTAC(quasi-PROTACs)的大型结构数据集上预训练,再在实际 PROTAC 数据上微调。该模型结合增强型 Transformer 架构与强化学习,生成在溶解性、稳定性与生物利用度等关键药代动力学性质上均优化的连接子结构,并已在小鼠实验中得到验证。
下一个挑战是使生成的结构与复杂三维构象对齐。AIMLinker 为此采用门控图神经网络(GGNN),按原子逐步生成连接子,并将输入片段的空间结构信息纳入其中。通过在训练中引入三维特征,AIMLinker 能设计出更符合三元复合物构象需求的连接子。对接与分子动力学模拟验证显示,生成的 PROTAC 具有高结合亲和力与结构完整性。此外,AIMLinker 强大的后处理能力与快速生成速度,提高了构建多样化 PROTAC 候选库的效率。
另一创新模型 PROTAC-INVENT 在 REINVENT 框架基础上,将三维结合位点数据纳入工作流程。与此前主要生成二维结构的模型不同,它整合来自蛋白三元结构(PTS)的三维结合位点数据,以优化生成 PROTAC 在靶标结合口袋中的契合度。其流程分为两步:首先用生成模型产生连接子的 SMILES 字符串,再预测完整 PROTAC 分子的三维结合构象。此优化过程确保与靶标结合位点的更好匹配。
最近,扩散模型的兴起促使其在连接子结构预测中的应用。DiffPROTACs 利用 O(3)-等变图变换器模块,将图神经网络处理空间数据的优势与变换器提取特征的能力相结合,生成 PROTAC 连接子。通过在自建 PROTAC 数据集上微调,该模型实现了 93.86% 的有效率,并为后续研究提供了生成 PROTAC 的综合数据库,缓解了数据稀缺问题,且能生成与 PROTAC 配体构象需求高度契合的连接子。
迄今为止,现有方法仍难以全面兼顾连接子性质、三元复合物稳定性与药代动力学优化之间的相互作用。此外,计算方法常依赖多样性与规模仍有限的数据集,制约了泛化能力。将连接子设计与配体优化相融合,实现两者的协同增强,仍是 PROTAC 从头设计未来一个雄心勃勃但前景可期的发展方向。5.3.3 分子胶诱导蛋白质−蛋白质相互作用的建模
分子胶诱导的蛋白质−蛋白质相互作用建模仍然是药物发现中一个新兴且复杂的研究方向。与PROTAC三元复合物形成机制已较为清晰不同,目前对分子胶作用机制的理解仍然有限。这种认识不足使得理性设计和数据驱动的开发受到限制,因为分子胶稳定的蛋白质相互作用通常是瞬时的、较弱的并且具有明显的环境依赖性。尽管如此,随着分子对接、分子动力学模拟以及深度学习技术的发展,计算方法已经开始为研究这些相互作用提供重要工具。
蛋白质−蛋白质对接是模拟分子胶诱导PPI的基础方法之一。该方法通过分析蛋白质结构特征,生成候选结合构象(即decoys),以预测两种蛋白之间的相互作用方式。常用工具如HADDOCK和RosettaDock已经被应用于该领域,并能够在对接过程中引入分子胶作为第三方稳定因子。这些工具通过评估在分子胶存在条件下蛋白质表面的互补性,帮助理解弱或瞬时相互作用如何被稳定。然而,仅依赖对接方法难以完全捕捉复合物的动态特征,因为该方法通常基于相对静态的蛋白质结构。
为了进一步优化预测的复合物并分析其稳定性,研究中常在对接之后进行分子动力学(MD)模拟。MD能够反映蛋白质柔性及构象变化,揭示分子胶如何重新组织相互作用界面、识别关键结合热点并评估在生理条件下相互作用的稳定性。此外,自由能计算方法,如自由能微扰(FEP),可以量化分子胶对蛋白质−蛋白质结合热力学性质的影响。尽管这些方法计算成本较高,但能够提供高分辨率的能量学信息,从而帮助筛选优先进行实验验证的候选分子。
深度学习技术的发展也显著提升了分子胶诱导PPI建模能力。早期模型如MaSIF和dMaSIF通过识别蛋白质界面的几何与生化特征,为该领域奠定了基础,而AlphaFold3则通过在统一框架中整合序列、结构和相互作用信息实现了重要突破。AlphaFold3采用基于扩散模型的神经网络架构,可预测复杂生物分子的结构,包括分子胶所涉及的弱或瞬时相互作用。该模型在多种生物分子相互作用预测中表现出前所未有的准确度,即使在存在显著构象变化的情况下也能提供可靠结果。
AlphaFold3能够预测分子胶介导相互作用的重要原因在于其新的训练策略与模型架构。与早期模型不同,AlphaFold3引入pairformer模块用于高效处理分子之间的成对关系,并通过扩散模块描述生物分子的多尺度空间构型。这种结构使模型能够捕捉分子胶诱导的动态结构重排,并揭示目标蛋白与E3泛素连接酶之间的复杂相互作用。实验评估表明,AlphaFold3在界面预测方面的准确度高于传统基于物理模型的方法以及早期机器学习模型。不过仍然存在一些挑战。例如已有数据集主要集中于高亲和力相互作用,这限制了模型对分子胶常见的弱和瞬时PPI的泛化能力。因此,需要构建更符合分子胶特性的专用数据集,以充分发挥AlphaFold3在理性药物设计中的潜力。5.3.4 降解剂的De Novo设计:潜力与挑战
降解剂(包括PROTAC和分子胶)的de novo设计代表了药物发现中的一种重要发展方向。通过结合计算化学与机器学习方法,可以从传统的试错式合成逐渐转向理性、数据驱动的设计策略,从而优化降解剂的药理特性。然而,要真正实现这一目标仍需解决一系列关键问题。
由于PROTAC相关数据相对丰富,目前已有多种工具可用于其设计。例如DeepPROTACs 2.0虽然并非完全意义上的de novo设计工具,但作为一种高效的降解效率预测模型,能够显著提高降解剂开发效率。该模型能够捕捉蛋白质口袋中的精细相互作用以及分子之间的非共价相互作用。在包含4140个已标注PROTAC的数据集中,其更新后的模型结构达到83.45%的预测准确率和0.9001的AUROC,相比原始模型分别提高约8%和9%。
在新分子生成方面,Nori等人基于GraphINVENT构建了一个从头设计降解剂的生成框架,可同时优化PROTAC的所有分子组成部分。与传统只针对PROTAC某一结构部分进行优化的模型不同,该方法利用强化学习(reinforcement learning,RL)根据预测的降解活性对生成分子进行优化。在以IRAK3为靶点的案例研究中,生成分子的预测活性从50.8%提升至83.8%,显示出较好的设计能力。
近期,Mslati等人开发了用于PROTAC de novo设计的综合计算流程PROTACable。该流程整合了分子对接、机器学习方法(包括SE(3)等变图变换网络)以及实验PROTAC数据库,可生成并评估结构精度较高的三元复合物模型。PROTACable在已解析晶体结构的三元复合物基准测试中表现出优于现有方法的性能。在针对G9A的案例研究中,该系统设计出多种新型VHL型PROTAC,展示了其在药物耐受和难成药靶点研究中的应用潜力。
针对分子胶的de novo设计,Geoffrey等人开发了Molecular Glue-Design-Evaluator(MOLDE)平台。该平台整合蛋白质−蛋白质对接、MD模拟、自由能计算(如MMPBSA和FEP)以及量子力学/分子力学(QM/MM)方法,用于预测和优化分子胶诱导的三元复合物结构。通过对已报道的分子胶体系(例如Protein Data Bank中的相关结构)进行回顾性分析验证,MOLDE能够准确再现结合构象、热力学稳定性以及三元复合物的形成过程。更重要的是,该平台还成功设计出针对DDB1-CDK12体系的新型分子胶,展示出一定的分子生成能力。
尽管这些研究取得了重要进展,但仍然存在多方面挑战。首先是数据数量不足以及数据质量问题,这限制了模型训练和验证的效果。例如PROTAC-DB等现有数据库往往缺乏完整注释,尤其是在三元复合物结构和降解活性指标方面。其次,降解剂功能本身涉及多个相互关联的优化目标,使得建模过程更加复杂。此外,计算预测结果与实验验证之间仍存在一定差距。de novo设计往往产生理论结构,但这些结构可能难以合成或难以在实验条件下实现。与此同时,当前模型多基于静态结构表示,难以充分考虑降解过程中关键的动态构象变化。
未来研究需要进一步扩展数据集规模并提高数据质量,同时引入真实时间尺度的动力学信息以提高模型准确度。多目标优化算法的发展、实验反馈的持续整合以及三维结构感知建模与迁移学习方法的应用,将有助于探索新的降解剂化学空间,从而推动难成药靶点治疗策略的发展。6 结论与展望
“不可成药”靶点通常具有独特特征,例如缺乏配体结合口袋、高度保守的活性位点、功能由蛋白质-蛋白质相互作用(PPI)介导,以及缺乏稳定或明确的三维结构。药物发现与开发技术的进步,以及基于物理和人工智能的计算方法,催生了应对这些高难度靶点的创新策略。针对固有无序蛋白(IDP)与 PPI 的干预方法、变构药物发现以及靶向蛋白降解等领域已显现出重大潜力。这些进展促成了多个先导化合物的诞生,部分甚至已获临床批准。因此,“不可成药”的概念正逐渐转变为“难以成药”或“尚未成药”,反映出应对这些一度棘手的靶点的能力正在不断增强。
该综述重点介绍了针对不可成药蛋白的小分子药物发现策略,特别强调了计算方法在其中发挥的重要作用,并总结了已开发的成功及潜在治疗实体。尽管创新药物发现技术与新型治疗实体的出现带来了令人振奋的可能性,但知识空白依然显著,持续研究以克服这些挑战十分必要。
IDP 在人类蛋白质组中广泛存在,且在多种疾病的发病机制中扮演关键角色。将 IDP 转化为可成药靶点,将大幅拓展可成药靶标空间。虽然针对 IDP 的药物设计方法已经问世,但仍面临重大挑战与局限。成药 IDP 的主要障碍在于缺乏优化 IDP 配体的高效方法,这需要具备更高时空分辨率的实验技术,以及能有效分析 IDP-配体动态结合模式的新颖计算手段。以下方向有望加快 IDP 药物发现:(1)AI 辅助药物设计。鉴于 IDP 配体具有“多构象亲和性”特征,多靶点药物设计 AI 模型在生成新型 IDP 配体方面潜力巨大。(2)配体特异性预测与验证。IDP 配体结合模式复杂,且受 IDP 靶标调控的互作网络广泛,其特异性与调控精确性备受关注。实验上建议采用如 MS-CETSA 等蛋白质组学技术评估脱靶效应;计算上,基于 AI 的多组学模型有望预测 IDP 配体对细胞内分子网络的影响,但仍需深入探索。(3)凝聚体调节疗法(C-mods)。靶向无膜细胞器或生物分子凝聚体,是应对不可成药蛋白的有力策略。许多 IDP(包括关键转录因子)通过凝聚体形成推动疾病进展。已有报道指出,小分子配体可通过诱导形成、促进溶解、改变定位或调节理化性质等方式调控疾病相关凝聚体。通过作用于功能过程而非直接结合或降解蛋白,C-mods 有望提供更有效且更具选择性的治疗方案,并减少副作用。
变构药物发现在攻克不可成药靶点方面已取得显著成功。变构位点预测与变构药物设计的进步促成了大量变构调节剂的发现,其中部分已上市。然而,仍需应对若干挑战以进一步加速该领域发展。例如,(1)变构调控机制有待深入探索。一旦发现变构位点,预测结合化合物的调控强度上限及其作为激活剂、抑制剂或中性占位者的作用属性仍具难度。变构理论、计算方法、扩展的实验数据集以及 AI 驱动模型的进展或可提供帮助。(2)亟需开发高效的隐藏变构位点发现方法。隐藏变构位点常通过高通量筛选或长期分子动力学模拟偶然发现,耗时较长。现有计算方法大多仅能预测单体蛋白中的隐藏位点,且在非结合态结构中的预测准确性偏低。迫切需要更快、更准确且更全面的隐藏变构位点预测方法。此外,探究隐藏变构位点形成的进化机制亦值得深入研究。
随着新药物靶点的不断涌现与结构研究的进展,潜在治疗靶标空间持续扩大,甚至延伸至非蛋白类靶点。据估计,人类基因组约 75% 可转录为 RNA,而仅有 1.5% 编码蛋白质。RNA 靶向,尤其是小分子干预 RNA,是药物发现中相对新颖且快速发展的领域。潜在 RNA 靶点包括编码被归为不可成药的疾病相关蛋白的 mRNA,以及影响疾病进程的非编码 RNA。尽管功能重要,RNA 作为药物靶点的潜力仍未充分发掘。这主要源于其固有挑战:内在柔性、强负电荷以及缺乏明确的疏水口袋。RNA 与小分子的相互作用主要由非共价力主导,如堆叠作用和氢键。芳香族小分子可嵌入碱基对之间增强 π 相互作用,而 RNA 带负电的糖-磷酸骨架有利于与带正电配体的静电作用。因此,现有化合物库筛选常得到性质相似、非特异性结合且具有毒性的分子。应对之道在于开发针对 RNA 靶点的专用化合物库与定制筛选方法。技术进步已催生特定策略,如核糖核酸酶靶向嵌合体(RIBOTAC),可招募 RNase-L 促进 RNA 的靶向降解。高通量筛选常获得因与非功能区结合而生物学惰性的 RNA 结合化合物,幸运的是,RIBOTAC 等方法可将此类配体转化为有效工具。
从可成药化学空间的角度看,开发用于高通量筛选的专用化合物库与应用 AI 辅助从头药物设计至关重要。如前所述,RNA 靶向筛选的一大挑战是频繁识别化学骨架相似的基团,导致特异性低。由于多数小分子库面向蛋白靶点设计,亟需构建 RNA 偏好配体库。此外,PPI 调节剂与 PROTAC 往往不符合 Lipinski 五规则等传统指导原则。现有商业化合物库多为传统靶点设计,未能覆盖不可成药靶点的配体化学空间。因此,必须通过新技术拓展化学空间至未探索领域。一方面,自动化实验技术的迅速普及促进了高通量合成构建化合物库的方法。然而,在打造化学多样性丰富的类药分子库,尤其是面向特定靶点的聚焦库并与机器学习结合实现快速活性筛选方面,仍存在重大挑战。另一方面,基于 AI 的深度生成模型为从头药物设计带来新机遇。依赖已知活性化合物预测新分子活性的深度生成模型局限于狭窄的化学空间,而以靶标结构为导向的从头生成模型则可探索更广的化学空间。为确保生成分子可被实验测试,扩展的化学空间必须保持合成可及性。这要求进一步整合分子生成与合成路线规划,以及反应产率与条件的预测建模。
尽管该综述聚焦于针对不可成药靶点的小分子药物设计,AI 辅助蛋白质结合剂设计这一新兴领域值得更多关注。随着 RFdiffusion、Chroma、SCUBA-D 等新蛋白质支架生成工具,以及 ProteinMPNN、ABACUS-R、ProDesignLE、GeoSeqBuilder 等序列生成方法的出现,能够结合 PPI、IDP 乃至 RNA 的蛋白质可被从头设计。已有报道指出具备治疗潜力的蛋白质结合剂,其中部分甚至可口服给药。同时,肽类尤其是环肽也为不可成药靶点提供了新机遇。尽管蛋白质结合剂易于作用于细胞因子、膜锚定受体等分泌蛋白,其细胞内递送仍需深入研究。还应注意到,通过表型筛选与 AI 建模绕过靶点特异性难题的可能性。例如,化学扰动基因表达谱与单细胞 RNA 测序数据已被用于在不明确细胞靶标的情况下预测新化合物的效应。深度学习模型仅凭蛋白质序列与配体化学结构即可预测蛋白-配体相互作用,无需显式的蛋白质结构数据。实验筛选与主动学习框架的结合已促成新型抗生素及抗衰老化合物的发现。
随着对疾病机制理解的加深,潜在药物靶标空间预计将进一步拓展。为应对新药靶点与既有难点靶标的成药挑战,持续开发创新型计算机辅助药物设计方法,并与新兴药物发现及开发技术并行推进,至关重要。凭借这些进展,大多数不可成药靶点终将有望进入可治疗干预的范畴。
往期精彩:
Chemical Reviews 2025 | 难以成药靶标的计算机辅助药物发现(上)
Annu. Rev. Pharmacol. Toxicol. 2014 | 受体别构位点的药物
Nature 2025 | 光学生成模型
2025-12-21
·药界探微
21 世纪以来,制药研发领域面临着生产力持续下滑的挑战,这一现象被多项分析所证实,而导致这一趋势的关键因素之一,在于临床前研究阶段的目标选择、靶点类型及药物候选物发现策略等决策环节。随着药物研发的深入,靶点类型逐渐发生结构性转变,传统的激酶、G 蛋白偶联受体(GPCR)等易成药靶点仍是研究重点,但蛋白质 - 蛋白质相互作用(PPIs)、表观遗传蛋白、转录因子等更具挑战性的靶点占比不断提升,这就对苗头化合物的发现方法和药物化学优化策略提出了全新要求。此前,关于药物化学优化的分析多集中在 2000-2012 年,针对近十年小分子口服药物研发趋势的系统性研究相对匮乏,尤其是缺乏对苗头化合物、先导化合物与药物候选物全链条优化过程的跨时期对比,也未充分结合企业内部研发数据进行验证,因此亟需通过全面的数据分析揭示近年来药物化学优化的真实格局变化。
为解答这一科学问题,研究团队开展了跨时期、多维度的对比分析,核心聚焦于近年来小分子口服药物的苗头化合物发现策略、优化路径及分子性质演变,同时探讨传统药物设计规则的适用性与新药物模态的发展趋势。研究选取了两个关键时间段:2000-2010 年(基准期)和 2015-2022 年(当前期),通过手动筛选《药物化学杂志》等文献,分别构建了包含 91 组和 247 组 “苗头 - 先导 - 候选药物” 三元组的数据集,同时纳入阿斯利康(81 组)和诺华(超过 25 组)的内部研发数据进行补充验证。分析维度涵盖治疗领域分布、靶点类型变化、苗头化合物发现策略、物理化学性质演变、药物设计规则符合性等,还针对 PROTACs、大环化合物、分子胶、PPI 调节剂等新模态药物进行了专项分析,全面勾勒药物化学优化的变化图景。
从治疗领域来看,肿瘤适应症的主导地位愈发凸显,2015-2022 年药物候选物中肿瘤领域占比达 38%,较基准期的 17% 大幅提升,成为当前药物研发的核心方向;中枢神经系统(CNS)适应症占比保持稳定(约 19%),尽管大型药企曾一度缩减该领域投入,但小型生物技术公司的持续探索及后续的收购整合,让 CNS 药物研发重新受到关注。与之相反,心血管疾病和感染性疾病的占比分别从 12%、15% 降至 6%、8%,反映出大型药企在这些领域的投资收缩。靶点类型方面,激酶和 GPCR 仍是主流,合计占当前候选药物的 45%,但两者占比发生反转 —— 激酶从 13% 升至 30%,GPCR 从 32% 降至 15%,同时表观遗传蛋白等非常规靶点占比有所增加。苗头化合物发现策略上,高通量筛选(HTS)与已知化合物仍是核心手段,合计占比超 75%,但 HTS 占比从 40% 降至 33%,已知化合物占比从 41% 微升至 43%,而片段筛选、DNA 编码库(DEL)筛选等补充策略的占比从 1% 升至 8%,基于结构的药物设计(SBDD)也从 4% 提升至 7%,这些变化与挑战性靶点的 HTS 命中率较低密切相关,已知化合物因优化路径更可预测、合成效率更高,成为许多项目的首选起点。
药物化学优化的核心是多参数协同提升,其作用机制体现在不同研发阶段的分子性质精准调控上。从苗头化合物到先导化合物,再到药物候选物,分子结构的优化遵循明确的逻辑:苗头到先导阶段,重点提升亲和力,配体效率(LE)显著提高,这一阶段会适度增加分子大小(分子量、重原子数)和氢键受体(HBA)数量,同时控制氢键供体(HBD)数量以避免溶解性和 ADMET 问题;先导到候选药物阶段,核心目标是优化成药性,亲脂配体效率(LLE)持续提升,亲脂性(logP)显著降低 —— 当前期先导化合物和候选药物的 logP 值较基准期明显下降,这是因为过去二十年的研究证实过度亲脂性与低临床成功率直接相关,因此在化合物筛选、库设计和优化过程中,亲脂性控制成为关键考量。值得注意的是,苗头化合物的物理化学性质(如分子量、sp³ 碳比例、HBD 数量)在两个时期变化不大,而先导化合物和候选药物的极性相关性质(HBA、拓扑极性表面积 TPSA)变化显著,体现了优化策略的聚焦点转移。
在药物设计规则的适用性方面,传统的 “先导化合物类药性” 标准(亲和力 > 0.1μM、分子量 < 350Da、logP<3)已不再完全适用,当前仅有约 40% 的先导化合物符合该标准,取而代之的是高亲和力先导化合物(亲和力 < 0.1μM、分子量 > 350Da、logP<3)占比从 10% 升至 34%,这一变化源于现代研发对体内靶点结合、药效学验证的早期需求,要求先导化合物具备更高的活性和更优的理化性质。而 Lipinski 的五规则(Ro5)仍保持较强的适用性,当前约 70% 的候选药物符合全部四项标准(分子量 < 500Da、logP<5、HBA<10、HBD<5),即使是扩展规则(eRo5)和超越规则(bRo5)的化合物,也多集中在特定模态,并未动摇 Ro5 在传统小分子药物研发中的核心地位。
新药物模态的崛起为攻克难成药靶点提供了全新路径,这些模态在作用机制、理化性质上与传统小分子存在显著差异。PROTACs(蛋白降解靶向嵌合体)通过连接靶蛋白配体和 E3 泛素连接酶配体,诱导靶蛋白泛素化降解,其分子量通常在 800Da 左右(甚至更高),TPSA 达 150-180Ų,含有较多 sp³ 碳和可旋转键,优化重点在于缩短连接子长度、降低柔性以提升口服生物利用度,例如口服 IRAK4 降解剂 KT-474 已进入临床,为自身免疫性疾病治疗提供了新方向。大环化合物则通过含至少十个原子的大环结构形成预组织构象,能够结合平坦或浅表面结合位点,其理化性质介于 PROTACs 和传统小分子之间,凭借 “分子变色龙” 特性平衡溶解性和细胞膜通透性。分子胶的作用机制与传统小分子类似,理化性质也高度相近,而 PPI 调节剂则因靶向极性较弱的蛋白质表面,亲脂性显著高于其他模态。这些新模态中,80% 以上针对肿瘤适应症,靶点多归类为 “其他” 类别,苗头化合物发现高度依赖已知化合物和 SBDD,突破了传统小分子的性质限制,但最终在亲脂性、溶解性等关键成药性参数上仍向主流标准收敛。
多个典型案例印证了这些趋势的实践意义:在共价抑制剂领域,BTK 抑制剂伊布替尼、EGFR 抑制剂阿法替尼和奥希替尼的成功,证实了共价作用机制在肿瘤治疗中的有效性,推动了难成药激酶突变体的药物研发;KRAS G12C 靶点曾被认为不可成药,但首个共价抑制剂的披露引发了行业广泛跟进,目前已有多个候选药物进入临床,体现了已知化合物作为起点的快速转化价值;RNA 靶向药物利司扑兰的上市,证明了针对 RNA 靶点的小分子药物研发可行性,为这类新型靶点开辟了道路。企业层面,阿斯利康聚焦肿瘤领域,激酶靶点占比提升,同时大幅降低候选药物的亲脂性;诺华则走多元化路线,治疗领域分布更均衡,HTS 仍是主要的苗头发现策略,这些差异反映了企业战略对研发格局的深刻影响。
展望未来,激酶靶点在肿瘤领域的重要地位仍将持续,共价抑制、靶向降解等新作用机制将进一步拓展其治疗潜力。随着组学技术、人工智能(AI)与药物研发的深度融合,难成药靶点的验证效率将显著提升,AI 辅助的超大库虚拟筛选、逆合成分析、生成式分子设计等工具,将缩短研发周期、降低合成成本。片段筛选、DEL 筛选等策略的占比有望进一步提升,尤其是在中小型生物技术公司中,而大型药企则会继续发挥 HTS 库和筛选平台的积累优势。新药物模态的优化将更加聚焦成药性,同时 AI 技术的长期影响仍需时间检验,但可以确定的是,药物化学优化已从单一参数优化转向多维度协同、模态创新与规则兼容的综合策略,这些变化将持续推动临床前研发生产力的提升,为更多疾病提供有效的治疗方案。
看了这么久,累了吧,玩个游戏放松下吧?
原文链接:
https://doi.org/10.1038/s41573-025-01225-1
蛋白降解靶向嵌合体并购
2025-12-17
化学信息学杂志
文章Alphappimi:一个用于预测PPI调节剂相互作用的综合深度学习框架研究开放获取发布日期:2025年8月29日文章
抽象的
蛋白质-蛋白质相互作用(PPI)通过复杂的界面调控重要的生物过程,其功能障碍与多种疾病相关。因此,识别PPI及其界面靶向调节剂已成为一种关键的治疗策略。然而,发现靶向PPI及其界面的调节剂仍然面临挑战,因为传统的基于结构相似性的方法无法有效表征PPI靶点,尤其是那些目前尚无活性化合物的靶点。本文提出了AlphaPPIMI,一个综合性的深度学习框架,它结合了大规模预训练语言模型和领域自适应技术,用于预测PPI-调节剂相互作用,特别是针对PPI界面的相互作用。为了实现稳健的模型开发和评估,我们构建了全面的PPI-调节剂相互作用基准数据集(PPIMI)。我们的框架整合了来自Uni-Mol2的综合分子特征、源自最先进语言模型(ESM2和ProTrans)的蛋白质表征以及由PFeature编码的PPI结构特征。 AlphaPPIMI 通过专门设计的跨注意力架构和条件域对抗网络 (CDAN),能够有效地学习 PPI 靶标和调节因子之间的潜在关联,同时确保稳健的跨域泛化能力。大量的评估表明,AlphaPPIMI 在 PPIMI 预测方面始终优于现有方法,为优先筛选候选 PPI 调节因子(尤其是靶向蛋白质-蛋白质相互作用界面的调节因子)提供了一种很有前景的方法。科学贡献
本文提出了一种名为 AlphaPPIMI 的新型深度学习框架,用于精确预测靶向蛋白质-蛋白质相互作用 (PPI) 及其界面的调节剂。其核心贡献包括:一个专门的交叉注意力模块,用于协同融合多模态预训练表征;以及创新性地应用条件域对抗网络 (CDAN),显著提升了模型在不同蛋白质家族间的泛化能力。AlphaPPIMI 在精心设计的基准数据集上展现出卓越的性能,为靶向 PPI 疗法的发现提供了一种强大的计算工具。
其他人也在浏览类似内容基于进化尺度模型(ESM)特征的蛋白质-蛋白质接触预测深度学习章节 © 2024基于多模态深度表征的蛋白质相互作用识别和蛋白质家族分类文章 开放获取 2019年12月2日利用深度学习方法区分和预测蛋白质-蛋白质结合亲和力本章 © 2018
探索相关主题利用机器学习技术,发现相关主题的最新文章、书籍和新闻。生物化学网络计算智能智能增强预测标志物蛋白质功能预测蛋白质-配体相互作用请使用我们的提交前检查清单
避免在稿件中犯常见错误。
介绍
蛋白质-蛋白质相互作用(PPI)是所有生物过程的基石,它们协调信号转导、代谢调控、基因表达和细胞周期控制。作为复杂生物网络的组成部分,PPI在生理和病理条件下都发挥着关键作用,包括癌症、神经退行性疾病和传染病[ 1 , 2 , 3 , 4 ]。PPI调节剂的治疗潜力已通过成功靶向MDM2-p53和BCL2-BAX等相互作用得到显著证实,尤其是在解决先前被认为“不可成药”的靶点方面[ 5 ]。然而,准确预测PPI与调节剂之间的相互作用仍然是一个巨大的挑战[ 6 , 7 , 8 ]。与传统药物靶点不同,PPI靶点通常缺乏明确的结合口袋,其特征是扁平的疏水性相互作用界面[ 9 ]。此外,传统药物靶点和蛋白质-蛋白质相互作用(PPI)靶点的界面特性表现出不同的生化特征,进而影响PPI与其调节剂之间的相互作用模式[ 10 , 11 , 12 , 13 , 14 , 15 , 16 , 17 ]。由于缺乏已知的活性化合物和高分辨率界面结构数据,新型或研究不足的PPI在界面调节剂的发现方面面临着巨大的挑战。因此,开发能够有效识别和靶向PPI及其界面的深度学习模型对于推进靶向PPI调节剂的发现至关重要[ 18 , 19 , 20 ]。
由于蛋白质-蛋白质相互作用(PPI)界面面积大、平坦且疏水,传统的计算方法面临诸多挑战,这使得设计能够调节这些相互作用的小分子变得复杂。值得注意的是,突变研究的进展表明,这些界面内的特定“热点”驱动着分子间的相互作用。这些区域通常具有疏水性和构象灵活性,是小分子调节剂的理想靶点,并已成为计算药物设计的关键所在[ 21 , 22 , 23 , 24 ]。近年来,机器学习(ML)和深度学习(DL)的快速发展,通过利用大规模数据集和复杂的算法框架,显著提升了PPI调节剂的预测能力[ 25 , 26 , 27 , 28 , 29 , 30 , 31 , 32 ]。早期研究包括 2P2IHUNTER,这是一种新型的基于支持向量机的工具,专门用于筛选正构蛋白-蛋白相互作用调节剂,在识别真正的 PPI 抑制剂方面展现出很高的准确性 [ 33 ]。随后是 PPIMpred,这是一个网络服务器,能够对靶向蛋白-蛋白相互作用的小分子进行高通量虚拟筛选,为 PPI 调节剂的发现提供了一个便捷的平台 [ 34 ]。近期进展包括 PDCSM-PPI [ 35 ] 和 Sharma 等人提出的 SMMPPI,这是一种基于机器学习的方法,成功预测了蛋白-蛋白相互作用的调节剂,并展示了其在识别 SARS-CoV-2 中 RBD:hACE2 相互作用的新型抑制剂方面的实际应用 [ 36 ]。值得注意的是,Wang 等人引入了一种专门为 PPI 调节剂设计的界面感知分子生成框架,这代表了基于结构的药物设计领域的一项重大进展 [ 37 ]。这些计算范式彻底改变了 PPI 调节剂发现领域,提供了强大的框架,可以高精度、高效率地预测调节剂-PPI 相互作用。
尽管用于发现靶向蛋白质-蛋白质相互作用(PPI)调节剂的计算方法取得了显著进展,但仍存在一些关键挑战。传统的计算方法主要依赖于基于结构相似性的筛选,通过将候选化合物与已知调节剂进行比较来预测其活性。然而,这种方法无法充分捕捉PPI界面及其分子识别机制固有的复杂且多方面的特征。现有方法通常使用浅层的分子描述符(例如RDKit指纹)或简单的几何特征,缺乏有效整合来自不同来源的多种尺度特征的复杂策略。这种局限性严重阻碍了对精确界面识别至关重要的细微化学和生物相互作用进行准确建模。
一个更根本、更关键的限制是现有模型在不同蛋白质家族间的泛化能力较差。蛋白质-蛋白质相互作用(PPI)调节剂的数据集本身就具有碎片化特征,不同蛋白质结构域之间的化学空间和界面性质分布存在显著差异。因此,基于特定结构域训练的模型在应用于缺乏足够参考化合物的新型界面靶点时,性能往往会急剧下降。这种结构域适应性挑战极大地限制了目前有限的界面靶向调节剂库的扩展,并且仍然是实际药物研发应用中的一大障碍。
近年来,基于Transformer的预训练语言模型取得了显著进展,例如ESM[ 38 , 39 , 40 , 41 ]、Uni-Mol[ 42 ]和ProtTrans[ 43 ],展现出巨大的潜力,能够从蛋白质序列和分子结构中编码丰富的进化信息。这些模型无需大量的结构数据即可揭示界面区域的隐藏相互作用模式,从而有望解决传统方法的关键局限性。然而,仅仅应用这些预训练模型是不够的。目前的研究重点在于开发一个统一的计算框架,该框架能够通过专门的融合机制协同整合这些强大的多模态嵌入,并明确解决跨领域泛化问题。
为了应对这些挑战,我们构建了一个全面的蛋白质-蛋白质相互作用(PPI)-调节因子相互作用基准数据集,并开发了AlphaPPIMI——一个综合性的深度学习框架。该框架结合了大规模预训练语言模型和先进的领域自适应技术,用于预测靶向PPI界面结合位点的调节因子。我们的架构首次协同整合了多模态预训练表征、双向交叉注意力融合机制以及条件域对抗学习(CDAN)[ 44 ],用于界面特异性调节因子的预测。交叉注意力模块动态地对调节因子和PPI界面之间的相互影响进行建模,从而实现深度、上下文感知的相互作用建模。此外,AlphaPPIMI在该领域引入了CDAN的新应用,显著增强了模型在不同蛋白质家族和靶域间的泛化能力。基准测试验证表明,AlphaPPIMI性能优异,能够有效识别界面特异性调节因子,为靶向PPI疗法的发现提供了一种极具前景的工具。
结果与讨论AlphaPPIMI 的模型架构
我们提出了一种名为 AlphaPPIMI(图 1)的新型框架,用于预测蛋白质-蛋白质相互作用(PPI)调节剂的相互作用,特别是那些靶向界面结合位点的相互作用。该框架集成了多个先进组件,用于全面提取 PPI 特征并进行表征学习。具体而言,我们采用先进的 Uni-Mol2 模型,通过整合原子、键和几何信息以及分子指纹来构建分子表征。在蛋白质特征提取方面,我们结合了两种互补的方法:进化模式通过预训练于大型序列数据库的先进语言模型(ESM2-150M 和 ProTrans)进行捕获,而结构特征则使用 PFeature 方法进行编码。这种集成方法确保了对预测靶向界面调节剂至关重要的序列和结构信息的全面捕获。为了有效地对蛋白质和调节剂之间复杂的相互作用进行建模,我们设计了一个专门的交叉注意力模块,该模块能够动态学习相互作用模式,同时保留模态特异性信息。然后,将集成特征通过优化的全连接层进行处理,以进行最终的 PPIMI 预测。值得注意的是,我们引入了 CDAN [ 44 ] 来增强模型在不同蛋白质家族间的泛化能力,从而解决了界面靶向药物发现中的一个关键挑战。图 1
AlphaPPIMI架构概述。A .总体框架,展示了调节因子和蛋白质特征提取流程的集成。B .交叉注意力模块的详细结构,说明了调节因子和PPI特征之间的动态交互。C .条件域对抗网络(CDAN)模块完整尺寸图片AlphaPPIMI 与现有 PPIMI 预测器的性能比较分析
为了进行领域内评估,我们将 AlphaPPIMI(未嵌入 CDAN)与五种基线方法——SVM [ 45 ]、XGBoost [ 46 ]、MLP [ 47 ]、RF [ 48 ] 和 MultiPPIMI [ 49 ]——在随机划分和冷配对划分两种配置下进行了比较。如表 1所示,AlphaPPIMI 在随机划分中取得了近乎完美的分数(例如,AUROC 为 0.995)。如此高的分数部分归因于训练集和测试集之间存在实体级重叠,即某些蛋白质或调节因子可能同时出现在两个划分中。尽管两个集合中没有完全相同的 PPI-调节因子对,但重叠的单个蛋白质或调节因子的存在可能会使模型在训练过程中接触到熟悉的实体,从而导致实体级信息泄露,进而造成性能膨胀。因此,我们着重研究更具挑战性的冷配对配置,以评估模型的真实泛化能力。在该配置中,PPI-调节剂组合严格互不重叠,从而模拟药物发现中的真实场景。在此设置下,AlphaPPIMI 实现了稳健的泛化,AUROC 为 0.827,AUPRC 为 0.781,与基线方法相比,泛化能力有所提升。值得注意的是,SVM 和 MultiPPIMI 等模型表现出对预测阳性相互作用的强烈偏好。其特征是灵敏度高,但特异性极低且不稳定。这表明,虽然这些模型能够有效地识别阳性相互作用,但代价是极高的假阳性率,从而削弱了其实际应用的可靠性。为了确保结果的透明度,补充材料 S1 中提供了这些模型混淆矩阵的逐折分析。
与此形成鲜明对比的是,AlphaPPIMI展现出更为均衡稳定的性能。它在保持高灵敏度和特异性的同时,方差也较低,展现了其正确识别真阳性和真阴性的能力。AlphaPPIMI的卓越性能可归功于其精细的特征提取能力,它利用大规模预训练模型(例如,用于分子表征的Uni-Mol2以及用于蛋白质特征的ESM2、ProtTrans和PFeature)来全面表征界面靶向调节剂。虽然现有方法(例如MultiPPIMI)也利用了预训练模型,但它们主要依赖于浅层的分子表征(例如,RDKit描述符),无法捕捉PPI-调节剂结合所需的复杂特征。相比之下,我们的框架实现了一个专门设计的交叉注意力模块,该模块旨在动态捕捉调节剂和蛋白质界面特征之间的复杂相互作用,从而有助于更深入地理解稳健预测所需的细微相互作用。此外,AlphaPPIMI 还整合了 CDAN,能够对不同蛋白质-蛋白质相互作用域的特征分布进行比对。这种均衡的性能表明其在实际药物发现环境中具有更高的泛化能力。表 1 AlphaPPIMI 与基线方法在 DLiP 数据集上的性能比较(采用随机分割和冷配对分割,5 折交叉验证)全尺寸桌子绩效评估
为了评估我们框架在PPI调节器预测中的跨域泛化能力,我们评估了模型直接从源域(DLiP)迁移到未知目标域(DiPPI和iPPIDB)时的性能。如图 2所示,域迁移导致所有模型的性能显著下降。值得注意的是,AlphaPPIMI始终表现出更优异的鲁棒性,在DiPPI基准测试中,其AUROC和AUPRC均较MultiPPIMI有了显著提升。尽管基线性能良好,但域内和跨域结果之间的差距凸显了采用显式域自适应策略的必要性。
为了应对这一挑战,我们开发了 AlphaPPIMI-CDAN,一种域自适应架构,它将条件特征对齐显式地集成到学习过程中。如图 2A所示,该模型成功地对齐了跨域的特征分布,同时保持了清晰的类可分性。这种对齐直接促成了其在 DiPPI 和 iPPIDB 数据集上优于所有基线模型的预测性能(图2B)。与传统的边缘对齐方法不同,我们的模型利用类条件分布来指导域自适应,从而产生更具区分性和任务相关性的特征表示。这种条件对齐在 PPI 研究中尤为重要,因为域的转换通常对应于细微但功能上显著的变化。此外,该模型通过在域自适应过程中保留类特定的结构来减少负迁移,这有助于在清晰区分不同类别的同时保持一致的全局模式。这些结果表明,AlphaPPIMI-CDAN 有效地利用了条件域自适应,从而增强了跨域 PPI 预测的稳定性、鲁棒性和泛化能力。图 2
跨域特征分布分析及性能比较。A . 应用 CDAN 前后学习到的特征表示的 t-SNE 可视化图(左图,右图)。B .小提琴图比较了不同方法下的模型性能。上图显示了 DiPPI(蓝色)和 IPPDB(橙色)数据集上的 AUROC 得分,下图显示了 AUPRC 得分。完整尺寸图片消融研究
为了系统地评估两种蛋白质语言模型(ESM2 和 ProtTrans)以及一种结构特征提取方法(PFeature)在 PPIMI 预测中的贡献,我们利用交叉注意力网络,对六种不同的特征嵌入进行了全面的基准测试。这些嵌入包括分别源自 ESM2 和 ProtTrans 的两种独立表示,以及通过组合多种来源构建的四种集成嵌入:ESM2 + ProtTrans、ProtTrans + PFeature、ESM2 + PFeature 以及 ESM2 + ProtTrans + PFeature 的综合集成。图 3 展示了三个基准数据集(DLiP、DiPPI 和 iPPIDB)的性能比较 。结合所有三种方法的集成方法(ESM2+ProtTrans+PFeature)始终取得了最佳性能。具体而言,与 ESM2、ProtTrans、ESM2+ProtTrans、ProtTrans+PFeature 和 ESM2+PFeature 相比,该方法平均 AUROC 值分别提升了 0.136、0.117、0.029、0.065 和 0.090。AUPRC 指标也观察到了类似的提升。值得注意的是,在各个特征中,ProtTrans 表现最为出色,并且它与其他特征的结合能够持续提升所有数据集的预测精度。图 3
六种特征嵌入在三个数据集上的AUROC和AUPRC值。误差线代表五折交叉验证的标准偏差。完整尺寸图片
我们选择 ESM2-150 M 模型(640 维嵌入)以获得最佳计算效率。对不同 ESM2 模型规模的比较分析(补充图 S6)表明,尽管计算成本显著增加,但更大的模型规模仅带来微弱的性能提升。语言模型之间的维度差异远小于它们互补的信息内容。表 2 DiPPI 数据集上的领域自适应策略消融全尺寸桌子
基于优化的骨干网络,我们进一步研究了领域自适应策略的贡献,从而分离出 CDAN 模块的影响。具体而言,我们将 AlphaPPIMI-CDAN 与两个基线模型进行了比较:(1) AlphaPPIMI(直接迁移),以及 (2) AlphaPPIMI-PL,后者是一个更强的基线模型,它使用与最终模型相同的数据进行训练,但采用了更简单的伪标签技术。这项受控消融研究的详细设置见补充材料 S7。如表 2所示,在 DiPPI 数据集上,AlphaPPIMI-CDAN 不仅优于直接迁移基线模型,而且优于性能更强的 AlphaPPIMI-PL 基线模型。这些结果表明,性能提升主要归功于 CDAN 框架,而不仅仅是目标领域数据的加入。AlphaPPIMI在筛选PPI界面调节剂中的应用
为了展示AlphaPPIMI的实际预测能力,我们开展了一项深入的案例研究,重点关注热休克蛋白90 (Hsp90) 和细胞周期蛋白37 (Cdc37) 之间的蛋白质-蛋白质相互作用(PPI) [ 50 ]。Hsp90-Cdc37 PPI界面具有结构清晰的结合口袋,其中包含特征性的沟槽和疏水区域,使其成为典型的PPI界面的理想范例。这种相互作用是破坏分子伴侣功能和抑制致癌信号转导的关键治疗靶点。
我们利用 AlphaPPIMI 对 ChemDiv 化合物库中的潜在调节剂进行了评估,并筛选出预测活性评分高于 0.8 的分子。通过 t-SNE 投影可视化的化学空间分析表明,这些预测化合物与已知的活性抑制剂具有相似的化学特征(图 4A)。我们选择经验证的 Hsp90-Cdc37 相互作用抑制剂 DCZ3112 [ 51 ] 作为参考化合物,并基于结合最大公共子结构 (MCS) 分析、Tanimoto 系数计算和药效团特征的综合评估,筛选出结构相似性评分最高的三个化合物(0.65–0.67)(图 4B)。有关我们结构相似性评估方法和评分系统的详细信息,请参见补充材料 S6。
使用 UCSF DOCK 6.9 [ 52 ] 对 Hsp90-Cdc37 复合物的晶体结构(PDB ID:1US7) 进行分子对接研究。之前的研究已鉴定出蛋白质-蛋白质相互作用(PPI)界面上的关键热点氨基酸残基(图4C)。对接分析表明,DCZ3112 与界面残基 Arg32、Ser36、Asp40、Arg167 和 His197 建立了关键相互作用(图 4D)。值得注意的是,所有三个预测化合物均表现出相似的结合模式,并与这些关键残基结合(图 4E )。这些化合物一致的相互作用模式和良好的预测结合亲和力为我们的筛选策略及其作为 Hsp90-Cdc37 抑制剂的潜力提供了强有力的支持。所有结构可视化均使用 UCSF ChimeraX [ 53 ]生成,以展示蛋白质-蛋白质界面的分子相互作用。图 4
上传失败,网络异常。
重试
潜在Hsp90-Cdc37蛋白-蛋白质相互作用(PPI)抑制剂的鉴定和结构分析。A.预测化合物(蓝点)和已知活性化合物(红点)的t-SNE化学空间分布可视化图。B .参考化合物DCZ3112和三个具有高结构相似性评分的预测化合物的化学结构。C . Hsp90-Cdc37复合物的整体结构,结合界面高亮显示(方框),金色区域表示热点氨基酸残基。D .参与DCZ3112在PPI界面结合的关键残基。E .三个预测化合物的分子对接姿势,显示其与Hsp90-Cdc37界面关键残基的相互作用。完整尺寸图片AlphaPPIMI在筛选变构PPI调节剂中的应用
蛋白质-蛋白质相互作用(PPI)通常具有一些对药物发现构成挑战的特性,例如结合口袋较浅和构象柔性较高,这使得传统的基于结构的药物设计方法效果不佳[ 54 ]。传统小分子化合物库筛选的低命中率进一步印证了识别有效界面靶向调节剂的难度。在此背景下,AlphaPPIMI的预测结果为优先筛选可能与特定PPI活性位点结合的化合物提供了宝贵的指导,显著提高了PPI靶向抑制剂虚拟筛选的效率。
为了验证我们方法的实用性,我们研究了HIV-1包膜糖蛋白gp120与CD4之间的关键相互作用,该相互作用是具有重要治疗意义的蛋白质-蛋白质相互作用(PPI)靶点。这种相互作用对于病毒进入宿主细胞至关重要,并在多种病理过程中发挥核心作用,包括病毒感染、免疫逃逸和T细胞功能障碍。通过靶向gp120上gp120/CD4相互作用的特定区域来破坏该相互作用,是一种很有前景的阻断HIV-1入侵的治疗策略。这种PPI靶向策略旨在通过特异性抑制gp120与CD4之间的相互作用来阻止病毒附着和后续感染,而不是靶向整个蛋白表面[ 55 , 56 ]。
在本研究中,我们利用AlphaPPIMI从ChemDiv数据库中筛选gp120/CD4相互作用的潜在抑制剂,并选择预测概率大于0.8的化合物进行后续分析。我们使用t-SNE投影图(图 5A)可视化了gp120/CD4活性抑制剂与预测化合物之间的化学空间相似性。然后,我们选择与已知活性抑制剂化学空间重叠的先导化合物进行实验验证。我们使用具有非典型表面结构的gp120/CD4(PDB ID:6L1Y)进行分子对接。之前的研究已经确定了gp120上的活性结合口袋(图 5B)[ 54 ]。我们使用UCSF DOCK6.9[ 52 ]程序进行虚拟筛选,并使用ChimeraX可视化对接结果。如图 5C所示,先导化合物和参考化合物均能与由残基 THR51、LEU52、PHE53、CYS54、ALA73、GLN103、GLU106 和 ASP107 形成的口袋结合。这些结果表明,AlphaPPIMI 有潜力用于探索非经典 PPI 表面,并为这类具有挑战性的靶点发现候选小分子抑制剂。图 5
gp120/CD4 PPI抑制剂的虚拟筛选。A.使用t-SNE分析的化学空间可视化。B . gp120 /CD4复合物的晶体结构(PDB ID:6L1Y),显示了非典型结合界面。gp120和CD4分别以青色和鲑鱼色显示。C .参考化合物与三种代表性先导化合物在gp120结合口袋中的结合模式比较。关键相互作用残基已标记并以棒状模型显示。完整尺寸图片
方法数据集
我们使用 DLiP 数据集 [ 49 , 57 ] 训练了我们的模型,该数据集包含 12,605 个独特的调节剂,靶向 120 个不同的 PPI。该数据集整合了每个调节剂-PPI 对的蛋白质序列、三维结构信息和实验活性数据(IC50/EC50 值或结合常数)。
为了进行独立验证,我们从 DiPPI [ 58 ] 和 iPPIDB [ 59 ] 数据库中创建了两个基准数据集。这些经过整理的数据库包含实验验证的 PPI 界面调节剂,并具有详细的结构和结合信息,为我们的模型提供了严格的测试集。数据整理过程遵循三个关键的质量控制标准。首先,我们专注于异源蛋白-蛋白相互作用,排除相互作用伙伴具有相同 UniProt 标识符的情况。其次,我们删除了界面结合位点不明确的条目。第三,我们将分析范围限定于人类 PPI。为了确保靶标注释的准确性,我们将具有多个 PPI 靶标的化合物条目拆分(例如,“β-catenin/Tcf4 和 Tcf3”被拆分为单独的相互作用)。
如表3所示 ,最终整理的数据集包括:DiPPI数据集,其中包含201个不同的界面靶向调节剂,作用于1316个PPI靶点,每个样本包含调节剂的分子结构、蛋白质序列、界面三维结构信息以及二元活性标签(活性/非活性);以及iPPIDB数据集,其中包含2203个调节剂,靶向34个PPI。所有蛋白质序列均来自UniProt数据库,以保持标准化。补充图S1展示了这些数据集中分子的详细理化性质分析,包括分子描述符分布和化学空间表征。分析表明,这两个基准数据集中调节剂的界面靶向性质和化学空间分布均存在显著的异质性,这给开发通用预测模型带来了重大挑战。此外,我们使用ECFP4指纹图谱计算了化合物之间的成对Tanimoto相似性(补充图S2),以评估数据集中的分子多样性。分析结果显示平均 Tanimoto 相似性较低,表明调节因子之间存在高度结构多样性。表3 本研究中使用的训练数据集(DLiP)和基准数据集(DiPPI和iPPIDB)的统计信息全尺寸桌子
为了构建阴性样本,我们开发了一种基于化学选择性原理的策略。具体而言,对于每个PPI家族,我们筛选出能够选择性结合其他PPI家族的调节剂,并将其指定为目标家族的潜在非活性化合物。为了最大限度地降低假阴性结果的概率,我们实施了严格的过滤流程,排除了任何与目标PPI家族已知活性调节剂具有结构相似性或重叠的潜在阴性调节剂。随后,我们将这些潜在非活性调节剂与其对应的PPI靶标配对,构建了阴性样本。为了解决数据集中的类别不平衡问题,我们对阴性样本进行了下采样,以创建一个正负界面靶向对比例相等的平衡数据集。为了评估假阴性可能造成的偏差,我们对不同的正负采样比例进行了敏感性分析。如补充材料S8和表S4所示,该模型在不同的配置下均保持了其预测优势,表明其对任何特定采样比例的依赖性都很小。值得注意的是,实验验证的非活性化合物被特意排除在阴性样本库之外,因为此类验证数据在不同 PPI 靶标上的稀缺性和分布不均可能会在模型训练过程中引入偏差。
我们还通过筛选ChemDiv的蛋白质-蛋白质相互作用库(包含205,497个针对PPI靶向设计的化合物[ 60 ])评估了AlphaPPIMI在药物发现中的实际应用价值。该化合物库包含专门靶向PPI界面的化合物,这些界面具有大而平坦的表面以及关键的“热点”区域。补充图S4提供了该化合物库的分子性质和骨架多样性的详细分析。通过将我们的模型应用于该商业化合物库的筛选,我们旨在识别新型PPI调节剂,并在真实的药物发现环境中验证我们的方法。蛋白质和调节因子的特征提取
AlphaPPIMI框架采用了三种互补的蛋白质特征提取方法。ESM2模型利用Transformer架构(36个注意力层,每层20个注意力头)来捕获对界面形成至关重要的氨基酸关系。完整的ESM2模型包含30亿个参数,这些参数是在6000万条UniRef50序列上训练得到的[ 61 ]。为了平衡计算效率和性能,我们采用了ESM2-150 M变体来生成640维的特征向量。
ProtTrans模型(24层,每层32个节点)使用来自BFD[ 62 , 63 ]和UniRef50[ 61 ]的超过4500万条蛋白质序列进行预训练,生成1024维嵌入,以捕捉互补的进化模式。这两个Transformer模型并行工作,以提取与界面区域相关的全面序列特征。
PFeature 通过 19 个描述符类别提供额外的结构和理化表征,包括:(1) 基于组成的特征,(2) 序列顺序耦合数,(3) 理化性质,(4) 结构特征,以及 (5) 进化信息。PFeature 描述符与 Transformer 嵌入的整合生成了 3366 维蛋白质表示,该表示同时捕捉了序列模式和界面特异性。
对于调制器表示,我们利用 84 M 参数 Uni-Mol2 模型,该模型通过原子类型、度和化学属性的嵌入生成原子级特征 :(1)
成对特征包含键类型、最短路径距离和几何信息:(2)
其中编码原子对之间的距离。该模型为每个分子生成一个 768 维的全局特征向量。我们通过引入 ECFP4 指纹 [ 64 ] 进一步增强分子表征,ECFP4 指纹提供了一个 1024 维的二进制向量,用于捕获环状子结构信息。最终得到的 1792 维特征向量整合了分子拓扑结构、三维几何结构以及对界面结合预测至关重要的化学子结构信息。PPIMI预测的交叉关注
在对调节器和PPI目标对进行特征编码之后,我们引入了一个双向交叉注意力模块,以有效地建模调节器和目标对之间的交互作用,从而捕获增强的交互表征,用于调节器-PPI交互预测。该模块促进了目标注意力和调节器注意力键值对之间的双向信息交换,实现了全面的特征融合。这种架构设计捕捉了调节器和PPI之间复杂的交互作用,确保了两个组件的上下文一致性。
在此过程中,PPI特征会利用调制器衍生的注意力权重进行自适应细化,而调制器特征也会通过PPI衍生的注意力机制进行动态调整。这种双向交互使得交叉注意力模块能够促进特征图之间的高效信息交换,从而有效地整合调制器-PPI特性,并生成更全面的特征表示。交叉注意力模块的架构如图 1B所示。
具体来说,调制器特征矩阵和目标特征矩阵分别经过线性变换层后,再分别输入到相应的注意力子模块。在调制器注意力组件中,调制器特征按照以下公式进行处理:(3)
并利用蛋白质特征通过线性投影生成键向量和值向量(4)
这里,W表示每个注意力头的权重矩阵,表示每个注意力头的维度,(表示注意力头的数量)。类似地,对于目标特征 FP,注意力机制的计算方式如下:(5)
这里,权重矩阵W与调制器注意力共享相同的权重。
每个注意力头的调制器/目标对特征图是通过相应的注意力矩阵和值矩阵相乘计算得到的:(6)
同样地,对于目标特征:(7)
将所有注意力头的特征图沿通道维度连接起来,并通过线性层进行变换,生成两个互补的表示:调制器-PPI 交互表示和 PPI-调制器交互表示。
为了保持原始特征信息,我们通过将交互表示与其初始特征相结合来实现残差连接:添加到原始调节因子特征得到,同时与初始蛋白质特征相结合得到。然后,这些特征矩阵进行最大池化操作,分别生成紧凑表示和。最后,将池化后的表示连接起来,形成最终的联合特征表示f。
这种双向交叉注意力设计,结合了调节因子和蛋白质之间的特征交互、残差连接和最大池化操作,建立了一个可靠的框架来预测调节因子-蛋白质的相互作用。
最后,将联合表示f通过由全连接层组成的解码器网络进行处理,以预测 PPI-调制器对之间的相互作用。相互作用概率p的计算公式如下:(8)
其中W和b分别代表可学习的权重矩阵和偏置向量。最终预测结果通过 softmax 变换进行归一化:(9)
该模型通过预测概率和真实标签之间的交叉熵损失进行优化。跨领域适应
由于数据采集条件、环境和标准的差异,不同的数据集在特征分布和标签空间方面常常存在差异。DiPPI专注于界面靶向调节剂,能够捕捉界面结合所需的独特分子特征,而像DLiP这样的通用PPI数据集可能缺乏此类特定的界面靶向信息。此外,传统模型的泛化能力有限,因为它们对分布变化高度敏感,当应用于新的结构域时,尤其是在预测靶向新型PPI界面的调节剂时,会导致性能显著下降。这给在不同的PPI系统中识别有效的界面靶向化合物带来了严峻挑战。为了克服这一挑战,我们将CDAN集成到AlphaPPIMI中,从而实现了对新型界面靶向调节剂的稳健跨家族预测。
CDAN 通过将域判别器置于特征嵌入和分类器预测的联合表示上(图 1C),扩展了传统的对抗域自适应方法。这种条件架构有助于在保持判别特性的同时,更精确地对齐源域和目标域之间的分布。具体而言,CDAN 使用极小极大优化范式来最小化源域和目标域之间的差异,其中特征编码器和交叉注意力模块旨在生成域不变的表示,而判别器则试图区分不同的域。图 1C右侧面板可视化的对抗训练过程展示了源域和目标域特征如何通过相同的编码器和解码器架构进行处理,其中判别器优化对抗损失以实现有效的域对齐。
在此框架下,领域特定特征表示f和分类器预测g被组合成一个联合变量。领域判别器D以该联合变量h为条件,从而使模型能够捕捉复杂的跨领域依赖关系。对抗目标函数表述如下:(10)(11)
其中T ( h ) 表示应用于联合变量h 的条件化策略,而用于平衡源分类损失和域对抗损失。我们采用多线性条件化,其定义如下:(12)
其中表示外积,能够捕捉特征与预测之间复杂的交互作用。为了解决高维空间中的维度问题,我们采用随机多线性映射:(13)
其中和是随机矩阵,表示逐元素乘法。
此外,我们应用熵条件化来优先考虑置信度高的预测样本,并使用熵感知权重重新加权判别器损失,其中H ( g ) 是预测的熵。该技术强调高置信度样本,进一步增强了模型的鲁棒性。
CDAN模块的集成使AlphaPPIMI能够有效地比对不同PPI系统中的特征分布,从而促进在新型蛋白质家族中发现靶向界面调控剂。这种设计增强了模型对不同界面类型的泛化能力,提高了其识别特异性调控蛋白质-蛋白质界面化合物的性能。实施细节
我们使用 Python 3.8 和 PyTorch 1.13.1 实现了 AlphaPPIMI,并集成了 Scikit-learn 1.0.2、Numpy 1.21.5 和 Pandas 1.3.3 等其他库。我们的训练方案采用 AdamW 优化器,初始学习率为 5e-4,权重衰减为 1e-5,批大小为 64,这些参数是通过大量的超参数调优确定的。模型架构采用 8 个注意力头,隐藏层维度为 256。对于所有数据集,我们使用早停机制训练模型最多 500 个 epoch,该机制通过监测验证集 AUROC 值来判断模型是否达到最佳状态,耐心值为 50 个 epoch。为了防止过拟合,我们应用了 dropout(dropout 率为 0.1)和层归一化。最终,我们根据验证集 AUROC 值选择了性能最佳的模型。通过全面的超参数敏感性分析,我们的模型在不同配置下均展现出稳健的性能,通常在 150-200 个 epoch 内即可达到最佳收敛(详细分析见补充材料 S4)。所有实验均在配备 40GB 显存的单个 NVIDIA A100 GPU 上进行。评估策略和指标
我们使用五折交叉验证在DLiP数据集上进行了领域内模型评估,首先将数据划分为训练集、验证集和测试集。为了评估模型在不同泛化难度下的性能,我们采用了两种划分策略:随机划分和冷配对划分。在随机划分设置中,PPI-调节因子对被随机分配到训练集和测试集,确保完全相同的相互作用对不会同时出现在两个集中。然而,这种方案允许单个蛋白质或调节因子同时出现在两个集中,这可能导致由于实体层面的信息泄露而高估模型性能。我们在补充图S3中报告了蛋白质层面和调节因子层面的重叠统计数据,以量化这种影响。尽管存在这种局限性,随机划分仍然适用于评估模型在已知生物实体存在的情况下学习成对相互作用模式的能力。这反映了早期筛选或药物重定位中的常见场景,即在新的环境中重新组合已知的蛋白质或化合物。因此,我们报告了随机分割和冷配对分割的结果:前者反映了在宽松假设下的性能,而后者则作为更严格的泛化基准。
为了克服随机分割的局限性,我们实施了一种冷对分割策略,其中训练集和测试集中不共享任何蛋白质-蛋白质相互作用(PPI)-调节剂相互作用对。尽管单个蛋白质或调节剂之间可能仍然存在重叠,但它们的组合被严格隔离。这种设计更好地模拟了预测新型相互作用的挑战,并突出了模型的泛化能力。虽然理论上存在更严格的分割方法,例如冷蛋白分割或冷实体分割,但它们可能无法反映药物发现中的实际情况,因为在药物发现中,治疗假设通常涉及已知蛋白质或小分子的新组合。我们相信,冷对分割设计提供了一个实用且具有挑战性的基准,兼顾了泛化能力和应用相关性。
为防止数据泄露,20% 的测试集严格地不参与所有训练和调优过程。对于随机划分,超参数在从 80% 训练数据中划分出的内部验证集上进行优化。对于更为严格的冷对划分,我们采用了嵌套方法,在训练集上执行内部 5 折交叉验证以选择最佳超参数。在这两种情况下,最终模型均使用最优参数在完整的 80% 训练集上重新训练,并在未见过的测试集上进行一次评估。
此外,各数据集内调节剂的化学空间分布呈现出显著的聚类现象(补充图S1),表明仅凭领域内指标不足以反映泛化能力。为了进行更严格的评估,我们使用两个具有挑战性的数据集DiPPI和iPPIDB进行了跨领域测试,测试场景旨在反映真实药物发现应用中固有的复杂性。
参考以往的领域自适应研究,我们使用完整的DLiP数据集,并结合80%的未标注目标域数据(来自DiPPI或iPPIDB)进行训练,剩余20%的已标注目标域数据用于测试。为了平衡训练过程中源域和目标域的数据分布,我们采用了分层批次抽样策略。具体而言,每个训练批次都保持源域和目标域样本的固定比例()。对于批次大小为N的情况,我们从源域随机抽取个样本,其中代表源域的比例。这种方法确保了模型在训练过程中能够均匀地接触到源域和目标域,从而避免模型偏差,并促进有效的领域自适应。
我们使用标准指标评估模型性能:受试者工作特征曲线下面积(AUROC)和精确率-召回率曲线下面积(AUPRC)。此外,我们还计算了准确率、灵敏度和特异性:(14)(15)(16)
其中,真阳性 (TP) 和真阴性 (TN) 分别表示正确预测的相互作用对和非相互作用对,而假阳性 (FP) 和假阴性 (FN) 表示错误的预测。
结论
本研究提出了一种名为 AlphaPPIMI 的综合深度学习框架,旨在解决发现特异性靶向蛋白质-蛋白质相互作用界面的调节剂所面临的根本性挑战。我们构建了基于 DiPPI 和 iPPIDB 的基准数据集,并进行了严格的质量控制,重点关注结合于 PPI 界面而非一般蛋白质表面的化合物,从而为开发靶向 PPI 界面调节剂预测模型奠定了坚实的基础。我们的框架利用预训练的大规模模型和专门的交叉注意力模块,能够有效地模拟复杂的结合模式。此外,CDAN 的集成显著增强了模型在不同 PPI 家族间的泛化能力。大量的评估结果表明,AlphaPPIMI 在域内和跨域场景下均优于现有方法。该框架成功应用于Hsp90-Cdc37复合物这一结构明确的界面以及gp120/CD4这一复杂的非界面,验证了其在真实世界PPI药物发现中的实用性,并展现了其识别靶向不同PPI(界面)的潜在调节剂的能力。然而,需要指出的是,目前的验证尚处于计算机模拟阶段,这些识别出的化合物应被视为有潜力的候选药物,仍需实验验证。
展望未来,AlphaPPIMI 为蛋白质-蛋白质相互作用 (PPI) 调节剂的发现奠定了坚实的基础。未来的发展将聚焦于两个关键领域。在计算方面,我们将继续改进特征融合策略,并扩展训练数据中化学和生物学空间的覆盖范围。至关重要的是,在实验方面,未来的一个关键方向是通过生物物理分析(例如表面等离子共振)和后续的基于细胞的功能分析来验证高分候选药物。这一转化步骤对于将计算预测结果转化为切实可行的治疗先导化合物至关重要。这些改进将进一步增强框架的预测能力,并加速新型 PPI 靶向疗法的发现。
数据可用性
所有数据均来自公开资源。DLiP 数据集可从https://skb-insilico.com/dlip下载。DiPPI 和 iPPIDB 数据集可分别从https://github.com/ku-cosbi/DiPPI/和https://ippidb.pasteur.fr/下载。本文结论所依据的数据集和源代码可在 [ https://github.com/Bigrock-dd/AlphaPPIMI ] 代码库中找到。
缩写PPI:
蛋白质-蛋白质相互作用PPIMI:
PPI调节剂相互作用CDAN:
条件域对抗网络ML:
机器学习DL:
深度学习AUROC:
受试者工作特征曲线下面积AUPRC:
精确率-召回率曲线下面积t-SNE:
t分布随机邻域嵌入Hsp90:
热休克蛋白90Cdc37:):
细胞分裂周期 37MCS:
最大公共子结构ECFP4:
直径为 4 个键的扩展连接指纹TP:
真阳性TN:
真阴性FP:
假阳性注:
假阴性
参考
Wells JA, McClendon CL (2007) 在蛋白质-蛋白质界面上寻找药物发现中的高垂果实。Nature 450(7172):1001–1009
文章 CAS PubMed 谷歌学术
Stelzl U, Worm U, Lalowski M, Haenig C, Brembeck FH, Goehler H, Stroedicke M, Zenkner M, Schoenherr A, Koeppen S 等 (2005) 人类蛋白质-蛋白质相互作用网络:蛋白质组注释资源。Cell 122(6):957–968
文章 CAS PubMed 谷歌学术
Rual JF、Venkatesan K、Hao T、Hirozane-Kishikawa T、Dricot A、Li N、Berriz GF、Gibbons FD、Dreze M、Ayivi-Guedehoussou N 等人 (2005) 绘制人类蛋白质-蛋白质相互作用网络的蛋白质组规模图。自然437(7062):1173–1178
文章 CAS PubMed 谷歌学术
Titeca K、Lemmens I、Tavernier J、Eyckerman S (2019) 发现细胞蛋白质-蛋白质相互作用:技术策略和机遇。质谱评论 38(1):79–111
文章 CAS PubMed 谷歌学术
Vassilev LT, Vu BT, Graves B, Carvajal D, Podlaski F, Filipovic Z, Kong N, Kammlott U, Lukacs C, Klein C et al (2004) mdm2 小分子拮抗剂体内 p53 通路激活。科学 303(5659):844–848
文章 CAS 谷歌学术
Ivanov AA、Khuri FR、Fu H (2013) 靶向蛋白质-蛋白质相互作用作为抗癌策略。Trends Pharmacol Sci 34(7):393–400
文章 CAS PubMed PubMed Central 谷歌学术
Ashkenazi A、Fairbrother WJ、Leverson JD、Souers AJ (2017) 从基础细胞凋亡发现到先进的选择性 Bcl-2 家族抑制剂。Nat Rev Drug Discov 16(4):273–284
文章 CAS PubMed 谷歌学术
Shin WH、Christoffer CW、Kihara D (2017) 基于计算机结构的蛋白质-蛋白质相互作用靶向药物发现方法。Methods 131:22–32
文章 CAS PubMed PubMed Central 谷歌学术
Nero TL、Morton CJ、Holien JK、Wielens J、Parker MW (2014) 致癌蛋白界面:小分子,大挑战。Nat Rev Cancer 14(4):248–262
文章 CAS PubMed 谷歌学术
Scott DE、Bayly AR、Abell C、Skidmore J (2016) 小分子,大靶点:药物发现面临蛋白质-蛋白质相互作用的挑战。Nat Rev Drug Discov 15(8):533–550
文章 CAS PubMed 谷歌学术
Mignani S、Rodrigues J、Tomas H、Jalal R、Singh PP、Majoral JP、Vishwakarma RA (2018) 药物化学中先导化合物优化过程中的类药性筛选:它们可以简化到什么程度?Drug Discov Today 23(3):605–615
文章 PubMed 谷歌学术
Lipinski C、Lombardo F、Dominy B、Feeney P (1997) 用于筛选候选药物的体外模型——药物发现和开发中溶解度和渗透性的实验和计算方法。Adv Drug Deliv Rev 23(1):3–25
文章 CAS 谷歌学术
Lipinski CA (2004) 先导化合物和类药化合物:五规则革命。药物发现与技术 1(4):337–341
文章 CAS PubMed 谷歌学术
Morelli X, Bourgeas R, Roche P (2011) 从蛋白质-蛋白质相互作用抑制 (2p2i) 的最新成功中汲取的化学和结构经验。Curr Opin Chem Biol 15(4):475–481
文章 CAS PubMed 谷歌学术
Bickerton GR、Paolini GV、Besnard J、Muresan S、Hopkins AL (2012) 量化药物的化学之美。Nat Chem 4(2):90–98
文章 CAS PubMed PubMed Central 谷歌学术
Kosugi T, Ohue M (2021) 蛋白质-蛋白质相互作用的定量评估及其在药物相似性中的应用。载于:2021 年 IEEE 生物信息学与计算生物学计算智能会议 (CIBCB),第 1-8 页。IEEE
王杰,毛杰,王敏,乐晓,王勇(2023)利用深度生成模型探索类药空间。方法 210:52–59
文章 CAS PubMed 谷歌学术
Andrei SA、Sijbesma E、Hann M、Davis J、O'Mahony G、Perry MW、Karawajczyk A、Eickhoff J、Brunsveld L、Doveston RG 等 (2017) 药物发现中蛋白质-蛋白质相互作用的稳定性。Expert Opin Drug Discov 12(9):925–940
文章 CAS PubMed 谷歌学术
Gainza P、Sverrisson F、Monti F、Rodolà E、Boscaini D、Bronstein MM、Correia BE (2020) 利用几何深度学习从蛋白质分子表面解读相互作用指纹。Nat Methods 17(2):184–192
文章 CAS PubMed 谷歌学术
Lyu J, Wang S, Balius TE, Singh I, Levit A, Moroz YS, O'Meara MJ, Che T, Algaa E, Tolmachova K 等 (2019) 超大型化合物库对接用于发现新的化学类型。Nature 566(7743):224–229
文章 CAS PubMed PubMed Central 谷歌学术
Kozakov D, Hall DR, Napoleon RL, Yueh C, Whitty A, Vajda S (2015) 成药性新领域。医学化学杂志 58(23):9063–9088
文章 CAS PubMed PubMed Central 谷歌学术
Keskin O, Gursoy A, Ma B, Nussinov R (2008) 蛋白质-蛋白质相互作用原理:蛋白质相互作用的首选方式是什么? Chem Rev 108(4):1225–1244
文章 CAS PubMed 谷歌学术
Cukuroglu E、Engin HB、Gursoy A、Keskin O (2014) 蛋白质-蛋白质界面热点:迈向药物发现。Prog Biophys Mol Biol 116(2–3):165–173
文章 CAS PubMed 谷歌学术
Winter A、Higueruelo AP、Marsh M、Sigurdardottir A、Pitt WR、Blundell TL (2012) 基于生物物理和计算片段的蛋白质-蛋白质相互作用靶向方法:在结构导向药物发现中的应用。Q Rev Biophys 45(4):383–426
文章 CAS PubMed 谷歌学术
Cheng Y, Gong Y, Liu Y, Song B, Zou Q (2021) 药物发现中的分子设计:深度生成模型的综合综述. Brief Bioinform 22(6):344
文章 谷歌学术
Tong X,Liu X,Tan X,Li X,Jiang J,Xiong Z,Xu T,Jiang H,Qiao N,Zheng M(2021)从头药物设计的生成模型。医学化学杂志 64(19):14011–14027
文章 CAS PubMed 谷歌学术
Wang M, Wang Z, Sun H, Wang J, Shen C, Weng G, Chai X, Li H, Cao D, Hou T (2022) 深度学习方法在从头药物设计中的应用:概述. Curr Opin Struct Biol 72:135–144
文章 CAS PubMed 谷歌学术
Yamanishi Y, Araki M, Gutteridge A, Honda W, Kanehisa M (2008) 基于化学和基因组空间整合的药物-靶标相互作用网络预测。生物信息学 24(13):232–240
文章 谷歌学术
Huang K, Fu T, Glass LM, Zitnik M, Xiao C, Sun J (2020) Deeppurpose:用于药物靶点相互作用预测的深度学习库。生物信息学 36(22–23):5545–5547
CAS PubMed Central 谷歌学术
Milroy LG、Grossmann TN、Hennig S、Brunsveld L、Ottmann C (2014) 蛋白质-蛋白质相互作用的调节剂。化学评论 114(9):4695–4748
文章 CAS PubMed 谷歌学术
Soleymani F, Paquet E, Viktor H, Michalowski W, Spinello D (2022) 基于深度学习的蛋白质-蛋白质相互作用预测:综述. Comput Struct Biotechnol J 20:5316–5341
文章 CAS PubMed PubMed Central 谷歌学术
胡晓,冯超,凌涛,陈敏(2022)用于蛋白质-蛋白质相互作用预测的深度学习框架。计算机结构生物技术杂志 20:3223–3233
文章 CAS PubMed PubMed Central 谷歌学术
Hamon V, Bourgeas R, Ducrot P, Theret I, Xuereb L, Basse MJ, Brunel JM, Combes S, Morelli X, Roche P (2014) 2p2ihunter:一种通过专用支持向量机过滤正构蛋白-蛋白相互作用调节剂的工具。JR Soc Interface 11(90):20130860
文章 PubMed PubMed Central 谷歌学术
Jana T、Ghosh A、Das Mandal S、Banerjee R、Saha S (2017) Ppimpred:用于高通量筛选靶向蛋白质-蛋白质相互作用的小分子的网络服务器。皇家学会开放科学 4(4):160501
文章 谷歌学术
Rodrigues CH、Pires DE、Ascher DB (2021) Pdcsm-ppi:利用基于图的特征识别蛋白质-蛋白质相互作用抑制剂。J Chem Inf Model 61(11):5438–5445
文章 CAS PubMed 谷歌学术
Gupta P, Mohanty D (2021) Smmppi:一种基于机器学习的蛋白质-蛋白质相互作用调节因子预测方法及其在SARS-CoV-2中RBD:HACE2相互作用新型抑制剂鉴定中的应用。Brief Bioinform 22(5):111
文章 谷歌学术
Wang J, Mao J, Li C, Xiang H, Wang X, Wang S, Wang Z, Chen Y, Li Y, No KT 等 (2024) 面向蛋白质-蛋白质相互作用调节剂的界面感知分子生成框架. J Cheminform 16(1):1–18
文章 谷歌学术
Lin Z, Akin H, Rao R, Hie B, Zhu Z, Lu W, Smetanin N, Verkuil R, Kabeli O, Shmueli Y 等 (2023) 利用语言模型进行原子级蛋白质结构的进化尺度预测。Science 379(6637):1123–1130
文章 CAS PubMed 谷歌学术
Rives A, Meier J, Sercu T, Goyal S, Lin Z, Liu J, Guo D, Ott M, Zitnick CL, Ma J 等 (2021) 将无监督学习扩展到 2.5 亿条蛋白质序列,从而揭示生物结构和功能。美国国家科学院院刊 118(15):2016239118
文章 谷歌学术
Rao RM、Liu J、Verkuil R、Meier J、Canny J、Abbeel P、Sercu T、Rives A (2021) MSA Transformer。载于:国际机器学习会议,第 8844–8856 页。PMLR
Meier J、Rao R、Verkuil R、Liu J、Sercu T、Rives A (2021) 语言模型能够零样本预测突变对蛋白质功能的影响。神经信息处理系统进展 34:29287–29303
谷歌学术
Zhou G, Gao K, Hu J, Liu M, Gao J (2023) Uni-mol:一种通用的三维分子表征学习框架。载于:国际表征学习会议
Elnaggar A, Heinzinger M, Dallago C, Rehawi G, Wang Y, Jones L, Gibbs T, Feher T, Angerer C, Steinegger M 等 (2021) Prottrans:通过自监督深度学习和高性能计算破解生命密码语言。IEEE模式分析与机器智能汇刊 44(7):3195–3211
谷歌学术
Long M, Cao Z, Wang J, Jordan MI (2018) 条件对抗域适应. 神经信息处理系统进展 31:1640–1650
Cortes C, Vapnik V (1995) 支持向量网络.机器学习20:273–297
文章 谷歌学术
Chen T, Guestrin C (2016) Xgboost:一种可扩展的树提升系统。载于:第22届ACM SIGGDD国际知识发现与数据挖掘会议论文集,第785-794页。
Popescu MC、Balas VE、Perescu-Popescu L、Mastorakis N (2009) 多层感知器和神经网络。WSEAS Trans Circuits Syst 8(7):579–588
谷歌学术
Breiman L (2001) 随机森林.机器学习 45:5–32
文章 谷歌学术
Sun H, Wang J, Wu H, Lin S, Chen J, Wei J, Lv S, Xiong Y, Wei DQ (2023) 用于预测 ppi-调节剂相互作用的多模态深度学习框架. J Chem Inf Model 63(23):7363–7372
文章 CAS PubMed 谷歌学术
王莉,张莉,李莉,姜娟,郑志,尚健,王超,陈伟,包强,徐晓等(2019)小分子抑制剂靶向结直肠癌中hsp90-cdc37蛋白-蛋白相互作用。Sci Adv 5(9):2277
文章 谷歌学术
Chen X, Liu P, Wang Q, Li Y, Fu L, Fu H, Zhu J, Chen Z, Zhu W, Xie C 等 (2018) 新型 HSP90 抑制剂 Dcz3112 通过破坏 HSP90-CDC37 相互作用,对 HER2 阳性乳腺癌发挥强效抗肿瘤活性。Cancer Lett 434:70–80
文章 CAS PubMed 谷歌学术
Balius TE、Tan YS、Chakrabarti M (2024) Dock 6:通过预先计算的配体构象进行分层遍历以实现大规模对接。J Comput Chem 45(1):47–63
文章 CAS PubMed 谷歌学术
Goddard TD、Huang CC、Meng EC、Pettersen EF、Couch GS、Morris JH、Ferrin TE (2018) Ucsf chimerax:应对可视化和分析方面的现代挑战。蛋白质科学 27(1):14–25
文章 CAS PubMed 谷歌学术
Duan LW, Zhang H, Zhao MT, Sun JX, Chen WL, Lin JP, Liu XQ (2017) HIV-1 gp120 核心与 CD4 复合物晶体结构中的非典型结合界面。Sci Rep 7(1):46733
文章 PubMed PubMed Central 谷歌学术
Kwong PD、Wyatt R、Robinson J、Sweet RW、Sodroski J、Hendrickson WA (1998) HIV gp120 包膜糖蛋白与 CD4 受体和中和性人抗体的复合物结构。Nature 393(6686):648–659
文章 CAS PubMed PubMed Central 谷歌学术
Myszka DG、Sweet RW、Hensley P、Brigham-Burke M、Kwong PD、Hendrickson WA、Wyatt R、Sodroski J、Doyle ML (2000) HIV gp120-CD4 结合反应的能量学。美国国家科学院院刊 97(16):9026–9031
文章 CAS PubMed PubMed Central 谷歌学术
Ikeda K, Maezawa Y, Yonezawa T, Shimizu Y, Tashiro T, Kanai S, Sugaya N, Masuda Y, Inoue N, Niimi T 等 (2023) Dlip-ppi 库:一个整合了靶向蛋白质-蛋白质相互作用的小分子至中分子的化学数据库。Front Chem 10:1090643
文章 PubMed PubMed Central 谷歌学术
Cankara F, Senyuz S, Sayin AZ, Gursoy A, Keskin O (2024) Dippi:蛋白质-蛋白质界面中类药分子的精选数据集。J Chem Inf Model 64(13):5041–5051
文章 CAS PubMed PubMed Central 谷歌学术
Labbé CM、Laconde G、Kuenemann MA、Villoutreix BO、Sperandio O (2013) ippi-db:一个人工整理的交互式小分子非肽类蛋白质-蛋白质相互作用抑制剂数据库。Drug Discov Today 18(19–20):958–968
文章 PubMed 谷歌学术
ChemDiv Inc (2024) ChemDiv:研究与发现筛选库。商业化合物库。https ://www.chemdiv.com/。访问日期:2025年8月14日。
Suzek BE、Wang Y、Huang H、McGarvey PB、Wu CH、Consortium U (2015) Uniref 集群:一种用于改进序列相似性搜索的全面且可扩展的替代方案。生物信息学 31(6):926–932
文章 CAS PubMed 谷歌学术
Steinegger M, Söding J (2018) 在线性时间内对海量蛋白质序列集进行聚类分析。Nat Commun 9(1):2542
文章 PubMed PubMed Central 谷歌学术
Steinegger M、Mirdita M、Söding J (2019) 蛋白质水平组装可显著提高宏基因组样本中蛋白质序列的回收率。Nat Methods 16(7):603–606
文章 CAS PubMed 谷歌学术
Rogers D, Hahn M (2010) 扩展连接指纹。J Chem Inf Model 50(5):742–754
文章
引进/卖出
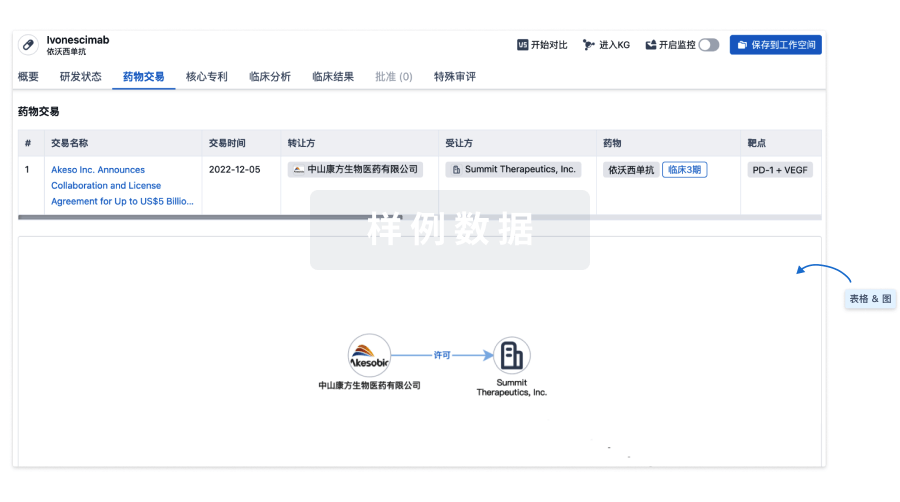
100 项与 PPI 调节剂 (湃隆生物) 相关的药物交易
登录后查看更多信息
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 实体瘤 | 临床前 | 中国 | 2024-12-01 |
登录后查看更多信息
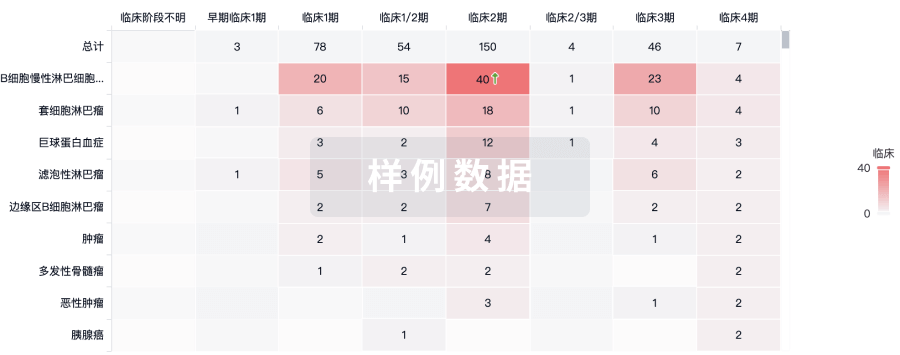
临床结果
临床结果
适应症
分期
评价
查看全部结果
| 研究 | 分期 | 人群特征 | 评价人数 | 分组 | 结果 | 评价 | 发布日期 |
|---|
No Data | |||||||
登录后查看更多信息
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用