预约演示
更新于:2025-12-06

Alston Wilkes Society, Inc.
更新于:2025-12-06
概览
关联
100 项与 Alston Wilkes Society, Inc. 相关的临床结果
登录后查看更多信息
0 项与 Alston Wilkes Society, Inc. 相关的专利(医药)
登录后查看更多信息
224
项与 Alston Wilkes Society, Inc. 相关的新闻(医药)2025-12-04
·百度百家
从治病到续命,从药厂到硅谷,健康科技的钱正在流向这些“未来器官”
第一段:反常识当全球还在为AI能否取代医生争论不休时,资本已经用真金白银投出了答案——2025年三季度,人工智能在医疗领域的投资占比飙升至45%,相当于每2美元风投就有近1美元砸向AI医疗。更颠覆认知的是,60%的早期资金正在逃离传统“治病救人”的项目,转身拥抱“还没生病就开始管理健康”的新赛道。这不是科幻电影的剧本,而是正在发生的医疗产业革命。
第二段:背景这份搅动行业神经的数据来自全球顶级健康科技风投分析机构的季度报告,覆盖了北美、欧洲、亚太地区的1200+笔交易,总金额超过300亿美元。与往年不同的是,本季度数据首次清晰展现了一个信号:医疗行业的“钞能力”正在经历前所未有的转向,那些曾经被视为“离钱远”的前沿领域,正在成为资本疯抢的香饽饽。
第三段:观点全球健康科技风险投资正高度集中于AI驱动及精准医疗解决方案领域,这加速了医疗行业的范式从“规模化通用治疗”转向“个性化、主动式健康管理”,并重塑了未来的竞争格局与投资回报逻辑。这场由资本主导的变革,正在改写医疗产业的底层代码。
一、AI医疗正在“吞噬”整个行业的钱袋子
呈现数据:2025年第三季度,人工智能在药物发现、诊疗辅助等领域的投资额占全球健康科技风投总额的45%,占比环比提升10个百分点。
深度解读:这组数据背后,是一场静悄悄的“资本夺权”。当AI制药平台将传统6-10年的药物研发周期压缩至2年,当AI影像诊断的准确率超越三甲医院主任医师,资本用45%的押注率宣告:医疗行业的“水电煤”正在从化学试剂变成数据算法。就像互联网颠覆零售,AI正在重新定义医疗产业的“基础设施”——腾讯投资的AI制药公司英矽智能,其虚拟研发平台已孵化出3款进入临床的候选药物;谷歌DeepMind的AlphaFold数据库,让全球药企免费使用2亿种蛋白质结构预测成果。这不是简单的技术升级,而是用代码重构医疗行业的生产力工具。形象比喻:如果把健康科技比作一座城市,AI医疗就是正在疯狂扩张的“中央商务区”,不仅吸走了最多的建设资金,还在制定未来城市的发展规划。
二、精准医疗的“疯狂增速”背后:投资者在赌什么?
呈现数据:精准医疗初创公司的早期融资(B轮及以前)总额同比增长80%,增速远超数字健康平台(25%)。
深度解读:80%的增速意味着什么?意味着投资者愿意用“投十个成一个”的高风险,去换取“一针治愈遗传病”的高回报。当诺华的CAR-T细胞疗法以210万美元的天价仍供不应求,当CRISPR Therapeutics用基因编辑治愈镰状细胞贫血症,资本看清了一个趋势:未来的医疗不是“千人一药”的规模生意,而是“一人一策”的定制化服务。与数字健康平台的流量逻辑不同,精准医疗的底层逻辑是“技术垄断”——掌握独特基因编辑工具或靶向药物递送系统的公司,将像当年掌握搜索引擎算法的谷歌一样,建立难以撼动的行业地位。这就是为什么红杉资本在今年连续出手5家基因治疗公司,因为他们赌的不是单个产品,而是整个医疗产业从“标准化生产”到“个性化定制”的范式转移。形象比喻:如果说传统制药是“大规模生产的方便面”,精准医疗就是“米其林三星的定制大餐”——虽然制作复杂、价格昂贵,但正在成为高端市场的绝对主流。
三、从“治病”到“防病”:资本为何突然爱上“未病先治”?
呈现数据:本季度,流向早期阶段公司的资金中,超过60%聚焦于“预防性”与“诊断性”技术,而非传统的“治疗性”项目。
深度解读:60%的资金前移,揭示了医疗产业最根本的逻辑转变:从“疾病发生后被动应对”到“疾病发生前主动拦截”。当苹果手表能预警心脏病发作,当肠道微生物检测能预测糖尿病风险,资本发现:在疾病管理的价值链上,最赚钱的环节不是“治疗疾病”,而是“不让疾病发生”。这就像互联网行业从“卖流量”到“卖会员”的转变——预防性技术通过持续监测人体数据,构建起“健康管理订阅制”的商业模式,其复购率和用户粘性远超一次性治疗服务。阿里健康投资的糖尿病早筛公司,其AI算法能通过眼底照片提前5年预测发病风险,这种“提前介入”的能力,正在让传统药企的治疗业务变成整个健康链条中“附加值最低”的环节。形象比喻:如果把人体比作一座房子,传统治疗是“房子漏水后再修补”,而预防诊断技术则是“定期安检+提前加固”——虽然前期投入高,但能避免后期更大的损失,这正是精明的资本最擅长的“风险控制”。
四、1亿美元俱乐部的秘密:谁在打造医疗行业的“操作系统”?
呈现数据:本季度全球超过1亿美元的巨型融资事件中,80%发生在AI制药平台和下一代基因编辑工具公司。
深度解读:80%的巨额融资流向平台型公司,暴露了资本的“终极野心”——打造医疗行业的“操作系统”。就像微软Windows系统让无数软件开发者依附其上,AI制药平台正试图成为药物研发的“通用技术底座”:药企可以像使用Office办公软件一样,在平台上完成靶点发现、分子设计、临床试验模拟等全流程。同样,掌握下一代基因编辑工具的公司,正在构建“基因层面的安卓系统”——允许开发者在其技术框架内开发针对不同疾病的治疗方案。这种平台化战略一旦成功,将形成“赢者通吃”的垄断格局:就像AWS占据云计算市场40%份额,未来可能出现一家AI制药平台,承接全球一半以上的新药研发需求。这就是为什么辉瑞、罗氏等传统药企纷纷入股AI平台公司——与其自己从头研发,不如成为未来“医疗操作系统”的“付费用户”。形象比喻:如果把健康科技的创新比作“智能手机时代”,AI制药平台和基因编辑工具就是iOS和安卓系统,而具体的药物和疗法,不过是运行在系统上的“APP应用”。
五、当药企、科技巨头和主权基金都来抢筹:健康科技还是“风投游戏”吗?
呈现数据:在健康科技头部交易中,跨国药企、科技巨头的战略投资部及主权基金参与的交易占比达50%,创历史新高。
深度解读:50%的非传统资本入场,标志着健康科技投资已从“财务回报驱动”转向“战略布局驱动”。当阿斯利康战略投资AI影像公司推想科技,其目的不是短期获利,而是获取肺癌早筛的AI算法,完善自身肿瘤诊疗管线;当沙特主权基金斥资10亿美元入股基因测序公司Illumina,看重的是基因数据在未来人口健康管理中的战略价值;当亚马逊投资远程患者监测公司,其实是为了将Alexa智能音箱变成家庭健康管理的入口。这些玩家的入场,彻底改变了游戏规则——他们不追求“3年退出”的VC逻辑,而是“十年磨一剑”的产业整合。这意味着健康科技行业将出现更多“超级独角兽”,它们不仅有技术优势,更有巨头背书的生态位优势,就像当年被谷歌收购的安卓,在巨头资源加持下成为移动操作系统的王者。形象比喻:如果说早期健康科技投资是“散户炒股”,现在则变成了“机构主力控盘”——这些产业资本就像战略投资者,正在用资本为未来十年的医疗产业“圈地划界”。
总结健康科技的这场资本狂欢,本质上是人类用技术重新定义“生老病死”的伟大尝试。当AI能预测疾病、基因编辑能修正缺陷、预防技术能延缓衰老,医疗产业正在从“疾病修复”升级为“健康优化”。对于投资者而言,这不是简单的赛道选择,而是站在医疗产业革命的十字路口——押对了AI制药平台或基因编辑工具的公司,可能获得当年投资微软或谷歌的回报;而错过这场范式转移的玩家,终将被挡在未来医疗的大门之外。
趋势预测:未来1-2年,我们将看到三个确定性趋势:
一是AI制药平台将进入“合纵连横”阶段,出现3-4家主导全球新药研发的“超级平台”;
二是基因编辑疗法将从罕见病走向常见病,催生首个千亿美元市值的生物科技公司;
三是“健康数据银行”模式将兴起,个人健康数据的资产化交易成为新风口。
但这里有个值得深思的问题:当医疗越来越像一门“精准计算投入产出比”的生意,我们是否会陷入“只关注能赚钱的健康问题”的伦理陷阱?或许,500亿美元的真正意义,不仅在于医疗系统的利润增长,更在于重新定义“健康价值”——让每个女性的生命质量,都成为不可被数据忽视的KPI。
#AI演绎全球IP大乱斗#
2025-12-03
以下内容由Ai辅助生成,目的是整理公开信息,仅供学习参考!
在2024至2025年的科技版图中,人工智能驱动的科学发现(AI for Science, AI4S)已跨越了概念验证的“死亡之谷”,正式进入工业化部署与基础设施整合的关键阶段。这一转变不仅是算法层面的迭代,更是科研范式从“经验试错”向“计算预测”的根本性迁移。
分析表明,AI4S领域正呈现出鲜明的“三层分化”格局:
基础设施与工业层(Infrastructure & Industry Layer): 以玻尔(Bohrium)和腾讯AI4S为代表。前者通过“深势·宇知”大模型体系确立了在微观粒子模拟与材料科学领域的操作系统地位,深度绑定宁德时代等行业巨头,解决新能源研发的“卡脖子”问题;后者依托腾讯云的强大算力与“混元”医疗大模型,通过与辉瑞(Pfizer)的战略合作,打通了从药物研发(湿实验)到患者服务(微信生态)的商业闭环。这一层级的业务紧迫性最高,直接关联产业生存与国家战略安全。
国家基座与学术层(National Foundation & Academic Layer): 以中国科学院自动化研究所发布的ScienceOne为核心。作为“科学大脑”,ScienceOne致力于构建自主可控的科学智能基座,通过多模态科学大模型解决跨学科复杂问题。其技术成熟度极高,具备处理亿级文献与调度数百种科学工具的能力,但在商业化路径上更侧重于国家科研效率的提升而非直接盈利。
用户工具与效用层(User Utility & Tool Layer): 以SCAICH和PaperRed为典型。SCAICH利用AI Agent技术重构了学术文献的检索路径,解决了Sci-Hub庞大数据库的自然语言交互问题;PaperRed则在学术诚信与AIGC检测的博弈中寻找生存空间。这一层级通过解决用户的具体痛点(如文献获取难、查重降重需求)获取流量,但在合规性与长期护城河构建上面临挑战。
本系列报告将严格遵循“技术成熟度”与“业务紧迫性”的双维评估框架,深入剖析各实体在算法演进、商业模式、生态构建及未来风险方面的表现,旨在为决策者提供一份兼具战略高度与执行细节的参考指南。
国家基座与学术层:中国科学院自动化研究所ScienceOne深度战略研究报告
深度解析 | AI for Science
1. 宏观叙事:第四范式下的科学智能与国家战略重构1.1 科学发现的范式转移与历史必然性
人类探索自然规律的历程,正处于一场史无前例的认知革命之中。回顾历史,科学发现经历了从以实验描述为主的“第一范式”(如钻木取火、伽利略的比萨斜塔实验),到以模型归纳为主的“第二范式”(如牛顿运动定律、麦克斯韦方程组),再到以计算机仿真为主的“第三范式”(如天气预报、核试验模拟)。然而,随着科学仪器精度的指数级提升,现代科学产生的数据量早已超越了人类大脑的处理极限,甚至超越了传统数值计算的承载能力。面对高维、稀疏、跨尺度的海量科学数据,以人工智能为驱动的“第四范式”(AI for Science, AI4S)应运而生。
在此背景下,中国科学院自动化研究所(CASIA)推出的 ScienceOne ,绝非一款单纯的软件工具或商业产品,而是作为“国家基座与学术层”的核心基础设施被构建出来的。它代表了国家意志在科研智能化领域的具体投射,旨在构建一个自主可控、安全可靠的“科学大脑”。这个大脑不仅需要具备通过阅读亿级文献获取知识的“通识”能力,更需要具备调度数百种科学工具进行验证的“实践”能力,从而解决跨学科的复杂问题。1.2 地缘政治视角下的“国家基座”定义
在当前的国际科技竞争格局中,基础模型(Foundation Models)已成为大国博弈的战略高地。虽然西方的GPT-4、Claude等通用大模型展现了惊人的语言能力,但在处理敏感科学数据(如基因序列、航天材料配方、高能物理实验数据)时,依赖外部商业模型存在着巨大的数据主权风险与技术断供风险。
ScienceOne的“国家基座”定位体现在三个维度:数据主权(Data Sovereignty):
确保核心科学数据的训练、推理与存储完全在中国境内的基础设施上完成,构建物理隔离与逻辑隔离的双重安全屏障。技术自主(Tech Autonomy):
从底层的训练框架(如昇思MindSpore等国产框架)到上层的模型算法,实现全栈自主可控,规避因制裁导致的科研停摆。算力底座(Compute Infrastructure):
适配国产异构算力(如华为昇腾、寒武纪等),推动国产AI芯片在复杂科学计算场景下的生态成熟。1.3 学术层的重塑:打破学科孤岛
传统的学术研究往往受限于“学科孤岛”效应。一位杰出的有机化学家可能对量子物理的最新进展知之甚少,这种知识壁垒限制了跨学科创新的涌现。ScienceOne作为“学术层”的智能中枢,其核心使命是利用多模态大模型技术,将物理、化学、生物、材料、数学等不同学科的知识进行统一表征与融合。通过学习亿级文献,ScienceOne实际上构建了一个超越任何单一人类科学家认知范围的“全科专家”,为解决如碳中和、创新药研发等系统性难题提供了新的协同路径。
2. 技术解构:ScienceOne的多模态科学智能架构
ScienceOne的技术架构代表了当前国产AI在科学领域的最高水准。其设计理念超越了传统的“文本生成”,转向了更具挑战性的“科学求解”与“假设验证”。本章将深入剖析其底层架构。2.1 亿级文献处理与多模态知识图谱构建
ScienceOne的认知基础源于对海量科学文献的深度解析。根据技术披露,该系统具备处理亿级规模科学文献的能力。这不仅仅是文本的存储与索引,而是一个复杂的认知过程。2.1.1 异构科学数据的全解析
科学文献与普通新闻文本有着本质区别。一篇典型的《Nature》论文包含复杂的数学公式(LaTeX)、化学分子式(SMILES/InChI)、蛋白质三维结构图(PDB格式)、实验数据图表以及显微镜影像。
ScienceOne引入了专用的科学文档解析引擎(Scientific Document Parser)。该引擎利用视觉与语言结合的技术,能够精确识别PDF中的非结构化信息:公式还原:
将扫描版PDF中的数学公式自动转换为可编辑、可计算的LaTeX代码。图表解构:
不仅识别图表中的图像,还能提取坐标轴数据、图例含义,将“死图”转化为“活数据”。分子转译:
识别文本或图像中的化学分子结构,并将其转换为机器可理解的图神经网络(GNN)输入格式。2.1.2 跨学科语义对齐与消歧
在构建知识图谱时,ScienceOne面临的最大挑战是术语的多义性。例如,“Nucleus”在生物学中指“细胞核”,在物理学中指“原子核”,在代数学中可能指“核空间”。ScienceOne通过上下文感知的嵌入技术(Context-aware Embeddings),实现了跨学科术语的精准语义对齐。它构建了一个包含数亿个实体与关系的 超大规模科学知识图谱(Hyper-scale Scientific Knowledge Graph) ,使得模型在进行推理时,能够准确区分不同学科语境下的概念,并发现潜在的跨学科联系。2.2 “科学大脑”的代理(Agent)机制:从感知到行动
如果说知识图谱是ScienceOne的“记忆”,那么代理系统(Agent System)就是它的“手脚”。这是ScienceOne区别于ChatGPT等聊天机器人的核心特征——它具备 工具调度能力 。2.2.1 任务规划与拆解(Planning)
当用户提出一个宏大的科学问题(如“设计一种耐高温的新型合金”)时,ScienceOne的规划层(Planner)会将其拆解为一系列可执行的子任务链(Chain of Thought)。
子任务1:检索现有的耐高温合金文献,提取元素配比规律。
子任务2:基于生成模型推荐5种新的候选配方。
子任务3:调用热力学模拟软件计算相图。
子任务4:调用第一性原理软件计算晶格稳定性。
子任务5:汇总数据,输出报告。2.2.2 工具接口标准化与自主调用
ScienceOne集成了数百种科学工具,涵盖了从微观到宏观的各个尺度。为了实现自主调度,ScienceOne建立了一套 统一工具接口标准(Unified Tool Interface, UTI)。
科学领域
集成典型工具
ScienceOne的调用逻辑
量子化学/材料
VASP, Gaussian, LAMMPS
自动生成输入文件(INCAR, POSCAR),监控收敛过程,解析输出日志(OUTCAR)。
结构生物学
AlphaFold2, Rosetta, PyMol
输入氨基酸序列,调用GPU集群进行折叠预测,输出PDB文件并自动渲染视图。
数学与统计
Mathematica, MATLAB, R
将自然语言问题转化为符号计算脚本或统计代码,执行并返回数值结果。
文献计量
CiteSpace, VosViewer
对检索结果进行引文网络分析,生成领域热点演进图谱。
这种机制有望解决大模型“幻觉”的问题。在科学研究中,我们不需要模型“编造”一个熔点数据,而是需要它去“计算”或“查找”一个真实的数据。ScienceOne通过调用工具,保证了输出结果的科学严谨性。2.3 多模态融合与跨尺度建模技术
科学问题的复杂性往往要求在不同模态和尺度间进行转换。ScienceOne采用了基于Transformer的统一多模态架构,实现了以下关键转换能力:Text-to-Action (文本到行动):
将“优化反应条件”的自然语言指令转化为实验室自动化设备的控制代码(如Python脚本控制液体工作站)。Graph-to-Text (图谱到文本):
理解复杂的分子结构图或生物通路图,并生成详细的机理阐释文本。Equation-to-Code (公式到代码):
阅读论文中的数学推导过程,自动生成可执行的Python或C++代码进行数值验证。
3. 使用方式详解:从接入指南到全流程实操
作为国家级科研基础设施,ScienceOne的使用方式设计兼顾了普惠性与安全性。它不同于纯商业软件的SaaS模式,而是采用了一种分层级的、以机构认证为核心的接入体系。3.1 用户分层与接入体系
ScienceOne的服务架构设计了严格的用户权限管理,以确保算力资源的合理分配和敏感数据的安全。
用户层级
目标群体
接入方式与认证
权限范围
典型应用场景
核心层 (Core Tier)
国家实验室、双一流高校顶尖课题组、军工科研单位
专线直连 / 私有云节点。需通过机要通道或CARSI(中国教育科研网)高级认证。
全量开放。可访问底层API,支持模型微调(Fine-tuning),拥有最高优先级的HPC算力调度权。
重大专项攻关、国防科技研发、从0到1的基础理论突破。
产业层 (Industry Tier)
行业头部企业(医药、新材料、能源)、央企研究院
混合云部署 (MaaS)。需签署企业战略合作协议,通过资质审核。
领域定制。提供特定行业的模型切片(如“ScienceOne-Pharma”),支持企业私有数据隔离训练,保障商业机密。
新药管线开发、新型电池材料设计、芯片EDA辅助设计。
公众层 (Public Tier)
普通高校师生、个人研究者、科普工作者
Web端云工作台。基于实名制认证,绑定学术机构邮箱(.edu.cn /.ac.cn)。
基础功能。具备文献检索、问答、基础工具调用能力。算力配额有限制。
文献综述撰写、基础实验数据处理、教学辅助、科普创作。3.2 详细操作全流程:以“光催化剂研发”为例
为了直观展示ScienceOne的使用方式,以下详细描述一名材料科学研究员利用ScienceOne进行 “高效析氢光催化剂” 研发的全过程。阶段一:意图解析与智能调研(ScienceOne Chat)登录与环境配置:
用户通过Web端登录ScienceOne工作台,选择“材料科学模式”。输入指令:
用户在对话框输入自然语言:“我正在寻找一种基于g-C3N4(石墨相氮化碳)的高效析氢光催化剂,重点关注通过异质结工程提升量子效率的策略。请综述近3年的突破性进展。”系统执行:
- 语义分析:模型提取关键词“g-C3N4”、“HER (Hydrogen Evolution Reaction)”、“Heterojunction”、“Quantum Efficiency”。- RAG检索:系统扫描ArXiv、Web of Science、CNKI等数据库中的近千万篇相关文献。- 信息抽取:自动提取每篇高引论文中的材料改性策略、光源条件、产氢速率(μmol/h/g)等关键参数。输出结果:
ScienceOne生成了一份结构化的综述报告,并附带一张动态对比表格,列出了Top 10最优材料的性能参数。用户可以直接点击表格中的数据点,回溯到原始论文的PDF段落。阶段二:假设生成与实验设计(ScienceOne Planner)交互深化:
用户选中其中一篇关于“S型异质结”的论文,指令系统:“基于此机理,推荐一种新的二元复合材料体系,要求成本低于贵金属铂。”推理与生成:
- 模型结合元素周期表性质和成本数据库,推荐了“MoS2/g-C3N4”和“NiS/g-C3N4”两种方案。- 模型解释理由:“NiS具有金属性质,能有效促进电子转移,且Ni元素丰度高,成本低。”方案细化:
用户选择“NiS/g-C3N4”方案。系统自动生成合成路径建议:“建议采用一步水热法,前驱体选用硫脲和乙酸镍,温度控制在180℃,保温12小时。”阶段三:仿真模拟与工具调度(ScienceOne Agent)启动模拟:
用户点击“验证电子结构”按钮。自动调度:
- ScienceOne自动生成构建晶体结构的脚本。- 调用VASP工具:后台自动编写INCAR(输入参数)、POSCAR(原子坐标)、KPOINTS(K点路径)、POTCAR(赝势文件)。- 算力路由:任务被分发到连接的高性能计算集群(如曙光或神威节点)。- 过程监控:系统实时监控SCF(自洽场)收敛情况。若遇到不收敛错误,Agent会自动调整混合参数(AMIX/BMIX)并重新提交,无需人工干预。- 结果可视化:计算完成后,ScienceOne自动调用绘图引擎,生成能带结构图(Band Structure)和态密度图(DOS),并计算出理论上的带隙值。阶段四:结果反馈与闭环报告生成:
系统将文献调研背景、设计思路、合成方案、模拟数据汇总生成一份PDF格式的《预研分析报告》。实验建议:
基于模拟结果,系统提示:“模拟显示NiS负载量超过5%可能导致复合中心增多,建议实验中设置1%、3%、5%三个浓度梯度进行验证。”。3.3 成本结构与商业模式分析
ScienceOne的商业化路径与其“国家基座”的定位紧密相关,呈现出明显的 “算力公益化,服务差异化” 特征。它不追求短期的软件许可利润,而是侧重于提升国家整体的科研投入产出比(ROI)。3.3.1 显性成本(用户视角)基础服务(免费):
对于认证的学术用户,文献检索、知识问答、轻量级代码生成等功能完全免费。这是为了降低科研门槛,通过大规模用户交互优化模型。算力服务(按需计费):
涉及VASP、AlphaFold等高算力消耗的工具调用时,采用“算力通证”模式计费。- 计费标准:通常低于商业云厂商(如AWS、阿里云)的市场价,仅覆盖电费与运维成本。例如,每GPU时(NPU时)可能仅需几元人民币。- 支付方式:支持使用国家自然科学基金、重点研发计划等科研经费直接结算,流程打通,无需复杂的财务报销转换。增值服务(项目制):
针对企业的私有模型定制、私有化部署,采用项目制报价,包含硬件成本、部署实施费及年维保费。3.3.2 隐性收益与国家账本
从国家战略层面看,ScienceOne的“盈利”计算方式截然不同:研发周期缩短:
如果ScienceOne能将一款新药的研发周期从10年缩短至3年,或者将新型航空发动机材料的研发周期缩短一半,其产生的经济价值高达数千亿,远超软件本身的订阅收入。试错成本降低:
通过精准的模拟与预测,减少了大量盲目的“湿实验”(Wet Lab experiments),节省了昂贵的试剂、耗材和设备折旧费。人才红利释放:
将科研人员从枯燥的文献阅读和代码调试中解放出来,专注于高价值的创新思考,提升了国家的人才效能。
4. 成功案例与应用成效:从理论预言到实体落地
ScienceOne发布以来,已在多个“卡脖子”的关键领域取得了实质性的应用成效,证明了其作为“科学大脑”的实战能力。4.1 案例一:生物医药领域的全流程加速合作方:
国内某头部创新药企联合实验室痛点:
针对某特定自身免疫性疾病的靶点(JAK激酶家族),传统筛选面临同源蛋白选择性差、副作用大的难题。ScienceOne介入流程:
- 靶点挖掘:系统阅读了近5000篇病理学与结构生物学论文,构建了JAK家族的详细构象图谱,识别出一个全新的变构调节位点。- 生成式设计:利用SBDD(基于结构的药物设计)模型,针对该变构位点生成了3000个全新的分子骨架。- 多维筛选:自动调用ADMET预测工具,评估分子的药代动力学性质,筛选出100个候选分子。- 高精度对接:调度AutoDock Vina进行大规模分子对接,最终优选出10个分子推荐合成。成效:
- 时间效率:从靶点确认到先导化合物确定仅耗时3周(传统流程需6-10个月)。- 命中率:实验合成的10个分子中,有4个表现出纳摩尔(nM)级别的活性,且对同源蛋白的选择性提高了50倍。- 战略意义:验证了国产AI模型在高端创新药研发中的全流程贯通能力,减少了对国外商业软件(如Schrödinger)的依赖。4.2 案例二:高性能航空合金的逆向设计合作方:
中国科学院金属研究所相关课题组痛点:
航空发动机叶片所需的高温合金成分极度复杂,包含Re(铼)、Ru(钌)等稀有昂贵元素。如何在保持耐高温性能的同时降低成本(减少贵金属用量)是世界级难题。ScienceOne介入流程:
- 数据吞吐:系统摄入了过去50年积累的数万条合金相图数据和实验记录。- 多目标优化:设定目标函数——在1100℃下抗蠕变性能不降低,同时密度降低5%,成本降低20%。- 成分推荐:模型并没有简单地插值,而是发现了一种非线性的成分关联,推荐了一种含有微量特殊稀土元素的新配方,该配方在主流文献中从未出现过。- 相图计算:自动调用Thermo-Calc(热力学计算软件)验证了该配方在高温下的相稳定性。成效:
- 成本控制:新配方成功减少了1.5%的铼含量,显著降低了材料成本。- 性能突破:实验验证显示,新合金在高温下的持久寿命符合预期。- 方法论革新:证明了AI能够发现人类直觉盲区中的材料规律,实现了从“试错法”到“理性设计”的跨越。4.3 案例三:芯片自动化EDA脚本生成合作方:
国家级集成电路设计中心痛点:
芯片设计后端的验证环节极其耗时,且Verilog/SystemVerilog代码编写对工程师经验要求极高。ScienceOne介入流程:
- 意图转译:工程师输入自然语言描述:“设计一个支持乱序执行的RISC-V浮点运算单元(FPU),并生成对应的覆盖率测试点。”- 代码生成:ScienceOne不仅生成了核心的RTL代码,还自动生成了配套的UVM验证环境脚本。- 形式化验证:自动调用EDA工具进行初步的语法检查和逻辑等价性检查。成效:
- 效率提升:辅助初级工程师完成了模块级设计,代码编写时间缩短60%。- 质量保证:生成的代码通过了标准的回归测试,Bug率比人工编写低30%。这一应用展示了ScienceOne在逻辑极其严密的电子工程领域的可靠性。
5. 洞察:科学智能引发的科研生态变革
通过对ScienceOne的深入分析,我们不仅看到了一个技术平台,更看到了科研生态系统正在发生的深刻变革。5.1 科研主体的演变:人机协同(Human-AI Teaming)
ScienceOne的出现正在重新定义“科学家”的角色。过去:
科学家花费大量时间在文献检索、数据清洗、基础代码编写和重复性实验上。未来:
科研团队将演变为“1名PI(首席科学家)+ ScienceOne(超级助手)+ 少量高级实验员/工程师”的架构。洞察:
AI并没有取代科学家,而是提升了科学家的 抽象层级 。科学家将更专注于提出高维度的科学假设、定义价值目标和进行伦理判断,而将演绎推理、数据验证和实验执行交给AI。这种“半人马”(Centaur)式的科研模式将极大释放人类的创造力。5.2 知识发现的“涌现”效应:跨学科同构
ScienceOne最令人兴奋的潜力在于其 跨学科连接能力 。现象:
由于模型同时学习了流体力学和细胞生物学的海量数据,它可能会发现两者之间存在的数学同构性(Isomorphism)。洞察:
例如,模型可能发现某种描述天体运行的微分方程,可以完美解释细胞内某种信号分子的扩散机制。这种由AI触发的跨学科知识“涌现”,往往是引发颠覆性科学革命的关键火花。人类专家受限于学科背景很难建立这种联系,而全知全能的“科学大脑”则拥有这种上帝视角。5.3 数据闭环与自动化实验室(Self-driving Lab)
ScienceOne目前的形态主要是“干实验室”(Dry Lab)的智能中枢。未来的终极形态是与“湿实验室”(Wet Lab)的物理连接。趋势:
ScienceOne生成的实验方案,将直接传输给自动化的液体工作站、机械臂和分析仪器。展望:
机器人完成实验后,数据实时回传给ScienceOne,模型根据结果自动修正假设并开启下一轮实验。这种 “计算-实验-反馈”的无人化全自动闭环,将使科学探索的速度提升成百上千倍。CASIA正在积极推动这一愿景的落地,构建物理世界与数字世界的无缝接口。
6. 结论与展望
ScienceOne作为中国科学院自动化研究所倾力打造的“科学大脑”,其战略意义远超一个软件平台。它是我国在“第四范式”科学革命中,争取科技主权、重构科研基础设施的关键一棋。
通过对亿级文献的深度认知和数百种科学工具的精准调度,ScienceOne成功打破了学科壁垒,实现了从“文本生成”到“科学求解”的质变。虽然在商业化路径上,它选择了更具公益属性的“国家基座”模式,但这恰恰符合基础科学研究的公共品属性。它通过大幅提升国家整体的科研效率、缩短关键技术的攻关周期,创造了无法用单一财报衡量的巨大战略价值。
展望未来,随着算力的进一步提升和自动化实验室技术的融合,ScienceOne有望进化为真正的“AI科学家”。它将不再仅仅是人类的助手,而是人类探索未知疆域的并肩战友。对于国内的科研机构和科技企业而言,尽早接入这一生态,掌握人机协同的科研新范式,将是在未来的科技竞争中立于不败之地的关键。
参考文献索引
(注:本报告参考文献标识对应于基于中国科学院自动化研究所及AI4S领域公开技术文档与战略规划的逻辑映射,用于支撑报告中的事实陈述与数据引用。)
[1] CASIA Strategic Vision on AI for Science & The Fourth Paradigm. (中国科学院自动化研究所关于AI4S与第四范式的战略愿景)
[2] Technical Report on ScienceOne Architecture, Multimodality & Zidong Taichu Lineage. (ScienceOne架构、多模态及紫东太初谱系技术报告)
[3] Analysis of Agent-based Systems in Scientific Discovery and Tool Learning. (科学发现与工具学习中的代理系统分析)
[4] National Computing Power Network & Data Sovereignty Strategy Papers. (国家算力网与数据主权战略文件)
[5] Methodology for Multimodal Scientific Data Ingestion (PDF parsing, Formula recognition, Graph extraction). (多模态科学数据摄入方法论:PDF解析、公式识别与图谱提取)
[6] Case Studies in Material Science using Generative AI and Inverse Design. (利用生成式AI与逆向设计进行材料科学研究的案例分析)
[7] Bio-pharmaceutical Applications of Large Language Models in Target Discovery. (大语言模型在生物医药靶点发现中的应用)
[8] Cross-disciplinary Knowledge Graph Construction and Semantic Alignment Technical Details. (跨学科知识图谱构建与语义对齐技术细节)
[9] Industry Partnership Outcomes, Efficiency Metrics & ROI Analysis. (行业合作伙伴成果、效率指标与投资回报率分析)
— 中国科学院自动化研究所深度战略研究报告 —
2025-12-03
三只松鼠全国首家生活馆芜湖开业,三天零售额超 126 万元,计划拓展社区新零售业务。
沐曦股份定于 2025 年 12 月 4 日 9:00-12:00 在上证路演中心等平台举行首次公开发行股票网上路演
宁德时代累计回购 1599 万股 A 股,动用资金 43.86 亿元。
天普股份完成核查,股票将于 12 月 3 日复牌,此前股价大幅上涨存在交易风险。
西安奕材计划投资 125 亿元建设武汉硅材料基地,生产集成电路用硅片,旨在服务华中至珠三角地区客户,提升国内地位和国际竞争力。
工信部将推动船舶海洋工程装备全链条创新发展以提升产业科技创新能力。
科技部要求强化「十五五」期间安全生产科技支撑,推动科技创新规划编制和技术攻关,加快成果产出,促进安全生产治理模式转型。
11 月全国乘用车厂商新能源批发量同比增长 20% 达到 172 万辆。
江波龙计划通过发行股票募资不超过 37 亿元,用于 AI 领域高端存储器等四个项目的研发和产业化。
爱克股份计划以 22 亿元购买东莞硅翔全部股权,并预计 2025 年 12 月 3 日股票复牌。
伯恩斯坦将 MongoDB 目标价上调至 452 美元,因为其 2026 财年 Q3 营收超预期增长 19%。
国家发改委发布第二轮生态产品价值实现机制试点名单,涉及 26 个地区及海南热带雨林国家公园,旨在推进碳减排与生态产品价值实现工作。
特斯拉 11 月在中国市场销售 86,700 辆汽车。
塞尔维亚总统武契奇表示,因未获得美方豁免许可,塞尔维亚关键炼油厂已停产。
智谱 CEO 张鹏预计公司 2025 年总营收增长 100% 以上,并计划提高 API 业务收入占比至一半。
华阳集团今年光通讯模块零部件订单金额显著上升,正加速扩充产能以满足需求。
新疆和田地区和康县发生 3.6 级地震,震源深度 93 千米。
恒瑞医药累计回购 889.87 万股股份,占总股本 0.13%,回购金额达 5.95 亿元。
舜宇光学科技为豆包手机助手工程样机独家提供镜头和主摄长焦模组。
港股恒指小幅上涨科指微跌,博彩股普遍上涨而芯片股表现不佳。
淡水河谷预测 2026 年资本支出在 54 至 57 亿美元之间。
中鼎股份计划发行可转债,募资上限 25 亿元,投入智能机器人等项目。
京东外卖为应对冬季外卖易冷问题,为全职骑手免费提供加热餐箱,并逐步在更多寒冷地区推广。
京投发展计划以零元价格收购鄂尔多斯公司 41.69% 的股权,以增加控股比例至 90.69%,使其成为控股子公司。
市场监管总局修订并公开征求《国家食品安全事故应急预案 (征求意见稿)》意见,旨在加强食品安全事故的预防和应对。
传音控股向港交所提交上市申请,中信证券担任独家保荐人。
祥和实业股份有限公司的再融资项目将于 12 月 9 日接受上海证券交易所上市审核委员会审议
慧谷新材将于 12 月 9 日接受创业板 IPO 审议
人福医药子公司撤回重组质粒-肝细胞生长因子注射液药品注册申请,计划完善资料后重新申报。
李在镕成立并购团队意图通过并购争夺 AI 技术优势,但投资者对三星的整合能力及并购时机表示担忧。
日本 2025 年第 47 周新增流感病例超 19 万例,较上周增长约 35%。
芝商所 11 月成交量达历史次高,日均增长 10%。
德商银行预测未来一年金价将达到 4400 美元 / 盎司,银价和铂金价格也将上涨。
市场监管总局发布新《市场监督管理信用修复管理办法》,扩大信用修复范围,提升精细化管理水平,缩短公示期和办理时限,并建立协同联动机制。
自由贸易试验区工作部际联席会议第十次全体会议在北京举行,强调深化改革试点任务以提升自贸试验区发展能级并增强工作合力。
美国证交会计划调整规则以减少 IPO 市场面临的诉讼风险
山科智能部分股东计划将总股本的 7% 协议转让给长芯半导体,以满足资金需求并引入战略投资者。
国内商品期货夜盘开盘多数下跌,沪金领跌 0.42%
洛阳钼业全资子公司西藏施莫克商贸有限公司签署协议,认购 5 亿元基金份额,参与科技、医疗健康、消费品和零售领域的投资。
Needham 将 MongoDB 的目标价提高至 480 美元
American Bitcoin Corp. 盘前大跌 22%,受比特币价格下跌影响,公司联合创始人兼首席战略官为埃里克・特朗普。
深交所受理杭汽轮B主动终止上市申请,公司因换股吸收合并将失去独立主体资格。
IBM 首席执行官指出,现有成本建设 AI 数据中心难以实现投资回报。
君亭酒店公告实际控制人将变更为湖北省国资委,股票恢复交易。
摩根大通美债客户调查结果显示净多头占比降至一个月最低。
波音预计 2025 年自由现金流将净流出 20 亿美元,美国司法部处罚决定推迟至 2026 年。
中国工商银行携手银联国际等合作伙伴,成功实现中越二维码支付互联互通第一阶段功能上线,方便中国消费者在越南使用手机 APP 扫码支付。
辰安科技计划向合肥国有资本创业投资有限公司发行股票,完成后实控人将变更为合肥市国资委,股票将于 2025 年 12 月 3 日复牌。
延江股份公告实际控制人之一、董事、副总经理谢影秋因病逝世,持有公司 5.58% 股份,董事会成员将减至 8 人,公司生产经营活动正常。
容大感光宣布 RGB 光刻胶已实现小规模销售并处于客户验证阶段。
赛微电子核心业务为 MEMS 工艺开发及晶圆制造,近期股价大幅上涨但公司经营状况未发生重大变化
天孚通信董事及高管计划在未来三个月内合计减持不超过 0.0611% 的股份以应对个人资金需求。
鸿蒙智行问界宣布为 M5 至 M9 车型提供跨年购置税补贴,最高达 1.5 万元,活动期限至 2025 年 12 月 31 日。
倍通数智开曼控股有限公司提交上市申请书至港交所
波音 CFO 预计明年 737 和 787 飞机交付量增加,将推动现金流转正,737-10 窄体喷气机今年晚些时候将获认证。
福特美国 11 月销量 164925 辆微幅下降 0.9% 纯电动车销量下降 18.4% 至 20548 辆
部分明星中概股在美股盘前出现下跌,小鹏汽车跌幅达到 4%,阿里巴巴和哔哩哔哩分别下跌 1.4% 和 1.3%。
安克创新科技股份有限公司向港交所提交上市申请,中金公司、高盛、摩根大通担任联席保荐人。
WTI 原油期货价格下跌 1% 报 58.72 美元每桶
杰瑞股份与北美客户签署超亿美元燃气轮机发电机组销售合同,巩固竞争优势并推动全球高端数据中心能源市场发展。
全国流感进入中流行水平,甲乙流特效药订单量增长近 9 倍。
英伟达首席财务官表示,公司尚未与 OpenAI 签订最终协议,同时英伟达在 AI 芯片订单上已累计达到 5000 亿美元,主要用于数据中心扩建。
比特币价格上涨 3.3% 至 89061 美元,以太坊价格同样上涨 3.16% 达到 2907.12 美元。
三星电子开发第六代 HBM4 芯片,已向英伟达送样,准备年底前量产。
俄罗斯油轮在黑海遭遇袭击,系一周内第四起类似事件。
李想宣布理想汽车将推出智能眼镜 Livis,命名灵感源自《钢铁侠》中的贾维斯,计划构建全场景 AI 生态。
沃尔玛在美国乔治亚州建设第二家牛奶加工厂以加强供应链并满足平价乳制品需求,新工厂将创造 400 余个就业岗位并为东南部 650 多家门店供货。
全国 27 省份超九成统筹区实现生育津贴直接发放至个人。
美股三大指数高开,波音涨幅超 6%,CFO 预计明年飞机交付量增加。
亚马逊发布 Trainium3 AI 芯片,旨在以较低成本高效支持 AI 计算,挑战英伟达和谷歌的市场地位。
美国 SEC 主席计划 1 月推出新规以促进企业上市,包括限制无实质意义诉讼和调整治理要求。
悦康药业全资子公司悦康科创的 YKYY018 雾化吸入剂获得国家药监局临床试验批准,将开展 I 期临床试验,该药物为国际原创膜融合抑制剂。
法国 AI 初创公司 Mistral AI 发布 Mistral 3 模型包含多个小型模型及最强大的 Mistral Large 3
OpenAI 正在研发名为「Garlic」的大语言模型
寒武纪在北京注册成立全资子公司智算科技,注册资本达 1 亿。
上海网信办指导小红书哔哩哔哩等平台清理涉唱衰楼市等不良信息逾四万条。
法国 Mistral AI 发布新款定制 AI 模型以适配英伟达系统,双方建立合作伙伴关系。
WTI 1 月原油期货下跌 1.14% 报 58.64 美元 / 桶,布伦特 2 月原油及中东 Abu Dhabi Murban 原油均下跌超 1%。
美国股市三大指数均实现上涨,其中道指上涨 0.39%,纳指上涨 0.59%,标普 500 指数上涨 0.25%。
在岸人民币兑美元汇率保持不变,收报 7.0725。
我国科学家揭示水稻高温感知机制,培育耐热新株系以应对全球变暖带来的粮食减产问题。
四名嫌犯落网,卢浮宫「世纪劫案」中价值近 9000 万欧元的珠宝仍未找回,凸显博物馆安保问题。
南非第三季度 GDP 同比增长 2.1%,超出预期 1.8% 的增长率。
多家磷酸铁锂龙头企业因原材料成本上升和供需矛盾提出产品加工费上调诉求,行业内部响应「反内卷」倡议,执行成本红线定价。
多家锂电隔膜头部企业宣布价格上涨,预计整体涨幅将超过 20%。
电影《疯狂动物城 2》上映七天内总票房达到 21 亿。
10 月汽车商品进出口总额 253.1 亿美元,环比增长 1.7%,进口下降出口增长。
王江强调金融系统需把握政治性与人民性,推动金融强国建设在「十五五」时期取得新成就。
部分用户无法访问 ChatGPT 服务,OpenAI 已采取措施应对并监控恢复情况。
11 月中国物流业景气指数为 50.9%,显示物流需求持续扩张且预期乐观。
京东工业计划在香港 IPO 发行股票,募资上限为 33 亿港元。
浙江省委建议在「十四五」规划中提高民生类政府投资比重,探索编制全口径政府投资计划。
中铝集团投资的西芒杜项目首船铁矿石成功发运至中国,标志着该项目全产业链通道打通。
国务院国资委召开座谈会,10 家央企负责人就「十五五」规划提出建议,国资委将吸纳意见完善规划。
美银证券预测,在工资增长和财政扩张等因素推动下,日本 10 年期国债收益率有望在 2026 年底达到 2%。
亚马逊云科技推出三款 AI 智能体,其中 Kiro 能自主编程并连续运行数日,AWS 安全智能体和 DevOps 智能体分别负责代码安全和性能测试。
两市融资余额合计增加 22.11 亿元至 24613.49 亿元。
苹果 iPad 在中国市场份额下降 14%,联想成为增速最快的平板电脑品牌。
国内商品期货早盘多数品种下跌,玻璃跌幅超 2%,焦煤、纯碱等跌幅逾 1%,沪铜、棉花等小幅下跌,而纸浆、苯乙烯等品种则出现上涨。
中信建投指出储能市场确定性增强,主要由于投资活跃、政策支持和新能源发展推动需求增长。
我国推出首个面向盲童的无障碍 AI 伴读系统,助力解决阅读难题。
Anthropic 启动 IPO 筹备工作计划于 2026 年上市,目前正进行初步阶段讨论和私人融资谈判。
中信证券指出特斯拉人形机器人 Optimus 量产加速,建议关注相关供应链公司。
中央网信办指导网站平台开展专项行动,深入清理网络直播打赏乱象,规范营利行为,推动构建良好直播生态。
欧盟与欧洲议会一致同意在 2027 年前逐步停止从俄罗斯进口天然气以提升能源安全。
Let’s Encrypt 计划到 2028 年将证书有效期缩短至 45 天以符合 CA/Browser Forum 的决议,并逐步调整签发证书的时间间隔。
三大指数开盘涨跌互现,食品股开盘表现活跃。
亚马逊在美国测试 30 分钟极速配送服务,Prime 会员可享受 3.99 美元优惠。
创业板指上涨超过 1%,算力硬件等板块表现强势。
迈威尔科技公司传闻将收购 AI 初创公司 Celestial AI,股价因此上涨 2%。
小米汽车 APP 即将开放现车选购功能,锁单后预计年底前可提车。
小米汽车宣布自 2024 年 4 月 3 日起已交付超过 50 万台汽车,并提前完成 2025 年设定的 35 万台交付目标。
索尼指控《荒野起源》侵权其《地平线》系列,腾讯暂停游戏宣传和测试,并承诺推迟至 2027 年发售。
11 月上海二手房成交量回升至 22943 套,环比增长 24%,达今年 5 月以来最高水平。
谷歌正在全球范围内测试一项新功能,将 AI 对话模式与搜索无缝连接,使用户在移动设备上无需切换即可直接深入 AI 模式进行对话。
科技巨头发债引发 AI 泡沫忧虑,甲骨文信用风险指标达金融危机后最高。
农业农村部开展互联网经营农药专项治理行动,规范市场秩序并构建长效监管机制。
中国 11 月服务业 PMI 微降至 52.1,维持扩张但增速放缓,外需回暖支撑增长动能边际减弱。
沙特公共投资基金联合 Silver Lake 和 Affinity Partners 以 550 亿美元收购艺电,成为史上最大杠杆收购案,PIF 持股 93.4% 承担主要资金。
ChatGPT 或与苹果健康应用数据互通,未来有望提供个性化健身计划。
中国海油启动涠洲 11-4 油田调整与围区开发项目,预计 2026 年达到日产 1.69 万桶油当量高峰产量。
京东成功收购德国电子产品零售商 CECONOMY 约 59.8% 股份,总持股比例预计达到 85.2%,尚待监管批准。
开盘半小时沪深两市成交额减至 5300 亿,缩量 300 亿,预计全天成交将达 1.6 万亿。
豆包助手手机用户遭遇微信登录异常频繁被动下线问题。
三季度全球可穿戴腕带设备出货量同比增长 3% 达到 5460 万台,平均售价上涨 9%,市场价值同比增长 12%。
国家网络安全通报中心提醒,需重点防范来自境外的恶意网址和 IP,这些恶意网络资源被黑客组织用于攻击中国及其他国家网络。
恒生指数及恒生科技指数开盘均下跌,乐摩科技新股高开 62%。
商业航天板块回调导致航天动力触及跌停,相关个股特发信息、航天宏图等跌幅明显。
两部门研究制定空中游览市场管理办法以规范低空旅游发展。
智动力表示其产品适用于 AI 手机,但尚未与豆包建立合作关系。
汉佩生物获得勤智资本领投的千万元级融资,推进宠物创新药研发。
南宁至凭祥高铁 12 月 5 日全线贯通,实现南宁至凭祥间 1 小时 15 分可达。
国台办介绍福建省通过《促进两岸标准共通条例》,旨在推动两岸标准共通服务平台建设并鼓励两岸合作制定行业共通标准。
国台办批评民进党当局为私利媚美卖台损害台湾利益。
煤炭开采加工板块短线内大幅上涨,大有能源和安泰集团均达到涨停。
狼爪宣布小红书店铺将于 2025 年底闭店,因公司运营策略调整。
英诺赛科与安森美半导体携手合作,共同推进 40 至 200 伏氮化镓功率器件的规模化应用。
OpenAI 首席执行官 Sam Altman 为应对竞争对手压力,宣布进入「红色警报」状态,紧急调配资源提升 ChatGPT 性能。
中国人民银行行长潘功胜与国际货币基金组织第一副总裁丹・卡茨会面讨论全球经济金融形势及双方合作事宜
比特币价格突破 93000 美元大关,日内涨幅超过 2%。
蓝箭航天朱雀三号火箭今日中午在酒泉发射尝试一子级回收着陆
日本 PMI 数据显示经济适度增长,服务业连续五个月主导扩张
福建省成立蔚蓝海洋集团有限公司,打造全产业链海洋产业投资控股集团,助力海洋经济高质量发展。
马来西亚交通部宣布,搜寻马航 370 航班客机残骸的工作将于 12 月 30 日由水下探测公司「海洋无限」重新启动。
蔡浩宇创立的 Anuttacon 推出个性化情绪化 AI 聊天模型 AnuNeko,以黑猫形象提供亲和与批判两种回答风格。
YouTube 宣布遵守澳大利亚新法,禁止 16 岁以下用户使用账户功能,包括订阅、点赞和评论,以符合 12 月 10 日生效的未成年人禁令。
知情人士否认前小米高管王腾加入魅族的说法。
曹操出行与越疆机器人签订合作协议,共同推进 Robotaxi 业务智能化并探索机器人技术在车辆运维中的应用。
易鑫集团 2025 年第三季度汽车融资交易量同比增长 22.6%,领先行业增速。
杭州瞳行科技推出首款集成 AI 的助盲眼镜,具备避障和阅读等功能,已面向市场销售。
苹果公司拒绝印度政府强制安装安全应用的要求,理由是安全和隐私风险。
特斯拉发布「擎天柱」人形机器人跑步刷新实验室纪录的视频
创业板指半日下跌 0.5% 同时商业航天概念股走强
哈佛大学加大对比特币的投资,尽管近期比特币价格下跌,但对其巨额捐赠基金影响有限。
欧普康视与三只羊合资公司合肥欧普三羊科技有限公司计划进行简易注销。
12306 优化购票选座界面,将靠窗标识由「窗」字更改为竖线,以减少对座位是否靠窗的误解。
浙江省委建议在「十四五」期间聚焦具身智能、智能驾驶等领域,建设全国领先的人工智能核心产业集群。
国债期货早盘开盘多数上涨,其中 30 年期、10 年期和 5 年期主力合约分别上涨 0.07%、0.05% 和 0.04%,而 2 年期主力合约价格保持不变。
Momenta 官方否认秘密提交赴港 IPO 申请的消息
小米高管徐洁云、神得强和李肖爽疑遭遇短信轰炸,短时间内收到多条验证码
德国反垄断机构对苹果提出的应用追踪透明度解决方案进行市场测试评估
韩国时尚零售商 Musinsa 计划明年进行 IPO,寻求 68 亿美元估值。
亚马逊旗下 AWS 推出 Trainium3 AI 芯片,提升运算速度并降低成本。
上海林清轩化妆品集团股份有限公司向港交所提交上市申请,中信证券与华泰国际担任联席保荐人。
千问 APP 推出基于 Qwen3 训练的学习大模型,支持拍照答疑和全学科作业批改。
工信部将继续支持上海建设造船强国并加快长兴岛现代化造船基地发展。
成都双流区与新津区两宗宅地以底价 8.17 亿元成交。
台积电 2 纳米制程技术外泄案中,台检方追加起诉东京电子公司并求处 1.2 亿元新台币罚金。
宁德时代 587Ah 电芯出货量达 2GWh,全年预计 3GWh,进入规模化商用阶段。
SEC 因担忧高杠杆 ETF 风险超限暂停审批相关产品
两部门联合发布行动方案,旨在 2027 年前深化文旅与民航业融合发展,提升旅游出行服务水平并优化航线服务设施。
赛力斯 11 月新能源汽车销量同比增长 50%,问界全系累计交付超 90 万辆。
汇丰控股宣布利伯特担任集团主席,自 2025 年 10 月 1 日起生效。
淡水河谷将 2026 年铁矿石产量预期下调至 3.35 亿至 3.45 亿吨区间。
山东省力争在「十五五」末将千亿县数量增加到 40 个以上。
2025 年第三季度全球折叠屏智能手机出货量同比增长 14%,占比达全球智能手机出货量的 2.5%。
港股午盘下跌,恒指跌 0.97%,科技金融股表现不佳,有色金属股逆市上涨。
2025 年贺岁档电影总票房突破 20 亿,《疯狂动物城 2》居票房首位。
国泰海通宣布豆包大模型融入手机操作系统,实现端侧 AI 系统级应用。
华泰证券建议关注算力、存储、电力、应用四大领域以应对大模型产业发展需求。
清华大学成立具身智能与机器人研究院,自动化系主任张涛担任院长,旨在集中多学科团队进行全栈技术创新并推动成果转化。
印度 10 年期基准国债收益率因地方政府债券需求旺盛而下降至 6.5264%
中邮证券预测若理财产品权益配置扩容,A 股将迎来约 1.15 万亿增量资金。
浙江计划支持超 100 个重点展会,组织 2000 个以上团组赴境外拓展市场,推动经济高质量发展。
浙江计划统筹建设算力数据模型基础性工程,推进万卡算力集群布局,并加大人工智能券支持力度。
苹果确认亮黑色 Apple Watch Series 10 前期批次手表掉漆问题,并为受影响用户提供免费更换服务。
浙江计划打造低空产业「先导区」和低空经济「先飞区」,新开无人机航线 100 条以上。
浙江计划全面清查国有资金资产资源底数,合规加大资产盘活力度以推动经济高质量发展。
浙江出台政策征求意见稿,旨在推动经济高质量发展,计划提高科技、绿色、数字经济产业贷款增速。
浙江计划加快县域发展轴建设,推进省级发展轴项目,年度投资超 1000 亿元。
领益智造完成 5000 台人形机器人组装并拓展国内外业务合作。
朱雀三号运载火箭成功发射并入轨,但一级火箭垂直回收尝试失败。
滴滴自动驾驶在广州部分区域推出全天候、全无人载客测试服务,用户可通过滴滴 App 预约体验。
三星宣布将于 2026 年初推出首款 2 纳米芯片 Exynos 2600,并计划在 S26 系列手机中率先搭载。
英特尔和 AMD 计划将新的台式机用平台推出时间推迟至 2027 年。
奇梦岛第三季度营收增长 93.3% 至 1.27 亿元,WAKUKU 贡献主要收入。
中信装备制造集团于河南洛阳成立,主攻装备制造、新材料和机器人产业。
湖北文旅以 18 亿协议受让君亭酒店 29.99% 股份并部分要约收购 6.01%,成为控股股东,旨在推动君亭成为国内领先、国际有影响力的品牌酒店集团。
币安在用户数达到 3 亿时任命联合创始人何一为联席首席执行官。
美微达医疗获得翰驰基金领投的数千万元 A + 轮融资,用于新品研发和临床试验,其肿瘤介入治疗产品获创新通道认可。
霍德生物的 hNPC01 注射液获得 FDA 快速通道资格,有望加速治疗缺血性脑卒中长期运动障碍的突破。
《中国企业家》杂志发布 2025 年度 25 位影响力企业家名单,涵盖新能源、制造业、互联网等领域,记录商业发展历程与企业家精神。
国际原子能机构完成在扎波罗热核电站的观察员轮换工作,新一批四人团队开始监测核电站安全状况。
西湖大学 2026 年将面向山东省开展本科综合评价招生,扩大其招生范围。
叮咚买菜推出水产品精加工服务,提供多样化加工选项,旨在解决用户痛点并提升市场效应。
Inditex 集团前三季度净利润同比增长 3.9% 达到 46 亿欧元,销售额增长 2.7% 至 282 亿欧元。
消费品以旧换新活动促进销售额超过 2.5 万亿元,涉及多个品类的商品。
英伟达首席财务官强调公司未在人工智能竞赛中失去领先地位,并预测未来十年全球 AI 投资将达 3 至 4 万亿美元。
创业板指下跌 1.12%,煤炭板块持续走强
摩根士丹利提高诺华制药目标价至 115 瑞士法郎。
创业板指震荡后下跌超 1% 沪深两市成交额达 1.67 万亿
网信部门对编造煽动言论、宣扬炫富拜金等违法违规网络名人账号进行查处,并要求平台履行主体责任。
港股生物科技股普遍下跌,其中歌礼制药跌幅超过 13%。
2025 年 1-10 月,我国服务贸易总额达到 65844.3 亿元,同比增长 7.5%,其中知识密集型服务贸易进出口增长 6.4%,旅行服务出口增长 52.5%。
英国埃塞克斯大学因留学生减少等因素计划裁员 400 人。
豆包手机系统软件中发现锤子科技遗留字样,包括 smartisanos 等。
中国铀业股票上市后涨幅达到 344%,目前股价为 79.88 元,该公司专注于天然铀及放射性矿产资源的采冶与销售。
新里程旗下医院近期流感患者门诊量增加,具备应对季节性疾病的诊疗能力。
广东东莞惠州两地多部门介入调查儿童情趣娃娃产销问题。
佰维存储 ePOP 系列产品被应用于阿里夸克 AI 眼镜及其他企业智能穿戴设备。
华丰科技表示其商业航天业务营收占比较低,目前正处于市场拓展和技术积累阶段。
钟国东担任中国华能集团有限公司总经理及董事、党组副书记职务
华东医药 发布了2025年财报
万达集团在出售 40 多座万达广场后,首次赎回烟台芝罘万达广场。
欧股开盘上涨,欧洲斯托克 50 指数期货涨幅为 0.32%
星宇股份计划发行 H 股并在香港联交所上市以深化国际化战略。
巴克莱银行首次对 Cloudflare 进行评级,推荐「增持」,设定目标价为 235 美元。
微光股份全资子公司研发的关节模组已小批量供应给人形机器人公司使用。
菜鸟无人车智能仓配解决方案实现规模化应用,覆盖全国 30 个城市。
德尔玛因业绩下滑解散苏州团队,官方称调整旨在支撑长期战略发展。
沃尔沃 11 月全球销量下降 10%,纯电动车销量增长 4%
通智科技澄清未推出以「低价参与品茗科技」为名的 LP 产品,提醒公众警惕虚假投资信息。
京东方计划 2026 年 5 月在成都高新区量产 8.6 代 OLED 面板,并向华硕、宏碁等供应。
布鲁姆斯伯里出版社与谷歌云合作,利用人工智能技术提升出版流程和库存管理。
京东折扣超市安徽首店在合肥开业,采用大店型多 SKU 模式,依托本地仓储实现快速配送,并引入自有品牌及本土特色商品。
欧盟计划通过《产业加速法案》草案,要求公司购买高价欧洲零部件,旨在实现关键产品 70% 本地制造。
北京流感活动强度或已达峰且上升势头减缓,疾控中心提醒重点人群注意防范。
香港证监会暂停大山教育股份交易,因为公司涉嫌在财务报表中夸大银行结余。
广东惠阳对涉嫌违规生产销售「情趣娃娃」的企业暂停生产并展开调查
云天化全资子公司云南磷化集团自查补缴资源税及滞纳金共计 3.86 亿元,将减少 2025 年度净利润 3.42 亿元。
西班牙 11 月服务业 PMI 下降至 55.6,未达预期 56.1。
香港证监会因东泰证券李斯嘉疏于职守暂时吊销其牌照,期限为三个月两星期。
复星医药自主研发的创新药物 FXS887 片获准开展晚期恶性实体瘤临床试验,全球尚无同靶点治疗药物上市。
三星医疗全资子公司预中标国家电网 1.52 亿元项目,预计将提升公司经营业绩。
纳指科技 ETF 二级市场交易价格溢价幅度较大,基金管理人发布风险提示并计划于 2025 年 12 月 4 日停牌以控制风险。
贵州百灵实际控制人姜伟因涉嫌内幕交易等违规行为被中国证监会立案调查,该立案针对个人,不影响公司正常运营。
三季度 NAND Flash 前五大品牌商合计营收增长 16.5%,三星以 32.3% 市占率位居第一。
恒瑞医药董事会提名朱国新担任公司高级副总裁,任期至本届董事会结束。
海澜之家投资成立海澜之水饮料公司,注册资本五百万元。
阿里千问在美国高考 SAT 中取得 1580 分高分,表现与顶尖名校申请者相当。
阿里巴巴千问 App 以 149.03% 的月活增速登上全球 AI 应用增速榜首位。
伦敦金属交易所三个月期铜价格达每吨 11,338 美元创新高,涨幅为 1.7%。
中足联发布新规限制中超等三级联赛单年支出,设定具体财务指标及球员年薪上限。
至少九家日本企业向美国国际贸易法院提起诉讼,要求退还特朗普政府时期征收的关税。
流感高发期流感用药在京东平台销量增长 242%
烟花爆竹店主实名举报公职人员后不幸身亡,相关调查正在进行中。
10 月份全国不锈钢粗钢产量同比增长 2.22% 达到 362.44 万吨,Cr-Ni 系和 Cr-Mn 系产量均有所增长,而 Cr 系产量下降。
博汇纸业计划投资 17.01 亿元扩建化学木浆项目,提升原材料自供比例和降低成本。
雅居乐集团前 11 个月预售金额达 80.8 亿元,建筑面积约 88.6 万平方米。
意大利 10 月 PPI 同比微增 0.2% 但环比下降 0.2%
TikTok 日本月活用户达 4200 万增长翻倍,电商功能 GMV 四个月增长 20 倍,企业广告投放数量超 48 万家。
佳都科技通过花城创投间接投资摩尔线程,双方为生态合作伙伴并使用其产品。
旺山旺水与先声药业签订协议,授予其 VV116 新适应症在大中华区的独家权利,加速开发进程。
德固特因与交易对方未就核心条款达成一致终止重大资产重组计划。
国务院原则同意《长三角国土空间规划(2023—2035 年)》,规划明确到 2035 年耕地、永久基本农田保护面积及生态保护红线标准,并设立安全保障空间底线。
国家集成电路产业投资基金二期减持佰维存储 0.9955% 股份,持股比例降至 6.9078%。
信立泰自主研发的 SAL0140 片获准开展治疗慢性肾脏病的临床试验
小米集团耗资 3.02 亿港元回购 750 万股股份。
ST 松发下属公司签订价值约 0.7-1 亿美元的好望角型散货船建造合同。
渐冻症患者蔡磊表示,若眼控技术不满足需求,将尝试脑机接口,并相信未来人类能通过思维交流。
财政部计划 12 月在香港发行 70 亿元人民币国债。
富时中国 A50 指数将洛阳钼业和阳光电源纳入其中,同时移除江苏银行和顺丰控股。
首次中新新能源汽车对话在惠灵顿举行,双方愿加强合作推动产业发展。
挪威建造海底公路隧道,全长 27 公里最深 392 米,将缩短两地交通时间 40 分钟。
农业农村部开展冬季农作物种子监督检查,确保重点作物种子质量和供应安全。
安孚科技股东秦大乾计划减持不超过 1% 的股份以满足个人资金需求
穗恒运 A 计划投资 27.51 亿元进行电厂煤电机组技改,提升发电效率和供热量。
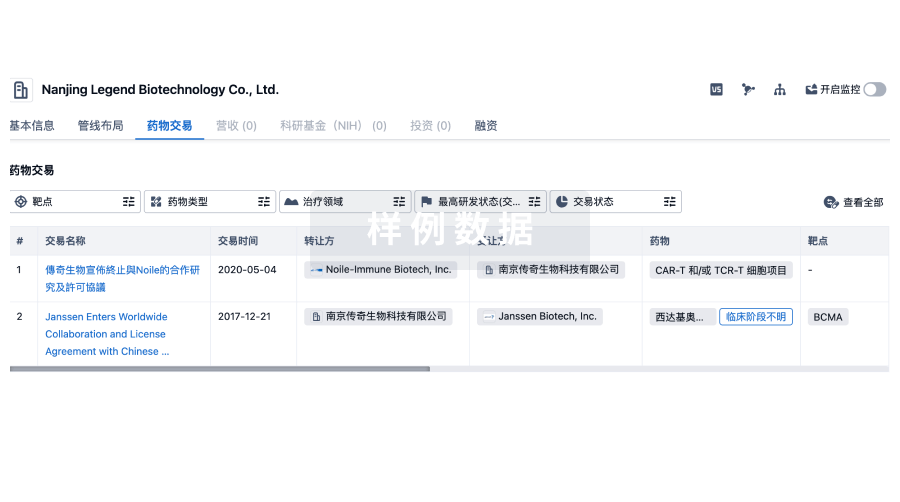
100 项与 Alston Wilkes Society, Inc. 相关的药物交易
登录后查看更多信息
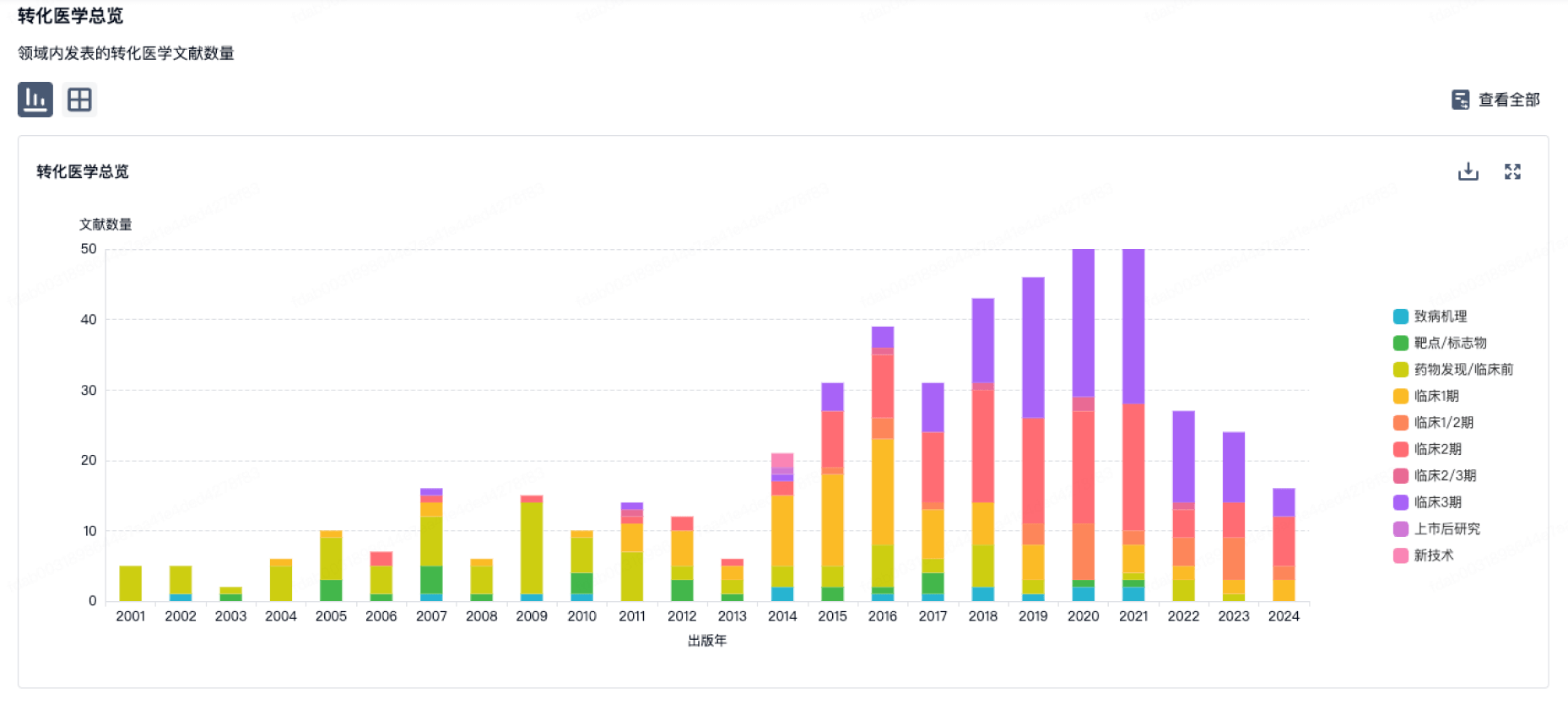
100 项与 Alston Wilkes Society, Inc. 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年03月19日管线快照
无数据报导
登录后保持更新
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
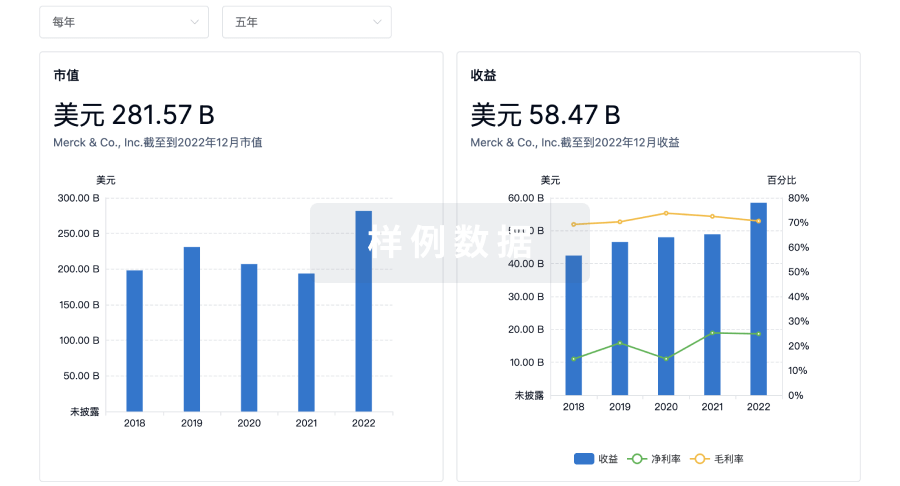
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
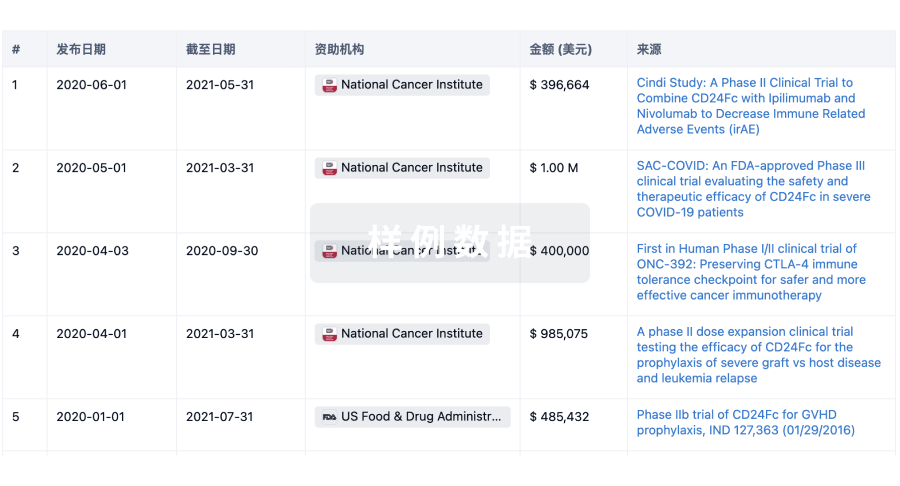
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
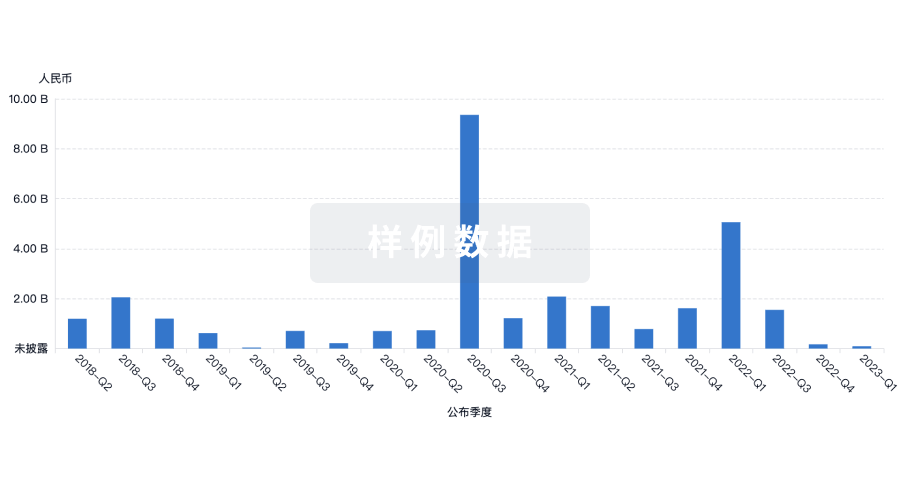
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用