预约演示
更新于:2026-01-28
Beijing Information Science & Technology University
更新于:2026-01-28
概览
关联
100 项与 北京信息科技大学 相关的临床结果
登录后查看更多信息
0 项与 北京信息科技大学 相关的专利(医药)
登录后查看更多信息
1,298
项与 北京信息科技大学 相关的文献(医药)2026-05-01·NEURAL NETWORKS
Coherent optical neural network chip with novel computing model for large-scale matrix-vector multiplication
Article
作者: Zhang, Yejin ; Pan, Jiaoqing ; Pan, Jingshan ; Zhang, Ye ; Guo, Meng ; Zhang, Jinyu ; Yu, Lei ; Raikov, Aleksandr
In this work, an innovative optical neural network (ONN) chip based on the coherent detection structure has been proposed. By establishing a mathematical model, the approach eliminates the need for phase compensation while reducing the encoding and decoding process by integrating the transformation function into the activation function. This improves the computing efficiency while maintaining high accuracy. The performance of the chip has been evaluated across multiple image classification datasets, with its accuracy on the MNIST dataset reaching 97.28 %, comparable to the results run by a computer. Furthermore, the design demonstrates strong robustness and generalizability accommodating diverse network architectures ranging from single-hidden-layer networks to more complex multi-hidden-layer configurations.
2026-01-13·ENVIRONMENTAL SCIENCE & TECHNOLOGY
Leveraging LLMs for Environmental Complexity: Structured Fine-Tuning Data Sets and Deployment Strategies
Article
作者: Xu, Changqing ; Chen, Chuke ; Guo, Jing ; Chang, Huimin ; Shi, Wenjie ; Xu, Ming ; Yuan, Jiayi ; Yang, Hang ; Qi, Jianchuan ; Li, Nan ; Xie, Jinliang
Generative artificial intelligence, especially large language models (LLMs), could accelerate environmental analysis, but deployment is hindered by two gaps: limited structured domain knowledge and unclear strategies matched to environmental decision contexts. Here, this study constructs a textbook-based, China-centered environmental knowledge data set with hierarchical organization to enable reliable fine-tuning and benchmarking. Results show a consistent trade-off that fine-tuned models achieve modest gains in precision (+1%) and response efficiency (+52%) on standardized tasks but exhibit limited adaptability when embedded in agentic workflows (-3%). In contrast, state-of-the-art generalist models consistently outperform in system-level sustainability and interdisciplinary decision tasks (+10%), benefiting from stronger cross-domain reasoning and dynamic tool integration. Together, these findings support a layered LLMs' deployment strategy for environmental intelligence. Specifically, selective fine-tuning for stable, regulatory, and verification tasks, combined with agentic workflows anchored in up-to-date generalist backbone models for dynamic, data-intensive, and interdisciplinary decision-making. This work provides both a reusable data set foundation and a practical framework for deploying LLMs as scalable and reliable decision-support tools in environmental decision.
2026-01-01·Biomaterials advances
Chiral petal honeycomb metamaterial structures: Biomimetic design and application in vascular stents
Article
作者: Zhang, Junhua ; Yao, Minghui ; Geng, Wen
Auxetic structure has a very good application prospect in biomedical engineering as implant and stent design, but this scenario faces the difficulty of synergistic optimization of multiple performance indexes. This paper aims to break through this dilemma through innovative design concepts and methods. The study integrates bio-morphology and engineering biomimicry to design a chiral petal-type honeycomb structure by extracting the cross symmetry of cruciferous plant petals and the mechanical properties of wind turbine blades. The whole process framework of "bio-morphological feature extraction-parametric modeling -- multi-objective optimization -- application" is constructed. The neural network model is used to carry out multi-objective prediction, parameter sensitivity analysis, and structure optimization with the help of differential evolutionary algorithm. It is found that the designed structure greatly improves the adjustable range of negative Poisson's ratio, and at the same time, a smaller value of the chiral parameter la4 can make the structure improve the load carrying capacity in the elastic phase. Simulation of the balloon-expandable stent-vessel coupling process shows that the chiral petal-type cellular stent has outstanding advantages in reducing the stenosis rate maintaining the structural stability and dispersing the stress in the vessel wall among the three cellular structures. This study provides innovative technological solutions for medical device design, and is expected to promote the translation of metamaterial honeycomb structures from theoretical research to practical applications in the field of biomedical engineering, pointing out the direction of focusing on the optimization of key parameters and expanding the clinical applications for subsequent studies.
3
项与 北京信息科技大学 相关的新闻(医药)2025-05-25
京医保中心发〔2025〕7号
各区医疗保障经办机构,各有关定点医药机构:
为加强我市医疗保障定点医药机构协议管理工作,根据《北京市医疗保障局关于印发〈北京市医疗机构医疗保障定点管理暂行办法〉的通知》(京医保发〔2021〕30号)和《北京市医疗保障局关于印发〈北京市零售药店医疗保障定点管理暂行办法〉的通知》(京医保发〔2021〕31号)等文件有关规定,经市、区医保经办机构审核,现决定对定点医药机构协议管理的有关事项予以动态调整。
一、新增定点
北京市海淀区东升镇文晟家园社区卫生服务站等11家医药机构已具备为参保人员提供医保服务的条件,符合新增定点医药机构的相关规定,现决定将上述11家医药机构纳入北京市医疗保障定点医药机构协议管理,签订定点医药机构医疗保障服务协议(以下简称:协议)(见附件1)。
请相关医保经办机构督促上述医药机构及时签订协议,签订协议后,要认真执行北京市医疗保障规定,落实协议的各项条款,切实为参保人员提供规范、优质、便捷的服务。
二、信息变更
首都医科大学附属北京口腔医院等27家家定点医药机构申请信息变更,经市、区医保经办机构审核,现决定对上述27家定点医药机构有关信息予以变更(见附件2)。
三、中止协议
中铁十六局集团有限公司总部事务服务管理中心门诊部等6家定点医药机构因不能继续为参保人员提供服务,申请中止协议,经市、区医保经办机构审核,现决定对上述6家定点医药机构中止协议(见附件3)。
中止协议后,上述定点医药机构将不再承担医疗保障任务,参保人员在上述医药机构发生的费用医疗保障基金不予支付。
四、解除协议
北京信息科技大学医务室等4家定点医药机构因已注销等原因,申请解除协议。经市、区医保经办机构审核,对上述4家定点医药机构解除协议(见附件4)。
解除协议后,上述定点医药机构将不再承担医疗保障任务,参保人员在该医药机构发生的费用医疗保障基金不予支付。
五、恢复协议
北京同仁堂润丰医药有限公司百子湾药店因不能正常营业、地址变更等原因中止协议,现已完成迁址,申请恢复协议。
经市、区医保经办机构审核,上述医药机构已经具备承担医疗保障任务的条件,现决定对上述1家医药机构恢复协议(见附件5)。
请相关医保经办机构督促上述医药机构及时签订协议,恢复协议后,要认真执行北京市医疗保障规定,落实协议的各项条款,切实为参保人员提供规范、优质、便捷的服务。
六、签订“互联网+”医保服务补充协议
北京小汤山医院(北京小汤山疗养院)申请开展“互联网+”医保服务,经市、区医保经办机构审核并通过信息系统业务验收,上述1家定点医疗机构符合“互联网+”医保服务条件,签订《〈北京市定点医疗机构医疗保障服务协议〉“互联网+”医保服务补充协议》,为参保人员提供北京市医疗保障“互联网+”医保服务(见附件6)。
七、违规处理
首都医科大学附属北京地坛医院违反《北京市医疗保障定点医疗机构服务协议书》及基本医疗保险有关规定。根据《北京市医疗保障定点医疗机构服务协议书》相关条款,对首都医科大学附属北京地坛医院进行协议处理。
八、取消黄牌警示
北京九华医院、北京市昌平区沙河医院、北京养生堂药店有限公司龙锦三街药店申请取消黄牌警示,经市、区医保经办机构检查,认为北京九华医院、北京市昌平区沙河医院、北京养生堂药店有限公司龙锦三街药店整改后符合医疗保险定点医药机构的条件,现决定取消对北京九华医院、北京市昌平区沙河医院、北京养生堂药店有限公司龙锦三街药店的黄牌警示。
本通知自2025年5月30日起执行。
附件:1.北京市医疗保障新增定点医药机构名单
2.北京市医疗保障定点医药机构信息变更名单
3.北京市医疗保障定点医药机构中止协议名单
4.北京市医疗保障定点医药机构解除协议名单
5.北京市医疗保障定点医药机构恢复协议名单
6.北京市医疗保障定点医疗机构签订“互联网+”医
保服务补充协议名单
北京市医疗保险事务管理中心
2025年5月26日
高管变更
2023-12-17
·动脉网
90后们,正大举登上医疗创投的历史舞台。这一年多以来,包括邦邦机器人、磅策医疗、博志生物、迪视医疗、恩泽康泰、富伯科技、芙迈蕾、辉大基因、剂泰医药、普瑞纯正、深纳普思、深势科技、图湃医疗、曦健科技、芯宿科技等一众创新企业拿下了数千万甚至数亿元的新一轮融资。而这些企业都有一个共同的元素,就是创始人(含联合创始人、董事长、总经理等关键岗位)均出生于1990年以后。与2015年前后第一批90后创业者齐聚TMT领域并享尽高光时刻不同,医疗行业由于相对高壁垒、重经验等原因,入局门槛更高,所以90后医疗创业者直到现在才逐渐崭露头角“我见到的很多90后医疗创业者拥有全球化的视野与极强的学习力。更关键的是,他们与前辈们一样——非常拼。”君联资本执行董事戚飞告诉动脉网。在经纬创投投资副总裁薛明宇看来,从新一代环境下成长起来的年轻创始人们,得益于良好的教育背景、人生履历,他们更不容易设限。“90后创业者伴随着互联网产业成长,信息接触比较充分,决策前会充分调研,更加理性。同时在商业化领域,网感强,善于运用新渠道、新技术、新打法。”凯乘资本创始合伙人邹国文表示,“他们的成长曲线非常陡峭。”正是凭借扎实的知识积淀和敏锐的商业嗅觉,90后医疗创业者才得以缔造一个又一个现象级公司,且身后已云集了BAI资本、博远资本、DCM中国、高瓴、红杉、经纬、君联资本、联想创投、启明、水木创投、夏尔巴投资、源码资本、远毅资本、长岭资本、真格基金等明星机构,以及百度、美团、腾讯等巨头。毫无疑问,90后医疗创业者们正在成为行业创新的中坚力量。投身产业化大浪潮,90后医疗创业者崭露头角7月12日的香港,正值盛夏,室外温度超30℃,天气十分炎热。虽然顶着高温,仍有不少从全国各地赶来的投资人、券商和企业人士前往中环德辅道中19号17层——这是港交所的所在地。他们此时要见证的,是一家明星企业的IPO——毕业于北京信息科技大学的王宁在创业9年后成功敲钟,这代表着其耕耘的健身平台Keep正式上市。一时之间,Keep的商业崛起史被媒体广泛报道,而创始人王宁90后的标签也成为各方关注的焦点。不少行业人士坦言,90后创业者正接棒70、80后,真正开始站上新商业的历史舞台。动脉网也观察发现,在医疗创新这一垂直领域,至少已有50位90后企业创始人:他们与王宁一样,往往在嗅到行业机会后,会不顾一切投身其中,并持续带领企业走向成功。例如出生于1990年的夏雨青,其在2021年时敏锐地观察到医美器械行业正在发生的底层演变,便毅然选择在该领域创业。“医美光电器械行业属于多学科交叉整合的技术密集型产业,具有极高的技术壁垒。”夏雨青告诉动脉网,当时国内正规医美机构所使用的中高端医美光电设备几乎为进口产品,占比高达80%以上,处于垄断局面。“但其实,国内相关技术和人才已经具备,政策也在支持,高端医美器械领域的国产替代箭在弦上,加之国产设备成本优势的凸显,这必定是一个蓝海创业的机会。”面对机会窗口,敢想敢做的夏雨青躬身入局,他携手北京大学生物医学工程系博士王国鹤,于2021年在苏州成立了芙迈蕾。公司成立后不久,夏雨青发现,创业的想法很性感,落地却很骨感。无论是研发进展、质量体系的把控,还是公司的日常经营与管理,作为创始人都需亲力亲为,工作量非常大。创业有多忙?就在动脉网与夏雨青邀约访谈的头一天,他正在接待三家行业顶级VC,到晚上八九点送完投资人后,又与研发人员到公司进行设备的系统调试,搞到凌晨一两点,睡了五个多小时后又到正在进行新装修的办公区监工。而这,只是创业后日常的一天。“昨天还在与投资人、大专家侃侃而谈,今天就过来‘工地’当包工头,创业的感觉确实很魔幻。”夏雨青笑言。尽管创业的过程很琐碎,但目标却很唯一。在夏雨青看来,很多事情想归想,但最后能不能做成,要用结果来说话。“一旦创业,实际上是没有回头路的。”为此,芙迈蕾坚定聚焦高端医美设备领域,在此基础上做好产品研发、技术创新、专利布局及商业化落地。持续的积淀带来了不错的结果,就在今年2月,芙迈蕾旗下的智能水光机-ForeShine成功获批二类医疗器械注册证并顺利开启商业化,在2023年Q2季度就销售超百台;5月,芙迈蕾核心产品“ForePico皮秒激光治疗仪”已完成注册检测,检验报告显示产品性能参数完全不亚于进口同类产品,并于近期正式获得NMPA注册受理。面对未来发展,夏雨青认为一定要树立宏大伟愿,公司才能走得更远。针对此,芙迈蕾会做更大投入,进行更多探索,真正做出国际上没有的、基于本土特色的高端医美产品,从而推动行业发展,帮助更多求美者变美。与夏雨青一样,狄赛生物创始人、90后的林贤丰也有一个宏大目标——让动物细胞可以通过光合作用获取能量,从而返老还童,逆转细胞的衰老退变。于是,作为浙大医学院骨科学博士和浙大医学院附属邵逸夫医院的特聘研究员、骨科主治医师,他与导师、我国知名微创脊柱外科专家范顺武教授共同创办了狄赛生物,专注于去免疫原性的脱细胞生物材料在组织损伤和再生修复方面产品的科研与产业化。这并不容易。背后的原因在于,当下再生医学仍是一个十分前沿的技术领域,很多技术路径仍有待验证,并需从零做起。但林贤丰认为,做科技创新型企业,就是要有想象力,才可以发现更多可能。目前,得益于团队的持续突破,狄赛生物首款骨修复产品已提交国家药监局创新医疗器械申报。1991年出生的微构工场副总裁欧阳鹏飞,也是在敏锐地嗅到合成生物学正经历产业化的关键时刻,于是决定选择加入到行业的创新中。“读书的时候我就一直对生物学感兴趣,后来在清华大学生命科学学院完成了博士学位,合成生物学及生物化工领域进行了近10年一线研究,发表并申请多项SCI论文及发明专利。”欧阳鹏飞告诉动脉网,其博士导师是清华大学合成与系统生物学中心主任陈国强教授,后者在科研生涯中积累了大量合成生物技术以及PHA生产工艺的经验,也申请了一系列专利。“与模式创新不同,技术的创新需要更多时间的沉淀,非常感谢陈教授的积累,微构工场才能够顺利推进PHA在生物医用材料应用的一系列研发工作。”具体来说,微构工场通过细胞工厂生产生物医用材料PHA,具备良好的生物可降解性、生物相容性,可用于软骨组织工程、口腔修复膜、食管组织工程、人工心脏瓣膜等领域的医用材料应用开发。在2023年工业和信息化部、国家药监局联合开展生物医用材料创新任务揭榜挂帅工作中,微构工场的PHA生物医用材料成功入围,揭榜这一国家级创新任务。除了夏雨青、林贤丰、欧阳鹏飞外,在动脉网梳理与访谈的90后创业者中,他们绝大多数都是在敏锐嗅到行业的潜在变化与有了助推技术产业化的远大发心后,毅然决然投身到创新的大潮里,并深入生物医药、医疗器械、医疗服务、数字健康、生命科学多个方向。其中,医疗器械与数字健康占比最高,二者合计占到总体90后创业项目的近70%。(90后医疗创业者创业动机与创业方向 动脉网制图)浪潮奔涌下,敢想敢干的90后创始人已活跃在医疗创新的各个角落。勇闯医疗创新“无人区”,直面挑战与解决挑战创新创业的路上往往布满荆棘。而对于经验相对缺少的90后创业者而言,挑战更是只多不少。“创业的过程中面临最大的挑战是找到适合的人。”90后的深纳普思创始人、COO邱雨薇告诉动脉网,“因为对年轻创业者来说,在行业待的时间并不长,人脉相对欠缺一些,如何找到志同道合,且对创业富有激情的伙伴确实是一大考验。”针对这一问题,每一家企业都给出了自己的解法。1989年出生的芯宿科技创始人赵昕告诉动脉网,为了招聘到想要的人才,团队每次都会竭尽全力去到线下跟候选人深聊。有一次为了能在应聘者下班时与其能一起吃个饭、聊下天,赵昕与另两位创始人吴丹博士、董一名博士(90后)在一次会议刚结束时,三人立刻从苏州驱车超200多公里奔赴南京,与应聘者畅聊之后,三人深夜又开车返回苏州。除了拼劲和对人才的重视,富伯科技联合创始人、CEO孔令杰则向动脉网提到了诚意的重要性。2021年时,孔令杰正不停地去寻找适合公司发展的科学家,因为地处北京,所以首选是清华、北大、北航、北理工等院校。经过一个朋友推荐,孔令杰认识了清华大学一位做相关领域研究的教授。“因为老师有很多的教学任务和科研任务,时间特别紧,并不是随时都能约到时间。正巧有一个时间合适,可我当时刚因消化道疾病住院第3天,医生不让外出。没办法,我就拔了留置针,签了一份自愿临时出院的声明去和老师第一次见面。半天的时间里,与老师交流了我对这个细分市场的理解,谈了对公司未来发展的规划。最终达成了我们之间的合作,从而为公司找到了一名非常合适的优秀科学家。”招人之后,更难的还在留人和人才管理上——90后由于缺乏足够的资历和经验,如何凝聚团队成为普遍的短板。对此,微构工场副总裁欧阳鹏飞认为,由于合成生物学领域聚集的往往都是高知人才,与传统偏严格的组织架构和绩效管理相比,创新型的合成生物学企业想要高效发展,就更需要用一个共同的愿景、目标、价值观去凝聚共识,去调动每一位员工的积极性和想象力。“客户第一就是团队最大的共识。”欧阳鹏飞说,“对新技术要有信仰,对市场更要有敬畏之心。”深纳普思创始人、COO邱雨薇也有同感,她表示,从创业第一天开始,深纳普思另一位90后创始人、CEO王智华博士就给公司设立了一个非常大的期权池(30%),以希望当公司走向成功时,能给每一位为公司做出贡献的员工以真正可见的回报,并在公司营造了良好的尊重技术的氛围。此外,公司的文化与愿景也是引人、留人的重要因素。邱雨薇提到,作为一家致力于研发、制造人工智能赋能医疗级智能可穿戴设备及数字化慢病管理算法平台的创新性技术企业,深纳普思所处的赛道是慢病管理和AI的结合,公司的愿景是通过技术提供普惠、有效的慢病管理手段真正提高慢病患者的生活质量,且创始人坚持“做正确的事”。这样的愿景让志同道合的员工能感同身受,因此深纳普思也更能凝聚年轻人。当然,在医疗创新的“无人区”探索,研发挑战亦不可避免。对此,邱雨薇告诉动脉网,“创业公司普遍具有的一个优点就是,我们并不是一成不变的,每天都在自我迭代。比如团队会经常去拜访优秀的企业,学习他们的经验,以学习市场上或者科研领域最新的一些技术,把它融入到我们的产品设计开发中。”一个可以佐证的例子是,在此前一段时间,深纳普思的核心团队会在长三角与珠三角进行day trip,从早到晚开着车去友商、供应商、优秀的工厂等拜访,在交流的过程中快速的学习、提取知识和建立认知。在邱雨薇看来,技术型的公司其实离产品很远,对如何将技术转化成一个能够被可制造的产品的理解是不够的,所以需要大量的看和学习。“一旦认知不够,可能最后导致团队在闭门造车。”富伯科技CEO孔令杰也表示,当下他们所处的智能康复外骨骼领域,亦尚无对标学习的对象,只能靠自己去学习和探索。“因此,解决问题一定要小步快跑,不要总停留在思考层面,先做,如果合适,可能运气比较好,如果不合适,也没关系,抓紧时间调整,再继续往前走。从创业开始到现在,我基本上每周工作时间都是 100 个小时。”研发之后,紧随而来的便是商业化的挑战。“创新研发和商业化是完全不同的两个逻辑。”芯宿科技联合创始人、首席科学家董一名告诉动脉网,最重要的一点是(创新公司)要跟一些成熟的大公司对标,去做出明显的区隔和差异化,这个差异化恰恰是客户可能最关心的问题。“做商业化的过程要有心理预期,大概会面对怎样的困难,以及客户有怎样的需求。除了解决基本问题外,还要关注客户的潜在痛点,保持开放的心态多去沟通,逐渐就能理顺。”成立仅两年多时间,芯宿科技的商业化开始启程,目前国内首款自主研发的短链CMOS芯片已流片成功。(90后医疗创业者的挑战与解法 动脉网制图)不难发现,基于大量学习与快速迭代,勇闯医疗创新“无人区”的90后创业者们逐渐解决了招人、管理、研发与商业化难点,取得了更多成绩,也吸引到资本的关注与押注。3年获VC/PE超百亿投资支持,向未来持续探索越来越多的投资机构开始出手90后的医疗项目。据动脉网不完全统计,90后创业者参与创办的医疗创新企业,总计在近3年间获得了VC/PE超80起融资,融资总额逾百亿元人民币。(90后医疗创业项目融资事件数走势图 动脉网制图)从出手的投资机构来看,这些90后医疗创新项目背后更是囊括了经纬创投、源码资本、腾讯、五源资本、BAI资本、纪源资本、红杉中国、水木创投、高瓴、夏尔巴投资、启明创投、深创投、BV百度风投、君联资本、长岭资本等一众知名机构。(投资机构出手90后医疗项目次数分布情况 动脉网制图)90后医疗创业者频频获得融资背后,资本究竟看重他们什么?“相比起很多医疗产业的前辈而言,90后们产业经验会欠缺一些;但是年轻也会更灵活一些,更有想象力,更敢想、能说和敢干,迭代能力更强,爬出坑的能力更强,固有思路和包袱会更少,跨学科能力会更强。”天超资本管理合伙人王玥月告诉动脉网,“这是他们获得资本青睐的重要原因。”在经纬创投副总裁薛明宇看来,简单、直接也是90后创业者获得押注的重要特质。他至今还记得与微元合成的90后创始人、CEO刘波第一次见面的场景,两个人在深圳蛇口的希尔顿酒店聊了4个多小时。“他穿了一件T恤和一条普通的长裤。整个交流节奏非常的快,也十分to the point(切题),完全没有花里胡哨的东西,非常符合90后创始人敢想敢干、‘all in一切’的闯劲。”拿下融资后,多位创始人也表示,VC/PE在企业成长过程中给予的重要助力。“当时选择水木创投,对富伯科技能走到今天起到了非常重要的作用。”富伯科技创始人、CEO孔令杰告诉动脉网,“那个时候我们公司还没有正式员工,只有一个技术能够展示和一个未来规划可以讨论。但水木创投看准了我们的创业方向,他们有孵化器,有全球健康产业创新中心,还可以为我们配产品经理、配法务、配财务、找专家,使得我们能一步步走到现在。所以第一个种子或者天使投资人,一定要找那种真的是带有非常好资源的人,能够陪伴项目发展的机构。”“90后的创业者在一开始的时候是需要有投资人在前期给他一些陪伴的,当他遇到一个事情,比如招人开多少薪酬、股权给多少等,投资人能基于过往经验给予一些指导。”水木创投董事总经理颜祎告诉动脉网。以水木创投投资的图湃医疗为例,作为创始人,90后的王颖奇是典型的从学校走出来的创业者。“当年颖奇第一次向投资人讲PPT,就有些紧张。但他非常认真和较真,比如说像融资这件事,他就会走入一个比较好的自我迭代和循环的模式中去,会关注哪些方面做得还不够,哪些地方还需要改进。此外,我跟颖奇一起面试过一些40多岁的候选人,交流下来,大家都认为这个CEO是比较谦逊的,有很强的包容心,能够一起共事。”帮助图湃医疗顺利拿下近3亿元最新一轮融资的凯乘资本创始合伙人邹国文对此也表示,“(王颖奇)最令我们印象深刻的有几个点:一是他的坚毅和执着态度,遇到困难不抛弃,不放弃,表现出了超出同龄人的心力。二是他的专业能力,某一次面对业内顶级投资人与顶级产业机构的路演中,通过扎实的专业知识,完美hold住投资人的提问,产品也获得了认可。三是关键时刻,能理性审时度势,接受专业建议,决策果断,同时留有足够的弹性和备选方案,表现出了成熟企业家的潜力。”从上不难看出,在更为紧密的协同中,90后创业者们与投资机构们互相成就、彼此共赢,这也带动着项目持续向前:根据动脉网的统计,截至目前,已有超60%以上的90后医疗创业项目迈过种子期,走到了A轮及以后。其中,C轮及以后的项目也达到了18%左右。(90后医疗创业项目当下融资阶段分布情况 动脉网制图)在VC/PE的持续助力下,更多的90后医疗项目正不断地迈过成长期向成熟期跃进,甚至走到上市前夜。世界永远属于年轻人“2002年,马斯克创办了私人航天公司SpaceX,那年他31岁;2013年,张锋教授创立基因编辑公司Editas Medicine,那年他31岁。”经纬创投投资副总裁薛明宇告诉动脉网,在硬核科技领域,从来不缺乏年轻人。在薛明宇看来,年轻创始人往往具备一些优秀的创业特质。·一是不给自己设限,特别是在新一代环境下成长起来的创始人,他们的教育背景、人生履历使得他们更能接受风险,且有闯劲。·二是十分好学,尽管在一些领域缺乏经验,但年轻创始人的学习意愿和能力很强,并常常有定义一个新领域的勇气。·三是谦逊和有领导力,作为一个真正的创始人,关键的一点是要能够凝聚一个团队,很多年轻创业者在博士阶段已经开始尝试管理十几个人的小团队。·四是年轻创业者身处一线,离战场特别近,能听见炮火声,让研发能跟着一线走。“未来以医疗创新为代表的中国高科技公司,会延伸两条路径,一种是拥有丰富经验的大专家与科学家,搭配同样阅历丰富的管理层一起做出了不起的公司,比如百济神州;也会有另外一种类型的,比如像恩和生物、微元合成这类,由年轻创业者主导,去重新定义一个全新领域的企业。”薛明宇表示。当然,君联资本执行董事戚飞也坦言,不管是80后创业者还是90后创业者,行业对他们的评价标准不会有任何差别。“所以要注意,里程碑是创业过程中极其重要的事情。虽然没有统一的标准,但是会与行业进度做对比,而不会因为创始人是一个年轻人,企业就可以慢一点,允许他们多走弯路。” 另外,90后创业者很少经历过社会“毒打”,缺乏社会经验,因此需要有一个时间窗口期。“在这个过程去看他的学习能力和拼劲,通过一段时间观察之后,若他真的把企业带跑起来,那公司很有可能会成为细分领域的头部企业了。而如果不行,就考虑是否换一个CEO。”一位不愿具名的投资人表示,“在管理上不要优柔寡断,要更杀伐果断一点。很多从高校出来的这种技术背景的创业者,他们这方面可能稍微有所欠缺。”“希望90后创业者保持谦逊与空杯心态,多和有经验的产业大佬、投资人等业内资深人员成为朋友,获取多视角专业建议,把握好融资和发展节奏。我们也期待着90后创业者凭借技术改变生活的信仰,站在前人的肩膀上,能够给医疗产业一个新的面貌。”凯乘资本创始合伙人邹国文表示。不可否认,在医疗创新征途中,这些踏入无人区的90后创业者有的可能会乘风而起取得巨大成功,有的也可能遭遇险滩急流或失败,但这些其实都不重要——浮浮沉沉之间,无论是曾经或正在台前的60后、70后与80后,亦或是当下的90后,未来的00后,都会遇到各种各样的问题,而代际观察只是窥见行业变革的一个切面,并不是要对一代人褒与贬。因为只有当把视角放到整个产业创新的大历史中时,才能发现创新的拐角处,永远不变的是那些永不言弃、勇敢逐梦且一直年轻的一代又一代。这也是创新征途中最宝贵也最性感的注脚所在。* 注:本文图表的数据源因统计样本(企业55个、融资数据158条)有限,与实际情况或存在较大误差。因此,图表结论展示仅做参考。* 鸣谢:在本文的撰写过程中,得到了芙迈蕾、富伯科技、华兴资本、经纬创投、君联资本、凯乘资本、深纳普思、水木创投、天超资本、微构工场、芯宿科技等(按名称首字母排序)企业/机构和多位不愿具名的资深行业人士的支持,在此一并表示感谢。*封面图片来源:123rf近期推荐声明:动脉网所刊载内容之知识产权为动脉网及相关权利人专属所有或持有。未经许可,禁止进行转载、摘编、复制及建立镜像等任何使用。动脉网,未来医疗服务平台
IPO
2023-05-08
·动脉网
2018年6月,在“龙门创将”全球创新创业大赛·中国赛区总决赛上,罗国东代表的北京幸福益生再生医学项目从全国两万多个项目中脱颖而出,获得了项目第四名,并借此登上了新闻联播的专题报道。总决赛上,罗国东分享了国产化再生医学如何走出国门走向世界的内容,他认为科技型企业必须在夯实自身研发实力后走出国门,走进全球化,不断完善自身,做好未来医疗器械国产替代进口的准备。从北京幸福益生的联合创始人身份出发,2022年,罗国东回到故里重庆,创建了再生医疗企业雷杰思特。依托于此前的再生医学技术,雷杰思特主要从事再生医学医疗器械领域的研究与开发,相关产品应用在口腔修复、创伤无疤痕修复、医美修复以及高端化妆品领域。在再生医疗企业相对匮乏的西南地区,雷杰思特不偏安一隅,野心初露——它将在重庆涪陵区建立一个完善的供应链产业园,通过资源共享的战略平台,推动整个再生医学行业的发展。沉淀近10年,瞄准骨修复、医美的再生医学市场2013年,从北京信息科技大学毕业的罗国东在北京重庆企业商会遇到了自己的伯乐,也就是北京幸福益生的创始人胡方,机缘巧合下进入了再生医学行业。在过往的职业生涯里,罗国东负责过行政、政府事务、销售、生产甚至研发的工作。罗国东在北京幸福益生与团队成员共同研发的再生硅再生医学材料解决了促进细胞有序生长、组织原位再生的医学难题。在再生医学行业沉淀近10年,他始终觉得这个行业的潜力巨大。创始人罗国东在富春山·中国医药生物技术行业年度报告会上图片来源:雷杰思特罗国东的判断并非空穴来风。动脉网《2022再生医学行业研究报告》数据显示,目前,我国生物材料在临床应用中主要用作医疗器械,并已成为整个医疗器械产业的重要基础,其产品约占医疗器械市场的40%—50%。2017年我国生物医用材料市场达到1954亿元,以16.5%的年均增长率计算,预计到2020年市场规模将达4000亿元。而在细分领域上,雷杰思特将目光集中在骨修复领域、医美领域以及高端医疗器械领域。光是骨修复领域便能给雷杰思特带来数十亿的市场空间。根据南方所统计数据预计,2023年我国骨修复材料行业的市场规模将达到96.9亿元,2018 年至 2023年的年均复合增长率为19.8%。其中骨科骨缺损修复材料行业的市场规模将达到53.4亿元,口腔科骨植入材料行业的市场规模将达到26.0亿元。进军医学美容领域,则让雷杰思特拥抱更大的资本蓝海。根据东方证券的数据,经测算到2030年,国内再生医美出厂/零售规模预计分别达到67亿/300亿元人民币。在技术层面上,雷杰思特已做好了打入市场的准备。据罗国东透露,雷杰思特目前拥有专利10多项,产品批文5项,聘请了三名再生医学科学家、院士做技术指导。此外,雷杰思特正在筹划建立再生医学院士、博士后工作站以及国家再生医学研究中心,已拥有一名科学家股东,五名博士研究生。 从生物活性玻璃切入,三大应用领域进入研转产生物活性玻璃是生物材料的热门研究领域。生物活性玻璃是一种固体、无孔、硬质材料的生物陶瓷,主要由二氧化硅(或硅酸盐)和三种生物陶瓷组成。它的降解产物能够促进生长因子的生成、细胞的繁衍以及增强成骨细胞的基因表达和骨组织的生长。生物活性玻璃由于其可控的降解性和刺激新组织形成的能力,是组织工程领域有前途的材料。在牙科方面,其用途包括牙齿修复材料、矿化剂、作为牙种植体的涂层材料、牙髓封盖、根管治疗和空气磨损;在医学方面,其应用范围从整形外科扩展到软组织修复。然而生物活性玻璃的应用方式、稳定性和生产成本一直是生物活性玻璃研究的主要问题。为了获得不同形式的生物活性玻璃,人们进行了各种各样的研究,如块状、粉末状、复合材料和多孔支架。雷杰思特解决了生物活性玻璃材料的水溶性问题,使其再生材料可以和医美产品完美结合,并将核心技术运用在其系列产品中,加速了组织修复及细胞原位再生技术的临床应用。雷杰思特的产品主要布局在口腔修复、创伤修复、医美医疗器械。其主要产品包括再生系列伤口护理型敷料产品;“活丽本源”品牌牙膏以及化妆品;“浅美”系列医美产品。● “活丽本源”牙膏,改善牙龈健康在口腔修复领域,雷杰思特推出了“活丽本源”品牌牙膏。“活丽本源”牙膏的核心材料为生物活性玻璃以及重组角蛋白,是雷杰思特针对牙齿松动、牙釉质等牙齿问题以及解决口腔问题研发而成。 “活丽本源”牙膏图片来源:雷杰思特雷杰思特对“活丽本源”牙膏的临床研究表明,生物活性玻璃和氟离子导入均可以在牙本质表面和小管内生成再矿化沉积物,堵塞牙本质小管,对敏感牙本质有很好的再矿化效果,从而消除牙本质敏感。此外,“活丽本源”牙膏具有抑制牙菌斑形成、减轻牙龈炎、改善牙龈健康的作用。基于“活丽本源”牙膏对口腔的修复功效,罗国东表示,雷杰思特希望将“活丽本源”牙膏与二三十块钱的普通牙膏区分开来,打入高端牙膏市场,凸显牙膏的功效性。● 伤口护理型敷料,伤口愈合速度提升30%在创伤修复领域,雷杰思特的伤口护理型敷料产品具有多种应用潜力。该敷料产品由再生医学材料、苹果干细胞、表皮生长因子、碱性成纤维细胞生长因子、酸性成纤维细胞生长因子等构成,适用于新伤口,起到修复受损组织的作用。医用液体敷料图片来源:雷杰思特伤口护理型敷料能够促进浅表伤口快速愈合,预防疤痕生成。雷杰思特的护理型敷料的伤口愈合时效仅为7天,伤口愈合速度提升了30%。其产品适应症包括各类手术切口及愈合不佳的手术后伤口,如宫颈创面、外阴溃疡等妇科疾病创伤;烧烫伤和放射性灼伤;伤口周围潜行的窦道;筋膜减张切开伤口等。● 医美产品覆盖水光、皮肤修复、女性私密多品类雷杰思特的“浅美”系列医美产品涵盖水光系列、皮肤修复系列、女性私密系列。其中水光系列产品包括皮肤再生液水光、美白祛斑水光、医用透明质酸钠水光。水光产品添加了大、小分子透明质酸钠,能够实现自源性细胞修复,稳定释放成分功效,进而加速皮肤恢复、代谢,实现补水滋润、长效抗衰的作用。“浅美”系列医美产品,皮肤再生液水光super图片来源:雷杰思特为了打通“浅美”系列产品医美销售渠道,雷杰思特计划线上利用自营官方电商渠道、阿里系电商、腾讯系电商、字节跳动系、社群电商系等进行销售,线下进驻公立医院,民营医院、美容院线、OTC。目前“活丽本源”品牌牙膏以及化妆品已经上市。雷杰思特预计2023年下半年完成医疗器械二类申请提交,含无菌伤口护理软膏、功能性纱布敷料、无菌喷剂敷料、医用液体敷料、妇科凝胶等多种产品,继续申请二类医美产品注册证。除了以上三大应用领域外,雷杰思特未来还将进军高端医疗器械产品,攻破再生医学医疗器械在人工骨头、人造血管、人工皮肤、可降解心脏支架等的应用。 建设60亩再生医学产业园,打通上下游供应链基于罗国东对行业前沿的判断,雷杰思特决定将战略重点放在生物材料的市场化、商业化上,这也是建立再生医学医疗器械应用供应链的初衷。目前,雷杰思特已与重庆市涪陵区高新区签订了重点招商协议,建设2200平标准化医疗器械生产基地,作为公司医疗器械产品的生产中心,2023下半年将完成标准化厂房建设。项目二期拿地60亩,雷杰思特计划搭建再生医学医疗器械产业园,联合再生医学企业共同开发新品,实现自我造血功能,建设一个囊括再生行业整个上下游的产业园。重庆涪陵区2023年一季度重点项目集中开竣工仪式,左四为罗国东 图片来源:雷杰思特产业园将以再生医学医疗器械的应用以及开发为核心,引进先进的生物技术及设备,建设再生医学生物科技产业园项目。据雷杰思特透露,该产业园将服务于区域生物医药企业和机构,预计2023年底,申报二类创新医疗器械2项;实现与区域医药企业和服务机构服务对接10次以上,开展技术培育或论坛5次以上;2025年申报国家三类创新医疗器械产品1项。产业园5年预计实现产值总计约6.3亿元,缴纳税收约0.5亿元。罗国东表示,通过产业园,各再生医学企业能够共同交流和开发技术,将技术叠加应用,形成新的产品和技术,实现连锁开发。产业园建设是雷杰思特打入千亿市场的第一步,它还有更长远的目标——不断壮大产业园,形成再生医学产业集群,进而成为再生医学行业独角兽企业,成为再生医学优质上市公司,成为再生医学行业领军者。罗国东在采访中袒露道:“未来雷杰思特可能会遇到更新技术的挑战,我们所需要的是不断提高技术壁垒,不断更新换代技术及产品,走在技术前沿阵地。”近期推荐声明:动脉网所刊载内容之知识产权为动脉网及相关权利人专属所有或持有。未经许可,禁止进行转载、摘编、复制及建立镜像等任何使用。动脉网,未来医疗服务平台
生物类似药医药出海
100 项与 北京信息科技大学 相关的药物交易
登录后查看更多信息
100 项与 北京信息科技大学 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年02月07日管线快照
无数据报导
登录后保持更新
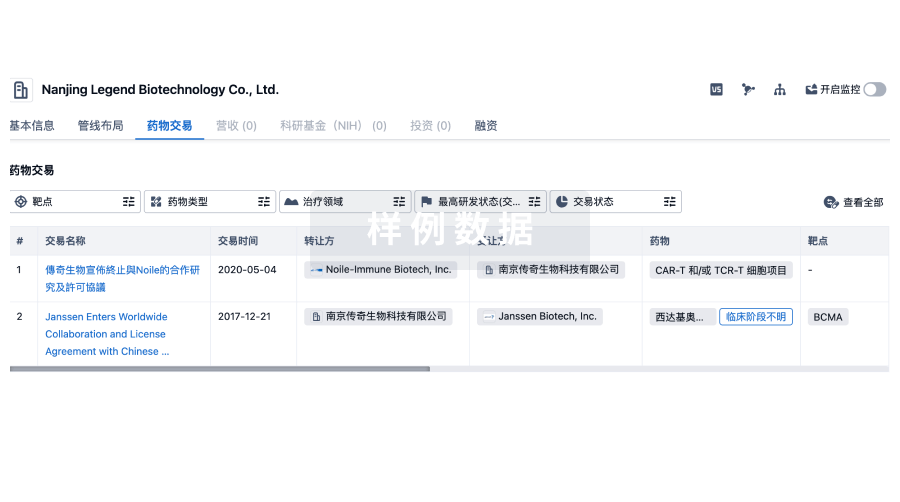
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
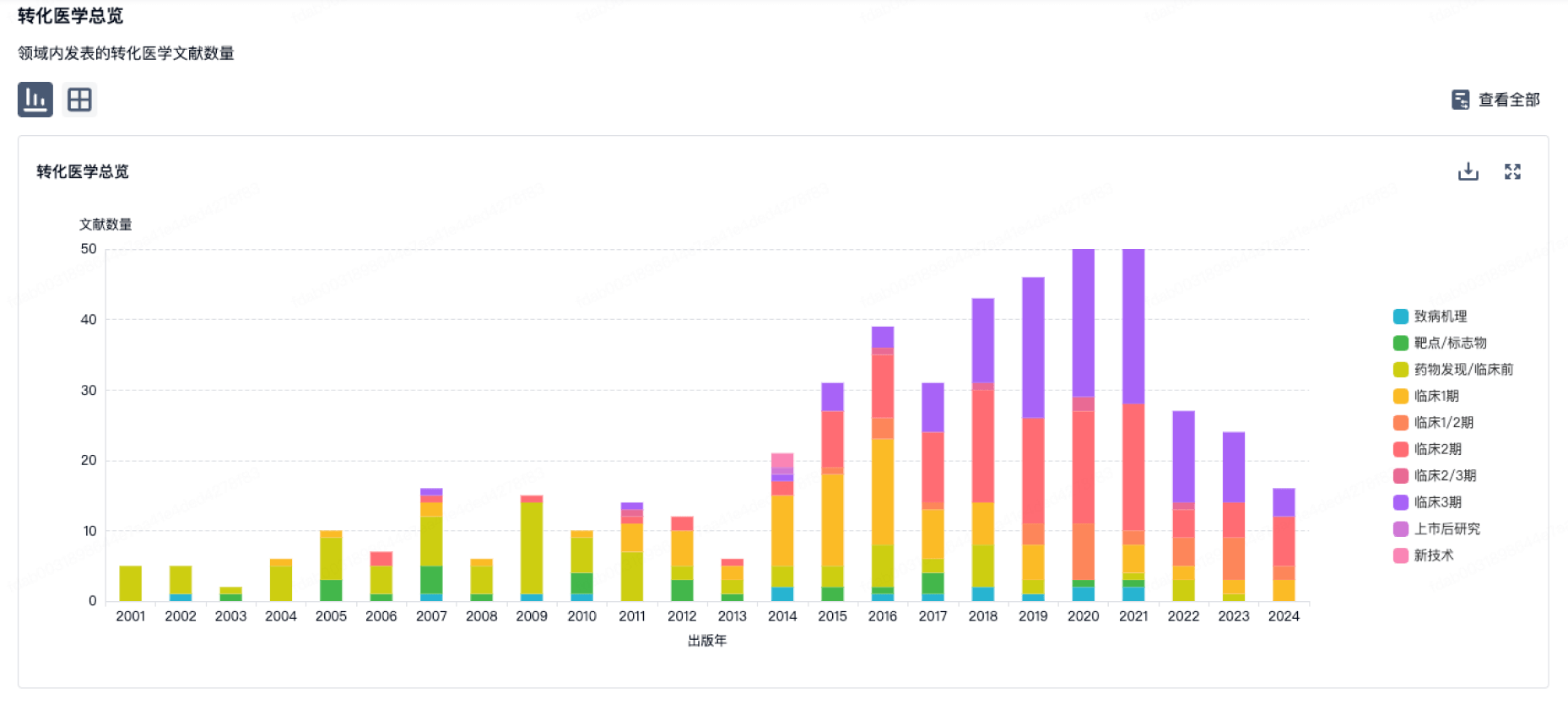
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
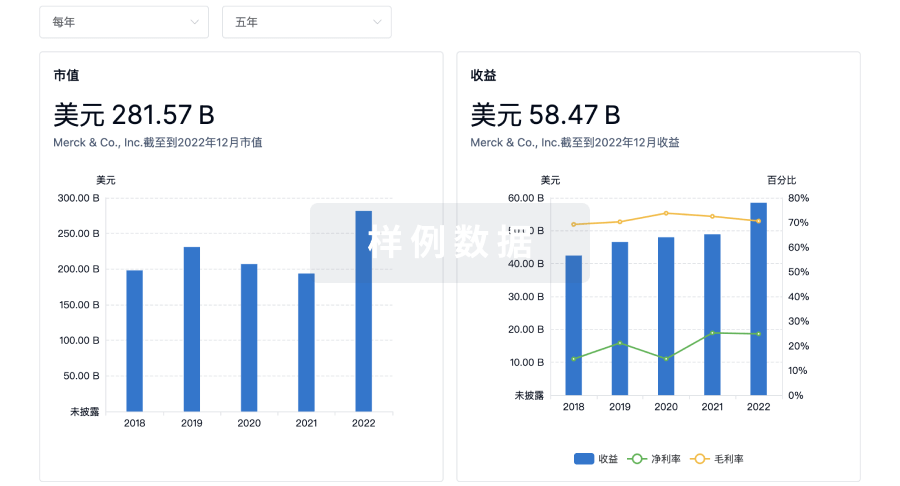
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
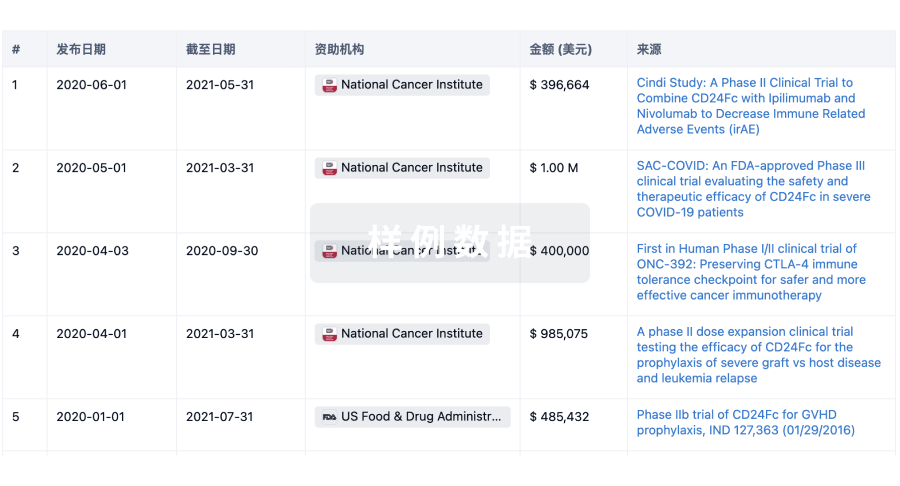
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用