预约演示
更新于:2025-05-07

School of Engineering & Applied Science
更新于:2025-05-07
概览
关联
100 项与 School of Engineering & Applied Science 相关的临床结果
登录后查看更多信息
0 项与 School of Engineering & Applied Science 相关的专利(医药)
登录后查看更多信息
296
项与 School of Engineering & Applied Science 相关的文献(医药)2025-04-22·ACS Nano
Hierarchical Self-Assembly of Magnetic Handshake Materials
Article
作者: Du, Chrisy Xiyu ; Brenner, Michael P. ; Cohen, Itai ; Fenley, Andreia L. ; McEuen, Paul L. ; Dshemuchadse, Julia
2025-04-22·ACS Omega
Metal-Oxide-Decorated Mesoporous Silica Chemiresistors for Exhaled Biomarker Detection
作者: Ahn, Jaeyong ; Wang, Tiancheng ; Sung, Minchul ; Hwang, Geelsu ; Stebe, Kathleen J. ; Kim, Jin Woong ; Lee, Daeyeon ; Oh, Joon Hak ; Oh, Min Jun
2025-04-15·ACS Omega
Biodegradable Microneedle Patch Confers Crocin with Outstanding Effects in the Treatment of Myocardial Infarction
Article
作者: Lin, Shudong ; Liu, Qian ; Wang, Tianlei ; Hou, Shiying ; Zhang, Danni ; Lu, Yunyun ; Zhang, Ling ; Jin, Liang ; Yang, Bin ; Lou, Zhaohuan ; Yuan, Mengyao ; Zhao, Rui ; Wu, Jiangyue
23
项与 School of Engineering & Applied Science 相关的新闻(医药)2024-12-13
FRIDAY, Dec. 13, 2024 -- The same technology behind COVID vaccines might be able to protect both the mother and child from a dangerous complication of pregnancy.
A new mouse study published Dec. 11 in the journal
Nature
shows that injections based on that vaccine platform reduced the risk of
preeclampsia
in lab mice.
Preeclampsia is persistent high blood pressure that occurs during pregnancy or after giving birth. It can threaten the life of both the mother and baby, or leave the mom with severe organ damage.
The experimental injection “was able to deliver an mRNA therapeutic that reduced maternal blood pressure through the end of gestation and improved fetal health and blood circulation in the placenta,” said researcher
Kelsey Swingle
, a doctoral student in bioengineering at the University of Pennsylvania School of Engineering and Applied Science. “Additionally, at birth we saw an increase in litter weight of the pups, which indicates a healthy mom and healthy babies."
Preeclampsia affects 3% to 5% of pregnancies, researchers said in background notes. There’s no cure for the condition; instead, women take blood pressure medication or stay on bed rest.
Preeclampsia arises due to insufficient blood flow to the placenta, which causes a mom’s blood pressure to rise while restricting blood flow to the fetus.
Researchers figured that a drug designed to get into the placenta despite the restricted blood flow might help resolve the condition.
To design that drug, researchers turned to the particles used to deliver mRNA COVID vaccines.
The mRNA that creates an immune response to COVID is delivered inside lipid nanoparticles (LNP), which are microscopic balls of fatty material. These particles dissolve inside the human body, releasing the payload they’re carrying.
Swingle examined 98 different lipid nanoparticles, assessing their ability to reach the placenta of pregnant mice.
Swingle finally landed on a particle that provided 100-fold better mRNA delivery to the placenta than an FDA-approved lipid nanoparticle.
The results showed that the one-time injection cured mice with preeclampsia until the end of their pregnancy.
“At this stage in our research, we would bring this LNP to larger animals such as rats and guinea pigs first, to determine how well it works in the ‘gold standard’ models of preeclampsia before we could advance this work to human trials,” Swingle said in a university news release.
“Testing our LNP on guinea pigs will be particularly interesting, as their placenta closely resembles a human’s and their gestational period is longer, up to 72 days,” Swingle added. “We will be asking the questions ‘How many doses do these animals need?’ ‘Will the minimum effective dose change?’ and ‘How well does our current LNP work in each?’”
This research also shows the potential for using lipid nanoparticles to deliver cures for other diseases and disorders, Swingle concluded.
Whatever your topic of interest,
subscribe to our newsletters
to get the best of Drugs.com in your inbox.
疫苗信使RNA临床结果
2024-08-08
SOMERSET, N.J., Aug. 08, 2024 (GLOBE NEWSWIRE) -- Legend Biotech Corporation (NASDAQ: LEGN) (Legend Biotech), a global leader in cell therapy, today announced the appointment of Peter Salovey, Ph.D., President Emeritus of Yale University, to its Board of Directors. Dr. Salovey will serve as an independent director, effective August 9. “We are pleased to welcome Dr. Salovey to the Legend Board,” said Ying Huang, Ph.D., Chief Executive Officer of Legend Biotech. “Dr. Salovey’s deep experience and wealth of knowledge in medical research and public health will be invaluable to Legend and offer a new and diverse perspective. We look forward to his insights and contributions to the strategic decisions that will strengthen and drive further growth for our Company.” Dr. Salovey is the Chris Argyris Professor of Psychology and was the twenty-third president of Yale University, serving as president from July 2013 to June 2024. As President, Dr. Salovey led the development of new programs and facilities across the schools and departments of Yale, including restructuring and expanding the Faculty of Arts and Sciences and the School of Engineering and Applied Science, launching the Jackson School of Global Affairs, transitioning the Yale School of Public Health into a self-supporting independent school, and opening two new residential colleges to expand the undergraduate student population by 15%. Before becoming president, Dr. Salovey served as Yale’s provost, dean of Yale College, and dean of the Yale Graduate School of Arts and Sciences. Dr. Salovey also played key roles in multiple Yale healthcare programs, including the Yale Center for Emotional Intelligence, which he founded; the Center for Interdisciplinary Research on AIDS; and the Cancer Prevention Research Program of the Yale Cancer Center. The research conducted in his laboratory focused on health communication and human emotion. “There has been a lot of momentum within the CAR-T space over the past several years, as it has the potential to transform the treatment paradigm for multiple myeloma patients,” said Dr. Salovey. “I am honored by the opportunity to be part of the Legend Board and collaborate with such a high-caliber organization and leadership team working to bring innovative therapies to patients with debilitating and life-threatening diseases.” Dr. Salovey received his an A.B. (psychology) and A.M. (sociology) from Stanford University and earned an M.S., M.Phil., and Ph.D. in psychology from Yale University. He completed his internship in clinical health psychology at the West Haven Veterans Administration Medical Center and is a licensed clinical psychologist in the State of Connecticut. ABOUT LEGEND BIOTECH Legend Biotech is a global biotechnology company dedicated to treating, and one day curing, life-threatening diseases. Headquartered in Somerset, New Jersey, we are developing advanced cell therapies across a diverse array of technology platforms, including autologous and allogeneic chimeric antigen receptor T-cell, gamma-delta T cell (gd T) and natural killer (NK) cell-based immunotherapy. From our three R&D sites around the world, we apply these innovative technologies to pursue the discovery of cutting-edge therapeutics for patients worldwide. Learn more at www.legendbiotech.com and follow us on X (formerly Twitter) and LinkedIn. INVESTOR CONTACT: Jessie YeungTel: (732) 956-8271 jessie.yeung@legendbiotech.com PRESS CONTACT: Mary Ann OndishTel: (914) 552-4625media@legendbiotech.com
高管变更免疫疗法细胞疗法
2024-03-27
Engineers have developed a novel method for manufacturing CAR T cells, one that takes just 24 hours and requires only one step, thanks to the use of lipid nanoparticles (LNPs), the potent delivery vehicles that played a critical role in the Moderna and Pfizer-BioNTech COVID-19 vaccines.
Penn Engineers have developed a novel method for manufacturing CAR T cells, one that takes just 24 hours and requires only one step, thanks to the use of lipid nanoparticles (LNPs), the potent delivery vehicles that played a critical role in the Moderna and Pfizer-BioNTech COVID-19 vaccines.
For patients with certain types of cancer, CAR T cell therapy has been nothing short of life changing. Developed in part by Carl June, Richard W. Vague Professor at Penn Medicine, and approved by the Food and Drug Administration (FDA) in 2017, CAR T cell therapy mobilizes patients' own immune systems to fight lymphoma and leukemia, among other cancers.
However, the process for manufacturing CAR T cells themselves is time-consuming and costly, requiring multiple steps across days. The state of the art involves extracting patients' T cells, then activating them with tiny magnetic beads, before giving the T cells genetic instructions to make chimeric antigen receptors (CARs), the specialized receptors that help T cells eliminate cancer cells.
Now, Penn Engineers have developed a novel method for manufacturing CAR T cells, one that takes just 24 hours and requires only one step, thanks to the use of lipid nanoparticles (LNPs), the potent delivery vehicles that played a critical role in the Moderna and Pfizer-BioNTech COVID-19 vaccines.
In a new paper in Advanced Materials, Michael J. Mitchell, Associate Professor in Bioengineering, describes the creation of "activating lipid nanoparticles" (aLNPs), which can activate T cells and deliver the genetic instructions for CARs in a single step, greatly simplifying the CAR T cell manufacturing process. "We wanted to combine these two extremely promising areas of research," says Ann Metzloff, a doctoral student and NSF Graduate Research Fellow in the Mitchell lab and the paper's lead author. "How could we apply lipid nanoparticles to CAR T cell therapy?"
In some ways, T cells function like a military reserve unit: in times of health, they remain inactive, but when they detect pathogens, they mobilize, rapidly expanding their numbers before turning to face the threat. Cancer poses a unique challenge to this defense strategy. Since cancer cells are the body's own, T cells don't automatically treat cancer as dangerous, hence the need to first "activate" T cells and deliver cancer-detecting CARs in CAR T cell therapy.
Until now, the most efficient means of activating T cells has been to extract them from a patient's bloodstream and then mix those cells with magnetic beads attached to specific antibodies -- molecules that provoke an immune response. "The beads are expensive," says Metzloff. "They also need to be removed with a magnet before you can clinically administer the T cells. However, in doing so, you actually lose a lot of the T cells, too."
Made primarily of lipids, the same water-repellent molecules that constitute household cooking fats like butter and olive oil, lipid nanoparticles have proven tremendously effective at delivering delicate molecular payloads. Their capsule-like shape can enclose and protect mRNA, which provides instructions for cells to manufacture proteins. Due to the widespread use of the COVID-19 vaccines, says Metzloff, "The safety and efficacy of lipid nanoparticles has been shown in billions of people around the world."
To incorporate LNPs into the production of CAR T cells, Metzloff and Mitchell wondered if it might be possible to attach the activating antibodies used on the magnetic beads directly to the surface of the LNPs. Employing LNPs this way, they thought, might make it possible to eliminate the need for activating beads in the production process altogether. "This is novel," says Metzloff, "because we're using lipid nanoparticles not just to deliver mRNA encoding CARs, but also to initiate an advantageous activation state."
Over the course of two years, Metzloff carefully optimized the design of the aLNPs. One of the primary challenges was to find the right ratio of one antibody to another. "There were a lot of choices to make," Metzloff recalls, "since this hadn't been done before."
By attaching the antibodies directly to LNPs, the researchers were able to reduce the number of steps involved in the process of manufacturing CAR T cells from three to one, and to halve the time required, from 48 hours to just 24 hours. "This will hopefully have a transformative effect on the process for manufacturing CAR T cells," says Mitchell. "It currently takes so much time to make them, and thus they are not accessible to many patients around the world who need them."
CAR T cells manufactured using aLNPs have yet to be tested in humans, but in mouse models, CAR T cells created using the process described in the paper had a significant effect on leukemia, reducing the size of tumors, thereby demonstrating the feasibility of the technology.
Metzloff also sees additional potential for aLNPs. "I think aLNPs could be explored more broadly as a platform to deliver other cargoes to T cells," she says. "We demonstrated in this paper one specific clinical application, but lipid nanoparticles can be used to encapsulate lots of different things: proteins, different types of mRNA. The aLNPs have broad potential utility for T cell cancer therapy as a whole, beyond this one mRNA CAR T cell application that we've shown here."
This study was conducted at the University of Pennsylvania School of Engineering and Applied Science and is supported by the U.S. National Institutes of Health Director's New Innovator Award (DP2 TR002776), a U.S. National Science Foundation CAREER Award (CBET-2145491), an American Cancer Society Research Scholar Grant (RSG-22-122-01-ET), and a Burroughs Wellcome Fund Career Award at the Scientific Interface. Further support for this paper and the researchers involved came from the Emerson Collective, U.S. National Science Foundation Graduate Research Fellowships, a U.S. National Institutes of Health Ruth L. Kirschstein National Research Service Award (F31CA260922), the National Institute of Dental and Craniofacial Research of the US National Institutes of Health (T90DE030854), the University of Pennsylvania Fontaine Fellowship, the Norman and Selma Kron Research Fellowship, and the Robert Wood Johnson Foundation Health Policy Research Scholars Program. The researchers thank the Human Immunology Core at the University of Pennsylvania (RRID: SCR_022380) for assistance with primary human T cell procurement. The HIC is supported in part by NIH P30 AI045008 and P30 CA016520.
疫苗免疫疗法细胞疗法信使RNA
100 项与 School of Engineering & Applied Science 相关的药物交易
登录后查看更多信息
100 项与 School of Engineering & Applied Science 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年02月08日管线快照
无数据报导
登录后保持更新
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
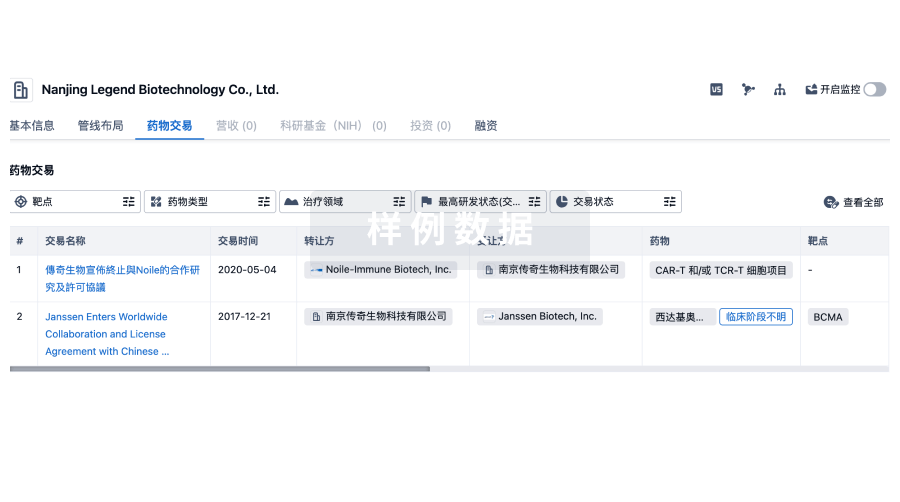
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用