预约演示
更新于:2026-03-11
OpenAI OpCo LLC
更新于:2026-03-11
概览
关联
100 项与 OpenAI OpCo LLC 相关的临床结果
登录后查看更多信息
0 项与 OpenAI OpCo LLC 相关的专利(医药)
登录后查看更多信息
1,245
项与 OpenAI OpCo LLC 相关的新闻(医药)2026-03-11
·动脉网
脑机接口正在“沸腾”!
3月5日,在十四届全国人大四次会议发布的政府工作报告中明确提到,2026年我国将培育壮大新兴产业和未来产业,并点名脑机接口为需扶持的未来产业之一。这一提法将脑机接口置于国家战略性新兴产业的前沿位置,有望获得更多的政策支持和资源投入,以推动其技术创新和产业化进程。
受此影响,港股脑机接口概念股全线走高,最高者涨幅甚至超过20%,重演了今年年初首个A股交易日的盛况。彼时,受马斯克宣布旗下Neuralink将于2026量产脑机接口设备的影响,国内脑机接口概念股集体大涨。
当然,概念股始终只是概念股,全球范围内仍没有“真正”的脑机接口上市企业。不过,今年年初国内两家脑机接口头部企业陆续曝出冲击上市。在当下政策的强力支持下,我国拿下全球“脑机接口第一股”的可能性正在急剧上升。
01
德国总理访问,杭州“六小龙”强脑科技冲刺港股IPO
强脑科技是最先曝出IPO传闻的。1月底,据媒体报道,强脑科技以保密形式向港交所提交了IPO申请。在此之前,这家杭州“六小龙”之一刚刚完成了高达20亿元的融资,打破了国内脑机接口领域融资额的纪录。
即便放在全球,强脑科技此次融资也是不遑多让,是脑机接口领域Neuralink以外第二大规模融资。
公开资料显示,自2015年成立以来,强脑科技已完成六轮融资。最早于2016年完成天使轮和Pre-A轮融资,后又在2019年完成A轮融资,将公司估值推升至4亿美元。2025年开始,脑机接口概念大热,强脑科技在短时间内连续完成融资,成为了这轮脑机接口热国内最大的获益者之一。
在2月26日德国总理默茨访华停留杭州期间,强脑科技也作为脑机接口代表企业受邀出席,牌面十足。
作为国内非侵入式脑机接口的代表,也是首支入选哈佛大学创新实验室的中国团队,强脑科技的方案也代表了国内之前的选择方向。
彼时脑机接口技术成熟度有限,且没有Neuralink这样成功植入侵入式脑机接口的先例,普遍对于侵入式脑机接口的接受度有限。非侵入式脑机接口可通过头戴设备或体表传感器采集脑电信号,规避了开颅手术风险,成为了当时首选也在情理之中。
强脑科技多功能助眠仪(图片来自强脑科技官网)
相比之下,非侵入式脑机接口的技术门槛较低,具有强烈的消费属性。目前,强脑科技的非侵入式脑机接口广泛应用于医疗康复、健康管理和教育等多个领域。不过,其在医疗的应用主要以改善睡眠、降低压力及注意力训练为主,消费健康的属性较为明显。
除此以外,强脑科技还对脑机接口应用场景进行进一步拓展,从成立以来就持续研发智能仿生手及智能下肢,并获得FDA认证。通过多年积累,其在该领域取得技术突破,在去年成功研发全球首款量产直觉控制智能仿生手。
强脑科技智能仿生手(图片来自强脑科技官网)
在宣传视频中,强脑科技的产品不仅可以轻松拿起然后以较大力量捏碎鸡蛋,还可以瞬间切换为轻柔模式捡起脆弱的蛋壳,整个过程无需人工干预,完全依靠触觉仿生手的力控自主完成,显示其已具备堪比人类的操作灵活性。
从视频来看,强脑科技的智能仿生手已经可以精准捕捉用户的肌电与神经信号,实现五指协同操作,帮助上肢残障者重获精细运动能力。
强脑科技希望其脑机接口可以让1000万经受自闭症、ADHD、阿兹海默病、失眠等脑部疾病痛苦的患者得到改善,并在未来5-10年帮助100万肢体残疾人通过佩戴神经控制假肢恢复日常生活。并让普通人能通过脑机接口设备用意念与世界直接交互,体验人机融合的未来。
目前,强脑科技的产品已大规模落地,并已实现规模化营收。鉴于多数脑机接口企业仍处于临床阶段,这无疑为其IPO增加了更多的筹码。
相比侵入式脑机接口,非侵入式脑机接口显然在对大脑信号的接受上存在先天不足。在现有技术条件下,其所能实现的健康功能相对较为有限。在日前公布的国内首份《非侵入式脑机接口在神经康复临床应用中的专家共识》中,只有“脑机接口结合功能性电刺激或康复机器人用于卒中后上肢中重度运动功能障碍的治疗”应用场景获益明显,推荐常规开展。值得注意的是,这恰好是强脑科技的智能仿生手可以发挥作用的领域。
不过,也正因为应用门槛不高,它在消费领域有广泛的应用潜力。若能结合具体的应用场景(如脑机接口+智能义肢),其价值不容小觑。此外,随着技术的不断发展,一旦非侵入式脑机接口在大脑信号接收上突破阈值,未来可期。
02
脑机接口首例植入,博睿康科创板IPO展示“硬科技”含量
紧随强脑科技,国内侵入式脑机接口的领军企业博睿康也在2月初向上海证监局提交IPO辅导备案。
不同于非侵入式脑机接口,无论是半侵入式还是侵入式脑机接口都需要对大脑进行有创手术植入,风险极大,需要较高的技术门槛。直到近一两年,这两类脑机接口才实现了不小突破。
博睿康则是我国侵入式脑机接口的领军企业之一,早在2011年就已成立。核心创始人出自在脑机接口领域排名全球前列的清华大学神经工程实验室。
根据公开资料显示,博睿康研发实力雄厚,已获得17项技术专利及9个软件著作权,承担或参与了国家十二五科技支撑计划“脑-机接口中的微弱信息采集技术及产品开发”课题以及科技部十三五重点研发计划 “阿尔兹海默病神经调控及智能康复关键技术和临床应用研究”课题。
不过,真正让博睿康声名鹊起的还是在2023年。当年10月,其脑机接口产品NEO在首都医科大学宣武医院完成了首例植入。一位四肢瘫痪十多年的患者在手术后实现了用“意料”抓取水瓶并自主完成喝水的行为。这也被认为是全球首例无线微创脑机接口植入。
不同于Nueralink,博睿康的系统属于半侵入式脑机接口,其电极置于颅骨和大脑皮层之间的硬脑膜上,这种方案希望能够平衡脑机接口的性能和创伤,虽然采集信号不如全侵入式,但它仅需微创手术,不损伤脑细胞。同时,植入物也可以通过体外机无线供电,可实现微创与长期使用的平衡。
在宣武医院的首例植入中,患者在术后10天即出院回家。
随后,博睿康陆续在北京天坛医院、上海华山医院、江苏省人民医院等开展可行性试验并取得了显著成效。截至2025年12月,已有32位颈部脊髓受损患者在全国11家医院完成NEO植入手术。根据其临床试验总结会披露的信息,全部患者均成功实现居家脑控抓握辅助与康复训练,在主要临床终点上实现了100%达标。
博睿康自主研发的NeuroHUB多模态研究平台(图片来自博睿康官网)
2024年8月,博睿康“植入式脑部采集刺激系统”进入国家药监局创新医疗器械特别审查程序,成为我国首款进入该程序的脑机接口产品。除此以外,博睿康的经颅电刺激仪和脑电图机也已获得医疗器械注册证,主要用于神经调控、康复治疗辅助以及脑功能的监护评估等。
产品不仅可广泛应用于神经科学、心理学、人因工程、运动学、管理学等科研领域,还可应用于临床神经疾病诊断、治疗与康复工程等临床医学领域,研发成果与技术实力受到了国内外神经工程与临床医学领域专家们的普遍认可。
作为我国侵入式脑机接口的明星企业,博睿康一直是资本市场的宠儿。2015年12月,博睿康完成1200万元天使轮融资,是较早完成融资的国内脑机接口企业。2018年3月,它又完成3000万元Pre-A轮融资。此后,博睿康又陆续完成多轮融资,包括红杉中国、松禾资本、华控基金、浦东创投、百度风投等知名机构纷纷加入。
2025年,博睿康据传完成D+轮融资,投后估值达到35-40亿元。此后,博睿康提交了上市辅导申请,剑指科创板。
大体上,科创板要求企业拥有自主知识产权的核心技术,且技术处于国际领先或国内领先水平的相应规定使其是目前“硬科技”企业上市的首选。博睿康选择冲击科创板,或许在一定程度上也代表了其对技术实力的自信。
03
“两会”定调未来产业之一,创纪录投资热潮来临
强脑科技和博睿康冲刺IPO,也给本已火热的国内脑机接口市场又添了一把火。
公开信息显示,近一两年脑机接口领域一级市场日趋火爆。2025年,脑机接口领域共发生26起融资事件,融资总额达17.78亿元。其中,仅金额破亿元的融资就超过6起,融资金额纪录也在不断刷新。相比2024年的7起融资事件、2.3亿元的融资规模,实现大幅增长。
今年以来,受各种利好因素影响,脑机接口一级市场热度不减。不完全统计,开年仅2个多月时间,国内脑机接口领域就已完成了10起融资,且融资金额普遍较大。按此趋势,全年融资规模有望再创历史新高。
2026年国内脑机接口融资事件不完全统计
除了融资上的突飞猛进,脑机接口也得到了来自政策的大力扶持。2026年1月1日,《采用脑机接口技术的医疗器械 术语》正式开始实施。这部制定于2025年下半年的标准是我国第一项脑机接口医疗器械标准,将为脑机接口医疗器械产业高质量发展奠定基础。
在此基础上,国家药监局又发布公告,确定了《采用脑机接口技术的医疗器械 侵入式设备 可靠性验证方法》和《采用脑机接口技术的医疗器械 范式设计与应用规范 运动功能重建》两项推荐性医疗器械行业标准的制订计划。
3月2日,科技部、金融监管总局、工业和信息化部和国家知识产权局联合印发《关于加快推动科技保险高质量发展 有力支撑高水平科技自立自强的若干意见》,引导保险资金投向科技创新领域,明确鼓励开发脑机接口、人工智能等领域的科技保险专属产品,建立专项风险准备金制度。这一政策安排被业内解读为“国家为资本试错买单”——让投资人敢于押注那些可能失败、但一旦成功将改变世界的技术。
当然,最受关注的莫过于日前的十四届全国人大四次会议上,脑机接口又被写入政府工作报告,首次被明确列为培育发展的未来产业之一,与量子科技、具身智能等并列。这为整个产业提供了最高级别的政策背书,预示着国家将加大对该领域的科技攻关和产业扶持力度。
这些支持对于推动国内脑机接口行业的发展,抢占脑机接口全球先机至关重要。环顾四周,全球都已在脑机接口领域行动起来,大额融资事件频现。
3月5日,Neuralink 前总裁 Max Hodak创立的美国神经科技公司 Science完成 2.3亿美元C轮融资,自2021年成立以来累计融资已接近 4.9亿美元。其核心项目并非传统意义上的通用脑机接口,而是视觉恢复植入设备,显示资本已开始关注可率先商业化的细分应用场景。
更早的1月初,OpenAI及其CEO萨姆·奥特曼(以个人身份参与)共同支持的脑机接口研究实验室Merge Labs完成2.52亿美元种子轮融资,由OpenAI等重量级投资者领投。Merge Labs选择非侵入或极低侵入的技术路线,初期设备可能置于脑保护膜(硬脑膜)之上,未来目标是完全外部化、非侵入式设备。
甚至印度的投资者也在关注脑机接口,被称为印度版“美团”,估值超百亿美元的外卖巨头Zomato联合创始人Deepinder Goyal新创立的大脑监测可穿戴设备初创公司 Temple在“亲友投资”阶段便筹集了高达5400万美元的资金,投后估值达到1.9亿美元。
显然,尽管我国脑机接口目前占得了一些先机,但逆水行舟,不进则退。且脑机接口仍处于初期,需要进一步的扶持。两大头部企业若能成功IPO,也将会为行业提供进一步的推动。
04
写在最后
强脑科技与博睿康相继冲击IPO,是中国科技企业从“跟跑”到“并跑”的缩影,向世界展示了中国在脑科学领域的实力。对于行业来说,我们也希望两大头部企业的IPO不是终点,而是构建全产业链生态的起点,并带动上游核心芯片和下游应用的协同发展,推动更多的企业快速发展,并最终IPO成功。
动脉网也将保持对该领域的关注,欢迎行业人士提供相关信息。
*封面图片来源:123rf
如果您认同文章中的观点、信息,或想进一步讨论,请与我们联系;也可加入动脉网行业社群,结交更多志同道合的好友。
近
期
推
荐
声明:动脉网所刊载内容之知识产权为动脉网及相关权利人专属所有或持有。未经许可,禁止进行转载、摘编、复制及建立镜像等任何使用。文中如果涉及企业信息和数据,均由受访者向分析师提供并确认。
动脉网,未来医疗服务平台
2026-03-10
·汇聚南药
“药店价值大讨论”之八十一
前天店里来了一位三十来岁的年轻人,拿着手机给我看。屏幕上是一个AI对话界面的截图,问的是“阿托伐他汀对肝脏的影响”,AI洋洋洒洒列了七八条,最后说“建议定期监测肝功能,如有异常应停药”。
他问我:“药师,我吃了三个月了,血脂降下来了,看了这个有点担心,要不要停?”
我问他:“最近查过肝功能吗?”
他说没有。
我又问:“觉得哪里不舒服吗?”
他说也没有。
我说:“那就先别停,抽空去查一下,指标正常就接着吃。”
这不是第一个拿着AI建议来问我的顾客。
主流的AI工具有哪些,能做什么
目前影响用药决策的AI工具大致分为几类。
第一类是通用大语言模型,如ChatGPT、Google Gemini、DeepSeek等。患者可以直接提问“阿托伐他汀有什么副作用”,几秒内就能得到答案。
第二类是垂直医学AI工具,如OpenEvidence(面向医疗专业人员的搜索引擎)、Heidi Health(临床记录工具)、ChatGPT Health(OpenAI推出的健康问答功能)。这类工具在数据训练时更侧重医学文献,准确率相对更高。
第三类是面向大众的健康AI应用,典型代表是蚂蚁阿福。截至目前,全国已有5000多家医院接入阿福,30万真人医生在线问诊,1000多位名医开设了“AI分身”。阿福的用户量在春节期间突破1亿,每天解答健康咨询超过1000万次。它的数据按证据等级对信源进行分层筛选,收录了3600万篇高质量医学文献,包括中华医学会等本土最新指南共识。用户对着手机说句话,就能完成挂号、医保支付、报告查询,甚至能“拍药盒问用法”。
还有重庆“渝小健”、广州“穗小伊”等城市级智能体入驻阿福,为用户提供本地化的就医服务。普安县一位68岁的老村医,已经学会了用阿福拍检查报告。他说AI成了他身后的那本翻不完的医书。
AI会给顾客带来哪些影响
对患者来说,AI的直接影响是“信息获取门槛降低了”。过去需要搜半天才能找到的信息,现在一句话就能得到答案。IQVIA在2025年进行的一项调查显示,38%的医疗专业人士认为AI工具是“关键”或“非常重要”的科学信息来源,已高于销售代表的30%。专业人士都在用,普通患者更不例外。阿福的用户中,55%来自三线及以下城市,50后、60后占比达20%——连过去习惯“信偏方”的老年人,也开始尝试问AI。
但问题也随之而来。AI会犯错,而且犯得很理直气壮。
有研究让ChatGPT回答各类药学问题,总体正确率只有64.3%。它对“达格列净是否与中性粒细胞减少症相关”的回答是“文献中未见报道”,但该药说明书已明确标注了相关风险。在计算万古霉素给药剂量时,它没有根据肌酐清除率进行调整。回答妊娠期间服用螺内酯是否有致畸风险时,它提供了不存在的参考文献。
还有AI转录工具在记录患者谈话时,会把“我有个Seretide吸入器”错误总结成“我每天使用Seretide吸入器两次”,差之毫厘谬以千里。阿福的早期用户也反馈过“回答模式机械”“错误解读体检报告”等问题。
AI犯的错和人类不一样。人错了,往往是知识盲区;AI错了,是“幻觉”——它会在没有依据的情况下生成看起来合理的答案,还理直气壮地端给你。那位顾客手机上截图的回答,看起来条理清晰、语气笃定,但如果他肝功能本来就正常,停药就是画蛇添足。
AI能做什么,不能做什么
它能做的,是快速整合已有知识。比如你问“阿托伐他汀的常见不良反应是什么”,它能把药品说明书和文献里的话重新组织一遍,速度比人快,覆盖面比人广。山东省第二人民医院用DeepSeek辅助药师审方,错误处方拦截率达到99.7%,临床药师对患者的药学监护覆盖率增长70%,药历和查房记录书写时间减少85%。这是实打实的效率提升。
但它不能做的,是针对一个具体的人做判断。那位顾客拿着AI结论来问要不要停药,AI给的是一个通用建议——肝功能异常的人应该监测。但问题在于,他有没有肝功能异常,AI不知道,也没法知道。
这恰恰是药师柜台前每天都在做的事:问几句、看一眼,给出一个针对眼前这个人的建议。
药师的核心能力是什么
北京鼓楼社区卫生服务中心2024年启动了一个项目,给117位高血压患者配备智能血压计,数据实时上传到AI管理系统。当患者血压连续偏高时,AI会自动发送提醒短信,同时通知医务人员跟进。这个项目里,AI负责监测和提醒,但真正给出治疗方案调整建议的,还是人。
药师的核心能力从来不是背说明书——AI一天能背一万本。真正不可替代的,是这几样:
第一,用药信息采集与初步评估能力
顾客拿着AI答案来问“阿托伐他汀要不要停”,AI给的是通用回答——“肝功能异常者应监测肝功能”。但问题在于,这个人肝功能到底有没有异常,AI不知道。
药师能做的,是在柜台前问几个关键问题:“吃多久了?”“最近查过肝功能吗?”“有没有肌肉酸痛、乏力这些感觉?”这几个问题不是诊断,而是采集与用药安全直接相关的信息。根据回答,可以给出明确的建议:如果没查过,建议去查一下;如果查过且正常,可以继续服用;如果出现可疑症状,警惕他汀相关不良反应。
AI能给出标准知识,但主动采集个体信息并做出初步判断的能力,AI没有。
第二,个体化风险评估的能力
AI给出的信息是平均意义上的——来自临床试验的群体数据、药品说明书的标准警告。但药是吃在具体人身上的。
同样是他汀,80岁的老人和40岁的中年人,肝肾功能不同、合并用药不同、基础疾病不同、生活饮食习惯不同,风险收益比完全不一样。AI不知道这位顾客是否同时服用胺碘酮(增加肌病风险),是否最近做过手术(可能暂时停药),是否有过肌痛史。这些细节决定了一份用药建议是否真的安全。
药师的价值,正是在通用知识和个体情况之间搭一座桥——把标准答案转化成针对这个人的答案。
第三,信息甄别与整合的能力
顾客拿着AI答案来问,往往不是因为AI错了,而是因为他不知道AI的答案能不能信、适不适用。
AI会犯两种错。一种是知识性错误,比如对“达格列净是否与中性粒细胞减少症相关”回答“文献中未见报道”,但说明书上白纸黑字写着。另一种是适用性偏差,AI给的答案本身没错,但它不知道这个问题放在这个人身上是否成立。
药师需要做的不是否定AI,而是帮他把信息过一遍筛子:这条信息来源可靠吗?它的结论有没有被其他证据支持?放在这个人的具体情况里,它成立吗?筛完之后,剩下的那部分信息,才是真正对这个人有用的。
国家卫生健康委医院管理研究所的专家共识明确强调:药师是处方审核工作的第一责任主体,必须对AI模型输出的结果进行人工复核,将幻觉风险降到最低。这不是谁取代谁的问题,是人给AI兜底的问题。
未来药师的定位
2024年国家卫生健康委发布的《卫生健康行业人工智能应用场景参考指引》,把AI技术嵌入了处方前置审核、临床用药辅助、患者用药指导等药学服务环节。AI不是来抢饭碗的,是来帮忙的。
帮忙体现在哪?山东一家医院的例子很说明问题——AI把80%以上的机械性工作干了,药师就能把时间花在更复杂的事情上。青海大学附属医院院长樊海宁在阿福开通了“AI分身”,牧民可以直接咨询健康问题,不再为一个小问题奔波千里。但他同时强调,这些AI分身的作用是分担日常咨询,遇到复杂情况,还是需要真人医生介入。
国家药品监督管理局执业药师资格认证中心的一位专家说得很直接:AI对于执业药师而言只是辅助工具,而不是替代品。执业药师的专业判断和人文关怀,仍然是药学服务不可或缺的核心。
国家卫健委也反复提醒:那些“饿死癌细胞”“吃补品治肿瘤”的观点往往以偏概全,缺乏科学依据。面对AI的建议,记住三句话:AI是参谋,不是主帅;信息要溯源;防癌靠科学,不靠玄学。
钟南山院士说得很清楚:推动AI医疗不是为了取代医生,而是为了让医生更好地回归“以人为本”,而不是“以病为本”的初心。
那天那位顾客听完我的话,没停药,去查了一次肝功能。指标正常,回来接着吃药。
他后来跟我说:“幸亏来问了,要不然就自己瞎停了。”
信息来源:中国药店
往期推荐
!
免责声明
“汇聚南药”公众号所转载文章来源于其他公众号平台,主要目的在于分享行业相关知识,传递当前最新资讯。图片、文章版权均属于原作者所有,如有侵权,请在留言栏及时告知,我们会在24小时内删除相关信息。
本平台不对转载文章的观点负责,文章所包含内容的准确性、可靠性或完整性提供任何明示暗示的保证。
喜欢的点个“看一看”和"喜欢"吧
不然微信推送规则改变,有可能每天都会错过我们哦~
2026-03-10
·生息致知
以下内容是《Applied Artificial Intelligence for Drug Discovery》中「第十四章:大型语言模型(LLMs)在药物发现领域应用」的内容。详细探讨了LLMs的技术基础、在化学和药物研发各阶段的具体应用、最新进展、挑战及未来方向。
「第一部分:引言与LLMs的技术基础 (Introduction & Fundamentals)」
「1. 引言 (Introduction)」
「背景与现状」:LLMs(如GPT、BERT)作为生成式AI的核心,已从单纯的自然语言处理(NLP)工具转变为药物发现的关键技术。尽管公众感觉LLMs突然兴起,但IBM等公司在自然语言理解方面的长期投入为其奠定了基础。
「核心优势」:与传统针对特定任务开发的模型不同,LLMs是基于海量数据训练的“基础模型”(Foundation Models),具有广泛的适用性、成本效益和高性能。
「应用概览」:LLMs不仅能处理文本,还能通过特定架构处理化学结构(SMILES)和生物序列(FASTA),在药物靶点识别、分子生成和临床试验优化中展现潜力。
「1.1 LLMs 的工作原理与架构」
「核心技术」:基于「Transformer」架构(Vaswani et al. 提出),利用“注意力机制”(Attention Mechanism)处理序列数据,克服了传统RNN(循环神经网络)在处理长距离依赖时的梯度消失问题。
「训练过程」:
「预处理」:包括Tokenization(分词,如BPE、WordPiece)、Padding(填充)和Truncation(截断)。
「学习方式」:通过自监督学习(Self-supervised Learning),预测句子中的下一个词(GPT)或掩码词(BERT)。
「对齐技术」:使用RLHF(基于人类反馈的强化学习)减少幻觉,提高模型可靠性。
「功能领域」:LLMs在分类、聚类、响应生成、文本生成、翻译和知识回答五个核心领域表现出色。
「1.1.1 LLMs 在化学领域的应用 (Chemistry)」
文章详细列举了LLMs在化学细分领域的具体应用案例:
「化学机器人 (Chemistry Robotics)」:将自然语言指令转化为机器人可执行的代码(如Python脚本)。例如,CLARify系统利用GPT-3将语言转化为化学描述语言(XDL),或控制OT-2液体处理机器人的实验。
「逆合成规划与反应预测 (Retrosynthetic Planning)」:利用Molecular Transformer和Chemformer等模型,通过分析反应数据预测合成路径或反应产物,精度甚至超过人类化学家。
「从头分子生成 (De Novo Molecular Generation)」:利用MolGPT、MolT5等模型生成具有特定属性(如药代动力学、毒性控制)的新型药物分子结构。
「从头蛋白质生成 (De Novo Protein Generation)」:利用ProtGPT2、ProGen等模型生成具有特定功能的蛋白质序列,或利用RFDiffusion进行精确的蛋白质折叠设计。
「蛋白质-配体相互作用预测」:利用AlphaFold-Multimer或PSICHIC等模型预测药物与靶点的结合,辅助虚拟筛选。
「1.1.2 化学LLMs的主要范式」
本节对比了三种主要的预训练目标:
「掩码语言建模 (MLM)」:随机隐藏输入序列中的Token并进行预测(如BERT, ChemBERTa)。适用于理解上下文和分子属性预测。
「分子属性预测 (MPP)」:直接预测分子量、极性表面积等物理化学性质,用于分子表示学习。
「自回归Token生成 (ATG)」:根据前序Token预测下一个Token(如GPT)。适用于分子补全(Molecule Completion)和表示转换。
「1.1.3 分子的Tokenization方法」
「字符级 (Character-level)」:将每个字符视为Token(如SMILES中的C, O, =)。虽然简单但可能破坏化学实体的完整性。
「原子级 (Atom-level)」:将原子或官能团视为基本单位,更符合化学逻辑(如SELFIES格式)。
「基序级 (Motif-level)」:基于化学规则或数据驱动将分子分解为功能子结构(如BRICS),计算量大但化学意义明确。
「第二部分:LLMs在药物发现中的概念化与应用 (Conceptualization & Applications)」
「2. 药物发现中的LLMs概念化 (Conceptualizing LLMs in Drug Discovery)」
「行业痛点」:传统药物发现耗时(15-20年)、昂贵(约27亿美元)且失败率高。
「LLMs的价值」:ChatGPT等模型的出现加速了药物研发。LLMs不仅能处理文本,还能处理结构化数据(CSV, JSON)、化学结构文件(SDF, MOL)甚至图像(多模态)。
「具体输入形式」:包括自然语言查询、基因列表、高通量筛选结果、分子对接可视化图像等。
「专用模型」:针对药物发现的特定需求,出现了如「DrugChat」等专用模型,结合了LLM、适配器和图神经网络(GNN)。
「3. 药物发现中的最新进展 (Advancements)」
「分子设计与生成」:利用MolGPT等生成具有理想药理特性的新分子。
「靶点识别」:通过分析生物数据识别潜在药物靶点。
「药物重定向 (Drug Repurposing)」:分析现有药物信息,预测新的适应症(如利用知识图谱)。
「文献挖掘与假设生成」:利用GPT-4或BioBERT快速总结海量文献,从非结构化数据中生成新假设。
「多组学数据整合」:整合基因组、转录组和蛋白质组数据,理解疾病机制。
「临床试验AI」:优化试验设计,通过患者分层提高精准医疗效率。
「解决数据稀缺」:利用Few-shot(少样本)和Zero-shot(零样本)学习,解决罕见病研究中数据不足的问题。
「4. 具体应用领域 (Applications)」
文章指出药物发现主要应用BERT(双向,擅长理解/预测)和GPT(单向,擅长生成)两大模型家族:
「微调 (Fine-tuning)」:在大规模无标签数据上预训练后,利用小规模标签数据进行特定任务微调(如Accenture Labs用于抗菌肽设计)。
「表格应用」:文档中的Table 6展示了具体的Prompt示例,涵盖药物重定向、从头设计、结合亲和力预测、ADMET预测等任务。
「行业案例」:
「In silico Medicine」:利用ChatGPT增强数据整合。
「Sanofi」:与OpenAI合作加速研发。
「Google DeepMind」:开发Med-PaLM医疗问答模型。
「第三部分:挑战与未来方向 (Challenges & Future)」
「5. 挑战与未来方向 (Challenges and Future Directions)」
尽管前景广阔,LLMs在药物发现中仍面临严峻挑战:
「1. 核心挑战」
「数据质量与稀缺性」:高质量的标注数据(尤其是罕见病或新靶点)非常有限,现有数据常包含噪声和偏差。
「可解释性 (Interpretability)」:LLMs常被视为“黑箱”,在高风险的药物研发中,缺乏透明的决策过程阻碍了科学家和监管机构的信任。
「泛化能力 (Generalization)」:模型容易过度拟合训练数据的相关性,难以真正理解生物机制,导致在面对分布外数据(Out-of-distribution)时表现不佳。
「计算成本」:训练和部署大模型需要巨大的算力资源,限制了中小型机构的使用。
「伦理与隐私」:涉及患者数据隐私、知识产权归属及算法偏见问题。
「2. 未来发展方向」
「技术融合」:
「强化学习 (RL)」:结合RL引导LLMs更有效地探索化学空间。
「生成式模型」:与GANs(生成对抗网络)或VAEs(变分自编码器)结合,生成属性更精确的分子。
「多尺度模拟」:开发能从分子相互作用模拟到全器官模型的LLMs。
「监管框架」:FDA等机构需建立针对AI生成药物预测的验证标准(包括透明度和可重复性)。
「高效架构」:开发稀疏注意力机制或参数高效微调(PEFT)技术,降低算力门槛。
「协作生态」:需要学术界、工业界和监管机构合作,建立共享数据标准,推动AI驱动的药物发现。
「总结表格」
为了更直观地理解,以下是文档中关于「LLM架构对比」及「药物发现阶段应用」的核心总结:
对比维度
GPT 系列 (Generative Pre-trained Transformer)
BERT 系列 (Bidirectional Encoder Representations)「核心架构」
Decoder-only (仅解码器)
Encoder-only (仅编码器)「训练目标」
自回归 (Autoregressive),预测下一个词
掩码语言建模 (MLM),预测被掩盖的词「上下文理解」
单向 (从左到右)
双向 (同时考虑左右上下文)「主要优势」
擅长文本/分子生成、序列补全
擅长语义理解、分类、属性预测「化学应用」
生成新分子结构 (MolGPT)
分析分子性质、反应分类 (ChemBERTa)
药物发现阶段
LLMs 的具体应用价值「靶点识别」
分析多组学数据,整合文献知识,识别潜在致病靶点。「分子设计」「从头生成」
具有特定理化性质的新分子;「逆合成分析」规划合成路线。「临床前研究」
预测ADMET(吸收、分布、代谢、排泄、毒性);预测蛋白质-配体相互作用。「临床试验」
优化试验设计,筛选符合条件的患者群体,预测患者依从性。「药物重定向」
挖掘现有药物的新适应症,加速老药新用。
关注「生息致知」,AI与数学学习不迷路。欢迎加微信号AIAI4SCI交流。
100 项与 OpenAI OpCo LLC 相关的药物交易
登录后查看更多信息
100 项与 OpenAI OpCo LLC 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年03月13日管线快照
无数据报导
登录后保持更新
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
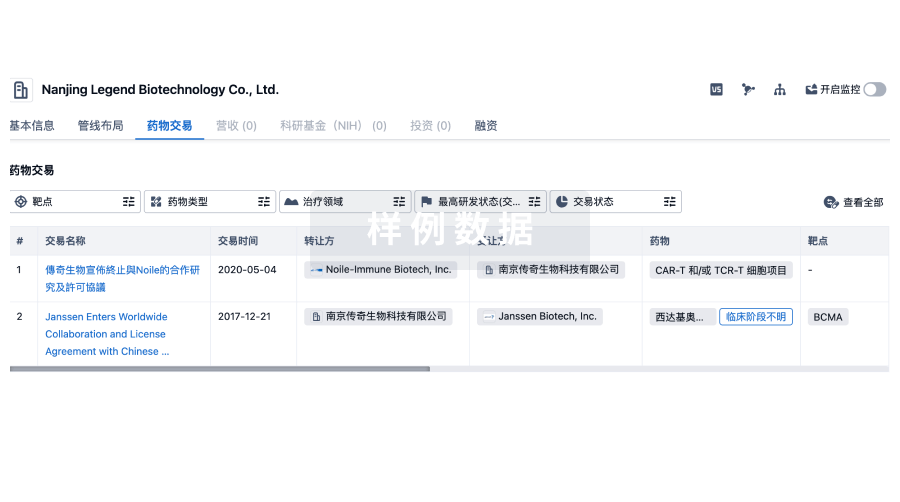
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
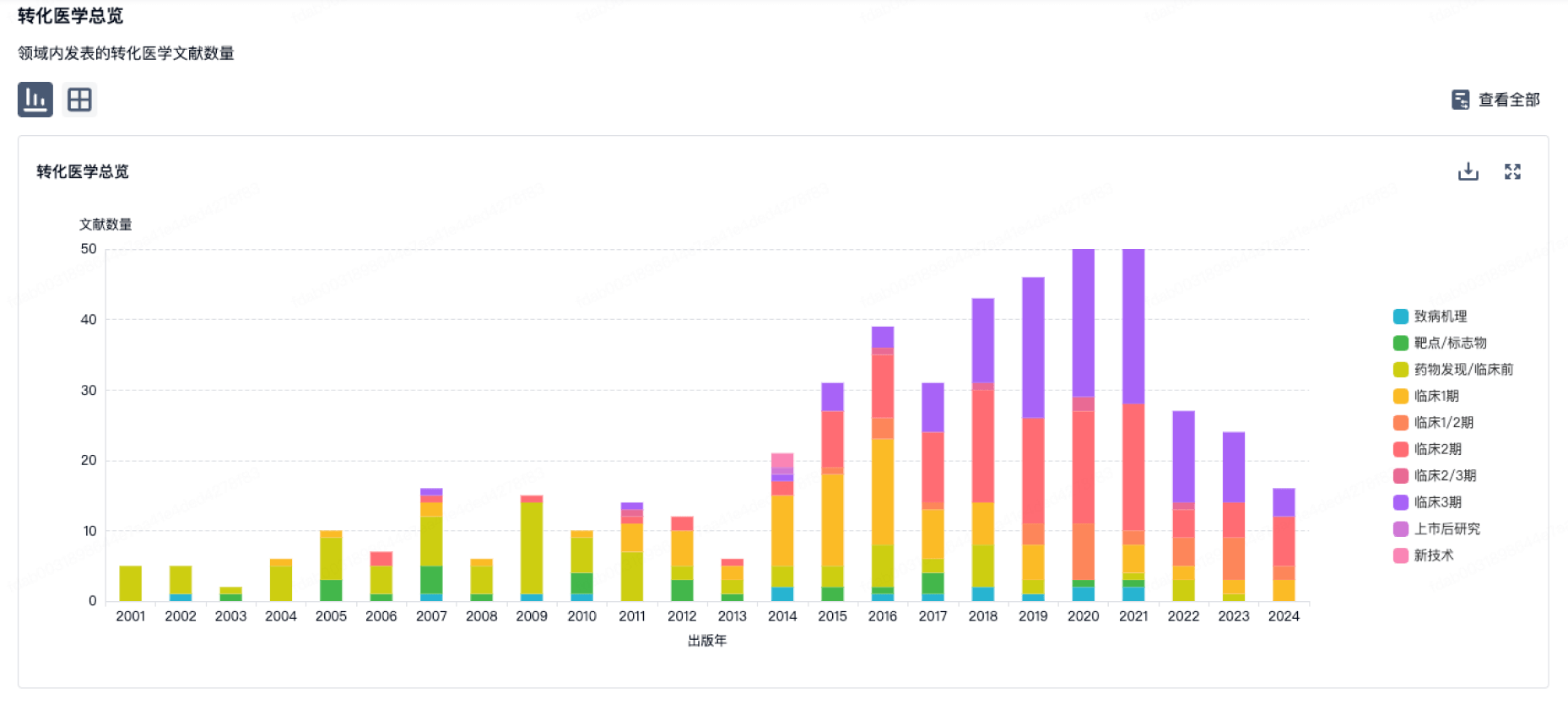
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
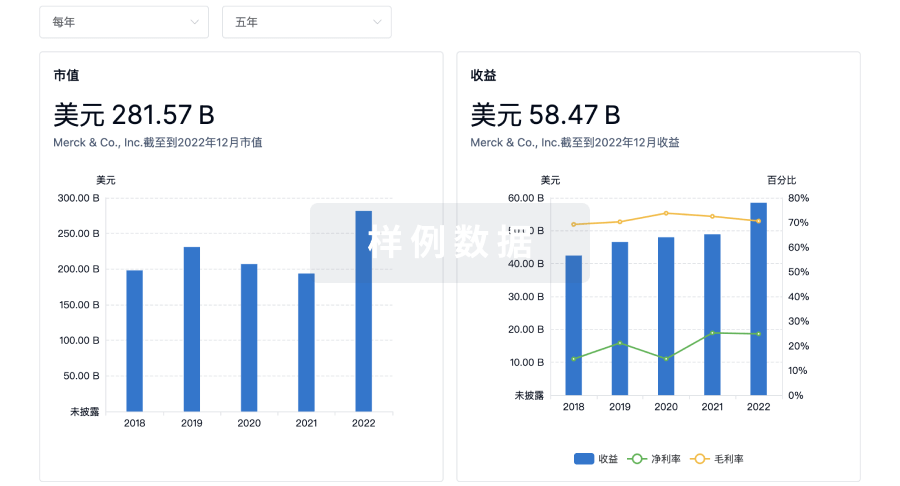
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用