预约演示
更新于:2025-12-17
Shanghai University of Finance & Economics
更新于:2025-12-17
概览
关联
ChiCTR1900024449
Impact of Mindfulness-based Stress Reduction on Anxiety and Stress among College Athletes
100 项与 上海财经大学 相关的临床结果
登录后查看更多信息
登录后查看更多信息
2026-01-01NEUROPSYCHOLOGIA
Processing trimorphemic words: linearity and internal structure
Article
作者: Meng, Yaxuan ; Kotzor, Sandra ; Lahiri, Aditi
The internal structure of trimorphemic words and its potential impact on stem access have not as yet been explored in great depth. The combinatory possibilities of a single stem with two affixes can vary between left-branching unkindness or right-branching unhelpful. The non-linearity of the grouping leads to an obvious query regarding the decomposition of the complex words and the consequences this may have for lexical access of the stems. To address this question, we conducted a cross-modal priming experiment employing a combination of trimorphemic primes and stem targets across four conditions: semantic (indecisive - hesitate), form (extensive - tense), morphological left-branching (e.g. un-kind-ness > kind), and right-branching (e.g. un-help-ful > help). Behavioural results revealed facilitation in both left- and right-branching conditions, whereas no such effect was found in semantic and form conditions. The ERP analysis, however, revealed different patterns between the semantic and morphological conditions. Semantically related primes facilitated the targets, evidenced by an N400 attenuation. The two morphological conditions differed; facilitation effect was not detected in the morphological left-branching condition, whereas right-branching related primes inhibited access to the target, indicated by an increased N400 response compared to control primes. This asymmetry between the two morphological conditions suggests a difference in the speed and ease of lexical access in trimorphemic words which is affected by their internal structure with suffixes being less easily separable from the stem than prefixes.
2025-11-01NEURAL NETWORKS
HG2P: Hippocampus-inspired high-reward graph and model-free Q-gradient penalty for path planning and motion control
Article
作者: Shi, Haibo ; Tang, Zeshen ; Jiao, Chenyuan ; Wang, Haoran ; Sun, Yaoru
Goal-conditioned hierarchical reinforcement learning (HRL) decomposes complex reaching tasks into a sequence of simple subgoal-conditioned tasks, showing significant promise for addressing long-horizon planning in large-scale environments. This paper bridges the goal-conditioned HRL based on graph-based planning to brain mechanisms, proposing a hippocampus-striatum-like dual-controller hypothesis. Inspired by the brain mechanisms of organisms (i.e., the high-reward preferences observed in hippocampal replay) and instance-based theory, we propose a high-return sampling strategy for constructing memory graphs, improving sample efficiency. Additionally, we derive a model-free lower-level Q-function gradient penalty to resolve the model dependency issues present in prior work, improving the generalization of Lipschitz constraints in applications. Finally, we integrate these two extensions, High-reward Graph and model-free Gradient Penalty (HG2P), into the state-of-the-art framework ACLG, proposing a novel goal-conditioned HRL framework, HG2P+ACLG.1 Experimentally, the results demonstrate that our method outperforms state-of-the-art goal-conditioned HRL algorithms on a variety of long-horizon navigation tasks and robotic manipulation tasks.
2025-10-01STATISTICAL METHODS IN MEDICAL RESEARCH
Optimal treatment regimes in the presence of a cure fraction
Article
作者: Qi, Chenrui ; Zhan, Zishu ; Lin, Zicheng ; Zhang, Baqun ; Lin, Cunjie
Despite the widespread use of time-to-event data in precision medicine, existing research has often neglected the presence of the cure fraction, assuming that all individuals will inevitably experience the event of interest. When a cure fraction is present, the cure rate and survival time of uncured patients should be considered in estimating the optimal individualized treatment regimes. In this study, we propose direct methods for estimating the optimal individualized treatment regimes that either maximize the cure rate or mean survival time of uncured patients. Additionally, we propose two optimal individualized treatment regimes that balance the tradeoff between the cure rate and mean survival time of uncured patients based on a constrained estimation framework for a more comprehensive assessment of individualized treatment regimes. This framework allows us to estimate the optimal individualized treatment regime that maximizes the population’s cure rate without significantly compromising the mean survival time of those who remain uncured or maximizes the mean survival time of uncured patients while having the cure rate controlled at a desired level. The exterior-point algorithm is adopted to expedite the resolution of the constrained optimization problem and statistical validity is rigorously established. Furthermore, the advantages of the proposed methods are demonstrated via simulations and analysis of esophageal cancer data.
100 项与 上海财经大学 相关的药物交易
登录后查看更多信息
100 项与 上海财经大学 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年02月08日管线快照
无数据报导
登录后保持更新
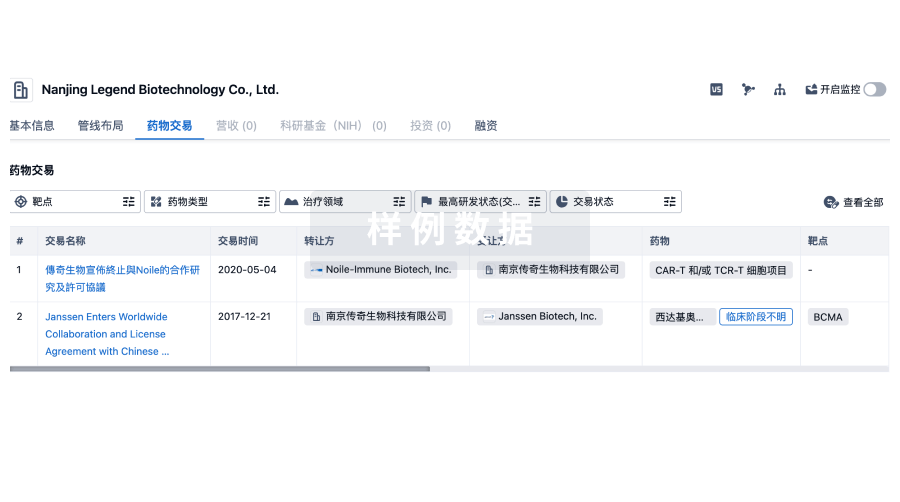
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
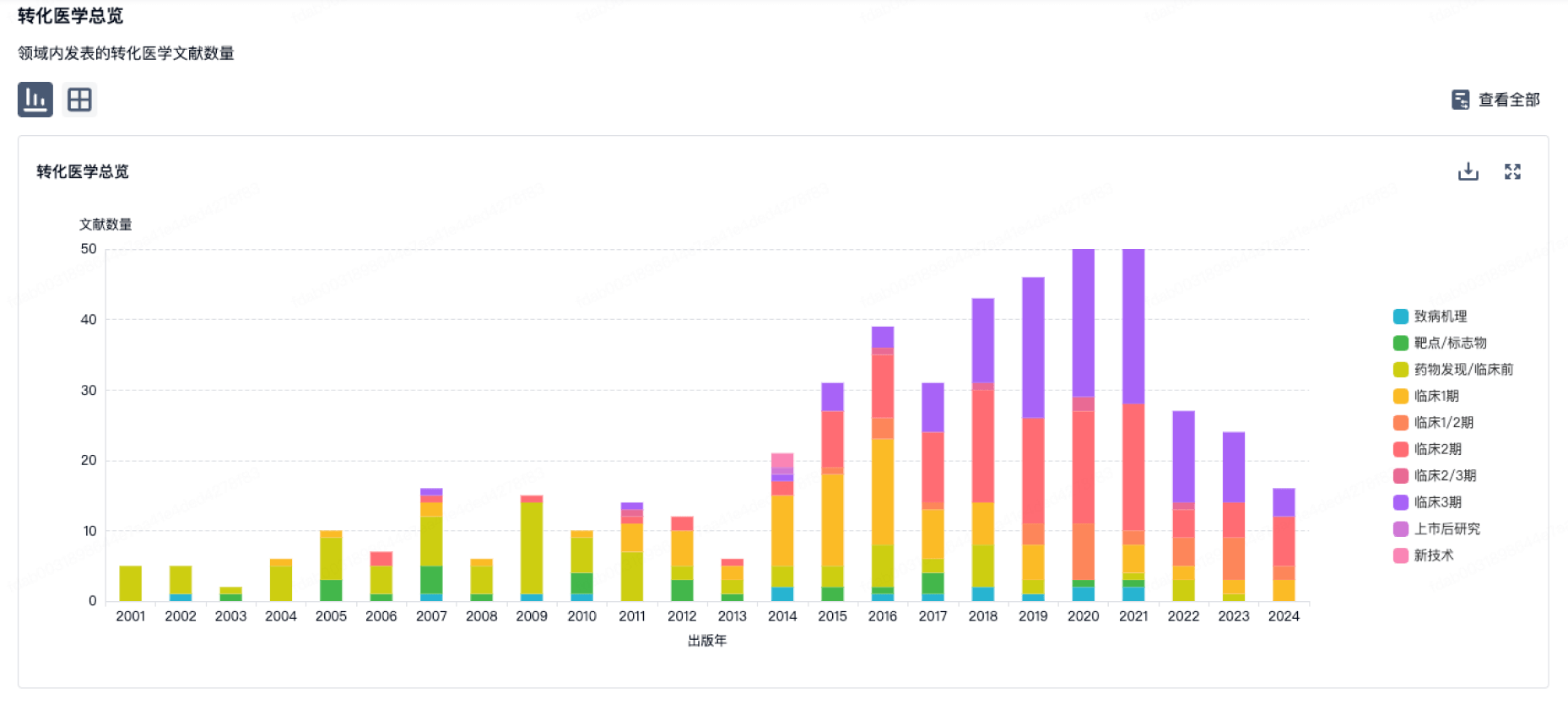
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
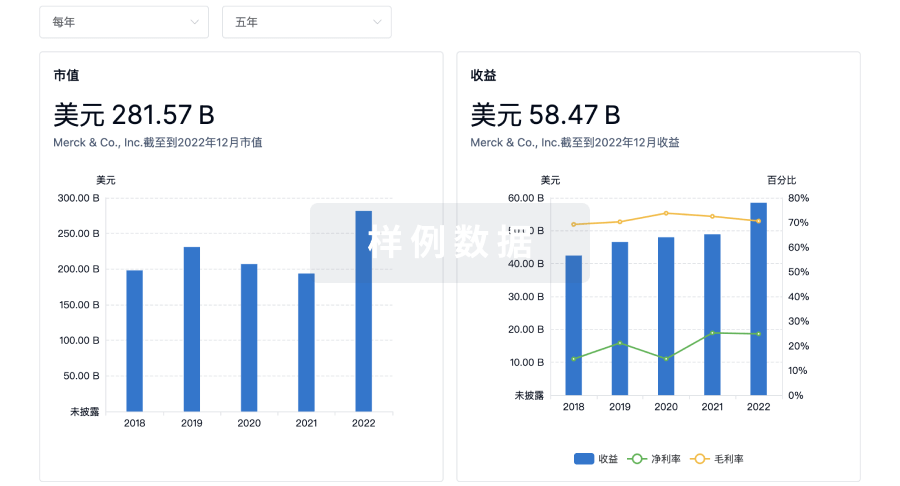
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
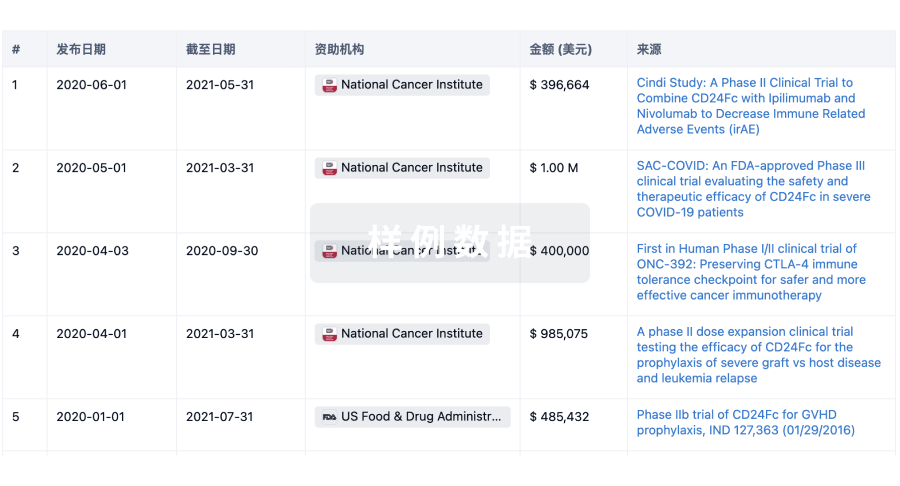
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
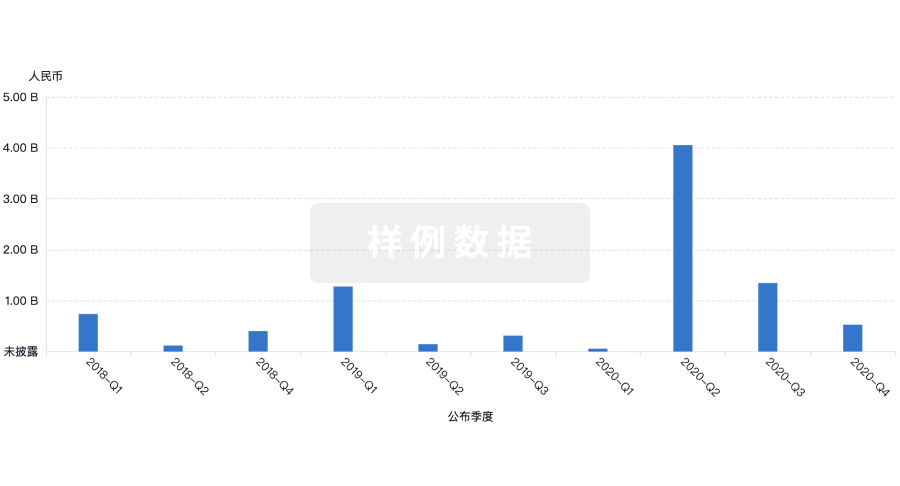
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
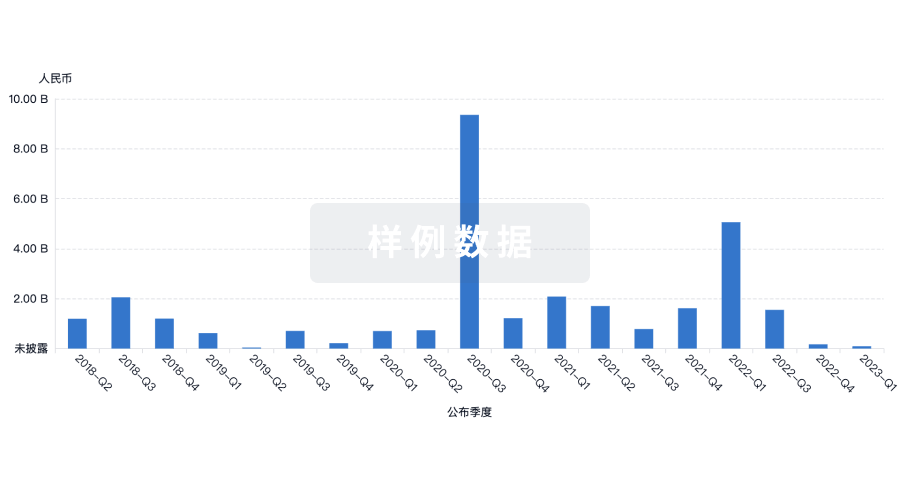
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用