预约演示
更新于:2025-12-09

University of Pittsburgh School of Dental Medicine
更新于:2025-12-09
概览
关联
ChiCTR-OON-17013251
Visual Quality and Corneal Biomechanical Changes after Laser Treatments for Myopia with or without Astigmatism Using FS-LASIK, SMILE and surface ablation; A Prospective Multicenter Clinical Trial
100 项与 University of Pittsburgh School of Dental Medicine 相关的临床结果
登录后查看更多信息
登录后查看更多信息
2026-04-01BIOMATERIALS
Intracortical microstimulation induces rapid microglia process convergence
Article
作者: Cui, X Tracy ; Williams, Nathaniel P ; Vazquez, Alberto L ; Zheng, X Sally ; Kelly, Anna M
Intracortical microstimulation (ICMS) has the potential to restore vision and hearing by stimulating relevant cortical regions in both animals and humans, offering significant clinical promise for sensory restoration. While the neuronal response to ICMS has been extensively studied at the cellular level through electrophysiology and two-photon (2P) imaging, the response of non-neuronal cells, particularly microglia, as well as the effects on blood-brain barrier (BBB) integrity remain poorly understood. In this study, we applied ICMS under 2P imaging in dual-reporter mice, with green fluorescent protein labeling microglia and a red fluorescent Ca2+ indicator labeling neurons. We also monitored vascular dye leakage to assess BBB integrity. Using clinically relevant waveforms, we tested a range of current amplitudes. Surprisingly, we found that microglia responded within 15 min of stimulation by converging their processes (MPC) on areas of high neural activity and the prevalence of MPC increased at higher current amplitudes. Additionally, vascular dye penetration into brain tissue was higher in stimulated animals and increased with current amplitude. This study reveals a rapid microglia and BBB response to ICMS that has not been reported previously, underscoring the need for further research to fully characterize the biological response to ICMS and establish improved safety standards.
2026-03-01PATTERN RECOGNITION
Medical image segmentation using dual-decoder mutual teaching with a mean teacher framework
Article
作者: Wang, Lei ; Chen, Hao ; Zhang, Juan ; Yu, Qingxiang ; Yi, Quanyong ; Jiang, Gaoqiang ; Li, Zhongwen ; Tian, Bihan ; Pu, Jiantao ; Zhou, Jie ; Yu, Shuchen
Accurate segmentation of medical images is essential for many clinical applications and is now typically achieved by training deep learning models on large annotated datasets. However, acquiring sufficient labeled images remains challenging, as pixel-level manual annotations are highly time-consuming. To substantially reduce the manual effort, we developed a novel semi-supervised segmentation method, termed dual-decoder mutual teaching (DDMT), which incorporates a smoothed exponential moving average (sEMA) scheme and a shape consistency constraint (SCC) scheme into the classical mean teacher (MT) framework. The sEMA scheme enhances the stability of the student and teacher models during training, while the SCC scheme ensures consistent learning of shape characteristics across the two different decoders within each model. With these two innovative components, DDMT achieves promising segmentation performance when trained on limited labeled images and abundant unlabeled images. Experiments on public datasets for left atrium, pancreas, and optic disc segmentation demonstrated that DDMT consistently outperforms several state-of-the-art semi-supervised learning (SSL) methods (e.g., MT, UAMT, DTC, and MCNet) across varying proportions of labeled images. The source code is publicly available at https://github.com/wmuLei/ddmt.
2026-02-01JOURNAL OF AFFECTIVE DISORDERS
Dont cry, sweetheart: Moment-to-moment responses to toddler negative affect for mothers with and without depression
Article
作者: Morgan, Judith K ; Griffith, Julianne ; Hendricks, Zachary ; Taraban, Lindsay ; Forbes, Erika E
Depression is common among mothers of young children and has documented impacts on the parent-child relationship and children's emotional development. Examining in-the-moment maternal responses to toddlers' expressions of negative affect can inform our understanding of the specific ways depression may impact mother-child interaction. Among a sample (n = 131) of mothers (44.3 % clinically depressed) and their 1- to 3-year-old children, we examined maternal response to toddler expression of negative affect during a series of interactive tasks. We looked across the spectrum of maternal responses to child negative affect, including responding with comforting behavior, positive affect, neutral affect, and negative affect, and how this differed between mothers with and without depression. Consistent with hypotheses, we found that mothers with depression were less likely to display positive affect and more likely to display neutral affect in the epoch following child negative emotional expression, compared to mothers without depression. Contrary to hypotheses, we found that mothers with depression were similarly likely as mothers without depression to respond to child negative affect with comforting behavior and negative affect themselves. As caregiver response to toddler negative affect shapes the development of early child emotional regulation abilities, better understanding specific patterns of maternal emotional responsiveness to toddler's negative affect can support effective intervention with mothers to help them build their child's emotion regulation abilities, even in the context of maternal depression.
100 项与 University of Pittsburgh School of Dental Medicine 相关的药物交易
登录后查看更多信息
100 项与 University of Pittsburgh School of Dental Medicine 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年02月07日管线快照
无数据报导
登录后保持更新
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
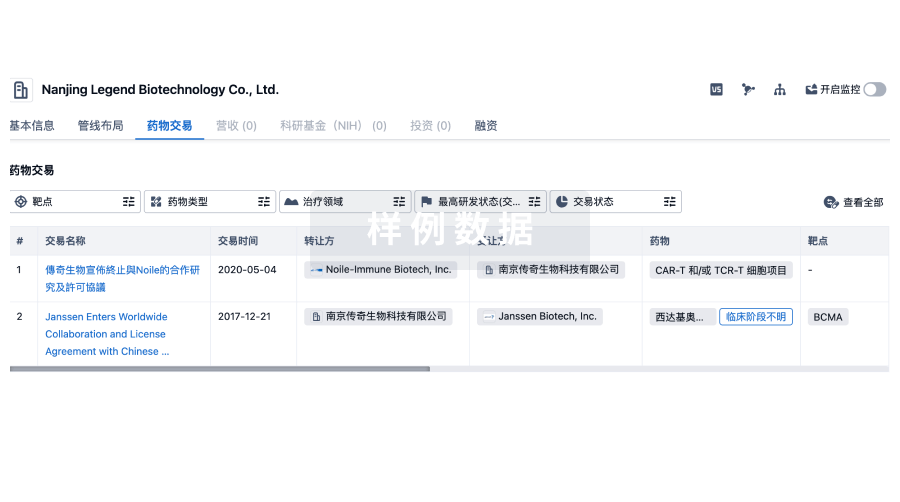
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
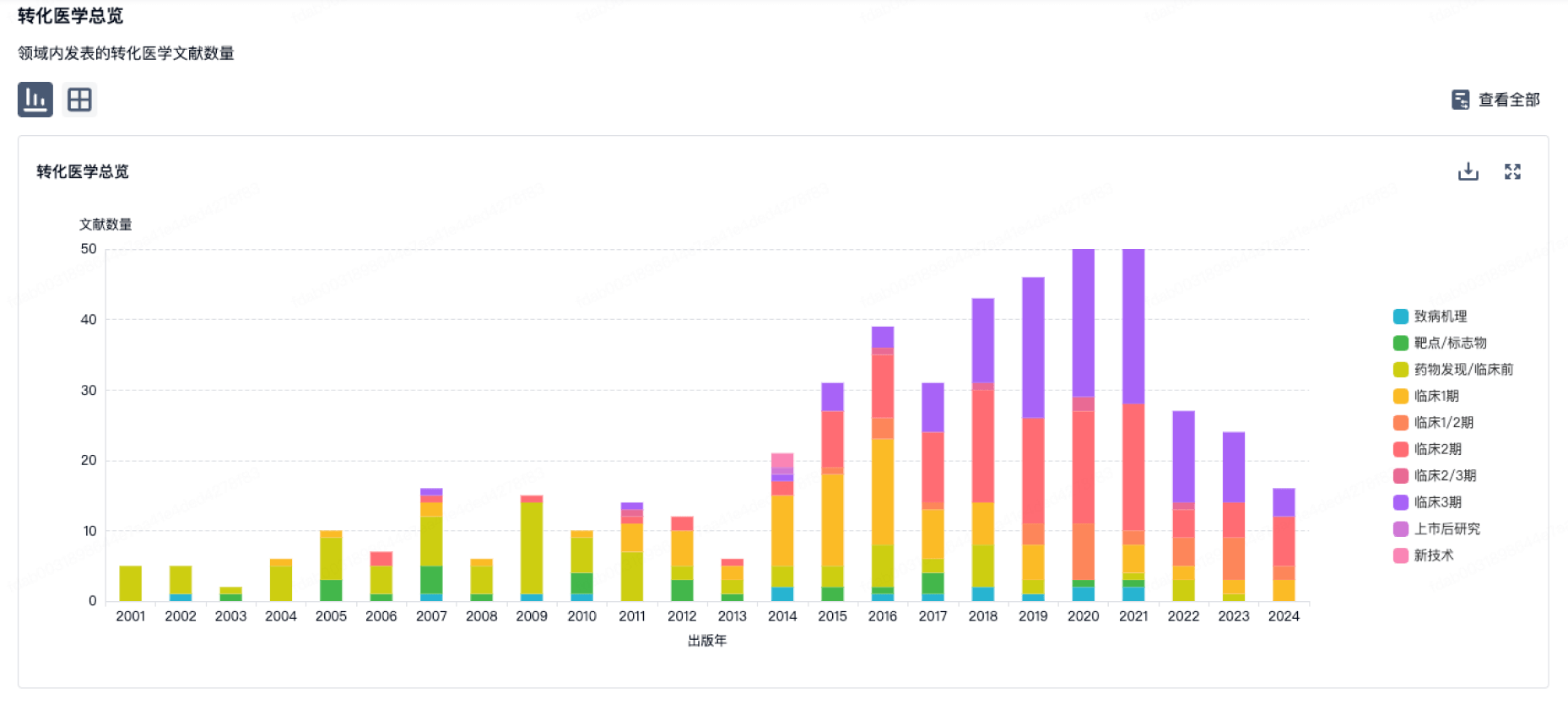
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
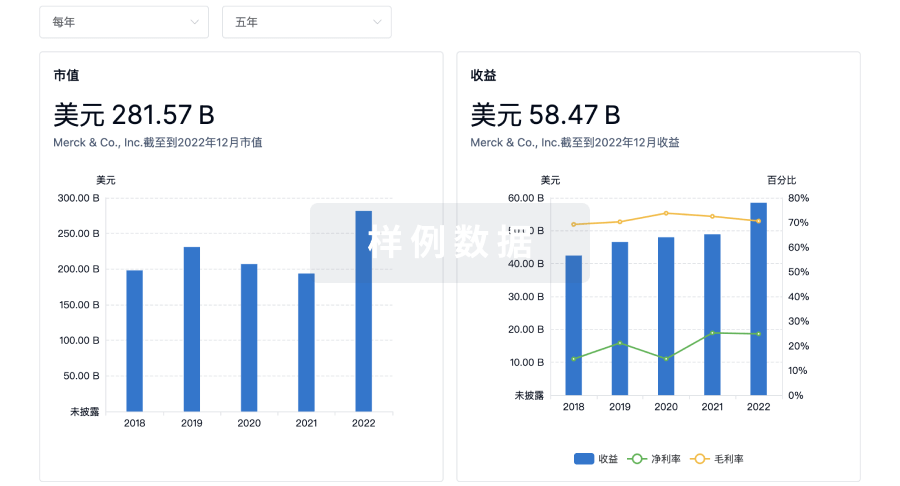
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用