预约演示
更新于:2026-07-18
TTP-273
更新于:2026-07-18
概要
基本信息
药物类型 小分子化药 |
别名 TPP-273、TTP 273 |
靶点 |
作用方式 激动剂 |
作用机制 GLP-1R激动剂(胰高血糖素样肽-1激动剂) |
治疗领域 |
在研适应症 |
非在研适应症 |
最高研发阶段临床前 |
首次获批日期- |
最高研发阶段(中国)终止 |
特殊审评- |



登录后查看时间轴
关联
4
项与 TTP-273 相关的临床试验CTR20210142
[14C]TTP273在中国成年男性健康志愿者体内吸收、代谢和排泄临床试验——[14C]TTP273的人体物质平衡与生物转化研究
主要目的:评价中国男性健康志愿者单次口服[14C]TTP273的物质平衡及生物转化途径。次要目的:评价TTP273在人体内的药代动力学整体特征及安全性。
开始日期2021-01-20 |
申办/合作机构 |
CTR20202349
一项评估2型糖尿病(T2DM)成人患者口服TTP273片疗效、安全性和药代动力学的多中心、随机、单盲、平行组、安慰剂对照Ⅱ期研究
主要目的:评价成人T2DM患者接受TTP273片多次口服给药治疗12周后对糖化血红蛋白(HbA1c)的影响。次要目的:1.评价成人T2DM患者接受TTP273片多次口服给药治疗12周的安全性和耐受性;2.评价成人T2DM患者接受TTP273片多次口服给药治疗12周后对药效学(PD)标志物的影响;3.研究成人2型糖尿病患者口服TTP273片剂的药代动力学特征。
开始日期2020-12-04 |
申办/合作机构 |
NCT02653599
A Phase 2, Randomized, Double-Blind, Placebo-Controlled Parallel-Group Multi-Center Study to Evaluate the Efficacy and Safety of TTP273 Following 12 Weeks Administration in Subjects With Type 2 Diabetes Mellitus on a Stable Dose of Metformin
This trial is a multi-center, randomized, double-blind, placebo-controlled parallel group, Phase 2 study in subjects with Type 2 diabetes mellitus on a stable dose of metformin to evaluate the safety and efficacy of TTP273 versus placebo glucose control and body weight following administration for 3 months.
开始日期2015-12-01 |
申办/合作机构 |
100 项与 TTP-273 相关的临床结果
登录后查看更多信息
100 项与 TTP-273 相关的转化医学
登录后查看更多信息
100 项与 TTP-273 相关的专利(医药)
登录后查看更多信息
47
项与 TTP-273 相关的新闻(医药)2026-05-14
·知和医药
糖尿病(diabetes mellitus,DM)是全球患病率最高的慢性病之一,其中2型糖尿病(type 2 diabetes mellitus,T2DM)患者的数量约占DM患者总数的90%。T2DM的成因复杂,大量研究指出另一种慢性病[肥胖或中心型肥胖(又称内脏型肥胖)]与糖尿病前期(prediabetes mellitus,PDM)患病风险存在显著关联。PDM是DM发展的一个重要中间环节,相关研究显示,若无积极干预,PDM在10年内转化为DM的概率高达70%[1]。随着生活水平的提高,DM与肥胖的全球发病率在几十年间快速增长。据国际糖尿病联盟(International Diabetes Fed-eration,IDF)第10版糖尿病地图数据显示: 截至2021年,全球DM成年患者人数已高达5.37亿,预计2030年该数字将上升到6.43亿,2045年将上升到7.83亿。世界卫生组织公布,截至2022年,已有25亿成人超重,其中8.9亿患有肥胖症。
胰高血糖素样肽-1受体(glucagon-like peptide-1 receptor,GLP-1R)是一种属于B类促胰液素家族的跨膜G蛋白偶联受体(G protein-coupled receptors,GPCR),介导胰高血糖素样肽-1(glucagon-like pep-tide-1,GLP-1)的生理反应。GLP-1R基因表达范围十分广泛,诺和诺德公司开发的单克隆抗体通过靶向GLP-1R的胞外结构域,可以高选择性地检测人类和啮齿动物组织中GLP-1R的表达。这些抗体对人类和非人灵长类动物组织的免疫组织化学研究证实,GLP-1R均存在于脑、甲状腺、心脏、肺脏、胃、十二指肠、胰腺、肾脏、肾上腺、白色脂肪组织中,仅表达水平有所不同。基于其广泛表达的特点,GLP1R的主要功能包括增加胰岛素分泌、抑制胰高血糖素分泌、促进β细胞增殖、抑制细胞凋亡、抑制食物摄入,从而达到血糖控制和减轻体质量的效果。同时还有研究发现其对心血管系统和神经系统的有益反应有望设计出针对非酒精性脂肪性肝炎、帕金森病和炎症的药物。基于以上特点,针对其设计的激动剂往往具有多种理想的药理作用。近年来,随着对GLP-1R结构的认识加深,靶向GLP-1R的小分子药物设计有较大发展,多款药物进入临床阶段。
本文对GLP-1R的结构和激活等方面的研究进展进行综述,并对靶向GLP-1R的小分子激动剂和变构调节剂以及相关天然化合物的开发进展进行讨论,旨在为进一步开发GLP-1R的口服药物提供思路。
1
GLP-1R的结构与激活
GLP-1R主要由三部分组成: 具有亲水性的N端细胞外结构域(extra cellular domain,ECD)、7次螺旋跨膜核心结构域(transmembrane domains,TMD)以及细胞内侧的C末端区域。3个细胞内环(intracellular loops,ICL) ICL1~ICL3和3个细胞外环(extracellular loops,ECL) ECL1~ECL3将7个α螺旋(TM1~TM7)分开[7]。ECD结构相对保守,包括1个N端α螺旋和2个β折叠。5个残基(D67,W72,P86,G108和W110)有助于ECD结构的稳定性。GLP-1R与配体间的相互作用遵循双结构域模型: 肽的中心α螺旋和C末端与受体的N末端ECD结合,随后肽的N末端与受体的TMD结合,从而引起受体活化和G蛋白偶联。TMD与配体N端之间的相互作用对于GLP-1R的激活至关重要。GLP-1结合口袋位于TM束深处,涉及由TM1/2/5/7,ECL1和ECL2组成的广泛相互作用网络。其中His7和Ala8这2个残基位于TM腔深处,对维持GLP-1的功能至关重要。His7通过与Gln2343.37,Val2373.40,Trp3065.36,Arg3105.40和Ile3135.43形成氢键和疏水相互作用从而与TM3和TM5相互作用,而Ala8则与TM7中的Glu3877.42和Leu3887.43形成疏水相互作用。关键结构水还通过与肽上的His7和受体上的TM5形成网络将肽锚定在适当位置。肽结合并与TM核心相互作用后,主要构象变化之一是TM6的细胞质半部分向外开放和TM5更有限的相关运动与TM2,TM23和TM7共同形成一个空腔以容纳G蛋白,由此触发其下游信号级联反应,最终促进胰岛素分泌等效应[7]。
2
GLP-1R介导的关键信号通路
在β细胞中,GLP-1与GLP-1R的结合导致腺苷酸环化酶(adenyl cyclase,AC)激活从而使细胞内环磷酸腺苷(cyclic adenosine monophosphate,cAMP)升高,进而激活下游蛋白激酶A(protein kinase A,PKA)、cAMP激活的交换蛋白2(exchange protein 2 activated by cAMP,Epac2)通路增加胰岛素分泌。此外,GLP-1R的激活是通过抑制K+通道诱导β细胞膜去极化,从而实现电压依赖性Ca2+通道打开和加速Ca2+内流,导致胰岛素从β细胞中胞吐。与此同时,GLP-1与GLP-1R的结合促进胰岛素受体底物2(insulin receptor substrate2,IRS2)信号传导,增强磷酸肌醇-3-激酶(phosphoinositide 3-kinase,PI3K)和细胞外信号调控的蛋白激酶1/2(extracellular signal-regulated kinase 1/2,ERK 1/2)的活性,这些信号介导β细胞增殖和分化以及胰岛素基因的转录。激活后的GLP-1R被G蛋白偶联受体激酶(Gprotein coupled receptor kinases,GRK)磷酸化引起β-制动蛋白(β-arrestin)募集,从而产生其他细胞活动。
3
GLP-1R的偏向激动作用
Jarpe等最早提出了“偏向激动”的概念,指同一GPCR的2种化学性质不同的配体转导和/或调节不同信号通路的能力。不同的激动剂还可以诱导不同的受体内化和运输特征,从而影响与下游信号通路的结合。近年来,偏向激动剂逐渐受到新药研发者的关注,经过“微调”的激动剂有可能会改善现有疗法,例如: oliceridine(商品名为Olinvyk)是首款μ-阿片受体偏向激动剂,对于β-arrestin通路的作用明显弱于传统阿片类药物,因此明显减少了阿片样不良反应,如严重恶心、呕吐、呼吸抑制和成瘾性等。GLP-1R也有相似的偏向激动作用,尽管与相同的受体结合,但不同的GLP-1R配体可以参与选择性途径以引发不同的细胞反应。这种偏向作用很可能与受体-配体结合差异而引起的相关构象变化有关,并且具有很大的开发价值,因为某些配体可能会使特定信号通路的信号传导增强以优化疗效。有研究表明,利用有偏向性的激动剂优先激活一条通路可以提高T2DM和肥胖症等疾病治疗管理中的效益与不良反应比,如一种新型的GLP-1类似物ecnoglutide,与semaglutide相比,虽然在cAMP诱导方面有相似的效力,但其β-arrestin募集少于semaglutide,导致血糖控制和体质量减轻方面表现出更好的疗效。虽然并没有实验证明β-arrestin募集与恶心等不良反应有关,但对cAMP诱导的偏向血糖控制与减轻体质量作用有更好的效果,并且可能提供了一种方法减少这类治疗中的恶心等不良反应。
4
已上市的GLP-1R激动剂药物
目前已上市药物均为肽类药物(见表1),由于注射类药物患者依从性的影响,其发展经历了从短效到长效再到口服的研发历程。虽然口服semaglutide的上市开创了口服剂型的新时代,但口服利用度仅有1%成为其明显短板。各大医药企业从未放弃对注射剂型长效化的追求,2025年上市的依苏帕格鲁肽α(efsubaglutide alfa)的体内半衰期高达204h,未来有望支持每2周一针。但出于对患者依从性的考虑,各研发机构对口服GLP-1R受体药物,尤其是小分子激动剂的开发也已经取得了不错的成果。
5
进入临床试验的小分子GLP-1R激动剂
目前并无小分子GLP-1R激动剂上市,但已有药物进入临床阶段,并展示出了优于传统肽类药物的降糖与减轻体质量效果。
5.1 orforglipron
orforglipron由美国礼来公司(Eli Lilly and Company)研制,通过靶向GLP-1R诱导葡萄糖降低和体质量减轻。orforglipron的发现是通过一种基于细胞的高通量方法,采用检测表达人GLP-1R的LLC-PK1细胞中化合物诱导的尿激酶型纤溶酶原激活剂的表达鉴定GLP-1R的小分子激动剂,再经过逐轮的结构改造优化得到吡唑并吡啶衍生物orforglipron。
体外研究表明,orforglipron是GLP-1R的部分激动剂,偏向于cAMP积累,没有可检测到的β-arrestin募集,这一特征可能增强GLP-1R诱导的葡萄糖降低和体质量减轻作用,在刺激GLP-1R介导的cAMP积累方面比TT-OAD2强得多,并且对其他B类GPCR具有高度选择性。体内研究表明,口服orfor glipron可导致人源化GLP-1R转基因小鼠的葡萄糖降低以及非人灵长类动物的促胰岛素和食物摄入减少作用。
鉴于其良好的药动学特征和疗效,该药物进入了临床研究阶段。在最新的为期26周的旨在评估口服orforglipron治疗T2DM和肥胖患者的疗效和安全性的Ⅱ期临床研究中,在第26周的主要终点评估时,新型口服非肽类GLP-1R激动剂orforglipron在12mg或更高的剂量下,与安慰剂和dulaglutide比较显示出糖化血红蛋白(glycated hemoglobin,HbA1c)和体质量的显著降低。同时,接受不同剂量(12,24,36或45mg) orforglipron治疗的患者均表现出具有统计学意义的剂量依赖性体质量减轻效果。此外,orforglipron的安全性与其他基于肠促胰岛素的治疗方法相似。orforglipron目前已开始进行多个Ⅲ期临床试验,评估口服orforglipron在T2DM和肥胖/超重患者中的安全性和有效性。
5.2 danuglipron
danuglipron由美国辉瑞公司(Pfizer Inc. )研制,是通过直接作用于GLP-1R达到降糖和减轻体质量效果的小分子激动剂。体外研究表明,danuglipron的药理学特征比某些与GLP-1密切相关的肽(如exendin-4和liraglutide)更接近GLP1。其是cAMP产生的完全激动剂,但在Ca2+动员、磷酸化ERK1/2和β-arrestin募集中仅是部分激动剂。体内研究表明,danuglipron具有口服生物利用度,并可有效降低猴子的葡萄糖水平和食物摄入量。
在最新结束的评估danuglipron控制T2DM患者血糖的疗效和安全性Ⅱb期临床试验中,在第16周的评估终点时,对于所有danuglipron剂量,HbA1c和静脉血浆空腹血糖(fasting plasma glucose,FPG)与安慰剂相比显著降低。另一项评估danuglip ron在肥胖患者中疗效和安全性的Ⅱb期临床试验中,2次·d-1服用danuglipron,显示所有剂量的体质量较基线显著降低,平均减少范围为-6.9%~-11.7%。所有剂量的停药率均高于50%,而安慰剂约为40%。该药物已经结束了Ⅱ期临床试验,但是由于其严重的不良反应和高停药率,目前辉瑞公司决定不再继续进行2次·d-1剂量的Ⅲ期临床试验,转而投入1次·d-1制剂的开发。
5.3 TTP273和TT-OAD2
TTP273与TT-OAD2是由美国vTvTherapeutics公司研发的一种口服小分子GLP-1R激动剂。TTP273是TT-OAD2同类类似物,目前TTP273的结构还未披露,但是TTP273表现出cAMP的偏向信号传导,并且在临床相关浓度下没有显著激活ERK通路。在小鼠中,TTP273增强葡萄糖依赖性胰岛素分泌,降低口服葡萄糖耐量实验后的葡萄糖水平并减少食物摄入量。TTP273已完成T2DM的Ⅱa期疗效临床试验,在试验终点时,TTP273降低了T2DM患者的HbA1c,并观察到了体质量减轻的趋势,没有报告恶心病例,表明该系列化合物与orforglipron和danuglipron相比具有潜在的临床优势。然而,TTP273的最新进展受到确定最佳剂量复杂性的阻碍,这可能与缺乏对其作用机制的理解有关。
TT-OAD2是该系列其中一个化合物,对人源化GLP-1R小鼠急性体内活性的评估显示,TT OAD2具有促胰岛素作用,并且这种作用取决于GLP-1R。体外研究表明TT-OAD2是一种低效cAMP积累的部分激动剂,在非常高的浓度(100μmol·L-1)下仅检测到细胞内Ca2+动员和ERK1/2磷酸化的微反应,并且没有检测到β-arrestin的募集。这些数据表明,相对于内源性GLP-1,TT-OAD2偏向于激活cAMP信号传导通路,是GLP-1R的偏向激动剂。
5.4 RGT-075和RGT-1383
RGT1383是G蛋白介导的cAMP信号传导的完全激动剂和β-arrestin募集的部分激动剂。但其没有更多的体内活性数据,可能是由于瑞格公司(Regor Therapeutics Group)转而开发了RGT-075。RGT-075是瑞格公司发现和开发的一种口服(qd)小分子GLP-1R完全激动剂,用于治疗T2DM和超重/肥胖。RGT-075很有可能是RGT1383的类似物,但是具有更高的活性和更好的降糖、减轻体质量效果。瑞格公司已完成了其单次递增剂量和多次递增剂量Ⅰ期临床研究。在迄今为止完成的临床试验中,RGT-075安全且临床耐受性良好。目前正在进行口服(qd) GLP-1R激动剂RGT-075治疗肥胖症的Ⅱ期临床研究。
5.5 DD202-114
DD202-114是通过AIDD/CADD方法设计的一种GLP-1R激动剂,其结构与danuglip-ron十分相似,仅将苯环上的氰基替换为氧杂环丁烷。DD202-114与danuglipron增加cAMP的积累具有相同效力,同时其激活β-arrestin募集的效力也与danuglipron相似,是一个偏向cAMP积累的偏向激动剂。评估其对人延迟整流钾离子通道基因(human ether-à-go-go-related gene,hERG)通道的影响时发现,与danuglipron相比,DD202-114对hERG通道的亲和力较低,表明其潜在安全性更高。并且DD202-114在口服葡萄糖耐量实验中显示出抑制血糖升高和减少人GLP-1R转基因小鼠食物摄入的强大功效,与danuglipron相比,效果持续时间更长。由于DD202-114在体外活性、降低hERG抑制和体内疗效方面表现出卓越的特性,其盐和晶体形式正处于Ⅰ/Ⅱ期临床试验开发阶段,为糖尿病和肥胖症提供了有前途的治疗选择。
5.6 HRS-7535
HRS-7535是我国恒瑞医药有限公司(Hengrui Pharmaceuticals Co. ,Ltd. )开发的新型口服小分子GLP-1R激动剂,在临床前研究中显示出其改善葡萄糖耐量、刺激胰岛素分泌、抑制食欲、减少食物摄入量的能力。目前已经完成了一项单次给药和多次给药的健康受试者Ⅰ期临床试验,结果表明,HRS-7535具有良好的安全性、耐受性及药动学特征,支持1次·d-1的给药方式。值得一提的是,即使在基数较低的健康受试者中也观察到了体质量降低。目前该药正处于Ⅲ期临床研究中。
5.7 GSBR-1290
GSBR-1290是一种小分子GLP1R激动剂,与人GLP-1R具有高结合亲和力。GS BR-1290强烈激活cAMP通路,而不诱导β-arrestin募集,这表明其是一种完全偏倚的激动剂。GSBR-1290在刺激胰岛素分泌、改善葡萄糖耐量、减少食物摄入和减轻体质量方面表现出强大的体内功效。最新一项对GSBR-1290在T2DM和肥胖患者的安全性和耐受性的Ⅱa期临床试验中,在T2DM患者中,12周时HbA1c(-1.01%~-1.02%)和体质量(-3.26%~-3.51%)有统计学意义的降低; 在肥胖患者中,8周时体质量有统计学意义的降低(-4.74%),且大多数报告的不良事件为轻度或中度。值得注意的是,在第8周时,GSBR-1290120mg剂量的体质量减轻效果与orforglipron24/45mg剂量相当。由于其良好的临床结果,已经开展了更长期的Ⅱ期临床试验。
5.8 SAL0112
SAL0112是以GLP-1R偏向激动剂为目标而发现的偏向激活GLP-1R的cAMP信号传导通路苯并咪唑类化合物。以danuglipron(EC50=0.42nmol·L-1)和liraglutide(EC50=0.46nmol·L-1)作为对照,SAL0112(EC50=1.27nmol·L-1)以高效力增加cAMP的产生,并且没有观察到脱敏现象。对其他信号通路的活性进行测试发现,SAL0112对Ca2+内流、磷酸化ERK1/2、β-arrestin募集和受体内化的效力都很低。SAL0112可导致小鼠体质量、口服葡萄糖耐量实验后的血糖水平、HbA1c水平显著降低并且可以改善胰岛素抵抗。值得注意的是,其增加了外周脂肪细胞密度并改善了肝脂肪变性。SAL0112的疗效与danuglipron和liraglutide相当,并且没有显著缺陷,有很高的临床价值,目前该药正在进行评估T2DM成人患者口服SAL0112片的有效性、安全性和药动学的Ⅱ期临床研究,但目前并无结果披露。
6
天然产物中的GLP-1R激动剂
除虚拟筛选外,天然产物中的活性成分也是药物发现的重要来源。虽然已有不少团队对天然产物中的GLP-1R激动剂进行了探索,但是大多处于临床前阶段,并且对其是否具有偏向性的研究少之又少,所以本文仅综述了天然产物中GLP-1R激动剂的作用与作用机制,为小分子GLP-1R的开发和结构改造提供参考。
6.1 黄酮类
Fang等验证了loureirin B具有降低血糖并减少胰岛损伤的作用。loureirin B是一种二氢查尔酮类似物,是血竭(Sanguis draconis)的主要活性成分之一。体内实验中,将loureirin B作用于糖尿病小鼠模型,观察到糖尿病小鼠的血糖降低。体外实验中,用loureirin B处理Ins-1细胞,结果显示,loureirin B可以促进细胞增殖,减少Ins-1细胞凋亡。该团队进一步对其机制进行了研究,研究发现loureirin B与GLP-1R结合后,通过激活IRS2-AKT PDX1信号通路促进胰岛素分泌,同时抑制K+离子通道,增加细胞内Ca2+浓度,进一步促进胰岛素分泌,显示loureirin B可能是潜在的K+通道抑制剂。目前该团队正在进行loureirin B的结构优化,以探索loureirin B来源的小分子GLP-1R激动剂。
Wang等发现puerarin可以改善糖尿病小鼠的高血糖症,并对其机制进行了研究。puerarin是从葛根(Pueraria lobata)中提取的一种类黄酮物质,将其作用在高脂饮食(high-fat diet,HFD)诱导的糖尿病小鼠后,患病小鼠的葡萄糖稳态改变。并且在puerarin治疗的HFD小鼠胰管中观察到新β细胞形成的标志物(胰岛素、胰岛素启动因子1和神经元生成因子3)。对其机制进行研究,发现puerarin与GLP-1R结合后可能激活Wnt/β-catenin和JAK2/STAT3信号通路促进新β细胞的生成,从而产生胰岛素,达到降血糖效果。
6.2 木脂素类
Shang等通过细胞膜层析(cell membrane chromatography,CMC)、钙成像和分子对接技术从中药分子库中筛选出schisandrin B。分子对接结果表明,schisandrin B位于GLP-1R蛋白的活性口袋中,与GLP-1R蛋白活性位点的Ser72和Leu256连接,并且形成多个分子间氢键,与GLP-1R有很强的结合作用。在体外实验中,schisandrin B可以刺激β-TC-6细胞的胰岛素分泌。schisandrin B通过结合GLP-1R激活下游cAMP/PKA信号通路并增加细胞内Ca2+,促进胰岛素释放。在进一步的研究中发现,该化合物还可降低胰岛损伤并改善糖尿病小鼠的血脂水平和脂质代谢。这些结果表明schisandrin B是潜在的GLP-1R激动剂先导化合物,对其进行结构改造可能得到新型的GLP-1R激动剂。
7
GLP-1R变构调节剂
变构调节剂分为增强活性的正变构调节剂(positive allosteric modulators,PAMs)、降低活性的负变构调节剂(negative allosteric modulators,NAMs)和不改变活性但与其他变构调节剂竞争结合位点的中性调节剂(neutral allosteric ligands,NALs)。一般来说,纯变构调节剂单独作用时并不影响受体活性,但有些变构调节剂对受体表现出内在活性,并可增加或减弱正构配体与受体结合的信号传导,这类变构调节剂被称为变构激动剂或变构反向激动剂。近年来发现有一些变构调节剂可以增强或减弱正构配体与受体结合后的一部分信号通路,这类变构调节剂被称为偏向变构调节剂(biased allosteric modulators,BAMs)。
如上文所述,GLP-1R的偏向激动剂可以偏向激动有益于胰岛素分泌的信号通路而不激动或较弱激动β-arrestin募集从而增加其降血糖或减轻体质量效果。同理,与GLP-1R的PAMs相比,BAMs可以增强或减弱特定的信号传导通路,使无偏向作用的GLP-1R激动剂发挥偏向激动的效果甚至进一步增强偏向激动剂的偏向激动作用。
7.1 GLP-1R的PAMs
Decara等对Vivia Biotech化学库进行高通量筛选,发现了化合物9(V-0219)。V-0219能够促进葡萄糖依赖性GLP-1诱导的β细胞分泌胰岛素、增强GLP-1R激动剂exendin-4诱导的饱腹感、诱导对葡萄糖负荷的最佳反应、减少Wistar大鼠高血糖的时间。但目前暂时没有支持V-0219偏向激动的数据。
Campbell等对2-氨基噻吩(2-aminothiophene,2-AT)类PAMs进行了进一步改进,发现了一类新型的2-AT类PAMs,其中化合物6,7,23,24以剂量依赖的方式显示出显著的变构效应。使用INS-1832/13细胞在含/不含GLP-1条件下通过体外胰岛素分泌测定4种选定化合物(6,7,23和24)的胰岛素分泌活性,与单独的GLP-1(10nmol·L-1)相比,在16.7mmol·L-1葡萄糖存在下,每种化合物与GLP-1的组合刺激胰岛素分泌量都超过2倍。在没有GLP-1的情况下,与载体对照相比,每种单独化合物也较弱刺激了胰岛素的产生,说明每种化合物都是GLP-1R的弱变构激动剂。但目前该类化合物还无数据支持其是否具有偏向作用。
据报道,在存在20%最大有效浓度GLP-1(9-36)的情况下,使用表达人GLP-1R的HEK293细胞筛选多样化的220000个化合物库发现,一种已知的MET激酶抑制剂8是GLP-1R的弱PAMs。通过对构效关系的研究,并进行相关改造,发现了LSN3160440。LSN3160440可以增强GLP-1(9-36)引发GLP-1R诱导的cAMP信号传导效力。然而,在啮齿动物中观察到LSN3160440较差的药动学特性,特别是在大鼠中观察到高清除率[Cl=(78±10) mL·min-1·kg-1]和高分布容积[Vdss=(18±1) L·kg-1],因此Willard等[27]对其进行进一步的改造发现了LSN3318839。LSN3318839与LSN3160440的效力相似,但具有更好的药动学特性,并且在对信号传导通路偏向的实验中也发现了其对于cAMP通路的明显偏向而非β-arrestin募集。
Mendez等在过表达人GLP-1R的HEK293细胞系中使用同源时间分辨荧光cAMP测定(homo-geneous time-resolved fluorescence cAMP assay,HTRF cAMP)对其化合物库进行HT筛选,命中了化合物8,然后对化合物8进行结构优化发现了化合物19。化合物19能够将活性显著降低的代谢物GLP-1(9-36)转化为有效的配体,使其能够以与GLP-1本身类似的方式激活GLP-1R。并且在分散的大鼠胰岛中,化合物19可以明显改善GLP-1(9-36)介导的葡萄糖刺激的胰岛素分泌。尽管化合物19是一个高效的变构激活剂,但仍然需要外源性添加GLP-1(9-36)才能在体内引起对葡萄糖稳态的显著反应。7.2偏向cAMP信号传导的变构调节剂Xin等[29]利用双击反应平台,结合亲和选择质谱法合成和筛选了38400种三唑化合物,鉴定了GLP-1R的一系列PAMs,其中化合物3-24和化合物3-20均显著增强GLP-1(9-36)引发的GLP-1R依赖性cAMP信号传导效力。并且对GLP-1肽募集β-arrestin的活性研究发现,2种PAMs在GLP-1(9-36)或GLP-1(7-36)的β-arrestin募集中没有使信号发生变化,表明这些PAMs对GLP-1作用的增强完全偏向于cAMP信号通路。
Wang等通过进行基于结构的高通量虚拟筛选,选择24种结构多样的药物样化合物进行生物测定以发现新的GLP-1R PAMs。化合物L7可以增加GLP-1与GLP-1R的受体亲和力,并且增加高浓度下cAMP的积累。通过进行构效关系研究,设计并合成了一系列新型苯甲酰胺作为化合物L7的类似物。结构优化从而发现了L7-028,该化合物将GLP-1的结合亲和力从7.6nmol·L-1提高到2.9nmol·L-1,并且增强了GLP-1引发的cAMP信号传导。其增加受体亲和力的机制如下: L7-028与受体结合后,与位点处的Tyr2413.44b,Ile3175.47b,Phe3245.54b,Ile3576.46b,Leu3606.49b和Gln3947.49b相互作用,增加TM6螺旋和其他跨膜螺旋之间的距离,以打开GLP-1结合口袋,从而促进配体识别。根据这一特点又筛选出活性更好的2个化合物C5[EC50值为(1.59±0.53)μmol·L-1]和C16[EC50值为(8.43±3.82)μmol·L-1]。可惜的是,在信号传导的偏向性研究中发现,L7-028,C5,C16都不同程度地对β-arrestin1/2募集表现出显著影响,这可能会导致激动剂药物的疗效降低或不良反应的增强。
8
总结与展望
GLP-1R作为治疗T2DM的重要靶点,其靶向药物因卓越的疗效备受瞩目。虽然肽类药物在该领域取得了显著成果,但其固有的局限性推动了小分子激动剂的研发热潮。本文详细回顾了目前已知的GLP-1R小分子激动剂,分析了其研发背景、结构特点及生物活性,为克服多肽类药物的不足提供了新的方向。小分子药物凭借其稳定性和可口服性,展现出巨大的发展潜力,为T2DM的治疗带来了新的希望和研究思路。
展望未来,随着药物化学、计算机模拟技术以及生物活性筛选技术的发展,小分子GLP-1R激动剂有望突破现有技术瓶颈,成为治疗糖尿病、肥胖等代谢性疾病的重要工具。未来小分子GLP-1R激动剂的研究将会集中在提高小分子药物的活性和选择性、降低毒副作用以及设计双重或多重机制的药物(如GLP-1R/GIP双激动剂)。综上所述,小分子GLP-1R激动剂具有改变代谢性疾病治疗领域中治疗模式的巨大潜力,将会为患者提供更多高效的治疗选择。
来源:凡默谷
免责声明:
本文信息部分内容来自网络文章,不保证所有信息、文本、图形、链接及其他项目的绝对准确性和完整性,故仅供访问者参照使用。如您(单位或个人)认为本文某部分内容有侵权嫌疑,敬请立即通知我们,我们将在第一时间予以更正或删除。以上声明之解释权归本公众号所有。法律上有相关解释的,以中国法律之解释为基准。如有争议限在我方所在地司法部门解决。谢谢。
2026-03-27
·笛杨投研
备注:本文绝不构成任何投资建议、引导或承诺,仅供学术研讨,请审慎阅读。市场有风险,投资需谨慎!
2026年第一季度还未落幕,全球减肥药市场就已掀起白热化竞争浪潮,各类创新药、仿制药轮番登场,产业链上下游企业纷纷发力,行业格局持续重塑。
其中,礼来旗下首创GIP/GLP-1/胰高血糖素三重激素受体激动剂瑞他鲁肽(retatrutide),凭借惊艳的三期临床数据成为全球医药界关注焦点。该药物在2型糖尿病患者治疗中,实现糖化血红蛋白A1C最高降幅1.9%,患者9个月体重平均下降15.3%,凭借强效降糖与显著减重的双重核心优势,展现出极高的临床应用价值与广阔的市场发展空间,也进一步推动了减肥药赛道的热度攀升。
去年年底替尔泊肽、司美格鲁肽等主流减肥药,在各大医药电商平台开启促销模式,正式打响减肥药市场“以价换量”的竞争号角,国内外药企纷纷入局,市场争夺愈发激烈。
替尔泊肽加速市场扩张,司美格鲁肽全力稳固现有市场份额;2026年1月,替尔泊肽、依苏帕格鲁肽等多款国产GLP-1类药物成功纳入国家医保目录,更是让行业价格竞争进入新阶段。
关注我,每天梳理市场热门题材与核心公司逻辑。
结合2026年最新市场动态,从业务核心度、行业影响力等维度,梳理出A股及产业链高度关联的港股市场中,减肥药(主打GLP-1类药物)产业链十大正宗企业,按创新药研发、原料药/中间体供应、制剂/仿制药、产业链配套的业务逻辑排序如下:
1. 华东医药(000963)
作为国内创新药研发领域的核心企业,华东医药在减肥药赛道布局领先。其旗下利拉鲁肽(商品名“利鲁平”)是国内首个获批上市的GLP-1类减肥药,目前减肥适应症仍在持续研发推进中;同时,公司重点布局GLP-1/GIP双靶点创新药,代表性产品TTP273研发进展顺利。依托糖尿病药物与减肥药双适应症的协同发展优势,华东医药在商业化落地方面走在行业前列,是国内减肥药研发与市场化的标杆企业。
2. 恒瑞医药(600276)
恒瑞医药凭借顶尖的自研实力,在减肥药创新药赛道占据重要地位。公司自主研发的GLP-1/GIP双靶点药物HRS9531已进入临床阶段,潜在适应症重点覆盖肥胖症,未来市场潜力十足。作为国内医药研发龙头,恒瑞医药拥有完善的药物研发管线、雄厚的技术储备与临床研发能力,全方位的管线布局为其在减肥药领域的发展筑牢根基,后续研发成果值得期待。
3. 信达生物(01801.HK)
虽为港股上市企业,但却是GLP-1类减肥药研发的行业龙头,与A股产业链关联度极高。公司核心产品玛仕度肽属于GLP-1R/GCGR双靶点药物,二期临床数据表现优异,减重效果突出,在同类在研药物中竞争力强劲,是国内双靶点减肥药研发的佼佼者,未来有望凭借出色的临床效果抢占市场份额。
4. 诺泰生物(688076)
诺泰生物是减肥药原料药及中间体环节的核心供应商,专注于司美格鲁肽、利拉鲁肽等主流GLP-1类减肥药的原料药及中间体生产,是诺和诺德、礼来等国际巨头的重要合作伙伴,海外订单占比居高不下。公司产品已通过FDA、EDQM等权威认证,具备规模化、标准化的生产能力,在原料药供应环节拥有不可替代的行业地位。
5. 圣诺生物(688117)
圣诺生物聚焦多肽类药物CDMO服务,核心为利拉鲁肽、司美格鲁肽等减肥药提供从临床阶段到商业化阶段的全流程定制化服务。公司凭借领先的多肽合成技术,攻克多肽药物生产的技术难题,合作客户涵盖多家国内外知名药企,在CDMO细分领域技术优势明显,是产业链中游的关键配套企业。
6. 翰宇药业(300199)
翰宇药业是国内多肽原料药领域的产能龙头,其利拉鲁肽原料药已获得欧洲上市许可,顺利打开海外市场;同时积极布局司美格鲁肽仿制药研发与生产,全方位覆盖GLP-1类减肥药原料药及仿制药业务。凭借大规模的产能储备与成熟的生产工艺,翰宇药业在国内多肽减肥药原料供应环节竞争力突出。
7. 通化东宝(600867)
通化东宝是传统胰岛素领域龙头企业,近年来积极向减肥药赛道延伸转型。公司旗下利拉鲁肽注射液(肥胖适应症)已处于申报上市阶段,同时同步布局GLP-1类创新药研发。依托在糖尿病领域积累的品牌、渠道与研发经验,通化东宝在减肥药仿制药与创新药布局上具备天然优势,转型进展备受行业关注。
8. 联邦制药(03933.HK)
作为港股上市的制剂与仿制药龙头,与A股减肥药产业链协同性极强,公司利拉鲁肽仿制药已成功获批上市,同时司美格鲁肽相关产品处于在研阶段。凭借成熟的制剂生产工艺与市场化推广能力,联邦制药在国产GLP-1类减肥药仿制药市场占据重要席位,持续加码减肥药赛道布局。
9. 药明康德(603259)
药明康德是全球CRO/CDMO行业龙头,也是减肥药产业链不可或缺的配套企业,为全球各大药企的GLP-1类药物提供临床前研发、生产定制等全链条CDMO服务。依托全球化的服务网络、顶尖的研发与生产平台,公司订单确定性高,业务量持续稳定增长,为全球减肥药创新研发提供关键技术与服务支撑。
10. 蓝晓科技(300487)
蓝晓科技聚焦减肥药产业链上游配套领域,专业提供多肽固相合成载体,该产品是GLP-1类药物生产的核心原材料之一。公司在该细分领域技术壁垒极高,全球市场占有率领先,凭借独家核心技术成为多家药企GLP-1药物生产的核心供应商,是产业链上游不可忽视的优质企业。
风险提示:本文内容来源网络,绝不构成任何投资建议、引导或承诺,仅供学术研讨。股市有风险,决策需谨慎
整理码字不易,方便的点个红心,谢谢!
上市批准临床3期申请上市
2026-03-04
从大模型的出现到现在,不管是日常简单信息检索还是专业信息的收集和研究,搜索引擎用得已经越来越少了。因此自己觉得非常有必要系统地对比和评价下国产大模型在执行自己专业领域的不同难度的任务时的具体表现。
本次测评中,选取的模型包括:
1. 腾讯元宝 - deepseek(联网、深度思考)
2. 阿里千问(Qwen3.5 Plus深度研究,每日4次免费报告生成)
3. 豆包(深入研究,生成报告暂时没遇到限制)
4. Kimi(K2.5思考,K2.5 Agent每日有3次免费报告生成机会,但实际上因为网络堵车不订阅无法使用)
以上四个是目前不订阅即可使用的最新模型,其中只有Kimi在测评任务过程中弹出过流量限制降级为K2.5快速并询问是否升级订阅。通过元宝接入的deepseek比直接使用deepseek在回答上会更加详尽(token限制更少),并且不会出现网络拥堵。千问和豆包都有生成完整报告的功能,生成速度上豆包快于千问,元宝的deepseek没有这个功能。而Kimi虽然有,但因为网络拥堵,免费的3次生成机会不升级套餐没法使用。
测评共三个任务,分别涉及行业热点事件解读、临床数据解读和竞争格局分析,三个任务都和GLP-1相关,分别侧重于信息收集的准确性和完整性、基于信息的发散能力以及信息挖掘和整合能力。prompt如下:
任务一(热点事件解读):你现在是生物医药投资领域的专业研究员,我想对行业热点事件进行深入解读, 1月30日石药集团公布和阿斯利康的重磅BD后股价放量大跌,帮我解读背后的原因。
任务二(临床数据解读):诺和诺德近期公布了CagriSema和礼来Zepbound的头对头临床数据,帮我整理公布的结果并进行前瞻性解读,尽可能引用官方发布的数据或文献,尽可能使用英文数据源。
任务三(竞争格局分析):在诺和诺德公布数据的基础上,帮我整理当前减重领域在研疗法的竞争格局,结果通过表格展示,最左边两列为Wegovy和Zepbound的三期临床的给药形式、有效性、安全性、减重适应症获批时间、获批具体适应症,右边五列为你认为当前有效性最好的5款候选药物的相应数据,未获批的产品用预期获批时间、适应症代替,在最后一行标注信息来源,尽可能引用官方发布的数据或文献,尽可能使用英文数据源。
测评中,上述三个任务在同一个对话窗口让模型依次完成。
任务一是最简单的,因为事件发生在一个月前的1月30日,并且引发了行业内广泛的讨论。简单搜索可以获得大量不同来源的事件解读。模型只需要对内容进行归纳总结后输出即可。
四个模型对BD交易内容的总结以及大跌原因的归纳(资本市场提前计价、交易结构上的不确定性、GLP-1竞争格局激烈、企业基本面问题、行业逻辑的变化)在信息准确性和要点覆盖上都很全面。
元宝对回答中的每一个观点都给出了引用,其中包含微信公众号的内容。让我惊喜的是回答中两次引用了我石药重磅BD收获12亿美元首付款,股价为什么大跌?中的观点,而意外的是引用来源是我在雪球上转载的内容而非公众号的原文,这点元宝和自己腾讯系的生态还可以磨合地更好一些。
Kimi的表现和元宝差不多,但增加了BD对新诺威的影响,并进行了一定的拓展分析。
千问生成的报告可以直接导出为word,全文共4100字,106条引用,在内容深度和引用广度上是远超不具备深度研究能力的元宝和Kimi的。千问对外资机构持股、研报态度信息做了整理,这也是元宝结果中不具备的:
千问的美中不足在于,对于部分信息有一定的‘AI幻觉’。这是现阶段生成式AI在具备较强推理能力但又缺乏行业通识的情况下很容易出现的问题。比如下面这段对于交易结构问题的描述,终止条款和销售分成机制披露在石药的BD中属于行业常规的条款表述,不应该作为风险点单独放在这里。第5点没有引用,应该是模型自己推理的:
最后是豆包,豆包生成了13000字的完整报告,共130条引用。相比千问,豆包虽然在细节上也有细微瑕疵(阶段最低股价9.12港元)以及在归纳也存在一定‘幻觉’但它生成的报告排版更加清晰,基本上直接可用。内容上,豆包对股价异动表现、市场分歧、石药的战略转型、GLP-1赛道竞争态势、同类BD(恒瑞和GSK等)、机构行为、技术指标变化等内容都做了深入分析,甚至对事件前后的市场反应也做了细致的复盘:
豆包让人眼前一亮的还有在生成报告的同时,会附带生成一个html网页文件,一张图将报告内容进行了可视化(千问也可以通过切换深度研报模式将文本报告更好地可视化,但是元素没有豆包丰富),报告最后还给出了精简后的对不同类型投资者的投资建议:
在信息收集并梳理成逻辑清晰的报告这个任务上,除了一些难以避免的过度总结(即便是human研究员也很难),豆包的表现几乎是无可挑剔的。豆包的报告是带着明确观点和态度的汇报口吻,而非早期生成式AI的观点罗列模式,这点已经让我很难看出这份报告是不是AI生成的了。对打工人来说,好消息是文中的观点更多是‘总结’出来的,而非‘推理’出来的。市场的情绪和行为本质也还是人的情绪和行为(不知道还能维持多久)。所以行业通识+观点输出能力是保住工作的救命稻草,但是entry level的data工作可能真的要逐渐消失了。
任务二主要测评不同大模型对临床结果的前瞻性看法,难点在于发散能力。在这个任务上,四个模型在临床数据总结的全面性和准确性上都没有大的问题。元宝额外整理了CagriSema过往在REDEFINE1/2的结果以及在心血管适应症上的收益,这为其后续在前瞻性分析中指出CagriSema潜在可能可以在代谢综合管理中实现差异化定位奠定了基础。而Kimi只中规中矩整理了REDIFINE4的结果,因此在后续分析中miss了这个点。但是相比元宝,Kimi在市场变化、分析师观点以及临床选择上给出了更多信息,综合下来我觉得各分千秋。
千问是四个模型中唯一将前瞻性解读做成了销售额预测的,整体感觉千问的报告更像是在元宝、Kimi这类快速回答的基础上,对每个细分点补充了更详实的表述。在发散性上,千问的深度报告相比元宝和Kimi快速回答的结果并没有显著的提升,在其他代谢适应症的分析覆盖上甚至不如元宝。千问花了很大篇幅阐述口服和三靶点的在未来市场的主导地位,但是似乎完全miss了对便利性和疗效平衡、安全性以及市场定位的讨论,这可能是源于对某几篇高权重引用的过度依赖。
豆包在内容深度上依然是四个模型中最出色的,除了对剂量和人群的细化分析,它还加入了和其它GLP-1类药物的横向对比,但在对比药物的选取上我觉得还可以做得更好(报告选取了利拉鲁肽、贝那鲁肽和玛仕度肽,除信达管线均不是潜在的有利竞争者)。在其他代谢适应症的谈论中,豆包没有挖掘到REDIFINE1的post hoc analysis也没有将司美格鲁肽的心血管获益和CagriSema进行关联,因此在心血管获益对比中没能给出明确的结论。豆包做得非常好的是对应用场景的划分,毕竟‘推荐算法’是字节的强项:
从这个任务中我们可以看出,数据源的数量和质量直接影响了大模型生成的深度报告输出质量。显然,2月23日诺和诺德公布的这个临床更新并没有像任务一中石药的事件一样在医药投资圈引发广泛讨论,而英文互联网上公开可得的分析远不如国内丰富,所以在深度报告中千问和豆包的报告质量相比任务一都有不小的下滑。
任务三除了需要严格按照提示词生成对比表格,更具挑战的是在数据搜集的基础上给出竞争格局中排名前五的管线。在这个任务中,元宝是唯一完全按照提示词要求编制表格的。Kimi在表格中添加了对比作用机理、样本量、基线BMI和心血管结局实验结果的内容,虽然不是我要求的,但对于这个任务本身倒是可接受的发散。豆包在深度报告模式下只生成了文本报告,没有生成表格,并且在报告中出现了基本事实错误,将礼来的口服管线Orforglipron送给了辉瑞(辉瑞的是Danuglipron,长得很像,但已经终止开发):
切换为快速生成的专家模式后,豆包正确地生成了表格,并只额外补充了作用机制这一行。千问在这个任务中生成的表格完全没有按照提示词来,表格只对比了两款候选药物,表格中出现了重复内容,并且将药品名称放在了第一列,而非提示词要求的第一行。切换为深度思考模式后,千问给了我全英文的结果,即便如此,表格中替尔泊肽出现了两次,Retatrutide有归纳错误,候选药物中还包含了已经终止开发的TTP273:
在对比的候选药物选择上,元宝给出的是Retatrutide(礼来三靶点)、Orforglipron(礼来口服)、AMG133(Amgen双靶点)、Survodutide(BI/Zealand双靶点)和CagriSema(诺和诺德联用)。对于疗效排名前五的选取,由于管线药物无法直接跨研究对比,这里是可以有一定主观性的,不同研究人员也会有自己不同的选择,但是提示词给的是减重有效性最好的前五,那么在不加限定词的情况下,口服GLP-1就不应该包含在内,这点四个模型全部miss。此外,AMG133按临床表现也不应该进入这个列表。Retatrutide和CagriSema是最无争议应该被包含的,这点除了千问都做到了。Survodutide是可选之一,Kimi选择了上述三个,其余两个分别是是礼来的Orforglipron和信达的玛仕度肽,比元宝的选择稍微好一点点。千问在文本中给出的前五是罗氏的CT-388、恒瑞HRS9531、玛仕度肽以及诺和礼来的口服,除了口服两款其余都能接受。最后,豆包在专家模式下给出了Retatrutide、CagriSema、Orforglipron、VK2735以及Petrelintide,同样除了口服其余都能接受。
在最后这个任务中,如果先给出大致的范围(比如药企名称)然后通过提示词优化输出结果,几个模型应该都能很快给出预期中的表格。比较有意思的是豆包在整个测评过程中像极了打工人,在第一个小任务中强势输出1.3万字深度报告,然后就好像累了倦了一般在后面两个任务中逐渐开始摸鱼。
作为任务测评的结尾,这里放上豆包在任务三中总结出来的GLP-1减重疗效的对比表格:
总结
对于简单的事件回顾,四个国产模型都能快速让我们了解全貌并基于公开报道总结事件背后的原因和影响、公众号是腾讯专有的内容库,如果能够解决内部山头问题,真正打通资源,这会是元宝独特的竞争优势。其实在豆包给出的引用中也出现了抖音的内容,但是可以想见因为视频内容挖掘的难度以及抖音在专业领域内容质量的差距,豆包很难做到和元宝一样的输出效率。
在任务一中,内容准确性方面四个模型都没有犯明显错误,而对于内容的溯源,做得最好的是元宝,豆包只在深入研究模式下可溯源,Kimi的引用来源相对较少,千问则有一些引用无法显示或访问。
对于需要发散能力和信息整合能力的任务二和任务三,四个模型在对企业过往公布的数据和竞争对手的信息挖掘上各有侧重,最后给出的分析结果没有表现特别突出的,也没有明显拉胯的。千问和豆包都在这里出现了张冠李戴的问题。千问在任务三中还偏离了提示词的要求。
在生成完整报告能力上,元宝不具备,Kimi无法免费使用,豆包在内容饱满度和报告可用性上完胜。如果是信息来源丰富并且不涉及大量专业判断的报告工作,豆包的输出基本上可以直接使用,并且很难看出AI痕迹。豆包独特的报告可视化功能是向领导‘简单汇报’的出色工具。
基于上面几个维度,最终的测评结果可以汇总成下面的表格:
我自己是元宝的深度使用者,因为日常需要写代码挖掘数据和可视化,元宝接入deepseek的代码生成能力是国产四个模型中可靠性最高的,python数据库+可视化2-300行的小任务基本上只需要微调就能直接跑出来。
通过本次测评,以后简单的了解个大概的任务我会继续使用元宝,需要整合观点的我会使用元宝+豆包,而写报告我会在豆包的基础上通过元宝进行查漏补缺。
最后的最后,觉得内容不错的朋友麻烦帮忙点个关注和在看,给点小小的支持呀
临床研究
100 项与 TTP-273 相关的药物交易
登录后查看更多信息
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 2型糖尿病 | 临床2期 | 美国 | 2015-12-01 | |
| 囊性纤维化相关糖尿病 | 临床前 | 美国 | 2023-11-02 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
| 研究 | 分期 | 人群特征 | 评价人数 | 分组 | 结果 | 评价 | 发布日期 |
|---|
No Data | |||||||
登录后查看更多信息
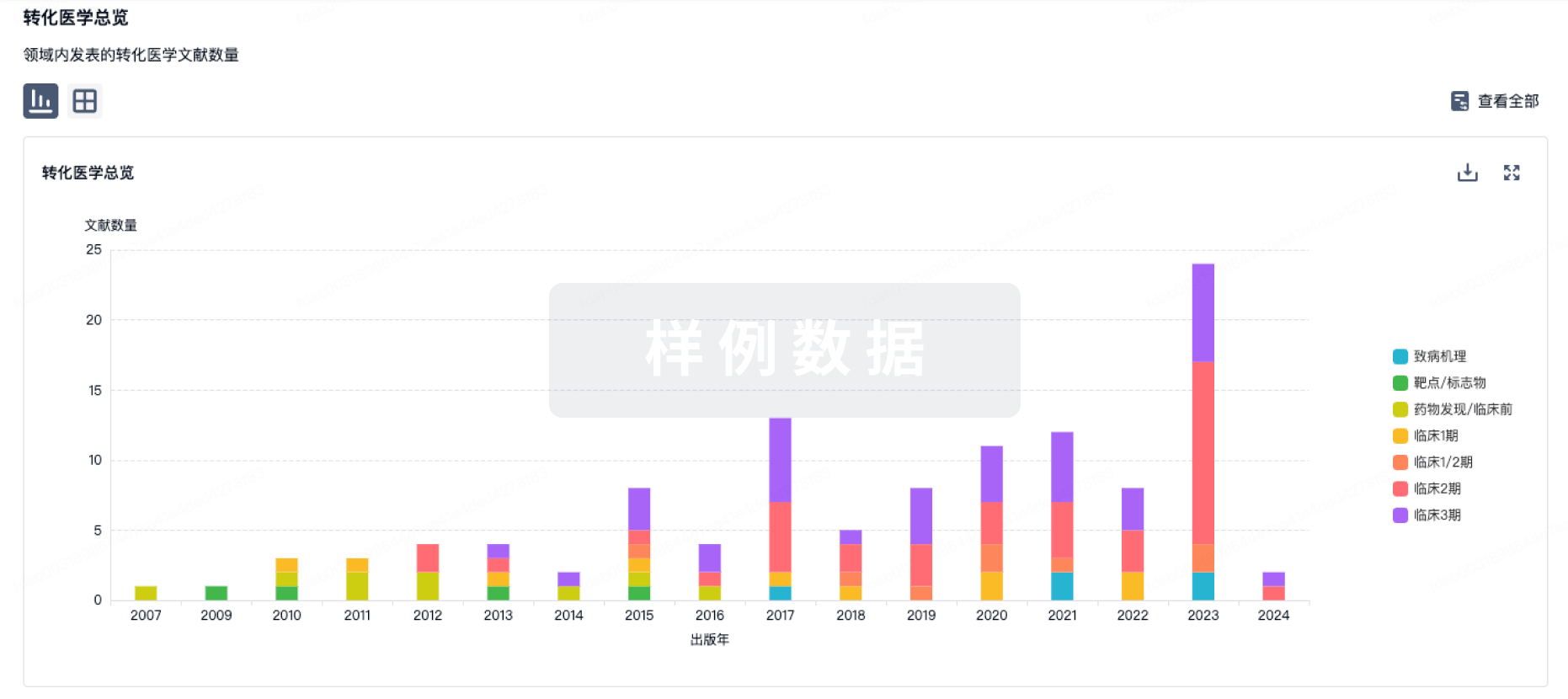
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用