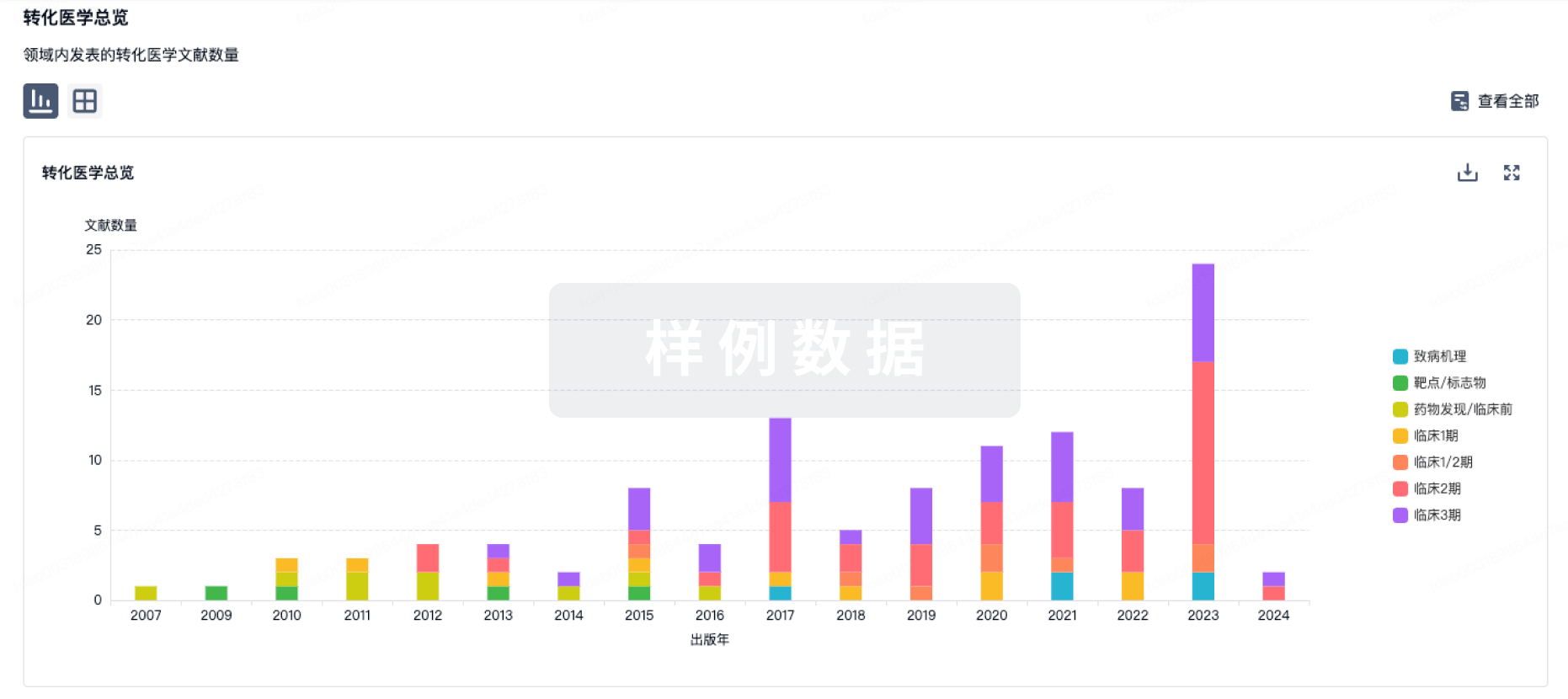
Effective mol. representation learning plays an important role in mol. modeling process of drug design, protein engineering, material science and so on.Currently, self-supervised learning models based on the Transformer architecture have shown great promise in mol. representation.However, batch training of Transformer model requires input data of consistent length, while the length of each entrys mol. data (SMILES sequence) is inconsistent, which results in the model being unable to process batches directly.Therefore, corresponding strategies should be proposed to enable the model to smoothly process data with inconsistent length in batches.In this work, we adopt a strategy of head-tail padding and tail padding to obtain fixed-length data, which are employed as inputs for the Transformer encoder and decoder resp., thus overcoming the limitation of the Transformers inability to batch process input data with inconsistent length.In this way, our Transformer-based model can be used for batch training of mol. data, thereby improving the efficiency, accuracy, and simplicity of mol. representation learning.Subsequently, public datasets are used to evaluate the performance of our mol. representation model in predicting mol. property.In the classification and regression tasks, the average ROC-AUC and RMSE values improves by over 10.3% and 3.3% resp. compared to the baseline models.Furthermore, the specific distributions are found after the compressing mol. representation vectors into two-dimensional or three-dimensional space using PCA dimensionality reduction algorithm, instead of random distributions.Our work highlights the potential of Transformer model in batch training for constructing mol. representation model, thus providing new path for AI technol. in mol. modeling.