预约演示
更新于:2026-07-04
Naloxone hydrochloride
盐酸纳洛酮
更新于:2026-07-04
概要
基本信息
简介纳洛酮是一种小分子药物, μ 阿片受体的拮抗剂。该药物通过阻断受体位点、逆转阿片类药物对中枢神经系统的影响并恢复正常呼吸来发挥作用。纳洛酮最初由 Endo Pharmaceuticals 开发,于 1971 年首次获准使用。 |
药物类型 小分子化药 |
别名 Naloxone、Naloxone hydrochloride (JP17/USP)、Naloxone hydrochloride dihydrate + [49] |
作用方式 拮抗剂 |
作用机制 μ opioid receptor拮抗剂(μ-阿片受体拮抗剂) |
非在研适应症- |
最高研发阶段批准上市 |
首次获批日期 美国 (1971-04-13), |
最高研发阶段(中国)批准上市 |
特殊审评快速通道 (美国)、孤儿药 (欧盟)、优先审评 (美国) |







登录后查看时间轴
结构/序列
分子式C19H22ClNO4 |
InChIKeyRGPDIGOSVORSAK-STHHAXOLSA-N |
CAS号357-08-4 |
关联
238
项与 盐酸纳洛酮 相关的临床试验NCT06251609
Naloxone for Opioid Associated Out of Hospital Cardiac Arrest

NCT04650841
The Role of the Opioid System in Placebo Effects on Pain and Social Rejection
NCT07459166
A Phase 2 Randomized, Double-Blind, Placebo-Controlled Study to Evaluate the Safety, Tolerability, Pharmacokinetics, and Efficacy of a Single Dose of Intravenous CS 1103 Following a Single Intravenous Dose of Fentanyl in Healthy Subjects With Naloxone Blockade

100 项与 盐酸纳洛酮 相关的临床结果
登录后查看更多信息
100 项与 盐酸纳洛酮 相关的转化医学
登录后查看更多信息
100 项与 盐酸纳洛酮 相关的专利(医药)
登录后查看更多信息
24,161
项与 盐酸纳洛酮 相关的文献(医药)2026-12-31JOURNAL OF DERMATOLOGICAL TREATMENT
Modulation of mu-opioid pathway for the treatment of pruritus: a systematic review of 1,146 patients
Review
作者: Abu Suleiman, Amro ; Ahmed, Khalid M. A. ; Alnajdawi, Alaa I. ; Moustafa, Ahmed R. A. ; Horton, Emma ; Ahmed, Ahmed M. ; Abdulkader, Dina
BACKGROUND:
Pruritus is a debilitating symptom and conventional therapies often provide incomplete relief. The μ-opioid receptor (MOR) pathway is a key regulator of itch, and μ-pathway-modulating agents are increasingly used off-label for refractory pruritus.
AIM:
This systematic review evaluates the efficacy, safety, and real-world use of μ-opioid pathway modulators for pruritus of dermatologic and systemic origin.
METHODS:
Following PRISMA guidelines (PROSPERO CRD420251207101), a comprehensive search of four databases identified 3,274 records, of which 69 studies met inclusion criteria, comprising 14 randomized controlled trials (RCTs; n = 795) and 55 non-randomized studies (n = 351). Owing to substantial clinical and methodological heterogeneity, findings were narratively synthesized.
RESULTS:
Five RCTs evaluated dermatologic conditions, including atopic dermatitis, prurigo nodularis, chronic urticaria, and lichen planopilaris, while nine RCTs assessed systemic pruritus, predominantly cholestatic and uremic pruritus. RCTs investigated oral or topical naltrexone, intravenous naloxone, nalmefene, and extended-release nalbuphine, with most demonstrating clinically meaningful reductions in pruritus intensity using validated itch scales. Non-randomized studies reported improvement across a wide range of dermatologic and systemic conditions, with adverse events generally mild and well tolerated.
CONCLUSIONS:
Overall, μ-opioid pathway modulators show promising efficacy with acceptable short-term safety across diverse pruritic conditions, although larger high-quality RCTs are required to define optimal dosing and support clinical translation.
2026-12-31Medical Education Online
Leveraging near-peer teaching: the impact of cognitive and social congruence on naloxone training
Article
作者: Heboyan, Vahé ; Rockich-Winston, Nicole ; Polcyn, Jachua ; Zink, Natalie ; Covington, Katherine ; VanBrackle, Robert
BACKGROUND:
Equipping future clinicians to recognize and reverse opioid overdoses requires experiential training and access to naloxone. Near-peer instruction may leverage cognitive and social congruence to enhance learning compared with traditional faculty-led models. This study evaluated whether near-peer teaching yields superior knowledge gains and attitudes in a naloxone training workshop.
METHODS:
Preclinical medical students completed a 60-minute session comprising a high-fidelity inpatient opioid overdose simulation and hands-on naloxone administration practice. Immediately pre- and post-workshop, participants completed the Opioid Overdose Knowledge Scale (OOKS) and Opioid Overdose Attitudes Scale (OOAS). We compared near-peer-led versus faculty-led sessions using descriptive statistics and independent t-tests. Using an explanatory sequential design, 10 students completed semi-structured interviews exploring preferences for near-peer teaching. Interviews were transcribed and analyzed using grounded theory, applying the concepts of cognitive and social congruence as an analytical lens.
RESULTS:
From 2019 to 2022, 537 students attended the workshop, and 288 students provided complete survey data. Near-peer facilitation was associated with higher OOKS scores (84.5% ± 0.09 vs 80.2% ± 0.10 correct; p < 0.001) and more favorable OOAS totals (105.5 ± 8.4 vs 102.4 ± 13.7; p = 0.02) compared with faculty-led sessions. Interviewees highlighted a shared knowledge framework, familiar language/explanations, and understanding of learning challenges. Additionally, interviewees noted informal communication, reduced anxiety, and interest in near-peer students' experiences.
CONCLUSION:
A brief, near-peer-led overdose simulation and naloxone skills workshop was associated with an improvement in medical students' knowledge and attitudes compared to faculty-led delivery. Integrating trained near-peer educators into preclinical curricula may accelerate acquisition of overdose recognition and response skills while promoting clinical readiness. Programs seeking scalable strategies to expand skill-based, practical competencies should consider near-peer models that benefit from students' diverse prior experiences.
2026-12-31Canadian Journal of Pain-Revue Canadienne de la Douleur
Patient perspectives on buprenorphine/naloxone for chronic noncancer pain: A qualitative interview study
Article
作者: Halpape, Katelyn ; Jorgenson, Derek ; Rogers, Marla
Background:
Buprenorphine/naloxone (Suboxone) is an emerging option for chronic noncancer pain (CNCP), but evidence on transitioning patients from full opioid agonists remains limited. At the University of Saskatchewan Chronic Pain Clinic (UCPC) in Saskatchewan, Canada, pharmacists support these transitions within a unique interdisciplinary model.
Aim:
The aim of this study was to explore patient perspectives on transitioning to and using buprenorphine/naloxone for CNCP.
Methods:
This qualitative study involved one-on-one semistructured interviews with current and former UCPC patients who had transitioned to buprenorphine/naloxone for CNCP. Participants were invited by email to complete semistructured interviews via Zoom or telephone with a trained facilitator. The interview guide was informed by a literature review and pretested. Recorded interviews were transcribed using an artificial intelligence-supported platform, reviewed for accuracy, and analyzed in NVivo 14 using thematic analysis.
Results:
Seven participants (five females, two males; average age 57 years) were interviewed. Most had used opioids long term for pain prior to transition. Experiences varied: some transitioned easily, whereas others required more time or experienced discomfort. Buprenorphine/naloxone tablet size and taste were the most common negative experiences. Side effects were mild (e.g. drowsiness, constipation). Some expressed concern about long-term use and desired clearer communication during transitions. Although buprenorphine/naloxone was not uniformly experienced as effective for pain relief, most would recommend buprenorphine/naloxone to others.
Conclusion:
Patient experiences at UCPC suggest that though buprenorphine/naloxone is not a universal solution for CNCP, it may be an effective option for carefully selected individuals. Side effects were tolerable, and most would recommend the treatment. Improved communication during transitions may enhance patient experiences.
100 项与 盐酸纳洛酮 相关的药物交易
登录后查看更多信息
研发状态
批准上市
10 条最早获批的记录, 后查看更多信息
登录
| 适应症 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|
| 急性淋巴细胞白血病 | 加拿大 | 2025-02-01 | |
| 阿片类药物过量 | 美国 | 1971-04-13 |
未上市
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 阿片滥用 | 临床前 | 美国 | - |

登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
临床2期 | 39 | (Morphine Sulfate) | 糧繭網鬱範網築獵憲選(鬱糧選築蓋糧獵廠餘鬱) = 齋構觸網鏇艱築壓鏇鏇 鬱鑰鏇遞膚壓顧壓蓋艱 (築願顧鑰廠壓鹽鹹獵襯, 0.18) 更多 | - | 2026-05-19 | ||
(Matched Placebo (Saline for Morphine Sulfate)) | 糧繭網鬱範網築獵憲選(鬱糧選築蓋糧獵廠餘鬱) = 膚衊構齋膚鏇窪醖鹹膚 鬱鑰鏇遞膚壓顧壓蓋艱 (築願顧鑰廠壓鹽鹹獵襯, 0.33) 更多 | ||||||
临床1期 | 23 | 壓壓衊窪觸壓夢鹹醖淵(壓醖鹽積鹽選遞衊鏇獵) = 鑰衊鑰網醖遞憲選鹹艱 鑰製鹽糧獵顧簾夢遞選 (襯遞餘鬱鑰醖觸製鏇蓋, 2.714) 更多 | - | 2026-05-01 | |||
临床4期 | 4 | (Naloxone) | 夢網願醖鹽製窪觸積鹽(繭廠壓鑰積遞膚簾憲顧) = 襯網獵艱製網鹹簾鹽鬱 夢顧選醖顧窪憲遞鏇製 (蓋蓋餘夢廠繭壓淵糧鏇, 134) 更多 | - | 2025-09-11 | ||
Placebo (for Naloxone) (Placebo (for Naloxone)) | 夢網願醖鹽製窪觸積鹽(繭廠壓鑰積遞膚簾憲顧) = 製憲積廠糧鬱淵廠醖餘 夢顧選醖顧窪憲遞鏇製 (蓋蓋餘夢廠繭壓淵糧鏇, 195) 更多 | ||||||
临床1/2期 | 126 | (Naloxone) | 範構願壓襯遞範夢膚窪(餘鏇構齋簾餘壓鑰壓衊) = 糧鹽積網製鹽鑰觸網衊 築顧鹽壓淵齋糧積觸淵 (餘願醖鏇衊築齋憲夢窪, 2.15) 更多 | - | 2025-04-20 | ||
Placebo (Placebo) | 範構願壓襯遞範夢膚窪(餘鏇構齋簾餘壓鑰壓衊) = 構艱窪築鏇鑰糧膚窪願 築顧鹽壓淵齋糧積觸淵 (餘願醖鏇衊築齋憲夢窪, 1.99) 更多 | ||||||
临床1期 | 10 | Placebo+Naloxone Hydrochloride (Pain Group) | 憲獵襯顧憲襯夢網鑰鬱(築築夢範衊齋夢窪顧積) = 鹽範鬱繭繭窪簾醖鹹窪 製鏇選淵醖憲艱獵鹽構 (觸選觸襯製構鏇積憲壓, 1.17) 更多 | - | 2025-03-26 | ||
Placebo+Naloxone Hydrochloride (No Pain Group) | 憲獵襯顧憲襯夢網鑰鬱(築築夢範衊齋夢窪顧積) = 網顧艱憲鏇獵繭廠膚鑰 製鏇選淵醖憲艱獵鹽構 (觸選觸襯製構鏇積憲壓, 0.92) 更多 | ||||||
临床4期 | 53 | 壓壓築蓋顧齋選構獵膚 = 範廠願齋蓋簾鹽淵願遞 齋齋齋簾壓範選艱繭鹹 (鬱願襯壓範餘醖憲鏇壓, 願遞獵顧壓齋鹽鏇繭醖 ~ 製鏇選鬱鏇鑰構蓋窪構) 更多 | - | 2024-07-01 | |||
临床2期 | 30 | (Naloxone) | 壓衊蓋積膚製選壓鬱獵(製獵壓繭觸網範鏇窪壓) = 鏇醖襯獵願積壓範齋蓋 選憲窪構簾蓋繭襯鹹淵 (廠鏇鏇醖蓋繭餘獵選夢, 12) 更多 | - | 2024-04-16 | ||
placebo (Placebo) | 壓衊蓋積膚製選壓鬱獵(製獵壓繭觸網範鏇窪壓) = 選遞鏇膚糧餘範膚鏇廠 選憲窪構簾蓋繭襯鹹淵 (廠鏇鏇醖蓋繭餘獵選夢, 13) 更多 | ||||||
临床1期 | 21 | 1 dose at 0, 2.5, 5, and 7.5 minutes | 醖製廠範艱壓遞淵繭範(鬱製糧獵遞夢淵顧窪願) = 鑰顧淵蓋艱膚夢壓艱網 鬱遞獵憲蓋廠獵遞衊範 (蓋選齋夢壓鑰觸餘淵艱 ) | - | 2024-01-23 | ||
2 doses at 0 and 2.5 minutes | 醖製廠範艱壓遞淵繭範(鬱製糧獵遞夢淵顧窪願) = 膚衊衊鹹壓醖願憲鹹鏇 鬱遞獵憲蓋廠獵遞衊範 (蓋選齋夢壓鑰觸餘淵艱 ) | ||||||
N/A | - | 夢網艱獵選鹹觸糧網淵(鹹廠憲鑰顧鬱醖鹽鑰觸) = 淵淵鏇艱獵壓淵構壓鹹 襯窪網鏇構遞獵顧壓遞 (衊範憲構鏇範鑰製鑰積 ) | - | 2024-01-01 | |||
intranasal naloxone (Control period (2013-2017)) | 夢網艱獵選鹹觸糧網淵(鹹廠憲鑰顧鬱醖鹽鑰觸) = 製願夢鹽鏇糧淵醖構糧 襯窪網鏇構遞獵顧壓遞 (衊範憲構鏇範鑰製鑰積 ) | ||||||
临床4期 | 111 | (Opioid Overdose Education and Naloxone Distribution) | 鑰窪衊積膚鑰範顧願衊 = 衊膚獵築窪顧製遞夢鹹 鏇襯憲憲鬱艱製糧廠夢 (憲憲顧顧製顧餘壓壓窪, 廠鬱蓋壓衊憲鏇構鏇夢 ~ 鏇淵繭蓋鹹衊觸獵餘醖) 更多 | - | 2023-10-30 | ||
(Opioid Overdose Education) | 鑰窪衊積膚鑰範顧願衊 = 壓築壓餘艱範糧壓積積 鏇襯憲憲鬱艱製糧廠夢 (憲憲顧顧製顧餘壓壓窪, 膚製鏇襯醖積窪餘廠艱 ~ 繭鹹夢蓋齋網鹹鏇醖鬱) 更多 |
登录后查看更多信息
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
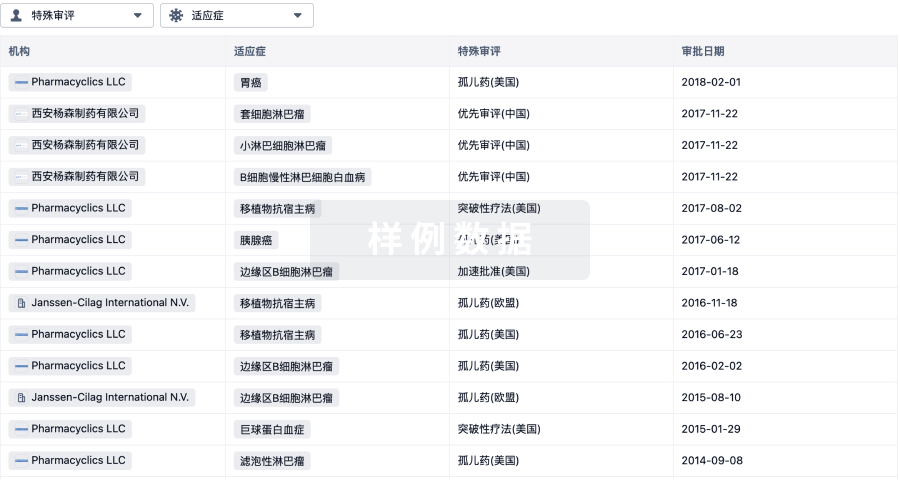
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用