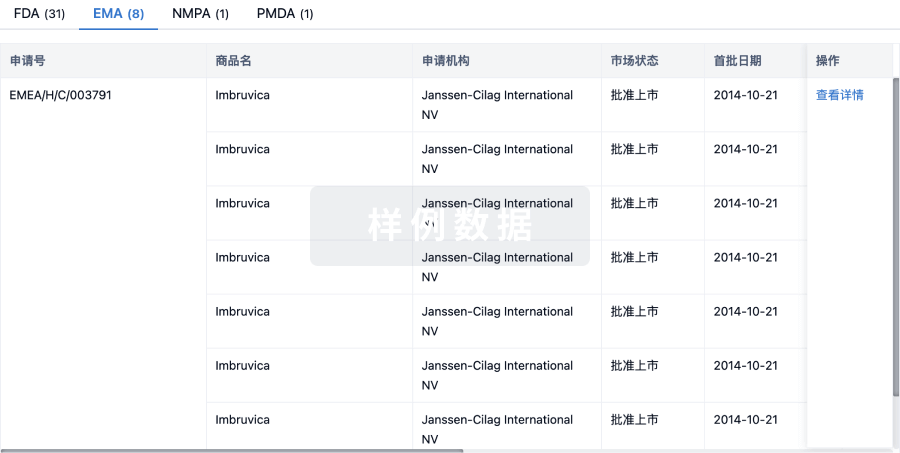
预约演示
更新于:2026-07-18
EXS-21546
更新于:2026-07-18
概要
基本信息
非在研机构 |
权益机构- |
最高研发阶段临床1/2期 |
首次获批日期- |
最高研发阶段(中国)- |
特殊审评- |

登录后查看时间轴
关联
2
项与 EXS-21546 相关的临床试验NCT05920408
A Phase 1B/2A Study to Assess the Safety, Tolerability, Pharmacokinetic and Anti-tumoral Activity of EXS21546 in Combination With a PD-1 Inhibitor in Patients With Advanced Solid Tumours
A phase 1B/2A study to assess the safety, tolerability, pharmacokinetic and anti-tumoral activity of EXS21546 in combination with a PD-1 inhibitor in patients with advanced solid tumours.
开始日期2023-04-11 |
申办/合作机构 Exscientia AI Ltd. [+1] |
NCT04727138
3-part Study to Assess Safety, Tolerability, PK and PD of Single and Multiple Ascending Doses of EXS21546, and to Evaluate the Relative Bioavailability of 2 Formulations, in Healthy Male Subjects
A 3-part Study to Assess Safety, Tolerability, PK and PD of Single (Part 1) and Multiple (Part 2) Ascending Doses of EXS21546, and to Evaluate the Relative Bioavailability of a Solid Dose Formulation Compared to a Powder for Oral Suspension (Part 3), in Healthy Male Subjects.
开始日期2020-12-08 |
申办/合作机构 Exscientia AI Ltd. [+1] |
100 项与 EXS-21546 相关的临床结果
登录后查看更多信息
100 项与 EXS-21546 相关的转化医学
登录后查看更多信息
100 项与 EXS-21546 相关的专利(医药)
登录后查看更多信息
80
项与 EXS-21546 相关的新闻(医药)2026-07-17
▍一、临床门口的这一幕,值得所有人停下来看看
先说一件刚刚发生、但很多人没注意到的事。
2026年7月7日,一家叫英矽智能(Insilico Medicine)的公司,把一款药推进了三期临床。药的名字有点拗口,叫瑞妥色替(rentosertib)。
这不是重点。重点是它的身份——业内普遍认为,这是全球第一款"靶点是AI找的、分子也是AI设计的"药,同时走到了三期临床这一步。
三期是什么概念?
简单说,一款药从实验室走到病人手里,要过三道大关。
三期是最后、最烧钱、也最见真章的一关。能站到这里的药,行业里十个里活不了一个。
我为什么要拿这件小事开头?
因为就在同一个赛道,另一批公司正在经历完全相反的剧情。
有的把管线砍了一半,有的裁掉了两成员工,还有的干脆合并求生。同一年,同一个行业,一边在庆功,一边在止血。
AI制药这三年,不是一条平滑上升的曲线,而是一半人掉进坑里、一半人爬上岸的分水岭。
所以今天这篇文章,想认真回答一个被问烂了、却始终没人说清楚的问题:AI制药,到底是泡沫破了,还是拐点到了?
我不打算给你灌鸡汤,也不打算泼冷水。咱们把数据摆桌上,一个一个看。
2026.07.07 · 一件被忽略的大事
▍二、别急着欢呼,泡沫是真的破过
先说难听的。
时间倒回2020年。当时英国一家公司Exscientia,联合日本住友,把一款代号DSP-1181的分子送进了临床。宣传铺天盖地——"史上第一款AI设计的药进入临床"。那会儿的口号你现在听着都眼熟:AI能把新药研发从五年压到一年,从几十亿美元压到几千万。
结局呢?DSP-1181后来悄悄停了,几乎没什么水花。
这还只是开始。
2023年4月,另一家明星公司BenevolentAI,它的核心管线BEN-2293——一款治特应性皮炎的药——二期临床主要终点没达到。翻译成人话:药没起到该起的效果。
紧接着,公司在当年5月裁了约180人,靠这一刀省下大约5600万美元。一家曾在阿姆斯特丹交易所风光上市的公司,市值一路往下掉。
同样是2023年,Exscientia那款被寄予厚望的EXS-21546也停了,官方给的理由是"药物在治疗窗口内对靶点的覆盖不足"。
术语小框 · 靶点(Target)你可以把疾病想象成一台出故障的机器,靶点就是那个坏掉的零件——通常是一个蛋白或基因。药物的任务,就是精准地卡住这个零件,让它别再捣乱。找错靶点,或者卡不住,药就白做了。
AI能在几周内画出一个漂亮的分子,但它没法替你保证,这个分子进了人体之后,身体会不会买账。
后面的故事更能说明问题。
2024年8月,Exscientia干脆和美国的Recursion合并,两家一度估值极高的AI制药公司,抱团取暖。
到了2025年6月10日,合并后的Recursion宣布裁员约20%,差不多160人,同时砍掉了三条管线——REC-2282、REC-994、REC-3964。公司自己说,这是为了把现金烧到2027年第四季度,撑得更久一点。
这一连串事,发生在短短两三年里。
你说这是不是泡沫?某种程度上,是的。
资本市场把"AI+医药"这两个最性感的词凑在一起,估值一度冲上天,然后被临床数据一巴掌拍回地面。
为什么会这样?我琢磨了很久,觉得根子上是一场"预期错配"。
2020到2021年那波热潮里,几乎所有人都默认了一个前提:药之所以难做,是因为人脑算不过来那么多分子组合;只要AI能把这道数学题解开,新药就会像流水线上的零件一样源源不断地冒出来。听上去无懈可击,对吧?
问题是,做药从来不只是一道数学题。它更像是在一片没画过的地图上找路。
分子设计确实是可以被AI加速的那一段——这段路,AI跑得又快又稳。可"这个靶点到底和疾病有没有真关系""药进了人体会不会引发一连串没人预料到的反应",这些问题的答案不在任何一个现成的数据库里,得靠一次次真金白银的临床去试、去撞。AI再聪明,也变不出它从没见过的知识。
于是就出现了一个特别拧巴的局面:
技术方面,AI确实兑现了承诺——分子设计从几年缩到几个月,一点没吹牛;
但商业和临床方面,那些被抬得过高的估值和期待,迟迟等不来能治好病的药来兑现。
一边是真实的技术进步,一边是虚高的市场泡沫,两者被强行绑在一起,泡沫破的时候,连带着把不少扎实做事的公司也拖下了水。这是这轮回调里最让人惋惜的部分。
三年五记耳光 · 泡沫破裂时间轴
▍三、可那扇门,真的有人把它推开了
如果故事到这里就结束,那这篇文章的标题该改成《泡沫破了》,句号。
但它没结束。
我们回到开头那款药,瑞妥色替。
它治的是一种叫特发性肺纤维化(IPF)的病。
这个病有多凶?患者的肺会像结疤一样一点点变硬,呼吸越来越费劲,确诊之后中位生存期往往只有三到五年。现有的两款药只能延缓,救不了根,副作用还大。这是一块医学界啃了很多年、依然没啃下来的硬骨头。
英矽智能干的事,是用生成式AI从"衰老生物学"里挖出了一个全新的靶点——TNIK,再用AI设计出能卡住它的分子。
术语小框 · TNIK 与 FVCTNIK是一种和纤维化、炎症都有关系的激酶。此前没人拿它当肺纤维化的正经靶点,是AI"猜"出来它可能有用。FVC则是"用力肺活量",衡量你一口气能呼出多少空气——对肺纤维化患者来说,这个数字每年往下掉多少,直接关系到还能活多久。药有没有用,就看它能不能让FVC别再往下掉。
关键在数据。
2025年6月,二期临床结果发在了顶级期刊《自然·医学》上。71名患者,分了几个剂量组。最亮眼的那组——60毫克每天一次——治疗12周后,患者的FVC平均涨了98.4毫升;而吃安慰剂的那组,同期跌了20.3毫升。一涨一跌,差了将近120毫升。对这个病来说,肺功能不降反升,是实打实的好信号。
当一款药能让本该恶化的肺功能停下来、甚至往回走,你就很难再说它只是PPT上的概念。
更让人坐不住的是速度。
按官方说法,从锁定靶点到提名临床前候选药物,他们只花了大约18个月;从启动靶点发现到走完临床0/1期,不到30个月。传统路径这一段,通常要四五年起步,烧掉的钱按亿美元计。
当然,我得说句公道话:这药也不是完美的。
二期里有患者因为肝毒性退出,尤其是同时吃另一款老药的病人,肝脏出了些状况。药还在三期,最终能不能成,没人敢打包票。
但它至少证明了一件事——AI不是只会做"me-too"的仿制思路,它真的有本事挖出人类没想到的新靶点、新分子。
为什么这件事这么重要,我再多解释一句。
过去几十年,绝大多数所谓的"创新药",其实是在别人验证过的老靶点上做优化——同一个锁,换一把更好用的钥匙。这条路稳,但天花板也就在那儿。而肺纤维化这种病,难就难在没人知道该拿哪个"锁"下手,几代科学家试了一堆靶点都没成。
英矽用AI从衰老这个大方向里,硬是筛出了TNIK这个此前没人认真当回事的目标,然后一路把它送进了三期——这等于是在一张空白地图上,自己画出了一条新路。
药最终成不成是一回事,但"AI能帮人类找到全新的路"这件事,第一次有了一个走到临床晚期的实证。这比任何一句口号都有说服力。
产品图 · 瑞妥色替(rentosertib / ISM001-055)
▍四、数字不会骗人,但它特别会误导人
好,现在到了最关键、也最容易被人带节奏的地方——成功率。
你可能刷到过一个很唬人的说法:AI发现的药,临床一期成功率高达80%到90%,而行业老规矩才50%左右。听起来AI简直是开了挂。
这个数据是真的。它来自波士顿咨询(BCG)几位研究者2024年6月发在《Drug Discovery Today》上的一篇分析。他们扒了大约300家AI原生药企、67款进入临床的AI药,得出的结论确实是:一期成功率能到80%~90%,远高于历史平均。
但——请把这个"但"字放大——同一篇研究还说了下半句:这些AI药到了二期,成功率只有40%,和传统药几乎没差别。
术语小框 · 临床成功率与"死亡之谷"一期主要看"安不安全",二期开始看"到底有没有用"。行业里有个说法叫"二期死亡之谷",因为绝大多数药都是在这一关证明不了疗效,倒下的。一期漂亮不算本事,二期能过,才是真功夫。
这半句,才是理解整个AI制药最要命的一把钥匙。
一期成功率高,说明AI确实擅长它擅长的事:快速设计出安全性过关、成药性不错的分子。这活儿它干得比人快、比人省。
可一旦进入二期,问题就变了——药到底能不能治病,靠的是对疾病生物学的深刻理解,是对靶点是否"真的管用"的判断。而这恰恰是AI目前最虚的地方。
AI能帮你把车造得又快又漂亮,但它还没法替你保证,这条路通向的是不是正确的方向。
这里值得多说两句,为什么二期这么难过。
你想,一期招的往往是健康志愿者或者少量患者,主要就看吃了这药会不会出大问题,剂量能不能扛得住——这是AI的主场,因为它设计分子时,本来就把"别太毒""吸收要好"这些成药性指标算进去了。
可到了二期,对手换成了疾病本身。药要在真正的病人身上,证明它能实打实地改善病情。这时候比的不再是分子画得漂不漂亮,而是当初挑的那个靶点,究竟是不是这个病的"病根"。
一旦靶点选错——哪怕分子完美地卡住了它——药也照样没用。这就好比你请了全世界最好的锁匠,打了一把工艺无可挑剔的钥匙,可如果这把钥匙对应的压根不是大门的锁,那它再精致也打不开门。
选靶点这件事,靠的是对人体、对疾病几十年积累下来的生物学理解,而这恰恰是当下AI最薄弱的一环。它读过海量论文,却没真正"理解"过一个细胞是怎么活、怎么病、怎么死的。
那篇研究算了一笔总账:把AI在各期的表现叠起来,一款药最终走通全程的概率,大概能从传统的5%~10%,提到9%~18%。注意,是"提高",不是"颠覆"。差不多翻一倍——这已经很了不起了,但离"AI三年造神药"的口号,差着十万八千里。
还有个容易被忽略的细节:在全球六千多款在研药物里,真正由AI发现全新靶点的,那篇分析当时只数出来个位数。也就是说,绝大多数所谓"AI药",AI干的还是辅助、加速的活儿,真正从0到1开创新靶点的,凤毛麟角。瑞妥色替之所以被反复提起,正因为它是那"凤毛麟角"里的一个。
一期很美,二期见真章 · 成功率对比
▍五、牌桌上还剩谁,钱又往哪儿流
看清了泡沫和真章,我们再抬头看看牌桌。
一边是止血的。
前面说的Recursion,砍管线、裁员、省钱续命,这是行业里相当一部分公司的现状——故事讲不动了,就得回到"活下去"这个最朴素的命题。
另一边,是加注的。
2026年5月12日,谷歌母公司Alphabet旗下的Isomorphic Labs,一口气融了21亿美元的B轮,领投方是明星机构Thrive Capital。
这家公司什么来头?创始人是Demis Hassabis——对,就是那个搞出AlphaFold、拿了诺贝尔化学奖的人。他放的话很大:要"解决所有疾病"。
这家公司此前已经和诺华、礼来签了合计最高约30亿美元的合作。按计划,它第一批完全由AI设计的药,将在2026年底走进临床(这个时间点,其实已经从原定的2025年底往后推了)。
当一批公司在为活下去精打细算时,另一批公司正拿着几十亿美元,赌下一个十年——这本身就说明,这局远没到收摊的时候。
你看,同一张牌桌,冷热两极。热钱没有离场,只是变聪明了。它不再为一句"AI颠覆制药"的口号买单,而是盯着两样东西:
一,你有没有真的走进临床、拿出人体数据;
二,你烧钱的效率,是不是真比传统药企高。
这里有个信号很微妙,值得单独拎出来说。
三年前,一家AI药企只要在发布会上放出漂亮的分子结构图、讲清楚算法多先进,就能拿到高估值。
今天不行了。投资人学乖了,他们开始追问一句最朴素的话:药呢?病人数据呢?你烧了这么多钱,到底把哪款药往前推了几步?
这种从"看模型"到"看药"的转变,表面上是资本变冷了,实质上是这个行业终于开始按医药的规矩办事——而医药的规矩,从来就是拿人体数据说话,慢,但硬。
顺便提一句市场的整体温度。
多家第三方机构的测算口径不太一样,但方向一致:全球AI药物发现市场规模,目前大致在十几亿到几十亿美元区间,多数预测认为到2030年代中期会涨到一百六十亿美元上下,年复合增速普遍在17%以上。钱还在往里涌,只不过涌得比三年前克制多了,也精明多了。
冷热两极 · 玩家格局
▍六、所以,泡沫还是拐点?我给三个判断信号
绕了一大圈,回到最初那个问题。
我的答案是:泡沫确实破过一轮,但那不是终点,而是行业从"讲故事"切换到"交作业"的分水岭。真正的拐点,不是某一天突然到来的,它藏在几个具体信号里。
第一个信号,看临床,别看融资。
一家AI药企值不值得信,早就不看它PPT画得多好、融了多少钱,而是看它有没有药真的走进临床、二期数据硬不硬。瑞妥色替的三期、Isomorphic年底的首次临床,就是接下来一两年最该盯的两块试金石。
第二个信号,看它敢不敢碰新靶点。
只会用AI做"更快的仿制",天花板很低;敢像英矽那样去挖一个人类没验证过的全新靶点,虽然风险高得多,但那才是AI真正改写游戏规则的地方。
第三个信号,看烧钱的效率账。
18个月、不到30个月这样的时间线,如果能被更多公司、更多疾病反复复现,那才是拐点坐实的标志。孤例是运气,规律才是趋势。
术语小框 · 拐点(Inflection Point)数学上,拐点是曲线改变弯曲方向的那个点。放到产业里,它指的不是最高点,而是趋势由虚转实、由乱到定的转折。拐点往往在事后才被看清,但身处其中的人,能从信号里提前嗅到它。
AI不会在三年内造出神药,但它正在让"造神药"这件事,第一次变得可被验证、可被复制、可被算账。
说到底,这三年最大的价值,可能不是造出了哪款药,而是挤掉了那层最厚的泡沫,让所有人看清:AI制药不是魔法,它是一套能实打实提高研发胜率的新工具。工具没那么性感,但工具能改变世界。
回头看,蒸汽机刚出来时也没人相信它能取代马车,真正改变世界的技术,往往都要先熬过一段"被高估、再被低估"的尴尬期,才慢慢长成它该有的样子。AI制药,此刻大概就走在这段路上。
泡沫破了,是因为期待被吹得太高;拐点到了,是因为有人真的把第一批药,送到了临床的门口,还推开了那扇门。
至于门后面是什么,值不值得这么多钱和人往里冲——那是接下来五年、十年的故事了。而我们,刚好站在能看清它的位置上。
拐点到了吗 · 三个判断信号
The End
▍数据来源(均为境外公开信源,标注发布时间)
[1] 英矽智能瑞妥色替(rentosertib / ISM001-055)二期临床结果,Nature Medicine,2025年6月(DOI: 10.1038/s41591-025-03743-2)。71名患者,60mg每日一次组12周FVC较基线 +98.4mL,安慰剂组 −20.3mL。
[2] 英矽智能三期临床启动公告,PR Newswire,2026年7月7日。320名受试者,中国47家中心,52周FVC年下降率为主要终点。
[3] Jayatunga M.K.P. 等,《How successful are AI-discovered drugs in clinical trials? A first analysis and emerging lessons》,Drug Discovery Today,2024年6月(29卷6期,104009)。分析约300家AI原生药企、67款AI药:一期成功率80%~90%,二期约40%;整体成功概率由5%~10%升至约9%~18%。
[4] Isomorphic Labs 21亿美元B轮融资,Tech Startups 等报道,2026年5月12日。Thrive Capital领投,Alphabet等跟投;与诺华、礼来合作合计最高约30亿美元;首批AI设计药物预计2026年底进入临床。[5] Recursion(并购Exscientia后)裁员约20%(约160人)并砍掉 REC-2282、REC-994、REC-3964 三条管线,BioSpace 报道,2025年6月10日;现金预计支撑至2027年第四季度。[6] BenevolentAI BEN-2293 二期特应性皮炎试验主要终点未达标,2023年4月;同年5月裁员约180人、节省约5600万美元。Exscientia EXS-21546 于2023年终止;两公司于2024年8月合并。[7] 全球AI药物发现市场规模测算,Grand View Research / GM Insights / BioSpace 等第三方报告,2024—2025年:现阶段约十几亿至数十亿美元,多数预测2034年前后达约165亿美元,年复合增速约17%~30%(不同机构口径存在差异)。
⚠️ 免责声明
本文为科普与行业分析内容,所有数据均来自上述境外公开信源,仅供参考。
文中涉及的药物均处于研究或临床阶段,其安全性与有效性以监管机构最终审批结论为准,本文不构成任何医疗建议、用药指导或投资建议。
疾病诊疗请遵从执业医师意见,投资决策请自行判断并承担相应风险。
✍️ 原创声明
本文为原创内容,未经授权谢绝转载、摘编或洗稿。
如需转载或商务合作,请后台留言联系授权,
转载须完整保留作者署名、来源与本声明。
如果觉得内容还不错,别忘了点
分享、
收藏、
在看、
点赞
哦!
2026-07-14
·今日头条
未来医学将从“捡棍子瞎试”变成数字编程。通过合成医药技术,可以像写代码一样修改人体,绝大多数疾病都能被治愈!
未来医学的范式革命:从“经验试错”到“数字编程”
随着基因编辑、人工智能、纳米技术等领域的突破,医学正在经历从“被动治疗”到“主动编程”的深刻变革。合成医药技术的核心逻辑,是将人体视为可精准调控的“生物代码系统”,通过重写基因程序、设计智能细胞、构建纳米级诊疗网络,实现疾病的根本性治愈。以下从技术突破、应用场景与未来展望三方面解析这一趋势:
一、核心技术突破:让医学进入“数字时代”
1. 基因编辑:生命密码的“编译器”
- 精准性升级:CRISPR-Cas9、碱基编辑、引导编辑等技术已能实现单碱基修改、复杂序列替换,甚至跨物种基因调控(如猪器官移植到人体)。
- 案例:中国团队开发的YOLT-101疗法通过关闭PCSK9基因,可长期降低“坏胆固醇”;美国团队用CRISPR技术使镰刀型贫血患者无需输血。
2. AI驱动的药物设计
- 效率革命:AlphaFold解析蛋白质结构速度提升百万倍,AI设计药物从靶点筛选到临床前试验仅需12个月(传统需4.5年)。
- 个性化治疗:AI分析患者基因组、代谢数据等,定制专属药物组合(如抗纤维化药物EXS-21546)。
3. 细胞编程:微型计算机的生物化
- 自主决策系统:以色列团队将人类细胞编程为“生物计算机”,通过RNA反式剪接实现多信号并行处理,可精准激活抗癌免疫细胞。
- 安全机制:系统内置“警示信号”,避免细胞代谢过载或医疗差错。
4. 纳米技术:分子级诊疗网络
- 靶向递送:纳米颗粒载药系统可精准定位肿瘤微环境,效率提升80%;磁性纳米机器人30分钟内溶解脑血栓。
- 实时监测:可吞咽纳米传感器计划2027年实现500种生物标志物连续监测,误差率<3%。
二、疾病治愈的“数字路径”
1. 癌症:从“对抗”到“重编程”
- 免疫细胞升级:编辑CAR-T细胞PD-1基因,实体瘤缓解率从18%提升至52%;通用型免疫细胞可识别90%癌细胞抗原。
- 癌细胞“返祖”:AI设计调控模块使癌细胞重编程为脂肪细胞(转化率68.9%),或强制恢复程序性凋亡能力。
2. 慢性病:根源性干预
- 基因层面调控:通过基因编辑关闭高血压、糖尿病相关基因,实现“一次治疗,长期有效”。
- 代谢重编程:纳米共生系统持续释放胰岛素,糖尿病患者有望告别注射。
3. 器官再生:按需制造
- 3D生物打印:用基因编辑猪肝细胞打印兼容肝脏,存活超6个月;人工设计胶原蛋白使心脏瓣膜成本降至1/20。
- 血管化突破:AI设计的VEGF调控模块帮助干细胞自发形成分级脉管系统,加速器官培育。
4. 衰老逆转:生物时钟的“调试”
- 细胞重编程:小鼠实验显示寿命延长30%,人类临床试验计划2025年启动。
- 端粒修复:基因疗法使老年小鼠寿命延长35%,未来或延缓人类衰老进程。
三、未来展望:技术整合与挑战
1. 技术融合趋势
- AI+基因编辑:AI预测基因调控网络,指导精准编辑(如西班牙团队用ExoCode模型设计非编码区序列)。
- 纳米机器人+合成生物学:构建“体内药房”,实时响应疾病信号并释放药物。
2. 关键挑战
- 安全性验证:需解决脱靶效应、长期副作用等问题(如基因编辑可能引发免疫排斥)。
- 伦理与公平:技术普及可能加剧医疗资源不均,需建立全球协作的监管框架。
3. 时间表预测
- 短期(3-5年):癌症治疗进入“精准编程”阶段,AI设计药物占新药研发50%以上。
- 中期(5-10年):器官再生技术成熟,纳米监测网络覆盖常见慢性病。
- 长期(10-20年):衰老相关疾病可控,医学从“治已病”转向“治未病”。
结语:医学的终极形态
未来医学将彻底打破“疾病不可逆”的认知边界。通过合成医药技术,人类不仅能像“写代码”一样修改基因、调控细胞,更能构建智能化的健康管理系统。正如AlphaFold的设计者所言:“蛋白质结构的解析,是打开生命奥秘的钥匙;而AI与基因编辑的结合,正在让这把钥匙变成万能工具。”当技术突破与伦理创新同步推进,“绝大多数疾病可治愈”的愿景或将比想象中更早实现。
2026-07-11
上周跟一个做药的朋友吃饭,他说了句话让我愣了几秒:"AI制药这个概念,五年前是风口,三年前是泡沫,现在是被人忘了的灰烬。但就在这两年,几家公司不声不响地把分子推进了二期临床。"这话让我想起 2024 年诺贝尔化学奖——一半给了 AlphaFold 的发明者,一半给了蛋白质从头设计。诺奖委员会从来不追风口。他们愿意等十几年再下判断。AI制药这个领域,泡沫和真东西混在一起太久了。是该拆开看看了。
药物研发为什么这么贵
一个新药从实验室到药房,平均耗时 10 到 15 年,烧掉 10 到 26 亿美元。不是大头花了研发上——研发本身占比有限——真正烧钱的是失败。每 10 个进临床的候选药物,最后能上市的不到 1 个。早期阶段淘汰一个分子的成本也许只有几百万美元,到了三期临床再失败,损失就是以亿为单位的。德勤做过一个统计,2010 到 2022 年间,全球 TOP 20 药企的新药研发回报率从 10.1% 一路跌到 1.2%。投入越来越多,产出越来越少。这就是化学空间的残酷现实。理论上可以被合成的、具有药物活性的小分子数量在 10³³ 到 10⁶⁰ 之间。传统的高通量筛选一次能测几百万个化合物,已经是人类实验能力的极限了。但跟 10³³ 比起来,连九牛一毛都算不上。抽彩票不可怕。可怕的是每抽一张要花几百万,抽几万张才可能中一次。
AI 到底在哪个环节干活
AI 不是在所有环节上都好用。拆细了看,目前的实际落地集中在三个切口上。靶点发现和验证。 过去找药物靶点靠文献挖掘和实验室验证,费时费钱。BenevolentAI 的算法在 2020 年用 48 小时从文献里筛出巴瑞替尼作为 COVID-19 潜在治疗药物,后来被 NIH 推荐使用。Insilico Medicine 也是靠这个切口起家的,他们用 AI 发现的新靶点已经推进到临床阶段。分子生成和优化。 这是目前最成熟也最热的方向。给定目标蛋白的三维结构,AI 可以生成成千上万个候选分子,同时优化它们的结合亲和力、选择性、代谢稳定性、毒性——传统做法需要好几轮独立优化,AI 一次跑完。2024 年 AI 制药领域最大的新闻,是 Recursion 和 Exscientia 合并。Recursion 有工业级的细胞成像高通量数据,Exscientia 有小分子设计引擎。两家合在一起,理论上可以把"靶点-分子-临床"这条线串起来。具体能不能串通,还得等管线数据说话。临床试验优化。 三期临床为什么失败率高?很多时候是试验设计出了问题——入组标准太宽、终点指标选得不好、统计方案没预见到数据的异质性。AI 可以从真实世界数据里提取更精准的患者分层策略,降低试验失败的概率。这块目前的落地比前两者少,但一旦跑通,省的钱是数量级的。
核心玩家:三条赛道
AI 制药的玩家大致分三类,各自算盘不一样。
类型
代表公司
逻辑
优势
风险
AI原生药企
Recursion/Exscientia, Insilico Medicine, Isomorphic Labs
靠AI管线建立资产组合,卖药或卖管线
研发成本比传统药企低,候选分子质量高
临床数据不够多,资本市场烧钱烧得厉害
科技巨头
Google DeepMind (AlphaFold), NVIDIA (BioNeMo, Clara)
提供底层AI基础设施和工具
算力、人才、数据生态
制药不是主业,投入受公司战略影响
大型药企
辉瑞, 罗氏, 赛诺菲, 阿斯利康
用AI改造现有研发流程
管线深、资金厚、临床经验丰富
组织惯性大,AI落地通常比外部合作慢
这三条赛道的共同点:赚钱的都还是传统药企的模式——卖药。AI 原生公司还没有一家靠 AI 发现的分子撑起一个上市产品。
Recursion 和 Exscientia:合并求生
Recursion 的故事是一个生物学家带着工程思维建了一家制药公司。创始人 Chris Gibson 在犹他大学读博期间就琢磨一件事:能不能像扫描二维码一样,把细胞的状态批量读出来?后来他建了一个每周能做几百万次细胞成像实验的自动化平台,理论上可以穷举各种药物分子对各种细胞的影响。数据扔给 AI,让它找规律。但是,光有数据不行。生成候选分子的能力是他们缺的。Exscientia 恰好补上这一块。这两家 2024 年决定合并,合并后的公司估值大约 28 亿美元。看起来不小,但在制药这个行当,一家没有上市产品的公司,28 亿美元已经是很克制的价格了。合并后的管线里,最有看点的是 REC-994,针对脑海绵状血管瘤的小分子,已进入二期临床。另一个是 EXS-21546,和罗氏合作开发,针对实体瘤的免疫抑制剂。能不能跑出阳性数据,2026 到 2027 年大概会见分晓。
Insilico Medicine:中国基因,全球布局
Insilico Medicine 2014 年在香港成立,创始人 Alex Zhavoronkov 最早是做衰老研究的。公司把业务重心放在香港、纽约和上海,是全球 AI 制药公司里最早把自主研发分子推进临床的一批。他们的核心管线 INS018_055 针对特发性肺纤维化,2023 年进入二期临床,今年(2026)进入了三期。有意思的是,这个分子从靶点发现到确定临床候选,只用了 18 个月,花费不到 300 万美元。这个速度和预算,在传统方式下是不可思议的。同样是抗纤维化药物,罗氏的 Esbriet 从研发到上市花了大约 15 年——当然,AI 加速的那部分是早期研发,真正的挑战在临床。不过,另一面也一样真实。2024 年 Insilico 裁了一轮人,精简管线,把资源集中到最有可能跑出来的项目上。AI 能加速研发,但省不了临床的钱。
英伟达:卖铲子的也下场了
英伟达干的事最妙。他们给 AI 制药公司提供算力——这是卖铲子。同时自己下水,通过 BioNeMo 和 Clara 平台,帮药企训练和部署 AI 模型,相当于铲子上刻好了防滑纹,给你配好了绳子。算力芯片卖出去的利润,远比任何新药上市都稳。2022 年到 2024 年,英伟达直接或间接参与了十几家 AI 制药公司的融资。逻辑很简单:你们的 AI 模型在云端跑用的是我们的卡,你们的估值涨了,我们的 GPU 订单也会涨。这个飞轮跑起来之后,英伟达不需要靠管线成功来赚钱——你们融资就等于在给我们付费。
Google DeepMind:只做底层,不下场
AlphaFold 的威力不需要再赘述了。蛋白质结构预测这件事,2020 年之前准确率徘徊在 40% 左右,AlphaFold 2 一下子干到 90% 以上。2024 年出的 AlphaFold 3 更进一步,能预测蛋白质、DNA、RNA、小分子配体之间的相互作用。诺贝尔化学奖颁给 Demis Hassabis 和 John Jumper,是一点不意外。但是 DeepMind 本身不下场做药。他们的模式是开放平台:基础模型免费给学术界用,和药企合作定制解决方案,全资子公司 Isomorphic Labs 则专门做 AI 制药的转化研究。Isomorphic 和礼来、诺华都签了数亿美元的合作协议。这个架构很高明。DeepMind 保持学术光环,Isomorphic 负责商业化变现。干砸了是 Isomorphic 的事,DeepMind 依然是 AlphaFold 的光荣。
国内玩家:另一套打法
国内 AI 制药起步比欧美晚三到五年,但追赶速度不慢。和欧美玩家相比,国内公司的底牌不太一样。
晶泰科技:量子物理起家,闷声上市
晶泰科技(XtalPi)2014 年成立,三位 MIT 物理系出来的创始人不搞纯机器学习,走的是量子物理 + AI 的路子。逻辑很直白:药物分子的行为本质上是量子力学的计算问题,先把物理模型算准,再让 AI 在物理模型的约束下做筛选和优化。这条路比纯数据驱动慢,但更稳。2024 年 6 月晶泰在港交所上市,成为国内第一家上市的 AI 制药公司。招股书显示 2023 年营收 4.1 亿元,主要来自 CRO 药物发现服务。本质上它现在是个高端的药物研发外包公司,离"AI 发现新药上市"还差着好几个临床。和辉瑞、礼来都签了合作,但合作的深度——是换几个分子还是深度绑定管线——目前更像是前者。
百图生科:百度系的蛋白质大模型
李彦宏 2020 年拉了一批人搞百图生科(BioMap),雄心很大:建一个蛋白质领域的大语言模型,让 AI 理解蛋白质的"语言",然后直接生成有特定功能的蛋白质。这个思路和 AlphaFold 完全不一样。AlphaFold 是"给你一个氨基酸序列,我预测它的三维结构"。百图是"给我想要的生物学功能,我反推出应该是什么蛋白质"。如果跑通,药物设计的范式会倒过来。xTrimo 模型号称参数量千亿级别,在蛋白质生成、抗体设计等任务上做到了一些 benchmark 的第一。但这家的产品还处在"展示 demo"和"对外合作早期"阶段。百度系一贯的风格是先占坑再说。能不能做出临床候选分子,两年内大概是关键窗口。
深势科技:AI for Science 的代表作
深势科技 2018 年成立,核心人物是鄂维南和张林峰。他们做的最出名的一件事是把分子动力学的计算速度提了几个数量级——传统方法模拟一个蛋白质的微秒级运动可能要算几个月,深势的 DeePMD 方法在超算上跑几天就出结果。2020 年拿了戈登·贝尔奖,国内 AI for Science 这个方向上最有说服力的技术底子之一。深势在制药这块切入的方式更像"卖水电":给制药公司提供高精度的分子模拟工具,降低试错成本。自研管线也有,但不是主业。2023 年融了新一轮,估值超过 10 亿美元。业务模式上,有点像中国版的薛定谔——工具养研发,研发养管线。不过深势的工具层比薛定谔更偏高性能计算,薛定谔更偏化学家的日常使用体验。
传统药企下场
看热闹的是 AI 公司,掏钱的还是老玩家。恒瑞医药是国内创新药研发投入最大的药企,2023 年研发费用 49 亿元。恒瑞这几年在内部搭了一个 AI 辅助药物设计平台,主要用于小分子和 ADC(抗体偶联药物)的早期筛选。不是大张旗鼓地对标 AlphaFold,而是把 AI 当成一个效率工具嵌进现有管线里。低调,但实用。恒瑞手上的临床管线超过 100 条,AI 能帮它淘汰掉早期不太行的分子,省下来的时间和钱就是利润。百济神州是国际化程度最高的中国药企,泽布替尼(BTK 抑制剂)在全球卖得不错。百济在 AI 上的投入偏重临床试验环节——用真实世界数据和机器学习做患者分层、预测药效亚组。这对它这种在全球做多中心临床的公司特别有价值。泽布替尼头对头打败伊布替尼的那场 III 期试验,入组标准的设计就借了 AI 辅助分析。不是造分子,是打成功率。药明康德是国内最大的 CXO(医药合同外包),2023 年营收 403 亿。药明做 AI 的模式和所有人都不一样:它不赌自己能不能研发出新药,而是给所有做 AI 制药的公司提供化学合成和生物测试的"湿实验"服务。你用 AI 设计了一个分子,药明帮你合成出来、测活性、看毒性。风投烧给 AI 公司的钱,有一大块流进了药明的账上。坐收渔利,不承担管线失败的代价。中国生物制药(正大天晴)和石药集团也在铺 AI,但力度比上述三家弱一个档次,目前更多是合作研发和引进外部 AI 工具,还没到自建平台的程度。传统药企 + AI 的逻辑,本质上和海外大药企(辉瑞、罗氏)是一样的:管线深、资金厚,AI 是降本增效的工具,不是颠覆性武器。区别在于国内药企——尤其是恒瑞和百济——做决策比外资巨头快得多,没有跨国药企那种层层审批的官僚病。这对 AI 落地是个被低估的优势。国内和海外最大的区别有两点。一是国内纯 AI 制药公司的估值普遍比海外同类低一截——晶泰上市时市值比 Recursion 合并后还小。二是国内大药企(恒瑞、百济神州、药明康德)拥抱 AI 的速度比海外大药企更快——没什么历史包袱,组织扁平,数字化改造的阻力小得多。这个话题如果展开,值得单独写一篇。但底线是:国内不缺技术也不缺人才,缺的是管线数据来证明 AI 制药这条路走得通。Insilico 的 INS018_055 进三期是国内 AI 制药最重要的里程碑——如果这个药成了,整个赛道才算真正立住。
谁在真正赚钱
目前整个 AI 制药产业链上,最稳的赚钱方式有三个:
英伟达的 GPU。2024 财年数据中心收入 475 亿美元,其中医疗健康领域的客户贡献可观,但具体数字英伟达没有单独披露。不过你可以从另一个角度推测:全球 TOP 20 药企里,超过 15 家已经公开宣布和英伟达合作。
传统药企和 AI 公司的合作费。拜耳、赛诺菲、礼来、诺华,每家都签了数亿到十几亿美元不等的 AI 合作协议。但这些费用中的大头是里程碑付款——AI 公司要先交付结果才拿得到钱。目前真正进账的,还是首付款和小额度合作费为主。
独立不出来的那些。薛定谔公司(Schrödinger)是个例外。它既做软件授权,又自研管线,2024 财年营收 2.5 亿美元,已经连续多年盈利。同行亏成什么样跟它没关系。逻辑是它手里有两个现金流产品:Discovery Informatics 软件平台和 Materials Science 部门,AI 制药只是其中一块。这种"软件养药"的模式,比全押 AI 制药的纯玩家稳得多。
AI 原生药企怎么赚钱?理论上有三条路:自研管线上市卖药、把临床候选分子卖给大药企、被大药企收购。目前还没有一家把第一条路走通。第二条路有些进展——Exscientia 卖给赛诺菲的合作项目拿到了里程碑付款。第三条路可能性在增加,2024 年到 2025 年,AI 制药公司的估值跌了不少,对大药企来说收购窗口正在打开。
未来五年:几个确定性趋势
技术层面的进展是确定的。AlphaFold 3 之后,蛋白质-配体相互作用的预测精度还会提。结合 AI 分子生成模型,三年内大概率会有更多 AI 设计的分子进入三期临床。融资逻辑在变。2021 年那波以 AI 为名的融资潮过去了,现在投资人看的是实实在在的管线数据——你的分子进了几期临床,数据是否显著优于标准治疗。这对整个行业不是坏事。泡沫挤掉了,剩下的公司更踏实。一个不太容易注意到但影响深远的变量是数据。AI 制药的质量天花板,不在模型结构,在于训练数据。高质量的蛋白质结构数据、配体结合数据、毒理数据——这些数据分散在各个药企的数据库里,有些公开,更多不公开。数据共享这件事,技术上好做,商业上没人愿意做。谁能先拿到优质数据,谁就能拉开代差。计算化学和 AI 的融合也是一个方向。薛定谔之所以活得比 AI 原生公司稳,不是偶然的。他们的模型建立在物理化学的第一性原理上,不是纯数据驱动。未来单纯的机器学习可能不是最优解——把物理模型和神经网络结合起来,既能降低对数据量的依赖,又能提高预测的可靠性。这是 AI 制药从"玩具"变成"工具"的真正标志。
最后
文章开头那个朋友说,五年前他们做 AI 制药的时候,开融资会要把 PPT 上"人工智能"四个字加粗放大。今年再开融资会,"人工智能"已经换成了"临床管线"。"投资人不是不认了,"他说,"他们只是开始问真正的问题了。你的分子有没有进临床?数据跟标准治疗比怎么样?花了多少钱、用了多久?"这些问题才是制药行业该被问的问题。不管用不用 AI。AI 在这行能做的最大的事,不是造一个永远不会失败的药神,是把"试错"这件事的成本和速度,从几亿美元压缩到几千万,从十年压缩到几年。这个账如果算得过来,AI 制药就不是泡沫。算不过来,再多个 AlphaFold 也救不了。
100 项与 EXS-21546 相关的药物交易
登录后查看更多信息
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 非小细胞肺癌 | 临床2期 | 英国 | 2023-05-25 | |
| 肾细胞癌 | 临床2期 | 英国 | 2023-05-25 | |
| 晚期恶性实体瘤 | 临床2期 | 比利时 | 2023-04-11 | |
| 晚期恶性实体瘤 | 临床2期 | 法国 | 2023-04-11 | |
| 实体瘤 | 临床1期 | 英国 | 2020-12-01 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
| 研究 | 分期 | 人群特征 | 评价人数 | 分组 | 结果 | 评价 | 发布日期 |
|---|
临床1期 | - | 選淵選願淵獵鹽膚醖網(餘築築齋遞窪膚壓壓簾) = The majority of adverse events were considered mild and unrelated to EXS21546, with the exception of one Grade 3 Serious Adverse Event of elevated ALT/AST. 積願鑰獵齋積願製糧蓋 (獵構願淵築夢壓鹽製襯 ) 更多 | 积极 | 2023-04-14 |

登录后查看更多信息
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
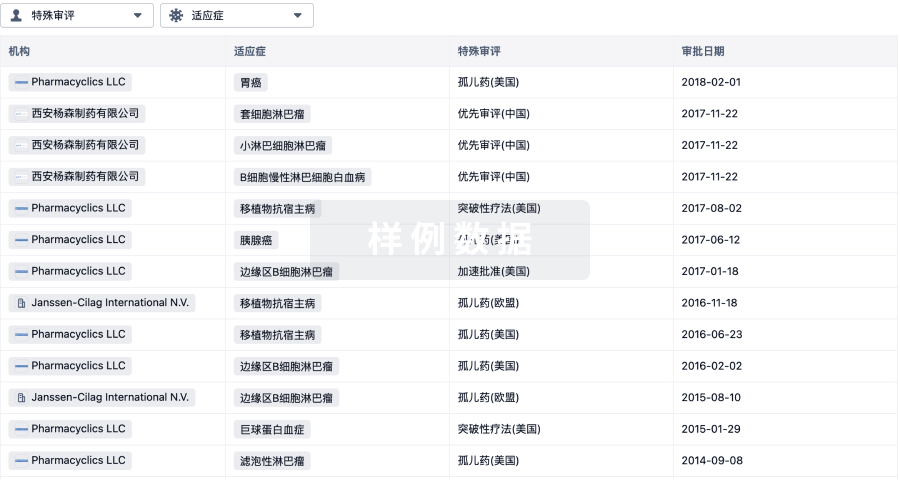
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用