预约演示
更新于:2026-02-01

Getinge AB
更新于:2026-02-01
概览
关联
NCT07286890
A Real-World Post-Market Clinical Follow-Up Study to Evaluate the Safety and Performance of Getinge's Beating Heart Product Family in Patients Undergoing Beating Heart Coronary Artery Bypass Graft Surgery
NCT07322913
Post-Market Clinical Follow-up Registry to Evaluate the Safety and Performance of the Intervascular Vascular Grafts and Patches in Patients Undergoing Bypass, Replacement, or Repair of Aortic, Peripheral, or Carotid Arteries
NCT07161583
Post-Market Clinical Follow-up Registry to Evaluate the Safety and Performance of the Atrium Advanta VXT and Flixene Vascular Grafts in Patients Undergoing Surgical Repair or Replacement of Peripheral Arteries

100 项与 Getinge AB 相关的临床结果
登录后查看更多信息
登录后查看更多信息
2025-09-12JOURNAL OF CLINICAL MONITORING AND COMPUTING
Towards reliable prediction of intraoperative hypotension: a cross-center evaluation of deep learning-based and MAP-derived methods.
Article
作者: Jacobsson, Martin ; Björne, Håkan ; Winski, Greg ; Lundström, Niclas ; Chaari, Nada ; Hallbäck, Magnus
Intraoperative hypotension (IOH) is associated with an increased risk of heart and kidney complications. Although AI tools aim to predict IOH, their real-world reliability is often overstated due to biased data selection. This study introduces a framework to enhance reliability by: (1) including borderline blood pressure cases (65-75 mmHg, the "Gray Zone"), (2) comparing AI model to simple blood pressure threshold, and (3) validating across diverse surgical cohorts, centers and demographics. Using datasets from Karolinska University Hospital (Sweden) and VitalDB (Korea), we found AI model performs better than MAP threshold method in more ambiguous cases. In contrast, when hypotensive and non-hypotensive cases had clearly separated MAP values, both methods performed similarly well. Cross-validation revealed asymmetric generalizability: models trained on datasets containing more borderline (Gray Zone) cases generalized better to datasets with clearer class separation, whereas the reverse struggled. To ensure fair model comparison and reduce dataset-specific bias, we standardized the MAP difference between positive (hypotension) and negative (non-hypotension) samples at the time of prediction. This virtually eliminated the class separation and demonstrated that inflated performance in some datasets can be attributed to selection bias rather than true model generalizability. Age also influenced generalization: Cross-age validation revealed models trained on older patients generalized better to younger cohorts, whereas differences in ASA classification had minimal effect. These findings highlight the need for realistic validation to bridge the gap between AI research and clinical practice.
2024-10-01ANESTHESIA AND ANALGESIA
Validation of a Novel Method for Noninvasive Mixed Venous Oxygen Saturation Monitoring in Anesthetized Children
Article
作者: Steiner, Kristoffer ; Karlsson, Jacob ; Andersson, Andreas ; Wallin, Mats ; Sjöberg, Gunnar ; Svedmyr, Anders ; Lönnqvist, Per-Arne ; Hallbäck, Magnus
BACKGROUND::
Mixed venous oxygen saturation (SvO2) is a critical variable in the assessment of oxygen supply and demand but is rarely used in children due to the invasive nature of pulmonary artery catheters. The aim of this prospective, observational study was to investigate the accuracy of noninvasively measured SvO2 acquired by the novel capnodynamic method, based on differential Fick equation (Capno-SvO2), against gold standard CO-oximetry.
METHODS::
Capno-SvO2 was compared to SvO2 measured by pulmonary artery blood gas CO-oximetry in children undergoing cardiac catheter interventions and subjected to moderate hemodynamic challenges. Bland-Altman analysis was used to describe the agreement of absolute values between CO-oximetry and Capno-SvO2, and a concordance rate was calculated to evaluate the ability of Capno-SvO2 to track change.
RESULTS::
Twenty-five procedures were included in the study. Capno-SvO2 showed a bias toward CO-oximetry of +3 percentage points; upper and lower limits of agreement were +11 percentage points (95% confidence interval [CI], 9–14) and −5 percentage points (95% CI, −8 to −3), respectively. The concordance rate was 92% (95% CI, 89–96).
CONCLUSIONS::
In conclusion, this first clinical application of a novel concept for noninvasive SvO2 monitoring without the need for a pulmonary artery catheter indicates that Capno-SvO2 generates absolute values and trending capacity in close agreement with the gold standard reference method.
2023-12-01Journal of clinical monitoring and computing
Capnodynamic monitoring of lung volume and pulmonary blood flow during alveolar recruitment: a prospective observational study in postoperative cardiac patients
Article
作者: Hallbäck, M ; Aneman, A ; McCanny, P ; Schulz, L F ; Iftikhar, H ; Austin, D ; Wallin, M ; Stewart, A ; O'Regan, W ; Keleher, E
Alveolar recruitment manoeuvres may mitigate ventilation and perfusion mismatch after cardiac surgery. Monitoring the efficacy of recruitment manoeuvres should provide concurrent information on pulmonary and cardiac changes. This study in postoperative cardiac patients applied capnodynamic monitoring of changes in end-expiratory lung volume and effective pulmonary blood flow. Alveolar recruitment was performed by incremental increases in positive end-expiratory pressure (PEEP) to a maximum of 15 cmH2O from a baseline of 5 cmH2O over 30 min. The change in systemic oxygen delivery index after the recruitment manoeuvre was used to identify responders (> 10% increase) with all other changes (≤ 10%) denoting non-responders. Mixed factor ANOVA using Bonferroni correction for multiple comparisons was used to denote significant changes (p < 0.05) reported as mean differences and 95% CI. Changes in end-expiratory lung volume and effective pulmonary blood flow were correlated using Pearson's regression. Twenty-seven (42%) of 64 patients were responders increasing oxygen delivery index by 172 (95% CI 61-2984) mL min-1 m-2 (p < 0.001). End-expiratory lung volume increased by 549 (95% CI 220-1116) mL (p = 0.042) in responders associated with an increase in effective pulmonary blood flow of 1140 (95% CI 435-2146) mL min-1 (p = 0.012) compared to non-responders. A positive correlation (r = 0.79, 95% CI 0.5-0.90, p < 0.001) between increased end-expiratory lung volume and effective pulmonary blood flow was only observed in responders. Changes in oxygen delivery index after lung recruitment were correlated to changes in end-expiratory lung volume (r = 0.39, 95% CI 0.16-0.59, p = 0.002) and effective pulmonary blood flow (r = 0.60, 95% CI 0.41-0.74, p < 0.001). Capnodynamic monitoring of end-expiratory lung volume and effective pulmonary blood flow early in postoperative cardiac patients identified a characteristic parallel increase in both lung volume and perfusion after the recruitment manoeuvre in patients with a significant increase in oxygen delivery.Trial registration This study was registered on ClinicalTrials.gov (NCT05082168, 18th of October 2021).
2026-01-21
2025-12-29
·健识局
IPO申请上市
100 项与 Getinge AB 相关的药物交易
登录后查看更多信息
100 项与 Getinge AB 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年06月13日管线快照
管线布局中药物为当前组织机构及其子机构作为药物机构进行统计,早期临床1期并入临床1期,临床1/2期并入临床2期,临床2/3期并入临床3期
其他
1
登录后查看更多信息
当前项目
登录后查看更多信息
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
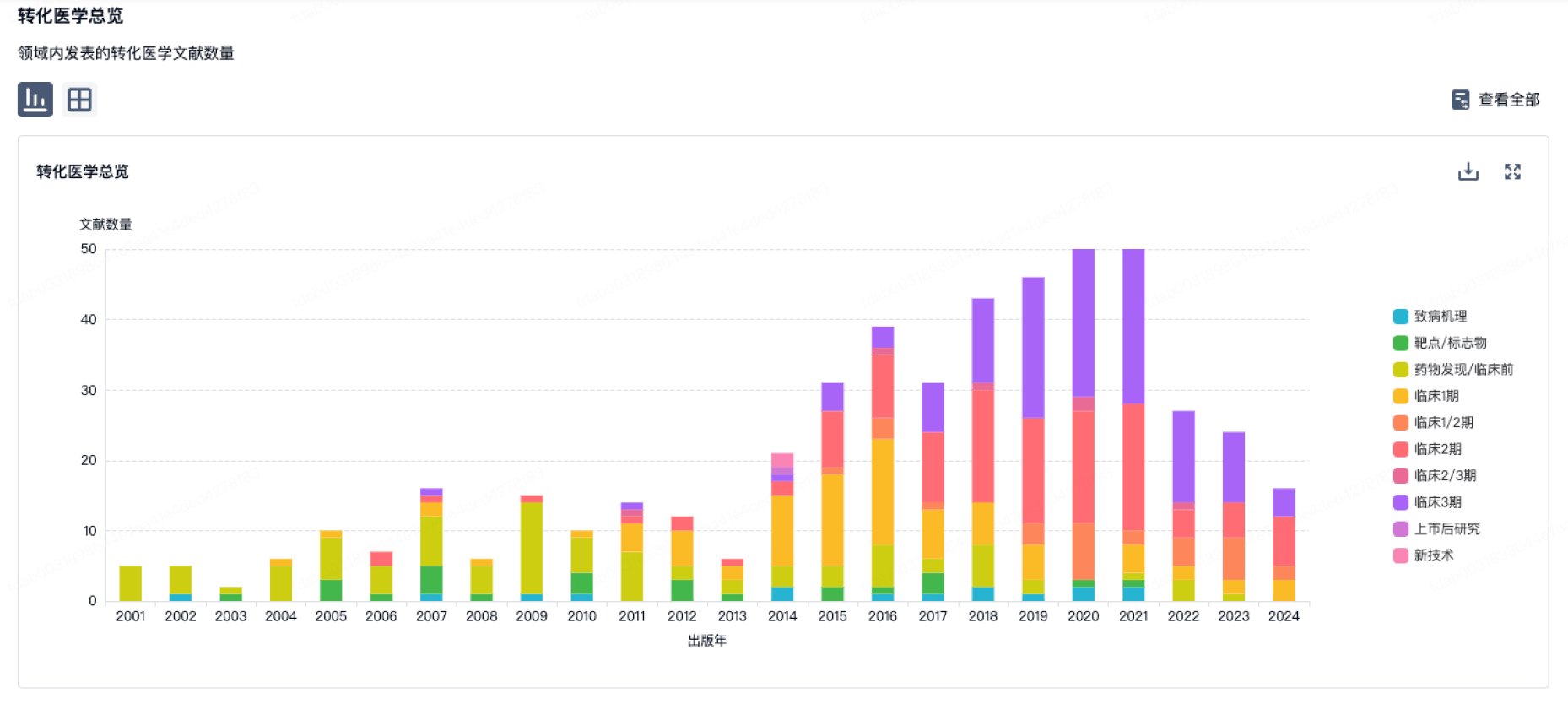
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
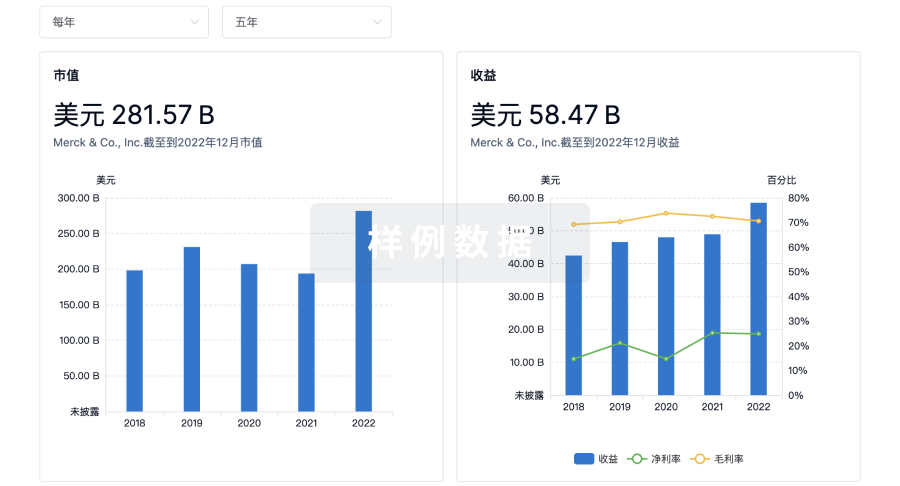
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
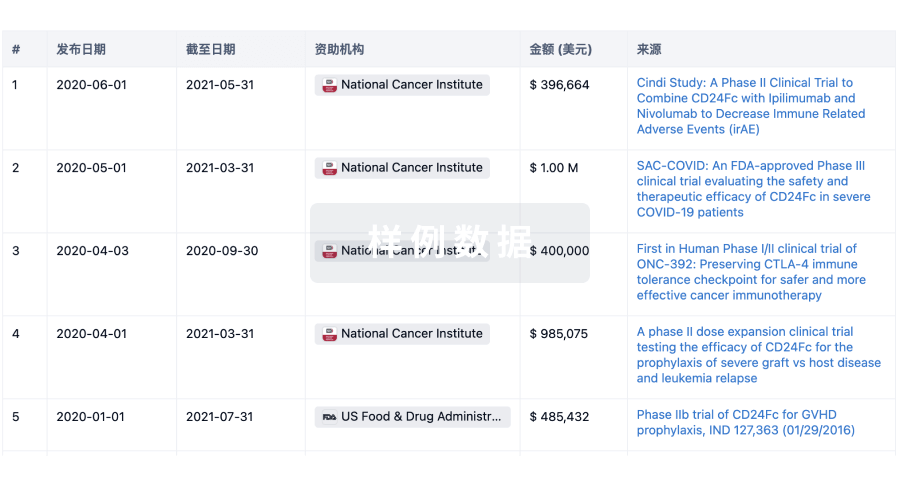
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用