预约演示
更新于:2026-05-12

American Medical Systems, Inc.
更新于:2026-05-12
概览
关联
NCT01862601
Study to Evaluate the Safety and Performance of the JetTouch Needle-Free Endoscopic Injection System to Deliver Saline Into the Bladder Wall of Healthy Subjects
NCT01725984
AMS AdVance and AdVance XP Male Sling Systems for the Treatment of Stress Urinary Incontinence Following Prostatectomy: Evaluation of Safety, Efficacy, and Quality of Life Through Retrospective Chart Review and Prospective Follow-up
NCT01500057
An Open-Label Randomized Phase 4 Study of Greenlight XPS Laser Versus BiVAP Saline Vaporization of the Prostate in Men With Symptomatic Benign Prostatic Hyperplasia
100 项与 American Medical Systems, Inc. 相关的临床结果
登录后查看更多信息
登录后查看更多信息
2011-02-10Proceedings of SPIE--the International Society for Optical Engineering
Interaction between high power 532nm laser and prostatic tissue: in vitro evaluation for laser prostatectomy
作者: Stinson, Douglas ; Kang, Hyun Wook ; Peng, Yihlih Steven
Photoselective vaporization of the prostate (PVP) has been developed for effective treatment of obstructive benign prostatic hyperplasia.To maximize tissue ablation for large prostate gland, identifying the optimal power level for PVP is still necessary.We investigated the effect of various power levels on in vitro bovine prostate ablation with a 532-nm laser system.A custom-made 532-nm laser was employed to provide various power levels, delivered through a newly designed 750-μm side-firing fiber.Tissue ablation efficiency was evaluated in terms of power (P; 120∼200W), treatment speed of fiber (TS; 2∼8 mm/s), and working distance between fiber and tissue surface (WD; 1∼5 mm).Coagulation depth was also estimated macroscopically and histol. (H&E) at various Ps.Both 180 and 200W yielded comparable ablated volume (104.3±24.7 vs. 104.1±23.9 mm3 at TS=4 mm/s and WD=2 mm; p=0.99); thus, 180W was identified as the optimal power to maximize tissue ablation, by removing tissue up to 80% faster than 120W (41.7±9.9 vs. 23.2±3.4 mm3/s at TS=4 mm/s and WD=2 mm; p<0.005).Tissue ablation was maximized at TS=4 mm/s and ablated equally efficiently at up to 3 mm WD (104.5±16.7 mm3 for WD=1 mm vs. 93.4±7.4 mm3 for WD=3 mm at 180W; p=0.33).The mean thickness of coagulation zone for 180W was 20% thicker than that for 120W (1.31±0.17 vs. 1.09±0.16 mm; p<0.005).The current in vitro study demonstrated that 180W was the optimal power to maximize tissue ablation efficiency with enhanced coagulation characteristics.
2010-10-01Lasers in surgery and medicine2区 · 医学
Laser vaporization of the prostate in vivo: Experience with the 150‐W 980‐nm diode laser in living canines
2区 · 医学
Article
作者: Alexander Bachmann ; Malte Rieken ; George R. Ruth ; Hyun Wook Kang ; Ed Koullick
Abstract:
Background and Objective:
Anatomic, tissue ablation and coagulation, and histopathologic outcomes of the 150‐W 980‐nm diode laser selective light vaporization (SLV™) of the prostate in the first survival study of living canines were analyzed.
Study Design/Materials and Methods:
Ten dogs underwent anterograde SLV™ with the 150‐W 980‐nm laser delivered by its side‐firing fiber (Fusion™). Postoperatively, two dogs were euthanized at 3 hours as planned, six at 2–7 days due to complications, and two, without complications, at 8 weeks as planned. Laser energy and time were recorded. Prostates were sectioned, measured, and histologically analyzed after hematoxylin and eosin (H&E), triphenyltetrazolium chloride (TTC), or Gomori trichrome (GT) staining.
Results:
SLV™ acutely and hemostatically created a 0.6 ± 0.3 cm3 cavity in the 3‐hour group accompanied by H&E‐ and TTC‐identified coagulation necrosis of up to 9.5 mm (6.1 ± 1.2 mm) that led to prostatic slough‐induced obstruction and perforation in six of eight (75%) surviving animals, necessitating unplanned euthanasia within 2–7 days. H&E‐ and GT‐stained prostates at 8 weeks postoperatively showed large (9.6 ± 1.4 cm3) re‐epithelialized prostatic cavities with persistent diffuse interstitial Prostatitis and collagenous fibrosis.
Conclusion:
SLV™ with the 150‐W 980‐nm diode laser in living canines produced small cavities acutely, and was accompanied by deeply necrotic prostatic slough‐induced obstruction and perforation in a majority of animals. A minority survived SLV and had favorable anatomic outcomes whereas histology revealed persisting inflammation. Further in vivo studies and a cautious clinical approach are recommended to finally evaluate the potential of SLV™ with the 150‐W 980‐nm diode laser. Lasers Surg. Med. 42:736–742, 2010 © 2010 Wiley‐Liss, Inc.
2010-10-01International urogynecology journal3区 · 医学
Effects of periurethral neuromuscular electrical stimulation on the voiding frequency in rats
3区 · 医学
Article
作者: Andrew D. Bicek ; Yingchun Zhang ; Guangjian Wang ; Gerald W. Timm
INTRODUCTION AND HYPOTHESIS:
This study aims to test the hypothesis that a urethra-to-bladder inhibitory pathway exists through which periurethral neuromuscular electrical stimulation (NMES) inhibits overactive bladder contractions in rats.
METHODS:
Bladder overactivity was induced in 22 female Sprague Dawley rats by injection of ketamine/xylazine/acepromizine (K/X/A). A bipolar electrode was placed surgically in the periurethral region to deliver NMES. Intravesical pressure, bladder inter-contraction interval (ICI) and voided volume (VV) were monitored while the bladder was continuously infused with saline.
RESULTS:
K/X/A induced more frequent bladder contractions (ICI = 48.6 +/- 20.1 s, before cutting the pubo-symphasis) compared to a 10-min ICI induced by urethane. NMES significantly increased ICI (63.1 +/- 31.3 s before vs. 97.2 +/- 42.9 s after NMES, p < 0.001) and VV (0.063 = 0.041 ml before vs. 0.088 = 0.044 ml after NMES, p < 0.02).
CONCLUSIONS:
Injection of K/X/A may potentially be used as a model of bladder overactivity. NMES inhibits bladder contractions in rats with bladder overactivity, which supports the existence of a urethra-to-bladder inhibitory pathway.
2026-03-25
专利侵权高管变更
100 项与 American Medical Systems, Inc. 相关的药物交易
登录后查看更多信息
100 项与 American Medical Systems, Inc. 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年05月19日管线快照
无数据报导
登录后保持更新
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
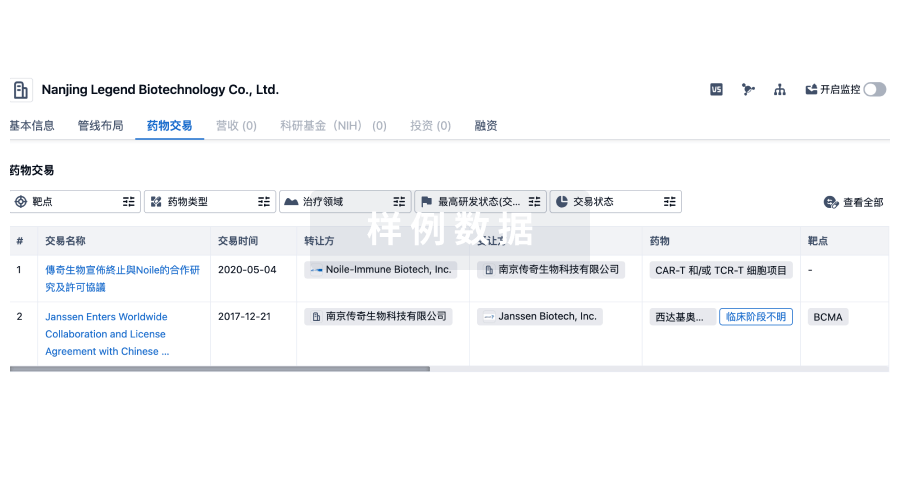
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
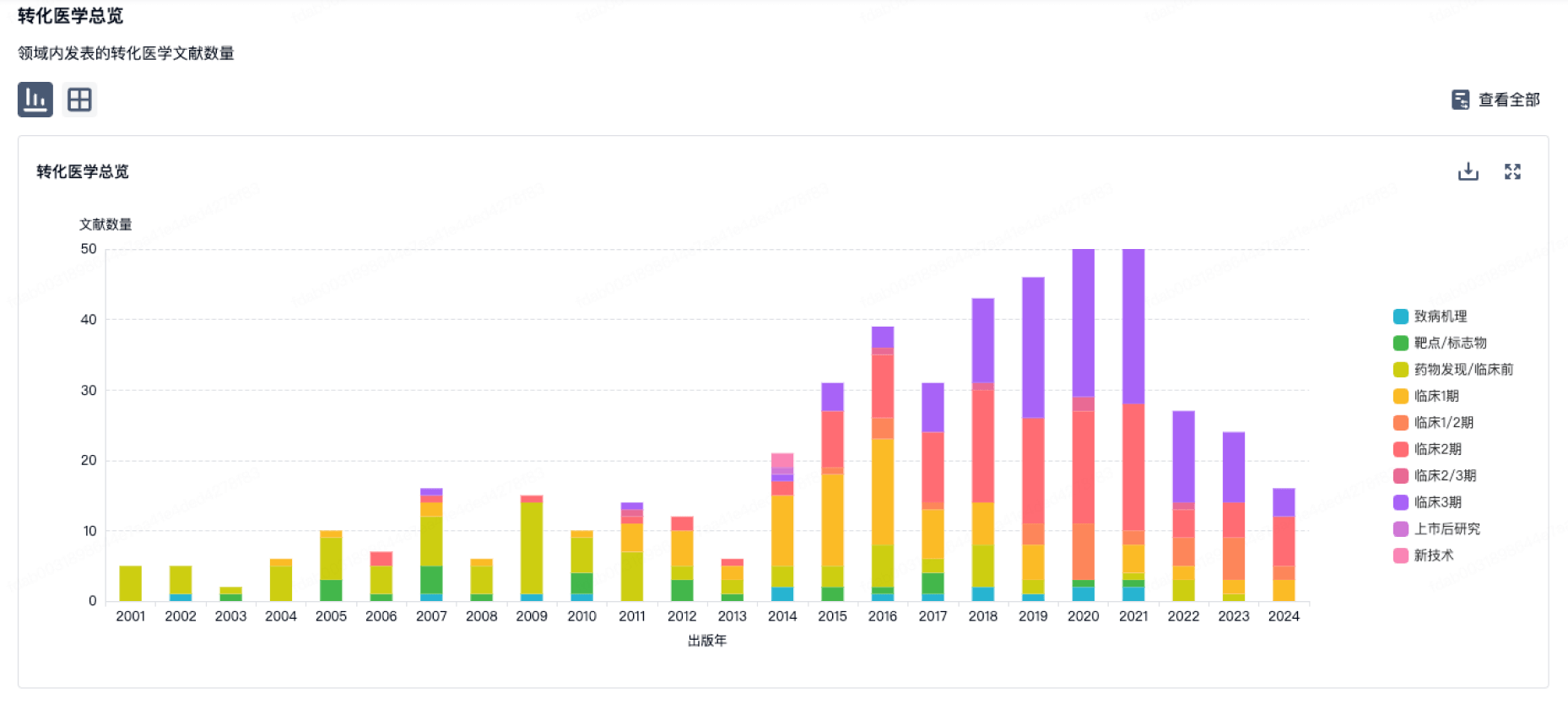
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
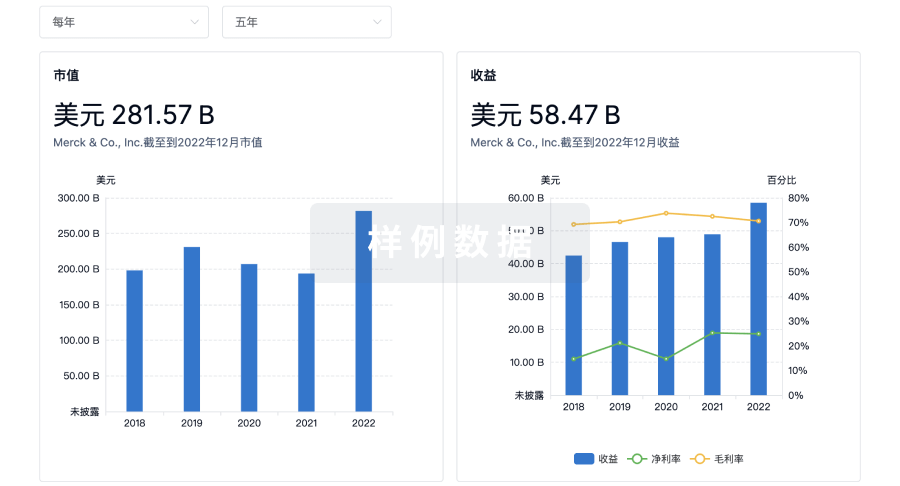
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用