预约演示
更新于:2026-06-16
Ningxia University
更新于:2026-06-16
概览
标签
其他疾病
肿瘤
神经系统疾病
小分子化药
化学药
多糖药物
疾病领域得分
一眼洞穿机构专注的疾病领域

技术平台
公司药物应用最多的技术
靶点
公司最常开发的靶点
关联
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |

靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |

100 项与 宁夏大学 相关的临床结果
登录后查看更多信息
登录后查看更多信息
2026-09-01Infectious Disease Modelling
Dynamics of a two-patch epidemic model with deterministic/stochastic migration and distributed delays
Article
作者: Shi, Zhenfeng ; Kang, Ting ; Wang, Qingyun ; Cao, Boqiang
We study the global dynamics of a two-patch epidemic model that integrates spatial migration, Erlang-distributed delays, and environmental stochasticity. The two patches are coupled by migration whose intensities are modulated by an Ornstein-Uhlenbeck (OU) process, capturing stochasticity but mean-reverting fluctuations in population movement, while the infection progression is described by a distributed delay structure represented through a linear-chain formulation. For the deterministic system, we establish threshold-type results that characterize disease extinction and persistence: the disease-free equilibrium is globally asymptotically stable when the basic reproduction number __-mml:math xmlns:mml="http://www.w3.org/1998/Math/MathML"-__ R 0 < 1 , whereas infection persists when __-mml:math xmlns:mml="http://www.w3.org/1998/Math/MathML"-__ R 0 > 1 . For the corresponding stochastic model, we derive explicit sufficient conditions for almost sure exponential extinction by constructing Lyapunov functions and exploiting the Metzler structure of the infected subsystem. Moreover, we prove that the stochastic system admits a stationary distribution when stochastic threshold __-mml:math xmlns:mml="http://www.w3.org/1998/Math/MathML"-__ R 0 s > 1 , which serves as a stochastic analogue of the endemic equilibrium and describes persistent random fluctuations of infection levels. Numerical simulations are provided to validate the theoretical findings and to quantify how distributed delays and OU-driven migration randomness shape long-term infection burden and stationary prevalence across patches. Notably, adjusting the noise intensity and the mean-reversion rate can redistribute the long-term infection burden between patches, which highlights how migration-driven randomness fundamentally reshapes spatial epidemic patterns.
2026-08-01Journal of Proteomics
Integrated analysis of transcriptomes and proteomes reveals the molecular mechanisms underlying the development of Dorper sheep hair follicles
Article
作者: Zhang, Ningyue ; Yang, Fan ; Wang, Siyu ; Wang, Chunguang ; Jing, Bin ; Li, Xinhai
Understanding the molecular mechanisms underlying normal hair follicle development is important for improving wool traits in sheep and skin traits in mammals. This study aims to investigate the genetic determinants influencing hair follicle (HF) development by conducting an integrated analysis of transcriptomic and proteomic datasets from skin tissues of adult Dorper ewes at different groups of shedding and non-shedding. We employed DIA quantitative proteomics technology to identify 2176 differentially abundant proteins (DAPs) across three stages in both the shedding and non-shedding groups. Six DAPs were validated using parallel reaction monitoring (PRM) to confirm the reliability of the discovery proteomics data. Functional enrichment analysis revealed that a series of biological processes and signaling pathways associated with HF development, such as glutathione metabolism, ferroptosis, Wnt, JAK-STAT, and PI3K-Akt pathways, were strongly enriched by these DAPs. Association analysis and protein interaction network analysis further indicated that ACTG1, ANPEP, CTNNB1, GCLC, GCLM, CSNK2A2, COL1A1, GLUL, VTN, CDK6, IKBKG, STAM2, ITGA3, and members of the keratin (KRT) family may be key factors contributing to the developmental differences in the hair follicle cycle. Our study contributes to the understanding of the genetic and proteomic mechanisms underlying the normal growth and development of hair follicles and mammalian skin-related traits. SIGNIFICANCE: The morphology of secondary hair follicles in Dorper sheep plays a crucial role in determining the hair follicle cycle. The hair follicle cycle, as well as hair follicle growth and morphogenesis, are coordinated and complex processes. This study constructed a protein regulatory network within the signaling pathways associated with the cyclic growth and development of Dorper sheep hair follicles, and investigated key genes whose expression levels were positively correlated between mRNA and protein. Understanding the genetic mechanisms underlying the hair-shedding ability of Dorper sheep is crucial for enhancing the economic value of meat sheep and advancing the breeding of automatically hair-shedding sheep.
2026-07-01MEAT SCIENCE
Incorporation of ternary biological preservatives into reduced-salt frankfurters for extended shelf life and enhanced storage quality
Article
作者: Kong, Baohua ; Feng, Yangyang ; Liu, Qian ; Zhang, Hongwei ; Zhang, Jingming ; Liu, Yutong ; Liu, Didi ; Cao, Songmin ; Li, Xin ; Cao, Chuanai
The significantly shortened shelf life of reduced-salt frankfurters necessitates the development of effective, non-chemical preservatives. This study aimed to optimise the ratio of nisin, ε-polylysine (ε-PL), and chitosan (CTS) and elucidate its effects on the bacterial community, physicochemical properties, and shelf life of reduced-salt frankfurters during refrigeration. The results indicated that the optimal composition of the ternary biological preservative (TBP) was 0.16, 0.18, and 0.47 g/kg of nisin, ε-PL, and CTS, respectively. The TBP significantly reduced bacterial diversity and inhibited spoilage bacteria such as Brochothrix thermosphacta, decreasing its relative abundance from 40.34% in the control group to 23.02% by day 70, while regulating the overall bacterial community composition. Moreover, the TBP-enhanced reduced-salt frankfurters maintained superior moisture and colour characteristics during storage at 4 °C, minimised pH fluctuations, decelerated fat oxidation and protein degradation, and ultimately delayed texture loss and flavour deterioration. A validated predictive model confirmed a 102-day shelf life for the TBP-enhanced reduced-salt frankfurters, surpassing that of preservative-free samples by 54.55% and that of samples with commercially available preservatives (CAP) by 4.08%. Therefore, our findings demonstrate that the TBP represents an efficient biological preservative strategy, offering a robust solution for developing non-chemical, high-quality, shelf-stable reduced-salt emulsified meat products.
100 项与 宁夏大学 相关的药物交易
登录后查看更多信息
100 项与 宁夏大学 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年07月21日管线快照
管线布局中药物为当前组织机构及其子机构作为药物机构进行统计,早期临床1期并入临床1期,临床1/2期并入临床2期,临床2/3期并入临床3期
药物发现
3
6
临床前
登录后查看更多信息
当前项目
登录后查看更多信息
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
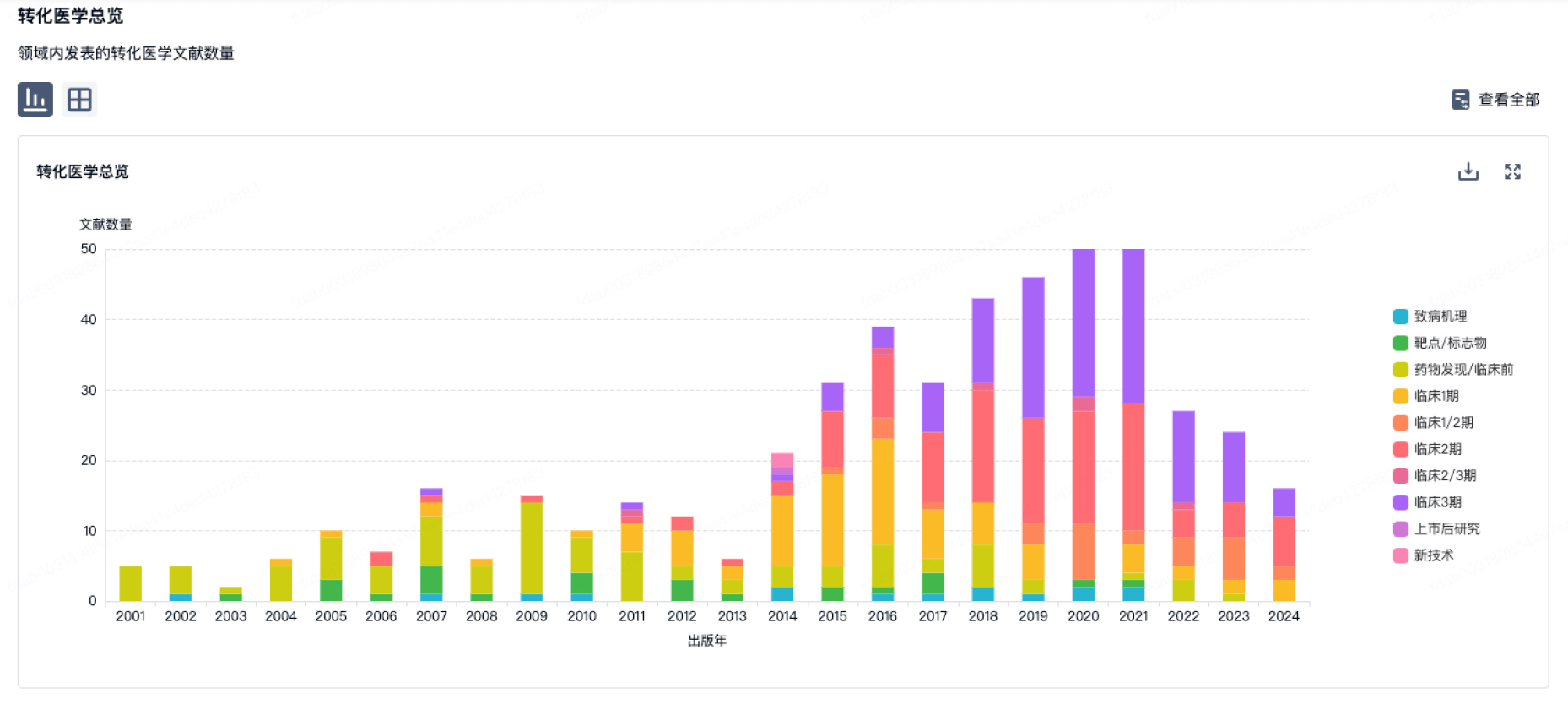
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用