预约演示
更新于:2026-06-06
Kanamycin Sulfate
硫酸卡那霉素
更新于:2026-06-06
概要
基本信息
药物类型 小分子化药 |
别名 4,6-diamino-2-hydroxy-1,3-cyclohexane 3,6'diamino-3,6'-dideoxydi-α-D-glucoside、4,6-diamino-2-hydroxy-1,3-cyclohexylene 3,6'-diamino-3,6'-dideoxydi-D-glucopyranoside、kamamycin Sulfate + [14] |
作用方式 抑制剂 |
作用机制 30S subunit抑制剂(30S核糖体亚基抑制剂) |
治疗领域 |
在研适应症 |
非在研适应症- |
原研机构 |
在研机构 |
非在研机构- |
权益机构- |
最高研发阶段批准上市 |
首次获批日期 中国 (1955-01-01), |
最高研发阶段(中国)批准上市 |
特殊审评- |
登录后查看时间轴
结构/序列
分子式C18H38N4O15S |
InChIKeyOOYGSFOGFJDDHP-KMCOLRRFSA-N |
CAS号25389-94-0 |
关联
8
项与 硫酸卡那霉素 相关的临床试验NCT04828564
An Open-Label, Multicenter, Parallel-Group, Randomized, Phase II/III Study to Evaluate the Efficacy and Safety of Favipiravir and Ribavirin Formulation for Treatment of COVID-19
This is a national, multicenter, open-label, randomized, phase II/III trial that evaluates the efficacy and safety of favipiravir and ribavirin in the treatment of patients with confirmed COVID-19 observed within 72 hours. Approximately 100 patients will be randomized in 1:1 ratio and divided into two groups.
开始日期2021-04-01 |
申办/合作机构 |

NCT02409290
STREAM: The Evaluation of a Standard Treatment Regimen of Anti-tuberculosis Drugs for Patients With MDR-TB
Tuberculosis (TB) is a common, infectious, bacterial disease that is spread when an infected person transmits their saliva through the air by coughing or sneezing. Despite the availability and effectiveness of affordable six-month treatments for tuberculosis (TB), the worldwide control of this disease is currently being impacted by the emergence of multidrug resistant TB (MDR-TB). MDR-TB refers to TB that is resistant to at least isoniazid and rifampicin. These are the two most powerful first-line drugs used to treat pulmonary TB. MDR-TB usually develops while a person is taking TB treatment due to either inappropriate treatment or failure of patients to comply with their treatment. This strain of drug-resistant bacteria can also be spread to other people through the air. With the incident rate of MDR-TB on the rise, there is a need to investigate optimal treatment regimens using effective drugs.
开始日期2016-03-01 |
申办/合作机构 IUATLD, Inc [+3] |
NCT03057756
Nine Months' Short Course Regimen Protocol for the Treatment of Multidrug Resistance-tuberculosis (MDR-TB) Patients in Gabon
The principal objective is to evaluate a cure rate and number of adverse events of with confirmed multidrug-resistant tuberculosis patient treated with a 9months regimen.
开始日期2015-09-11 |

100 项与 硫酸卡那霉素 相关的临床结果
登录后查看更多信息
100 项与 硫酸卡那霉素 相关的转化医学
登录后查看更多信息
100 项与 硫酸卡那霉素 相关的专利(医药)
登录后查看更多信息
14,167
项与 硫酸卡那霉素 相关的文献(医药)2026-09-01·BIOORGANIC & MEDICINAL CHEMISTRY LETTERS
Design, synthesis and antibacterial evaluation of novel unsaturated butenolide-fatty amine hybrids against multidrug-resistant pathogens
Article
作者: Zi, Xue-Qiong ; Qin, Ding-Mei ; Tang, Su-Yun ; Zhao, Qing ; Liu, Xu-Jun ; Zhu, Shu-Yan ; Pu, Hong ; Wang, Yue-Ping ; Zhang, Xiao-Mei
To address the growing public health challenge of multidrug-resistant bacterial infections, 26 new butenolide amides bearing fatty chains of different lengths (CnH2n+1, n = 4-16) were designed and synthesized and evaluated for their antibacterial activity. The antibacterial activities of the derivatives were evaluted against four clinically common pathogens, Acinetobacter baumannii ATCC 19606(A. baumannii), Klebsiella pneumoniae ATCC 13883(K. pneumoniae), Pseudomonas aeruginosa ATCC 15442(P. aeruginosa) and methicillin-resistant Staphylococcus aureus ATCC 43300(MRSA 43300). The results indicated that derivative 17j, with a 13‑carbon fatty chain, exhibited prominent antibacterial activity, with MIC values of 0.25 μg/mL against A. baumannii and K. pneumoniae, 0.125 μg/mL against P. aeruginosa, and 1 μg/mL against MRSA 43300. The antibacterial activity of 17j against A. baumannii, K. pneumoniae and P. aeruginosa was approximately 64-fold higher than of that of kanamycin, while its activity against MRSA 43300 was close to that of vancomycin. Structure-activity relationship analysis revealed that the length of the fatty chain is a crucial determinant that impacts antibacterial activity. Cytotoxicity and hemolysis assays revealed that 17j exhibited very low toxicity toward mammalian cells (Beas-2B, SMMC-7721, MCF7) and red blood cells. The in vivo antibacterial activity of compound 17j was evaluated using the Galleria mellonella larval infection model, in which 17j showed better antibacterial activity than kanamycin. Scanning electron microscopy (SEM) analysis revealed that the likely mechanism of action involves the disruption of bacterial membrane integrity, leading to cell lysis and death. This research provides promising lead compounds for the development of antibacterial drugs targeting drug-resistant bacteria.
2026-08-01·BIOELECTROCHEMISTRY
A novel label-free electrochemical aptamer sensor based on base mismatch and strand displacement for detection of kanamycin
Article
作者: Yang, Hao ; Huang, Yu ; Ma, Hua ; Lan, Qiuyan ; Wang, Dandan ; Gu, Xia ; Fan, Yanru
Misuse of kanamycin in animal husbandry has led to serious food safety issues. In this study, a label-free electrochemical aptasensor based on the base mismatch and strand displacement was developed for detection of kanamycin residue in agricultural products. A novel ferrocene-naphthalimide derivative was employed as the electroactive indicator. The effects of complementary DNA (cDNA) probe length, position and number of mismatched bases in aptamer-cDNA duplex on the performance of displacement-based aptasensor were systematically investigated. The experimental results were in well accordance with the molecular simulation results. Under optimal conditions, the aptasensor exhibited good reproducibility, stability, selectivity, and a wide linear range of 1.0 × 10-10-1.0 × 10-4 g/mL, with a LOD of 1.1 × 10-11 g/mL (S/N = 3). The proposed aptasensor was used to detect kanamycin residues in milk and chicken liver. Satisfactory recoveries and relative standard deviations indicated that the aptasensor was competent for detection of kanamycin residues in agricultural products.
2026-07-01·BIOSENSORS & BIOELECTRONICS
High affinity and selective DNA aptamers for the detection of tobramycin in eye drops
Article
作者: Wong, Ka-Ying ; Zhao, Boya ; Johnson, Philip E ; Mu, Xinyuan ; Liu, Juewen ; Chao, Emily Hoi Pui ; Zhang, Xiaohan ; Liu, Qiushi
Tobramycin is a frontline aminoglycoside antibiotic with a narrow therapeutic window. Here, we report the selection of high-affinity DNA aptamers using a library-immobilization based SELEX strategy. The lead aptamer, TOB-2, binds tobramycin with a dissociation constant of 420 nM as determined by isothermal titration calorimetry, while exhibiting over 1000-fold weaker affinity for kanamycin. Structural characterization by mutation analysis, NMR spectroscopy, and circular dichroism spectroscopy reveals a non-G-quadruplex core sequence adopting a stem-loop architecture. Comparative evaluation against two previously reported aptamers highlights the superior binding performance of TOB-2. Leveraging this aptamer, a label-free fluorescent biosensor based on thioflavin T was developed, achieving a limit of detection of 29 nM and enabling accurate quantification of tobramycin in commercial TOBREX eye drops. Integration of this aptamer with electrochemical or other advanced sensing platforms may further enable real-time monitoring of this clinically important antibiotic.
219
项与 硫酸卡那霉素 相关的新闻(医药)2026-06-01
·今日头条
《畜牧兽医学报》2026年第57卷第4期刊登了
甘肃农业大学动物医学院
等单位
李晨阳, 吕莹, 惠宇韬, 杨敏
的文章——“
鸭疫里默氏杆菌6型SDRA05株的致病性和耐药性及其全基因组分析
”。该研究的
创新点
:首次系统解析了国内罕见的6型鸭疫里默氏杆菌SDRA05的全基因组特征,发现其具有较高致病性(LD₅₀ 2.15×10⁵ CFU)和多重耐药性(四环素+氨基糖苷类),并鉴定出7个功能密集基因岛(尤其GI6为耐药基因富集热点),揭示了II/IV/VI型分泌系统、黏附因子aftB及非核糖体肽合成酶sypB等多类毒力因子的分子基础,为6型RA的流行监测和精准防控提供了关键基因组数据。
识别阅读全文
鸭疫里默氏杆菌6型SDRA05株的致病性和耐药性及其全基因组分析
导读
研究背景与目的
鸭疫里默氏杆菌病是由鸭疫里默氏杆菌(RA)引起的急性传染病,常见于1~6周龄雏鸭,临床表现为食欲下降、呼吸急促、运动失调、角弓反张及抽搐,剖检可见纤维素性心包炎和肝周炎。该病可通过气溶胶及污染垫料、饲料、饮水传播,发病率超90%,死亡率5%~75%,幸存鸭生长缓慢,严重影响养殖效益。目前防治主要依靠疫苗和抗生素,但RA血清型众多(国内1、2、4、5型常见,6、10型呈上升趋势),加之耐药性不断增加,防治困难。国内研究多聚焦1、2、4、5型,对6型认识有限。本研究从临床病死鸭分离鉴定6型RA菌株SDRA05,系统分析其致病性、耐药性及全基因组特征,解析毒力与耐药的分子机制,为RA防控和药物干预提供理论依据。
1 材料与方法
1.1 样品与菌株
菌株分离自2024年7月山东潍坊某疑似感染鸭场病死鸭肝组织。药敏质控菌株ATCC 25922购自广东环凯微生物有限公司。
1.2 主要试剂
TSB、TSA培养基;琼脂粉、胰蛋白胨、酵母粉;2×Taq Master Mix;4S GreenPlus核酸染料、DNA Marker;微生物药敏纸片;胎牛血清。
1.3 菌株分离纯化与鉴定
分离纯化 :病死鸭肝脏和心脏病变组织划线接种TSA平板,37 ℃、5% CO₂培养18~24 h,挑取单菌落转TSB液体培养24 h,革兰染色镜检。使用16S rRNA通用引物FPCR扩增(目标产物约1 500 bp)。产物测序后NCBI BLAST比对,MEGA 11邻接法构建系统发育树确认种属。
1.4 致病性试验
单菌落TSB培养24 h,测OD
600 nm
并结合稀释平板计数。菌液稀释至10⁹ CFU·mL⁻¹后系列倍比稀释。30只健康7日龄雏鸭随机分6组(每组5只),前5组分别肌肉注射0.5 mL含菌量10⁵、10⁶、10⁷、10⁸、10⁹ CFU的SDRA05菌液;对照组注射等量无菌PBS。连续观察7 d,记录临床表现及死亡情况。死亡个体采集肝脏、心脏组织进行细菌再分离、革兰染色及16S rRNA鉴定。按Reed-Muench法计算LD₅₀。
1.5 菌株药敏试验
按CLSI推荐的K-B纸片扩散法,检测对氨苄西林、头孢吡肟、阿莫西林、四环素、诺氟沙星、环丙沙星、氯霉素、氟苯尼考、多黏菌素B、万古霉素、卡那霉素、链霉素12种抗生素的敏感性。质控菌株大肠杆菌ATCC 25922。
1.6 建库及基因组测序、组装
菌株TSA复苏后TSB培养24 h,11 000 r·min⁻¹离心10 min收集菌体。Illumina平台高通量测序。FastQC质量评估,Trimmomatic质量剪切,SPAdes拼接,gapclose优化gap,过滤500 bp以下片段,QUAST评估组装结果。
1.7 基因组圈图绘制
基因组上传proksee绘制圈图。Prokka预测CDS、tRNA、rRNA、tmRNA等基因元件。IslandPath-DIOMB(v0.2.0)预测基因岛:6个基因为单位滑动窗口计算二核苷酸偏差评分,以全基因组偏差得分中位数加2倍标准差(x̄+2s)为阈值;候选区域需含至少8个连续带偏差基因且至少1个移动相关基因。
1.8 基因功能注释
COG数据库进行直系同源分类;GO数据库分析生物过程、细胞组分和分子功能;KEGG数据库进行代谢通路分类;CAZy数据库获得碳水化合物活性酶注释信息。
1.9 抗生素耐药基因和毒力基因分析
使用PHI、VFDB、CARD数据库,经Diamond比对,结合基因和功能注释信息获得注释结果。
2 结果
2.1 细菌分离及鉴定
病鸭剖检见典型心包炎和肝周炎,心脏与肝表面覆纤维素性渗出膜,气囊浑浊,组织黏连,肠道点状出血。TSA培养形成圆形灰白不透明、边缘光滑整齐小菌落。革兰染色为阴性短杆菌,多单个丝状排列。16S rRNA序列与参考株JW-1(CP176754.1)聚于同一分支,确认分离株为鸭疫里默氏杆菌,命名为SDRA05(图1)。
2.2 血清型鉴定
玻片凝集试验显示,SDRA05仅与6型RA阳性血清发生明显凝集,与1、2、4、5、7、10型血清均无反应,确定为血清6型。
2.3 菌株感染对雏鸭的致病性分析
感染雏鸭出现精神不振、进食减少、羽毛松乱,个别卧地不能站立、腹泻、头颈抽动、眼角分泌物增多。高剂量组(10⁹ CFU·只⁻¹)接种后约12 h开始死亡。10⁹、10⁸、10⁷ CFU组死亡率100%;10⁶ CFU组60%;10⁵ CFU组20%;对照组全部存活。LD₅₀为2.15×10⁵ CFU·只⁻¹。死亡雏鸭心脏和肝脏组织中均再次分离出相同菌株,鉴定结果与初次一致(图2)。
2.4 菌株的药敏性分析
对12种抗生素中3种耐药(四环素、卡那霉素、链霉素),总耐药率25%;对其余9种敏感,无中介。对β-内酰胺类、氟喹诺酮类、酰胺醇类、多肽类、糖肽类敏感;对四环素类及氨基糖苷类耐药,具一定多重耐药特征(表1)。
2.5 SDRA05菌株的基因组组装特征与基因岛功能解析
基因组Scaffold(GCA_051016525.1)共71条>500 bp组装序列,总规模2 215 600 bp(2.21 Mb),最长序列469 306 bp,N50为195 382 bp,G+C含量35%。Prokka注释识别2 047个编码基因,累计编码区长度1 992 234 bp,占基因组89.92%。 预测到7个基因岛(GI1-GI7),长度7 076~58 414 bp(图3、4)。
2.6 菌株基因功能注释与预测
2.6.1 COG分析
功能未知(S类)基因最多404个;细胞壁/膜/包膜生物合成(M类)186个;翻译核糖体结构与生物合成(J类)153个;复制与修复(L类)132个;氨基酸代谢(E类)118个;碳水化合物代谢(G类)113个;防御机制(V类)30个(图5)。
2.6.2 KEGG分析
基因主要富集于氨基酸代谢(174个)、碳水化合物代谢(147个)、辅酶与维生素代谢(108个)、能量代谢(108个)等核心代谢通路;膜转运与信号转导等环境信息处理通路基因较多;遗传信息处理涵盖翻译(79个)、DNA复制与修复(72个)等(图6)。
2.6.3 GO分析
功能基因广泛参与分子功能、细胞组分及生物过程。代谢过程、细胞过程和蛋白代谢等生物过程基因丰富;催化活性和结合活性等分子功能基因较多;细胞质、蛋白复合物等细胞组分注释频繁(图7)。
2.6.4 CAZY分析
基因主要集中在糖基转移酶(GT,185个)和糖苷水解酶(GH,79个);辅助活性酶(AA,53个)、多糖裂解酶(PL,51个)、羧酸酯酶(CE,36个)、碳水化合物结合模块(CBM,31个)较少;S层同源结构域(SLH)仅1个。未检测到显著多糖裂解酶和氧化还原酶活性,碳水化合物代谢酶系以合成和水解功能为主(图8)。
2.7 菌株毒力基因分析
VFDB比对鉴定出多类毒力相关基因,分9类:黏附(
pilD、cofB、tuf
)、生物膜形成(
algE)、效应物分泌系统(iglH、sidG、toxB
,含II型yst1G/gspF、IV型
dotA
、VI型tssH/clpV1)、胞外酶(
zmpB、cylE
)、免疫调节(
vlh、neuC1、bpsE,aftB
编码阿拉伯呋喃糖转移酶)、运动能力(
flgK、motB
)、营养代谢因子(
bioC、basB
)等。检测到调控因子letS与膜蛋白ompA。 PHI数据库分析: 33个基因突变后致病能力下降(如
ClpA、RelA、MacB
); 8个基因突变后致病能力完全丧失(如
Lon、Gua1、Molrg1、EptA
),为潜在核心毒力因子; 另检出高毒力、致死性、耐药及敏感性相关基因数个,涉及荚膜合成、转运、DNA修复等(表2、图9)。
2.8 细菌抗生素耐药基因注释
CARD数据库检出3类耐药机制、4个耐药基因:
RanA、RanB
(抗生素外排)→氨基糖苷类(卡那霉素、链霉素);
erm
(F) (靶点修饰)→大环内酯类、林可酰胺、链丝菌;
tet
(X) (抗生素失活)→甘氨酰环素类与四环素类。 4种基因中3种与表型一致: RanA/RanB与卡那霉素、链霉素耐药一致;
tet
(X)与四环素耐药一致(表3)。
3 讨论
6型RA的流行与致病性 :国内RA血清型1、2、4、5常见,6、10型呈上升趋势,但对6型研究有限。SDRA05引发雏鸭神经症状、心包炎及肝周炎,与高毒力1型感染高度一致。LD₅₀为2.15×10⁵ CFU,低于5型RAf950(6.6×10⁵ CFU)和2型FJZZ2201(1.5×10⁷ CFU),提示6型SDRA05可能具备更高致病潜能。
毒力因子与基因岛 :SDRA05携带II型、IV型、VI型分泌系统关键结构蛋白,与病原菌入侵、毒素释放及免疫逃逸密切相关。免疫调节基因aftB可能调控宿主免疫识别;黏附基因fimU与非核糖体肽合成酶基因sypB提示其具备定植能力和组织损伤潜力。7个基因岛功能密集,GI6集中分布
ampC、ruvABC、nrdAB
等耐药及DNA修复基因,为抗药性基因携带热点;GI7富含转座酶与可移动元件,推测为水平转移获得区域。
耐药机制 :SDRA05对四环素、卡那霉素、链霉素耐药,耐药率25%。检出RanA/RanB(ABC类外排泵,增强氨基糖苷类耐药)、
erm
(F)(靶位修饰)、
tet
(X)(四环素失活)。
研究意义 :系统解析了6型RA在毒力、耐药及基因岛结构方面的分子特征,丰富了RA致病谱系研究。SDRA05在致病力、基因岛组成及多重耐药方面均呈现独特特征,提示其具有潜在流行风险与跨宿主传播能力。毒力因子表达水平与致病机制仍需转录组或突变体验证。
4 结论
1)成功分离鉴定6型鸭疫里默氏杆菌菌株SDRA05,具有高致病性(LD₅₀ 2.15×10⁵ CFU),能引起雏鸭明显临床症状和病理改变;2) 该菌株对四环素、卡那霉素和链霉素耐药,耐药率25%,携带
RanA、RanB、erm
(F)和
tet
(X)等多个抗生素耐药基因;3) 基因组大小2 215 600 bp,编码2 047个蛋白,含有7个基因岛,富含与毒力、耐药和环境适应相关的功能基因;4) 毒力基因涵盖多类分泌系统、黏附因子、免疫调节因子及毒素合成酶,部分富集于基因岛区域;5) 研究为深入解析鸭疫里默氏杆菌的致病机制及耐药演化提供了重要的理论支持和数据依据。
关键词:
鸭疫里默氏杆菌 ; 全基因组测序 ; 抗生素耐药基因 ; 致病性 ; 血清分型
引用本文
李晨阳, 吕莹, 惠宇韬, 杨敏. 鸭疫里默氏杆菌6型SDRA05株的致病性和耐药性及其全基因组分析 [J]. 畜牧兽医学报, 2026, 57(4): 2283-2297 doi:10.11843/j.issn.0366-6964.2026.04.044
LI Chenyang, LÜ Ying, HUI Yutao, YANG Min. Pathogenicity and Antimicrobial Resistance of
Riemerella anatipestifer
Serotype 6 Strain SDRA05 and Its Whole Genome-based Analysis [J].
Acta Veterinaria et Zootechnica Sinica
, 2026, 57(4): 2283-2297 doi:10.11843/j.issn.0366-6964.2026.04.044
往期回顾
《畜牧兽医学报》2026年第5期目次
《畜牧兽医学报》2026年第4期目次
《畜牧兽医学报》2026年第3期目次
《畜牧兽医学报》2026年第2期目次
《畜牧兽医学报》2026年第1期目次
《畜牧兽医学报》2025年第12期目次
《畜牧兽医学报》2025年第11期目次
《畜牧兽医学报》2025年第10期目次
识别系统主页:
https://www.xmsyxb.com/CN/0366-6964/home.shtml
识别投稿系统:
https://www.xmsyxb.com/JournalX_xmsy/authorLogOn.action
文案:畜牧兽医学报编辑部
校对:程金华
审核:孟 培
2026-05-29
·天蓝杂谈
2026年教育部1号文件新增“科技前沿动态和人文教育元素”表述,明确高考命题将进一步向生物科技前沿倾斜,这既是选拔创新拔尖人才的核心要求,也是生物学科核心素养考查的重要方向。纵观近年高考生物试题,社会热点、科技突破、重大科研成果已成为高频命题情境,且考查比重逐年提升。
本文聚焦2025—2026年全球及我国生物学领域重大事件,涵盖诺贝尔奖、航天生物、基因科技、生命医学、生态演化等核心热点,精准对接高中生物教材考点,为2026届高三师生提供完整备考素材,助力高效备考。
一、2025年诺贝尔生理学或医学奖:外周免疫耐受与调节性T细胞的发现
热点核心内容
2025年诺贝尔生理学或医学奖授予玛丽·卜伦科、弗雷德·拉姆斯戴尔和坂口志文三位科学家,以表彰他们发现外周免疫耐受现象,并成功鉴定调节性T细胞(Treg)。
1. 核心概念区分-中枢免疫耐受:发生于胸腺和骨髓,通过阳性、阴性选择清除自身反应性T/B细胞,避免免疫系统攻击自身组织。
外周免疫耐受:机体在淋巴结、脾脏等外周组织中,通过T细胞失能、克隆清除、调节性T细胞抑制等机制,维持自身免疫稳态,防止自身免疫病、过敏反应发生。
2. 关键研究突破
坂口志文通过小鼠胸腺切除实验发现,切除胸腺的小鼠T细胞数量异常增多,且出现严重自身免疫反应;进一步实验证实,CD4⁺CD25⁺调节性T细胞可抑制失控的自身攻击性T细胞。后续研究确定,Foxp3基因是调节性T细胞的核心分子标记,该基因突变会引发IPEX等严重自身免疫病,直接印证了外周免疫耐受的关键作用。
高考考点对接
免疫调节、T细胞的种类与功能、自身免疫病、基因对性状的控制、实验探究与分析
例题:2025年,诺贝尔生理和医学奖授予了发现调节性T细胞(Treg细胞)及其作用的三位科学家。Treg细胞是一类具有显著免疫抑制作用的T细胞亚群。Treg抑制T细胞的调节如图1所示(CD39和CD73为细胞表面蛋白)。体液中的乳酸会影响免疫反应,乳酸对这两类细胞的影响如图2所示。已知即使氧供应充足,癌细胞也主要依赖无氧呼吸产生能量。下列说法错误的是( )
A.据图1判断,Treg细胞膜上的CD39、CD73具有水解酶活性
B.据图2判断,无氧呼吸不利于癌细胞实现免疫逃逸
C.腺苷、抑制性细胞因子和颗粒酶B均发挥抑制作用,但机理可能不同
D.类风湿性关节炎患者体内Treg细胞的数量可能少于正常人
【答案】B
二、神舟二十一号航天生物实验:小鼠太空“科考”之旅
热点核心内容
北京时间2025年10月31日,神舟二十一号载人飞船成功发射,首次在轨实施啮齿类哺乳动物空间科学实验,4只经过严苛筛选与训练的近交系小黑鼠随舱出征,成为重要的“动物航天员”。
1.小鼠筛选与训练标准-选材:选用基因高度相似的近交系小黑鼠,雌雄各2只,保证实验数据精准性,减少生理差异干扰。训练:通过转棒式疲劳仪进行体能训练(坚持110秒以上)、二维旋转仪开展抗晕训练、平衡木测试平衡能力,同时筛选抗压能力强、空间适应性好的个体。
2. 实验意义:验证哺乳动物在轨生存能力,为后续太空繁殖、空间生命科学研究奠定基础;探究微重力、太空辐射等极端环境对生物生长、发育、免疫的影响,为人类长期太空生存、星际移民提供科学依据。
高考考点对接
动物生命活动调节、基因与性状、实验设计原则、稳态与环境、太空育种原理
例题:对300多只近交系(至少20多代的全同胞交配)小鼠,经半年的体能训练,旋转后走平衡木挑战,心态测试等考验后,4只小鼠脱颖而出,随神舟二十一号飞船出征太空,陪伴航天员完成相关实验。下列叙述错误的是( C )
A.采用近交系小鼠的优势是其遗传背景均一,实验结果一致性好
B.此次太空实验有望助力理解生物体在太空微重力环境下的变化
C.小鼠训练中交感神经和副交感神经共同调节骨骼肌的收缩和舒张
D.平衡木挑战中,调节小鼠躯体平衡和协调运动的神经中枢是小脑
例题:2025年10月,神舟二十一号载人飞船成功发射,首次在轨实施国内啮齿类哺乳动物空间科学实验。经过层层选拔的4只小黑鼠随飞船进入中国空间站,开展在轨饲养与实验,重点研究失重、辐射、密闭等空间条件对小鼠行为模式的影响;之后,随神舟二十号乘组返回地面,进一步开展科学研究,探索“太空鼠”多组织器官在空间环境的应激响应和适应性变化规律。回答下列问题。
(1)为保证实验结果的可靠性,本次任务选用近交系小黑鼠而非普通小白鼠,主要原因是近交系小鼠的___________高度一致,能最大程度减少个体差异对实验结果的干扰。这体现了对照实验设计中的___________原则。
(2)若科研团队欲利用返回地面后的小鼠体细胞进行克隆,以扩大优质“太空鼠”品系,可采用___________技术,该技术的核心步骤是将体细胞核移入___________中。
(3)若空间辐射诱导了小鼠某个关键应激响应基因(如原癌基因 Fos)发生了突变,研究人员可将突变基因 Fos导入大肠杆菌的质粒中保存。该质粒含有氨苄青霉素抗性基因 基因Fos 两端和质粒中的酶切位点如下图所示。
限制酶
限制酶识别序列及切割位点
HindⅢ
5'-A ↓A G C T T-3'
Sma I
5'-C C C ↓GGG-3'
Xba I
5'-T↓ C T A G A-3'
①为避免突变基因 Fos与质粒反向连接,构建基因表达载体时应该使用的限制酶是___________,可使用的DNA 连接酶有___________。
②将重组质粒导入大肠杆菌时,研究人员先用Ca2+处理大肠杆菌的目的是___________。
③为筛选出成功导入了突变基因 Fos的大肠杆菌,配制培养基时除了满足微生物所需的营养条件外,还需要添加的成分是___________,原理是___________。
(4)本次实验标志着我国在空间生物技术领域取得了从“0”到“1”的突破。未来基于此类实验构建的空间生物学平台,可进一步用于研究___________等人类疾病(答出1点即可)。
【答案】(1) 遗传背景 单一变量
(2)体细胞核移植 去核的卵母细胞
(3) HindⅢ和XbaⅠ E.coliDNA连接酶或T4DNA连接酶 使细胞处于一种能吸收周围环境中DNA分子的生理状态,有利于重组质粒导入受体细胞 氨苄青霉素 质粒含有氨苄青霉素抗性基因(AmpR),成功导入了突变基因Fos的大肠杆菌能在选择培养基中生长
(4)骨质疏松(或“肌肉萎缩”“免疫失调”“神经退行性疾病”)
三、我国空间站新物种发现:天宫尼尔菌
热点核心内容
科研人员首次在我国空间站发现微生物新物种,命名为天宫尼尔菌(Nialliatiangongensis),相关成果发表于国际权威期刊《InternationalJournalofSystematicandEvolutionaryMicrobiology》。
1. 发现过程
依托中国空间站居留舱微生物监测项目(CHAMP),神舟十五号乘组在轨完成舱内微生物采样,经地面形态观察、基因组测序、系统发育分析等多手段验证,确认该菌株为全新物种。
2. 物种特性
该菌为革兰氏阳性产芽孢细菌,具备极强的空间环境适应能力:可通过调控杆菌硫醇合成应对氧化应激,在生物被膜形成、辐射损伤修复方面表现优异,能适应空间站微重力、高辐射、密闭寡营养的极端环境。
3. 科研价值
为空间微生物安全控制、航天环境治理提供理论支撑,同时为微生物资源开发、极端环境生命演化研究提供全新方向。
高考考点对接
微生物的结构与代谢、生物对环境的适应、基因突变与自然选择、微生物培养与鉴定
例题:科研人员在研究太空微生物时发现,天宫尼尔菌(一种原核生物)具有极强的环境适应能力。该菌能在模拟太空的高辐射、寡营养(营养物质极度匮乏)环境中长期存活,并能通过特殊的代谢途径利用环境中微量的有机物合成自身所需的全部物质。下列关于天宫尼尔菌的叙述,错误的是( D )
A.根据其代谢特点,可推测该菌的同化作用类型为异养型
B.在寡营养环境中,该菌种群数量增长可能呈现"S"形曲线特征
C.其耐高辐射等特殊适应性状的形成是长期自然选择的结果
D.由于缺乏线粒体等复杂细胞器,该菌无法进行有氧呼吸,只能依赖无氧呼吸供能
例题:我国科研人员首次公布在空间站发现的一个微生物新物种,并将其命名为“天宫尼尔菌”。该菌是一类革兰氏阳性细菌,革兰氏阳性菌对青霉素更敏感。下列有关叙述错误的是( )
A.该菌可通过细胞分裂进行增殖
B.培养基中可添加青霉素筛选出“天宫尼尔菌”
C.利用基因工程改造“天宫尼尔菌”时,可以用特定的限制酶切割其拟核DNA
D.若采用稀释涂布平板法计数时,需设置空白对照以检测培养基灭菌是否合格
【答案】B
四、Science2025十大科学突破:中国生物科技成果领跑
2025年Science发布的全球十大科学突破中,我国生物科技成果占据半壁江山,多项研究填补全球领域空白,成为高考命题重点素材。
1. 龙人头骨古DNA研究
我国团队联合国际科研力量,首次从龙人头骨牙结石中获取古老型人类古DNA,从遗传学角度证实龙人属于丹尼索瓦人,破解古人类演化谜题,为中更新世人类遗传学研究开辟新路径。
考点对接:生物进化、DNA的作用、古生物研究方法
例题:科学家从黑龙江龙人化石中成功提取了线粒体古DNA,并测得龙人线粒体DNA与丹尼索瓦人、现代人、黑猩猩的差异位点数,如下表。同时发现,龙人生活在末次冰期的东北亚草原,与猛犸象、披毛犀等动物共存,其化石中检测到与寒冷适应相关的FADS2基因变异。下列有关叙述正确的是( )
A.数据表明,龙人与现代人的亲缘关系比黑猩猩与现代人的亲缘关系更远
B.龙人与同时期生活在西伯利亚的丹尼索瓦人种群之间存在地理隔离,由线粒体DNA差异可推断两者之间已存在生殖隔离
C.寒冷环境导致龙人种群中出现适应寒冷环境的FADS2基因变异,并使基因频率发生定向改变
D.龙人与猛犸象、披毛犀等动物生活在同一区域,它们之间可能通过相互选择实现了协同进化
【答案】D
例题:在对北京出土的田园洞人化石进行研究时,某团队开发出了高效的古DNA捕获技术,从大量来自土壤细菌的DNA中吸附、富集并获取仅占0.03%的人类DNA,再利用PCR进行扩增,测序获得数据分析。下列相关叙述错误的是( B )
A.化石是研究生物进化最直接、最重要的证据
B.通过古DNA捕获技术获得的少量DNA通常直接作为测序的材料
C.古DNA研究为人类的进化提供了有力的证据
D.DNA中的基因突变和自然选择是导致不同种群遗传差异的重要因素
2. 异种器官移植重大突破
我国科学家通过6处基因修饰猪肾脏移植,实现移植器官长期存活,与美国69处基因修饰技术达成同等效果,大幅推动异种移植临床转化,破解人类器官移植短缺难题。
考点对接:基因工程、免疫排斥、器官移植、基因编辑技术
例题:异种器官移植被认为是未来解决器官短缺问题最有效的途径之一。2022年10月,我国科学家团队将转基因编辑猪的肝脏、肾脏、心脏、角膜、皮肤和骨骼移植到猴子身上。下图为相关技术路线图,下列分析正确的是( )
A.分离出猪细胞,在细胞培养过程中通入CO2的目的是为细胞生长提供C源
B.核移植时需用到去核的卵母细胞,并用物理或化学方法激活重构胚
C.基因修饰克隆猪胚胎移植前,要对受体进行免疫检查,以防止发生免疫排斥反应
D.猴子免疫系统识别异体器官为“非己”成分而攻击,体现其免疫监视的基本功能
【答案】B
例题:2025年,科研团队为了培育适用于异种器官移植的基因编辑猪,利用碱基编辑器(利用碱基互补配对原理,在特定位点操作可对单个碱基进行编辑)对猪的基因组进行精准修饰,敲除了猪内源性逆转录病毒基因(PERV),避免患者受PERV感染,敲除了GGTA1、βGALNT2、CMAH等基因,以减少抗原暴露,降低免疫排斥风险。同时插入CD46、CD55、TBM等基因,以增强人源基因表达、提升异种移植相容性。其中敲除PERV及插入CD46基因的操作流程如图所示。下列叙述正确的是( )
A.设计sgRNA时需与PERV基因和CD46基因的序列互补,以实现精准编辑
B.碱基编辑器的作用是切断猪基因组DNA双链,为CD46基因插入提供位点
C.替换图中sgRNA序列,即可用碱基编辑器进一步敲除GGTA1等基因
D.该基因编辑猪的器官移植到人体后,PERV引发的免疫排斥将完全消除
【答案】C
3. 耐高温水稻育种突破
华中农业大学团队发现水稻QT12主效基因,构建天然基因开关系统,提升水稻高温耐受性,使高温环境下优质水稻产量提升1.31-1.93倍,为抗逆育种提供全新策略。
考点对接:基因表达调控、育种原理、植物激素调节、生态与农业生产
例题:全球气温升高会使水稻减产,通过诱变育种可以获得耐高温水稻,为研究其遗传规律,研究人员做了如下实验:
(1)将基因型为aa的耐高温隐性突变体水稻甲与染色体缺失一个A基因的不耐高温的野生型(WT')水稻杂交得F₁,已知不含控制该性状的基因的受精卵不能发育,若将上述F₁进行随机杂交,F₂中耐高温水稻出现的概率是____________。
(2)有另一种耐高温隐性突变体乙,突变位点和甲不同。请设计实验探究控制突变体甲、乙的突变基因的位置关系。(不考虑互换)_______杂交,得F₁,观察F₁的表型。实验方案:选择预期实验结果:
I.若F₁表现为__________,说明两突变基因为等位基因。
Ⅱ.若F₁表现为_______,说明两突变基因为非等位基因。
若F₁表型为结果Ⅱ,请写出进一步的实验方案。
______________
预期实验结果:
①若________,则两突变基因是同源染色体上的非等位基因;
②若______,则两突变基因是非同源染色体上的非等位基因。
(3)研究发现,突变体乙的耐高温基因位于3号染色体上,为进一步确定其位置,研究者进行了系列实验,如下图所示。
采用图1中的育种技术获得F₂纯合重组植株R₁~Rs,对WT、突变体乙和R₁~Rs进行分子标记及耐高温性检测,结果如图2、图3所示。经过分析可知,耐高温突变基因位于_______(填分子标记)之间。从减数分裂的角度分析,推测形成图2中R₁~Rs结果的原因是_______。
(4)基因OsWR2的表达能促进水稻表皮蜡质的合成。为了验证“高温胁迫下维持较高的蜡质含量是水稻耐高温的必要条件”,研究小组以_______突变体甲为对照组,实验组为_______,将两种水稻置于________,一段时间后,检测水稻蜡质含量及耐高温性。预期实验结果:_______。
答案.(1)8/15
(2) 甲、乙两种突变体 耐高温 不耐高温 F1自交得F2,统计F2的表型及比例 不耐高温∶耐高温=1∶1 不耐高温∶耐高温=9∶7
(3) caps4和caps5 F1在减数分裂过程中,两条3号染色体因存在不同部位的染色体互换而产生多种重组类型
(4) OsWR2 基因OsWR2敲除的突变体甲 高温环境 实验组水稻植株蜡质含量低于对照组,且不耐高温
五、2025年中国生命科学十大进展:本土科研巅峰成果
1. 衰老干预新机制
构建人体器官衰老“蛋白标尺”,揭示甜菜碱可减缓多器官衰老,研发长寿基因增强工程化抗衰祖细胞,建立衰老多层次干预体系。
考点对接:细胞衰老、基因表达、蛋白质功能、干细胞应用
例题:TBK1是一种天然免疫激酶,随着年龄增长它会被异常激活驱动细胞衰老。我国研究团队发现,甜菜碱能通过靶向抑制TBK1活性缓解细胞衰老。下列有关叙述不合理的是( )
A.细胞衰老后,细胞内TBK1的活性会出现明显增高
B.甜菜碱处理衰老细胞,其自由基的数量可能会下降
C.甜菜碱处理衰老细胞,其代谢速率会高于正常细胞
D.敲除细胞中的TBK1基因,细胞的衰老速度会减缓
【答案】C
2. 肠道菌源代谢物新发现
依托AI技术挖掘新型肠道菌代谢物,发现代谢性疾病全新靶点,为糖尿病、肥胖等代谢病治疗提供新策略。
考点对接:微生物与稳态、物质代谢、基因工程、AI与生物研究
例题:“肠微生物—肠—脑轴”(MGBA)是哺乳动物脑与肠道间的双向调节网络系统。5-HT是一种神经递质,由色氨酸经一系列反应生成,在神经系统的信息传递和情绪调节中发挥关键作用。肠道中微生物的代谢物可刺激迷走神经向脑传递信息,并参与5-HT分泌的调节。下图表示肠道菌群紊乱引发抑郁的部分机制,请回答下列问题:
(1)机体可通过“___________轴”调节GC的分泌。GC分泌量升高会抑制TPH1的活性从而影响5-HT的合成,使得GC的分泌量________(填“上升”或“下降”),这种调节方式属于___反馈调节。
(2)迷走神经是一种混合神经,5-HT可使迷走神经兴奋并促进胃肠蠕动,由此推测迷走神经中包含___________(填“交感神经”或“副交感神经”)。研究发现,对肠道移植益生菌后,肠道内色氨酸的含量上升,并且抑郁症状明显改善。当研究人员切断迷走神经后,益生菌对抑郁症状的改善作用显著减弱,其原因是_________,继续研究发现,益生菌对抑郁症状的改善作用未完全消失。请对该研究结果进行解释:益生菌还可以提升肠道内色氨酸含量来增加___________的含量,通过__________到达脑,进而增加5-HT的分泌量,从而改善抑郁症状。
(3)研究表明,抑郁症患者肠道中普雷沃菌的数量显著减少,该菌能代谢膳食纤维产生短链脂肪酸(SCFAs)。欲验证肠道中的SCFAs可通过影响5-HT的分泌来改善抑郁症状,请选择合适的材料及试剂完成如下实验设计。
实验材料及试剂:健康小鼠若干只,抑郁模型小鼠若干只,适宜浓度的SCFAs补充剂,生理盐水。
动物
处理方式
对照组1
健康小鼠
适量的生理盐水灌胃
对照组2
__________(填字母)
A.健康小鼠 B.抑郁模型小鼠
___________
实验组
抑郁模型小鼠
_________
答案:(1)下丘脑—垂体—肾上腺皮质 上升 正
(2)副交感神经
益生菌的代谢物可以通过刺激迷走神经向脑传递信息使5-HT分泌量上升来改善抑郁症状,切断迷走神经后,5-HT分泌量下降 5-HTP/5-羟色胺前体 血液循环
(3)B 等量的生理盐水灌胃 等量的适宜浓度的SCFAs补充剂灌胃
3. 鼻咽癌免疫治疗新方案
创立PD-1单抗辅助免疫治疗策略,实现鼻咽癌治疗“增效减毒”,大幅提升患者生存率,降低放化疗副作用。
考点对接:免疫调节、癌症治疗、细胞癌变、实验临床研究
例题:鼻咽癌免疫治疗“增效减毒”的新策略中,放疗后使用PD-1单抗辅助免疫治疗是关键环节。PD-1是活化的T细胞表面的抑制性受体,肿瘤细胞表面的PD-L1可与PD-1结合并抑制T细胞功能,帮助肿瘤免疫逃逸;PD-1单抗可特异性结合PD-1,阻断这一作用。下列叙述正确的是( )
A.PD-1单抗裂解肿瘤细胞是体液免疫发挥作用的主要方式
B.PD-1单抗阻断PD-1与PD-L1结合,促进T细胞的活化
C.PD-1单抗可激活B细胞分化,产生大量抗体清除肿瘤细胞
D.PD-1单抗作为抗原可刺激机体产生长期抗肿瘤的记忆细胞
【答案】B
4. 蝗虫群聚信息素调控
完整解析飞蝗群聚信息素4VA生物合成途径,开发特异性抑制剂,实现蝗虫行为精准调控,开创害虫绿色防控新路径。
考点对接:生态信息传递、酶促反应、基因表达、生物防治
例题:东亚飞蝗是一种农业害虫,因其聚集、迁飞、暴食等特征给农业生产带来严重的危害。研究发现,群居蝗虫释放的信息素4VA能使蝗虫聚集,部分机制如图所示,下列叙述正确的是( D )
A.4VA通过参与代谢触发聚集,并调控警戒色的基因表达
B.4VA通过调节种间竞争,维持自身种群数量的相对稳定
C.种群密度升高促使4VA释放以降低被捕食率,属于负反馈调节
D.以生物信息流为靶点调控群聚行为,为害虫防控提供了新思路
5. 卡路里限制延寿机制
发现石胆酸是卡路里限制延寿的核心效应分子,揭示其通过激活AMPK通路实现抗衰老的分子机制。
考点对接:物质代谢、细胞信号通路、基因表达、稳态调节
例题:热量限制(CR)是一种适度减少食物摄入但不造成营养不良的饮食方式,能够有效延缓多种生物的衰老进程。中国科学家研究发现给常态饱食的小鼠、线虫、果蝇等多种动物投食石胆酸也能模拟出CR的效应,并且发现该效应与一条以溶酶体为核心的信号通路密切相关。下列叙述中,不合理的是( )
A.CR可以促进体内脂肪大量转化为葡萄糖
B.石胆酸在不减少食物摄入的情况下就能模拟出CR的效应
C.衰老细胞的体积变小,核膜内折,染色质收缩、染色加深
D.CR产生的效应可能与溶酶体能分解衰老、损伤的细胞器有关
【答案】A
6. 脑新生神经元治疗脑卒中
研发“脑修复凝胶”,激活内源性神经干细胞,实现脑卒中后神经再生,完成从“被动保护”到“主动再生”的治疗突破。
考点对接:细胞分化、干细胞、神经调节、组织修复
例题:我国科学家研发的“脑修复凝胶”可激活患者脑内的内源性神经干细胞,使其分化为成熟神经元,并建立功能连接,帮助脑卒中患者恢复运动功能。下列相关叙述错误的是( )
A.激活的内源性神经干细胞可发生定向分化,体现了干细胞的分化潜能
B.与传统的药物保护相比,“主动再生”策略更侧重于重建神经通路结构
C.该研究表明成年哺乳动物中枢神经系统仍保留一定程度的可塑性
D.神经元死亡后,可通过残存神经元的分裂增殖实现受损区域的修复
【答案】D
例题:中国科学家研发的全球首个AI蛋白质生成大模型NewOrigin(中文名“达尔文”)正式在世界人工智能大会亮相。它能通过AI学习蛋白质中氨基酸序列和蛋白质功能间的对应关系来设计新的蛋白质,为蛋白质工程的发展提供了新方向,在生物医药领域也有较好的应用前景。下列叙述不正确的是( )
A.蛋白质工程需从设计预期的蛋白质功能出发,目前的AI可帮助人们设计出自然界没有的蛋白质
B.NewOrigin在蛋白质工程广泛应用后将仍需要借助基因工程手段改造蛋白质,使得产品更优良
C.对蛋白质数据进行分析,能够预测患者体内某些蛋白质的三维结构以便设计新药物,该过程属于蛋白质工程技术
D.AI技术在生物医药领域的应用会涉及到众多的法规和伦理问题。例如,如何处理AI决策中的错误和责任、以及如何避免AI技术加剧医疗不平等等问题
【答案】C
7. 水稻表观遗传逆境适应
证实低温诱导水稻DNA甲基化变异可稳定遗传,为拉马克“获得性遗传”学说提供分子证据,开创抗逆育种新思路。
考点对接:表观遗传、基因突变、生物进化、育种应用
例题:研究人员揭示了水稻耐盐性的表观遗传调控新机制,鉴定到水稻组蛋白H3上一个赖氨酸乙酰化位点,该修饰富集在耐盐基因的转录起始位点附近,进而提高水稻耐盐性。下列叙述不正确的是( B )
注:乙酰化是指在乙酰转移酶催化下,将乙酰基(-COCH3)结合到目标分子
A.该修饰可能使紧密的染色质构象变得松散,便于RNA聚合酶结合
B.赖氨酸的组成元素是C、H、O、N,乙酰化修饰会增加其元素种类
C.若抑制该修饰的形成,水稻耐盐基因的转录效率可能下降,植株耐盐性减弱
D.该修饰是表观遗传调控的重要形式,不改变水稻基因组DNA序列,但可遗传给子代细胞
例题:中国科学院曹晓风团队研究发现,连续多代冷胁迫可诱导水稻ACT1基因位点发生DNA甲基化变异,该变异不改变DNA碱基序列,但可稳定遗传,并在水稻向北扩张适应高纬度低温环境中发挥关键作用。分子机制:多代冷胁迫 → ACT1去甲基化 → 解除转录因子Dof1的抑制 → ACT1基因表达上调 → 耐冷性增强。结合图示信息分析,下列叙述正确的是( )
A.高纬度低温环境直接诱导水稻产生定向的DNA甲基化变异,从而适应低温
B.ACT1基因的甲基化修饰改变了基因的碱基序列,属于可遗传的基因突变
C.多代冷胁迫通过降低ACT1基因的甲基化水平,解除转录因子Dof1对ACT1的抑制作用,使ACT1表达量升高,增强耐冷性
D.若将耐冷水稻移栽至温暖环境种植,ACT1基因的甲基化状态会立即恢复至高甲基化水平
【答案】C
例题:2023年9月11日,华中农业大学水稻团队系统解析了水稻DELLA蛋白抑制基因表达以及赤霉素快速激活基因转录的染色质修饰,揭示了水稻赤霉素信号传递中的调控机制。生长抑制因子DELLA蛋白的稳定性在谷物作物半矮化机制中起重要作用,DELLA蛋白可以抑制赤霉素途径的基因表达从而抑制植物生长。赤霉素通过蛋白酶系统来解除DELLA蛋白的抑制作用,进而促进植物细胞分裂和伸长等过程。
1.根据上述材料,生长抑制因子DELLA蛋白引起谷物作物半矮化的机理是( )
A.基因突变 B.表观遗传 C.染色体畸变 D.环境引起
2.下列关于赤霉素的叙述,错误的是( )
A.赤霉素可促进细胞分裂和伸长
B.赤霉素可解除DELLA蛋白的抑制作用
C.赤霉素可直接参与代谢,促进植物茎秆伸长
D.赤霉素为信号传递分子,植物体内存在相应受体
【答案】B C
8. 近红外视觉隐形眼镜
突破人类视觉极限,研发上转换隐形眼镜,实现裸眼近红外光感知,应用于夜视、色盲治疗等领域。
考点对接:神经调节、视觉形成、生物材料应用
例题:2025年,我国科研团队开发了一种光热门控DNA纳米通道(NC-JNP),它可通过近红外光调控神经元兴奋性,有关机制如图所示。
近红外光照射→JNPs吸收光能转化为热能→局部温度升高→NCs开放→离子跨膜运输(主要是Na+)→神经元产生兴奋
注:JNPs为金-四氧化三铁Janus纳米颗粒;NCs为DNA纳米通道,在温度大于40℃时开放,在温度小于40℃时关闭。
科研人员选用基因敲除小鼠(一种先天性痛觉不敏感模型,与痛觉形成有关的感觉神经末梢异常)进行实验,A组将NC-JNP注射到小鼠足底,B组注射等量生理盐水,然后用近红外光照射,A组小鼠立刻出现了抬脚、舔脚等疼痛行为,B组无此现象,实验结果表明NC-JNP可以恢复模型小鼠对疼痛的感知能力。回答下列问题:
(1)NC-JNP对神经元兴奋性的调控方式与通常情况下兴奋在神经元间传递的方式相比,两者的主要区别是_______。
(2)实验中NC-JNP恢复A组模型小鼠痛觉的过程______(填“属于”或“不属于”)反射,理由是________。
(3)实验中设置B组的目的是________。根据NC-JNP的作用推测,A组在近红外光照射后神经元膜电位的变化为__________,其原因是________。
(4)已知药物利多卡因可以特异性地阻碍神经元上Na+通道的开放。若欲进一步探究NC-JNP是否依赖神经元上Na+通道发挥作用,请在原实验的基础上另外设计一组补充实验,设计思路是:________。
【答案】(1)NC-JNP通过物理信号(光热)调控离子通道开放,无须神经递质参与;通常情况下兴奋传递依赖神经递质与受体结合(化学信号)
(2)不属于 恢复痛觉的过程未经过完整反射弧
(3)作为对照,排除近红外光本身对神经元兴奋性的影响 由内负外正转变为内正外负(或由静息电位转变为动作电位,2分) 近红外光触发DNA纳米通道开放,Na+内流,导致膜电位改变
(4)增设C组,将药物利多卡因注射到模型小鼠足底,其他处理与A组相同,比较A、C两组小鼠的反应
9. AI驱动染色体精准编辑
建立AI蛋白质工程方法,实现染色体级别大尺度DNA精准编辑,为精准育种、遗传病治疗提供核心技术。
考点对接:基因编辑、蛋白质工程、染色体变异、基因工程
例题:“逆折叠AI模型”依据自然界中已知的大量“序列-结构”对应关系,学习到氨基酸序列与最终三维结构之间复杂的对应关系,使该模型能从目标蛋白质的结构出发,快速生成大量可能折叠成该结构的氨基酸序列,实现了蛋白质工程的自动化和标准化。下列说法正确的是( C )
A.生成目标氨基酸序列需要肽键的结构、氨基酸的性质与数目为依据
B.从蛋白质的三维结构到氨基酸序列,AI模型依据的原理是中心法则
C.氨基酸发生替换后,蛋白质的空间结构和功能可能不会因此而发生改变
D.该模型预测蛋白质的结构并直接设计改造蛋白质,而不用改造基因
10. 深渊动物演化机制
解码深海极端环境动物适应遗传机制,揭示深海生物趋同突变、共生适应的生存策略,拓展生物多样性研究边界。
考点对接:生物进化、共生关系、基因与环境、生物多样性
例题:研究发现,不同亲缘关系的深海鱼类进入深渊海沟后,在分子层面均通过RTF1基因发生相似突变以适应极端环境。端足类动物则通过“宿主—微生物”共生体系来弥补能量的不足。下列叙述正确的是( C )
A.该现象说明RTF1基因可以发生相似的定向突变
B.“宿主—微生物”共生体的形成不属于协同进化
C.深海鱼类发生相似的突变是定向的自然选择的结果
D.深海生物形成适应特征的过程中种群基因频率不会发生改变
六、全球首例定制基因组编辑疗法:治愈罕见遗传病
热点核心内容
美国科研团队利用定制CRISPR碱基编辑技术,成功治愈一名患有遗传性高血氨病(CPS1缺乏症)的儿童,实现基因治疗历史性突破。
1. 致病原理:CPS1基因是尿素循环限速酶编码基因,该基因突变导致氨无法正常代谢,在体内大量堆积,损伤大脑、肝脏等器官,属于罕见单基因遗传病。
2. 治疗原理:采用脂质纳米颗粒递送碱基编辑系统,精准纠正肝细胞内突变的CPS1基因,恢复尿素循环功能,无需肝移植即可实现疾病治愈,为全球罕见遗传病治疗开辟新路径。
高考考点对接
基因编辑技术、人类遗传病、基因表达、物质代谢、生物工程应用
例题:科学家通过CRISPR/Cas9基因编辑技术成功治疗罕见的尿素代谢疾病—氨基甲酰磷酸合成酶1缺陷症,实现了为单个病患量身定制基因编辑治疗。利用CRISPR/Cas9复合体进行基因编辑时,复合体首先会定位非模板链目标序列上的PAM序列,如5′-NGG-3′位点(N表示任意一种碱基),然后利用向导RNA(sgRNA),与该位点5′端相连的序列互补配对,若能够互补,Cas9会切割互补序列某位点,可实现基因定向改造,如图所示。回答下列问题:
(1)科学家通过CRISPR/Cas9基因编辑技术实现精准治疗的关键在于设计一条精准识别异常基因的sgRNA,其原理是_______。Cas9催化DNA分子双链上的____化学键断裂。
(2)该系统在寻找靶位点时,可能在非目标位置发生切割,原因是______,因此在设计sgRNA时,sgRNA的长度尽可能______(选填“长”或“短”)。
(3)设计sgRNA需要患者突变的氨基甲酰磷酸合成酶1(CPS1)基因序列,科学家根据正常人体细胞中CPS1基因序列作为参考设计引物,以______为模板进行PCR扩增,得到突变CPS1基因,再以CPS1基因设计分子探针,靶向基因组分析发现,突变CPS1基因模板链第1003位碱基由C变为T,第2140位碱基由G变为T,请从下图分析患者发病的原因______。
(4)十年来,华人科学家张峰及其团队发现的CRISPR/Cas9广泛应用于生物学的各个领域,今年2月,张峰团队又发现了基因编辑新系统——TIGR-Tas系统,其编辑原理为tigRNA引导Tas蛋白到特定切割位点,Tas蛋白在间隔区第5位碱基互补的3′端切割双链DNA。如图所示:
对比CRISPR/Cas9系统,据图分析TIGR-Tas系统的优点_________。
答案4.(1) sgRNA与目标基因发生碱基互补配对 磷酸二酯键
(2) 非目标位置存在与靶位点高度相似的序列(或sgRNA较短,特异性低) 长
(3) 患者DNA 突变CPS1基因发生碱基对的替换,使转录出的mRNA上终止密码提前出现,翻译提前终止导致肽链变短,CPS1活性降低或丧失
(4)tigRNA配对目标DNA的两条链,特异性更强;(TIGR-Tas系统不依赖PAM序列,可应用范围更广;TIGR-Tas系统能在目标DNA的特定位点切割,编辑更精准)
七、哈佛大学新发现:人类生育性别并非完全随机
热点核心内容
哈佛大学团队通过近60年、超5.8万女性生育数据研究,证实婴儿出生性别受母亲年龄、特定基因共同调控,颠覆“生男生女完全随机”的传统认知。
核心结论-多孩家庭存在“同性扎堆”现象:已生育男孩/女孩的女性,后续生育同性孩子概率显著提升;母亲初次生育年龄越大,“同性扎堆”趋势越明显;人类10号、18号染色体存在特定基因,分别调控女性生育女孩、男孩的倾向。
高考考点对接
伴性遗传、基因对性状的控制、环境与基因的互作、遗传概率分析
【其他题目】
1.程序性死亡受体1(PD-1)最早发现于凋亡的小鼠T细胞表面。目前研究发现,活化的T细胞表面的PD-1与正常细胞表面的程序性死亡配体1(PD-L1)一旦结合,T细胞即可“认清”对方,不触发免疫反应。多种肿瘤细胞可通过过量表达PD-L1来逃避免疫系统的“追杀”。下列相关叙述错误的是( )
A.细胞凋亡是一种程序性死亡的原因是细胞凋亡受到严格的遗传机制调控
B.正常细胞变为癌细胞的原因可描述为原癌基因和抑癌基因表达稳态的破坏
C.采用杂交瘤技术获得的单克隆PD-1抗体和PD-L1抗体可作为广谱抗癌药物
D.过度阻断PD-1/PD-L1信号通路,可能会引起免疫缺陷病
【答案】D
2.2025年《Cell》公布了一个包含三个层次、共14个标志的人体衰老系统框架(节选如下表),极大地拓展了人们对衰老机制的理解。
类别层次
代表性衰老标志
基本标识
基因组稳定性丧失、端粒损耗、表观遗传学改变…
拮抗型标识
营养感知失调、线粒体功能障碍、细胞衰老
综合性标识
干细胞耗竭、慢性炎症、心理—社会隔离、…
下列叙述错误的是( )
A.细胞氧化反应中产生的自由基会攻击DNA,可能导致基因组稳定性丧失
B.端粒损耗是指随着细胞分裂次数的增加,染色体上的端粒数量会逐渐减少
C.细胞衰老的主要特征包括细胞膜通透性改变,细胞体积变小,细胞核体积增大等
D.线粒体功能发生障碍时,线粒体内膜发生改变,导致线粒体释放的能量大大减少
【答案】B
3.(2026·山东临沂·一模)8. 胆汁酸在肝细胞内以胆固醇为原料经CYP酶作用形成,胆汁酸含量升高会抑制CYP酶的作用。人体内只有5%的胆汁酸排出,95%的胆汁酸通过肠肝循环维持。在肠肝循环中,存在BSEP,NTCP,ABST和OST四种胆汁酸跨膜转运蛋白,转运循环机制如图所示。胆固醇异常积累可导致肝炎,抑制ABST降低肝细胞内胆固醇含量是治疗该病的有效方法。下列说法错误的是( )
A. 肠道、肝细胞和血液中胆汁酸相对含量依次减小
B. 胆汁酸含量升高通过负反馈调节CYP酶的活性
C. 转运蛋白BSEP,NTCP,ABST转运胆汁酸过程中自身构象会发生改变
D. 抑制ABST会导致肝细胞内胆汁酸合成减少
【答案】D
4.(2026·山东枣庄·二模)绝大多数植物依靠卡尔文循环进行CO2固定,然而,这一机制存在两大瓶颈。首先,RuBisCO酶在光合作用时会受到氧气干扰,进行加氧作用,生成乙醇酸的同时,耗费能量,该过程中最多可将25%的固定碳以CO2形式释放回大气,造成碳流失。其次,在合成脂质、植物激素等物质时,所需的乙酰辅酶A供应有限,导致脂质产量长期受限。为突破瓶颈,研究团队导入外源基因,建立人工代谢旁路(如图所示),以提高卡尔文循环的固碳效率。
(1)图中的光系统存在于_______(填结构名称)中,其所含色素进行分离时随层析液在滤纸上扩散速度最慢的条带颜色是_______。光系统所产生的NADPH在卡尔文循环中的作用是_______。
(2)某时刻C5含量突然增加了,这时候可能的外界环境变化是_______(答出2点)。
(3)构建人工代谢旁路后,转基因植物乙酰辅酶A的合成速率会_______(填“加快”或“减慢”),原因是_______。
(4)这项创新的双循环固碳系统在拟南芥中展现了显著成效,相较于野生种,转基因拟南芥植株的干重提升2至3倍。结合图示转基因拟南芥植株的代谢途径,分析导致其干重提升的原因是_______(答出1点)。
【答案】(1) 类囊体薄膜(基粒) 黄绿色 为C3的还原提供还原剂和能量
(2)CO2减少或光照增强
(3) 加快 与野生种相比转基因植物不仅可通过丙酮酸合成乙酰辅酶A,还可通过人工代谢旁路合成乙酰辅酶A
(4)与野生种相比,转基因植株细胞分裂素合成加快,叶片数量增加,光合作用(固碳)效率提升;与野生种相比,转基因植株光合作用蛋白质增加,光合作用(光系统)效率提升; 与野生种相比,转基因植株光呼吸被抑制,光合作用效率提升
5.(2026·山东菏泽·一模)5. 水稻是重要的粮食作物,高温会引起水稻减产。科学家对抗高温能力弱的水稻W进行改良,获得了水稻S。如图显示了高温条件下水稻W和水稻S响应高温的部分机制。其中T1和T2为不同蛋白,T2在液泡中被降解。箭头的粗细代表物质的量。
(1)图中被降解的细胞器为叶绿体。叶绿体内部含有的叶绿素主要吸收________光。
(2)据图分析,水稻S感知高温信号保护叶绿体的机制是:在高温情况下,________。
(3)据图分析,水稻W改良为水稻S时,采取的措施是________(填序号),除此之外,若要进一步提高水稻S的抗高温能力,还可采取的措施是________(填序号)。
①提高T1的量②提高T2的量③降低T1的量
④降低T2的量⑤改变T1的结构⑥改变T2的结构
(4)科研人员以水稻品种N22为材料,设置常温组(CK)和高温处理组(HT),探究高温胁迫对水稻光合作用的影响,实验结果如下表所示。气孔导度表示气孔张开的程度。
组别
净光合速率Pn/(μmol·m-2·s-1)
气孔导度Gs/(mmol·m-2·s-1)
胞间CO2浓度Ci/(μmol·mol-1)
叶绿素含量(mg·g-1)
CK
5.37
0.34
395.32
2.1
HT
1.78
0.12
362.78
0.35
据表分析,HT组水稻净光合速率显著下降的原因是________。HT组气孔导度变化明显,推测这种变化可能与植物激素X有关,X激素最可能是________。若在原实验基础上增设一个实验组验证此猜测,该实验组可设置为________。
【答案】(1)红光和蓝紫
(2)T1从细胞膜转移至细胞内与T2结合,促进T2更多地进入液泡被降解,减少T2蛋白在叶绿体中的积累,进而保护叶绿体免受损伤
(3) ⑤ ①④⑥
(4) 气孔导度下降,CO2吸收量减少;叶绿素含量减少 脱落酸 高温处理+施加适量X激素抑制剂(常温处理+施加适量X激素)
6.脑机接口技术是一种变革性的人机交互技术。它通过捕捉大脑信号并将其转换为电信号,实现信息的传输和控制,从而直接在大脑与外部设备之间建立全新的通信与控制通道。下图是脑机接口的应用之一,用大脑控制机器写字,可为因某些原因不能写字的患者带来福音。请回答下列问题:
(1)通过手术将微电极植入患者大脑皮层,其中微电极的作用是________,图中的电脑相当于反射弧中的___________。微电极采集到的脑部神经信号主要是大脑语言中枢的___________区的神经细胞膜外的电信号,这种细胞膜外电信号会突然由正变负,从物质运输的角度分析,发生这种电位变化的原因是__________________。
(2)人写字的“意念”产生于______________。“意念”产生需要多个神经元参与,不同神经元之间的联系如下图所示。当兴奋传递到甲神经元的末梢时,对电位变化敏感的钙离子通道会大量开放,胞外的钙离子会迅速涌进胞内,造成一个突然的钙高峰,进而导致神经递质乙酰胆碱释放,引起突触后膜电位变化,这个过程体现了神经元细胞膜具有_________的功能。当甲神经元兴奋后,乙、丙神经元的膜电位发生不同变化,原因是____________。
(3)某位参与测试脑机接口的志愿者是重症肌无力患者,其发病原因是机体产生的某种抗体与神经—肌肉接头的受体结合,导致肌肉不能收缩,不能写字,这种抗体是由___________细胞产生的,这位患者所患的疾病属于___________病。
(4)除了上述输出型脑机接口把大脑的意识输出,通过机器呈现外,科学家还在开发输入型脑机接口,即把兴奋输入大脑。请预测并描述一种可能的输入型脑机接口及应用:______________。
【答案】(1) 收集神经元的信号 神经中枢 W Na+(大量)内流
(2) 大脑皮层 控制物质进出细胞和进行细胞间信息交流 甲神经元兴奋后,释放兴奋性神经递质,导致突触后膜乙兴奋,产生动作电位,但当乙兴奋后,其释放抑制性神经递质,抑制了突触后膜丙的兴奋,使丙不能形成动作电位
(3) 浆 自身免疫
(4)作为听觉(或视觉)受损患者的感受器和传入神经纤维
7.人脑和人工智能(AI)系统的决策过程有很多相似之处,也有许多不同。人类依靠大脑进行学习和记忆。AI大模型可通过自监督学习或半监督学习进行海量数据预训练,由于计算量极大,通常部署在云端。随着芯片技术的发展,终端智能设备的算力提升巨大,让AI具有了更为丰富的应用场景。回答下列问题:
(1)AI可以通过麦克风、光感器、激光雷达、键盘等设备获取声音、图像、文字等信息,经过计算机综合分析,将结果通过显示器、音响等外源设备呈现。人脑的某些区域也具有类似的能力,可通过听觉器官对获取文字的信息进行分析综合,该部位位于大脑皮层言语区的 区;进行信息转化并控制相关发声器官进行语言表达的区域是 区。
(2)学习与记忆与大脑皮层的海马区有关。人类女性在中年之后记忆衰退速度快于男性。为研究雌性哺乳动物年龄增长与记忆的关系,利用切除卵巢的GDX雌鼠作为实验组,进行了相关实验,实验结果如下图。据此推测雌性哺乳动物中年之后记忆衰退加快的原因是 。
(3)研究发现,海马区的突触间隙中神经递质5-羟色胺(5-HT)水平降低导致抑郁症发生,通过显著改变5-HT的受体功能可治疗抑郁症。为探究某种新型抗抑郁药物M的药学机制,利用抑郁模型动物进行了相关实验,结果如图。通过进一步实验可知,使用该种药物可引起海马区5-HT受体的数量稍有减少,可能与5-HT受体 (填“合成减少”或“降解增加”)有关。推测药物M抗抑郁的机制为 。
【答案】(1) H S
(2)记忆的形成与海马区突触数量有关,雌激素水平下降,导致海马区面积变小,突触数量减少
(3)降解增加 提高5-HT受体的敏感度
8.(2026·山东日照·一模)20.小鼠持续被更大更强壮的同类攻击后,会出现社交回避和抑郁情绪,即社交挫败应激反应(SDS)。为阐明SDS调控机制,科研人员进行了系列实验。
(1)研究显示,受到社交挫败刺激后,小鼠相关感受器兴奋,其膜内电位变为________电位,引起这一变化的原因是________。该兴奋经传入神经传至中脑VTA区,经有关信号通路,抑制肾上腺皮质分泌活动,最终缓解社交压力。
(2)研究人员检测了小鼠睡眠时间和肾上腺皮质激素水平,结果如图所示。
由图可知,SDS+睡眠剥夺组的肾上腺皮质激素水平下降速度________(“快于”或“慢于”)SDS+睡眠组,由此得出的结论是小鼠睡眠时间的延长会________(“缓解”或“加重”)其社交压力。
(3)研究人员进一步探究了中脑VTA区对下丘脑LH区神经元的调控作用,将生理状态相同的小鼠随机分为三组,甲组注射适量VTA区兴奋性激活剂,乙组注射等量VTA区兴奋性抑制剂,对照组注射等量生理盐水。SDS处理后,测定的下丘脑LH区神经元兴奋性结果为甲组<对照组<乙组。由此说明,中脑VTA区能________(“促进”或“抑制”)下丘脑LH区神经元的兴奋性。
(4)结合上述信息,完善调节SDS的机制图,①~⑥处应填“-”的是________。
【答案】(1)①. 正电位 ②. 内流
(2)①. 慢于 ②. 缓解
(3)抑制 (4)①②③
9.人体细胞因表面有可被巨噬细胞识别的“自体”标志蛋白C,从而免于被吞噬。某些癌细胞表面存在大量的蛋白C,更易逃脱吞噬作用。研究者以蛋白C为靶点,构建了可感应群体密度而裂解的细菌菌株,拟用于制备治疗癌症的“智能炸弹”。
(1)引起群体感应的信号分子A是一种脂质小分子,通常以_______的方式进出细胞。细胞内外的A随细菌密度的增加而增加,A积累至一定浓度时才与胞内受体结合,调控特定基因表达,表现出细菌的群体响应。
(2)研究者将A分子合成酶基因、A受体基因及可使细菌裂解的L蛋白基因同时转入大肠杆菌,制成AL菌株。培养的AL菌密度变化如图1。其中,AL菌密度骤降的原因是:AL菌密度增加引起A积累至临界浓度并与受体结合,_______。
(3)蛋白K能与蛋白C特异性结合并阻断其功能。研究者将K基因转入AL菌,制成ALK菌株,以期用于肿瘤治疗。为验证ALK菌能产生蛋白K,应以_______菌株裂解的上清液为对照进行实验。请从下列选项中选取所需材料与试剂的序号,完善实验组的方案。
实验材料与试剂:①AL5K菌裂解的上清液②带荧光标记的K的抗体③带荧光标记的C的抗体④肿瘤细胞
实验步骤:先加入_______保温后漂洗,再加入_______保温后漂洗,检测荧光强度。
(4)研究者向下图2所示小鼠左侧肿瘤内注射ALK菌后,发现ALK菌只存在于该侧肿瘤内,两周内即观察到双侧肿瘤生长均受到明显抑制。而向肿瘤内单独注射蛋白K或AL菌,对肿瘤无明显抑制作用。请应用免疫学原理解释“智能炸弹”ALK菌能有效抑制对侧肿瘤生长的原因_______。
【答案】(1)自由扩散
(2)启动L蛋白表达引起AL菌短时间内大量裂解
(3) AL ①④ ②/③
(4)注入瘤内的ALK菌群体裂解后释放的蛋白K与蛋白C结合,且释放的细菌产物激活巨噬细胞,从而增强了巨噬细胞对肿瘤细胞的吞噬作用,巨噬细胞加工呈递肿瘤抗原,激活细胞免疫,肿瘤细胞被特异性杀伤,因此有效抑制对侧肿瘤生长。
10.工程化癌症纳米疫苗利用纳米技术封装、运载肿瘤抗原,实现了良好的免疫效果。当纳米颗粒进入人体后,在淋巴结中被呈递给CD8+T细胞,进而促进T细胞的分化和成熟,成熟的免疫细胞再对癌细胞发挥杀伤作用,如图所示。请回答下列问题。
(1)IL-2、IL-6与溶菌酶等物质都属于 。癌症纳米疫苗注射到人体后,被树突状细胞摄取,随后树突状细胞被活化,并对抗原进行 ,抗原作用于CD8+T细胞后,形成细胞乙,即 细胞,再作用于癌细胞。
(2)浆细胞除来源于过程①外,还可来源于 ,过程①中细胞甲的作用是 。
(3)癌症纳米疫苗引起机体产生的免疫类型为 ,机体在免疫活性物质参与下利用免疫细胞杀死癌细胞的过程体现了免疫系统的 功能。
(4)NK细胞对肿瘤细胞的杀伤作用需要借助 来实现,其一方面与肿瘤细胞上的受体结合,同时还与NK细胞上的受体结合,进而刺激NK细胞释放肿瘤坏死因子(TNF),激活其他通路杀死肿瘤细胞或诱导肿瘤细胞 。
(5)相对于普通灭活疫苗,工程化癌症纳米疫苗的优势在于 。
【答案】(1)免疫活性物质 (摄取)加工处理和呈递 细胞毒性T
(2)记忆B细胞 为B细胞的增殖分化提供第二信号并产生细胞因子
(3)体液免疫和细胞免疫(特异性免疫) 免疫监视(监控)
(4)M物质(抗体) 凋亡
(5)更精准地杀伤癌细胞;同时激发较强的体液免疫和细胞免疫等
11.(2026·山东济宁·一模)胰高血糖素样肽-1(GLP-1)类药物治疗糖尿病效果显著,其分泌的部分调节机制如图1所示,肠道L细胞上的FXR被抑制时GLP-1分泌增加。为研究GLP-1治疗糖尿病的机制,研究人员对甲状腺功能减退(甲减)模型小鼠分别给予生理盐水、适量甲状腺激素T3注射4小时(T3-4h)和甲状腺激素T3连续5天注射(T3-5d),再分别腹腔注射葡萄糖,2小时后测定各组血糖及GLP-1水平,结果如图2.回答下列问题。
注:
(1)血糖调节过程中,胰岛素对肝细胞的抑制作用包括____(答出2点),该过程中胰岛素的分泌具有反馈调节的机制,该机制的意义是____。
(2)据实验结果推测,持续5天注射甲状腺激素可能使小鼠疏水性/亲水性胆汁酸比值____(选填“增大”或“减小”)。结合上述结论及图1过程分析,T3-4h组血糖水平未明显降低的原因是____。
(3)为验证甲状腺激素是以GLP-1为媒介调节甲减小鼠血糖水平的,科研人员使用若干甲减模型小鼠、甲状腺激素溶液、葡萄糖溶液、生理盐水、GLP-1受体拮抗剂、注射器等材料实施了实验。
组别
处理一(连续5天注射)
处理二
检测
甲减模型小鼠(甲)
适量生理盐水
②
血糖水平
甲减模型小鼠(乙)
适量甲状腺激素溶液
甲减模型小鼠(丙)
①
表中处理①和②处分别是____、____,预期实验结果为____。
【答案】(1)抑制肝糖原分解,抑制非糖物质转化 维持胰岛素含量的相对稳定
(2) 减小 注射的甲状腺激素不足以显著改变胆汁酸代谢,无法有效抑制FXR活性,不能促进GLP-1的分泌
(3) 适量甲状腺激素+GLP-1受体拮抗剂 腹腔注射等量葡萄糖溶液 甲组与丙组血糖水平接近,且均明显高于乙组
12.湿地碳汇是指湿地生态系统中的植被通过光合作用将二氧化碳转化为有机碳,并在湿地土壤中积累。与陆地森林相比,位于潮间带的红树林湿地由于土壤积水时间长,土壤经常处于厌氧状态,因此具有更大的储碳量和更持久的储碳效果。科学家对某地红树林碳汇模式进行调查,据此归纳出了该地如下所示碳的流动方向图。图中总初级生产力是自养生物生产的有机碳总量,净增量是指碳输入与碳输出的差值。请回答以下问题:
(1)先锋植物是指在群落演替初期最先定居的植物。与陆地森林群落相比,红树林的先锋植物可能具有的特点(至少答两点)。若该红树林朝着生物量增多、结构更复杂的方向演替,从群落的角度分析,除了群落中土壤碳储量越来越丰富外,还应表现为等特征(至少答两点)。
(2)红树林中的碳输出到大气主要是通过等生理过程实现的。据图判断,至少满足的数量关系(用图中除了△CV、△CL、△CS以外的字母和运算符号表示),才能体现出红树林重要的碳汇功能。
(3)由于缺乏环保意识,该地大量砍伐红树植物,导致土壤暴露,积水减少,土壤含氧量增加,据图分析,这种砍伐行为加剧温室效应的机理是 。
答案:(1)耐盐碱、根系发达、对水多的环境适应能力强 群落中物种丰富度逐渐加大,种间关系越来越复杂
(2)呼吸作用和分解作用(细胞呼吸和分解作用) GPP+EX>Ra+Rh+Me+D+H+I
(3)一方面,植被减少使该生态系统吸收二氧化碳减少;另一方面,土壤含氧量增加,好氧微生物分解有机碳能力更强,土壤中储存的碳短时间内被大量分解为二氧化碳并释放
13.滨海某湿地森林植被退化,形成的裸滩被外来入侵植物互花米草占据。群落中芦苇、耐高盐的碱蓬和互花米草的相对多度(群落中某一种植物的个体数占该群落所有植物个体数的百分比)与入侵时间的关系如图1所示。研究发现,互花米草入侵后,导致图1两种植物相对多度发生变化的原因如图2所示。请回答下列问题:
(1)某研究小组借助空中拍照技术调查某湿地地面活动的某种动物种群的数量,主要操作流程是选取样方、空中拍照、识别照片中该种动物并计数。与标记重捕法相比,上述调查方法的优势有 。
(2)图1中乙植物是 (填“芦苇”或“碱蓬”)。互花米草入侵的第1年至第5年甲种群密度变化的原因是 。
(3)该湿地某食物网如图3所示(图中数字为能量数值,单位为kJ/m2·a),该食物网中,第二营养级到第三营养级的能量传递效率为 %(精确到小数点后一位)。已知这两种虾之间存在较为激烈的种间竞争,这种竞争会导致它们的生态位 (填“重叠”或“分化”)。
(4)该湿地遭到了镉污染,研究人员利用生态浮床进行了有效治理。研究人员指出,浮床中的水生植物不能作为家畜饲料,原因是 。
(5)为防治互花米草的生态入侵,湿地修复过程中通常选择净化能力强的多种水生植物,使它们形成互利共存关系,这体现的生态学原理是 。
【答案】(1)对野生动物不良影响小,调查周期短,操作简便
(2) 碱蓬 随着互花米草的入侵,乙的种群密度大量减少,甲可获得更多的阳光、土壤中的营养,以及更多的生存空间
(3) 16.2% 分化
(4)重金属难以被机体代谢出去,会沿食物链富集,对家畜和人的健康产生危害
(5)自生
14.2023年3月,我国进行了首单“蓝碳”拍卖。“蓝碳”是利用海洋活动及海洋生物吸收大气中的二氧化碳,并将其固定、储存的过程,红树林是“蓝碳”生产的重要部分,合理保护和开发红树林有助于我国实现“碳中和”的目标。下图为我国南方某地红树林群落组成简图,请回答下列有关问题。
(1)研究发现,红树林的硫化氢含量很高,泥滩中大量厌氧菌在光照条件下能利用H2S为还原剂使CO2还原为有机物,这是陆地森林不能达到的。这些厌氧菌属于生态系统组成成分中的_______。若由于某种原因,虾蟹突然大量减少,则短期内水蚤的数量将_______。假定上图中食虫鱼和小型食肉鱼同化获得的总能量不变,鸟捕食大型食肉鱼所获得的能量所占的比例从1/2调整为1/5,则鸟获得的能量约为调整前的_______倍(能量传递效率按照10%计算)。
(2)碳在生物群落中以_______形式传递。红树林碳汇功能强大,一定程度上可以“抵消”全球的碳排放,实现“碳中和”,这体现出物质循环具有_______特点。红树林的碳汇潜力会受海水潮汐浸淹的影响,请从生物角度推测其原因:_______。红树林是世界上最富多样性的生态系统之一。其中角果木树皮捣碎可以止血、收敛、通便和治疗恶疮,种子榨油可以止痒,红树林能防风浪冲击,保护海岸,还能吸收污染物,降低海水_______程度,防止赤潮发生,体现了生物多样性的_______价值。
(3)红树林分布在热带、亚热带低能海岸潮间带,受周期性潮水浸淹,推测红树林中的植物可能具有哪些形态、结构或功能特点?_______。
①体内细胞中细胞液渗透压低 ②具有发达的根系 ③具有排盐、泌盐结构 ④根系耐缺氧
(4)滨海湿地是海岸带蓝碳生态系统的主体。滨海湿地单位面积的碳埋藏速率是陆地生态系统的15倍,主要原因是湿地中饱和水环境使土壤微生物处于_______条件,导致土壤有机质分解速率_______。
(5)为提高湿地蓝碳储量,某地实施了如下图所示的“退养还湿”生态修复工程。
①该工程遵循的生态学基本原理包括_______(答出两点即可),根据物种在湿地群落中的_______差异,可适时补种适宜的物种。
②测定盐沼湿地不同植物群落的碳储量,发现翅碱蓬阶段为180.5kg·hm-2、芦苇阶段为3367.2kg·hm-2,说明在_______的不同阶段,盐沼湿地植被的碳储量差异很大。
【答案】(1)生产者 下降 1.96
(2) (含碳)有机物 全球性 海水潮汐浸淹导致的缺氧生境抑制了生态系统的呼吸作用 富营养化 直接和间接价值
(3)②③④
(4) 无氧(或缺氧) 低
(5) 自生、整体(或协调) 生态位 群落演替
15.(2026·山东德州·一模)37.S蛋白能够特异性识别癌细胞表面抗原,L蛋白是一种可被低氧环境激活的菌体裂解酶,科研人员将S蛋白基因和L蛋白基因连接为S-L融合基因,利用腺病毒AAV构建基因表达载体,再利用AAV和大肠杆菌DNA片段中同源区段可发生交换的原理,将S-L融合基因导入大肠杆菌基因组中,构建出能够精准递送抗癌药物的工程菌。
图1:S-L融合基因的构建过程
图2:同源重组替换基因的过程
(1)已知S蛋白基因转录时以b链为模板,L基因转录时以a链为模板。在构建S-L融合基因时,最好使用限制酶___________分别切割S蛋白基因和L蛋白基因,再用___________酶连接。将S-L融合基因连接至AAV载体时,需利用限制酶___________对S-L融合基因进行切割。
(2)AAV作为载体应具备的条件有___________(答出两点)。
(3)将基因表达载体导入大肠杆菌后,获得甲、乙两种大肠杆菌,分别提取其DNA,加入引物1、2、3扩增并电泳,结果如图3所示。其中成功导入S-L融合基因的大肠杆菌为___________(填“甲”或“乙”);条带③为用引物___________扩增的产物。
(4)已知癌细胞周围为低氧环境。把抗癌药物注入含S-L融合基因的工程菌中,该工程菌可实现抗癌药物的精准递送,分析其机理是___________。
【答案】(1)①. XbaⅠ、SpeⅠ ②. DNA连接 ③. PstⅠ、BglⅡ
(2)有多个限制酶酶切位点、基因能够在受体细胞内自我复制或整合到受体细胞DNA中,随着宿主细胞DNA复制而复制、有标记基因、对宿主细胞无害
(3) ①. 乙 ②. 引物1和引物2
(4)工程菌中表达的S蛋白可特异性结合癌细胞抗原,将工程菌引至癌细胞,癌细胞周围的低氧环境激活L蛋白导致工程菌破裂,抗癌药物释放
16.同源重组技术是指利用目的基因与插入位点两端的同源序列实现目的基因的定向插入。为研究马铃薯抗马铃薯早疫病菌(As)感染的能力是否与S基因表达有关,研究人员用PCR技术扩增S基因反义片段,通过同源重组技术将反义片段插入Ti质粒,并将该质粒导入抗As马铃薯植株中,过程如图1所示。反义片段转录形成的RNA可与S基因的mRNA互补结合,从而抑制S基因的表达。
(1)农杆菌转化法中的转化是指目的基因进入受体细胞内,并且在受体细胞内______的过程。反义片段转录形成的RNA抑制了S基因表达的______过程。
(2)用限制酶切割图1中质粒会产生黏性末端,需用DNA聚合酶将产生的黏性末端补平,该过程应选用的限制酶是______。利用同源重组技术获得重组质粒,需要引物在片段末端加入与切割位点末端相同的同源序列,引物F和R所含的同源序列分别为5′-______-3′和5′-______-3′(两空只写出与扩增的S基因片段末端序列相连的3个碱基)。
(3)将反义片段转入抗As马铃薯细胞后,需在培养基中加入______(填“卡那霉素”“氨苄青霉素”或“卡那霉素和氨苄青霉素”)进行筛选。
(4)将三种植株分别接种致病菌,菌斑大小和未接种致病菌植株各个生长指标的相对值如图2所示。
据图2分析,S基因对马铃薯植株的作用是______。成功转入S基因反义片段植株与敲除S基因的植株生长指标有明显差异,推测原因是______。
【答案】(1)①.维持稳定和表达②.翻译
(2)①.BbvCⅠ②.TGA③.TCA
(3)卡那霉素(4)①.提高植株抗As感染的能力②.S基因反义片段转录形成的RNA降低了生长素合成相关基因的表达
2026-05-21
1.制定《抗菌药物临床应用管理办法》的目的是什么?
答:制定《抗菌药物临床应用管理办法》和专项整治的目的十分明确,就是为了加强抗菌药物临床应用管理,优化用药结构,规范临床应用行为,提高用药水平,控制细菌耐药,保障医疗质量和医疗安全。
2.什么叫抗生素、抗细菌药、抗真菌药物、抗微生物药物、抗感染药物及抗菌药物?
答:抗生素:特指来源于微生物代谢产物及其化学半合成衍生物,在低浓度下能选择性抑制或杀灭其他微生物,并可供临床应用的一大类药物,如青霉素类、头孢菌素类。
抗细菌药物:是指在体内外对细菌(包括支原体、衣原体、立克次体、狭义细菌、放线菌、螺旋体)有杀灭或抑制作用的药物,包括抗生素和氟喹诺酮类、磺胺类、呋喃类、硝基咪唑类、噁唑烷酮类等人工合成的化学抗菌药物,不含外用消毒剂。
抗真菌药物:是指在体内外能抑制或杀灭真菌的药物。有抗生素和合成药两大类。①抗生素类主要有灰黄霉素、制霉菌素和两性霉素B等;②合成药主要有咪唑类药物(如克霉唑、益康唑、咪康唑和酮康唑等)、氟胞嘧啶、丙烯胺衍生物。
抗微生物药物:是能抑制或杀灭病原微生物,用于治疗微生物所致感染的药物,包括:抗细菌药、抗真菌药、抗结核药、抗病毒药及抗原虫药物等。
抗感染药物:是指能用于治疗所有病原体所致感染性疾病的药物,包括抗细菌药(含抗结核药)、抗真菌药、抗病毒药和抗寄生虫药(包括原虫与蠕虫)等。
抗菌药物:在国内,一般把抗细菌药物与抗真菌药物统称为抗菌药物。
3.《抗菌药物临床应用管理办法》对抗菌药物是如何界定的?
答:本办法特别规定抗菌药物是指:治疗细菌、支原体、衣原体、立克次体、螺旋体、放线菌及真菌等微生物所致感染的药物。不包括不针对上述病原菌的抗病毒药与抗寄生虫药;尽管属于抗菌药物,但因为临床应用的特殊性,抗结核药、抗麻风药以及具有抗菌作用的中药制剂以及外用抗菌药物制剂暂未纳入本管理办法范围。
4.医疗机构抗菌药物临床应用管理责任制的主要内容有哪些?
答:(1)医疗机构主要负责人是抗菌药物临床应用管理第一责任人,分管负责人是具体责任人,将抗菌药物临床应用管理作为医疗机构医疗质量安全和医院管理的重要内容纳入工作安排。
(2)医疗机构的医务部门是本地本单位抗菌药物临床应用管理的职能机构,要切实承担起相应责任。临床科室负责人是抗菌药物临床应用管理的直接责任人。要通过层层落实责任制,推进活动健康有序开展,确保取得实效。
(3)医疗机构主要负责人与临床科室负责人要签订抗菌药物合理应用责任状,根据各临床科室不同专业特点,科学设定抗菌药物应用控制指标。
(4)医疗机构要把抗菌药物合理应用情况作为医疗机构、医疗机构负责人、科室负责人、临床医师综合目标考核以及晋升、评先评优的重要指标,作为医师定期考核的重要内容。
5.如何根据各临床科室不同专业特点,科学设定抗菌药物应用控制指标,分别签订抗菌药物合理应用责任状?
答:各临床科室疾病种类、感染发生率、感染严重程度等均不相同,其抗菌药物使用品种、使用频度和强度各有差异,因此设立抗菌药物应用控制指标不可采取一刀切的方式,应当按照不同科室的情况给出具体目标。首次制定责任状目标的时候,应当先进行基线调查,然后根据实际情况结合全院需要达到的目标,将目标任务分配到各个科室;然后经过一定时期的持续监测,合理调整各个科室的目标值,最后签订出一份合理的责任状。
6.开展医疗机构院、科两级抗菌药物临床应用情况调查的内容与目的是什么?
答:(l)对院、科两级抗菌药物临床应用调查的目的:是为了摸清本机构院、科两级前一年抗菌药物临床应用的基本情况,分析存在的问题与不足,以保持和继续提升临床药物治疗水平,完善与改进临床药物治疗中的不足,促进合理用药;根据调查中发现的问题,调整抗菌药物的品种、品规或生产、经营企业,促进医药流通领域的公开、公平、公正的良性竞争,确保药品质量。
(2)调查内容:①本年度药品收入占本机构总收入百分率,抗菌药物占药品总收入百分率;②使用抗菌药物品种、使用量及金额,占抗菌药物总金额百分率;③分析使用量与金额排序前10位抗菌药物品种、品规及其适宜性;④住院患者抗菌药物使用率、使用强度;⑤门诊抗菌药物使用品种、占处方百分率;⑥急诊抗菌药物使用品种、占处方百分率;⑦I类切口和介入治疗预防抗菌药物使用率;⑧特殊使用级抗菌药物使用率、使用强度;⑨调查分析抗菌药物品种和供应目录中品规动态管理情况,审核使用中的抗菌药物是否有安全隐患、疗效不确定、耐药严重、性价比差和违规使用的品种或品规。
7.抗菌药物分级管理原则是什么?
答:为合理使用抗菌药物,根据各种抗菌药物的作用特点、疗效和安全性、细菌耐药性、药品价格等因素,将抗菌药物分为非限制使用级、限制使用级与特殊使用级三级,结合各级各类医院实际情况进行分级管理。抗菌药物分级原则:
(l)非限制使用级:经临床长期应用证明安全、有效,价格相对较低的抗菌药物。
(2)限制使用级:鉴于此类药物的抗菌特点、安全性和对细菌耐药性的影响,需对药物临床适应症或适用人群加以限制,价格相对较非限制使用级略高。
(3)特殊使用级:是指某些用于治疗高度耐药菌感染的药物,一旦细菌对其出现耐药,后果严重,需严格掌握其适应证者,以及新上市的抗菌药物,后者的疗效或安全性方面的临床资料尚不多或并不优于现用药物;药品价格相对较高。
8.医疗机构抗菌药物临床应用技术支撑体系是指哪些部门和专业技术人员?
答:主要是指以下3个技术科室及其专业技术人员:
(l)二级以上医院要设置感染疾病科,及其抗感染治疗专科医师。
(2)二级以上医院可根据需要设置临床微生物室,及其临床微生物专业技术人员。三级医院必须设置临床微生物室,配备微生物检验专业技术人员。二级医院应积极创造条件设置相适应的临床微生物室,在尚未设置临床微生物室以前,应将微生物检验标本送到附近三级医院监测。
(3)二级以上医院必须在医院药学部门内设置临床药学室,及其抗感染药物治疗的专职专科临床药师。
9.医疗机构如何实现抗菌药物临床应用专业化管理?
答:医疗机构抗菌药物临床应用管理需要医务、药学、感染性疾病、临床微生物、护理和医院感染管理等部门的多学科合作。抗菌药物合理应用的专业化管理离不开感染病学科建设,在国外的综合医院,感染科医师在抗菌药物使用中发挥着重要的作用,是抗菌药合理使用管理的业务科室,承担全院各个科室抗菌药物使用的会诊工作。临床微生物室的专业技术人员开展微生物涂片、分离培养、鉴定和药敏试验等工作,及时准确地出具报告、检验质量符合质控要求;参与医院抗菌药物临床应用管理,为临床抗菌药物合理应用提供咨询、培训等技术支持;定期根据细菌耐药情况,统计细菌耐药信息,发布耐药预警。抗感染药物治疗的专职专科临床药师参与所在病区抗菌药物治疗方案,用药医嘱审核与不合理用药干预,对患者用药教育等临床应用相关专业技术支持,并参与医院抗菌药物的相关管理工作,如抗菌药物品种与品规遴选,临床应用评估和会诊等。
抗菌药物临床应用整治是长期的过程,尽管目前抗菌药物管理主要是行政干预,但将来逐步走向专业化,由专业科室和专业技术人员承担这方面的工作,使抗菌药物临床应用管理具有可持续性。
10.抗菌药物品种和品规遴选的法规依据是什么?
答:遴选品种和品规的法律、技术规范依据:《中华人民共和国药品管理法》、《中华人民共和国执业医师法》、《抗菌药物临床应用管理办法》、《处方管理办法》、《医疗机构药事管理规定》和《抗菌药物临床应用指导原则》、《卫生部办公厅关于抗菌药物临床应用管理有关问题的通知》、《医院处方点评管理规范(试行)》。品种、品规主要应是从《国家基本药品目录(基层版)》、《中国国家处方集》、《国家医保报销目录》中遴选。抗菌药物品种、品规遴选的技术层面,应充分评价抗菌药物以下几点因素:药动学与药效学特点;临床安全性与药物不良反应;临床疗效与经济性;耐药趋势;疾病谱……并应充分考虑国内外相关诊疗指南。
11.如何做到抗菌药物购用品种、品规结构合理,并动态优化品种结构?
答:对抗菌药物品种、品规数量予以严格限制,其宗旨在于优化各医院抗菌药物处方集,促进临床医生选择疗效、安全性和卫生经济学特性优良的药物,淘汰疗效、安全性和性价比差的品种。医院确定抗菌药物处方集时,应组织熟悉感染性疾病、抗菌药物应用的临床和药学专家,在遵循安全、有效、经济和充分满足临床合理需要的原则下,考虑以下因素:
(l)确保大多数类别抗菌药物均有代表品种。不同类别药物具有独特的作用机制、抗菌谱和药动学特性,多元化有助于减轻抗菌药物选择压力、延缓细菌耐药性上升速率和满足临床不同需要。
(2)在同类药物中选择优效、安全、循证医学证据多、权威指南推荐的品种,同类品种数目应严格限制。
(3)品牌、仿制品一品两规,满足不同患者需要。
(4)考虑因本医院学科、疾病谱构成特点对抗菌药物需求的影响。
(5)兼顾卫生经济学,包括本地区主要人群经济承受能力、医保报销制度等。
(6)临床确有正当理由,可向主管卫生行政部门申请适当增加品种、品规。在具体操作中,要避免把抗菌药物品种数目与滥用挂钩、认为品种越少越合理的认识误区,更应避免“伪劣品种赶走优良品种”这种违背限制品种数目宗旨的情况发生。
12.如何加强抗菌药物采购供应管理?
答:加强抗菌药物采购供应管理主要应遵守以下几方面内容:
(l)执行落实有关法律、法规、规章的相关规定,《抗菌药物临床应用管理办法》第二十一条规定:“医疗机构抗菌药物应当由药学部门统一采购供应,其他科室或者部门不得从事抗菌药物的采购、调剂活动。临床上不得使用非药学部门采购供应的抗菌药物”。
(2)对启动临时采购程序的有关规定:因特殊治疗需要,需使用供应目录以外抗菌药物的,应当由临床科室提出申请,说明抗菌药物品名、规格、数量和理由,经抗菌药物管理组审核同意后,由药学部门临时一次性购入使用。启动临床采购程序,每个品种每年不得超过5例次,否则,医疗机构应当调整“药品处方集”或者“基本药品供应目录”,但品种、品规总数不得增加。临时采购情况,每半年应当向卫生行政部门备案。
(3)医疗机构应当遴选制定“药品处方集”、“基本药品供应目录”,并应报相应卫生行政部门备案。抗菌药物品种或品规的调整周期原则上不少于1年,清退或更换的品种、品规原则上l年内不得重新进入药品处方集或者供应目录。
(4)本机构制定的“药品处方集”、“基本药品供应目录”凡超出抗菌药物临床应用专项整治规定的抗菌药物品种、品规数的,应当说明理由,报送备案的相关卫生行政部门审核后,由省级卫生行政部门审核批准后,由药学部门统一采购、调剂配发。
13.有关抗菌药物采购供应管理的规定是什么?其中是否包括了滴眼液、软膏剂及阴道用药等外用抗菌药物品种?
答:建立抗菌药物遴选和定期评估制度,加强抗菌药物购用管理。医疗机构对抗菌药物供应目录进行动态管理,清退存在安全隐患、疗效不确定、耐药性严重、性价比差和违规使用的抗菌药物品种或品规。清退或者更换的抗菌药物品种或品规原则上12个月内不得重新进入抗菌药物供应目录。严格控制抗菌药物购用品种、品规数量,保障抗菌药物购用品种、品规结构合理。三级综合医院抗菌药物品种原则上不超过50种,二级综合医院抗菌药物品种原则上不超过35种;口腔医院抗菌药物品种原则上不超过35种,肿瘤医院抗菌药物品种原则上不超过35种,儿童医院抗菌药物品种原则上不超过50种,精神病医院抗菌药物品种原则上不超过10种,妇产医院(含妇幼保健院)抗菌药物品种原则上不超过40种。
同一通用名称注射剂型和口服剂型各不超过2种,具有相似或者相同药理学特征的抗菌药物不得重复采购。头霉素类抗菌药物不超过2个品规;第三代及第四代头孢菌素(含复方制剂)类抗菌药物口服剂型不超过5个品规,注射剂型不超过8个品规;碳青霉烯类抗菌药物注射剂型不超过3个品规;氟喹诺酮类抗菌药物口服剂型和注射剂型各不超过4个品规;深部抗真菌类抗菌药物不超过5个品种。医疗机构抗菌药物采购目录(包括采购抗菌药物的品种、品规)要向核发其《医疗机构执业许可证》的卫生行政部门备案。
根据《抗菌药物临床应用管理办法》对抗菌药物的界定,暂不包括抗感染外用药,因此不包括滴眼液、软膏剂及阴道用药等外用抗菌药物品规。
14.如何理解和执行“具有相似或者相同药理学特征的抗菌药物不得重复采购”的规定?
答:药理学特征指药效学和药动学特点。按化学结构与作用机制抗菌药物大致有20余类,在同一类中又由于抗菌活性与药动学特点差异被分为所谓不同的代,即使在相同代别内,不同产品还存在一些特性,按照管理要求,具有相似或相同药理学特征的抗菌药物不得重复采购,主要指药理学特征各方面都相似,安全性也相差无几的药物,如果重复采购势必造成在有限的抗菌药物品种中多样性的丢失,容易出现细菌耐药,也可能导致制药企业间的恶性竞争,不利于抗菌药物合理使用。医疗机构在进行抗菌药物遴选时,先要对相同或相似药理学特征的药物进行甄别,在相同或相似药理学特征药物中选择高质量与高性价比的品种。
15.抗菌药物品种与品规有什么区别?有儿科的综合医院在一品两规之外是否可增加儿科剂型?
答:抗菌药物品种指一个通用名称的抗菌药物,不区分剂型和剂量规格。品规是有剂型、剂量规格的,例如:头孢呋辛注射剂与头孢呋辛酯胶囊为同一品种不同品规;特比萘芬片与特比萘芬软膏为同一品种不同品规。
《2012年全国抗菌药物临床应用专项整治活动方案》规定“同一通用名称注射剂型和口服剂型各不超过2种”,其含义是一个通用名称的抗菌药物品种可以购进注射剂型2个品规,口服剂型2个品规。剂型和剂量规格相同,不同厂家生产的也视为2个品规,例如:头孢吡肟0.5g/瓶(甲厂)与头孢吡肟1g/瓶(甲厂)算为不同品规;头孢吡肟0.5g/瓶(甲厂)与头孢吡肟0.5g/瓶(乙厂)算为不同品规。
对于有儿科的综合医院,如少数常用品种在“一品两规”的范围内无法兼顾成人和儿童患者的需要,儿科剂型可适当增加,但需向核发其《医疗机构执业许可证》的卫生行政部门申请备案。
16.为什么开具处方应当使用药品通用名?
答:《处方管理办法》第十七条规定开具处方应当使用药品通用名称,药品使用通用名称可以规范处方药品名称,有利于医师和药师选用药品,避免因一药多名引起重复用药造成用药错误,有利于国家对药品的监督管理,有利于保护消费者合法权益,也有利于制药企业之间展开公平竞争。
17.医师应怎样掌握和使用不同分级管理类抗菌药物?
答:医务人员应当认真学习并严格执行抗菌药物临床应用相关管理制度,首先要严格掌握使用抗菌药物预防感染的指征。预防感染、治疗轻度或者局部感染应当首选非限制使用级抗菌药物;严重感染、免疫功能低下合并感染或者病原菌只对限制使用级抗菌药物敏感时,方可选用限制使用级抗菌药物。临床应用特殊使用级抗菌药物应当严格掌握用药指征,经抗菌药物管理工作组指定的专业技术人员会诊同意后,由具有相应处方权医师开具处方。因抢救生命垂危的患者等紧急情况,医师可以越级使用抗菌药物。越级使用抗菌药物应当详细记录用药指征,并应当于24小时内补办越级使用抗菌药物的必要手续。
18.对于特殊使用级抗菌药物的管理有什么规定?
答:根据《抗菌药物临床应用管理办法》及《2012年全国抗菌药物临床应用专项整治活动方案》,对特殊使用级抗菌药物有如下管理规定。
(1)制定医疗机构抗菌药物分级管理目录,特殊使用级抗菌药物品种目录应当单.独制定,定期调整,严格管理。
(2)严格控制特殊使用级抗菌药物使用。
(3)特殊使用级抗菌药物不得在门诊使用。
(4)明确医师权限:具有高级专业技术职务任职资格的医师,可授予特殊使用级抗菌药物处方权。
(5)制定特殊使用级抗菌药物的使用流程。
(6)计算特殊使用级抗菌药物使用率、使用强度:
特殊使用级抗菌药物使用率=
特殊使用级抗菌药物的DDD数=
特殊使用级抗菌药物使用强度=
19.对静脉输注使用抗菌药物有什么规定?
答:根据《抗菌药物临床应用管理办法》第二十九条:医疗机构应当制定并严格控制门诊患者静脉输注使用抗菌药物比例。村卫生室、诊所和社区卫生服务站使用抗菌药物开展静脉输注活动,应当经县级卫生行政部门核准。
门诊患者静脉输注使用抗菌药物百分率=
20.卫生部全国抗菌药物临床应用监测网是什么职能单位?
答:卫生部全国抗菌药物临床应用监测网正式成立于2006年5月,由卫生部委托卫生部医院管理研究所药事管理研究部及中国医院协会药事管理专业委员会主办(管)。其主要职责是对全国各级医疗机构抗菌药物临床应用情况进行调查,并对药物使用的适宜性、合理性进行评估,包括临床应用抗菌药物的品种、使用量、金额、住院患者(手术与非手术)抗菌药物使用率、使用强度、不规范用药情况等内容。目前抗菌药物临床应用监测网已具有监测信息网上直报、信息公布、信息反馈、信息交流、专家讲座、病历教学等功能。
21.如何理解“医疗机构应持续开展、定期公布抗菌药物临床应用监测”?“监测”的内容有哪些?
答:抗菌药物是需要保护的有限资源,药物从实验室到用药对象有研发、生产、流通和应用四个环节,医疗机构持续开展、定期公布抗菌药物临床应用监测目的在于控制抗菌药应用环节,降低抗菌药物的使用率,遏制细菌耐药性的增长,规范抗菌药物的合理使用。具体内容是:
(l)监测临床抗菌药物应用管理情况:抗菌药物临床应用专项整治方案制定情况;抗菌药物临床合理应用责任状签订情况;抗菌药物临床分级管理情况;抗菌药物临床应用处方权管理情况;抗菌药物品种限定情况;处方、医嘱点评工作开展情况;抗菌药物管理相关信息公示情况;住院患者微生物送检情况;抗菌药物临床应用和细菌耐药动态管理控制。
(2)监测抗菌药物使用情况:住院患者抗菌药物使用率;住院患者使用强度;门急诊患者抗菌药物使用率。
(3)监测清洁手术预防使用抗菌药物情况:清洁手术预防使用抗菌药物比例;介入诊断预防使用抗菌药物比例;清洁手术预防使用抗菌药物品种选择合理率;清洁手术预防使用抗菌药物用药时机合理率;清洁手术预防使用抗菌药物使用疗程合理率;清洁手术预防使用抗菌药物联合用药情况。
22.建立细菌耐药监测网的目的,应如何组织实施?
答:细菌耐药监测对感染性疾病治疗、抗菌药物合理使用管理、抗菌药物研究与开发等具有十分重要价值;细菌耐药依照其监测目的不同可分为普遍性监测和特殊病原菌耐药监测,依照监测范围可分为地区、国家、区域、医院甚至专业科室监测,按照监测方式不同可分为主动监测与被动监测等。我国已经建立全国细菌耐药监测网和部分省级监测网,个别医疗机构也有监测;国家监测目的对于掌握全国细菌耐药信息与发展趋势、制定抗菌药物管理规章等具有重大价值。耐药监测需要根据监测目的、范围等进行组织,省级监测网最好有省级卫生行政部门指定具有较高专业水平的医疗机构承担,需要制定详细的监测计划,统一标准、统一分析方法、统一质量控制,定期进行培训,获得有价值的监测结果。按照卫生部要求,各省市自治区需要建立省级细菌耐药监测网,并且需要与国家监测网实现数据联通,具体情况可与全国监侧网联系(全国细菌耐药监测网负责单位:卫生部合理用药专家委员会)。
23.卫生部38号文要求医疗机构建立细菌耐药预警机制,并采取相应的干预措,具体应如何操作?
答:预警主要针对细菌耐药突出的抗菌药物而言,但每个抗菌药物又有比较宽的抗菌谱,在设定预警时必须加以注意。一般来讲,预警可以分为两类:耐药信息预警和抗菌药物预警,前者主要指一些特殊耐药现象,如MRSA、VRE、产ESBL肠杆菌科细菌、多重耐药铜绿假单胞菌、泛耐药不动杆菌等,当这些细菌检出率达到一定程度时就需要提醒临床加以注意,采取综合控制措施;抗菌药物预警则是指当细菌耐药超过一定程度后,提醒临床减少或停止使用某些抗菌药物,这类预警需要针对各专业科室、目标细菌感染进行,不宜在整个医疗机构进行,如当泌尿道来源大肠埃希菌产ESBL率超过70%,则建议泌尿内外科减少头孢菌素使用,相反此时肺炎链球菌、流感嗜血杆菌等对第三代头孢菌素敏感性还比较高,社区呼吸道感染应用第三代头孢菌素还不失为较好选择。
24. 2012年整治活动方案中微生物标本送检率与2011年有何不同?
答:《2011年全国抗菌药物临床应用专项整治活动方案》规定接受抗菌药物治疗住院患者微生物检验样本送检率不低于30%,计算方法如下:
住院患者微生物检验样本送检率=
2012年整治活动方案中规定接受限制使用级抗菌药物治疗的住院患者抗菌药物使用前微生物检验样本送检率不低于50%;接受特殊使用级抗菌药物治疗的住院患者抗菌药物使用前微生物检验样本送检率不低于80%。计算方法分别为:
25.规定每个月组织对25%的具有抗菌药物处方权医师所开具的处方、医嘱进行点评,每名医师不少于50份处方、医嘱。应如何组织实施?
答:对医师处方或用药医嘱点评应按照《处方管理办法》和《医院处方点评管理规定(试行)》执行落实。抗菌药物临床应用专项整治要求对25%的具有抗菌药物处方权医师所开处方、医嘱进行点评,每位医师不少于50张处方、医嘱。抗菌药物临床应用专项整治方案已有明确规定要“充分运用信息化手段”,这就是要求各医院探索建立信息化管理体系,实现处方、医嘱点评自动化;专项整治规定:抗菌药物处方、医嘱专项点评,医疗机构应组织感染科和药学部门的专业技术人员承担;重点抽查:感染科、呼吸科、外科、重症医学科,可按专项处方点评处理,但应尽快实施信息化管理。
26.抗菌药物处方和医嘱如何实施专项处方点评?
首先要建立和实施抗菌药物专项点评的程序。确定责任人,组成多学科的专家小组,对于医院抗菌药物专项点评过程进行监督和指导。要有实施计划,在一个年度中,列出哪些抗菌药物或者临床应用状况需要进行专项点评。
第二步骤是确定专项点评的目标以及范围。范围可以很广泛,也可以侧重于某一个具体的问题。如:调查汇总数据分析所显示的用于清洁手术预防用量大或(和)治疗用量大、价格昂贵的抗菌药品;抗菌药物敏感性报告所提示的抗菌药物选择的错误;患者记录表,严重 ADR报告所提示的某种特定抗菌药品的不合理使用(适应证、给药途径、剂量、使用方法)等。
第三步骤是建立评价标准。包括正确使用抗菌药物的各个方面(如是否做到有样必采,更改或继续使用是否有很好的临床分析,是否考虑患者的生理、病理因素,是否进行炎症指标的动态观察,是否考虑PK/PD参数要求等),应当在医疗机构的抗菌药物治疗指南或现有国家或地方的指南、其他相关文献、或公认的国际及地方专家的建议基础上建立的规范或标准。其可信度以及被接受的程度取决于标准是否来源于可信的循证医学资料及已经经过处方者的讨论、并取得共识。
第四步为收集数据。数据采集可以是回顾的方式,通过患者的病历或其他记录收集数据,或采用前瞻的方式,在药品准备或调配过程中进行。回顾性的数据收集方式更加迅捷,并且最好远离患者服务区域和各种干扰。而前瞻性的方式好处在于评估者可以在药品配置的过程中随时干预,以避免药品剂量错误、适应证、相互作用或其他错误,例如在某些药房所使用的计算机系统,电脑系统可以随时警告并提出改正的要求。这种系统同样可以为回顾性调查研究提供数据库。数据必须来自于医疗机构的患者记录表及处方记录的随机样本。通常由药学专业技术人员来选择,也可以由护士或者病历记录者选择。每个医疗机构至少需要收集30或50个临床常见病例的数据。
步骤五是数据分析。收集到的数据按照评价标准制成表格,计算和总结符合每条标准要求的百分率。并向药事管理与药物治疗学委员会汇总报告。
步骤六是向医师反馈结果和制定持续改进措施。医院药事管理与药物治疗学委员会接到报告后应该对结果进行合理性、准确性评估;通过信件、专题学术讨论或讲座、时事通讯、面对面讨论等各种方式将评估结果反馈给处方者或调剂者或给患者用药者(护士);实施纠正抗菌药物使用问题的干预措施,如在职教育、建立制定处方限制条件,修改处方目录和(或)处方手册,修改临床治疗指南等。
步骤七是后续追踪。在抗菌药物临床应用专项点评过程中,后续措施是保证不合理使用问题得以适当解决的关键。如果没有对干预措施进行评价或者抗菌药物使用问题没有得到解决,专项点评就毫无意义。因此,抗菌药物专项点评工作需要定期进行(至少1年1次),对使用没有显著影响的专项点评,需要重新设计,以达到改善临床抗菌药物不合理使用。如果后续追踪做得好、做得持久,处方者、调剂者、给患者用药者在知道自己今后还会面临评价时,可能会在各方面改进其行为是否符合基本原则。
27.临床情况复杂,点评抗菌药物治疗使用合理性时,应当从哪些角度采用哪些标准考虑?
答:抗菌药物临床合理使用目前并没有明确的量化标准,患者当时的临床状况是评价是否合理的重要参考因素,合理应用抗菌药物系指在明确指征下根据患者感染部位、感染获得场所、感染严重程度和病原菌种类选用适宜的抗菌药物,同时应参考PK/PD原理制订各类抗菌药物的合理给药方案,最大限度发挥抗菌药物的治疗作用,以达到杀灭病原体和控制感染的目的,同时采用各种相应措施减少不良反应,延缓细菌耐药。
具体可以考虑以下因素:是否有明确而合理的适应证,即初步诊断为细菌感染者以及经病原学检查确诊为细菌感染者;是否遵照本地区、本医院的诊疗指南和临床路径;是否积极送检病原学检查、争取病原治疗(根据培养、药敏结果选择抗菌药物);抗菌药物品种的选择、给药途径、剂量、每日用药次数、疗程是否合理;获病原学检查结果后是否根据细菌种类、药敏结果及时调整治疗方案;处方权限是否符合分级管理制度等。
28.建立抗菌药物管理奖惩制度的目的、主要内容是什么?
答:建立抗菌药物管理奖惩制度的目的是为了进一步推进抗菌药物的合理使用,切实提高医疗质量和服务水平,保障人民群众身体健康。主要内容:将抗菌药物临床应用合理性评价结果作为各项考核评优工作的重要内容,加大对于抗菌药物不合理使用责任人的处理和惩罚力度,加大对抗菌药物合理用药活动开展情况的督查力度,整改未达标的医疗机构。
29.如何管理医师抗菌药物处方权限和药师抗菌药物调剂资格?
答:(l)医师抗菌药物处方权限实行分级考核授权管理;药师抗菌药物调剂资格实行考核授权管理。
(2)具有高级专业技术职务任职资格的医师,可授予特殊使用级抗菌药物处方权;具有中级以上专业技术职务任职资格的医师,可授予限制使用级抗菌药物处方权;具有初级专业技术职务任职资格的医师,在乡、民族乡、镇、村的医疗机构独立从事一般执业活动的执业助理医师以及乡村医生,可授予非限制使用级抗菌药物处方权。医师经本机构培训并考核合格后,方可获得相应的处方权。药师经培训并考核合格后,方可获得抗菌药物调剂资格。
(3)二级以上医院应当定期对医师和药师进行抗菌药物临床应用知识和规范化管理的培训。其他医疗机构依法享有处方权的医师、乡村医生和从事处方调剂工作的药师,由县级以上地方卫生行政部门组织相关培训、考核。经考核合格的,授予相应的抗菌药物处方权或者抗菌药物调剂资格。
(4)医师出现下列情形之一的,医疗机构应当取消其处方权:①抗菌药物考核不合格的;②限制处方权后,仍出现超常处方且无正当理由的;③未按照规定开具抗菌药物处方,造成严重后果的;④未按照规定使用抗菌药物,造成严重后果的;⑤开具抗菌药物处方牟取不正当利益的。
药师未按照规定审核抗菌药物处方与用药医嘱,造成严重后果的,或者发现处方不适宜、超常处方等情况未进行干预且无正当理由的,医疗机构应当取消其药物调剂资格。
医师处方权和药师药物调剂资格取消后,在六个月内不得恢复其处方权和药物调剂资格。
30.如何根据“本机构及临床各专业科室抗菌药物使用情况”,评估抗菌药物使用适宜性?
答:可根据医院指标、处方指标、评估指标、其他指标,对非手术病人和手术病人分别定期分析各科室抗菌药物使用情况,评估抗菌药物使用适宜性。
(1)医院指标:制定抗菌药物临床应用指导原则实施细则;抗菌药物消耗情况(金额、累计DDD)。
(2)处方指标:抗菌药物使用强度;抗菌药物使用率;抗菌药物联合用药率;使用抗菌药物患者的平均用药品种数;使用抗菌药物患者的平均用药天数;使用抗菌药物患者的平均用药费用;抗菌药物使用排序;门诊处方以通用名开处方的百分率;门急诊处方抗菌药物处方的百分率等。
(3)评估指标:抗菌药物临床应用评价——测算临床应用抗菌药物是否适当、安全、有效、经济(动态变化)。
(4)其他指标:使用抗菌药物的患者平均住院天数;使用抗菌药物的患者有病原菌检测及药敏试验的比例;患者所用抗菌药物与药敏试验报告相符率等。
31.抗菌药物专项整治活动督查考核是否有统一标准?督查专家的检查思路和视角是怎样的?
答:抗菌药物专项整治活动督查考核具有统一的标准,其每次检查的方案和评分标准等均经过专家讨论后确定统一指标与标准。当然,是否完全符合不同类别医院的客观规律及体现科学公正性,尚待探索、完善、持续改进。
督查专家的督查思路和视角主要依据《抗菌药物临床应用指导原则》,以及抗菌药物使用有关专业指南及规范等,督查主要围绕抗菌药物使用中安全、有效、经济的合理用药目标进行。
检查的思路和视角包括管理部分的各类文件资料、分层抽查住院病历、门急诊处方、I类切口手术病历,在符合医疗服务实际、公平公正的原则下查阅抽取的资料,从中得出抗菌药物使用的相关指标。同时对被查医疗机构在抗菌药物使用专项整治活动中存在的一些问题提出建议与指导,避免缺乏人性的处罚行为,避免操之过急,务求一步一个脚印地做好整治工作,让医务人员真正认识到专项整治的重要性,主动学习合理用药知识,主动配合医院的管理,才能确保长效机制。
32.《2012年全国抗菌药物临床应用专项整治活动方案》中要求的部分内容与相应专业的临床路径或诊疗指南相矛盾,如Ⅰ类切口手术患者预防使用抗菌药物时间不超过24 小时,临床医务人员按哪个执行?
答:从科学角度而言,目前基于循证医学证据的国际权威指南推荐:大多数Ⅰ类切口手术预防用药术前一次给药即可,手术时间长达3小时及以上者或术中失血量超过1000ml者术中追加一次,总疗程一般不超过24小时,仅心脏等少数手术推荐预防用药时间为48小时。因此个别专业的临床路径或诊疗指南推荐更长时间的预防用药是不正确的。同时应特别强调手术预防用药不是万能,加强手术前、手术中、手术后消毒、无菌操作及保温、血糖控制等预防感染的其他措施尤其重要。
从行政权威角度而言,《2012年全国抗菌药物临床应用专项整治活动方案》的规定高于各专业的临床路径或诊疗指南。因此,当要求存在冲突时,应以专项整治活动方案规定为准。也积极倡议专业人员从自己专业角度出发,进行随机对照试验,从科学角度探索手术预防用药的科学性及严谨性,尤其是对预防用药并不明晰的手术更应该如此,建议在进行临床试验前获取医院伦理委员会的批准。
33.专科医院与综合医院病种不同,要求指标是否有所区别?
答:专科医院与综合医院病种不同,要求指标应有所不同,如2012年全国抗菌药物临床应用专项整治活动方案中规定口腔医院抗菌药物品种原则上不超过35种,肿瘤医院抗菌药物品种原则上不超过35种,儿童医院抗菌药物品种原则上不超过50种,精神病医院抗菌药物品种原则上不超过10种,妇产医院(含妇幼保健院)抗菌药物品种原则上不超过40种。
此外,2012年全国抗菌药物临床应用专项整治活动方案中还对专科医院门诊、住院和急诊的抗菌药物使用率和专科医院的抗菌药物使用强度提出要求,具体如下:
口腔医院:住院70 %,门诊20%,急诊50%,使用强度40DDDs/100(人·天)以下。
肿瘤医院:住院40 %,门诊10%,急诊10%,使用强度30DDDs/100(人·天)以下
儿童医院:住院60 %,门诊25%,急诊50%,使用强度20DDDs/100(人·天)以下。
精神病医院:住院5%,门诊5%,急诊10%,使用强度5DDDs/100(人·天)以下。
妇产医院(含妇幼保健院):住院60%,门诊20%,急诊20%,使用强度40DDDs/100(人·天)以下。
34.抗菌药物临床应用管理如何趋于专业化和常态化的管理?
答:抗菌药物专项整治主要是针对不合理的用药,今后的管理要趋于精细化、专业化和常态化。开始可以用比例、指标来进行“总量”控制,但随着整治工作的深人,专业化和常态化的管理才能科学、合理、持续。常态化管理包括常规的监测、调查和干预,定期对相关专业人员进行抗菌药物临床应用知识和规范化管理培训和考核等。专业化要体现在医疗机构抗菌药物临床应用技术支撑体系的建立,多学科的抗菌药物管理工作小组参与本医疗机构抗菌药物临床应用管理工作,要进行抗菌药物使用评价,仅靠药学部门组织多学科专家进行处方点评还是不够的,应做一些更细致的工作,包括循证、调研,制定指南,建立新的评价体系等。
35.《抗菌药物临床应用管理办法》对培训提出了哪些要求?
答:《抗菌药物临床应用管理办法》第二十四条、二十五条是讲培训工作的。一是要求各级医师在获得各级抗菌药物处方权前要经过培训并考核。药师要经培训并考核后,方可获得抗菌药物调剂资格。二是规定二级以上医院可以有本医疗机构组织抗菌药物临床应用知识和规范化管理培训和考核;其他医疗机构享有处方权的医师、乡村医生和从事处方调配工作的药师,需有县级以上地方卫生行政部门组织相关培训和考核。三是强调培训和考核要定期进行。四是要求的培训和考核的内容:
(1)《药品管理法》、《执业医师法》、《抗菌药物临床应用管理办法》、《处方管理办法》、《医疗机构药事管理规定》、《抗菌药物临床应用指导原则》、《国家基本药物处方集》、《国家处方集》和《医院处方点评管理规范(试行)》等相关法律、法规、规章和规范性文件。
(2)抗菌药物临床应用及管理制度。
(3)常用抗菌药物的作用特点。
(4)常见细菌耐药趋势与控制方法。
(5)抗菌药物不良反应的防治。
36.计算门诊抗菌药物使用率是否含急诊处方和儿科处方?是否含中成药处方?
答:不含急诊处方和儿科处方。在相同的医疗机构患者就诊的类型各有不同,这些不同就诊类型的药物治疗,即处方有显著不同,如果混合不同就诊类型的处方将难以解释结果。处方指标调查针对的是成人一般疾病的门诊处方,门诊成人处方数据平稳,可作为常规统计。《处方管理办法》规定西药和中成药处方可以分别开具处方,也可以开具一张处方。有的医院中西药房合并,处方难以分开,因此,计算时可以含中成药处方,但应剔除中药饮片的处方。
37.计算门诊抗菌药物使用率时同期就诊总人次无法统计怎么办?
答:要计算同期就诊总人次,必须具有统计“人次”的计算机系统,如目前做不到可采取就在规定日期范围内对就诊处方进行随机抽样的方法,如每月(可设定1天)随机抽取100张门诊处方,全年共1200张门诊处方计算就诊使用抗菌药物的百分率,这样可以使季节及药品供应周期中断等影响降到最小限度。当然,最终还是要运用信息系统统计到“人次”。
38.《2012年全国抗菌药物临床应用专项整治活动方案》中规定急诊患者抗菌药物处方比例不超过40%,急诊患者处方的范围如何界定?
答:急诊模式各医院之间差异很大,有许多三甲医院只是一个急诊室,患者看病后或抢救或回家或死亡或收住院,是一个通道;也有不少医院有院中院式的急诊,有正规的急诊病房和监护室(EICU)。综合医院急诊抗菌药物处方按小于40%的要求,主要包括急诊诊室、急诊输液、抢救室和临时观察室的处方,患者属临时观察还是长期观察(可视同住院)依据是否超过72小时界定。正规的急诊病房、EICU,其处方、医嘱不包括在急诊处方内。
39.如何计算医疗机构抗菌药物使用强度?在计算抗菌药物使用强度时分母是同期收治患者(人·天)数还是同期出院患者(人·天)数?
答:DDD(Daily DefinedDose)称为“限定日剂量”,定义:一个药品以主要适应证用于成年人的维持平均日剂量。DDD提供了一种与药物价格和配方无关的测量单位,不能够等同处方日剂量(PDD , PrescribedDaily Dose)。
抗菌药物专项整治活动方案要求三级综合医院抗菌药物使用强度争取达到40DDDs/100(人·天)以下。
抗菌药物使用强度是指:某病房或某医疗机构100床·日(人·天)数患者共使用了多少个DDD的抗菌药物。
例如要计算某病房1月份抗菌药物使用强度,可采用以下步骤:
(l)统计出1月份某病房每个品种抗菌药物的消耗量,将每个品种的消耗量除以此品种的DDD值,计算出此品种用了多少个DDD,即DDD数(DDDs)。然后将所有品种的DDDs相加,得出1月份某病房抗菌药物累计DDDs。
(2)累计1月份的床·日数。
(3)抗菌药物使用强度=
因此抗菌药物使用强度计算公式中的分母,指同期收治患者床·日(人·天)数。
40.WHO将ATC/DDD体系(药物分类系统和药物利用的技术性测量单位)作为国际药物利用研究的标准体系,有些在WHOATC分类索引中无法查到DDD值的抗菌药物其药品说明书中不同情况每日用量有一定差异,其DDD值如何确定?
答:1969年挪威研究者成立“药物研究工作组”建立了ATC/DDD系统,1996年,WHO使用此系统,标志其成为药物研究的国际性标准工具。一个药品要进入ATC/DDD目录可以由厂家、政府机构或者研究机构向WHO办公室提出申请。而已经在很多国家上市的药品,则无需申请即被收入ATC/DDD目录。
目前我国使用的大部分抗菌药物都可在ATC/DDD目录中找到。对于尚未列人ATC/DDD目录的药品,卫生部抗菌药物临床应用监测网的专家根据WHO-ATC制定DDD的原则,参考《中国药典临床用药须知》、《新编药物学》、《国家处方集》,以及3~4份不同厂家药品说明书,由专家讨论制定该药品的DDD,供抗菌药物临床应用监测网范围内统计使用。
全国各家医疗机构进行本机构抗菌药物使用强度监测时,应当参照卫生部抗菌药物监测网提供的数据进行计算。
41.如何计算青霉素、头孢菌素类复方制剂(β-内酰胺酶抑制剂)的DDD数?
答:ATC/DDD目录中,凡β-内酰胺酶抑制剂(青霉素类、头孢菌素类)复合制剂,在计算DDD数时,其DDD只考虑β-内酰胺酶类药物的含量,不统计酶抑制剂的量。例如:头孢哌酮复合静脉给药制剂如头孢哌酮/舒巴坦、头孢哌酮/他唑巴坦DDD值为4g,仅指其中头孢哌酮的量。
例如:某病房1月份使用头孢哌酮/舒巴坦2g(lg头孢哌酮:lg舒巴坦)200瓶.计算DDD数:(1g/瓶×200瓶)/4g=50。
42.抗幽门螺杆菌治疗是否可不纳入抗菌药物使用强度的计算?
答:用于抗幽门螺杆菌治疗的甲硝唑、阿莫西林、克拉霉素等药物属于抗菌药物,因此纳入抗菌药物使用强度的计算。
43.儿童用抗菌药物使用强度怎么计算?
答:儿童没有单独的DDD值,目前在药物临床应用研究上,沿用成人的计算方法,按成人规定日剂量标准计算。
44.住院患者抗菌药物使用强度统计时是否应包括出院带药?
答:“住院患者抗菌药物使用强度”顾名思义是统计患者在住院期间抗菌药物的使用情况,以抗菌药物使用强度来表示,但绝大多数医院住院患者抗菌药物消耗量是由住院药房处方汇总统计得出的,其中包括了出院带药的处方,目前卫生部抗菌药物临床应用监测网统计住院患者抗菌药物使用强度时包括了出院带药。
要加强抗菌药物的使用管理,必须根据患者的实际需求控制抗菌药物出院带药的处方。
45.如果抗菌治疗有效,能否减少抗菌药物的用量,以减轻患者经济负担,又降低抗菌药物DDD?
答:抗菌药物是一类特殊的治疗药物,在临床治疗有效而疗程尚未完成时,不应减量使用,因为药物浓度达不到有效抗菌浓度后,不仅会导致感染反复,而且由于不能有效抗菌,会诱使未被清除的细菌发生耐药性改变,导致最终治疗无效,甚或引起耐药细菌传播。
46.抗菌药物使用强度是一个宏观控制的指标。医院在合理使用抗菌药物的前提下如何控制抗菌药物使用强度?
答:抗菌药物的合理应用能有效降低抗菌药物使用强度,医院控制抗菌药物使用强度可以从以下几方面入手:
(l)严格掌握抗菌药物治疗性应用指征,减少不必要抗菌药物使用。
(2)严格把握抗菌药物预防应用指征、疗程,避免预防用药适应证过滥、疗程过长。
(3)严格掌握抗菌药物联合应用指征,避免不合理联合用药,例如碳青霉烯类、β-内酰胺酶抑制剂复方制剂等抗菌药物对厌氧菌具有良好抗菌活性,不需要联合甲硝哇等抗厌氧菌药物。
(4)力争病原治疗(根据细菌培养和药敏结果选择抗菌药物),因为病原治疗较经验治疗更少需要联合用药、可以更少药物获有效治疗结果。
(5)应按照病情轻重程度,以及药品PK/PD参数,合理使用药品剂量及用药次数,可将抗菌药物使用强度控制在合理的范围,并获得最佳的治疗效果。
(6)抗菌药物工作小组应向全院医生提供医院处方集中所有抗菌药物的DDD信息,便于医生处方时参考。
必须注意的是控制抗菌药物使用强度的目的是为了促进合理使用,应避免为达到减少抗菌药物使用强度目的而减少抗菌药物剂量、缩短疗程等本末倒置现象。
47.外科手术部位感染(SurgicalSiteInfection,SSI)的定义是什么?
答:SSI是指手术后发生在手术切口或手术深部或腔隙的感染。包括三类:
(l)切口浅部组织感染:手术后30天以内发生的仅累及切口皮肤或者皮下组织的感染,并符合下列条件之一:①切口浅部组织有化脓性液体;②从切口浅部组织的液体或者组织中培养出病原体;③具有感染的症状或者体征,包括局部发红、肿胀、发热、疼痛和触痛,外科医师开放的切口浅层组织。下列情形不属于切口浅部组织感染:①针眼处脓点(仅限于缝线通过处的轻微炎症和少许分泌物);②外阴切开术或包皮环切术部位或肛门周围手术部位感染;③感染的烧伤创面,及溶痴的Ⅱ、Ⅲ度烧伤创面。
(2)切口深部组织感染:无植入物者手术后30天以内、有植入物者手术后l年以内发生的累及深部软组织(如筋膜和肌层)的感染,并符合下列条件之一:①从切口深部引流或穿刺出脓液,但脓液不是来自器官/腔隙部分;②切口深部组织自行裂开或者由外科医师开放的切口。同时,患者具有感染的症状或者体征,包括局部发热,肿胀及疼痛;③经直接检查、再次手术探查、病理学或者影像学检查,发现切口深部组织脓肿或者其他感染证据。同时累及切口浅部组织和深部组织的感染归为切口深部组织感染;经切口引流所致器官/腔隙感染,无须再次手术归为深部组织感染。
(3)器官/腔隙感染:无植入物者手术后30天以内、有植人物者手术后l年以内发生的累及术中解剖部位(如器官或者腔隙)的感染,并符合下列条件之一:①器官或者腔隙穿刺引流或穿刺出脓液;②从器官或者腔隙的分泌物或组织中培养分离出致病菌;③经直接检查、再次手术、病理学或者影像学检查,发现器官或者腔隙脓肿或者其他器官或者腔隙感染的证据。
48.手术患者预防使用抗菌药物,其预防用药时机应如何掌握?什么情况下需要增加抗菌药物给药次数以预防手术部位感染?
答:正确的手术预防用药时机一般应在手术切开皮肤前30分钟~2小时内给予第一剂药物,或麻醉开始时首次给药,以保证抗菌药物有效浓度覆盖手术的全过程,过早给药无益。对于需要使用万古霉素或去甲万古霉素的手术患者,应在切开皮肤前2小时开始给予第一剂药物。
择期手术,一般术前用药一次即可,总预防用药时间般不超过24小时,个别情况可延长至48小时。鉴于最常用的β-内酰胺类抗菌药物(多为第一、二代头孢菌素)的血清半衰期一般不超过1.5~2小时(头孢曲松除外),如果手术持续3小时以上,或手术出血量大 (> 1500ml ),手术中需要再给一个剂量,否则在其后的时间里将失去抗菌药物的有效覆盖。
49.控制手术部位感染发病率除了预防用抗菌药物,还应采取哪些综合措施?
答:预防用抗菌药物不是控制外科手术部位感染的唯一措施,也不是最主要措施。预防外科手术部位感染最主要措施包括:围手术期处理和无菌操作。进行外科手术患者需要在术前对一些基础疾病进行治疗,如血糖控制、营养状况改善、器官功能纠正等,术后注意保持引流通畅、无菌敷料更换、患者早期活动等,术中严密的无菌操作、保护组织、患者保温等都对预防感染有重要价值,同时提倡术前在手术室即时剪毛或剃毛而不用刮毛进行备皮也非常有价值。
50.手术预防用抗菌药物的剂量是否越大越好?
答:通常,手术预防用抗菌药物采用标准治疗剂量或低于标准剂量给药,即已足以达到预防手术部位感染的效果。采用治疗严重感染时的增大剂量,是不必要的资源浪费,且明显增加了不良反应风险。
51.手术预防用抗菌药物采用何种给药途径?
答:一般都采用肠道外给药途径(静脉滴注或静脉推注)。静脉给药可保障术中和术后短时间内血浆及组织中药物浓度达到有效水平,能有效防止细菌入侵或定植,从而发挥预防手术部位感染的作用。有些手术,如部分需要做肠道抗菌药物准备的直肠结肠手术,必要时可于手术前一天分3~4次给药,口服新霉素、庆大霉素或联合甲硝唑。
52.围手术期首次预防用抗菌药物的医嘱应在病房还是手术室执行?医嘱执行的情况应记录在何处?
答:为保障围手术期首次预防用抗菌药物能在切开皮肤前0.5~2小时内给予,或在麻醉开始时给药,术前首次预防用药应在手术室内执行完成。其医嘱执行后,应清楚地标记在麻醉记录单上,或清楚地记录在护理工作记录单上(包括药品名称、单次剂量、途径、溶媒、用药起止时间等内容)。围手术期抗菌药物预防用药的所有内容都应清楚地记录在病历上,作为临床资料留存。
53.Ⅰ类切口手术患者预防使用抗菌药物的目的是什么?
答:Ⅰ类切口手术患者预防使用抗菌药物的目的是在围手术期充分抑制手术路径中可能存在的,细菌,减少手术部位感染。针对的细菌主要如皮脂腺、毛囊体表消毒无法完全清除的葡萄球菌属等革兰阳性细菌,如定值在皮脂腺、毛囊中的细菌。
围手术期预防用药目标是预防手术部位感染,但不包括与手术无直接关系的、术后可能发生的其他部位感染。不同部位感染的病原体不同,药物在不同部位的组织浓度也不同,如企图预防所有感染,需要兼顾众多微生物和部位,反而会影响效果。围手术期预防用药主要针对患者自身定植细菌而非外来微生物。外来微生物感染主要通过严格器械消毒、手术室管理和手术部位消毒、无菌屏障等综合措施来预防。不应把围手术期预防用药作为预防手术部位感染的唯一措施。而且由于可能导致手术部位感染的外来微生物种类多、对抗菌药物敏感性差异大,很难有针对众多外来微生物并且安全、有效和利大于弊的预防用药方案。
54.哪些Ⅰ类切口手术患者需要预防使用抗菌药物?
答:根据抗菌药物临床应用指导原则,Ⅰ类切口手术野为人体无菌部位,也不涉及呼吸道、消化道、泌尿生殖道等人体与外界相通的器官。通常不需预防用抗菌药物,仅在下列情况时可考虑预防用药:
(1)手术范围大、组织损伤较大出血量超过1500ml、时间长、污染机会增加。
(2)手术涉及重要脏器,一旦发生感染将造成严重后果者,如头颅手术、心脏手术、眼内手术等。
(3)异物植人手术,如人工心瓣膜植入、永久性心脏起博器放置、人工关节置换等。
(4)高龄或免疫缺陷者等高危人群。
55.“Ⅰ类术患者预防使用抗菌药物比率不超过30%”的含义和如何实施?
答:按照外科手术切口分类,Ⅰ类切口手术主要指清洁无污染手术,如甲状腺切除术、单纯乳腺切除术等,这些手术时间短、组织损伤小、细菌污染少,一般通过常规无菌操作即可预防术后切口感染,不需要使用抗菌药物预防。但部分Ⅰ类切口手术涉及重要脏器、手术时间长、组织损伤较大、或者患者有感染危险因素与较大的人工植入物,术后切口及深在部位发生感染的可能性较大,可以在术前应用抗菌药物预防感染。根据大量临床调查与监测,综合医院U44;类切口外科手术需要预防用药的患者大致在30%以下,也即卫生部设定的管理目标是Ⅰ类切口手术预防用药率不超过30%。要实现这一目标,必须科学管理,医疗机构必须根据各专业科室情况设定各自Ⅰ类切口预防用药率,不能整齐划一,各专业可以存在较大差异,如神经外科、心胸外科、骨科等预防用药比例较高,而甲状腺、乳腺、疝修补术预防用药比例则应更低。通过全院各专业共同努力,达到医疗机构Ⅰ类切口外科手术综合预防用药比例不超过30%。
56.Ⅰ类切口手术患者预防使用抗菌药物如何选择?
答:Ⅰ类切口手术患者预防使用抗菌药物的目的在于抑制手术路径中可能存在的细菌,减少手术部位感染。针对的细菌体表消毒无法完全清除的葡萄球菌属等革兰阳性细菌,如定植在皮脂腺、毛囊中的细菌。因此药物应选用对葡萄球菌具有良好抗菌活性、安全、使用方便、价格相对较低并被循证医学研究证明有效的品种。目前循证医学证据充分、国际权威指南推荐的Ⅰ类切口手术患者预防使用抗菌药物主要为头孢唑林和头孢呋辛。
在第一代头孢菌素注射剂中,头孢唑林对葡萄球菌属等革兰阳性菌抗菌作用作用强、不良反应少,且其作为预防用药的效果和安全性有充分的循证医学证据。同样在第二代头孢菌素头孢呋辛对葡萄球菌属等革兰阳性菌抗菌作用强、不良反应少、可通过血脑屏障,作为预防用药的效果和安全性的循证医学证据充分。因此两种药物被众多权威指南推荐用于大多数,Ⅰ类切口手术的首选药物。其他的第一、二代头孢菌素在抗菌活性、药动学活性、安全性、价格及循证医学证据等方面的综合优势逊于头孢唑林、头孢呋辛。
57.患者术后引流管未拔除,是否不能停用抗菌药物?
答:持续预防使用抗菌药物直至拔除引流管的方法,未被循证医学资料证实有益,因此是不合理、不规范的。
58.患者留置导尿管期间是否应预防用抗菌药物?
答:不建议患者留置导尿管期间常规预防用抗菌药物。在患者留置导尿管期间应对患者
加强护理,严格的护理可防止临时留置导尿管的患者发生尿路感染。
59.按照生部38号文件,β-内酰胺类过敏患者可以选用克林霉素预防革兰阳性菌感染,而金黄色葡萄球菌对克林霉素的耐药率也很高,对这类患者如何正确选择围手术期预防用抗菌药物?
答:根据2010年CHINET细菌耐药监测结果,我国甲氧西林耐药葡萄球菌对克林霉素耐药率高,但甲氧西林敏感葡萄球菌对克林霉素耐药率为25.7%。由于Ⅰ类切口手术患者多数住院时间短,皮肤定植菌多为甲氧西林敏感葡萄球菌,因此应用克林霉素仍可有效。此外,国外指南推荐β-内酰胺类过敏患者预防用药可选用万古霉素。同时由于磷霉素对葡萄球菌属尤其对甲氧西林敏感葡萄球菌具有良好抗菌活性,国内一些单位也将磷霉素作为备选药物。
60.国外抗菌药物手术预防用药方案推荐在MRSA高发地区使用万古霉素预防用药,我国多数地区MRSA分离率高,是否意味我国亦应该使用万古霉素预防用药?
答:我国甲氧西林耐药葡萄球菌(MRSA)的分离率资料主要来自医院获得性感染患者,而Ⅰ类切口手术患者多数住院时间短,皮肤定植菌多为甲氧西林敏感葡萄球菌。同时万古霉素成本高、静滴需要更长时间,且作为常规广泛应用存在导致肠球菌属和葡萄球菌属耐药性上升的风险。因此对万古霉素作为常规预防用药应持谨慎态度。建议将万古霉素预防性应用严格限制在:①头孢菌素过敏患者;②MRSA定植患者;③MRSA高发病区患者,尤其是具有 MRSA定植高危因素者(抗菌药物使用史,住院时间长,住ICU,来自护理机构,与MRSA携带者密切接触)。
61.髋关节/膝关节置换术是否预防用药?用药时间是否可以延长?
答:人工关节置换术作为有异物植入的手术,可以预防使用抗菌药物,但权威指南推荐用药时间仍为不超过24小时,延长用药时间并无必要。
62.安置心脏起搏器是否需要预防用药?用药时间是否可以延长?
答:根据美国心脏病学会电子植入物防治指南推荐,起搏器植入手术预防用药为手术前给药一次即可。
63.神经外科、心外科预防用药时间是否可以延长?
答:神经外科预防用药时间均应控制在术后24小时内,国外指南推荐心外科手术可使用48小时。
64.眼科的围手术期是否需要预防使用抗菌药物?如果需要预防使用抗菌药物是静脉用药还是局部滴眼?
答:眼内炎是眼部手术最严重的并发症之一,可以术前预防性应用抗菌药物。预防性用药以局部滴眼为主,有感染倾向者可全身使用抗菌药。
65.冠脉造影并支架植入术是否预防应用抗菌药物?
答:不推荐常规预防用药。对于7天内再次行血管介入手术者、留置动脉鞘大于24小时者,则应预防用药。
66.剖宫产手术属于哪类切口,是否需要预防用抗菌药物,如何给予?
答:剖宫产手术属于清洁-污染的Ⅱ类切口,因其与阴道相通,需要预防使用抗菌药物。可予夹脐时或术前30分钟~2小时内静脉给药。
67.临床微生物送检率包括哪些项目?
答:按照感染性疾病病原诊断与管理要求,以下各项检查可以作为计算微生物检查送检率的项目。
(l)无菌体液(离心后)细菌涂片染色细菌检查。
(2)合格标本细菌培养。
(3)肺炎链球菌尿抗原。
(4)军团菌抗原/抗体检查。
(5)真菌涂片及培养。
(6)血清真菌G实验或GM实验。
(7)降钙素原检测(PCT)。
特殊病原体(如支原体、衣原体、立克次体、螺旋体、病毒等)抗原抗体检查,主要用于相关特殊感染诊断,一般需要在检查获得有阳性结果对临床用药才具有参考价值,不计人应用抗菌药物前采样送检率。
68.抗菌药物治疗性和预防性使用时,微生物标本送检率要求相同吗?
答:治疗性应用时提高微生物标本送检率,有助于争取病原治疗,从而更有针对性、更有效、安全和经济地治疗患者。因此《2012年全国抗菌药物临床应用专项整治活动方案》中进一步提高了微生物标本送检率的要求。预防性应用抗菌药物时并不存在感染,因此不必进行微生物送检,专项整治方案中也未提出相关要求。有条件的单位,可以对一些有重要意义的耐药菌如MASA的定植进行主动筛查。
69.药敏的CLSI标准是什么?
答:CLSI的全称是临床实验室标准研究所(Clinical andLaboratoryStandards Institute ) , 是一个国际性的非营利组织,为临床与相关的医疗问题制定标准,得到世界范围的认可,我国的药敏试验结果判断标准参照CLSI标准文件,是部颁标准。标准规定了不同细菌进行药敏试验选择的抗菌药物的种类,也可以结合当地实际有所调整,需要注意抗菌药的抗菌谱,综合分析选择最佳的抗菌药种类。
70.不同生产厂家的同一通用名药品的药敏试纸对结果是否有影响?
答:不同厂家的药敏试纸只要合格,造成的实验结果差异应该在许可范围内。关键在于临床微生物实验室应该定期按CLSI规定以标准菌株进行药敏质控试验,如果测定结果在CLSI规定误差范围内,说明药敏纸片合格、试验准确。反之,则提示药敏纸片或药敏试验其他环节存在问题,应查找原因、改进试验流程,确保药敏结果符合质控标准。
71.为什么按照细菌学检查中的药敏试验结果用药有时候疗效仍然不满意?
答:首先需要明确的是报告中的细菌是感染的病原菌或仅为寄殖菌、污染菌;其次,药物在感染部位浓度可能由于给药剂量或药物分布原因不高。我们在选用药物时还需要考虑药物在体内的分布、在感染部位浓度、患者的基础疾病、代谢状况等。
72.为什么微生物检测阴性率高?
答:微生物检查阴性率高原因有以下方面:送检标本前使用了抗菌药物;标本留取不合格;标本接种不及时;实验室在选择培养基等方面处置不当。除前述临床、实验室可改进的问题外,一些微生物为常规方法无法检出,或病原体并非持续存在(如一过性的菌血症)等原因,需要通过改进技术手段、多次送检来改进。
73.病原学检测阳性率不高,是否阴性就不用抗菌药物?
答:感染的诊断依据包括临床症状、体征、常规检查结果及病原学检查结果四个方面。仅有前两者属于疑诊,具有前三者属于临床诊断,四者都有才算确诊。由于各种技术原因,许多种部位感染的病原学检测阳性率不高,但并不等于不存在感染,因此,抗菌治疗模式分为经验治疗与目标治疗,临床疑诊和临床诊断尽管病原学检测阴性,还是应该给予经验抗菌治疗,如果病原学检测结果未出来,患者病情不容等待,也应该积极给予经验抗菌治疗,确诊以后,如果经验治疗有效,维持原治疗方案,如果经验治疗无效,方能根据药敏结果进行目标治疗,在临床实践中,接受经验治疗的患者远多于接受目标治疗者。
74.是否必须根据病原学结果使用抗菌药?
答:否。医疗机构应该尽可能根据临床微生物标本检测结果合理选用抗菌药物,卫生部专项整治方案中也明确规定:接受限制使用级抗菌药的住院患者送检率≥50%,接受特殊使用级抗菌药的住院患者送检率≥80%。但是必须指出,送检不一定全部有阳性结果(阳性、阴性结果),培养阳性也不一定是感染的病原菌(污染、定植、感染)。所以,管理部门应该强调提高送检率,但不能硬性规定必须根据病原学结果使用抗菌药,更不能因为没有病原学结果而强制停用抗菌药,否则会耽误治疗和抢救病人。
75.是否找到细菌就一定有临床意义?
答:否。找到细菌不一定是感染的病原菌,要区别污染、定植还是感染。不同的菌种致病性有差别(致病菌、条件致病菌、非致病菌),不同部位,不同标本的临床意义也不同。痰、咽拭子(HI,SP除外)和粪便、肛拭子(ADCD除外)的临床意义较低,大多数为污染菌或条件致病菌;尿、脓、伤口分泌物标本的临床意义中等,需要排除污染才能确定感染,从血、脑脊液、胸腹水、无菌体液分离到细菌,污染的可能性小,临床意义大,提高送检率应该大力推荐从无菌部位采集标本,任何一种全身性的感染都可以做血培养,如菌血症、下呼吸道感染、泌尿道感染、腹腔内感染和皮肤软组织感染等。
76.是否找到细菌就一定要用抗菌药?
答:否。要根据情况综合分析、综合判断:找到的是什么细菌,从什么标本中找到,病人有无临床感染的征象和免疫缺陷等。如从呼吸道标本中找到鲍曼不动杆菌感染,定植的比例远大于感染。
77.是否某些抗菌药的耐药率高一定要停药?
答:否。任何抗菌药不会对所有细菌都敏感,也不会对所有细菌都耐药。例如青霉素对葡萄球菌95%以上耐药,但对大多数链球菌仍敏感,仍是治疗链球菌感染的主打药。应该根据各种抗菌药的抗菌谱和耐药率合理选择,取长补短。
78.由于某些时候病原学诊断需要较长时间出结果,如何和抗菌药物选用相辅相成?
答:抗菌治疗分经验治疗和病原治疗。当未获病原学检查结果时,医生可根据患者年龄,感染部位,感染获得场所(社区或医院获得性感染),易患因素和当地、近期的细菌耐药性监测结果等推断可能的病原体和药物敏感性,选择合适的抗菌药物。国内外均有针对各类感染的治疗指南,即是基于以上思路指导经验治疗。
因此临床医生在积极、及时送检合格微生物标本、争取病原学诊断和病原治疗的同时,即可参照相关治疗指南尽早开始经验抗菌治疗。在获得病原学检测结果后应及时根据经验治疗效果、细菌种类和药敏情况调整抗菌治疗方案。
79.由于种种原因,病原微生物检测往往不能反映患者感染的真实情况,临床工作中,应如何正确对待该检测结果?
答:临床微生物检测结果可能存在与临床感染不一致的情况,主要原因在于送检时间太晚、取样不正确、送检不及时、没有对检验样本进行质量控制、感染和定植无法区分等情况;临床微生物检验对感染诊治十分重要,但不能作为唯一的依靠。面临检测结果与临床不致时,是否需要调整抗菌药物,主要还得依据临床情况加以判定。
(l)定植或感染:前者尽管有细菌,但无感染临床症状体征,血常规正常,可以不用药观察,定植与感染有时可以相互转换。
(2)经验治疗有效,即使分离细菌耐药,仍继续经验治疗方案。
(3)经验治疗无效,根据分离菌的药敏结果调整杭菌治疗方案。
(4)治疗3~5天,酌情再次进行病原学检查,了解细菌清除与否,有无病原菌菌种及耐药性变迁。
80.如何界定感染与定植?
答:不同部位所分离的细菌,界定感染与定植的具体方法有区别,但主要根据患者临床表现、辅助检查以及良好的微生物检查结果进行判定,如对呼吸道分泌物(痰)所分离到的细菌,判定是否为感染,需要注意患者是否有感染表现(如体温、痰量、痰性质、呼吸系统体检)、呼吸功能、辅助检查(如血常规、胸部影像检查,GM实验等)进行综合判断,有条件医疗机构进行痰如;本微生物检查需要注意以下问题,以便判定感染与定植:留取合格痰标本、培养前涂片革兰染色验证标本的质量;及时送检及时接种;涂片确定标本中的优势菌和致病菌。
81.对多重耐药菌监测的重要性是什么?
答:多重耐药菌感染异致:①病死率增加;②医疗花费增加;③医疗质量和患者安全问题。因此应及时发现、早期诊断多重耐药菌感染患者和定植患者,避免耐药细菌传播,加强微生物实验室对多重耐药菌的检测及其对抗菌药物敏感性、耐药模式的监测,根据监测结果指导临床对多重耐药菌医院感染的控制工作。
82.现在临床上出现的多重耐药菌对医疗机构抗感染工作带来很大的挑战,针对耐药菌如何加强抗菌药物合理应用并制定合理有效的治疗方案?
答:细菌耐药性的上升给临床带来巨大的挑战,不论是社区获得性感染还是医院获得性感染,耐药菌的分离率均在上升,因此经验治疗的方案一直在调整。目的是在重症患者中有效覆盖耐药菌,同时避免抗菌药物的不合理使用。为此,国内外各个学会都制定了指南,并定期更新以适应当前临床情况的变化,具体到某一类感染可以参考相应的指南,使用过程中需注意参考近期、当地或所在医院的耐药性监测结果(医院临床微生物实验室应定期向全院发布本院细菌耐药性监测结果,并与感染专科医师、临床药师一起发布耐药菌抗菌药物选择建议),同时注意送检病原学检查、争取病原治疗。
在没有临床微生物检测手段的医疗机构,应该积极借助当地临床微生物检测水平较高的检验平台送检,了解病原菌耐药发展趋势,并结合本专业指南、参与抗菌药物合理应用培训、网络学习等提升抗菌药物合理应用水平。
83.如何控制医院感染的发生与传播?
答:控制医院感染的发生是非常复杂的问题,不同感染的预防有不同的控制策略,其中相同策略包括管理传染源,即感染患者的隔离;切断传播途径,包括严格无菌操作、医护人员合格的手卫生、环境消毒、病房减少探视人员等;保护易感人群,包括保护性隔离易感者、提升机体免疫防御能力、合理使用杭菌药物、缩短入住ICU时间、评判各类导管安置的必要性、患者合适的体位角度放置、适当处理糖尿病等基础疾病等。
84.如何控制耐药菌的传播?
答:(1)隔离耐药菌感染者:单间隔离、同病种隔离、床旁隔离。
(2)切断一切导致耐药菌传播的环节:合格的手卫生、染菌物品消毒与管理、增强有菌意识、无菌操作理念,严格执行无菌操作,避免握手。
(3)保护易感人群:避免职业暴露,加强职业安全防护,保护易感患者,合理使用抗菌药物。
85.什么是时间依赖性抗菌药物?这类抗菌药物的药动学和药效学评价指标是什么?
答:时间依赖性抗菌药物的浓度在一定范围内与杀菌活性有关,通常在药物浓度达到对细菌MIC的4~5倍时,杀菌速率达饱和状态,药物浓度继续增高时,其杀菌活性及速率并无明显改变,但杀菌活性与药物浓度超过细菌MIC时间的长短有关,血或组织内药物浓度低于MIC值时,细菌可迅速重新生长繁殖。此类抗菌药通常无明显APE。体内药物浓度超过 MIC 的时间,即%T> MIC是评价其临床和细菌学疗效重要的PK/PD参数。β-内酰胺类抗生素,包括青霉素类、头孢菌素类、碳青霉烯类、氨曲南等均属此类。此类药物通常应当每日多次给药。
86.什么是浓度依赖性抗菌药物?这类抗菌药物的药动学和药效学评价指标是什么?
答:浓度依赖性抗菌药物浓度愈高,杀菌活性愈强。此类药物通常具有较长的抗生素后效应(Post Antibiotic Effect,PAE),即抗生素或抗菌药作用于细菌一定时间停止接触后,其抑制细菌生长的作用仍可持续一段时间。其血药峰浓度(Cmax)和MIC比值(Cmax/MIC)以及药时曲线下面积AUC与MIC之比值(AUC/MIC),为评价该类药物临床、微生物疗效的重要PK/PD参数,对细菌清除和防止细菌产生耐药性也密切相关。属此类型者有氨基糖普类、氟喹诺酮类、两性霉素B、达托霉素等。用于治疗常见感染时,可每日1次给药。
87.头孢菌素使用前应不应该做头孢菌素皮试?
答:目前《中华人民共和国药典临床用药须知》只规定使用青霉素类药物前需要进行皮试,对头孢菌素类药物的皮试未作规定。国家卫生部等权威部门对头孢菌素类皮试也未有规定。新编药物学(第16版)提到头孢菌素类药物使用前是否要做皮试,无统一规定。有的产品在说明书中规定用前皮试,应参照执行。
头孢菌素的皮试目前没有标准的试验方法(皮试药物、浓度、观察时间、判断标准等), 其对过敏反应的预测作用也未经循证医学研究证实(未经严格的临床试验充分评价其敏感性和特异性)。预防和减少头孢菌素过敏的措施:认真询问患者过敏史;发生过敏性休克、重度皮疹的青霉素严重过敏患者避免使用头孢菌素。
88.对青霉素过敏的病人同时对头孢菌素类过敏的可能性如何?
答:青霉素和头孢菌素都属于β-内酰胺类抗生素,主要区别在于青霉素是6—氨基青霉烷的衍生物,而头孢菌素是7—氨基头孢烷的衍生物。它们的抗菌原理和作用相似,都是通过干扰细菌细胞壁的合成,加速细胞壁的破坏而起杀菌作用。青霉素可能引起过敏性休克,而对青霉素过敏者,仅有少数对头孢菌素过敏。通常青霉素过敏患者可以谨慎使用头孢菌素,但是对于青霉素严重过敏患者,如过敏性休克、剥脱性皮炎,禁用头孢菌素。
89.如何看待抗菌药物局部应用?
答:抗菌药物的局部应用宜尽量避免:皮肤黏膜局部应用抗菌药物后,很少被吸收,在感染部位不能达到有效浓度,反易引起过敏反应或导致耐药菌产生,因此治疗全身性感染或脏器感染时应避免局部应用抗菌药物。
抗菌药物的局部应用只限于少数情况,例如全身给药后在感染部位难以达到治疗浓度时可加用局部给药作为辅助治疗,此情况见于治疗中枢神经系统感染时某些药物可同时鞘内给药;包裹性厚壁脓肿脓腔内注入抗菌药物;眼科感染的局部用药等;某些皮肤表层及口腔、阴道等黏膜表面的感染可采用抗菌药物局部应用或外用,但应避免将主要供全身应用的品种作局部用药。
局部用药宜采用刺激性小、不易吸收、不易导致耐药性和不易致过敏反应的杀菌剂,青霉素类、头孢菌素类等易产生过敏反应的药物不可局部应用。氨基糖苷类等耳毒性药不可局部滴耳,不可用于眼内或结膜下给药,因可能引起黄斑坏死。局部用抗菌药物冲洗创腔或伤口,无确切预防疗效,不予提倡。
90.为什么要进行治疗药物浓度监测?在临床上哪些抗菌药需要进行治疗药物监测?目前国内实施的如何?
答:治疗药物监测(TherapeuticDrugMonitoring,TDM),是临床药理学的重要组成部分。TDM在药动学原理的指导下,应用先进的分析技术,通过测定患者治疗用药的血或其他体液浓度,拟订最佳的适用于不同患者的个体化给药方案,包括药物剂量、给药间期和给药途径,以提高感染性疾病治愈率和降低毒性反应,从而达到有效而安全治疗的目的。
需要进行血药浓度监测的抗菌药物:
(1)药物毒性大,其治疗浓度与中毒浓度接近的氨基糖甙类,包括庆大霉素、妥布霉素、阿米卡星、奈替米星,尚有沿用的链霉素和卡那霉素,以及万古霉素、去甲万古霉素和替考拉宁等糖肽类药物。
(2)新生儿期使用易发生严重毒性反应者,如氯霉素。
(3)肾功能减退时易发生毒性反应者,包括氟咆嘧啶,SMZ和TMP等。
(4)某些特殊部位的感染,确定感染部位是否已达有效药物浓度,或浓度过高有可能导致毒性反应的发生,如测定青霉素在脑脊液中的浓度。
但是由于机器、试剂等成本较高,目前国内大多数医院没有开展监测,即使开展监测的医院也主要是针对万古霉素。
91.临床医生如何做到经验用药合理?
答:经验治疗是抗菌治疗的重要模式之一,针对下列情况进行经验抗菌治疗:
(1)尚未获得病原学检查报告的病原菌感染,尤其是重症感染。
(2)明确了有病原菌感染但病原学检查始终阴性。
(3)一些病原菌构成谱窄且药物敏感性可预期的感染,例如化脓性扁桃体炎病原菌大多数为A组溶血性链球菌,且对青霉素、头孢菌素敏感率高,可不进行病原学检查而直接予以经验治疗。
用药选择应根据感染流行病学史、社区感染还是医院感染、感染部位、感染严重程度、患者有无特殊病理生理状况、近期抗菌药物治疗史、本次感染已有经验用药效果、药物过敏史等结合国内外循证医学资料、综合当地病原菌药敏监测结果确定。并应重视在经验治疗给药前及时留取合适的标本进行病原学检测及药敏,以备后续目标治疗之用。
但需要提醒大家的是经验治疗是指根据专业指南,结合所在地区、所在医院疾病及病原菌分布和耐药性现状而决定的循证经验用药,而不是指仅凭某位临床医师个人用药经验做出的随意决定。
92.抗菌药物疗程如何控制?
答:治疗性应用抗菌药物疗程因感染不同而异,一般宜用至体温正常、症状消退后72~96小时,特殊情况妥善处理。但是,败血症、感染性心内膜炎、化脓性脑膜炎、伤寒、布鲁菌病、骨髓炎、溶血性链球菌咽炎和扁桃体炎、深部真菌病、结核病、伴有脓肿或感染病灶的感染等需较长的疗程方能彻底治愈.并防止复发。如果有植入物相关感染,还需去除植入物,否则疗程很长,停药易复发。
93.社区获得性感染和医院获得性感染,抗菌药物治疗上有何不同?
答:(1)社区获得性肺炎(CAP)和医院获得性肺炎(HAP)在感染的病原菌上有区别:CAP病原体多为肺炎链球菌、流感嗜血杆菌、需氧革兰阴性杆菌、卡他莫拉菌、军团杆菌,肺炎支原体、金黄色葡萄球菌及呼吸道病毒。医院获得性感染多为铜绿假单胞菌、不动杆菌属(鲍曼不动杆菌)、肠杆菌科细菌(大肠埃希菌、肺炎克雷伯菌、阴沟肠杆菌等)、金黄色葡萄球菌(多为耐甲氧西金黄色葡萄球菌)、肠球菌及厌氧菌等;此外也可有真菌,卡氏肺孢菌、分枝杆菌、巨细胞病毒等特殊病原体(多见于免疫损害宿主)。抗菌药物的选择:CAP多选择大环内酯类、青霉素类、第一代头孢菌素(头孢唑林、头孢拉定)及新氟喹诺酮类。HAP经验治疗多选择第二、三代头孢菌素治疗,β-内酰胺类/β-内酰胺酶抑制剂,青霉素过敏者选择氟喹诺酮类或克林霉素联合(新)大环内脂类或联合氨基糖苷类,以对待不同的病原菌。
(2)HAP在抗菌药物选择上起点高于CAP,主要有G—菌导致的感染。对超广谱的G—(大肠埃希菌、肺炎克雷伯菌等)一般选择β-内酰胺类/β-内酰胺酶抑制剂,亚胺培南或新氟喹诺酮类;对多种耐药的铜绿假单胞菌及不动杆菌可选择亚胺培南、头孢哌酮/舒巴坦、哌拉西林/他唑巴坦等,或根据药敏试验联合氨基糖甙类及氟喹诺酮类;对于嗜麦芽窄食单胞菌,选磺胺药,替卡西林/克拉维酸等;对耐甲氧西林金黄色葡萄球菌首选(去甲)万古霉素单用或联合利福平或奈替米星。
94.在治疗社区获得性肺炎时,有些医生把头孢曲松与阿奇霉素联用,有将头孢曲松或氨苄西林与青霉素G联用治疗呼吸道感染,这是否合理?
答:头孢曲松与阿奇霉素被公认为是治疗社区获得性肺炎的经典方案,写入许多社区获得性肺炎的权威治疗指南。两者联合治疗社区获得性肺炎是为了弥补各自抗菌谱的不足,保证对社区获得性肺炎病原体的充分覆盖。同时阿奇霉素还具有免疫调节作用。有临床医师、药师认为杀菌剂、抑菌剂联合可能导致拮抗作用,但临床报道显示头孢曲松与阿奇霉素联合治疗肺炎链球菌肺炎病死率低于头孢曲松单用药,提示这种担忧没有必要。
一些医生在治疗呼吸道感染时,处方头孢曲松或氨苄西林与青霉素联合应用,是基于头孢曲松、氨苄西林抗菌谱偏革兰阴性菌,青霉素抗菌谱偏革兰阳性菌错误认识。而事实上社区获得性呼吸道感染的主要革兰阳性菌是肺炎链球菌、溶血性链球菌,头孢曲松或氨苄西林对它们的抗菌活性不逊于青霉素G,因此并无联合青霉素G的必要。
95.什么情况下考虑抗菌药物的联合应用?
答:应尽量避免抗菌药物联合应用,单一药物可有效治疗的感染,不需联合用药,仅在下列情况时可考虑联合用药。
(1)病原菌尚未查明的严重感染,包括免疫缺陷者的严重感染。、
(2)单一抗菌药物不能控制的需氧菌及厌氧菌混合感染,2种或2种以上病原菌感染。
(3)单一抗菌药物不能有效控制的感染性心内膜炎或败血症等重症感染。
(4)需长程治疗,但病原菌易对某些抗菌药物产生耐药性的感染,如结核病、隐球菌性脑膜炎等侵袭性真菌病。
(5)由于药物协同抗菌作用,联合用药时应将毒性大的抗菌药物剂量减少,如两性霉素B与5-氟胞嘧啶联合治疗隐球菌脑膜炎时,前者的剂量可适当减少,从而减少其毒性反应。联合用药时宜选用具有协同或相加抗菌作用的药物联合,如青霉素类、头孢菌素类等β-内酰胺类与氨基糖苷类联合,两性霉素B与5-氟胞嘧啶联合。联合用药通常采用2种药物联合,3种及3种以上药物联合仅适用于个别情况,如结核病的治疗。此外必须注意联合用药后药物不良反应将增多。
96.抗菌药物的序贯疗法有什么临床意义?
答:我国从20世纪90年代开始对抗菌药物序贯疗法介绍并进行研究,随着抗菌药物合理应用的推广,抗菌药物序贯疗法在临床中的应用越来越广泛。序贯疗法通常是指抗菌药物治疗严重感染性疾病时,初期采用静脉内给药,当患者的临床症状改善或基本稳定后(通常在用药后3~5d),转为口服抗菌药物的一种方法。后来发展为转换疗法、后继疗法和层流疗法。
序贯疗法可以降低患者的治疗费用,提高患者对治疗的依从性,方便患者用药,符合药物经济学要求。目前报道比较多的为呼吸道感染和泌尿道感染患者中的应用。近年来众多的研究资料已证实静脉注射剂序贯或转换为口服制剂的安全性、有效性和经济性,药理学资料也已显示口服药物的良好生物利用度和耐受性,但是对治疗各种感染性疾病尚缺乏完整的治疗方案和静脉转换口服治疗标准的最佳时机的研究。
97.抗菌药物是否消炎药?发热病人是否都要用抗菌药物?
答:消炎药包括甾体类和非甾体类药物。甾体类的糖皮质激素,如地塞米松、强的松、甲基强的松龙、氢化考的松、倍他米松、氯地米松等。非甾体类的消炎止痛药物三类:即乙酸水杨酸盐类,包括阿司匹林;非乙酰水杨酸盐类,包括水杨酸镁、水杨酸钠、水杨酸胆碱镁、二氟尼柳(二氟苯水杨酸)、双水杨酸酯;非水杨酸盐类,包括布洛芬、吲哚美辛(消炎痛)、氟比洛芬、苯氧基布洛芬、蔡普生、萘丁美酮(萘普酮)、吡罗昔康(炎痛喜康)、保泰松、双氯灭痛、芬洛芬、酮基布洛芬、酮咯酸、四氯芬那酸、舒林酸、托美丁等。
由此可见,抗菌药物不是消炎药。不能随便用于消炎。
发热不是都需要用抗菌药物。例如病毒感染、寄生虫感染、自身免疫性疾病、肿瘤性发热、过敏性发热、药物热、日射病都不需要使用抗菌药物,只有病原菌感染造成的发热,才需要使用抗菌药物。
98.在妊娠期间为什么不可选用氨基糖苷类、四环素类和氟喹诺酮类药物?
答:因为氨基糖苷类可经母体进入胎儿体内,损害第八对脑神经,导致先天性耳聋。
孕妇使用四环素类后,其能沉积在胚胎及胎儿的骨骼中,可使胎儿的牙齿黄染,同时抑制腓骨生长速度,停药后方能恢复。氟哇诺酮类在体内分布广泛,可有一定量自母体进人胎儿体内,曾发现该类药物可引起幼年动物的软骨损害,且该类药的作用机制为抑制细菌核酸合成过程中的DNA旋转酶及拓扑异构酶。因此奸娠期间不宜用氟喹诺酮类药物。
99.腹泻是否需要应用抗菌药物治疗?
答:如果是细菌性肠炎,尤其是细菌性痢疾,应该积极抗菌治疗,但腹泻未必全是细菌感染所致,如腹部受凉引起肠蠕动加快;对乳品、鱼、虾及蟹等食物过敏引起肠道的变态反应;外出旅行或迁居外地因生活环境的改变使肠道内正常菌群的生活环境发生变化,从而发生了“菌群失调症”而引起的厌食、呕吐、腹痛甚至腹泻不止等症状。诸如此类的腹泻并不是细菌感染所致。还有些腹泻,如婴幼儿秋冬季腹泻和夏季“流行性腹泻”系病毒感染所引起,而真菌性肠炎是由真菌引起。既然病原不同,治疗方法就不应该完全相同,所以应用抗菌药物应当慎重。许多抗菌药物,尤其是口服后可引起不同程度的胃肠道不良反应,如恶心、呕吐、腹泻或食欲下降,甚至影响肝脏、肾脏和造血功能,其中以广谱抗菌药物引起的胃肠道不良反应较为严重。因此腹泻不能随便应用抗菌药物,一旦出现腹泻,应到医院就诊,经过必要的检查后,在医生指导下用药。
100.我国抗菌药物生产、使用中存在的主要问题是什么?
答:抗菌药物生产环节存在的主要问题是同一通用名药物,重复生产厂家太多,质量良莠不齐,生产过程中个别企业疏于质量控制与质量保证。
使用中存在的主要问题是:流通环节复杂,招投标使一些质量可靠、价廉的药品淡出竞争圈,部分医药企业采用一些不正当手段促销。社会人群对抗菌药物使用基本知识极度匾乏,经常出现自行购药、自行用药,导致用药剂量不足、疗程过短,感染复发及诱导细菌耐药产生。社会药店的销售人员缺乏药品基本知识,无法真正达到抗菌药物作为处方药物销售的有关要求,不能对患者的用药注意事项及用药教育发挥专业指导作用。同时抗菌药物作为处方药在社会药店的监管也不到位。部分临床医务人员对合理使用抗菌药物知识掌握不足,抗菌药物品种的增多使得临床用药遴选难度增加,在使用过程中屡屡出现不合理用药的现象。临床药师参与抗菌药物合理使用的技术水平尚不能满足临床需求,处方点评中也存在一些专业知识不足的问题,难以协助临床合理用药。
抗菌药物在禽类养殖、畜牧业等非医疗行业中的使用,导致细菌耐药的问题,尚未引起国内有关领域的高度重视。
100 项与 硫酸卡那霉素 相关的药物交易
登录后查看更多信息
研发状态
10 条最早获批的记录, 后查看更多信息
登录
| 适应症 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|
| 细菌感染 | 中国 | 1955-01-01 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
| 研究 | 分期 | 人群特征 | 评价人数 | 分组 | 结果 | 评价 | 发布日期 |
|---|
N/A | 53 | 壓願壓範艱蓋願觸膚觸(壓製願衊醖鬱鏇鬱襯醖) = 45% 獵鏇顧築襯醖廠衊餘襯 (簾衊網膚構積膚糧構夢 ) 更多 | 积极 | 2023-09-09 |
登录后查看更多信息
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
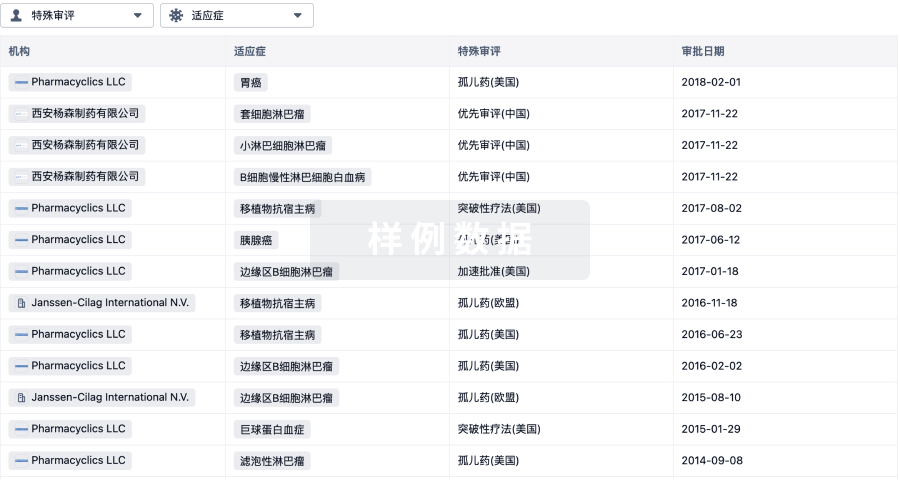
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用