预约演示
更新于:2026-05-12
SKB-518
更新于:2026-05-12
概要
基本信息
原研机构 |
在研机构 |
非在研机构- |
权益机构- |
最高研发阶段临床2期 |
首次获批日期- |
最高研发阶段(中国)临床2期 |
特殊审评- |
登录后查看时间轴
结构/序列
使用我们的ADC技术数据为新药研发加速。
登录
或

关联
5
项与 SKB-518 相关的临床试验NCT07448922
An Open-label, Multicenter, Phase II Clinical Study to Evaluate the Efficacy and Safety of SKB518 as Monotherapy or Combination Therapy in Patients With Advanced Gynecological Malignancies
This is an open-label, multicenter, Phase II clinical study to evaluate the efficacy and safety of SKB518 as monotherapy or combination therapy in patients with advanced gynecological malignancies.
This study will include 5 cohorts: SKB518 as monotherapy in advanced ovarian cancer; SKB518 as monotherapy in advanced cervical cancer and endometrial cancer; SKB518 in combination with Carboplatin in advanced ovarian cancer; SKB518 in combination with Carboplatin and Bevacizumab in advanced ovarian cancer; and SKB518 in combination with Bevacizumab in advanced ovarian cancer.
Study hypothesis: SKB518 will show meaningful clinical activity and a favorable risk benefit profile in gynecological malignancies.
This study will include 5 cohorts: SKB518 as monotherapy in advanced ovarian cancer; SKB518 as monotherapy in advanced cervical cancer and endometrial cancer; SKB518 in combination with Carboplatin in advanced ovarian cancer; SKB518 in combination with Carboplatin and Bevacizumab in advanced ovarian cancer; and SKB518 in combination with Bevacizumab in advanced ovarian cancer.
Study hypothesis: SKB518 will show meaningful clinical activity and a favorable risk benefit profile in gynecological malignancies.
开始日期2026-04-08 |
申办/合作机构 |
NCT07019675
A Phase II, Multicenter, Open-label Study to Evaluate the Efficacy and Safety of SKB518 in Patients With Lung Cancer
This is an open-label, multicenter, phase II study. The purpose of this study is to evaluate the safety, tolerability and preliminary anti-tumor activity of SKB518 in patients with lung cancer. Eligible subjects will receive SKB518 monotherapy, until radiographic disease progression, intolerable toxicity, discontinuation of study treatment required by the subject, or other protocol-specified treatment discontinuation criteria, whichever occurs first.
开始日期2025-08-29 |
申办/合作机构 |
NCT06428331
A Phase 1, Multicenter, Open-label First-In-Human Study to Evaluate the Safety, Tolerability, Pharmacokinetics and Antitumor Activity of SKB518 in Subjects With Advanced Solid Tumors
This is a first-in-human (FIH), phase 1, multicenter, open-label, dose-escalation study of SKB518 to evaluate the safety, tolerability, PK, immunogenicity, and antitumor activity in adult subjects with advanced or metastatic solid tumor relapsed/refractory to standard therapies or for which no effective standard therapy is available.
开始日期2024-07-04 |
申办/合作机构 |
100 项与 SKB-518 相关的临床结果
登录后查看更多信息
100 项与 SKB-518 相关的转化医学
登录后查看更多信息
100 项与 SKB-518 相关的专利(医药)
登录后查看更多信息
51
项与 SKB-518 相关的新闻(医药)2026-05-07
·今日头条
恒瑞医药一直是A股创新药的“代言人”。2025年营收突破316亿、净利大增21.69%的财报,加上狂砍超10种差异化ADC分子、25项即将披露的III期数据,这份成绩单确实配得上龙头地位。但事实是,从去年高点算起,恒瑞股价已经盘整了不短的时间,H股市值维持在4300亿港元左右,对于许多冲着高赔率来的投资者来说,涨10个点的难度和一只腰部Biotech涨50%的难度,已经完全不是一个量级。
钱往阻力最小的方向流。当市场的聚光灯过度集中在恒瑞身上时,很多细分赛道的“隐形冠军”正在闷声发大财,它们手里的管线深度和市场预期差,可能才是2026年创新药投资真正的硬核底牌。
信达生物:真正兑现COMBO策略的“六边形战士”
为什么要把它放在第一家?因为它是极少数在A股和港股同时具备了“大药企规模化效应”和“Biotech爆发力”的独特存在。
2026年一季报,信达产品收入直接拿下超38亿元的实绩,同比劲增50%以上。这背后不是靠讲故事,而是实打实的“联合作战”能力:五款TKI新药进医保后快速放量,加上玛仕度肽(减肥降糖)、替妥尤单抗等综合产品线的爆发,让它去年产品收入首次突破百亿大关,达到118.96亿元。
更关键的是,信达正在一步步兑现“IO+ADC”的联用策略。管线里的IBI363(PD-1/IL-2双抗)是全球首创设计,已经借免疫耐药非小细胞肺癌的成熟数据直接推进全球多中心关键注册临床;IBI343(CLDN18.2 ADC)也在齐头并进。这三项核心资产对应的潜在市场规模合计超过600亿美元。
早年有人说信达“杂而不精”,现在看,这种多领域的布局恰恰给了它穿越周期的底气。2025年直接扭亏盈利8.14亿元,这是一家“造血能力”被验证过的公司。
康方生物:不卷靶点,卷核弹级临床数据的双抗龙头
如果说这两年的关键词是“出海”,那康方绝对是被动接受国际检验的典型。
核心产品依沃西单抗(Ivonescimab),是目前全球唯一正式向FDA递交上市申请、进入审评阶段的中国原创双抗新药。合作伙伴Summit Therapeutics在全球主导了5项国际多中心III期临床,而更狠的是,今年ASCO年会上,依沃西的HARMONi-6研究总生存期(OS)数据直接被选入全体会议(Plenary Session)的最新突破摘要(LBA)。
全体会议是什么概念?那是全球肿瘤领域最具含金量的展示舞台。EGFR-TKI耐药突变非小细胞肺癌这类高难度适应症,一旦数据最终读优,这就是药物直接写入全球一线治疗指南的逻辑。
除了头对头硬刚,康方在后线的布局已经跳出了“卷靶点”的内耗。全球首个进入临床的ILT2/ILT4/CSF1R三抗(AK150),瞄准的是极具挑战的肿瘤相关巨噬细胞(TAM)重编程,要在先天免疫领域开辟新战场。而IL-4Rα/ST2双抗(AK139)同时针对自身免疫和呼吸系统疾病,一口气启动7项II期临床,这个速度和视野,放在全球坐标里也毫不逊色。
科伦博泰:默沙东选中的ADC“执棋人”
如果说有些公司的价值还停留在PPT上,那科伦博泰的价值是默沙东用真金白银在全球布下的棋子。
科伦博泰的核心王牌芦康沙妥珠单抗(sac-TMT),目前已在国内斩获4项适应症并纳入医保,同时还在推进5项注册三期临床。更值得期待的是,合作伙伴默沙东围绕芦康沙妥珠单抗一口气启动了17项全球三期临床,覆盖肺癌、乳腺癌等多个大癌种。2026年,一线PD-L1阳性非小细胞肺癌的关键三期数据将在ASCO读出,这个催化分量决定了它是否能在全球市场撕下一大块肉。
2025年公司确实受了医保调价的一次性影响,商业化产品销售收入5.4亿,低于此前预期,亏损也扩大到了3.8亿元。但很多人没看到,这恰恰是主动压价、以量换市场的战略选择。商业化团队已经在半年内狂扩至600多人、覆盖超1200家医院,管理层更将有医保加持后的2026年销售目标直接定在了翻倍以上,医保适应症收入占比将超过80%。更不必说早期管线的宽度:CLDN18.2 ADC、Nectin-4 ADC,乃至SKB518这类潜在“同类首创”ADC都已经迈入II期临床。
默沙东的“药王”K药迟早面临专利断崖,而科伦博泰的ADC管线,就是默沙东续命的备选王牌。
荣昌生物:技术全自研,出海授权拿到56亿美元的狠角色
荣昌生物给人的印象是基础扎实,但一度被市场怀疑商业化不够快。但2026年一季报出来后,这份怀疑被打消了大半:单季度营收6.56亿,同比增长24.76%,直接扭转去年同期亏损,实现净利润3.28亿。更健康的是,经营性现金流已转正至0.11亿元,算是在不依赖BD款项的情况下完成了初步的自我造血。
真正的重磅炸弹是RC148(PD-1/VEGF双抗)。2026年1月,艾伯维以高达56亿美元的总授权协议把这颗棋子握在手里,荣昌已收到6.5亿美元首付款且确认入账。艾伯维不是普通买手,它在自免和肿瘤领域有绝对的市场支配力,RC148在二线胃癌和非小细胞肺癌中展现出的ORR(胃癌优效于PD-1单抗、IO耐药人群高达66.7%),让它具备了直接冲击一线疗法的资质。
而且,荣昌的布局也很独特:泰它西普(TACI-Fc融合蛋白)另辟蹊径,把核心发力点锁定在全球范围极度缺药的干燥综合征、IgA肾病等慢性自免领域;维迪西妥单抗作为老牌国产ADC,还在不断拓展一线尿路上皮癌、胃癌等大适应症,甚至开始探索双抗ADC这种前沿技术形态。这种“肿瘤+自免”的双轮架构,抗风险能力极强。
总结
恒瑞当然值得关注,只是性价比的问题。信达胜在商业化规模,康方妙在临床数据,科伦博泰背靠默沙东的全球渠道,荣昌狠在BD授权的能力和自免赛道的独占性。这四家隐形冠军正处在不同的成长拐点上。当然,关于靶点数据的具体进度都有非确定性风险,不做买入建议,但必须说一点:未来几年创新药结构性行情里,光盯着“大白马”可能真的跑不赢这些各自领域的“小巨人”。
声明:本文内容基于公开信息和行业研究整理,仅供探讨交流。文中涉及个股均为案例分析,不构成任何实质性投资建议。创新药研发具有高度不确定性,股市有风险,投资需谨慎。
2026-04-29
本
文
目
录
1、The Innovation | 药物发现背后的故事:引领者、前沿技术与重磅药物
2、IF>100综述-药物发现中的天然产物:进展和机遇
3、GNN药物发现全景图:进展、模型与挑战一览
4、全球药物靶点发现、挖掘与探索:方法、技术及中外创新实例深度解析
5、【J.Med.Chem.】计算驱动苗头化合物发现:工业界视角下药物发现的技术变革与挑战
一、The Innovation | 药物发现背后的故事:引领者、前沿技术与重磅药物
(原创 B Yu,P Zhan Thelnnovation创新)
探索药物发现的台前幕后,领略大师风采、前沿技术与重磅新药的诞生故事。
导 读
《Drug Discovery Stories (volume 2)》(ISBN:9780443338854)是郑州大学余斌教授和山东大学展鹏教授共同主编,联合国内外众多高校、科研机构和制药企业新药研发人员联合编写的英文学术专著。由Elsevier出版社出版发行,全书共计47章,包含四大主题:药物研发历史人物、药物早期研发的重要性、前沿技术,以及重磅药物。该系列丛书已公开发行2卷,由常俊标院士、陈芬儿院士和密歇根大学王少萌教授作序推荐,回顾了过去几年药物研发领域的重大突破,讨论了前沿技术如何改变未来生物医药领域的格局,让读者窥见药物诞生的幕后故事。
图1 图文摘要
该书主要包括以下三个方面的内容:
每一款上市药物的背后,都有默默耕耘的科学家。该书第一章由比利时鲁汶大学Erik De Clercq撰写,特别提到了Piet De Somer教授(1917年12月22日 - 1985年6月17日)。Piet De Somer教授是比利时药物研究的奠基人之一,他在青霉素生产和脊髓灰质炎疫苗开发中做出了重大贡献,同时于1954年创立了比利时鲁汶大学的Rega研究所,为抗病毒研究搭建了重要平台,推动了现代抗病毒疗法的发展,比如治疗艾滋病和肝炎的药物。
药物从实验室走向临床,早期研发是关键的第一步。这包括从初步筛选到优化候选化合物,再到安全性测试等一系列复杂流程。Eckhard von Keutz博士认为,新技术(如计算科学)和不断更新的监管要求,正在让药物早期预测更精准。这意味着科学家能在研发初期就发现问题,避免后期高昂的失败成本。比如,通过模拟药物在人体内的表现,研究人员可以更快锁定有潜力的候选药物。
人工智能(AI)正在变革创新药物发现。意大利那不勒斯费德里科二世大学Antonio Lavecchia教授详细讲解了AI如何在药物研发的各个阶段发挥关键作用:从识别疾病靶点,到设计新分子,再到优化候选药物,AI都能大幅提升效率。比如,AI可以分析海量数据,预测哪些化合物可能有效,省去大量试错时间。当然,AI也并非无所不能,它也面临着数据质量参差不齐、模型透明度欠缺等挑战。如何让AI更好地融入现有药物研发流程,仍是科学家努力的方向。
此外,这本书还盘点了多个疾病领域的明星药物和潜力候选药物。肿瘤学领域:靶向疗法正带来新希望,像olverembatinib、repotrectinib等新一代靶向药物为癌症患者提供了更精准的治疗方案。此外,JPH-203、STX-478等临床候选药物也展现出对特定癌症治疗的巨大潜力。传染病领域:Azvudine、ensitrelvir等药物在COVID-19治疗中崭露头角,而比利时鲁汶大学Erik De Clercq教授回顾的抗病毒药物研发历史让我们看到了人类与病毒斗争的漫长历程。此外,针对抗菌素耐药性的新药,如enmetazobactam,研发进程正在加速。代谢紊乱领域:GLP-1受体激动剂,如司美格鲁肽的出现,彻底改变了糖尿病和肥胖症治疗格局,而resmetirom作为首个获批的非酒精性脂肪性肝炎药物也填补了领域空白,为患者提供了新的治疗选择。神经系统疾病领域:Omaveloxolone、roflumilast等药物为阿尔茨海默病等疾病的治疗提供了新思路,gepirone和fingolimod则分别在抑郁症和多发性硬化症领域带来了创新治疗选择。其他领域:书中还介绍了其他领域的重磅药物,Fexinidazole改变了非洲锥虫病的治疗方式,而fezolinetant则为更年期女性提供了非激素选择等。这些药物不仅是科学成就,更是无数患者的生命之光。此外,一些正在临床实验中的“未来之星”,如iptacopan(肾病相关)和nerandomilast(肺纤维化)等,或将改变更多疾病的治疗格局。
总结与展望
AI等前沿技术的发展让药物发现更加高效,有望迎来更多新药的诞生。未来,个性化医疗和精准医疗将成为趋势,满足不同患者的需求。但挑战依然存在,唯有通过持续创新和技术进步,才能让 “新药梦”变为现实,为人类健康书写新篇章。
二、IF>100综述-药物发现中的天然产物:进展和机遇
(原创 天南地北 催化合药化)
天然产物及其结构类似物在历史上对药物治疗做出了重大贡献,尤其在癌症和传染病领域。然而,天然产物在药物发现中也面临挑战,例如筛选、分离、表征和优化方面的技术障碍,这导致制药行业从20世纪90年代起对其研究有所减少。近年来,多项技术和科学发展,包括改进的分析工具、基因组挖掘与工程策略以及微生物培养技术的进步,正在应对这些挑战并带来新机遇。因此,以天然产物作为药物先导化合物的兴趣正在复苏,尤其在应对抗微生物耐药性方面。本文总结了推动天然产物基药物发现的最新进展,重点介绍了部分应用,并探讨了关键机遇。
文章信息:Natural products in drug discovery: advances and opportunities [Nature Reviews Drug Discovery (IF 101.8) Pub Date: 2021-01-28, DOI: 10.1038/s41573-020-00114-z]
天然产物药物发现中传统生物活性导向分离步骤概述(紫色方框:流程步骤;红色方框:关键局限;绿色方框:目前解决方案)
先进分析技术赋能现代天然产物药物发现的应用
基因组挖掘天然产物及天然产物类似物
先进微生物培养方法在鉴定新天然产物
获取具有优异性能天然产物类似物的策略
三、GNN药物发现全景图:进展、模型与挑战一览
(原创 榴莲忘返2014 榴莲忘返 AIDD)
目录
bioSBM 模型将表观遗传数据融入随机区组模型,为预测染色质三维结构并理解其生化调控机制提供了新工具。
BioLab 通过整合多个专用基础模型和智能体,首次实现了从靶点发现到湿实验验证的端到端、全自主抗体设计,并成功优化了帕博利珠单抗。
图神经网络(GNN)正全面渗透从靶点发现到分子设计的药物研发各环节,但要真正落地,还需解决数据、模型和可解释性三大挑战。
1. bioSBM:用图模型连接表观遗传与 3D 基因组
做基因组三维结构研究的人,手里常有两套地图。一套是 Hi-C 数据,它告诉你基因组的「路网结构」,也就是哪些 DNA 片段在空间上靠得近。另一套是表观遗传数据,比如 ChIP-seq,它告诉你每条路上的「建筑类型」,比如哪里是活跃的启动子(商业区),哪里是沉默的异染色质(工业区)。我们一直都想知道,这两套地图之间到底有什么关系?为什么路网会这样连接不同的功能区?
现在,有研究者开发了一个叫 bioSBM 的新模型,试图回答这个问题。
这个模型的核心是随机区组模型 (Stochastic Block Model, SBM)。SBM 是网络科学里的一个经典工具,它的工作原理很简单:把网络里的节点(这里是基因组区域)根据它们的连接模式进行分组。比如,A 组的节点内部连接很紧密,但和 B 组的连接就很少。在基因组里,这就能帮我们找到像拓扑关联结构域 (Topologically Associating Domain, TAD) 这样的社群。
bioSBM 的巧妙之处在于,它不只看「谁和谁连接」这个路网信息。它还把第二套地图,也就是生化特征(比如组蛋白修饰),作为协变量加了进来。模型在判断两个基因组区域是否应该互动时,不仅考虑它们过去的互动频率,还会考虑它们的「身份」——它们是活跃的增强子,还是被抑制的区域?这就好比一个城市规划师,不仅看交通流量,还考虑地块的功能属性来规划路网。
模型还有一个关键特性,叫「混合成员」 (mixed memberships)。传统的分类方法很死板,一个基因组区域要么是 A 区(活跃),要么是 B 区(沉默)。但生物学现实复杂得多。一个基因可能在某些条件下活跃,在另一些条件下则保持沉默。bioSBM 允许一个基因组区域同时属于多个社群,比如 70% 的属性像「活跃转录区」,30% 的属性像「多梳蛋白抑制区」。这更接近真实情况。
为了验证模型,研究者把它用在了大家都很熟悉的 GM12878 细胞系上。结果很好。模型不仅识别出了传统的 A/B 区室,还发现了 7 个更精细的生物学社群,这些社群的功能注释(比如与 CTCF 结合位点、增强子等的关系)都非常清晰。这就像是从一张黑白地图升级到了一张彩色的功能分区图。
最厉害的是它的预测能力。研究者用一部分染色体的数据训练模型,然后让它去预测一个它从未见过的染色体的 Hi-C 互作图谱,结果相当准确。他们还做了个更具挑战性的实验:用一个细胞系的数据去预测另一个完全不同的细胞系(HCT116),并且这个细胞系里的一个关键结构蛋白 RAD21 还被敲低了。即便如此,bioSBM 依然表现稳健。
这说明 bioSBM 不只是在「拟合」数据,它确确实实学到了一些连接表观遗传和三维结构的底层规则。理解这些规则对于药物研发意义重大。如果我们能准确预测某个表观遗传修饰的改变会如何影响三维结构,进而如何影响一个癌基因的表达,那我们就能更精准地设计靶向表观遗传的药物。这个模型为我们提供了一个强大的、可解释的计算工具,让我们朝这个方向迈出了一步。
📜Paper: https://arxiv.org/abs/2409.14425v2
2. BioLab:AI 智能体系统实现端到端药物研发
AI 设计的抗体,在实验中表现比默沙东的 Keytruda® (帕博利珠单抗) 还要好。
这听起来很科幻,但来自 BioLab 团队刚刚发布的预印本,把这件事变成了现实。作为一名研发科学家,我看到这种能将计算设计与湿实验验证完美闭环的工作,总是会格外兴奋。
这背后不是一个简单的大语言模型(Large Language Model, LLM)。BioLab 的架构更像一个高效的研究小组。系统里有八个各司其职的 AI 智能体(Agent)。比如,有一个「PI」角色的规划智能体(Planner)负责制定整体研究计划;有像「博士后」一样的推理智能体(Reasoner)来执行具体任务;甚至还有一个「审稿人」角色的批判智能体(Critic)来评估和修正结果。它们通过一个记忆智能体(Memory Agent)来共享信息、迭代优化,整个过程井井有条。
这些智能体的「大脑」也不是通用的。它们基于一个名为 xTrimo Universe 的模型库,这个库包含了 104 个专为生命科学领域训练的基础模型(Foundation Models),涵盖了蛋白质、RNA、DNA、细胞等多个层面。这就好比你不会让一个历史学家去解蛋白质结构,每个任务都由最合适的「专家模型」来完成。这种专业化让 BioLab 在 PubMedQA 这类生物医学推理任务上,表现超过了 GPT-4 等通用模型。
当然,跑分是次要的,真正的考验是解决实际问题。
研究者给 BioLab 布置了一个硬骨头的任务:从头设计一款靶向巨噬细胞的抗体。BioLab 自主完成了从文献中挖掘靶点,到多目标抗体优化的整个计算流程。通过分子动力学模拟,系统不仅找到了亲和力更好的变体,还揭示了亲和力增强背后的结构机制——这是做药的人非常看重的。
最关键的一步是闭环验证。计算设计得再好,也要回到实验台上来验证。他们将优化后的抗体(Pem-MOO-1, Pem-MOO-2)表达纯化,进行了活性测试。结果显示,新设计的抗体与 PD-1 结合的 IC50 值达到了 0.01–0.016 nM,优于亲本帕博利珠单抗的 0.027 nM。
数据不会说谎,这意味着 AI 设计的分子在生物活性上确实超越了已经成药的重磅炸弹。功能实验也证实,新抗体不仅结合得更紧,在阻断信号通路、多参数性能上也表现更佳。
BioLab 的工作展示了一种 AI 原生的科研范式。它告诉我们,将多个「专家」AI 组合起来,让它们自主地提出假设、设计实验、分析结果,并最终通过湿实验来验证,这条路是走得通的。这不再是单纯的计算模拟,而是真正意义上的端到端科学发现。
📜Paper: https://www.biorxiv.org/content/10.1101/2025.09.03.674085v1
3. GNN 药物发现全景图:进展、模型与挑战一览
做药的都知道,分子本身就是一种图(Graph)。原子是节点(node),化学键是边(edge)。过去,我们总要把这种立体的结构信息压缩成一维的 SMILES 字符串,这个过程不可避免地会丢失信息。图神经网络 (Graph Neural Networks, GNNs) 的出现改变了游戏规则。它不需要这种压缩,可以直接在分子图上进行学习和推理,这让它成了药物发现领域一个无法忽视的工具。
Katherine Berry 和 Liang Cheng 的这篇综述,很好地梳理了 GNN 在我们这个领域的应用现状。
GNN 首先在分子属性预测上证明了自己
这是 GNN 最早取得成功的领域,也相对容易理解。比如预测分子的 ADMET(吸收、分布、代谢、排泄、毒性)性质。模型通过学习大量已知分子,试图找出结构与性质之间的关联。早期的模型比较简单,后来的 Attentive FP、MolGIN 等模型则更进一步。它们引入了注意力机制(attention mechanism),让模型能自己判断分子中哪个官能团对特定的性质(比如毒性)影响最大。这有点像一个经验丰富的化学家,扫一眼分子结构就能抓住要害。
预测药物 - 靶点结合亲和力是真正的硬骨头
预测一个分子能否与蛋白靶点结合,以及结合的强度,这是药物发现的核心。这件事的难度在于,你不仅要考虑药物分子的结构,还要考虑蛋白结合口袋的三维结构。这就像要判断一把钥匙(药物)能不能打开一把锁(靶点),你得同时看清钥匙和锁的形状。GraphDTA、MGraphDTA 这类模型开始尝试融合这两种信息。它们分别对药物和靶点蛋白进行图编码,然后学习它们之间的相互作用。这类研究的目标,就是让计算机在海量分子库中,比高通量筛选更快、更准地找到那个「天选之子」。
药物组合与协同作用预测
在肿瘤等复杂疾病的治疗中,单一药物往往不够,联合用药才是常态。但两种药放在一起,效果是 1+1>2(协同)还是 1+1<2(拮抗)?这很难预测。DeepDDS、SynerGNet 等模型利用 GNN 来分析复杂的生物网络(比如基因调控网络或蛋白质相互作用网络)。它们试图从系统层面理解药物如何影响细胞,从而预测药物组合的效果。这对于开发新的联合疗法至关重要。
GNN 的应用远不止于此
这篇综述还提到了 GNN 在其他方向的应用。比如,预测药物与肠道微生物的相互作用,这对于理解个体化用药很有帮助。还有药物重定位(drug repositioning),也就是老药新用,GNN 可以通过分析药物和疾病的关联网络来寻找新的可能性。甚至在逆合成分析(retrosynthesis)上,GNN 也能派上用场,帮助化学家设计更优的合成路线。
挑战依然严峻
尽管 GNN 看起来前景光明,但我们一线研发人员都清楚,从论文到实际应用还有很长的路。
第一个就是数据问题。「Garbage in, garbage out.」这句老话在 AI 领域尤其正确。很多公开的生物活性数据集充满了噪声,而且数据量也并不总是足够。我们需要更多高质量、多样化的实验数据来喂养这些模型,否则训练出来的模型可能只是「看起来很美」,一到真实世界的化学空间就失灵了。
第二个是模型本身。GNN 的架构五花八门,到底哪一种最适合特定的化学或生物问题,并没有定论。这导致大量的「炼丹」,也就是不断调整模型参数和结构,缺乏系统性的指导。
最后一个,也是最关键的,是可解释性(interpretability)。模型告诉你这个分子活性很好,为什么?是哪个子结构起到了关键作用?如果模型不能回答这个问题,它对药物化学家来说就是一个黑箱。我们无法从中学到知识,也无法基于它的判断去理性地设计下一个更好的分子。我们做的是科学,不是算命。如果不能打开这个黑箱,AI 就永远只是一个辅助筛选的工具,无法真正指导创新。
这篇综述为我们描绘了一幅清晰的 GNN 药物发现地图。GNN 已经从一个学术概念,变成了药物研发工具箱里一个越来越重要的工具。下一步要做的很明确:积累更好的数据,设计更智能的模型,以及想办法让模型「开口说话」。
📜Title: A Survey of Graph Neural Networks for Drug Discovery: Recent Developments and Challenges📜Paper: https://arxiv.org/abs/2509.07887
四、全球药物靶点发现、挖掘与探索:方法、技术及中外创新实例深度解析
(原创 张江药哥 张江药哥)
2. 靶点发现:识别疾病核心驱动因素
靶点发现是指在药物研发的早期阶段,通过深入理解疾病的生物学机制,识别并确定与疾病发生发展密切相关的特定分子或细胞结构。这一过程旨在找到全新的、未被充分利用的,或已知但其在特定疾病中的关键作用尚未被完全阐明的潜在治疗靶点。它通常涉及基础科学研究、基因组学、蛋白质组学等“组学”技术,以及功能基因组学方法,以生成关于疾病驱动因素的初步假设。
2.1 靶点发现的方法
靶点发现的方法论涵盖了多种前沿技术和策略:
基础科学研究: 通过深入理解疾病的基本生物学机制,确定可能参与疾病发生发展的分子靶点,例如肿瘤细胞中的异常蛋白或炎症反应中的信号通路分子 。
基因组学: 识别与疾病相关的基因变异,并深入解析这些基因的功能及其调控网络,为靶点发现提供关键的分子层面线索 。例如,通过定量PCR(qPCR)等技术可以分析基因表达,确定拷贝数变异(CNV),并启动早期生物标志物的发现 。
蛋白质组学: 揭示蛋白质在疾病中的表达模式和相互作用方式,从而帮助科学家理解疾病的生物学特性 。通过流式细胞仪、自动化细胞分选仪和计数器以及细胞成像仪等工具,可以对蛋白质进行快速、可重复的评估,并进行蛋白定量和表达水平监测 。
生物信息学: 对大规模基因组和蛋白质组数据进行高效分析和挖掘,从而发现新的潜在靶点 。例如,通过基因本体(GO)富集分析和京都基因与基因组百科全书(KEGG)通路分析,可以共同识别差异基因主要参与的生物学过程和信号通路 。
高通量筛选: 快速筛选大量化合物,以寻找与靶点相互作用的潜在药物候选物 。
遗传学方法: 利用遗传相互作用(如增强子或抑制子)来生成潜在靶点的假设 。
化学蛋白质组学: 通过创建能够特异性结合目标蛋白的化学探针,进而检索和识别这些蛋白,从而在蛋白质组学层面识别药物靶点 。
全基因组关联研究(GWAS): 分析大量个体的全基因组,识别与特定疾病风险显著相关的基因变异 。
2.2 靶点发现的主体
靶点发现的主体通常包括:
学术研究机构和大学: 它们是基础科学研究的摇篮,通过前沿研究揭示疾病的分子机制,并发现新的潜在靶点 。
大型制药公司: 它们拥有强大的研发能力和资源,通过内部研究和外部合作,系统性地进行靶点识别 。
新兴生物技术公司: 它们通常专注于特定疾病领域或前沿技术,通过创新方法发现首创(First-in-class)靶点 。
目前中国大部分创新药企,都是fast follow,非常少的公司在做全新靶点发现的工作,因为靶点发现是一个非常耗时,充满了不确定性的事情,而且新的靶点发现可能是诺贝尔奖级别的工作,对科学家的综合素质要求也非常高 ,另外也看运气。
2.3 中国靶点发现实例
1、鞍石生物科技 (Avistone Bio) 与首都医科大学附属北京天坛医院江涛院士团队:脑胶质瘤PTPRZ1-MET融合基因的发现
2014年,江涛院士团队在全球范围内首次发现并报道了PTPRZ1-MET融合基因,并确定其是脑胶质瘤从低级别向高级别进展的重要驱动基因之一 。这一发现为脑胶质瘤的分子病理学研究做出了突出贡献,并为后续的靶向治疗药物开发奠定了基础。 这一发现直接促成了中国首个获批用于脑胶质瘤MET靶向治疗的小分子靶向药物伯瑞替尼(Beritinib)的研发和上市,开启了脑胶质瘤精准靶向治疗的时代 。
2、中国科学院上海有机化学研究所:帕金森病潜在新靶点FAM171A2的发现
研究团队通过GWAS发现FAM171A2基因的多个突变与帕金森病风险增加显著相关 。随后,通过分析帕金森病患者脑组织和脑脊液中FAM171A2蛋白水平升高,并结合体内和体外研究,揭示了FAM171A2介导病理性α-突触核蛋白淀粉样纤维摄取和扩散的关键机制 。 这项研究为帕金森病提供了新的治疗靶点和干预策略,是基础研究向临床转化迈出的重要一步 。
2.4 外国靶点发现实例
1、阿斯利康 (AstraZeneca):基因组学驱动的原创性靶点识别
主体: 阿斯利康(大型制药公司)及其合作机构,如英国癌症研究中心、Horizon Discovery和创新基因组学研究所 。旨在识别原创性的新型靶点,通过构建对疾病生物学机制的深刻理解来发现。通过大规模基因组测序(计划到2026年分析200万个基因组)、功能基因组学(大规模CRISPR筛选,包括基因敲除CRISPRn、基因上调CRISPRa和基因下调CRISPRi) 。 阿斯利康通过庞大的基因组数据收集和功能基因组学策略,旨在构建对疾病生物学机制的深刻理解,从而发现“更好”的原创性靶点 。这种策略旨在提高研发成功率,减少后期临床试验的失败 。
2、Ragon Institute:结核病抗体靶点发现
Ragon Institute(顶尖研究机构) 识别能够增强机体对抗结核分枝杆菌(Mtb)能力的抗体靶点。 通过单克隆抗体(mAbs)库筛选 。研究人员通过筛选大量的单克隆抗体库,这些抗体靶向Mtb的多种不同组分,以确定哪些抗体能有效减少感染小鼠体内的细菌生长 。这项研究揭示了抗体如何直接增强机体对抗Mtb的能力。 这项发现为开发新型结核病免疫疗法提供了重要基础 。
3、2023年FDA/EMA/PMDA批准的12个新颖作用机制靶点
主体: 全球范围内的制药公司和研究机构(通过多年基础研究和转化医学的结晶) 。
靶点/机制: 这些靶点是2023年首次被批准药物调控的靶点,代表了全新的作用机制。
发现方法: 涉及对疾病生物学机制的深入理解和创新性药物分子的设计,通常是多学科交叉研究的成果 。
实例:
神经激肽3受体 (NK3R): 药物Fezolinetant,小分子抑制剂,用于治疗更年期血管舒缩症状 。
补体因子B (CFB): 药物Iptacopan,小分子抑制剂,用于治疗阵发性睡眠性血红蛋白尿症 。
γ-分泌酶 (PSEN1 和 PSEN2): 药物Nirogacestat,小分子抑制剂,用于治疗硬纤维瘤 。
活化素受体1型 (ACVR1): 药物Momelotinib,小分子抑制剂,用于治疗骨髓纤维化 。
RAC-丝氨酸/苏氨酸蛋白激酶1, 2, 3 (AKT1, AKT2, AKT3): 药物Capivasertib,小分子抑制剂,用于治疗乳腺癌 。
G蛋白偶联受体家族C组5成员D (GPRC5D): 药物Talquetamab,双特异性抗体,用于治疗多发性骨髓瘤 。
组织因子途径抑制剂 (TFPI): 药物Concizumab,单克隆抗体,用于治疗血友病A/B 。
超氧化物歧化酶1 mRNA (SOD1): 药物Tofersen,反义寡核苷酸(ASO),用于治疗肌萎缩侧索硬化症(SOD1突变型) 。
l-乳酸脱氢酶A mRNA (LDHA): 药物Nedosiran,小干扰RNA(siRNA),用于治疗原发性高草酸尿症1型 。
意义: 这些新靶点的发现和相应药物的批准,为此前无有效疗法或现有疗法效果不佳的疾病带来了新的治疗选择 。
3. 靶点挖掘:从大数据中发现潜在靶点
靶点挖掘是指利用计算生物学、生物信息学和人工智能(AI)等先进技术,从海量的生物医学数据(如基因组学、蛋白质组学、转录组学、临床数据、科学文献、专利信息等)中,系统性地识别、提取和优先排序潜在药物靶点的过程。这一过程旨在通过数据分析和模式识别,揭示传统方法可能难以发现的复杂生物学关联和“隐藏”的靶点。
3.1 靶点挖掘的方法
靶点挖掘主要依赖于数据驱动的计算方法:
生物信息学分析: 对大规模“组学”数据(基因组学、蛋白质组学、转录组学、代谢组学等)进行整合和分析,识别疾病相关的基因、蛋白质和通路 。例如,通过基因本体(GO)富集分析和京都基因与基因组百科全书(KEGG)通路分析,可以共同识别差异基因主要参与的生物学过程和信号通路 。
人工智能(AI)与机器学习(ML):
自然语言处理(NLP): 从海量科学文献、临床试验报告和公共数据库中提取并综合信息,识别新型生物分子靶点(比如智慧芽数据库)。
知识图谱: 构建基因、药物、疾病和分子通路之间的复杂关系网络,从中发现新的生物学洞察和潜在靶点 。
深度学习与模式识别: 自动从异构数据集中提取和识别复杂模式,预测药物与疾病、基因之间的关联 。
虚拟筛选: 快速评估大量化合物与靶点的潜在相互作用,筛选出高活性的化合物 。
生成式AI: 用于从头设计新型分子和靶点,甚至攻克传统上被认为是“不可成药”的靶点 。
遗传学与AI结合: 通过遗传学研究发现与疾病风险相关的基因变异,并结合AI平台在活体动物中直接评估基因靶点 。
可能真实的靶点挖掘,就是通过智慧芽等数据库,跟踪大公司处于临床前研究的靶点,在这些靶点基础上,结合领导层的眼光,去部署做大量的文献调研,基于公共数据的机制深入挖掘
3.2 靶点挖掘的主体
靶点挖掘的主体通常包括:
AI驱动的药物发现公司: 它们专注于开发和应用AI平台来加速靶点识别和药物设计 。
大型制药公司: 它们通过与AI公司合作或建立内部AI团队,利用大数据和AI技术挖掘新靶点 。
学术研究机构: 它们利用生物信息学和计算生物学工具,从公开数据集中挖掘潜在靶点 。
3.3 中国靶点挖掘实例
1、英矽智能 (Insilico Medicine):AI驱动的靶点和化合物发现
英矽智能(AI驱动的药物发现公司) 发现特发性肺纤维化(IPF)药物Rentosertib的靶点TNIK(TRAF2 and NCK-interacting kinase) 。 通过开发的Pharma.AI平台,包括PandaOmics模块(利用深度生成模型、强化学习、Transformer模型、自然语言处理NLP和机器学习)和Chemistry42模块 。PandaOmics模块分析海量生物学数据和文献(1.9万亿数据点、1000万生物样本的RNA测序和蛋白质组学数据,以及4000万份专利和临床试验文档),通过NLP和机器学习来发现和优先排序新型靶点 。 Rentosertib是全球首个靶点和化合物均由生成式AI发现的药物,将靶点识别到临床前候选药物筛选的平均时间缩短至12-18个月,远低于传统方法 。
2、望石智慧 (Drug Farm):遗传学与AI结合的IDInVivo平台
望石智慧(生物技术公司)发现α-激酶1(ALPK1)抑制剂DF-003,靶向罕见遗传病ROSAH综合征和心肾疾病的根本原因 。通过IDInVivo平台,结合遗传学和人工智能技术,能够在活体动物中直接评估基因靶点 。这种结合活体动物评估和AI的挖掘方式,提高了靶点识别的效率和准确性,加速了创新免疫调节疗法的开发 。
3、中国医科大学 (CMU) 及其医疗系统:AI辅助药物发现
中国医科大学及其医疗系统(学术研究机构)发现异基因CAR-T疗法(用于实体瘤)、SOA101三特异性抗体、SOB100 HLA-G靶向外泌体 。通过AI驱动的药物发现平台,结合外泌体技术和AI,实现药物的精准递送 。 AI技术被广泛应用于医疗解决方案,包括儿童生长评估系统、远程ICU系统、智能健康排程和Tc-99mTRODAT-1平台辅助中枢神经系统运动障碍诊断等,这些都依赖于对大量医疗数据的挖掘和分析以识别潜在的干预点 。
4、Rgenta Therapeutics:口服小分子RNA靶向药物平台
Rgenta Therapeutics(生物技术公司)通过专有平台,挖掘基因组数据以识别可靶向的RNA加工事件 。 这为肿瘤治疗开辟了新的途径,通过靶向RNA加工事件来干预疾病 。
3.4 外国靶点挖掘实例
1、阿斯利康 (AstraZeneca) 与BenevolentAI:知识图谱AI驱动的靶点识别
阿斯利康(大型制药公司)与BenevolentAI(AI公司)发现慢性肾病(CKD)领域中肾小球足细胞功能相关的新型靶点 。通过 知识图谱AI、多组学表征(基因组、转录组、蛋白质组、代谢组、脂质组分析、多模态成像和临床数据) 。合作已在CKD领域识别出超越传统肾素-血管紧张素系统的全新靶点,并成功推动了一个基于此前未探索的肾小球足细胞功能靶点的药物发现项目 。
2、BenevolentAI:COVID-19药物再利用
BenevolentAI(AI公司)发现 巴瑞替尼(baricitinib)作为潜在COVID-19治疗药物。通过AI平台(知识图谱),对现有药物和疾病数据进行快速挖掘 。这个发型展现了AI在紧急情况下快速识别潜在治疗方案的强大能力,仅用三天就识别出巴瑞替尼 。
3、Recursion Pharmaceuticals:机器学习驱动的基因组筛选
Recursion Pharmaceuticals(生物技术公司)发现RBM39降解剂REC-1245,靶向生物标志物富集的实体瘤和淋巴瘤 。通过无偏倚的机器学习驱动的基因组筛选 。 将靶点识别到IND申报研究阶段的时间缩短至18个月内,比行业平均水平快一倍以上,显著加速了药物研发进程 。
4、Caris Life Sciences:肿瘤学新型靶点发现平台
Caris Life Sciences(生物技术公司)发现识别并验证肿瘤学领域中真正新颖的靶点 。 通过Caris Discovery®平台,包括专有的适体(aptamer)基蛋白质组学分析平台(ADAPT)、计算分析和机器学习预测AI 。该平台能够以系统级规模对任何实体瘤类型进行无偏倚的蛋白质组学分析 。 这一发现使得Caris能够发现并验证在传统方法中可能被忽视的新型肿瘤靶点,突破传统药物开发中靶点冗余和数量有限的瓶颈 。
4 靶点探索:深入理解与验证治疗潜力
靶点探索是指在潜在药物靶点被初步识别或挖掘出来之后,对其进行深入的生物学和药理学研究,以全面理解其在疾病发生发展中的具体作用、其“成药性”(是否能被药物有效调控),以及作为治疗干预点的可行性。这一阶段通常涉及功能基因组学(如CRISPR筛选以验证基因功能)、表型筛选、结构生物学、以及开发新型治疗模式(如核酸疗法、基因编辑)来验证和优化靶点。
4.1 靶点探索的方法
靶点探索主要通过以下方法进行:
功能基因组学: 通过系统性地操控基因表达(如基因敲除、上调、下调),观察模拟药物预期效果的表型结果,以深入理解基因型与表型之间的关系,构建疾病相关模型和检测方法 。
CRISPR基因编辑技术: 作为功能基因组学的重要工具,用于靶点验证,阐明作用机制和疾病中的生物学通路,并可用于寻找合成致死靶点 。同时,CRISPR本身也作为一种治疗模式,直接纠正或改变遗传指令 。
表型筛选: 通过观察化合物对细胞、组织或整个生物体产生的整体生物学效应来发现药物,尤其适用于疾病机制尚未完全阐明的复杂疾病 。现代表型筛选融合了高内涵成像、RNA谱分析等先进工具 。
结构生物学: 通过解析靶点分子的三维结构,理解其与药物分子的相互作用机制,指导药物设计和优化 。
蛋白质工程: 设计和构建具有特定功能的蛋白质分子,如融合蛋白、双特异性抗体、抗体偶联药物(ADC),以实现对靶点的精确调控 。
核酸靶向疗法: 开发直接结合或作用于DNA/RNA分子的药物(如反义寡核苷酸ASO、小干扰RNA siRNA、碱基编辑),调节基因表达或功能 。
4.2 靶点探索的主体
靶点探索的主体通常包括:
生物技术公司: 它们通常拥有特定的技术平台(如蛋白质工程、基因编辑平台),专注于将已识别的靶点转化为治疗候选药物 。
大型制药公司: 它们通过内部研发和外部合作,对潜在靶点进行全面的验证和优化,并将其推进到临床开发阶段 。
学术研究机构: 它们在基础研究的基础上,进一步探索靶点的功能和治疗潜力,并开发新的治疗模式 。
4.3 中国靶点探索实例
1、荣昌生物 (RemeGen):泰它西普(Telitacicept)双靶点融合蛋白的探索与优化
荣昌生物发现BLyS(B淋巴细胞刺激因子)和APRIL(增殖诱导配体)双靶点 。重组融合蛋白技术、分子信息学优化(提升稳定性、半衰期、免疫耐受性、降低免疫原性)。通过泰它西普是全球首款、同类首创的注射用重组BLyS和APRIL双靶点新型融合蛋白产品 。其结构由人跨膜激活剂和钙调蛋白配体相互作用因子(TACI)受体的胞外域与人免疫球蛋白G(IgG)的Fc段融合而成,能够同时靶向BLyS和APRIL,有效抑制B细胞介导的自身免疫反应 。泰它西普已获批用于治疗系统性红斑狼疮(SLE),并在重症肌无力(gMG)、类风湿性关节炎、IgA肾病等多种B细胞介导的难治性自身免疫疾病的后期临床试验中展现出显著疗效和良好安全性 。
2、康方生物 (Akeso):PD-1/VEGF-A双特异性抗体的创新探索
康方生物(生物技术公司)发现PD-1(程序性死亡受体-1)和VEGF-A(血管内皮生长因子A)双靶点 。通过双特异性抗体设计,实现配体结合的协同效应 。 康方生物的Ivonescimab(依沃西)是一款双特异性抗体,其创新之处在于将PD-1和VEGF-A这两个现有靶点以新颖的方式结合,实现了VEGF结合能够使PD-1结合增加10倍以上的协同效应 。这种独特的分子设计在非小细胞肺癌中显示出协同作用,为肿瘤治疗提供了新的策略 。
3、科伦博泰 (Kelun-Biotech):First-in-class ADC药物的靶点特性探索
科伦博泰(生物技术公司)发现潜在First-in-class ADC靶点(具体未披露)。基于对靶点生物学特性的深入理解,并利用公司专有的“OptiDCTM”平台开发ADC药物 。SKB518已获得美国FDA和中国NMPA的IND(新药临床试验)批准,并在中国进行I期临床试验,主要关注实体瘤、自身免疫、炎症和代谢疾病等主要疾病领域,体现了对靶点特性和成药性的深入探索 。
4、礼新医药 (Lanovamedicines):热门靶点竞争中的差异化探索
礼新医药(生物技术公司)通过药物筛选与优化,以在竞争激烈的热门靶点领域占据领先地位 。 其LM-302在胃癌及胰腺癌细胞模型中显示出优异的有效性,并在动物模型中展现出卓越的抗肿瘤活性,表明中国企业不仅在“首创”靶点上发力,也在热门靶点上通过深入探索和优化来巩固竞争优势 。
4.4 外国靶点探索实例
1、辉瑞 (Pfizer):现代化表型筛选的回归
辉瑞公司(大型制药公司)恢复囊性纤维化(CF)患者肺细胞液膜 。通过现代化表型筛选,融合了高内涵成像、RNA谱分析和CRISPR等先进工具,主要在细胞模型中进行 。 辉瑞利用表型筛选方法来深入理解化合物如何影响“疾病相关”的细胞或组织 。例如,为CF创建的表型筛选成功找到了能够重建肺细胞表面液膜的化合物 。表型筛选在疾病机制尚未完全阐明的复杂疾病领域,如阿尔茨海默病和某些感染性疾病,已被证明是发现新颖作用机制药物的关键工具 。
2、Granite Bio (与Versant's Ridgeline Discovery Engine合作):自身免疫疾病首创抗体的探索
Granite Bio(生物技术公司)与Versant的Ridgeline Discovery Engine(风险投资公司孵化器)发现 GRT-001(耗竭促炎单核细胞)、GRT-002(阻断白细胞介素-3, IL-3) 。通过 首创抗体疗法开发、Versant的发现引擎模式(多学科团队、先进实验室设施、与学术界合作) 。 这种模式通过提供强大的科学基础设施和运营支持,加速了学术突破向治疗候选药物的转化,尤其是在自身免疫疾病和肿瘤学等复杂领域 。
3、CRISPR基因编辑技术在靶点验证与治疗中的应用
主体: CRISPR Therapeutics、Vertex、Editas Medicine、Beam Therapeutics、Locus Biosciences、Intellia Therapeutics、PACT Pharma等生物技术公司和研究机构 。
靶点/机制:
镰状细胞病(SCD)和输血依赖型β地中海贫血(TDT): 诱导胎儿血红蛋白(HbF)表达 。
遗传性转甲状腺素蛋白淀粉样变性(hATTR): 减少体内错误TTR蛋白的产生 。
尿路感染(UTI): 靶向并破坏导致UTI的大肠杆菌菌株的基因组 。
家族性高胆固醇血症: 降低有害的低密度脂蛋白胆固醇水平 。
癌症: 针对多种转移性癌症 。
神经退行性疾病: 亨廷顿病(靶向Huntingtin基因)和帕金森病(靶向LRRK2基因) 。
探索方法: 大规模CRISPR筛选(基因敲除、上调、下调)、碱基编辑、体内/体外基因编辑、脂质纳米颗粒(LNP)递送 。
意义: CRISPR技术不仅通过精确的基因操作为靶点验证提供了前所未有的工具,极大地提高了对基因功能和疾病机制的理解;同时,CRISPR本身也作为一种革命性的治疗手段,直接纠正或改变遗传指令,为单基因疾病和传统上难以治疗的疾病提供了全新的解决方案 。
4、核酸作为药物靶点的新兴趋势
主体: Ionis Pharmaceuticals、Alnylam Pharmaceuticals、Novartis、Sanofi等制药公司和生物技术公司 。
靶点/机制:
信使RNA (mRNA): 在癌症和神经退行性疾病等多种RNA相关疾病的治疗中变得越来越重要 。例如,Inotersen和Patisiran通过靶向转甲状腺素蛋白mRNA(Transthyretin mRNA)来治疗遗传性转甲状腺素蛋白淀粉样变性 。Lumasiran通过靶向羟基酸氧化酶1 mRNA(Hydroxyacid oxidase 1 mRNA)来治疗原发性高草酸尿症1型 。Mipomersen则靶向载脂蛋白B-100的mRNA(mRNA of ApoB-100)来治疗纯合子家族性高胆固醇血症 。
其他核酸靶点: Bevasiranib靶向血管内皮生长因子A长链,Fitusiran靶向抗凝血酶-III,Golodirsen靶向肌营养不良蛋白,Inclisiran靶向前蛋白转化酶枯草杆菌蛋白酶/Kexin 9型(PCSK9),Oblimersen靶向凋亡调节因子Bcl-2 。
探索方法: 反义寡核苷酸(ASO)和小干扰RNA(siRNA)的设计与化学修饰(如硫代磷酸酯PS修饰、2'-O-甲基和2'-O-甲氧基乙基修饰、磷酰胺吗啉代寡核苷酸PMO、锁核酸LNA、乙烯桥接核酸ENA),以提高稳定性、靶向性和降低免疫原性 。
意义: 这种对核酸靶点的日益重视,标志着药物发现“可靶向空间”的显著扩展,为开发更具创新性和特异性的治疗方案提供了广阔前景 。
5. 中国与外国靶点研究比较
全球生物制药领域正经历一场显著的权力转移,中国作为新兴的创新力量,正在重塑原有的合作与竞争格局。
5.1 中国靶点研究的特色与优势
从“快速跟随者”到“首创”创新者的转变: 长期以来,中国生物制药行业被认为主要扮演“快速跟随者”的角色,即在西方创新靶点被发现后,迅速开发“me-too”或“fast follower”药物 。然而,近年来,中国正迅速向全球创新者转变。鞍石生物的伯瑞替尼和荣昌生物的泰它西普被明确描述为“First-in-class”或“全球首款”药物 。科伦博泰的SKB518也具备“潜在First-in-class”的特性 。康方生物的Ivonescimab则展示了在现有靶点基础上进行“组合创新”的强大能力 。
政府战略支持与监管优化: 中国政府自2006年以来一直将生物技术作为优先发展领域,实施了长期国家战略,并对监管生态系统进行了改革,使得药物测试在中国能够比美国更快、更经济地进行 。这为新兴的中国企业提供了竞争优势 。
人才回流与本土创新: 大量在西方受训的顶尖科学家回国,带来了先进的知识和经验,并将其转化为本土创新驱动的公司 。
AI驱动药物发现的全球领导力: 中国在AI驱动药物发现领域展现出独特的领导力和创新模式,尤其在利用生成式AI进行新靶点和新分子发现方面取得了世界级的突破 。英矽智能的Rentosertib是全球首个靶点和化合物均由生成式AI发现的药物 。中国拥有超过100家AI制药公司,并在2021年获得了超过12.6亿美元的投资 。
研发投入与科学产出: 中国在研发方面投入巨资,2023年公共研发资金可能超过200亿元人民币,并加强了知识产权框架 。中国在2023年是合成生物学、基因组测序与分析、新型抗生素和抗病毒药物等领域高被引论文数量最多的国家 。
“生物优化”药物(Biobetter)的战略: 中国企业在改进现有药物方面表现出色,通过优化分子结构以提高疗效或降低副作用,例如在抗体偶联药物(ADC)领域 。
5.2 外国靶点研究的特色与优势
传统创新领导者地位: 欧美国家长期以来是全球药物发现的领导者,拥有深厚的基础科学研究积累和完善的创新生态系统 。
多元化技术平台与方法: 大型制药公司和生物技术公司广泛采用基因组学、蛋白质组学、表型筛选、结构生物学、CRISPR基因编辑等多种技术,并不断探索新的方法 。
成熟的风险投资与孵化模式: 例如Versant Ventures的Discovery Engines模式,通过提供强大的科学基础设施和运营支持,加速学术突破向治疗候选药物的转化 。
全球合作网络: 顶尖研究机构(如Broad Institute、马萨诸塞州总医院、卡罗林斯卡学院、华盛顿大学)与全球伙伴合作,共同推动全球健康领域的靶点发现 。
核酸靶向疗法的先驱: 在核酸类药物(如ASO、siRNA)的开发和应用方面,欧美公司处于领先地位,并不断推动其技术成熟和靶点拓展 。
共同趋势与挑战
AI的深度融合: 无论是中国还是西方,AI在药物发现中的应用都正从辅助工具向核心驱动力转变,旨在加速研发进程、提高成功率并拓展“不可成药”靶点的空间 。
多组学数据整合: 双方都在向多组学数据(基因组、蛋白质组、转录组、代谢组、脂质组、多模态成像和临床数据)的深度整合转变,以构建更全面的疾病“表型指纹” 。
精准医疗的追求: 靶点发现的最终目标都是推动个性化和精准医疗的实现,通过针对特定靶点设计的药物,提高治疗效果并减少副作用 。
共性挑战: 药物研发的整体失败率依然居高不下(约90%的药物候选物在临床前或临床试验中失败),高昂的研发成本,以及AI模型结果的解释性和可重复性限制,都是全球面临的共同挑战 。
地缘政治影响: 地缘政治紧张局势对生物技术领域产生了影响,一些公司为降低风险,已将其运营进行多元化布局 。 6. 未来趋势与挑战6.1 靶点研究面临的共性挑战
尽管药物靶点研究领域取得了显著进步,但其固有挑战依然存在,并随着技术发展呈现出新的复杂性:特定靶点评估的时间和资源密集性
:从发现到验证,每一个环节都需要大量的投入AI模型的解释性和可重复性
:机器学习方法在靶点识别中虽然高效,但其结果的解释性和可重复性有时受到限制技术挑战
:检测低丰度、弱结合或膜蛋白等具有挑战性的靶点仍然存在困难表型筛选中的"命中验证"和"靶点去卷积"
:如何准确地确定引起表型变化的具体分子靶点仍是重大难题高失败率与成本压力
:药物研发的整体失败率依然居高不下,约90%的药物候选物在临床前或临床试验中失败,且整个过程可能耗时超过十年6.2 AI、基因编辑等前沿技术的发展趋势
AI的深度融合与拓展:
AI在药物发现中的应用正从辅助工具向核心驱动力转变。未来的趋势是AI将更深入地整合多模态数据(包括基因组、蛋白质组、转录组、代谢组、脂质组、多模态成像和临床数据),以构建更全面的疾病"表型指纹"。生成式AI(如GANs、VAEs、GPTs)将进一步提升从头设计新型分子和靶点的能力,甚至攻克此前被认为是"不可成药"的靶点,例如内源性无序蛋白和蛋白质-蛋白质相互作用。
CRISPR基因编辑技术的双重深化:
CRISPR技术将继续深化其在靶点验证和治疗应用中的双重角色。在靶点验证方面,大规模功能基因组学筛选将更加成熟,能够更精确地阐明基因功能、疾病机制和合成致死靶点。单细胞CRISPR筛选等高分辨率技术将提供更细致的细胞亚群特异性基因反应信息。在治疗应用方面,CRISPR将从治疗单基因疾病向更广泛的复杂疾病扩展,包括癌症和感染性疾病。同时,更精确的基因编辑工具(如碱基编辑)和体内递送策略的进步,将使其应用更安全、更便捷。
核酸靶向疗法的持续成熟:
核酸作为药物靶点和治疗药物的趋势将持续加强。反义寡核苷酸(ASO)和siRNA等核酸类药物的设计将更加精细化,通过更先进的化学修饰提高稳定性、靶向性和降低免疫原性。除了直接靶向mRNA,研究还将深入探索小分子药物如何结合和调节各种非编码RNA(如lncRNA、miRNA)的功能,从而开辟新的治疗途径。RNA疗法,包括mRNA疫苗和治疗性mRNA,也将继续发展,为多种疾病提供快速响应和高度特异性的解决方案。6.3 个性化与精准医疗的未来方向
药物靶点研究的最终目标之一是推动个性化和精准医疗的实现。精准医疗策略,如靶向治疗,正在逐步改变疾病治疗的格局。通过针对特定靶点设计的药物,靶向治疗能够更精确地干预疾病过程,最大限度地减少对健康组织的损伤,并提高治疗效果。
肿瘤新抗原驱动的个性化免疫治疗
肿瘤新抗原(neoantigens)是由肿瘤细胞特有的基因突变产生的蛋白质片段,可被免疫系统识别为"非己",因此成为个性化肿瘤免疫治疗的理想靶点。这些新抗原完全特异于癌细胞,不存在于正常组织中,提供了前所未有的治疗选择性。随着新一代测序技术和生物信息学算法的进步,科学家现在能够从个体患者的肿瘤样本中鉴定出特异性的新抗原谱系:个性化癌症疫苗
:基于患者特定的新抗原设计的疫苗(如Moderna和Merck的mRNA-4157/V940)已在临床试验中展现出与免疫检查点抑制剂联用时的显著疗效,特别是在黑色素瘤等高突变负荷肿瘤中新抗原特异性T细胞疗法
:通过分离、扩增或工程化改造患者自身的T细胞,使其能够识别肿瘤特异性新抗原,创造真正个性化的细胞疗法预测算法的革新
:AI和机器学习算法正在提高新抗原预测的准确性,能够更精确地识别哪些突变产生的肽段能够被HLA分子有效呈递并引发T细胞应答
此外,肿瘤新抗原研究也正在从单一新抗原扩展到新抗原"签名"概念,通过分析患者肿瘤的整体新抗原模式,更全面地预测免疫治疗反应和疾病进展。
多模态生物标志物整合
随着AI、多组学技术和基因编辑等前沿技术的不断发展,研究人员能够更深入地理解个体患者的疾病生物学特征和分子驱动因素。精准医疗正从单一生物标志物向多模态生物标志物整合方向发展:
AI能够整合海量异构数据来识别和预测最适合特定患者群体的靶点,包括基因组变异、转录组表达、蛋白质组谱、代谢组特征、微生物组成分和影像学特征等
基因组学和蛋白质组学提供详细的分子图谱,揭示疾病的分子驱动机制和潜在治疗靶点
液体活检技术正在革新患者监测方式,通过检测循环肿瘤DNA、外泌体和循环肿瘤细胞,实现早期诊断和动态监测,为治疗决策提供实时信息
靶向干预的精确化
CRISPR等基因编辑工具为根据患者的基因组特征进行精确干预提供了可能。基因治疗领域正经历从罕见单基因疾病向复杂多基因疾病扩展的趋势:
体内基因编辑技术正在快速进步,例如碱基编辑器和prime编辑技术能够以更高精度修复特定基因突变
组织和细胞特异性递送系统的开发,使靶向治疗能够更精确地在需要的组织和细胞中发挥作用
RNA靶向治疗(如ASO和siRNA)提供了比传统小分子和抗体更高度特异性的干预选择
这种技术融合将使得药物开发能够从"一刀切"的模式转向为特定患者群体甚至个体量身定制的疗法,从而最大化疗效并最小化副作用。精准医疗将持续驱动对高度精细的生物学数据、先进诊断工具和创新治疗模式的需求,以期精确调节疾病驱动机制,最终实现更有效、更安全的临床治疗。
随着这些技术的成熟,我们正进入一个能够为每位患者提供真正个性化治疗方案的时代,其中药物靶点的精准识别和靶向干预将成为实现这一愿景的核心要素。
7. 结论
靶点发现、挖掘与探索的比较
维度
靶点发现
靶点挖掘
靶点探索核心目标
确认新的生物分子为潜在药物靶点
深入研究靶点功能与作用机制
拓展靶点在新适应症、新组合中的应用主要方法
人类遗传学、多组学分析、高通量筛选、AI预测
结构生物学、化学生物学、蛋白质组学、功能验证
药理学拓展、联合治疗策略、耐药机制研究主要主体
学术机构、独立Biotech、大型药企研发部门
专业靶点公司、AI驱动的生物技术公司、大型药企早期研发部门
生物技术公司、大型药企后期开发团队、临床研究联盟代表案例
药物牧场的ALPK1、英矽智能的TNIK
BRD4分析平台、PROTAC技术平台、BenevolentAI的AI挖掘
BTK抑制剂从血液肿瘤到自身免疫疾病的拓展时间周期
5-10年
2-5年
3-8年成功关键
机制创新、可药性分析、临床转化潜力
深度机制解析、选择性工具开发、多维验证
转化医学证据、精准适应症定位、联合用药策略风险特点
高风险、高回报,成功率低但影响大
中等风险,与已有知识关联度高
风险相对可控,基于已验证靶点的拓展
药物靶点研究是生物医药创新的核心驱动力,其战略意义在于为未满足的医疗需求提供精准、高效的治疗方案。当前,全球药物靶点研究正经历一场深刻的范式变革,主要体现在以下几个方面:
五、【J.Med.Chem.】计算驱动苗头化合物发现:工业界视角下药物发现的技术变革与挑战
(原创 青梅煮药 青梅煮药)
制药行业历来存在较高的项目失败率,许多化合物未能成功进入最终产品阶段。因此,上市的药物不仅需要弥补成功药物的成本,还要覆盖所有失败化合物的花费,这使得药物发现过程成本高昂,并且需要不断填充潜在目标。所有这些目标都需要初步筛选来启动药物发现过程。
传统上,苗头化合物的筛选通常从已知的起始点或通过生化高通量筛选(HTS)开始。为了降低成本并提高命中率,许多新技术相继被提出,例如亲和选择质谱(AS-MS)和定向筛选。另一种方法是DNA编码库(DEL)筛选,尽管这种方法尚未证明其在苗头化合物发现中的优势。
最具革命性的技术变化是计算方法的应用,特别是虚拟筛选(VS)。超大化学库筛选的虚拟筛选被称为超高通量虚拟筛选(UHTVS),能够覆盖更广泛的化学空间,理论上能以较低成本发现更多、更好的苗头化合物。近年来,计算能力的提高、硬件与算法的发展,以及深度神经网络的出现,极大推动了计算苗头化合物发现的潜力。
近期的两场工业会议讨论了计算苗头化合物发现的方法发展,特别是成功与失败的案例,为药物发现提供了新的方向。这些讨论不仅涉及计算领域的科学家,也为非计算领域的研究人员提供了宝贵的观点。
2. 计算辅助发现苗头化合物:概述与挑战
计算辅助苗头化合物的识别面临许多挑战,这些挑战可能与靶标本身、化学库的选择或苗头化合物发现方法有关,通常是三者结合的结果。虚拟筛选(VS)是一种常用的计算策略,取决于目标的3D结构或已知活性化合物,可以分为基于结构和基于配体的筛选。当目标结构和苗头化合物都已知时,可采用混合方法。
图1. 来自靶标、苗头化合物和方法的挑战概述。
表1. 基于结构和配体的虚拟筛选典型方法及其前提条件概述
虚拟筛选分类方法
起始点(s)
方法
化合物来源
基于结构的
实验解析结构
(AL)对接和评分
内部库
AL绝对FEP+
(超)大库
AF2模型
所有上述方法,经过模型验证
同源模型
从MD获取的构象集
基于配体的
配体单体
子结构搜索
内部库
2D/3D(或形状)相似性搜索
(超)大库
枚举/生成式AI
公共可用的同系系列与SAR
2D/3D相似性搜索
N/A
骨架跳跃
生成式AI
组合/混合方法
靶标和配体/片段
所有上述方法
内部库
AL相对FEP
(超)大库
基于模板的对接
枚举/生成式AI
基于结构的虚拟筛选(SBVS)通过对接化学化合物至生物靶标的活性位点,并用经验评分函数评估结合自由能。该方法需要靶标的三维结构,尽管并非所有靶标都具备高分辨率结构,但近年来,AlphaFold2(AF2)和AlphaFold3(AF3)等技术突破改善了结构预测,提供了大量的蛋白质结构数据。对于超大化学库,主动学习(AL)对接结合机器学习和分子对接,提高了筛选效率,并通过多样性选择和结合位点水分析优化苗头化合物。更强大的计算方法如绝对自由能扰动(AB-FEP)可重新排序化合物,并通过视觉检查和实验筛选进一步确认候选分子。
基于配体虚拟筛选,通常以少数化学化合物及其生物信息为起点,通过2D或3D相似性搜索,并利用结构-活性关系(SAR)数据开发并验证计算模型。SAR分类数据可通过贝叶斯建模或药效团方法筛选化合物。3D相似性筛选直观但计算开销大,早期需要每个化合物每次查询约1小时CPU时间。ROCS程序通过原子中心高斯估算重叠积分,提高了计算效率。2011年,FastROCS基于GPU重新实现,能在一天内筛选10亿化合物。然而,3D表征存储成本高,1D相似性筛选提供了更节省存储的解决方案,结合2D和3D筛选可以有效筛选超大化学库。
表格 2. 超大化学库的典型示例
通过结构基础的药效团模型(源自目标的结合位点,活性或变构)与药物相似性过滤器的结合,可以对(超)大化合物库进行预筛选,从而得到更小的项目特定库。这些专注的化合物库随后可以进行对接和评分,或采用其他计算机辅助虚拟筛选方法。另一种方法是,当片段-靶标的3D结构可用时,可以设计量身定制的库,并进行基于模板的对接,以减少假阳性风险。该方法在9周内成功率达到40%,为片段-靶标结构可用时提供了一个有前景的方向。
3. 高级机器学习在苗头化合物识别中的作用
3.1 机器学习在虚拟筛选中的应用
过去的知识驱动方法通过学习配体特征进行虚拟筛选,但通常不包含靶标的三维结构。这类方法依赖已知活性化合物进行训练,但很多项目初期缺乏这些数据。
近年来,随着配体结构数据和结合测量数据库的增加,研究者开始开发无需模板化合物的模型。借助图像识别和自然语言处理中的机器学习进展,一些团队开发了用于结构基础虚拟筛选的模型,如构象预测和结合评分工具。
尽管这些方法仍处于早期阶段,且常局限于训练数据,主动学习等技术也被用于加速对超大型化学库的筛选。还有研究提出“被动”机器学习,通过Thompson采样在三维空间中扩展分子结构,表现良好。
3.2 主动学习
随着虚拟筛选库的快速增长,需求迫切要求以更具成本效益的方式对数十亿化合物进行对接。
现有的对接程序已相对成熟,进一步提升效率需大幅修改算法。虽然GPU加速对接取得了成功,但随着库的扩展,传统对接方法可能面临瓶颈。为了处理大规模化合物库,需要一种成本远低于对接计算的方法进行评估。
现代深度学习方法,如图卷积网络,已能有效地进行基于2D化学结构的属性预测。主动学习通过利用预测的对接得分来逐步改进模型,从而提高库中最佳化合物的回收率。
在主动学习中,选择合适的采样策略至关重要,过于贪婪的策略可能会失去化学多样性。选择合适的策略对不同目标蛋白和训练集大小有不同影响。
3.3 结合位点识别
对接程序通常需要结合位点的位置来限制搜索空间,这些信息通常来自已知配体诱导目标系统功能反应的晶体结构。若无这些信息,研究人员可使用计算工具识别蛋白的药物结合位点。
计算方法通常依赖于预定义特征,这些特征能够区分真实结合位点与假阳性。基于物理学的评分方法如FPocket、SiteHound和SiteMap,机器学习方法如P2Rank通过计算溶剂可接触表面特征,预测候选位点与配体的结合潜力。
P2Rank在测试中表现良好,超越了其他方法。最近,Tiwary等人推出的GRASP方法利用深度学习模型预测结合位点,表现优于P2Rank。在实际应用中,机器学习方法的效果取决于训练集中的相似结构。对于缺乏类似结构的目标,传统方法可能更为可靠。
3.4 姿势预测
分子对接仍然是预测配体结合模式的常用方法,尤其适用于虚拟筛选中的配体库。尽管有多种基于机器学习的评分函数用于排名化合物,但直到最近,结合模式的生成主要依赖经典的对接程序。近年来,基于生成型机器学习方法的对接程序如EquiBind、TankBind和DiffDock相继发布,带来了新的发展。
EquiBind(2022年发布)使用图匹配网络预测配体结合位点,采用E(3)等变神经网络,确保模型对输入结构的旋转和平移不敏感。它是“盲”对接程序,无需用户提供结合位点信息。通过能量最小化,EquiBind的预测精度可与传统方法媲美。
TankBind(同年发布)采用图表示,并引入“三角函数模块”增强几何约束,通过自注意机制考虑蛋白质和配体的相互作用。它能预测配体在不同潜在结合位点的亲和力,表现出色。
DiffDock采用扩散模型生成姿势,通过逐步添加噪声并去噪恢复输入,无需物理评分即可在PDBbind数据集上获得优异表现。
这些方法通常被视为“盲”对接适用于目标结合位点未知的情况,但对于已知位点,传统方法可能更为精准。由于训练数据的限制,DiffDock等方法对RNA对接效果有限,未来可能需要专门的工具。
4. 基于片段发现苗头化合物
基于片段的药物设计(FBDD)是药物发现中的重要方法,通常包括初步筛选片段分子,然后将这些片段扩展为候选化合物。FBDD一般包括三个关键步骤:首先,构建或购买符合“3规则”的片段;其次,使用体外结合实验,结合生物物理和生化技术,筛选与靶标结合的片段,且常用多种正交实验来区分真实苗头化合物和假阳性。现如今,虚拟库和计算方法可与实验片段筛选同步进行,增强实验的效果。最后,通过结构信息提高片段的结合亲和力和特异性,通常通过添加化学基团、合并片段或采用骨架跃迁方法。
最近,Müller等提出了结合实验与计算的片段到苗头化合物管线方法,实现了较高的成功率。
图2. 基于片段的药物发现流程图。启用计算方法的部分以加粗显示。注:尽管识别结合模式(MoB)是非常理想的,但有时并不可行,此时可以采用基于“盲目”结构-活性关系(SAR)的片段优化方法。实验性MoB检测方法:核磁共振(NMR)光谱学、X射线晶体学。
与传统的高通量筛选(HTS)相比,基于片段的药物发现(FBDD)有多项优势。FBDD使用的化学库比HTS小且冗余较少,有助于更高效地探索化学空间。筛选较小的片段集通常比筛选大量复杂化合物成本更低,特别是在药物发现的早期阶段。此外,由于片段较小且化学简单,即使结合亲和力较低,片段也更可能与目标蛋白结合,因此命中率较高。FBDD的另一个优势是在片段优化过程中,可以进行更多修改并利用更多信息。而HTS通常只能筛选已有的化合物。
然而,FBDD也有一些局限性,首先是片段库的化学空间受限于高溶解度的要求,其次,片段可能对目标选择性不够。实验筛选方法包括生物物理方法和生化功能测定。
4.1 超大数据库的片段筛选方法
机器学习中的主动学习方法使得分子对接可用于远大于以往的化合物库,如Enamine REALSpace和WuXi GalaXi等已超百亿化合物。用主动学习Glide对整个Enamine库筛选需数月。2022年提出的V-Synthes方法解决了这一问题:先对带封端基的反应骨架进行初步对接,选出潜力骨架,再替换为完整合成子并继续对接。该方法假设对接得分具有可加性,能独立评估不同修饰位点,适用于与Enamine库契合的目标,但无法用于其他化学库。
5. 分析和重新评分苗头化合物
5.1 虚拟筛选结果分析
虚拟筛选(VS)的成功不仅依赖于计算协议的执行,更取决于对结果的深入分析和解释。通过结合结合亲和力评分,能量评分是常用的筛选标准,但准确评分非常困难,必须进一步检查高评分化合物,最终生成苗头化合物列表。预测的结合模式分析有助于理解苗头化合物如何与目标蛋白相互作用,揭示关键结合残基和相互作用模式。如果已有实验确定的蛋白-配体复合物结构,可以作为参考来选择重要的相互作用。为了帮助分析,可以使用结构蛋白-配体相互作用指纹(SPLIF)来根据相互作用模式过滤化合物,提供详细的分子相互作用信息,为后续药物设计提供支持。
另一个重要任务是化合物多样性评估。多样性的化合物选择有助于全面探索化学空间,减少冗余,避免特定化学类过度代表,并有助于发现独特的苗头化合物系列。通过对高评分化合物进行聚类,并从每个簇中选择一些例子,能够优化苗头化合物的选择。使用UMAP、tSNE、PCA等方法可帮助可视化化学空间,进一步优化苗头化合物识别过程,提升药物发现的成功率
5.2. 重新评分对接苗头化合物
大多数对接算法依赖于经验参数和力场来估算结合亲和力,计算效率高,但预测的亲和力精度不足,无法可靠地对配体进行排序。对接算法通常将化合物分类为活性或非活性。由于经验评分函数的准确性有限,虚拟筛选的命中率通常较低,约为1-2%。这些方法还依赖于正确预测蛋白质构象,尤其是在蛋白质具有显著柔性的情况下。
为克服上述局限性并提高真实结合物的富集率,通常会使用更精确但计算量较大的方法重新评分虚拟筛选中的前几个结果。分子力学泊松-玻尔兹曼表面积(MM-PBSA)和分子力学广义Born表面积(MM-GBSA)方法结合了溶剂化效应和蛋白质柔性的考虑,提高了评分的准确性。最近的研究表明,使用FACTS方法识别虚假阳性(即评分过高的化合物)效果良好。这些“作弊者”利用了评分函数中的漏洞。详细的全原子模拟是计算蛋白-配体结合自由能的最精确方法。Metadynamics和自由能扰动(FEP)方法可以提供最准确的结合自由能预测。ABFE计算的发展使得无需参考化合物即可进行结合自由能的计算,这对于对接命中的重新评分具有重要意义。
表格 3. 用于FEP计算的开源和商业软件/库示例
5.3. 绝对结合自由能计算的作用
FEP计算在1980年代得到了CADD社区的认可,但其理论基础早在三十年前由Zwanzig等人提出,甚至可以追溯到1930年代的Peierls。促进其广泛应用的一个重要进展是使用热力学循环来简化相对结合自由能(RBFE)的计算,这将两个复杂的结合自由能计算转化为两个可管理的化学能计算。1984年,Tembe和McCammon首次提出热力学循环概念,用于RBFE计算。绝对结合自由能(ABFE)计算是一种有前景的提高计算命中率预测能力的方法,能够定量估计结合亲和力,考虑蛋白质灵活性、溶剂效应和配体构象变化。这些计算为药物发现过程提供了准确的配体-靶标相互作用评估。尽管ABFE计算非常精确,但计算成本较高且对结合姿势非常敏感。为了与实验对比,需要对计算结果进行校准。虽然ABFE重新评分尚未广泛应用,但其潜力巨大,尤其是通过监督机器学习模型降低每个化合物的计算成本后。
6. 结论与展望
虚拟筛选(VS)作为一种成熟的命中发现方法,近年来在算法和计算能力上有了重要发展,极大地改变了这一领域。尽管仍面临挑战,这些方法的预测能力将继续提高,尤其是自由能扰动计算和机器学习等关键进展推动了这一趋势。
自由能微扰计算特别在预测结合亲和力方面提供了前所未有的精度,未来将在现代计算命中发现中扮演重要角色。借助机器学习的技术,研究人员正在开发新工具用于姿势预测、评分、结合位点识别和构象生成,这些方法有望解决虚拟筛选中的许多挑战。超大虚拟库的崛起大大提高了筛选化合物的数量,并使得超过十亿化合物的库得以筛选。随着这些进展的应用,虚拟筛选将成为常态,计算方法将在未来的命中发现中发挥重要作用。
原文献链接:
https://pubs.acs.org/doi/10.1021/acs.jmedchem.4c03087
end
本公众号声明:
1、如您转载本公众号原创内容必须注明出处。
2、本公众号转载的内容是出于传递更多信息之目的,若有来源标注错误或侵犯了您的合法权益,请作者或发布单位与我们联系,我们将及时进行修改或删除处理。
3、本公众号文中部分图片来源于网络,版权归原作者所有,如果侵犯到您的权益,请联系我们删除。
4、本公众号发布的所有内容,并不意味着本公众号赞同其观点或证实其描述。其原创性以及文中陈述文字和内容未经本公众号证实,对本文全部或者部分内容的真实性、完整性、及时性我们不作任何保证或承诺,请浏览者仅作参考,并请自行核实。
2026-04-13
2026年4月11日,礼来靶向PTK7的ADC药物LY4175408在中国申请IND获CDE受理。
蛋白酪氨酸激酶 7(PTK7)是受体酪氨酸激酶家族中一种无催化活性的成员,在卵巢癌、非小细胞肺癌(NSCLC)、食管癌及三阴性乳腺癌(TNBC)等实体瘤中高表达,且与tumor-initiating cells相关。
LY4175408源自礼来收购的MabLink Bioscience,是靶向PTK7的ADC药物,其分子设计如下:
丫抗体: Fc silence的新型全人源抗 PTK7 IgG1 抗体
💊载荷:Topo1i Ecatecan
🔒连接子:VA-PAB-聚肌氨酸(PSAR)亲水连接子,根据专利分析,其连接子-载荷结构与已经进入临床III期的FRa ADC Sofetabart mipitecan一致
🔢DAR值:8
🐓MOA:
🐭体内活性:
👴目前已经启动肺癌,三阴性乳腺癌和子宫内膜癌的临床I期研究
🏃♀️竞争格局方面:
PTK7的ADC 开发比较挑战,首个PTK7 ADC Cofetuzumab pelidotin (PF-06647020/ ABBV-647)由于低疗高毒被辉瑞和艾伯维放弃;Genmab因“总体收益风险状况”停止了通过收购普方生物获得的GEN1107项目。
科伦博泰的SKB518是全球进度最快的PTK7 ADC。目前已经启动2项临床2期,适应症涵盖肺癌(NCT07019675)和妇科肿瘤(NCT07448922)。
DayOne/普众发现的MTX-13DAY301,同样采用Exatecan为有效载荷,于2026年12月在美国和加拿大启动临床1期研究(NCT06752681)。
Whitehawk于近期启动了PTK7 ADC HWK-007的临床(Whitehawk启动PTK7 ADC HWK-007临床,源自药明/多禧)
Kivu Bioscience采用synaffix糖偶联技术开发了KIVU-107,已经启动临床1期(NCT07229313),即将在AACR2026公开临床前研究数据
除了前述几款进入临床的ADC,双抗ADC也值得重点关注,Zymeworks开发了双表位 ADC ZW418
百奥赛图开发了多款PTK7双靶点ADC,其中授权给IDEAY的PTK7/B7H3 ADC药物IDE034/BCG034已经启动临床I期(NCT07503808)(百奥赛图又一里程碑,IDEAYA双抗ADC IDE034完成首例患者入组)。
点关注,不迷路
参考文献: WO2025227010A1.pdf
临床2期临床1期抗体药物偶联物并购引进/卖出
100 项与 SKB-518 相关的药物交易
登录后查看更多信息
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 骨癌 | 临床2期 | 中国 | 2026-04-08 | |
| 子宫内膜癌 | 临床2期 | 中国 | 2026-04-08 | |
| 输卵管癌 | 临床2期 | 中国 | 2026-04-08 | |
| 肝转移 | 临床2期 | 中国 | 2026-04-08 | |
| 卵巢癌 | 临床2期 | 中国 | 2026-04-08 | |
| 卵巢上皮癌 | 临床2期 | 中国 | 2026-04-08 | |
| 铂耐药性卵巢癌 | 临床2期 | 中国 | 2026-04-08 | |
| 铂类耐药性原发性腹膜癌 | 临床2期 | 中国 | 2026-04-08 | |
| 铂敏感性卵巢癌 | 临床2期 | 中国 | 2026-04-08 | |
| 宫颈癌 | 临床2期 | 中国 | 2026-04-08 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
| 研究 | 分期 | 人群特征 | 评价人数 | 分组 | 结果 | 评价 | 发布日期 |
|---|
No Data | |||||||
登录后查看更多信息
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
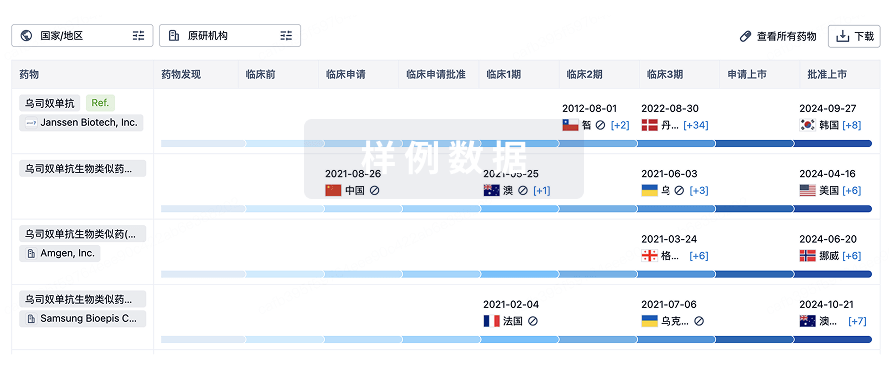
生物类似药
生物类似药在不同国家/地区的竞争态势。请注意临床1/2期并入临床2期,临床2/3期并入临床3期
登录
或
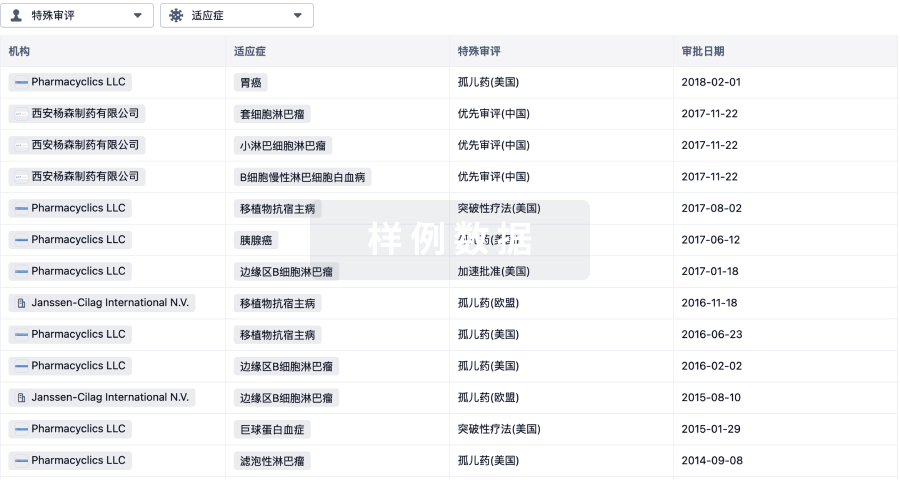
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用