预约演示
更新于:2025-12-08

Cyclica Therapeutics, Inc.
更新于:2025-12-08
概览
标签
神经系统疾病
其他疾病
小分子化药
疾病领域得分
一眼洞穿机构专注的疾病领域

技术平台
公司药物应用最多的技术
靶点
公司最常开发的靶点
关联
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |

靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |

100 项与 Cyclica Therapeutics, Inc. 相关的临床结果
登录后查看更多信息
登录后查看更多信息
2022-07-07BLOOD1区 · 医学
TP53 copy number and protein expression inform mutation status across risk categories in acute myeloid leukemia
1区 · 医学
Article
作者: Loghavi, Sanam ; Ravandi, Farhad ; Khoury, Joseph D. ; Khodakarami, Farnoosh ; Medeiros, L. Jeffrey ; Bivins, Carol A. ; Bhalla, Kapil ; Kantarjian, Hagop M. ; Routbort, Mark ; Wei, Peng ; Kadia, Tapan ; Sui, Dawen ; Kanagal-Shamanna, Rashmi ; Jabbour, Elias J. ; Pierce, Sherry ; Tashakori, Mehrnoosh ; Tang, Zhenya ; Daver, Naval
Abstract:
Mutant TP53 is an adverse risk factor in acute myeloid leukemia (AML), but large-scale integrated genomic-proteomic analyses of TP53 alterations in patients with AML remain limited. We analyzed TP53 mutational status, copy number (CN), and protein expression data in AML (N = 528) and provide a compilation of mutation sites and types across disease subgroups among treated and untreated patients. Our analysis shows differential hotspots in subsets of AML and uncovers novel pathogenic variants involving TP53 splice sites. In addition, we identified TP53 CN loss in 70.2% of TP53-mutated AML cases, which have more deleterious TP53 mutations, as well as copy neutral loss of heterozygosity in 5/32 (15.6%) AML patients who had intact TP53 CN. Importantly, we demonstrate that mutant p53 protein expression patterns by immunohistochemistry evaluated using digital image-assisted analysis provide a robust readout that integrates TP53 mutation and allelic states in patients with AML. Expression of p53 by immunohistochemistry informed mutation status irrespective of TP53 CN status. Genomic analysis of comutations in TP53-mutant AML shows a muted landscape encompassing primarily mutations in genes involved in epigenetic regulation (DNMT3A and TET2), RAS/MAPK signaling (NF1, KRAS/NRAS, PTPN11), and RNA splicing (SRSF2). In summary, our data provide a rationale to refine risk stratification of patients with AML on the basis of integrated molecular and protein-level TP53 analyses.
2022-01-01Bioorganic & medicinal chemistry
Novel structural-related analogs of PFI-3 (SRAPs) that target the BRG1 catalytic subunit of the SWI/SNF complex increase the activity of temozolomide in glioblastoma cells
Article
作者: Yang, Chuanhe ; Miller, Duane D ; Pfeffer, Lawrence M ; Sacher, Joshua R ; Wang, Yinan ; He, Yali ; Sims, Michelle M
Glioblastoma (GBM) is the most aggressive and treatment-refractory malignant adult brain cancer. After standard of care therapy, the overall median survival for GBM is only ∼6 months with a 5-year survival <10%. Although some patients initially respond to the DNA alkylating agent temozolomide (TMZ), unfortunately most patients become resistant to therapy and brain tumors eventually recur. We previously found that knockout of BRG1 or treatment with PFI-3, a small molecule inhibitor of the BRG1 bromodomain, enhances sensitivity of GBM cells to temozolomide in vitro and in vivo GBM animal models. Those results demonstrated that the BRG1 catalytic subunit of the SWI/SNF chromatin remodeling complex appears to play a critical role in regulating TMZ-sensitivity. In the present study we designed and synthesized Structurally Related Analogs of PFI-3 (SRAPs) and tested their bioactivity in vitro. Among of the SRAPs, 9f and 11d show better efficacy than PFI-3 in sensitizing GBM cells to the antiproliferative and cell death inducing effects of temozolomide in vitro, as well as enhancing the inhibitor effect of temozolomide on the growth of subcutaneous GBM tumors.
2017-01-01Biochemical and biophysical research communications3区 · 生物学
Computational proteome-wide screening predicts neurotoxic drug-protein interactome for the investigational analgesic BIA 10-2474
3区 · 生物学
Article
作者: Shahani, Vijay M ; Windemuth, Andreas ; Morayniss, Leonard D ; Woollard, Geoffrey ; MacKinnon, Stephen S ; Laforet, Marcon ; Molinski, Steven V ; Sanchez, Cecilia G ; Kurji, Naheed ; Wodak, Shoshana J
The investigational compound BIA 10-2474, designed as a long-acting and reversible inhibitor of fatty acid amide hydrolase for the treatment of neuropathic pain, led to the death of one participant and hospitalization of five others due to intracranial hemorrhage in a Phase I clinical trial. Putative off-target activities of BIA 10-2474 have been suggested to be major contributing factors to the observed neurotoxicity in humans, motivating our study's proteome-wide screening approach to investigate its polypharmacology. Accordingly, we performed an in silico screen against 80,923 protein structures reported in the Protein Data Bank. The resulting list of 284 unique human interactors was further refined using target-disease association analyses to a subset of proteins previously linked to neurological, intracranial, inflammatory, hemorrhagic or clotting processes and/or diseases. Eleven proteins were identified as potential targets of BIA 10-2474, and the two highest-scoring proteins, Factor VII and thrombin, both essential blood-clotting factors, were predicted to be inhibited by BIA 10-2474 and suggest a plausible mechanism of toxicity. Once this small molecule becomes commercially available, future studies will be conducted to evaluate the predicted inhibitory effect of BIA 10-2474 on blood clot formation specifically in the brain.
2025-04-08
2025-01-22
·智药邦
100 项与 Cyclica Therapeutics, Inc. 相关的药物交易
登录后查看更多信息
100 项与 Cyclica Therapeutics, Inc. 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年07月22日管线快照
管线布局中药物为当前组织机构及其子机构作为药物机构进行统计,早期临床1期并入临床1期,临床1/2期并入临床2期,临床2/3期并入临床3期
药物发现
1
1
临床前
登录后查看更多信息
当前项目
登录后查看更多信息
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
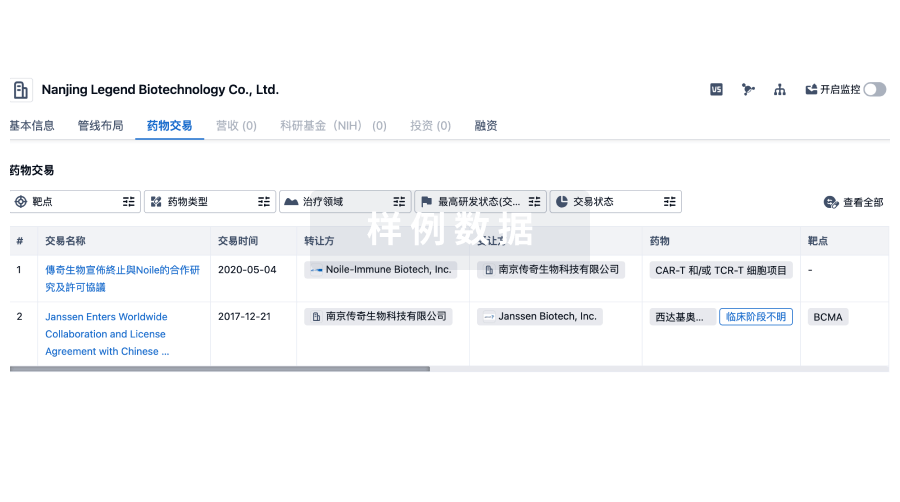
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
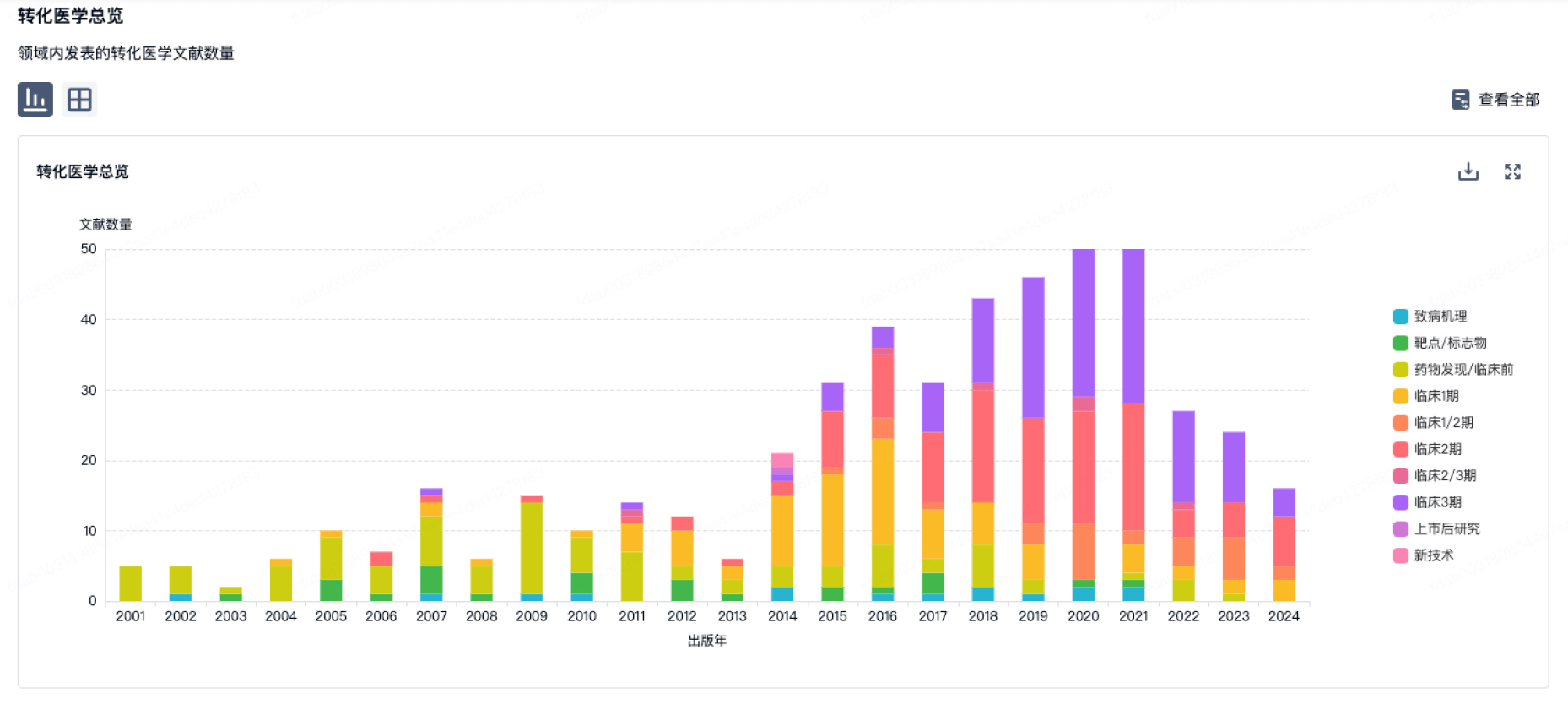
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
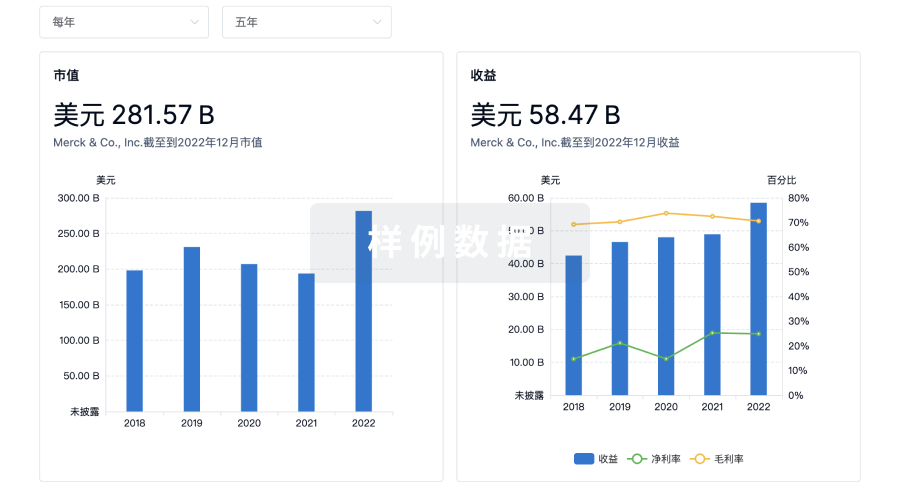
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
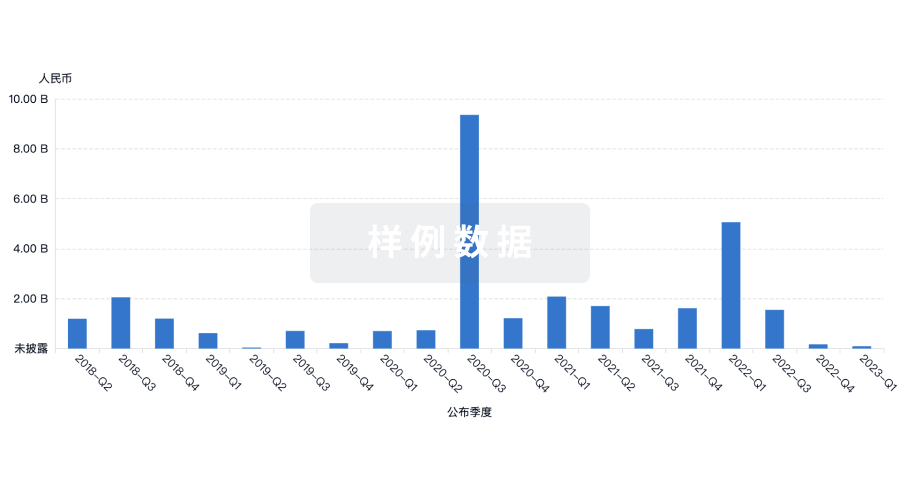
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用