预约演示
更新于:2025-08-14

National Research Foundation
更新于:2025-08-14
概览
关联
35
项与 National Research Foundation 相关的临床试验KCT0010064
Effects of Thermoelectric Element Tourniquet on Venipuncture in Adults
开始日期2024-11-13 |
申办/合作机构 |
CTRI/2023/03/050531
Evaluation of anti-Cataract activity of NIF herbal medication [Eye drop] in Senile Immature Cataract condition.
开始日期2023-04-01 |
申办/合作机构 |
NCT05679869
Effects of Natural Sounds on Attention Restoration in Virtual Reality
This study aims to examine whether listening to natural sounds in a noisy virtual reality environment compared to no natural sounds influences physiological markers.
开始日期2022-12-06 |
申办/合作机构 |

100 项与 National Research Foundation 相关的临床结果
登录后查看更多信息
0 项与 National Research Foundation 相关的专利(医药)
登录后查看更多信息
11
项与 National Research Foundation 相关的新闻(医药)2024-07-24
Overview: In 2022-2023, Sanaria® PfSPZ Vaccine and Sanaria® PfSPZ-CVac (CQ) malaria vaccines were assessed in a phase 2 clinical trial in Papua, Indonesia, against genetically diverse, naturally transmitted Plasmodium falciparum in malaria naïve, Indonesian military personnel. On July 17, 2024, the Faculty of Medicine, Universitas Indonesia (FMUI) hosted a scientific meeting in Jakarta, Indonesia attended by representatives of all the stakeholders to review the trial.
The Trial: The Sanaria-sponsored IDSPZV1 Clinical Trial was the first malaria vaccine trial ever conducted in Indonesia and the first in Southeast Asia in 30 years. This randomized, double-blind, placebo-controlled trial assessed the safety, tolerability and protective efficacy of Sanaria® PfSPZ Vaccine (radiation attenuated) and Sanaria® PfSPZ-CVac (CQ) (chemically attenuated) against naturally transmitted Plasmodium falciparum highly divergent from the vaccine strain in the vaccines. The trial was conducted by the Oxford University Clinical Research Unit (OUCRU), Indonesia, in collaboration with the FMUI, the Republic of Indonesia Army Health Centre (PUSKESAD RI), the Eijkman Molecular Biology Research Centre at the National Innovation Research Agency. Funding was provided by the US Congressionally Directed Medical Research Program and the Wellcome Trust.
The study research team consisted of over 90 individuals and there were 345 Indonesian volunteers from an Army battalion located in Pekan Baru, Riau Province,. After being fully immunized with a vaccine or normal saline placebo between May and September 2022, the battalion deployed to the Keerom District of northeastern Papua Province on the island of New Guinea until August 2023. During deployment the research team surveilled and treated more than 700 malaria cases over nine months. The team continued surveilling the volunteers for 6 months after the soldiers returned to their home base in Sumatra, treating more than 300 malaria relapses. Sanaria® PfSPZ Vaccine was immunogenic and as well-tolerated and safe as saline placebo. Sanaria® PfSPZ-CVac was also safe and well-tolerated, with expected minor transient side effects. Both vaccines provided significant protection against Plasmodium falciparum infection.
Historic first for malaria vaccines. The IDSPZV1 malaria vaccine trial is the first in history in which malaria-naive (non-exposed) individuals were immunized in a malaria-free area and then exposed to naturally transmitted malaria in a different, malaria-endemic area, thereby mimicking the situation faced by many travelers, including military personnel.
Most rigorous test of vaccine efficacy. It also provided a stringent test of vaccine efficacy because both PfSPZ Vaccine and PfSPZ-CVac (CQ) are based on a West African strain of Plasmodium falciparum and were tested for protection against malaria parasites indigenous to the island of New Guinea. These Pf parasites are genetically much more divergent from the West African strain used in the vaccine than any Plasmodium falciparum parasites anywhere in the world. The trial thus tested the ability of the vaccine to induce strong protective immunity against genetically heterogeneous malaria parasites. The efficacy results will be made public after being approved for peer-reviewed publication later this year.
The meeting:
Distinguished attendees: The meeting was attended by retired General Noch Tiranduk Mallisa, the Principal Medical Advisor to President Joko Widodo; Roy Himawan, Director of Pharmaceutical and Medical Device Resilience, Ministry of Health; Isnabarika, Clinical Trial Working Team, who represented the Director of Drugs Registration Department, Indonesian National Agency for Drugs and Food Control (BPOM RI), and additional representatives from the Indonesian Army, the Ministry of Health, the National Innovation Research Agency, the Indonesian National Agency Drugs and Food Control, FMUI, the trial’s Safety Monitoring Committee and the two Ethical Committees that provided research oversight during the trial.
The program: The more than 60 in-person attendees and 80 online attendees were welcomed by Dr. Rahayusalim, Director of Research and Community Service at FMUI, and Professor Kevin Baird, Director of OUCRU. Colonel Dr. Soni Endro Cahyo from PUSKESAD RI described the infectious threat posed by malaria to the Indonesian Armed Forces, Dr. Helen Dewi Prameswari, Chair of the Malaria Working Team, Ministry of Health, described the malaria situation in Indonesia, and Dr. Thomas L. Richie, Sanaria’s Chief Medical Officer, described the global threat posed by malaria, the need for a malaria vaccine, and Sanaria’s mission to develop a next generation product meeting the requirements set forth by the World Health Organization in 2022. The OUCRU team then showed a video describing trial implementation, including the testimony from Dr. Kennedy Siregar, the Health Commander of the battalion: “Our battalion received great benefit by participating in the trial; the study team provided important knowledge about malaria treatment,” he said. Dr. Krisin Chand, Site Medical Officer, shared the many challenges faced by the clinical team in the field, and Prof. Erni Nelwan, M.D, Ph.D, principal investigator for the trial and a professor at FMUI, described the safety, tolerability, immunogenicity and efficacy results. After a lively question and answer session moderated by Dr. Iqbal Elyazar, Program Manager of Geospatial Epidemiology and malaria expert at OUCRU, Dr. Richie described pending analyses and Sanaria’s clinical development plan for bringing a genetically attenuated, genetically engineered, next generation malaria vaccine, called Sanaria® PfSPZ-LARC2 Vaccine, to international licensure and deployment. Dr. Baird closed the meeting with a summary of key accomplishments and plans.
疫苗临床2期临床结果
2023-10-11
A massive computational analysis of microbiome datasets has more than doubled the number of known protein families. This is the first time protein structures have been used to help characterize the vast array of microbial 'dark matter.'
Imagine researchers exploring a dark room with a flashlight, only able to clearly identify what falls within that single beam. When it comes to microbial communities, scientists have historically been unable to see beyond the beam -- worse, they didn't even know how big the room is.
A new study published online October 11, 2023 in Nature highlights the vast array of functional diversity of microbes through a novel approach to better understand microbial communities by looking at protein function within them. The work was led by a team of scientists at the U.S. Department of Energy (DOE) Joint Genome Institute (JGI), a DOE Office of Science User Facility located at Lawrence Berkeley National Laboratory (Berkeley Lab), and collaborators across multiple other research centers around the world.
"We've more than doubled the number of protein families known up until now, and identified many novel structure predictions," said lead author on the paper Georgios Pavlopoulos, now a research director at the Biomedical Sciences Research Center Alexander Fleming. "This was a massive analysis of 1.3 billion proteins with massively parallel computations."
Guided by JGI scientists, the team embarked on a mission to unveil the mysteries concealed within the "dark" functional realm. Their focus sharpened on deciphering the intricate world of protein functional diversity: the novel protein families and novel functions in as-yet unveiled microbes. Harnessing the collective power of more than 26,000 microbiome datasets, all accessible through the publicly available Integrated Microbial Genomes & Microbiomes (IMG/M) database, they successfully crafted the Novel Metagenome Protein Families (NMPF) Catalog.
"We can now analyze new datasets by comparing against these protein families, or further analyze the protein families in order to predict new functions," said Nikos Kyrpides, senior author of the study and head of the JGI's Microbiome Data Science group.
Shining a Light on Functional "Dark Matter"
Microbial communities living everywhere from soils and stomachs to the deep sea are capable of doing a lot of unique things when it comes to energy cycles -- turning biomass into things like ethanol or hydrogen, or solar energy into hydrogen.
Microbial communities are also incredibly difficult to study. Many of the microbes within them cannot be cultivated in lab settings. Since each microbial community has its own unique makeup of microbe players and the functions they perform, artificially replicating a whole community is impossible.
Metagenomic sequencing allows researchers to study the entire genetic makeup of these communities via whole genome sequencing of the samples, without being able to distinguish which gene belongs to each individual microbial species within a community. Therefore, the process hinges on referencing to existing genome sequences.
Some of these proteins are what the scientists call "known knowns" -- that is, they are similar to genes with known function. Others are called "known unknowns" -- that is, they are similar to previously known genes from isolate organisms, but we still aren't sure of their function.
However, if a gene in the community doesn't match any of the previously known genes from isolates, there isn't much scientists can tell about its function or its origin. As a result, these genes were typically discarded from any analysis as useless information. These represent the "unknown unknowns" because they aren't similar to anything we've already defined.
"A huge percentage -- around 30-50% of the protein families that we knew so far -- still does not have any known function, but we knew the families," Kyrpides said. Yet, "almost 20 years of metagenomic data and metagenomic analysis, and still there has been no real analysis of protein families from metagenomes per se."
Recently, other research teams have leveraged the power of artificial intelligence to decode the language of protein sequences and obtain hints of their possible functions. Yet these efforts were limited to the realm of already-known protein sequences.
"In this endeavor, we have not only ventured into the uncharted territory of understanding the vast landscape of functional diversity, but we have also pushed the boundaries by applying AI methodologies to unravel their roles," Pavlopoulos said. "Consequently, we have amassed an extensive repository of groundbreaking insights, significantly expanding the horizons of potential functions across various categories of proteins, including those with pivotal applications in biotechnology, such as DNA editing enzymes."
Leveraging Protein Families in a New Way
The discovery of new protein families had started to plateau in recent years, perhaps suggesting that scientists had "captured" much of the diversity out there, even if it hadn't yet defined what it did, exactly. But what kind of diversity might those "unknown unknowns" hold?
The team started with 8 billion metagenome genes from IMG (the study also references data from the JGI's Genomes from Earth's Microbiome, or GEM catalog). Then they removed any genes with even a remote similarity to previously known genes, leaving them with around 1.2 billion novel genes.
They took what they were left with and clustered them into families. From there they focused on families with at least 100 members.
"If you have 100 sequences, the quality of the cluster is significantly higher because it is very hard to have 100 sequences from different locations or habitats that align very well, randomly," Kyrpides explained. "Replicating that 100 times would have been almost impossible."
When the team was finished with this phase, they found that the protein family diversity within this metagenomic space (the "unknown unknowns") was vastly greater than that of the reference genomes -- by at least double.
"As we keep on adding more samples, we're getting more protein families," Kyrpides said. "In a few years, as we keep on sequencing more metagenomes, some of the clusters that have currently 50 members or more will grow to 100 members or more as well. So, we're saying diversity has doubled, but in reality it could be three or four or five or tenfold more out there."
Digging Further into an Array of Diversity
While the team didn't drill down function, they were able to further characterize these families. They divided the protein families up by environment and found only 7% of protein families were shared across all eight environmental categories. Instead, families preferred a specific environment -- whether that be soil, animal hosts, marine ecosystems, etc.
"So, they must be doing something interesting or important for that habitat," Pavlopoulos explained. "That is definitely material that the scientific community now can use further. Let's say somebody is working on soil environments or the human body -- they may take some of those families and try to functionally characterize them because they are very specific to that habitat."
Taxonomic analysis found that the majority of these protein families belonged to bacteria and viruses, though 6 million of the sequences evaded classification. Researchers also tried to hone in on the function of the genes via 3D modeling, and comparing structures of the unknown to those of the known -- similar structure equates to high likelihood of similar function. The team also identified protein families with completely novel structures.
The computational power to perform this level of analysis hinged on access to the National Energy Research Scientific Computing Center, another user facility at Berkeley Lab.
"It's also a credit to Aydin Buluç's team with Berkeley Lab's Applied Mathematics and Computational Research Division," Pavlopoulos said. "They developed parallel algorithms to perform 'all-vs-all' comparisons and graph clustering able to run in such highly parallel infrastructures."
This is the first time protein structures have been used to help characterize the vast array of microbial dark matter. The study took roughly two years to complete, with only about 20,000 metagenomes sequenced at the time. Now, that number is closer to 60,000.
"There is still 70-80% of known microbial diversity out there that is not yet captured genomically," Kyrpides said. "So, that diversity is definitely holding a lot of new secrets in terms of functional diversity as well."
Researchers from Harvard University, Indiana University. University of Crete (Greece). Georgia Institute of Technology, Michigan State University, Lawrence Livermore National Laboratory, University of Washington, Centre for Research & Technology Hellas (Greece), Aristotle University of Thessalonica (Greece), and the University of California, Berkeley were also involved in the work. Other authors on the paper are Fotis Baltoumas, Sirui Liu, Oguz Selvitopi, Antonio Camargo Stephen Nayfach, Ariful Azad, Simon Roux, Lee Call, Natalia N. Ivanova, I Min Che, David Paez-Espino, Evangelos Karatzas, Novel Metagenome Protein Families Consortium, Ioannis Iliopoulos, Konstantinos Konstantinidis, James M. Tiedje, Jennifer Pett-Ridge, David Baker, Axel Visel, Christos A. Ouzounis, and Sergey Ovchinnikov.
2023-09-29
Diagnosis of Plasmodium falciparum malaria using rapid diagnostic tests and treatment with artemisinin derivatives, the main component of the malaria treatments recommended by the World Health Organization (WHO), are under threat in the Horn of Africa. Scientists have detected the emergence and spread in Eritrea of parasites with both artemisinin resistance and genome modifications that prevent their detection with rapid diagnostic tests, thereby jeopardizing malaria control and elimination campaigns in the region and potentially elsewhere in Africa.
Diagnosis of Plasmodium falciparum malaria using rapid diagnostic tests and treatment with artemisinin derivatives, the main component of the malaria treatments recommended by the World Health Organization (WHO), are under threat in the Horn of Africa. Scientists from the Laboratory of Parasitology and Medical Mycology at the University of Strasbourg and Strasbourg University Hospital, in collaboration with the Eritrean Ministry of Health, the Institut Pasteur, Columbia University in New York and WHO, have detected the emergence and spread in Eritrea of parasites with both artemisinin resistance and genome modifications that prevent their detection with rapid diagnostic tests, thereby jeopardizing malaria control and elimination campaigns in the region and potentially elsewhere in Africa.
The research results were published on September 28, 2023 in the New England Journal of Medicine.
Malaria, a disease caused by parasites of the genus Plasmodium, represents a major public health problem worldwide. Plasmodium falciparum, responsible for severe forms, is found mainly in Sub-Saharan Africa, where a child dies of malaria every two minutes. In 2021, 247 million cases and 619,000 deaths were reported, a 6.4% increase compared with 2019.
Current strategies to fight malaria involve prevention, with the use of insecticide-treated bed nets; diagnosis, with the introduction of rapid diagnostic tests; and treatment, which must be effective. For more than 15 years, treatment for malaria episodes (which alternate between fever, shivering and chills, and severe sweating) caused by Plasmodium falciparum in Sub-Saharan Africa has been based on artemisinin-based combination therapies (ACTs). These highly effective treatments combine a potent, fast-acting artemisinin derivative and a partner drug with a long half-life that acts more slowly to eliminate residual parasites.
Unfortunately, in 2008, the first cases of artemisinin resistance were detected in South-East Asia. Resistance was defined by delayed parasite clearance from the bloodstream of patients treated with an ACT. In recent years, Plasmodium falciparum artemisinin resistance has also been reported in two regions of Sub-Saharan Africa, in Central Africa (Rwanda) and East Africa (Uganda).
In this latest study, the scientists present the results of clinical trials conducted between 2016 and 2019 in Eritrea to assess the efficacy of two ACT treatments (artesunate/amodiaquine and artemether/lumefantrine) recommended for treating uncomplicated P. falciparum malaria. The clinical trials also aimed to estimate the proportion of patients with persistent P. falciparum parasitemia on day 3, the day after the last dose of ACT. In addition, the authors sought to identify molecular signatures in the Pfkelch13 gene associated with artemisinin resistance in parasites and to detect deletions of the hrp2 and hrp3 genes which are known to render rapid diagnostic tests ineffective in detecting parasites.
The data obtained revealed another hotspot of artemisinin resistance, in Eritrea. This novel area of resistance is more worrying than those observed in Rwanda and Uganda as the investigations reveal the emergence and spread of a new artemisinin-resistant variant, Pfkelch13 622I, accompanied by hrp2 and hrp3 gene deletions in around 17% of cases, making it impossible to detect these parasite strains using rapid tests. According to the published data, it seems that the phenomenon is not recent and that these strains have been circulating in western Eritrea for several years.
The findings therefore show how P. falciparum is capable of evading strategies introduced to control and eliminate malaria. "These data are a real cause for concern and undermine the quality of the health management of malaria patients in the region," warns Dr. Selam Mihreteab, a contributor to the study in Eritrea at the National Malaria Control Program, Ministry of Health. "We need to develop constant surveillance of the evolution of these parasites and their ability to spread," adds Dr. Lucien Platon, a PhD student at the Institut Pasteur (Malaria Parasite Biology and Vaccines Unit). "The strategies implemented in the Horn of Africa are under threat, not only because artemisinin resistant parasites are not detected by rapid tests but also because of the ability of malaria vectors to resist insecticides and because we have recently seen the arrival of a new mosquito species, Anopheles stephensi, capable of transmitting these strains in urban environments. There is a risk that these biological threats could lead to a rapid spread of these parasites in the region and beyond," analyzes Professor Didier Ménard, Director of the Institute of Parasitology and Tropical Diseases at the University of Strasbourg and a scientist in the Malaria Parasite Biology and Vaccines Unit at the Institut Pasteur.
Over the past two decades, the proactive strategy pursued by the Eritrean government has led to a significant reduction in malaria-related morbidity and mortality in the country. These new data seem to confirm that monitoring the emergence and spread of drug resistance must be a priority in areas such as Eritrea, where strategies to reduce malaria transmission are being effectively implemented, and that there is an urgent need to develop and introduce innovative control strategies.
This research received support from the Bill and Melinda Gates Foundation (WHO), the Global Fund (Ministry of Health in Eritrea), the Institut Pasteur, the French Government (National Research Agency), the University of Strasbourg (IdEX Program), and the United States Department of Defense and National Institutes of Health.
100 项与 National Research Foundation 相关的药物交易
登录后查看更多信息
100 项与 National Research Foundation 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年07月21日管线快照
管线布局中药物为当前组织机构及其子机构作为药物机构进行统计,早期临床1期并入临床1期,临床1/2期并入临床2期,临床2/3期并入临床3期
其他
1
登录后查看更多信息
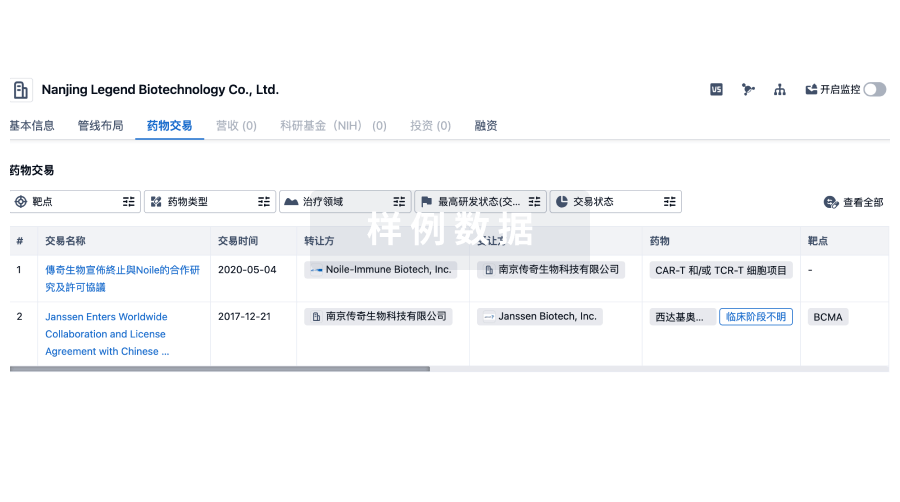
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
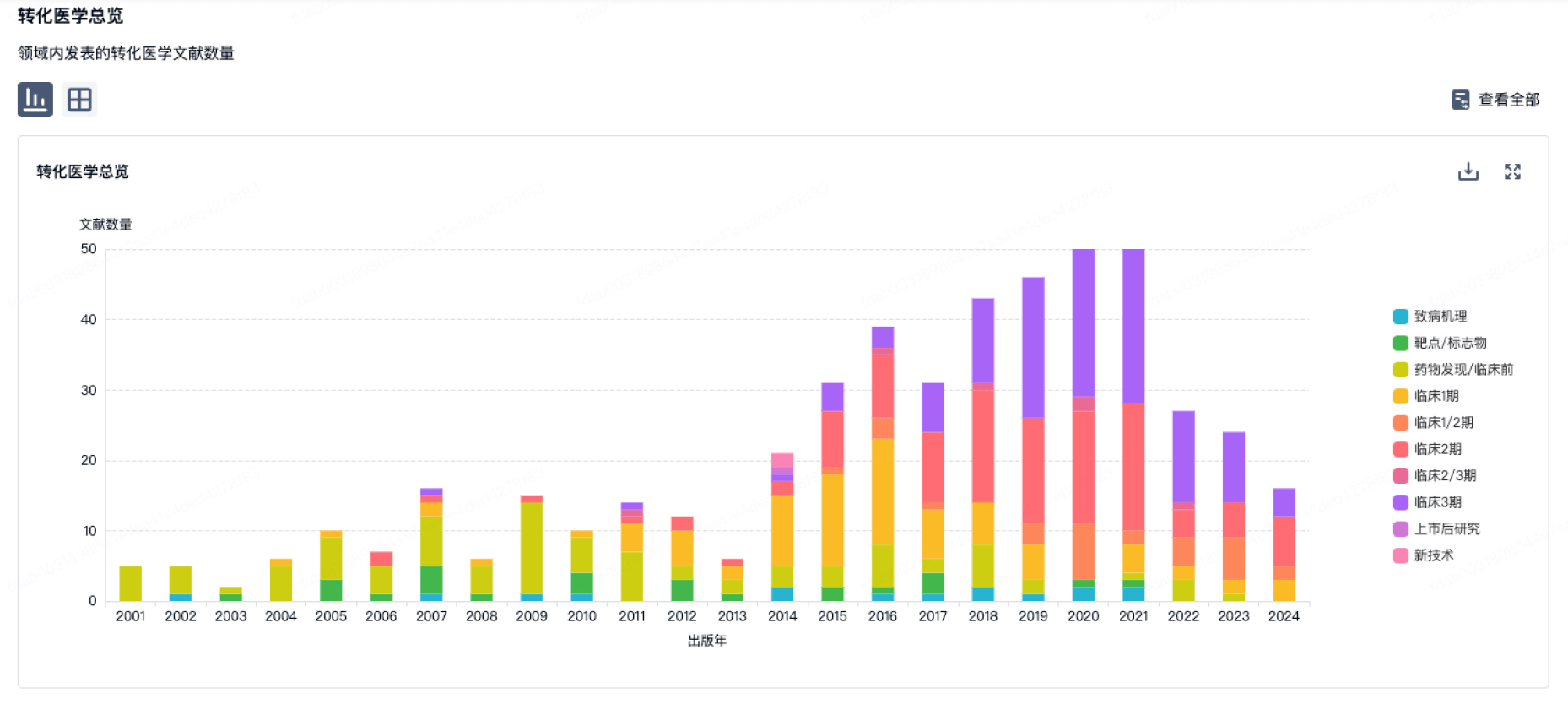
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
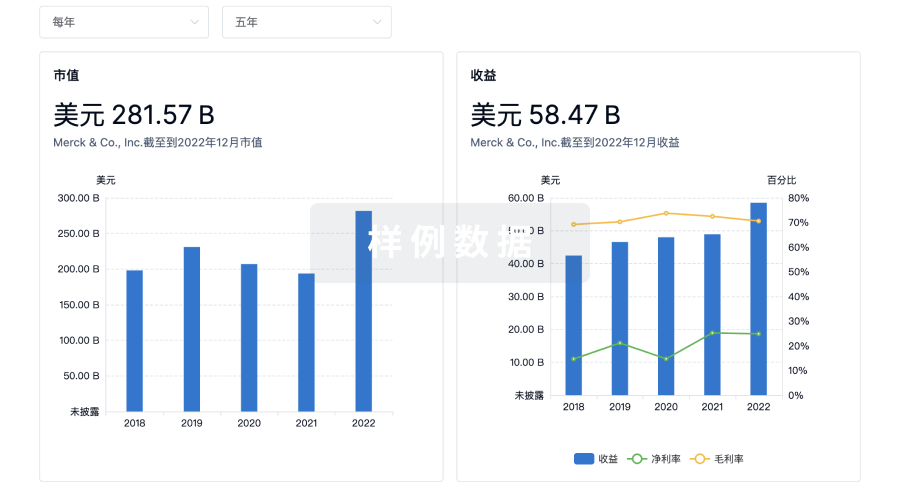
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
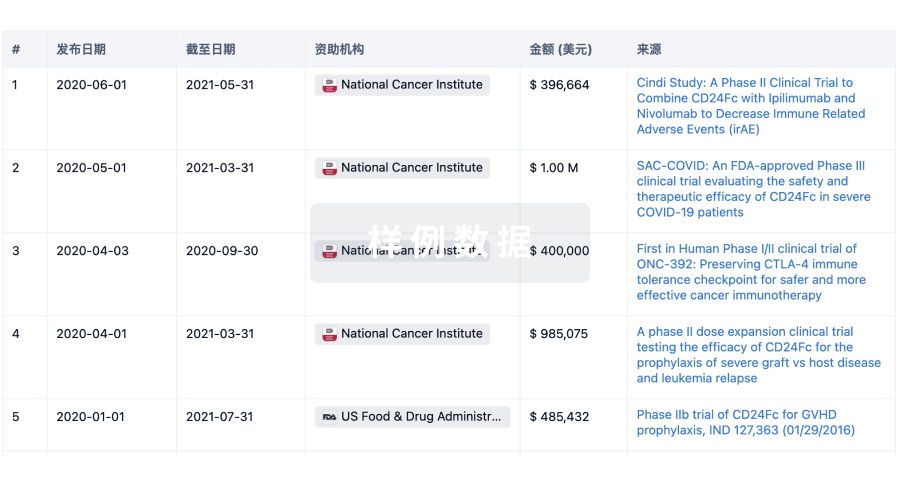
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用