预约演示
更新于:2025-05-07
THR x AR
更新于:2025-05-07
关联
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |

100 项与 THR x AR 相关的临床结果
登录后查看更多信息
100 项与 THR x AR 相关的转化医学
登录后查看更多信息
登录后查看更多信息
2025-04-21Chemical Research in Toxicology
Combining Molecular Docking and Pharmacophore Models Predicts Ligand Binding of Endocrine-Disrupting Chemicals to Nuclear Receptors
Article
作者: Sellami, Asma ; Lagarde, Nathalie ; Montes, Matthieu
2024-12-01Toxicological Sciences
Profiling the endocrine-disrupting properties of triazines, triazoles, and short-chain PFAS
Article
作者: Baygildiev, Timur ; Irwan, Jenny ; van Duursen, Majorie B M ; Escher, Sylvia E ; Carlier, Maxim P ; Hamers, Timo ; Cenijn, Peter H
2023-07-17Chemical research in toxicology
High Throughput Read-Across for Screening a Large Inventory of Related Structures by Balancing Artificial Intelligence/Machine Learning and Human Knowledge.
Article
作者: Rathman, James F ; Magdziarz, Tomasz ; Hobocienski, Bryan ; Yang, Chihae ; Ribeiro, João Vinícius ; Kulkarni, Sunil ; Mostrag, Aleksandra ; Barton-Maclaren, Tara
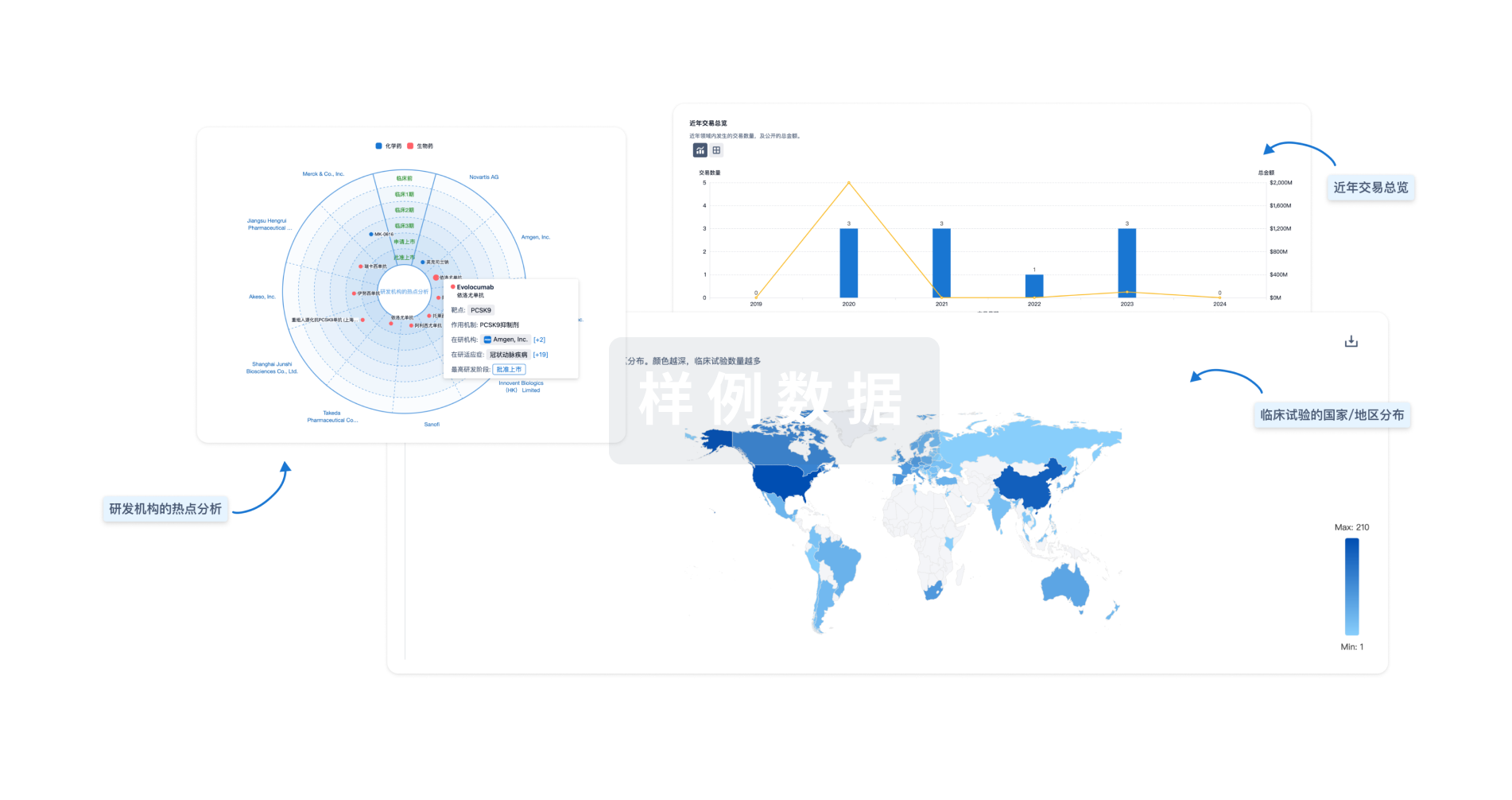
分析
对领域进行一次全面的分析。
登录
或
生物医药百科问答
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用