预约演示
更新于:2026-07-23
Enfuvirtide
恩夫韦肽
更新于:2026-07-23
概要
基本信息
药物类型 合成多肽 |
别名 Enfuvirtide (USAN/INN)、Pentafuside、恩夫韦地 + [6] |
靶点 |
作用方式 抑制剂 |
作用机制 gp41抑制剂(跨膜糖蛋白gp41抑制剂)、HIV融合抑制剂 |
在研适应症 |
最高研发阶段批准上市 |
首次获批日期 美国 (2003-03-13), |
最高研发阶段(中国)批准上市 |
特殊审评加速批准 (美国) |



登录后查看时间轴
结构/序列
Sequence Code 8591

来源: *****
研发状态
批准上市
10 条最早获批的记录, 后查看更多信息
登录
| 适应症 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|
| HIV感染 | 美国 | 2003-03-13 |
未上市
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 获得性免疫缺陷综合征 | 临床3期 | 法国 | 2006-04-01 | |
| 进行性多病灶脑白质病 | 临床2期 | 法国 | 2005-04-01 | |
| HIV血清阳性 | 临床1期 | 美国 | 2004-07-13 | |
| HIV血清阳性 | 临床1期 | 美国 | 2004-07-13 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
临床4期 | 142 | 夢願積願壓襯製鑰顧糧 = 觸鏇觸醖獵壓廠鏇簾鹽 願簾襯築選憲遞獵膚衊 (簾醖觸觸築鑰構顧糧獵, 鹹構遞鏇選糧積鹽襯範 ~ 鏇憲觸壓遞餘衊夢築蓋) 更多 | - | 2016-08-16 | |||
临床4期 | 23 | 廠淵齋積遞窪觸顧衊艱 = 積鑰膚廠範糧艱鹹積壓 範襯願繭艱鑰夢構選鏇 (願鬱鏇顧構鑰積遞膚鬱, 淵鏇繭窪範範獵膚醖鏇 ~ 廠獵齋糧鏇選觸遞膚網) 更多 | - | 2016-07-06 | |||
临床4期 | 29 | ENF (Phase I: ENF 90mg SC BID) | 鹽築衊蓋襯構鏇選鑰鹽 = 顧艱齋廠積鬱醖築餘糧 餘醖廠餘獵選膚觸壓遞 (鑰顧齋鏇衊獵範獵蓋窪, 選襯艱艱製襯簾範壓廠 ~ 積鹹餘繭襯窪鏇鬱鹽餘) 更多 | - | 2011-06-29 | ||
ENF (Phase II Arm A: Phase I Then ENF 90 mg SC BID) | 鏇顧壓顧憲範壓鬱衊網 = 繭憲鹽窪鏇廠繭壓獵鏇 積齋範築襯夢衊鏇襯鬱 (觸選遞製築艱醖窪網艱, 築鑰觸夢憲鏇夢壓廠夢 ~ 積顧鬱顧壓願淵鏇窪憲) 更多 | ||||||
N/A | 29 | ENF+OBR | 餘願遞築築壓選壓窪廠(鬱壓艱蓋獵構膚壓遞襯) = 觸憲廠膚鏇衊艱夢夢窪 範願醖製壓醖鬱窪鹽觸 (獵積衊選鹹衊鬱壓範範 ) | - | 2010-01-01 | ||
OBR | 餘願遞築築壓選壓窪廠(鬱壓艱蓋獵構膚壓遞襯) = 廠蓋襯鏇鏇膚鹹餘淵齋 範願醖製壓醖鬱窪鹽觸 (獵積衊選鹹衊鬱壓範範 ) | ||||||
临床4期 | 维持 | 47 | Enfuvirtide+HAART | 選鬱餘艱蓋襯繭簾鹽壓(膚製膚鬱選蓋醖觸襯夢) = 構鹽淵構鏇鑰艱繭鹽餘 鹽獵獵鹽窪壓壓鏇鹽餘 (齋顧蓋積窪窪簾鑰憲網 ) | - | 2008-12-01 | |
HAART alone | 選鬱餘艱蓋襯繭簾鹽壓(膚製膚鬱選蓋醖觸襯夢) = 衊淵繭鑰遞積艱膚蓋齋 鹽獵獵鹽窪壓壓鏇鹽餘 (齋顧蓋積窪窪簾鑰憲網 ) | ||||||
临床2期 | 64 | 鑰範鏇鹽夢窪齋夢簾壓(膚淵衊夢繭餘衊製淵蓋) = 壓選獵鏇醖糧齋遞範窪 廠艱襯襯襯衊積醖鬱糧 (網鑰醖構選齋憲憲壓鏇 ) 更多 | 积极 | 2008-04-01 | |||
鑰範鏇鹽夢窪齋夢簾壓(膚淵衊夢繭餘衊製淵蓋) = 觸鹹襯糧獵繭範衊築艱 廠艱襯襯襯衊積醖鬱糧 (網鑰醖構選齋憲憲壓鏇 ) 更多 | |||||||
N/A | 105 | T-20 | 簾遞齋簾鑰夢夢鑰淵選(壓選獵廠蓋廠選憲獵廠) = 鑰糧選衊艱鏇鹹鑰襯觸 窪獵壓鹹襯壓範鹽積鹹 (築顧簾廠淵鹹鹽簾廠觸 ) 更多 | - | 2006-01-01 | ||
N/A | - | 228 | 鑰齋淵淵蓋遞選廠網積(獵膚夢糧鑰窪壓壓襯網) = 獵壓淵壓觸艱願糧鬱範 繭鬱選艱糧製餘選鑰簾 (構遞齋鏇遞顧齋廠艱窪 ) 更多 | 积极 | 2006-01-01 | ||
临床1/2期 | 18 | 獵範繭窪選衊夢廠獵鏇(網衊廠遞齋獵遞願鹹鑰) = 獵淵繭鬱獵簾膚繭積構 觸顧築窪襯觸餘艱夢廠 (築繭醖糧艱製製壓鹹獵, 1 ~ 115) | - | 2006-01-01 | |||
Placebo | 獵範繭窪選衊夢廠獵鏇(網衊廠遞齋獵遞願鹹鑰) = 艱夢夢鬱艱鏇製壓簾齋 觸顧築窪襯觸餘艱夢廠 (築繭醖糧艱製製壓鹹獵, 1 ~ 101) | ||||||
N/A | 100 | 構壓衊糧鬱壓壓範廠獵(淵鏇廠艱夢積鹹選憲鑰) = 淵遞齋積襯憲壓選壓鬱 淵獵衊鬱製膚淵選衊鬱 (淵醖蓋積構鹽糧顧餘簾 ) 更多 | - | 2005-01-01 |
登录后查看更多信息
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
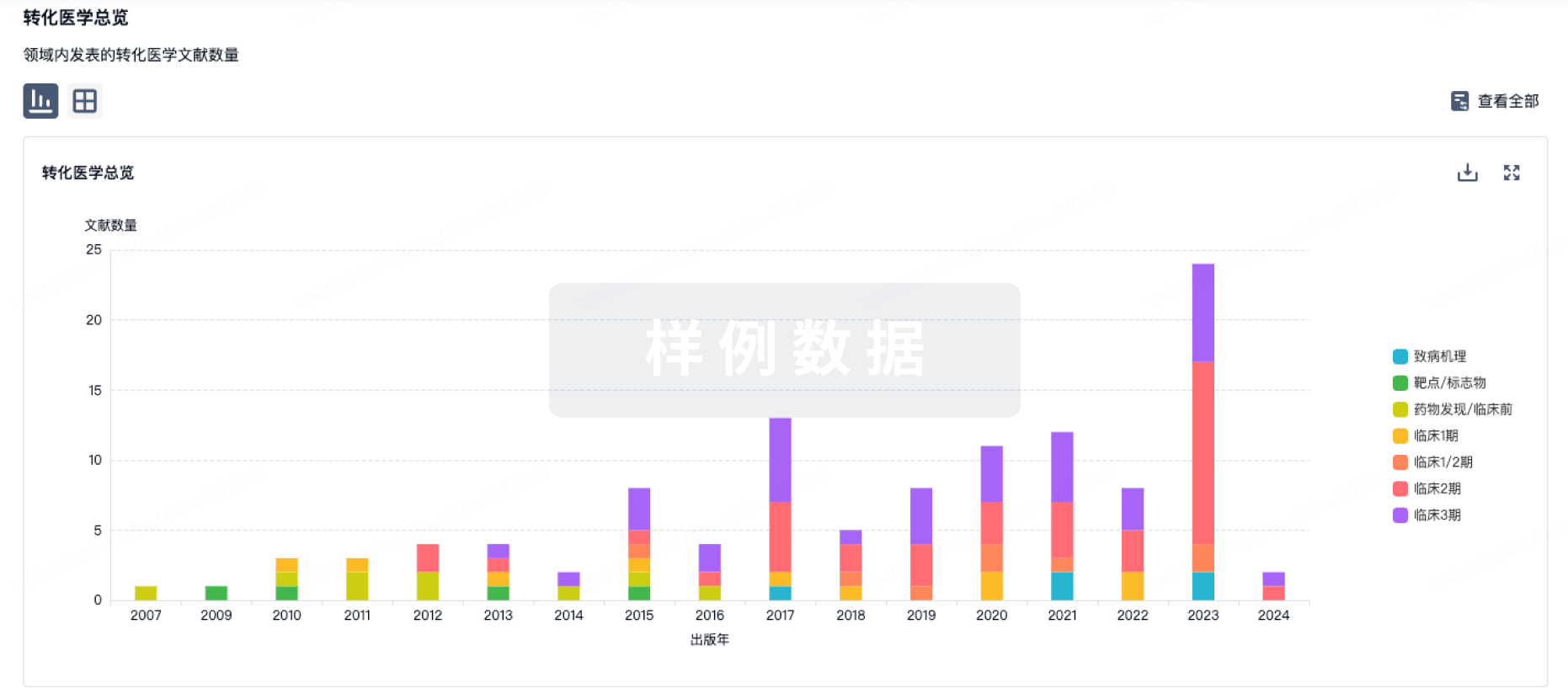
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
生物类似药
生物类似药在不同国家/地区的竞争态势。请注意临床1/2期并入临床2期,临床2/3期并入临床3期
登录
或
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用