预约演示
更新于:2026-01-29

Hong Kong Baptist University
更新于:2026-01-29
概览
标签
肿瘤
皮肤和肌肉骨骼疾病
消化系统疾病
小分子化药
适配体
中药
疾病领域得分
一眼洞穿机构专注的疾病领域

技术平台
公司药物应用最多的技术
靶点
公司最常开发的靶点
关联
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |

ChiCTR2500113491
Divergent Acute Exercise-Induced Intramyocellular Lipid (IMCL) Responses in Overweight Adults With and Without Prediabetes
NCT07243223
Epidemiological Profiles, Traditional Chinese Medicine Syndrome, and Biomarkers of Urinary Incontinence in Older Hong Kong Women: A Cross-sectional Study
ChiCTR2500112364
Epidemiological Profiles, Traditional Chinese Medicine Syndrome, and Biomarkers of Urinary Incontinence in Older Hong Kong Women: A Cross-sectional Study
100 项与 香港浸会大学 相关的临床结果
登录后查看更多信息
登录后查看更多信息
2026-04-01NEURAL NETWORKS
Full-spectrum prompt tuning with sparse MoE for open-set recognition
Article
作者: Chen, Jun ; Xie, Yifei ; Geng, Chuanxing ; Hu, Yahao ; Chen, Man ; Pan, Zhisong
Recent advances in open-set recognition leveraging vision-language models (VLMs) predominantly focus on improving textual prompts by exploiting (high-level) visual features from the final layer of the VLM image-encoder. While these approaches demonstrate promising performance, they generally neglect the discriminative yet underutilized (low-level) visual details embedded in shallow layers of the image encoder, which also play a critical role in identifying unknown classes. More critically, despite their significance, integrating such low-level part-based features into textual prompts-typically reflecting high-level conceptual information-remains nontrivial due to inherent disparities in feature representation. To address these issues, we innovatively propose Full-Spectrum Prompt Tuning with Sparse Mixture-of-Experts (FSMoE), which leverages the full-spectrum visual features across different layers to enhance the textual prompts. Specifically, two complementary groups of textual tokens are strategically designed, i.e., high-level textual tokens and low-level textual tokens, where the former interacts with high-level visual features, while the latter for the low-level visual counterparts, thus comprehensively enhancing textual prompts through full-spectrum visual features. Furthermore, to mitigate the redundancy in low-level visual details, a sparse Mixture-of-Experts mechanism is introduced to adaptively select and weight the appropriate features from all low-level visual features through collaborative efforts among multiple experts. Besides, a routing consistency contrastive loss is also employed to further enforce intra-class consistency among experts. Extensive experiments demonstrate the effectiveness of our FSMoE.
2026-04-01BIOORGANIC & MEDICINAL CHEMISTRY
Design, synthesis and biological evaluation of new ent-11α-hydroxy-15-oxo-kaur-16-en-19-oic-acid (5F) derivatives as potential antitumor agents
Article
作者: Seng, Zhongyi ; Zhang, Hongjie ; Liu, Kanglun ; Du, Yinxiao ; Zou, Juan ; Xia, Yixuan ; Chen, Baisen ; Lam, Chushing ; Zhao, Chenliang
Ent-11α-hydroxy-15-oxo-kaur-16-en-19-oic-acid (5F) is a naturally occurring ent-kaurane diterpenoid isolated from the traditional Chinese herbal medicine Pteris semipinnata L., a fern plant known for its reported antitumor properties. In an effort to expand the pool of natural scaffold-based compounds for anticancer purposes, novel derivatives of 5F have been synthesized by modifying functional groups at C-11 and C-19. These derivatives have been evaluated for their anti-proliferative activities against a panel of cancer cell lines. Among them, compound 13 exhibited approximately 27 times greater potency than 5F in HCT116 cells, with an IC50 value of 0.232 μM. In an HCT116 xenograft mouse model, 13 displayed superior tumor inhibitory effects compared to fluorouracil (5-FU).
2026-03-01JOURNAL OF PHARMACEUTICAL AND BIOMEDICAL ANALYSIS
SuHeXiang Wan in the treatment of stroke: Prediction potentially active metabolites using a combination of in silico analysis and experimental viability assessment
Article
作者: Shen, Lingyu ; Lu, Aiping ; Xu, Anqi ; Chen, Yupeng ; Guan, Daogang ; Li, Wenxing
SuHeXiang Wan (SHXW) is a renowned traditional Chinese medicine (TCM) prescription for treating stroke, but its active components remain largely unidentified. This study aimed to screen potential active compounds of SHXW and reveal their underlying mechanisms in stroke treatment. Ingredients and compounds in SHXW were obtained from TCM databases and subjected to initial screening based on ADMET and physicochemical properties, followed by target gene prediction for each filtered compound. A comprehensive network of filtered compound-target gene-stroke pathogenic gene was constructed and optimized using a multi-objective optimization algorithm. Seventeen potential active compounds were identified, which primarily influenced neuroactive ligand-receptor interactions, arachidonic acid metabolism, and several signaling pathways including PI3K-Akt, calcium, and cAMP. Using an oxygen-glucose deprivation and reoxygenation (OGD/R) model, cirsiliol was identified as the lead compound, significantly enhancing cell viability and morphology, decreasing apoptosis, and reducing oxidative stress and inflammatory responses. Molecular docking and dynamics simulations revealed that cirsiliol stably binds to the NADPH binding pocket of CBR1 protein. Further experiments demonstrated that cirsiliol decreased 4-hydroxynonenal (4-HNE, a substrate of CBR1) levels. This study provides a methodological framework for screening active compounds in TCM prescriptions. The neuroprotective effects of cirsiliol against ischemic stroke merit further investigation.
100 项与 香港浸会大学 相关的药物交易
登录后查看更多信息
100 项与 香港浸会大学 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年07月22日管线快照
管线布局中药物为当前组织机构及其子机构作为药物机构进行统计,早期临床1期并入临床1期,临床1/2期并入临床2期,临床2/3期并入临床3期
药物发现
3
9
临床前
临床2期
1
5
其他
登录后查看更多信息
当前项目
登录后查看更多信息
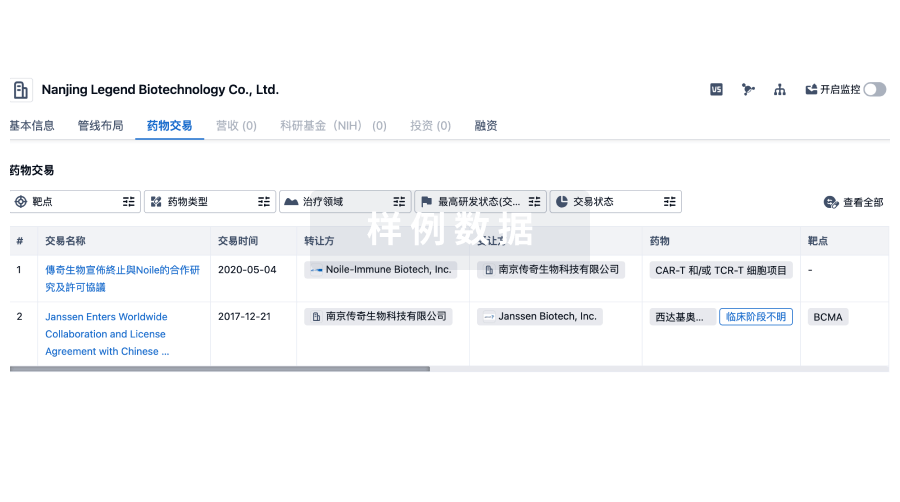
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
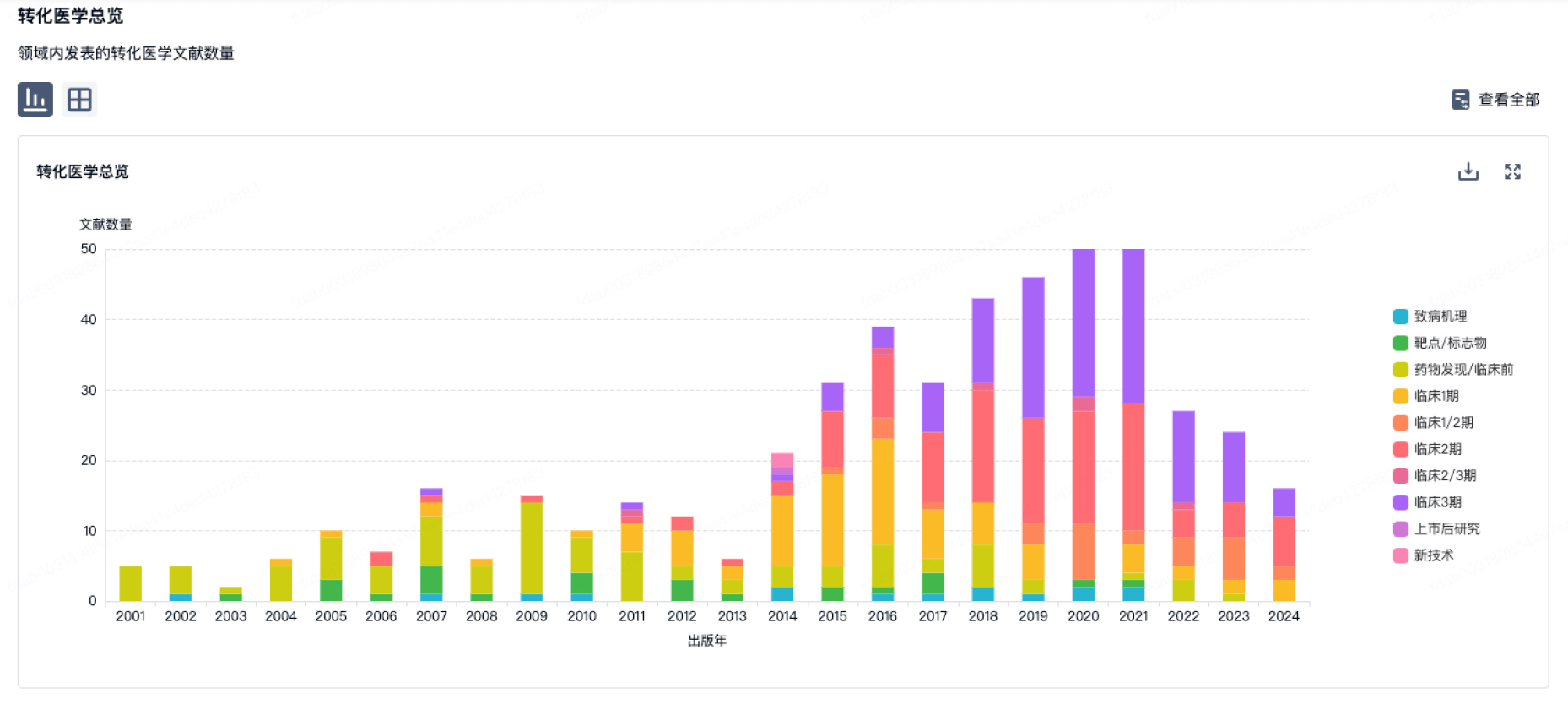
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
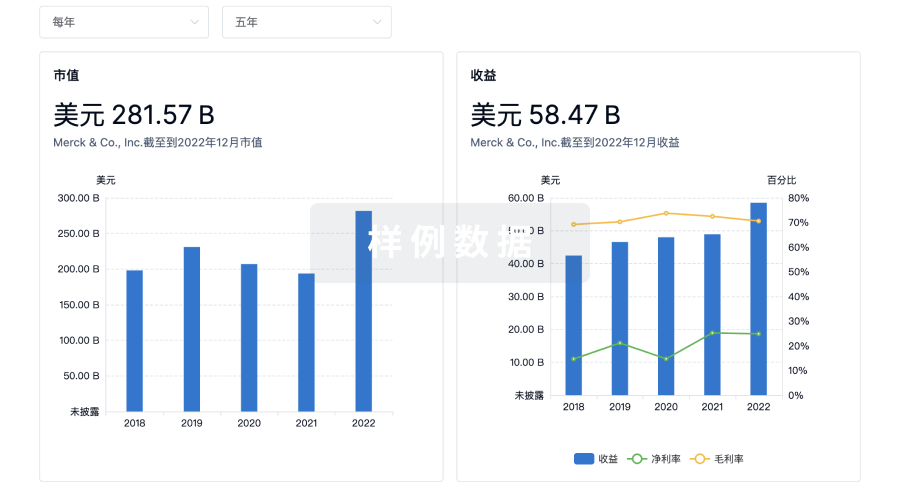
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
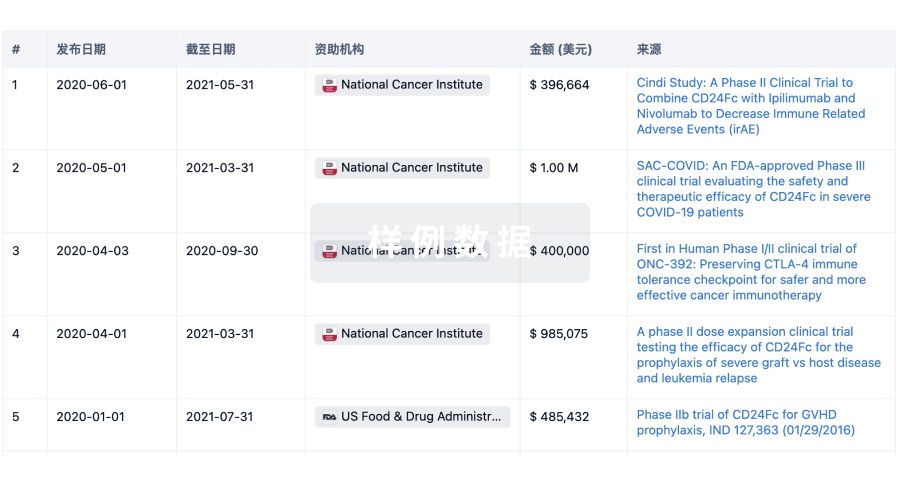
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用