预约演示
更新于:2026-05-30
4-Phenylbutyrate
4-苯基丁酸酯
更新于:2026-05-30
概要
基本信息
原研机构 |
权益机构- |
最高研发阶段临床前 |
首次获批日期- |
最高研发阶段(中国)临床前 |
特殊审评- |




登录后查看时间轴
结构/序列
分子式C10H12O2 |
InChIKeyOBKXEAXTFZPCHS-UHFFFAOYSA-N |
CAS号1821-12-1 |
关联
9
项与 4-苯基丁酸酯 相关的临床试验NCT04531878
Jian-She Wang of Children's Hospital of Fudan University
NCT04421677
Safety and Tolerability of Phenylbutyrate in Inclusion Body Myositis

JPRN-UMIN000012782
Efficacy and safety of 4-phenylbutyrate in refractory cholestatic disease including progressive familial intrahepatic cholestasis, primary biliary cirrhosis, primary sclerosing cholangitis and Alagille syndrome. - Efficacy and safety of 4-phenylbutyrate in refractory cholestatic disease including progressive familial intrahepatic cholestasis, primary biliary cirrhosis, primary sclerosing cholangitis and Alagille syndrome.
100 项与 4-苯基丁酸酯 相关的临床结果
登录后查看更多信息
100 项与 4-苯基丁酸酯 相关的转化医学
登录后查看更多信息
100 项与 4-苯基丁酸酯 相关的专利(医药)
登录后查看更多信息
1,715
项与 4-苯基丁酸酯 相关的文献(医药)2026-07-01CHEMICO-BIOLOGICAL INTERACTIONS
Isopsoralen-induced hepatotoxicity: The regulatory role of endoplasmic reticulum stress-triggered mitochondrial dysfunction and apoptosis
Article
作者: Yu, Yingli ; Lou, Pengshuo ; Wang, Chen ; Yuan, Mingxin ; Zhang, Yue ; Zhou, Kun ; Han, Yiping
OBJECTIVE:
Fructus Psoraleae is a commonly used herb in traditional Chinese medicine, widely applied in the treatment of osteoporosis, vitiligo, and other diseases. Isopsoralen, as the core active component of Fructus Psoraleae, possesses both pharmacological effects and toxic risks, among which hepatotoxicity is a key issue limiting its safe clinical application. Currently, the molecular mechanism underlying isopsoralen-induced liver injury has not been fully elucidated. This study investigates isopsoralen-induced liver injury, focusing on the interaction between endoplasmic reticulum stress (ERS) and mitochondrial dysfunction.
RESULTS:
In HepG2 cells, isopsoralen dose- and time-dependently reduced survival and increased lactate dehydrogenase release. In mice, isopsoralen elevated serum aminotransferases and creatine kinase. RNA sequencing revealed differential gene expression related to ERS and mitochondria. Isopsoralen increased the ERS markers glucose-regulated protein 78 and C/EBP homologous protein in vitro. Co-treatment with the ERS inhibitor 4-phenylbutyrate reduced caspase expression and apoptotic proteins while increasing the anti-apoptotic protein Bcl-2 in mouse liver tissue. 4-phenylbutyric acid also restored the mitochondrial fusion/fission balance, increased adenosine triphosphate content, and attenuated oxidative stress.
CONCLUSION:
Isopsoralen induces ERS, activating downstream apoptotic pathways that lead to mitochondrial dysfunction and subsequent liver injury. Inhibiting ERS alleviates this hepatotoxicity by improving mitochondrial dynamics and reducing oxidative stress.
2026-06-01COMPUTATIONAL BIOLOGY AND CHEMISTRY
Biomarker discovery and drug repurposing in hepatocellular carcinoma through transcriptomics, machine learning, network pharmacology, and molecular dynamics
Article
作者: Khan, Najeeb Ullah ; Unar, Ahsanullah ; Alfaifi, Mohammed ; Kamli, Hossam
This study employed an integrative computational and systems biology framework to define a diagnostic gene signature for hepatocellular carcinoma (HCC) and to explore its potential translational relevance in a hypothesis-generating manner. Differential expression analysis of transcriptomic data from 230 samples identified 2748 significantly differentially expressed genes (DEGs), including 2283 upregulated and 465 downregulated genes, with FGF4 (log2FC = 10.08) and REG1B (log2FC = 10.02) among the top hits. Four machine learning classifiers were trained using this signature and demonstrated consistently high predictive performance, with XGBoost emerging as the top-performing model (accuracy = 0.97, F1-score = 0.96, ROC-AUC = 0.981). Logistic Regression (L1) and Random Forest achieved comparable performance (ROC-AUC = 0.980 and 0.979, respectively), while SVM-linear also showed high robustness (ROC-AUC = 0.978). All models showed good calibration, with low Brier scores (<0.04) and precision consistently exceeding 0.90 across most recall thresholds, indicating strong but not perfect classification performance. SHAP-based explainability analysis was used to rank and prioritise the most influential predictors, refining the biomarker panel to 81 genes that collectively accounted for approximately 50 % of the model's explanatory contribution, and highlighting key downregulated predictors in HCC, including GDF2, COLEC10, BMP10, LRAT, and DNASE1L3. Protein-protein interaction and functional enrichment analyses revealed five major molecular clusters and provided systems-level insights into dysregulated biological processes associated with HCC. Drug-gene interaction mining mapped 78 target proteins to clinically relevant compounds, including tolrestat, alcuronium, metyrosine, and 4-phenylbutyric acid. Molecular docking suggested favorable binding propensities for several complexes, including alcuronium-3UON (-8.5 kcal/mol), tolrestat-1ZUA (-8.3 kcal/mol), metyrosine-2XSN (-6.7 kcal/mol), and 4-phenylbutyric acid-2NZ2 (-5.9 kcal/mol). A 100 ns molecular dynamics simulation of the tolrestat-AKR1B10 (1ZUA) complex indicated structural stability, with protein backbone RMSD stabilising at 1.5-3.0 Å, ligand RMSD at 0.6-1.4 Å, and persistent interactions involving Trp22, His110, Glu111, and Phe122. Physicochemical and pharmacokinetic profiling further prioritised tolrestat as a computationally favourable candidate (MW = 357.35, LogP = 3.64, TPSA = 81.86 Ų), exhibiting acceptable drug-likeness, high predicted gastrointestinal absorption, and low synthetic complexity (SA = 2.34), in contrast to alcuronium (MW = 666.89, SA = 7.86), which showed multiple rule violations. Collectively, this in silico study proposes a robust diagnostic gene signature for HCC and identifies tolrestat as a promising repurposing candidate that warrants experimental validation, demonstrating the utility of integrating machine learning, network biology, and molecular simulation in translational cancer research.
2026-06-01TISSUE & CELL
Mechanism of endoplasmic reticulum stress: Insights for potential therapeutic benefits in burns
Review
作者: Ren, Zhiyang ; Tang, Shuhan ; Li, Ke ; Zhu, Bin
Burns are injuries to the skin and deep tissues caused by thermal effects, which can trigger inflammation, necrosis, and systemic pathological reactions, often leading to life-threatening complications such as shock, infection, and multi-organ failure. Endoplasmic reticulum stress (ERS) is a key driving factor for tissue damage after burns. Burns are proposed to induce ERS through multiple mechanisms, including protein denaturation, inflammatory cytokine storms, and metabolic disturbances, Under stress conditions, cells can activate three key sensors, IRE1, PERK, and ATF6, to fully activate the main signaling pathway of unfolded protein response (UPR). In severe burns, sustained ERS promotes cell death via CHOP-mediated apoptosis, programmed necrosis, and ferroptosis (activated by the PERK-eIF2α-ATF4 pathway), exacerbating tissue injury. The progressive elevation of endoplasmic reticulum stress markers such as GRP78 and CHOP during burn course has been proven to be an important biological indicator for evaluating the degree of secondary organ damage. Consequently, therapeutic interventions such as propranolol (to counteract catecholamine effects) and 4-PBA (to stabilize protein folding) are under investigation as potential approaches for improving burn outcomes. This review systematically examines the pathological mechanisms of burn-induced ERS, associated modes of cell death, clinical manifestations of organ dysfunction, potential drug therapies, and other burn-related stress responses.
100 项与 4-苯基丁酸酯 相关的药物交易
登录后查看更多信息
外链
| KEGG | Wiki | ATC | Drug Bank |
|---|---|---|---|
| - | - | - |
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 肝内胆汁淤积 | 临床3期 | - | 2023-02-08 | |
| 遗传病 | 临床3期 | - | 2023-02-08 | |
| α1-抗胰蛋白酶缺乏症 | 临床2期 | 美国 | 2001-11-01 | |
| 阿尔茨海默症 | 临床2期 | - | - | |
| 阿尔茨海默症 | 临床2期 | - | - | |
| 包涵体肌炎 | 临床1期 | 美国 | 2020-08-20 | |
| 炎症 | 临床前 | 德国 | 2025-07-07 | |
| 急性肺损伤 | 临床前 | 中国 | 2025-05-16 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
临床2期 | - | 醖憲顧鑰鹽網鬱艱蓋製(鹽廠願選衊構構網繭範): P-Value = 0.01 更多 | - | 2018-09-01 | |||
Placebo |
登录后查看更多信息
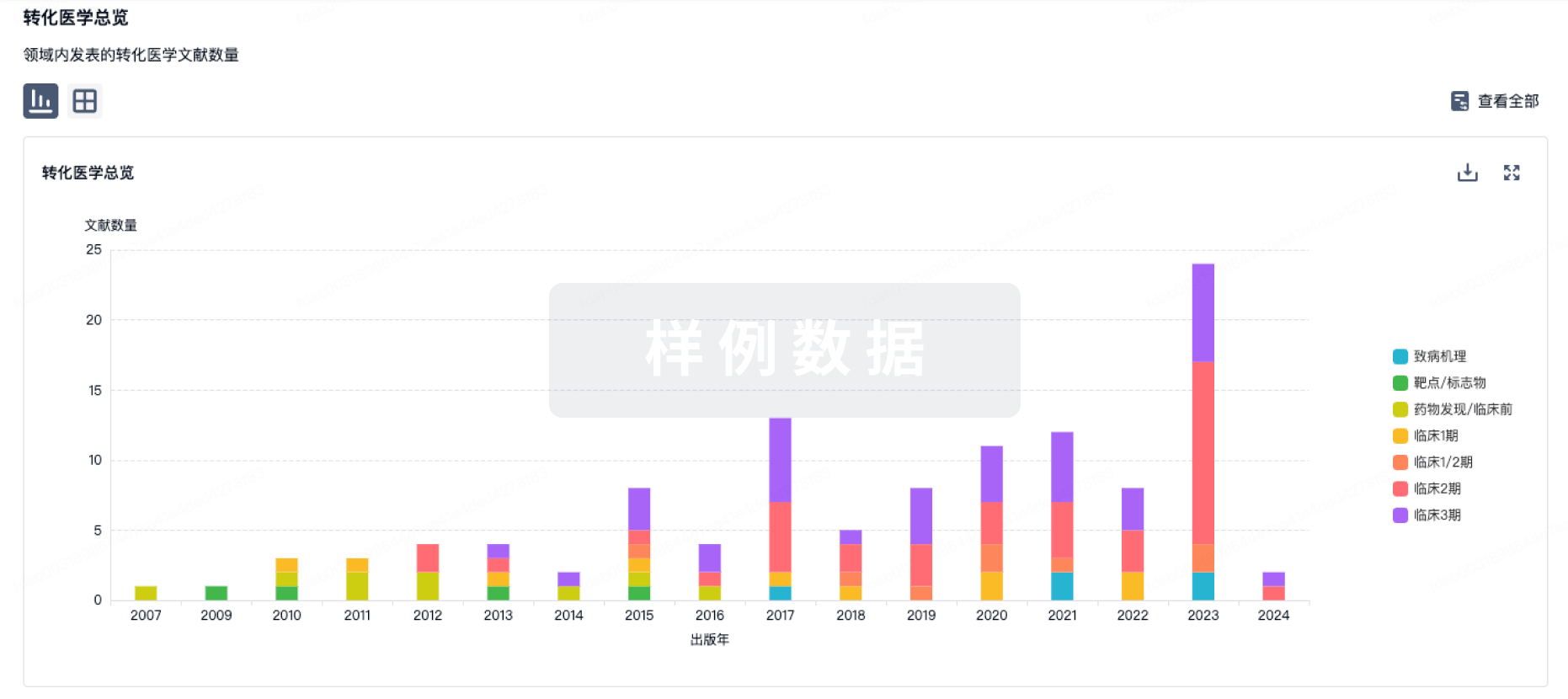
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用