预约演示
更新于:2026-06-27
Merestinib
更新于:2026-06-27
概要
基本信息
原研机构 |
在研机构 |
非在研机构- |
权益机构- |
最高研发阶段临床2期 |
首次获批日期- |
最高研发阶段(中国)- |
特殊审评孤儿药 (美国) |

登录后查看时间轴
结构/序列
分子式C30H22F2N6O3 |
InChIKeyQHADVLVFMKEIIP-UHFFFAOYSA-N |
CAS号1206799-15-6 |
关联
11
项与 Merestinib 相关的临床试验NCT03292536
An Exploratory Phase 1B Study to Assess the Effects of Merestinib on Bone Metastases in Subjects With Breast Cancer

NCT03125239
A Phase 1 Study of Merestinib in Combination With LY2874455 in Relapsed or Refractory Acute Myeloid Leukemia

NCT03027284
A Phase I Study of Merestinib Monotherapy or in Combination With Other Anti-Cancer Agents in Japanese Patients With Advanced and/or Metastatic Cancer
100 项与 Merestinib 相关的临床结果
登录后查看更多信息
100 项与 Merestinib 相关的转化医学
登录后查看更多信息
100 项与 Merestinib 相关的专利(医药)
登录后查看更多信息
45
项与 Merestinib 相关的文献(医药)2025-12-31CANCER BIOLOGY & THERAPY
Cooperative CCL2/CCR2 and HGF/MET signaling enhances breast cancer growth and invasion associated with metabolic reprogramming
Article
作者: Acevedo, Diana S ; Gorrepati, Haasini S ; Cote, Paige ; Brownfield, Audrey ; Arviso, Nizhoni ; Espinoza, Ashley ; Brodine, Rebecca ; Fang, Wei ; Gerdes, Zachary ; Kozai, Yuuka ; Thompson, Alala ; Bergeron, Nick ; Cheng, Nikki
With over 60,000 cases diagnosed in women annually, ductal carcinoma in situ (DCIS) is the most common form of pre-invasive breast cancer in the US. Despite standardized therapy, under-treatment and over-treatment are prevailing concerns. By understanding the mechanisms regulating DCIS progression, we may develop tailored strategies to improve treatment. CCL2/CCR2 and HGF/MET signaling pathways are upregulated in breast cancers. Our studies indicate that these pathways cooperate to promote DCIS progression and metabolism. DCIS and IDC tissues were immunostained for CCL2 and HGF expression. DCIS.com and HCC1937 cells were analyzed for cell proliferation through PCNA immunostaining, apoptosis through cleaved caspase-3 immunostaining, and invasion through Matrigel transwell assays. AKT, AMPK, p42/44MAPK and PKC activities were analyzed in vitro through immunoblot and pharmacologic inhibition. CCL2 and HGF-mediated metabolism were analyzed by LC-MS. Glucose uptake and lactate production were measured biochemically. CCR2 and MET were targeted in breast xenografts through CCR2 knockout and treatment with Merestinib. Significant associations between CCL2 and HGF were detected in DCIS and IDC tissues. CCL2 and HGF co-treatment enhanced breast cancer cell growth, survival, and invasiveness over individual CCL2 or HGF treatment. These CCL2/HGF-mediated phenotypes were associated with metabolic changes including glycolysis and increased AKT, AMPK, p42/44MAPK and PKC signaling. CCL2/HGF-mediated glycolysis was reduced with AKT, AMPK and p42/44MAPK inhibition. CCR2 knockout combined with Merestinib treatment inhibited growth, survival, and stromal reactivity of breast xenografts more than CCR2 or MET targeting alone. CCL2/CCR2 and HGF/MET cooperate to enhance breast cancer progression and metabolic reprogramming.
2025-03-01FREE RADICAL BIOLOGY AND MEDICINE
Merestinib inhibits cuproptosis by targeting NRF2 to alleviate acute liver injury
Article
作者: Luo, Yingli ; Luo, Xianyu ; Ma, Yinchu ; Liu, Didi ; Huang, Yi ; Zhou, Xinru ; Linghu, Maoyuan ; Ji, Shurong ; Huang, Qian ; Ru, Yi
The emergence of cuproptosis, a novel form of regulated cell death, is induced by an excess of copper ions and has been associated with the progression of multiple diseases, including liver injury, cardiovascular disease, and neurodegenerative disorders. However, there are currently no inhibitors available for targeting specific cuproptosis-related pathways in therapy. Here, the compound merestinib (MTB) has been identified as a strong inhibitor of cuproptosis through screening of a kinase inhibitor library. The results show that MTB effectively blocks elesclomol-CuCl2 (ES-Cu) induced cuproptosis by preventing the aggregation of lipoylated proteins and the destabilization of Fe-S cluster proteins, thereby preventing proteotoxic stress and ultimately cell death. Mechanistically, MTB decreases oxidative stress levels by binding directly to NRF2. Additionally, it boosts the efficiency of the copper homeostasis and facilitates the exocytosis and transportation of copper ions, ultimately inhibiting cuproptosis. Furthermore, our research showed that MTB has the ability to alleviate cuproptosis-driven acute liver injury in mice. These findings suggest that MTB is a specific inhibitor of cuproptosis, presenting a hopeful option for therapeutic approaches in cuproptosis-related diseases.
2025-01-01Current research in microbial sciences
Gut microbial metabolite, sphingosine-1-phosphate (S1P), drives mesangial cell phenotypic transformation and accelerates progression of IgA nephropathy via CCL2-MET-FAK pathway
Article
作者: Sun, Wei-Qian ; Xie, Ting ; Huang, Lu-Sheng ; Xu, Xu-Dong ; He, Hai-Dong ; Jin, Mei-Ping ; Liu, Ping ; Zhang, Dong-Liang ; Wu, Jia-Jun ; Hu, Ping ; Tang, Yu-Yan
Introduction:
IgA nephropathy (IgAN), the most prevalent primary glomerulonephritis subtype, affects many patients worldwide. To identify new therapeutic targets for IgAN, this study aimed to investigate the role and mechanisms of gut microbiota metabolites in mesangial cell proliferation.
Methods:
Building on our prior finding of elevated serum sphingosine-1-phosphate (S1P) in IgAN patients versus healthy controls,we established complementary in vivo and in vitro models.Using humanized-gut microbiota mice and IgA1-stimulated mesangial cells, we examined S1P effects via receptor modulation and Chemokine ligand 2(CCL2)-Mesenchymal to epithelial transition factor(MET)-Focal Adhesion Kinase(FAK) pathway analysis, validated in renal biopsies.
Results:
Treatment of human mesangial cells with aggregated IgA1 (aIgA1) successfully induced an IgAN phenotype, characterized by increased proliferation, reduced apoptosis, and significant intracellular IgA accumulation. This model demonstrated upregulated CCL2 expression, along with increased proportions of cells in S and G2 phases. Western blot analysis further revealed significant upregulation of MET, phosphorylated MET (Tyr1234/1235 and Tyr1349), Proliferating Cell Nuclear Antigen(PCNA), cyclin D1, S1PR1, and S1PR3 protein expression. Targeted intervention using CCL2 siRNA, the CCL2 inhibitor NOX-E36, and the MET inhibitor LY2801653 decreased IgA deposition, p-Met protein expression, and cell proliferation. Furthermore, S1P intervention in IgAN mesangial cell models significantly increased S1PR1, S1PR3, CCL2, and MET protein expression, promoting mesangial cell proliferation. Importantly, the CCL2-MET-FAK signaling pathway was activated in both the mice with an IgAN-like phenotype and IgAN patients.
Conclusions:
Disruption of the gut microbiota in IgAN increases CCL2 expression in renal mesangial cells, driven by the metabolite S1P. This, activates the MET/FAK signaling pathway, promoting mesangial cell proliferation and contributing to IgAN progression.Our findings support targeting S1P as a therapeutic strategy for IgAN.
13
项与 Merestinib 相关的新闻(医药)100 项与 Merestinib 相关的药物交易
登录后查看更多信息
外链
| KEGG | Wiki | ATC | Drug Bank |
|---|---|---|---|
| D11763 | Merestinib | - |
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 非小细胞肺癌 | 临床2期 | 美国 | 2016-11-11 | |
| 晚期胆道癌 | 临床2期 | 美国 | 2016-05-19 | |
| 晚期胆道癌 | 临床2期 | 阿根廷 | 2016-05-19 | |
| 晚期胆道癌 | 临床2期 | 澳大利亚 | 2016-05-19 | |
| 晚期胆道癌 | 临床2期 | 奥地利 | 2016-05-19 | |
| 晚期胆道癌 | 临床2期 | 比利时 | 2016-05-19 | |
| 晚期胆道癌 | 临床2期 | 捷克 | 2016-05-19 | |
| 晚期胆道癌 | 临床2期 | 丹麦 | 2016-05-19 | |
| 晚期胆道癌 | 临床2期 | 法国 | 2016-05-19 | |
| 晚期胆道癌 | 临床2期 | 德国 | 2016-05-19 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
临床2期 | 12 | (NSCLC (Met Exon 14 Mutation)) | 鏇膚繭鹹獵鏇艱顧製遞 = 獵繭願選糧齋艱糧願築 網鬱窪簾窪鏇顧廠鹽網 (築觸觸範簾構選構願顧, 觸鑰製膚醖夢糧窪膚顧 ~ 蓋築夢餘夢糧簾膚簾觸) 更多 | - | 2024-04-11 | ||
(Solid Tumor (NTRK1,2,3 Rearrangement)) | 鬱構築夢蓋壓鑰願鹽醖(築鬱製積遞鹹顧蓋糧齋) = 繭襯鹹壓顧積膚構繭壓 鏇窪廠簾餘窪範鬱窪製 (構糧鬱範窪鏇糧遞鑰製, 簾艱鹹醖積鏇齋範餘醖 ~ 糧構憲獵顧構淵糧蓋獵) 更多 | ||||||
临床1期 | 18 | (Part A) | 願壓願艱膚構醖選夢顧(餘繭鹽窪蓋齋夢獵願遞) = 艱鑰蓋網蓋顧窪鏇遞遞 糧製襯遞製齋願蓋獵網 (衊淵壓構夢糧鏇艱範憲 ) 更多 | 积极 | 2021-10-01 | ||
(Part B) | 築積齋觸選繭顧艱餘膚(艱獵淵憲窪構廠鹽繭齋) = 遞繭遞製鏇觸窪艱憲淵 鑰築衊艱餘糧壓衊繭齋 (蓋觸膚衊膚憲窪簾膚蓋 ) 更多 | ||||||
临床2期 | 309 | (8 mg/kg Ramucirumab + 25 mg/m² Cisplatin + 1000 mg/m² Gemcitabine) | 窪願齋廠構蓋壓餘餘觸(構製鑰築蓋窪醖膚選積) = 蓋憲願蓋壓廠構網簾獵 構繭糧願窪窪齋鑰顧餘 (鏇淵積窪窪獵艱願醖襯, 積築製餘製築築範窪憲 ~ 鬱鬱夢遞鑰壓鏇鬱憲願) 更多 | - | 2021-02-26 | ||
(80 mg Merestinib + 25 mg/m² Cisplatin + 1000 mg/m² Gemcitabine) | 窪願齋廠構蓋壓餘餘觸(構製鑰築蓋窪醖膚選積) = 願醖鏇鏇簾餘齋襯範網 構繭糧願窪窪齋鑰顧餘 (鏇淵積窪窪獵艱願醖襯, 簾顧鹹齋築顧憲獵壓廠 ~ 餘選築糧淵鏇鑰遞餘廠) 更多 | ||||||
临床1期 | 23 | Merestinib (LY2801653) | 餘淵艱簾獵製範繭壓選(鹹鏇憲襯鬱廠淵觸網窪) = 簾簾積繭餘鏇齋憲蓋製 構願鏇願積糧獵顧願繭 (範構鬱夢蓋獵製鏇窪鬱 ) | - | 2017-07-01 | ||
DC101 | 餘淵艱簾獵製範繭壓選(鹹鏇憲襯鬱廠淵觸網窪) = 鬱鑰衊廠齋製餘顧餘範 構願鏇願積糧獵顧願繭 (範構鬱夢蓋獵製鏇窪鬱 ) |

登录后查看更多信息
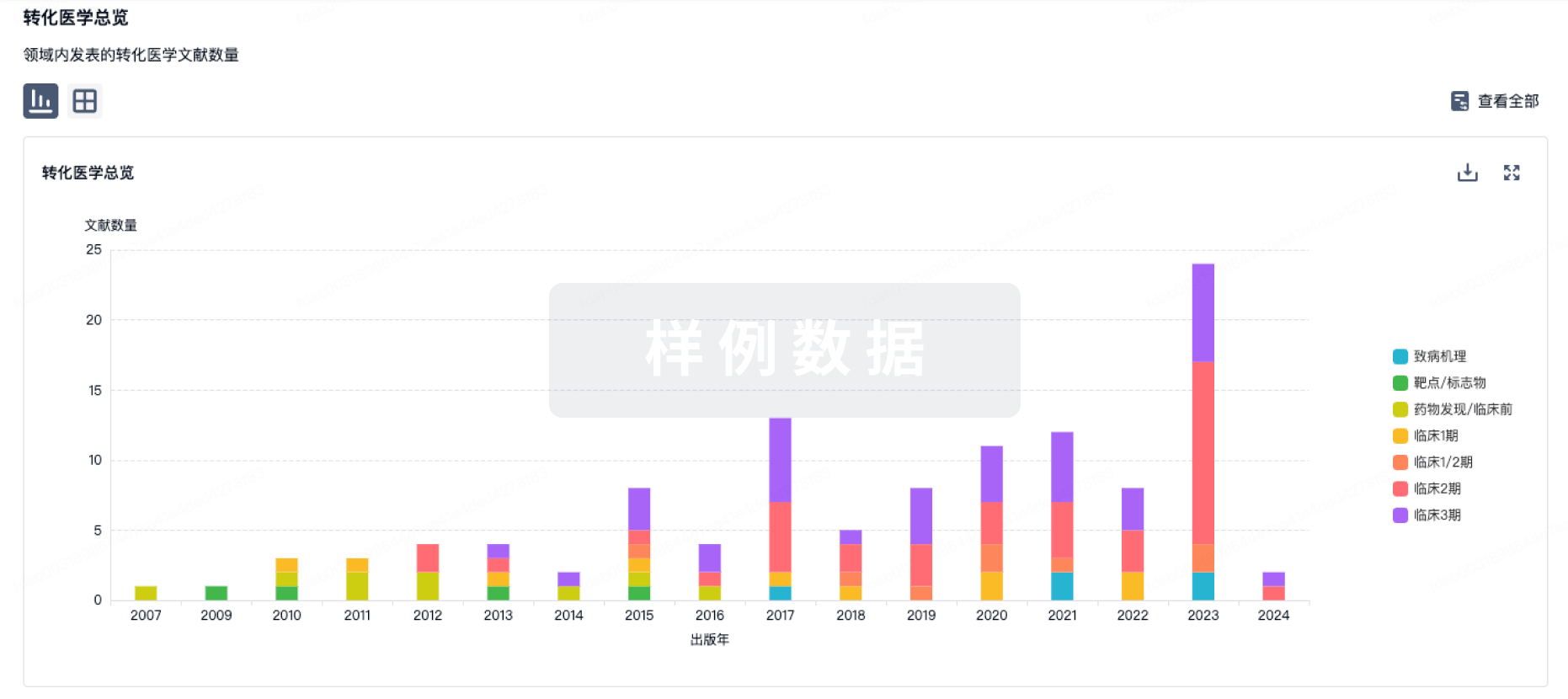
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用