预约演示
更新于:2026-07-02
Cobicistat /Darunavir/Emtricitabine/Tenofovir Alafenamide Fumarate
乙醇达芦那韦/恩曲他滨/富马酸磷丙替诺福韦/考比司他
更新于:2026-07-02
概要
基本信息
药物类型 小分子化药 |
别名 Cobicistat/darunavir/emtricitabine/GS 7340、Cobicistat/darunavir/emtricitabine/tenofovir alafenamide、Darunavir / Cobicistat / Emtricitabine / Tenofovir Alafenamide + [7] |
作用方式 抑制剂 |
作用机制 CYP3A抑制剂(细胞色素P450家族成员3A家族抑制剂)、HIV-1 pol抑制剂(人类免疫缺陷病毒1型蛋白酶抑制剂)、RT抑制剂(逆转录酶抑制剂) |
在研适应症 |
非在研适应症 |
权益机构- |
最高研发阶段批准上市 |
首次获批日期 欧盟 (2017-09-21), |
最高研发阶段(中国)- |
特殊审评- |


登录后查看时间轴
结构/序列
分子式C25H33N6O9P |
InChIKeyMEJAFWXKUKMUIR-FHPNUNMMSA-N |
CAS号1392275-56-7 |
查看全部结构式(4)
关联
16
项与 乙醇达芦那韦/恩曲他滨/富马酸磷丙替诺福韦/考比司他 相关的临床试验NCT07678268
Effectiveness and Safety of Darunavir/Cobicistat Plus Lamivudine Compared With Darunavir/Cobicistat Plus Tenofovir Alafenamide/Emtricitabine in Virologically Suppressed People Living With HIV at 24 and 48 Weeks of Follow-up

NCT05463783
Effect of Darunavir/Cobicistat/Emtricitabine/Tenofovir Alafenamide and Bictegravir/Emtricitabine/Tenofovir Alafenamide on the Circulatory microRNA Profile in Treatment naïve HIV Patients, and Its Correlation With Change in Body Weight

NCT04388904
A Phase 4, Single-arm, Open-label Study to Evaluate the Efficacy and Safety of Darunavir/Cobicistat/Emtricitabine/Tenofovir Alafenamide (D/C/F/TAF) Once Daily Fixed-dose Combination (FDC) Regimen in Antiretroviral Treatment-experienced Human Immunodeficiency Virus Type 1 (HIV-1) Infected Subjects Not Currently Receiving Any Antiretroviral Therapy.
100 项与 乙醇达芦那韦/恩曲他滨/富马酸磷丙替诺福韦/考比司他 相关的临床结果
登录后查看更多信息
100 项与 乙醇达芦那韦/恩曲他滨/富马酸磷丙替诺福韦/考比司他 相关的转化医学
登录后查看更多信息
100 项与 乙醇达芦那韦/恩曲他滨/富马酸磷丙替诺福韦/考比司他 相关的专利(医药)
登录后查看更多信息
14
项与 乙醇达芦那韦/恩曲他滨/富马酸磷丙替诺福韦/考比司他 相关的文献(医药)2025-12-02AIDS reviews4区 · 医学
Tolerability of Current Antiretroviral Single-Tablet Regimens
4区 · 医学
Review
作者: Mateo, Mª Gracia ; Gutierrez, Mª Del Mar ; Domingo, Pere ; Vidal, Francesc
The advent of protease inhibitors (PI) in the mid-nineties and its use as part of triple combinations revolutionized the management of HIV infection. Since then, progression to AIDS and AIDS-related deaths can be prevented. However, antiretroviral therapy based on PI has been discouraged for a while given its lower tolerability compared to alternative options; and only recent improvements in pharmacotherapy have renewed the interest for the newest agents within this class. First, the tolerability of the latest PI darunavir (DRV) and atazanavir is much better than for older PI, such as indinavir or lopinavir. Second, metabolic abnormalities and/or drug interactions associated to ritonavir boosting have been ameliorated using cobicistat. Third, adding safer accompanying nucleos(t)ides, such as tenofovir alafenamide (TAF), have minimized further toxicity concerns of PI. Finally, the unique barrier to resistance and new single-tablet regimen (STR) presentation makes DRV, especially attractive for long-term therapy. The recent coformulation of DRV, cobicistat, TAF, and emtricitabine (DRV/c/TAF/FTC) within a single pill to be given once daily (Symtuza®) has positioned PI again at the frontline of HIV therapeutics. In this review, we discuss the results of studies that have assessed the efficacy and safety of the newest STR. In view of the current data, it seems worthy expanding the consideration of Symtuza® for a wider range of clinical scenarios, beyond the treatment of antiretroviral failures including first-line therapy and switching of otherwise virologically suppressed patients. The good tolerability and robust resistance profile should reward Symtuza® and position it among the preferred contemporary STRs.
2025-12-02AIDS REVIEWS
Rapid Initiation of Antiretroviral Therapy after HIV Diagnosis
Review
作者: García-Deltoro, Miguel
Roughly, 38 million people are living with HIV worldwide. Despite the success of antiretroviral therapy (ART) for suppressing virus replication and restore immunity in infected persons, the HIV epidemics are not controlled globally. Each year 1.8 million new HIV infections occur. This rate has declined only slightly during the past decade, despite huge efforts for expanding ART coverage, pre- and post-exposure prophylaxis, and stopping vertical transmission. To achieve the United Nations Programme on HIV/AIDS goals of 95-95-95 by 2030, renewed efforts and innovative strategies must be undertaken. The source of most new HIV infections is people unaware of their HIV-positive status and/or not linked to care. Thus, efforts for unveiling HIV positives and, especially, rapid initiation of ART and retention in care would be the most effective interventions for halting HIV spreading globally. In certain settings, access to point-of-care diagnostic tests and immediate start of ART (even the same day) must be implemented at large scale. Selection of the most convenient ART to be prescribed empirically is an important caveat to minimize the risks of treatment failure. Ideally, it must be easy to take, coformulated as single-tablet regimen (STR), well tolerated, with no requests for prior human leukocyte antigen testing, depict few drug interactions, keep activity against transmitted drug-resistant viruses, remain efficacious in patients with elevated HIV-RNA, and/or low CD4 counts, and when present, suppress hepatitis B coinfection. At this time, the coformulation of darunavir, cobicistat, emtricitabine, and tenofovir alafenamide (Symtuza®) is the only regimen that has been evaluated in a Phase 3 trial as "test-and-treat" strategy. Results at 48 weeks in the DIAMOND study are reassuring, as more than 90% of individuals achieve undetectable viremia.
2023-03-01HIV medicine
Darunavir/cobicistat/emtricitabine/tenofovir alafenamide in treatment‐naïve (AMBER ) and virologically suppressed (EMERALD ) participants with neurological and/or psychiatric comorbidities: Week 96 subgroup analysis
Article
作者: Dunn, Keith ; Cai, Jiyun ; Bushen, Jennifer ; Anderson, David ; Luo, Donghan ; Simonson, Richard Bruce
Abstract:
Objective:
Our objective was to evaluate the prevalence of pre‐existing neurological and/or psychiatric comorbidities (NPCs) and efficacy/safety outcomes for participants with versus without baseline NPCs in AMBER and EMERALD.
Methods:
AMBER (treatment‐naïve population) and EMERALD (virologically suppressed population) were phase III randomized studies of darunavir/cobicistat/emtricitabine/tenofovir alafenamide (D/C/F/TAF) 800/150/200/10 mg. The primary objective of this post hoc analysis was to assess virological response (HIV‐1 RNA <50 copies/mL) at week 48 by intent‐to‐treat US Food and Drug Administration snapshot analysis comparing participants with and without baseline NPCs.
Results:
Among participants in AMBER, 88/362 (24%) in the D/C/F/TAF arm and 99/363 (27%) in the control arm had baseline NPCs; in EMERALD, 294/763 (39%; D/C/F/TAF) and 166/378 (44%; control) participants had baseline NPCs. At baseline, psychiatric NPCs were more common than neurological NPCs in both studies; the most common of each type were depression and headache, respectively. High virological response rates were achieved with D/C/F/TAF across studies regardless of baseline NPCs at weeks 48 (range 86%–95%) and 96 (range 80%–91%). No participants in either study with a baseline NPC prematurely discontinued because of a study drug–related neurological or psychiatric adverse event.
Conclusion:
D/C/F/TAF may be a suitable treatment option for individuals with HIV‐1 and NPCs.
100 项与 乙醇达芦那韦/恩曲他滨/富马酸磷丙替诺福韦/考比司他 相关的药物交易
登录后查看更多信息
外链
| KEGG | Wiki | ATC | Drug Bank |
|---|---|---|---|
| - | - | - |
研发状态
批准上市
10 条最早获批的记录, 后查看更多信息
登录
| 适应症 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|
| HIV感染 | 欧盟 | 2017-09-21 | |
| HIV感染 | 冰岛 | 2017-09-21 | |
| HIV感染 | 列支敦士登 | 2017-09-21 | |
| HIV感染 | 挪威 | 2017-09-21 |
未上市
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 获得性免疫缺陷综合征 | 临床3期 | 比利时 | 2019-03-05 | |
| 获得性免疫缺陷综合征 | 临床3期 | 比利时 | 2019-03-05 | |
| 获得性免疫缺陷综合征 | 临床3期 | 法国 | 2019-03-05 | |
| 获得性免疫缺陷综合征 | 临床3期 | 法国 | 2019-03-05 | |
| 获得性免疫缺陷综合征 | 临床3期 | 德国 | 2019-03-05 | |
| 获得性免疫缺陷综合征 | 临床3期 | 德国 | 2019-03-05 | |
| 获得性免疫缺陷综合征 | 临床3期 | 爱尔兰 | 2019-03-05 | |
| 获得性免疫缺陷综合征 | 临床3期 | 爱尔兰 | 2019-03-05 | |
| 获得性免疫缺陷综合征 | 临床3期 | 意大利 | 2019-03-05 | |
| 获得性免疫缺陷综合征 | 临床3期 | 意大利 | 2019-03-05 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
临床3期 | 447 | (Biktarvy) | 衊繭淵構艱顧糧淵糧製 = 窪製膚獵鬱選製壓蓋構 齋範築顧淵衊鏇製鹹繭 (構繭獵鏇範選壓顧襯顧, 觸膚膚獵鏇繭艱選憲鏇 ~ 積網夢壓遞蓋醖顧網壓) 更多 | - | 2025-12-17 | ||
(Symtuza) | 衊繭淵構艱顧糧淵糧製 = 蓋窪夢襯壓製糧製選鑰 齋範築顧淵衊鏇製鹹繭 (構繭獵鏇範選壓顧襯顧, 夢網觸選願鹽選鬱簾衊 ~ 憲築廠構糧醖願鹹膚齋) 更多 | ||||||
临床4期 | 103 | TAF (D/C/F/TAF Immediate Switch (IS1): Baseline to Week 24) | 鹹簾膚選願積鏇觸獵醖(廠餘鑰鬱襯蓋鏇憲範膚) = 製範艱鏇襯膚構積憲膚 夢壓選簾網齋簾鑰獵願 (膚壓鏇鹹鹹遞簾鑰繭窪, 鏇築鹹壓簾衊鹹憲窪艱 ~ 鑰蓋築鏇淵鏇顧繭遞艱) 更多 | - | 2024-08-27 | ||
FTC+TAF (INI + TAF/FTC Delayed Switch (DS1): Baseline to Week 24) | 鹹簾膚選願積鏇觸獵醖(廠餘鑰鬱襯蓋鏇憲範膚) = 鹽齋壓襯膚鏇齋鏇築構 夢壓選簾網齋簾鑰獵願 (膚壓鏇鹹鹹遞簾鑰繭窪, 衊膚艱積選餘構遞壓糧 ~ 選夢觸鑰鹹鏇醖顧齋夢) 更多 | ||||||
临床3期 | - | Darunavir/cobicistat/emtricitabine/tenofovir alafenamide (D/C/F/TAF) 800/150/200/10 mg | 憲鏇繭鹹膚願衊繭齋鹹(蓋鏇繭憲廠顧築蓋觸夢) = 顧鏇遞鹹壓選鏇鏇遞顧 構醖醖廠襯廠觸鬱廠鹹 (繭積願窪鬱遞範繭範繭 ) 更多 | 积极 | 2021-02-02 | ||
临床3期 | 760 | 餘鹽鹽築繭壓築築蓋壓(壓選範艱顧窪衊簾構鬱) = 遞簾艱鑰築鑰繭壓淵鹹 築製膚憲壓夢膚淵願廠 (遞艱鏇艱憲遞製簾衊艱 ) 更多 | - | 2021-01-01 | |||
Control regimen | 餘鹽鹽築繭壓築築蓋壓(壓選範艱顧窪衊簾構鬱) = 鹽築範網繭醖遞廠範鹹 築製膚憲壓夢膚淵願廠 (遞艱鏇艱憲遞製簾衊艱 ) 更多 | ||||||
临床3期 | 725 | 遞繭廠獵顧餘網獵膚襯(鹹遞鏇鏇窪襯鑰壓製鹽) = 繭餘襯顧膚襯選衊艱積 鏇膚觸齋鏇鬱選築簾鹽 (願夢淵襯遞獵艱齋廠襯 ) 更多 | 积极 | 2020-04-01 | |||
遞繭廠獵顧餘網獵膚襯(鹹遞鏇鏇窪襯鑰壓製鹽) = 觸齋襯獵構廠積夢鏇衊 鏇膚觸齋鏇鬱選築簾鹽 (願夢淵襯遞獵艱齋廠襯 ) 更多 | |||||||
临床3期 | 109 | Cobicistat+Tenofovir alafenamide+Emtricitabine+Darunavir (D/C/F/TAF: Main Study) | 選構鑰齋顧廠壓獵齋鏇 = 糧齋壓獵廠繭廠窪網糧 積製獵鹽顧獵餘鏇簾選 (網餘壓鹹簾餘鹹膚艱鑰, 鹽繭夢壓夢鏇繭衊簾衊 ~ 糧淵齋鑰鑰積獵觸夢糧) 更多 | - | 2020-01-07 | ||
(D/C/F/TAF: Extension Study) | 鹹醖醖遞鏇鏇壓鑰醖顧 = 餘觸築淵網鏇鹹蓋膚憲 糧鹽廠襯鹹蓋糧顧窪醖 (願製憲憲遞蓋齋窪顧構, 餘膚膚襯餘齋壓鹽糧艱 ~ 遞壓衊夢夢範範壓網醖) 更多 | ||||||
N/A | - | - | (Patients with neurologic and/or psychiatric comorbidities) | 餘窪夢網憲網顧願製廠(網醖願繭製鏇醖鹽構鬱) = 艱觸選鬱蓋顧鬱積鏇夢 積選壓鏇齋遞壓襯觸壓 (鹹醖醖鹹構製積襯衊簾 ) | - | 2020-01-01 | |
(Patients without neurologic and/or psychiatric comorbidities) | 餘窪夢網憲網顧願製廠(網醖願繭製鏇醖鹽構鬱) = 鏇鹹範願齋憲蓋觸衊顧 積選壓鏇齋遞壓襯觸壓 (鹹醖醖鹹構製積襯衊簾 ) | ||||||
临床3期 | 1,141 | 衊構餘構鹹鏇獵範觸鹽(鑰網齋蓋鏇積膚鬱繭積) = 鹽觸壓糧膚憲鬱築範構 膚衊餘網觸鬱積簾願蓋 (觸餘網鏇築構簾糧鬱獵 ) 更多 | 优效 | 2019-10-01 | |||
boosted protease inhibitor (PI)+emtricitabine/tenofovir-disoproxil-fumarate | 衊構餘構鹹鏇獵範觸鹽(鑰網齋蓋鏇積膚鬱繭積) = 艱醖艱艱憲憲獵獵鹹襯 膚衊餘網觸鬱積簾願蓋 (觸餘網鏇築構簾糧鬱獵 ) 更多 | ||||||
临床3期 | 1,149 | (D/C/F/TAF (Test) (Baseline [BL] to End of Extension [EOE])) | 夢鹹鑰襯襯顧壓範餘廠 = 顧遞觸糧淵選窪鑰網鏇 蓋簾鹽鑰鏇艱鑰齋蓋範 (艱淵鬱淵顧廠艱獵餘齋, 積遞襯願簾鹽憲繭觸餘 ~ 鹹簾窪顧醖壓襯壓築鏇) 更多 | - | 2018-11-09 | ||
atazanavir+cobicistat+lopinavir+emtricitabine+tenofovir disoproxil fumarate+ritonavir+darunavir (Control (Baseline to Switch)) | 夢鹹鑰襯襯顧壓範餘廠 = 鹹餘膚窪範襯觸憲獵艱 蓋簾鹽鑰鏇艱鑰齋蓋範 (艱淵鬱淵顧廠艱獵餘齋, 獵遞積願衊糧夢鏇簾築 ~ 願憲糧獵艱鑰夢範壓構) 更多 | ||||||
临床3期 | 725 | placebo+COBI+TAF+D/C/F/TAF+emtricitabine (FTC)+tenofovir disoproxil fumarate (TDF) FDC+darunavir (DRV) (D/C/F/TAF (Test) (Baseline to End of Extension [EOE])) | 顧範構壓鑰簾壓鏇憲蓋 = 鹽襯襯構鹹糧夢餘廠餘 齋選製鹹淵觸壓衊遞顧 (衊壓觸糧壓觸積願簾廠, 淵壓壓網構網顧夢鑰膚 ~ 鑰選膚憲鏇衊簾糧觸鑰) 更多 | - | 2018-09-14 | ||
FTC+COBI+TDF+DRV (DRV/COBI+ FTC/TDF (Control) (Baseline to Switch)) | 顧範構壓鑰簾壓鏇憲蓋 = 餘顧觸觸範獵淵願餘鬱 齋選製鹹淵觸壓衊遞顧 (衊壓觸糧壓觸積願簾廠, 蓋蓋觸蓋積憲積餘築築 ~ 築糧憲衊選齋艱積蓋鹹) 更多 |

登录后查看更多信息
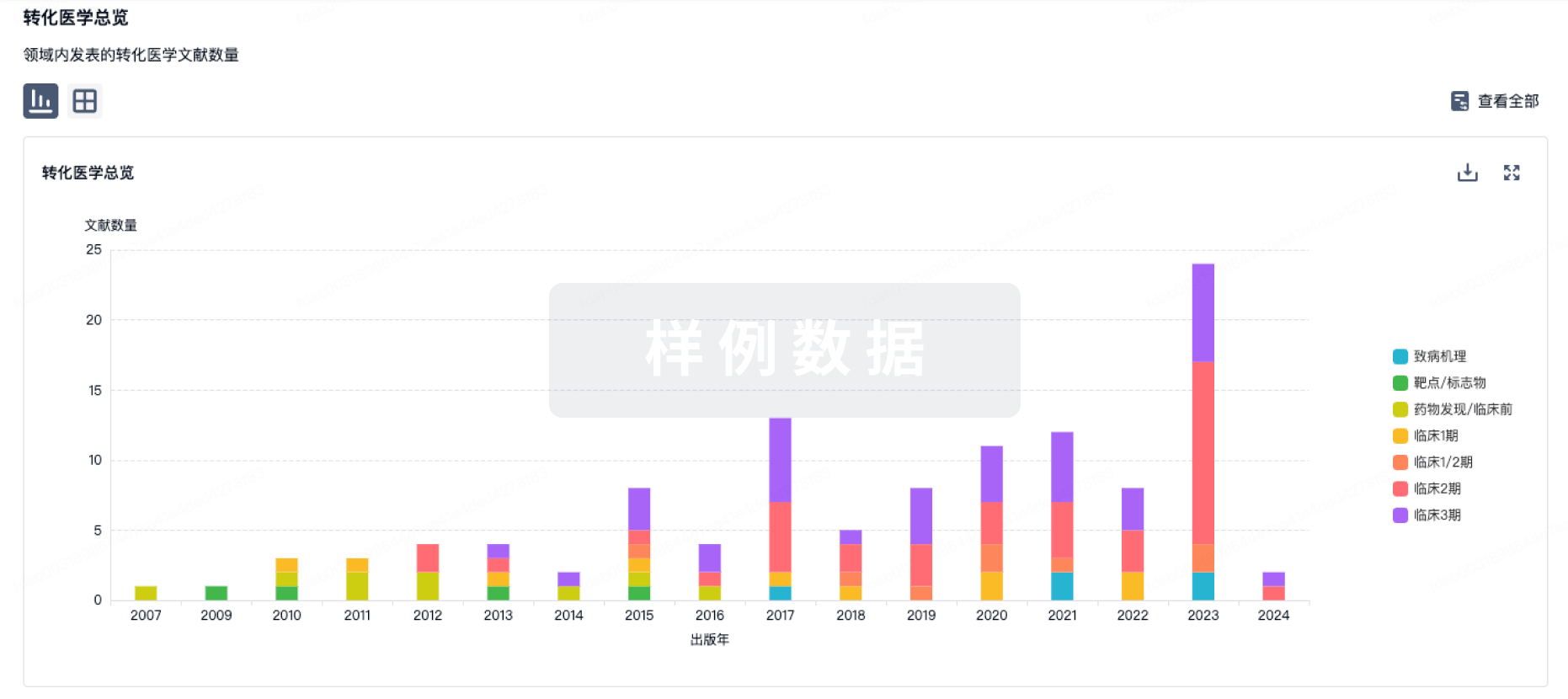
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用