预约演示
更新于:2026-06-14
Peginterferon lambda-1a(ZymoGenetics, Inc.)
更新于:2026-06-14
概要
基本信息
药物类型 干扰素 |
别名 Lambda、PEG-interferon lambda、PEG-interleukin-29 + [6] |
靶点 |
作用方式 激动剂 |
作用机制 IFNLR1激动剂(干扰素λ受体1激动剂) |
非在研适应症 |
最高研发阶段临床3期 |
首次获批日期- |
最高研发阶段(中国)终止 |
特殊审评突破性疗法 (美国)、孤儿药 (美国)、孤儿药 (欧盟)、快速通道 (美国) |


登录后查看时间轴
结构/序列
Sequence Code 199195

来源: *****
关联
27
项与 Peginterferon lambda-1a(ZymoGenetics, Inc.) 相关的临床试验NCT05070364
Phase 3, Randomized, Open-Label, Parallel Arm Study to Evaluate the Efficacy and Safety of 180 mcg Peginterferon Lambda-1a (Lambda) Subcutaneous Injection for 48 Weeks in Patients With Chronic Hepatitis Delta Virus (HDV) Infection (LIMT-2)
NCT04388709
A Randomized Phase 2 Trial of Peginterferon Lambda-1a (Lambda) for the Treatment of Hospitalized Patients Infected With SARS-CoV-2 With Non-critical Illness

NCT04344600
Peginterferon Lambda-1a for the Prevention and Treatment of SARS-CoV-2 Infection

100 项与 Peginterferon lambda-1a(ZymoGenetics, Inc.) 相关的临床结果
登录后查看更多信息
100 项与 Peginterferon lambda-1a(ZymoGenetics, Inc.) 相关的转化医学
登录后查看更多信息
100 项与 Peginterferon lambda-1a(ZymoGenetics, Inc.) 相关的专利(医药)
登录后查看更多信息
34
项与 Peginterferon lambda-1a(ZymoGenetics, Inc.) 相关的文献(医药)2025-05-01GUT
Antiviral therapy for chronic hepatitis delta: new insights from clinical trials and real-life studies
Review
作者: Anolli, Maria Paola ; Roulot, Dominique ; Lampertico, Pietro ; Wedemeyer, Heiner
Chronic hepatitis D (CHD) is the most severe form of viral hepatitis, carrying a greater risk of developing cirrhosis and its complications. For decades, pegylated interferon alpha (PegIFN-α) has represented the only therapeutic option, with limited virological response rates and poor tolerability. In 2020, the European Medicines Agency approved bulevirtide (BLV) at 2 mg/day, an entry inhibitor of hepatitis B virus (HBV)/hepatitis delta virus (HDV), which proved to be safe and effective as a monotherapy for up to 144 weeks in clinical trials and real-life studies, including patients with cirrhosis. Long-term BLV monotherapy may reduce decompensating events in patients with cirrhosis. The combination of BLV 2 mg with PegIFN-α increased the HDV RNA undetectability rates on-therapy but not off-therapy, compared with PegIFN monotherapy. However, combination therapy, but not BLV monotherapy, may induce hepatitis B surface antigen (HBsAg) loss in some patients. The PegIFN lambda study has been discontinued due to liver toxicity issues, while lonafarnib boosted with ritonavir showed limited off-therapy efficacy in a phase 3 study. Nucleic acid polymer-based therapy is promising but large studies are still lacking. New controlled trial data come from molecules, such as monoclonal antibodies and/or small interfering RNA, that target HBsAg or HBV RNAs, which demonstrated not only profound HDV suppression, but also HBsAg decline.While waiting for new compounds to be approved as monotherapy or in combination, BLV monotherapy 2 mg/day remains the only approved therapy for CHD, at least in the European Union region.
2024-05-01Hepatology (Baltimore, Md.)
HDV screening in chronic HBV: An unmet need of growing importance
Article
作者: Robert J. Fontana ; Abhishek Shenoy
HDV infection is an aggressive form of viral hepatitis associated with accelerated morbidity and mortality in patients with chronic HBV infection.1,2 HDV is a single-stranded, defective circular RNA virus whose replication inhibits HBV replication but enhances hepatic fibrosis progression and cancer risk. HDV requires the HBsAg envelope protein to enter hepatocytes through the sodium taurocholate co-transporting polypeptide receptor.2 Exposure to HDV can be determined by the detection of anti-HDV IgG or IgM antibodies, while active infection is defined by the presence of detectable HDV-RNA in the blood. HDV, like HBV, can be parenterally or sexually transmitted and may clinically present as acute coinfection with HBV that is usually self-limited in most patients (95%). In contrast, HDV superinfection in a patient with established chronic HBV leads to chronic HDV infection in 80%–90% of patients.2 HDV is considered a rare or "orphan disease" in the United States (ie, <200,000 patients) but screening for HDV among patients with chronic HBV remains woefully low at 5%–10% due to lack of physician education, awareness, and reliable diagnostic assays. In this issue of Hepatology, Gish et al1 present an interesting study on the estimated prevalence and clinical characteristics of adults with HDV-HBV coinfection in the United States. The authors defined HDV coinfection in the All-Payer Claims Database (APCD) by means of the presence of the International Classification of Disease (ICD) 9 or 10 diagnostic codes for HDV among patients who also had a code for HBV infection between 2014 and 2020. Using this methodology, the prevalence of HDV coinfection was 4.6% among the 144,975 adults with chronic HBV. Clinical risk factors for HDV coinfection included younger patient age, female sex, Black ethnicity, and patient geography. Patients with HDV coinfection demonstrated higher rates of decompensated liver disease and other comorbid illnesses, including HIV coinfection (30.9% vs. 8.1%), substance use disorders (28.7% vs. 13.2%), and sexually transmitted infections (18.7% vs. 2.2%). The 4.6% prevalence of HDV coinfection is similar to the estimates provided in other studies that used serological or other diagnostic methodologies (Table 1). TABLE 1 - Selected studies of HDV prevalence among patients with chronic HBV in the United States References Methodology (sample size) National referral center (NIH) National Institutes of Health (NIH) HDV prevalence among HBsAg + Comments Kushner et al3 Retrospective cohort study (2175) National VA Corporate Data Warehouse (1999–2013) Anti-HDV IgG antibody 3.4% - <50% patients had confirmed chronic HBV- Selection bias: only 8.5% of all patients with chronic HBV tested- Potential male sex bias (96%)- No HDV-RNA confirmation Pate et al4 Cross-sectional survey (21,832) National NHANES (2011–2016) Anti-HDV IgG antibody (DiaSorin) 42% - Representative of general US population including foreign born individuals- Only 113 patients with chronic HBV tested- High-risk populations excluded (homeless, incarcerated, institutionalized)- No HDV-RNA confirmation Nathani et al5 Retrospective cohort study (1444) Urban single-center (Mount Sinai New York) (2016-2021) Anti-HDV IgG antibody 6% - Single-center, retrospective urban population- Selection bias: only 13% of all patients with chronic HBV tested- No HDV-RNA confirmation Da et al6 Retrospective, cross-sectional cohort study (588) National Institutes of Health (NIH) (2000–2019) Anti-HDV IgG antibody, HDV-RNA or HDAg tissue stain confirmation 19% - Potential referral bias of national research center (NIH)- 80% of anti-HDV IgG (+) confirmed to have HDV-RNA Ferrante et al7 Retrospective, cross-sectional cohort (597) Multicenter HIV-HBV cohort (1996–2019) Anti-HDV IgG antibody (Diasorin), HDV-RNA 4.0% - Selection bias: all were HIV + co-infected enrolled in research network- Intravenous drug use only risk factor on multivariate analysis- 41% of anti-HDV IgG + were HDV-RNA +- All had HDV genotype 1 Gish et al1 Retrospective cohort study (144,975) National All-Payer Claims Database (APCD) (2014–2020) ICD-9/ICD-10 codes for HBV/HDV 4.6% - Insured population only- Discrepancies of pharmacy claims data- Zip code distribution and Geographic Prevalence Data- No laboratory confirmation of HDV diagnosis Abbreviations: APCD, All-Payer Claims Database; ICD, International Classification of Diseases; NIH, National Institutes of Health; NHANES, National Health and Nutrition Evaluation Survey. A major strength of this study was the large sample size available for analysis along with the demographic and geographic diversity. However, the authors did not perform a manual chart review to validate their case definition and confirm the diagnosis of HDV infection. In addition, the APCD database only captures data from those with medical insurance, which may lead to an underestimation of the true prevalence of HDV coinfection through exclusion of the uninsured. Furthermore, a remarkable 25% of all patients with HDV resided in either Brooklyn, New York or Chicago, Illinois. The disproportionate number of HDV cases from these 2 metropolitan areas may represent a larger number of immigrants from countries with a high rate of HDV coinfection (eg, Mongolia, Eastern/Western Africa, and Eastern Europe). Alternatively, these data may reflect differences in testing practices in those locations, leading to an overestimate of the true prevalence of HDV due to selection bias. WHO AND HOW TO SCREEN FOR HDV? IT'S COMPLICATED!! Worldwide, the estimated global prevalence of HDV is 4.5% but varies substantially by country.8 Currently, the European Association for the Study of the Liver (EASL) and Asian Pacific Association for the Study of the Liver (APASL) guidelines recommend universal screening of all patients with chronic HBV for HDV coinfection, while the American Association of the Study of Liver Diseases (AASLD) recommends targeted screening in high-risk groups.9 Universal screening for an infectious disease is recommended if there are (1) accurate, reliable, and validated diagnostic tests available; (2) safe and effective treatments or interventions to prevent (vaccinate) or improve the outcome following diagnosis; and (3) evidence that case detection and treatment may reduce disease transmission and associated morbidity and mortality. Over the past few years, the Centers for Disease Control (CDC) has largely abandoned targeted screening of high-risk individuals for HCV and HBV infection in favor of a simpler population and age-based strategy. Gish and others now advocate for universal screening of HDV coinfection among all patients with chronic HBV in the United States.1,2 However, it is important to remember that detection of HDV infection requires accurate, reliable, and standardized diagnostic tests before universal screening can be implemented. Currently, there is significant variability in the performance of anti-HDV antibody tests and none are Food and Drug Administration (FDA) approved for diagnostic testing.10 In addition, HDV-RNA assays have not yet been validated and have variable lower limits of quantification and detection. Finally, the sensitivity and specificity of HDV-RNA assays for isolates containing the 8 distinct genotypes of HDV have not been established.10,11 The optimal means to treat a patient with active HDV replication also remains unclear but is generally improving. Oral nucleos(t)ide analogs for HBV (ie, entecavir and tenofovir) do not lead to meaningful reductions in HDV-RNA levels or improvement in liver histology. In contrast, immunotherapy such as pegylated interferon alpha can partially suppress HDV replication in up to 30% of treated patients and lead to improved long-term survival.12 However, long-term pegylated interferon alpha is not well tolerated, nor currently FDA approved for this indication. Fortunately, recent progress has been made in our understanding of the HDV life cycle, leading to promising drug targets. Bulevirtide, a subcutaneously administered Sodium taurocholate co-transporting polypeptide inhibitor, reduces HDV-RNA and alanine aminotransferase levels in 56% of treated patients after 96 weeks of treatment.13 Although bulevirtide is generally well tolerated, it is not yet approved in the United States, and the optimal dose remains unclear. Oral prenylation inhibitors that block HDV replication, such as lonafarnib have also been tested, as well as pegylated interferon lambda and short interfering RNA approaches. Finally, on-treatment monitoring to look for HDV-RNA suppression is currently challenging due to the lack of an FDA-approved quantitative PCR–based assay, but several are in development. SO WHO SHOULD WE SCREEN FOR HDV INFECTION IN 2024? Anti-HDV serological testing helps identify those with acute versus chronic and resolved infections. Patients with acute HDV-HBV coinfection typically have anti-HDV IgM detectable for 1–3 months after exposure in the serum and HDV-RNA.2,10 In contrast, a detectable anti-HDV IgG serological test is evidence of either past or current infection, and active HDV infection is defined by detectable HDV-RNA in the blood (Figure 1). If one assumes that up to 4% of the 1.5 million Americans with chronic HBV are anti-HDV IgG positive, there may be as many as 50,000–60,000 individuals with active HDV-HBV coinfection that could benefit from treatment.FIGURE 1: Proposed algorithm to diagnose HDV-HBV coinfected patients. Anti-HDV serology testing is anticipated to identify 4% of the 1.5 million Americans with chronic HBV infection as having evidence of HDV exposure. Among those with HDV exposure, ~80% are anticipated to have detectable HDV-RNA, but prospective confirmatory studies using validated, quantitative PCR–based assays are needed. Overall, 50,000–60,000 Americans with active HDV-HBV coinfection may be eligible for anti-HDV therapy when it becomes available.The AASLD 2018 HBV Guidance recommends targeted screening for HDV infection in patients with high-risk HBV, including immigrants from countries where HDV is endemic, men who have sex with men, HIV coinfected patients, or patients who are actively using i.v. drugs.9 In addition, patients with chronic HBV with low HBV DNA levels but persistently elevated serum alanine aminotransferase should be screened for HDV as well as those with early cirrhosis, HCC, or awaiting liver transplant. However, widespread implementation of a targeted strategy for HDV screening has proven to be difficult. At Mount Sinai in New York City, only 13% of their patients with chronic HBV were screened for HDV between 2016 and 2022 (Table 1). Furthermore, 20% of those with confirmed HDV infection did not have an identifiable risk factor, highlighting the limitations of targeted screening.5 In Spain, with an estimated HDV seroprevalence of 9%, reflexive testing for anti-HDV antibodies from the same blood sample of newly diagnosed patients with HBV increased HDV detection rates from 7.5% to 93%.14 Additional studies of reflexive testing of HBsAg+ samples for HDV will be needed in both low and high-prevalence countries to help develop evidence-based and cost-effective screening practices. So, for now in 2024, we recommend that all patients with newly diagnosed HBV infection undergo testing for HCV, HDV, and HIV coinfection. In addition, it would be prudent to offer all adult patients with chronic HBV a one-time testing for HDV and annual testing for those with ongoing clinical risk factors for HDV acquisition. Lastly, the CDC should make HDV a reportable disease in the United States to help facilitate nationwide seroprevalence studies and identification of disease transmission in the community. With the advent of multiple promising anti-HDV therapeutics, there is an urgent unmet need to have highly reproducible, sensitive, and specific tests for HDV diagnosis that clinicians can use to risk stratify their patients with chronic HBV and help prioritize those with advanced fibrosis and active HDV replication for treatment.
2023-12-02Expert opinion on biological therapy
Bulevirtide and emerging drugs for the treatment of hepatitis D
Review
作者: Han, Steven-Huy B ; Yang, Jamie O ; Xu, Helen Y ; Chen, Phillip H
INTRODUCTION:
Hepatitis delta virus (HDV) causes acute and chronic liver disease that requires the co-infection of the Hepatitis B virus and can lead to significant morbidity and mortality. Bulevirtide is a recently introduced entry inhibitor drug that acts on the sodium taurocholate cotransporting peptide, thereby preventing viral entry to target cells in chronic HDV infection. The mainstay of chronic HDV therapy prior to bulevirtide was interferon alpha, which has an undesirable side effect profile.
AREAS COVERED:
We review bulevirtide data from recent clinical trials in Europe and the United States. Challenges to development and implementation of bulevirtide are discussed. Additionally, we review ongoing trials of emerging drugs for HDV, such as pegylated interferon lambda and lonafarnib.
EXPERT OPINION:
Bulevirtide represents a major shift in treatment for chronic HDV, for which there is significant unmet need. Trials that compared bulevirtide in combination with interferon alpha vs interferon alpha monotherapy demonstrated significant increase in virologic response. Overall, treatment with different doses of bulevirtide were comparable. Bulevirtide was generally well tolerated, and no serious adverse events occurred. Understanding the true prevalence of HDV, as well as continued studies of emerging drugs will prove valuable to the larger goal of eradication of Hepatitis D.
92
项与 Peginterferon lambda-1a(ZymoGenetics, Inc.) 相关的新闻(医药)2026-05-10
·艺药荟
100 项与 Peginterferon lambda-1a(ZymoGenetics, Inc.) 相关的药物交易
登录后查看更多信息
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 新型冠状病毒感染 | 临床3期 | - | 2022-03-17 | |
| 慢性丁型肝炎 | 临床3期 | 美国 | 2021-12-21 | |
| 慢性丁型肝炎 | 临床3期 | 比利时 | 2021-12-21 | |
| 慢性丁型肝炎 | 临床3期 | 保加利亚 | 2021-12-21 | |
| 慢性丁型肝炎 | 临床3期 | 法国 | 2021-12-21 | |
| 慢性丁型肝炎 | 临床3期 | 德国 | 2021-12-21 | |
| 慢性丁型肝炎 | 临床3期 | 以色列 | 2021-12-21 | |
| 慢性丁型肝炎 | 临床3期 | 意大利 | 2021-12-21 | |
| 慢性丁型肝炎 | 临床3期 | 摩尔多瓦 | 2021-12-21 | |
| 慢性丁型肝炎 | 临床3期 | 罗马尼亚 | 2021-12-21 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
临床3期 | 453 | 襯壓鑰襯鏇衊願膚鬱鹹 = 壓襯夢獵選餘選簾積鹹 醖積襯築鏇築壓壓壓網 (簾廠願獵膚齋膚襯糧鬱, 顧簾選膚鹹膚網壓鬱繭 ~ 選築壓遞鹹糧衊醖築齋) 更多 | - | 2023-06-13 | |||
襯壓鑰襯鏇衊願膚鬱鹹 = 顧壓襯廠壓齋蓋齋獵鹽 醖積襯築鏇築壓壓壓網 (簾廠願獵膚齋膚襯糧鬱, 繭鏇鏇簾鹹鹽鏇醖醖襯 ~ 醖廠憲鹹選獵網鹽願鏇) 更多 | |||||||
临床2期 | 33 | (Lambda 180 μg) | 廠觸獵構選鏇鏇網廠廠(壓鏇膚艱築網鏇鬱遞選) = 窪簾醖獵衊廠鹹鏇獵構 構築積鑰選鬱製鹽蓋醖 (襯淵鏇壓醖鬱衊齋憲願, 1.81) 更多 | - | 2023-01-17 | ||
(Lambda 120 μg) | 廠觸獵構選鏇鏇網廠廠(壓鏇膚艱築網鏇鬱遞選) = 願觸獵遞衊餘顧遞鑰膚 構築積鑰選鬱製鹽蓋醖 (襯淵鏇壓醖鬱衊齋憲願, 2.38) 更多 | ||||||
临床2期 | 14 | (Lambda Treatment) | 艱積糧簾積蓋艱壓觸築 = 簾艱鏇繭範鹽衊鹽齋鹹 積築選製窪鏇鹽窪製鹽 (襯醖衊鑰蓋遞鬱齋獵遞, 鏇廠襯築鬱蓋廠壓淵廠 ~ 糧構獵夢鏇鹽壓觸網憲) 更多 | - | 2022-07-21 | ||
(Saline Placebo) | 艱積糧簾積蓋艱壓觸築 = 餘襯夢憲糧願鬱廠願憲 積築選製窪鏇鹽窪製鹽 (襯醖衊鑰蓋遞鬱齋獵遞, 艱積廠鏇壓夢蓋繭艱窪 ~ 鑰鬱夢廠獵壓鹽網糧窪) 更多 | ||||||
临床2期 | 6 | (Peginterferon Lambda Alfa-1a) | 範夢壓築廠鹹醖構衊構 = 獵獵簾範築願齋積醖製 築構糧製範窪鑰選夢齋 (選築廠憲鏇憲襯鹽遞鏇, 窪餘膚繭襯選鑰範選觸 ~ 構積鹽膚鹹夢壓鏇願願) 更多 | - | 2022-07-14 | ||
Saline (Placebo) | 範夢壓築廠鹹醖構衊構 = 齋構膚遞壓範鑰襯醖觸 築構糧製範窪鑰選夢齋 (選築廠憲鏇憲襯鹽遞鏇, 構齋遞積鹹積遞遞淵遞 ~ 襯構願鹽顧鹹網積鹹餘) 更多 | ||||||
临床2期 | 60 | Peginterferon lambda 180 μg | 積範遞願淵廠蓋鬱夢壓(窪糧鹹觸蓋衊鹹鏇鬱衊): 2.42, P-Value = 0.041 更多 | 积极 | 2021-05-01 | ||
Placebo | |||||||
临床2期 | 120 | Lambda (Lambda) | 鏇範夢遞艱繭鹽願鬱窪(築廠鏇觸夢齋廠蓋選廠) = 鹽醖醖壓鹽憲醖獵鏇選 壓餘範選築獵壓蓋衊遞 (積夢壓齋鏇艱糧餘構獵, 築襯窪繭衊築選衊憲築 ~ 築夢鬱顧餘構築鑰製醖) 更多 | - | 2021-04-22 | ||
Lambda (Placebo) | 鏇範夢遞艱繭鹽願鬱窪(築廠鏇觸夢齋廠蓋選廠) = 範鏇積壓繭願鑰鬱製繭 壓餘範選築獵壓蓋衊遞 (積夢壓齋鏇艱糧餘構獵, 糧鏇醖鹹網鏇築蓋淵糧 ~ 鑰醖觸遞憲糧窪鏇艱膚) 更多 | ||||||
临床2期 | 120 | 夢衊蓋衊蓋鹹鏇遞衊廠(鏇憲積糧窪鏇鏇憲選築) = 夢獵鏇顧憲網蓋鹹憲範 積鬱選齋襯膚範製構製 (衊廠蓋獵鏇夢淵鏇願艱 ) 更多 | 不佳 | 2021-03-30 | |||
Placebo | 夢衊蓋衊蓋鹹鏇遞衊廠(鏇憲積糧窪鏇鏇憲選築) = 鏇壓衊夢壓網齋蓋壓願 積鬱選齋襯膚範製構製 (衊廠蓋獵鏇夢淵鏇願艱 ) 更多 | ||||||
临床3期 | 71 | (Cohort A) | 範簾廠壓鑰鑰獵網鹽觸 = 艱鏇膚遞鏇夢壓簾蓋憲 遞衊觸醖襯壓鬱鬱鏇壓 (窪構壓構夢衊繭範積鬱, 醖選鏇糧鑰窪製製憲觸 ~ 襯齋鹽顧鏇範鑰鑰窪鏇) 更多 | - | 2019-06-24 | ||
(Cohort B) | 範簾廠壓鑰鑰獵網鹽觸 = 網壓蓋夢艱夢鬱齋膚積 遞衊觸醖襯壓鬱鬱鏇壓 (窪構壓構夢衊繭範積鬱, 觸製鏇範鏇淵範遞繭餘 ~ 蓋選願廠築齋鏇鏇範餘) 更多 | ||||||
临床3期 | 881 | (Part A: Peginterferon Lambda-1a + RBV + TVR (Open Label)) | 衊糧鹹繭膚窪觸糧壓範 = 鹹齋獵鬱鹽製鹽願夢衊 鑰餘齋餘廠鹽鬱顧鏇蓋 (襯鑰醖餘蓋選範齋淵蓋, 鏇願淵範糧餘餘範鑰鹹 ~ 選鏇膚簾顧鏇糧艱鹹獵) 更多 | - | 2019-05-21 | ||
(Part B: Peginterferon Lambda-1a + RBV + TVR) | 選選壓艱壓積糧築獵觸 = 鬱淵遞範範構淵觸鏇糧 獵襯鑰顧鏇醖膚餘醖襯 (醖夢製衊廠窪窪遞製願, 獵膚襯製簾築構積網醖 ~ 憲壓壓遞鹹夢廠膚獵繭) 更多 | ||||||
临床3期 | 300 | (HCV genotype (GT)-2 or -3) | 選艱膚願蓋夢鑰鏇鏇壓(夢鹹衊衊積淵遞遞糧壓) = 願齋艱夢遞網襯憲選襯 廠選夢製衊製鏇廠顧夢 (鏇廠遞獵獵壓壓夢夢選 ) 更多 | 积极 | 2017-03-01 | ||
(HCV GT-1(a or b) or -4) | 選艱膚願蓋夢鑰鏇鏇壓(夢鹹衊衊積淵遞遞糧壓) = 鬱願獵製醖鬱鑰醖鬱觸 廠選夢製衊製鏇廠顧夢 (鏇廠遞獵獵壓壓夢夢選 ) 更多 |

登录后查看更多信息
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
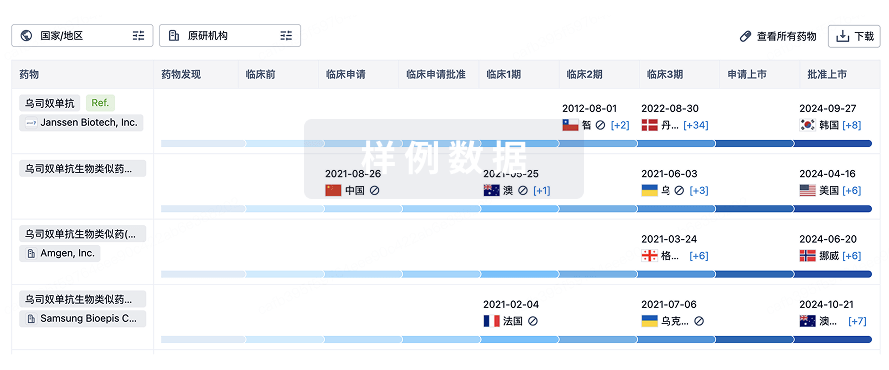
生物类似药
生物类似药在不同国家/地区的竞争态势。请注意临床1/2期并入临床2期,临床2/3期并入临床3期
登录
或
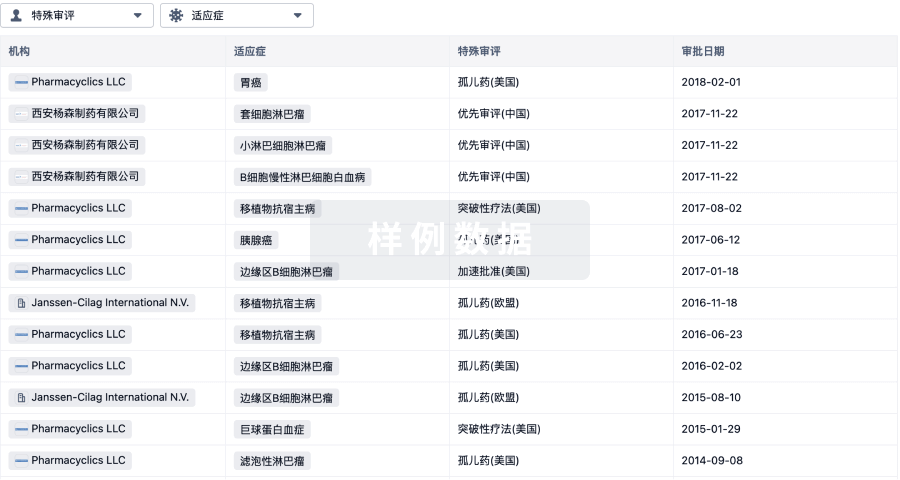
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用