预约演示
更新于:2026-05-22

Relay Therapeutics, Inc.
更新于:2026-05-22
概览
标签
肿瘤
皮肤和肌肉骨骼疾病
心血管疾病
小分子化药
化学药
蛋白水解靶向嵌合体(PROTAC)
疾病领域得分
一眼洞穿机构专注的疾病领域

技术平台
公司药物应用最多的技术
靶点
公司最常开发的靶点
关联
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |

靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |
靶点 |
作用机制 |
在研机构 |
原研机构 |
在研适应症 |
非在研适应症 |
最高研发阶段 |
首次获批国家/地区 |
首次获批日期 |
NCT07584226
A First-in-human Study of RLY-8161 for Treatment of Advanced NRAS-Mutant Melanoma and Other Solid Tumors
NCT06982521
A Phase 3 Open-Label Randomized Study Assessing the Efficacy and Safety of RLY-2608 + Fulvestrant Versus Capivasertib + Fulvestrant as Treatment for PIK3CA-mutant Hormone Receptor Positive, Human Epidermal Growth Factor Receptor 2 Negative (HR+/HER2-) Locally Advanced or Metastatic Breast Cancer Following Recurrence or Progression On or After Treatment With a CDK4/6 Inhibitor
NCT06789913
A Phase 2 Study of Mutant-selective PI3Kα Inhibitor, RLY-2608, in Adults and Children With PIK3CA Related Overgrowth Spectrum and Malformations Driven by PIK3CA Mutation
100 项与 Relay Therapeutics, Inc. 相关的临床结果
登录后查看更多信息
登录后查看更多信息
2026-02-09Journal of Chemical Information and Modeling
CACHE Challenge #3: Targeting the Nsp3 Macrodomain of SARS-CoV-2
Article
作者: Gentile, Francesco ; Chau, Irene ; Schapira, Matthieu ; Lee, Soowon ; Tarkhanova, Olga ; Walters, Patrick ; Tararina, Valentyna V. ; Della Corte, Dennis ; Tingey, Damon ; Sharma, Purshotam ; Fayne, Darren ; Chen, Yu ; Hoffer, Laurent ; Song, Minghu ; Ban, Fuqiang ; Paige, Brooks ; Talagayev, Valerij ; Herasymenko, Oleksandra ; Kozakov, Dima ; Jensen, Jan Halborg ; Cherkasov, Artem ; Arrowsmith, Cheryl ; Ravichandran, Rahul ; Hutchinson, Ashley ; Moretti, Rocco ; Meiler, Jens ; Koirala, Kushal ; Kotelnikov, Sergei ; Lessel, Uta ; Silva, Madhushika ; Steinmann, Casper ; Park, Keunwan ; Hillisch, Alexander ; Seitova, Almagul ; Stevens, Rick ; Sabnis, Yogesh ; Abu-Saleh, Abd Al-Aziz A. ; Rosta, Edina ; Karlova, Andrea ; Tropsha, Alexander ; Poda, Gennady ; Liu, Sijie ; Moroz, Yurii S. ; Doering, Niklas P. ; Günther, Judith ; Edwards, Aled ; Dehaen, Wim ; Beck, Hartmut ; Wortmann, Lars ; Wolber, Gerhard ; Bishop, Kevin P. ; Muvva, Charuvaka ; Edfeldt, Kristina ; Hogner, Anders ; Bolotokova, Albina ; Oprea, Tudor I. ; Gibson, Elisa ; Trant, John F. ; Gokdemir, Ozan ; Scott, Thomas ; Loppnau, Peter ; Breznik, Marko ; Zheng, Shuangjia ; Harding, Rachel J. ; Rognan, Didier ; Pandit, Amit ; Ashworth, Alan ; Gunnarsson, Anders ; Lee, Juyong ; Fraser, James S. ; Liu, Xuefeng ; Correy, Galen J. ; Kandwal, Shubhangi ; Bohórquez, Hugo J. ; Pütter, Vera ; Treleaven, Dakota ; Wells, Jude ; Protopopov, Mykola V. ; Denzinger, Katrin ; Westermaier, Yvonne ; Irwin, John J. ; Sindt, François ; Ackloo, Suzanne
The third Critical Assessment of Computational Hit-finding Experiments (CACHE) challenged computational teams to identify chemically novel ligands targeting the macrodomain 1 of SARS-CoV-2 Nsp3, a promising coronavirus drug target. Twenty-three groups deployed diverse design strategies to collectively select 1739 ligand candidates. While over 85% of the designed molecules were chemically novel, the best experimentally confirmed hits were structurally similar to previously published compounds. Confirming a trend observed in CACHE #1 and #2, two of the best-performing workflows used compounds selected by physics-based computational screening methods to train machine learning models able to rapidly screen large chemical libraries, while four others used exclusively physics-based approaches. Three pharmacophore searches and one fragment growing strategy were also part of the seven winning workflows. While active molecules discovered by CACHE #3 participants largely mimicked the adenine ring of the endogenous substrate, ADP-ribose, preserving the canonical chemotype commonly observed in previously reported Nsp3-Mac1 ligands, they still provide novel structure-activity relationship insights that may inform the development of future antivirals. Collectively, these results show that multiple molecular design strategies can efficiently converge on similar potent molecules.
2025-09-22Journal of Chemical Information and Modeling
Practically Significant Method Comparison Protocols for Machine Learning in Small Molecule Drug Discovery
Article
作者: Cheng, Alan C. ; Aldeghi, Matteo ; Clevert, Djork-Arné ; Ash, Jeremy R. ; Price, Daniel J. ; Hughes-Oliver, Jacqueline M. ; Rodríguez-Pérez, Raquel ; Fang, Cheng ; Wognum, Cas ; Engkvist, Ola ; Walters, W. Patrick
Machine Learning (ML) methods that relate molecular structure to properties are frequently proposed as in silico surrogates for expensive or time-consuming experiments. In small molecule drug discovery, such methods inform high-stakes decisions like compound synthesis and in vivo studies. This application lies at the intersection of multiple scientific disciplines. When comparing new ML methods to baseline or state-of-the-art approaches, statistically rigorous method comparison protocols and domain-appropriate performance metrics are essential to ensure replicability and ultimately the adoption of ML in small molecule drug discovery. This paper proposes a set of guidelines to incentivize rigorous and domain-appropriate techniques for method comparison tailored to small molecule property modeling. These guidelines, accompanied by annotated examples using open-source software tools, lay a foundation for robust ML benchmarking and thus the development of more impactful methods.
2025-07-14Journal of Chemical Information and Modeling
CACHE Challenge #2: Targeting the RNA Site of the SARS-CoV-2 Helicase Nsp13
Article
A critical assessment of computational hit-finding experiments (CACHE) challenge was conducted to predict ligands for the SARS-CoV-2 Nsp13 helicase RNA binding site, a highly conserved COVID-19 target. Twenty-three participating teams comprised of computational chemists and data scientists used protein structure and data from fragment-screening paired with advanced computational and machine learning methods to each predict up to 100 inhibitory ligands. Across all teams, 1957 compounds were predicted and were subsequently procured from commercial catalogs for biophysical assays. Of these compounds, 0.7% were confirmed to bind to Nsp13 in a surface plasmon resonance assay. The six best-performing computational workflows used fragment growing, active learning, or conventional virtual screening with and without complementary deep-learning scoring functions. Follow-up functional assays resulted in identification of two compound scaffolds that bound Nsp13 with a Kd below 10 μM and inhibited in vitro helicase activity. Overall, CACHE #2 participants were successful in identifying hit compound scaffolds targeting Nsp13, a central component of the coronavirus replication-transcription complex. Computational design strategies recurrently successful across the first two CACHE challenges include linking or growing docked or crystallized fragments and docking small and diverse libraries to train ultrafast machine-learning models. The CACHE #2 competition reveals how crowd-sourcing ligand prediction efforts using a distinct array of approaches followed with critical biophysical assays can result in novel lead compounds to advance drug discovery efforts.
2026-05-21
·药研苑
100 项与 Relay Therapeutics, Inc. 相关的药物交易
登录后查看更多信息
100 项与 Relay Therapeutics, Inc. 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年08月03日管线快照
管线布局中药物为当前组织机构及其子机构作为药物机构进行统计,早期临床1期并入临床1期,临床1/2期并入临床2期,临床2/3期并入临床3期
药物发现
4
1
临床前
临床1期
3
1
临床3期
其他
8
登录后查看更多信息
当前项目
登录后查看更多信息
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
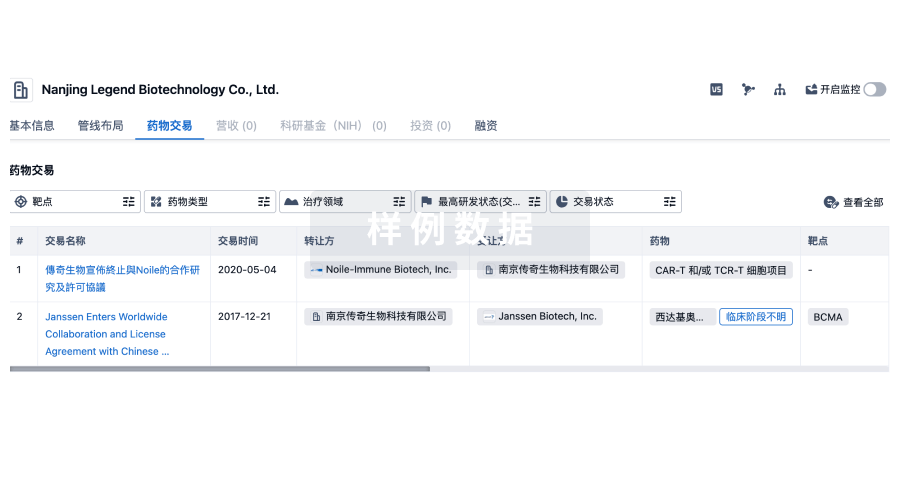
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
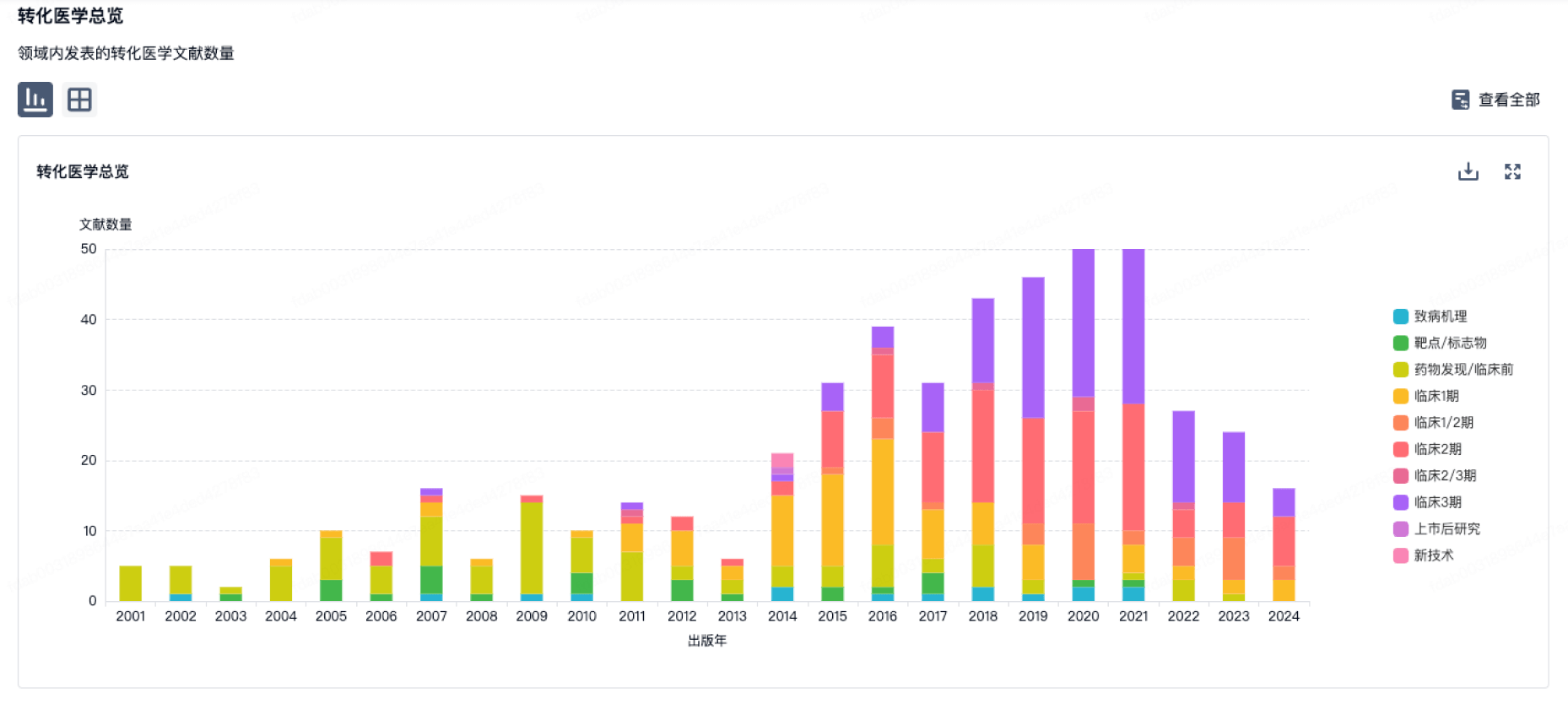
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
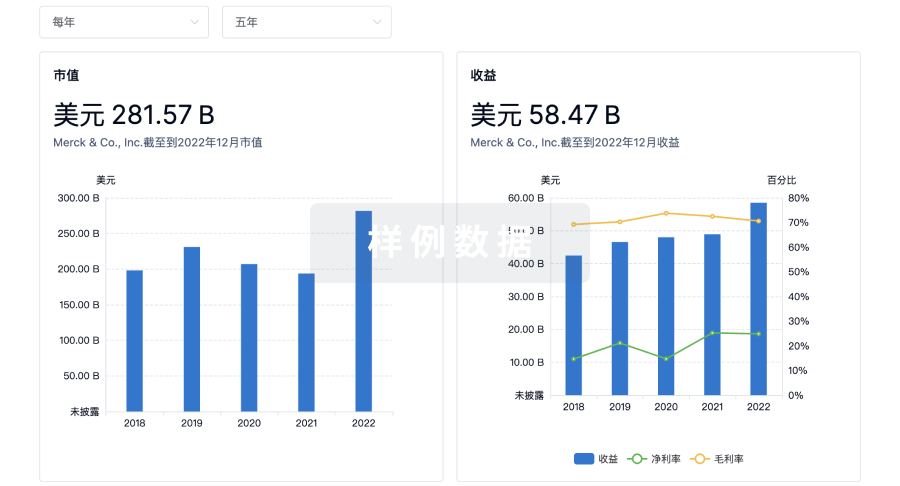
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用