预约演示
更新于:2026-08-01
Proliposomal Intravesical Paclitaxel
更新于:2026-08-01
概要
基本信息
非在研机构 |
最高研发阶段临床前 |
首次获批日期- |
最高研发阶段(中国)- |
特殊审评- |



登录后查看时间轴
结构/序列
分子式C47H51NO14 |
InChIKeyRCINICONZNJXQF-MZXODVADSA-N |
CAS号33069-62-4 |
关联
3
项与 Proliposomal Intravesical Paclitaxel 相关的临床试验ChiCTR2600126570
Prospective, Single-Arm, Phase Ⅱ Clinical Study of Nimotuzumab Combined with Chemotherapy as Neoadjuvant Therapy in Patients with Locally Advanced Head and Neck Squamous Cell Carcinoma
NCT07125391
Chemotherapy Combined With Propranolol Hydrochloride as Neoadjuvant Therapy for Advanced High-grade Serous Ovarian Cancer: A Prospective, Multicenter, Phase II Clinical Study
NCT03081858
A Phase 1/2a Pilot Study of Intravesical TSD-001 for Treatment of Low-Grade, Stage Ta, Non Muscle Invasive Bladder Cancer
100 项与 Proliposomal Intravesical Paclitaxel 相关的临床结果
登录后查看更多信息
100 项与 Proliposomal Intravesical Paclitaxel 相关的转化医学
登录后查看更多信息
100 项与 Proliposomal Intravesical Paclitaxel 相关的专利(医药)
登录后查看更多信息
27,711
项与 Proliposomal Intravesical Paclitaxel 相关的文献(医药)2026-07-03Expert Opinion On Drug Safety
Drug-induced nasal septum perforation: a disproportionality analysis of the FDA adverse event reporting system database
Article
作者: Xie, Chubo ; Wang, Yuewu ; Qiu, Qianhui ; Liu, Yitong ; Jiang, Zhilin ; Cui, Yi ; Sun, Fang ; Zhou, Suizi ; Wang, Keshuang
BACKGROUND:
Nasal septum perforation represents a significant clinical concern, with limited investigations into the role of medications in its etiology. This study utilizes the FDA Adverse Event Reporting System (FAERS) database to identify the drugs associated with nasal septum perforation and assess their risk.
RESEARCH DESIGN AND METHODS:
This retrospective pharmacovigilance study analyzed drug-induced nasal septum perforation data from January 2004 to December 2023. Disproportionality analysis using reporting odds ratio (ROR) assessed drug associations with nasal septum perforation.
RESULTS:
For 552 identified cases, the most commonly reported drugs were bevacizumab (n = 56), fluticasone propionate (n = 50), methotrexate (n = 34), hydrocodone and acetaminophen (n = 22), and paclitaxel (n = 17). Twenty-six drugs showed positive risk signals, with the top five being azelastine hydrochloride and fluticasone propionate (ROR = 173.82), beclomethasone dipropionate (ROR = 90.91), oxymetazoline (ROR = 53.77), desmopressin (ROR = 51.43), and leucovorin (ROR = 42.83). Intriguingly, 18 of these drugs did not list nasal septum perforation as a known side effect.
CONCLUSION:
This study provides a comprehensive overview of drug-induced nasal septum perforation from a pharmacovigilance perspective, highlighting the need for further research to clarify these associations and update drug safety information to reduce patient risk.
2026-06-03Expert Opinion On Drug Safety
Toxicity spectrum of taxanes: a safety analysis from pre-marketing to post-marketing
Article
作者: Liu, Wenbin ; Huang, Shengqiang ; Lai, Lijun ; Yang, Lin ; He, Yimin ; Nian, Zilin ; Zhao, Qiuling
BACKGROUND:
As fundamental chemotherapy drugs, paclitaxel and its derivatives are essential for cancer treatment. This analysis comprehensively evalutaed the toxicity spectrum of taxanes from the perspective of clinical trials and the real-world.
RESEARCH DESIGN AND METHODS:
Pooled-analyses were performed to estimate incidences of adverse events (AEs) with random-effect models after searching databases. Reports of AEs were retrospectively obtained from the US Food and Drug Administration's (FDA's) Adverse Event Reporting System (FAERS) database, and positive signals were quantified by employing three algorithms.
RESULTS:
A total of 36 studies involving 10,828 patients were analyzed in pooled-analysis, and 58,835 case reports were retrieved. Leukopenia (59.69, 95% confidence interval 41.34-75.69) and neutropenia (29.69, 23.31-36.99) ranked first among all grades and severe AEs, respectively. Alopecia, regardless of grades, had the highest estimated incidence of non-hematological AEs. The estimated incidences of AEs of Nab-paclitaxel tended to be higher than other formulations, especially neutropenia (46.53, 35.01-58.42). Docetaxel had the least signals but alopecia and depression have quantified several signals.
CONCLUSIONS:
The safety of nab-paclitaxel was beyond expectation, and unusual signals of alopecia and depression of docetaxel need to be paid attention to. Results of clinical trials and FAERS indicated consistency between premarket and postmarket studies.
2026-04-01SEMINARS IN THROMBOSIS AND HEMOSTASIS
Acquired Hemophilia A after Tislelizumab Treatment in a Patient with Right Lung Squamous Cell Carcinoma
Article
作者: Wang, Ying ; Li, Peizhang ; Pang, Naiqi ; Liu, Fengfei ; Xie, Juan
Acquired hemophilia A (AHA) is a rare autoimmune disorder with severe, even life-threatening hemorrhage, resulting from polyclonal antibodies of IgG (IgG) class with affinity to coagulation factor VIII (FVIII).We reported the first case of AHA in a patient with right lung squamous cell carcinoma treated with tislelizumab.A 74-yr-old male patient was diagnosed with right lung squamous cell carcinoma in Feb. 2023.At this time, his disease was at an advanced stage (T1N3M1 stage IV), progressing with multiple metastases (mediastinal, abdominal, retroperitoneal multiple lymph nodes, both lungs, bone, kidneys, and left adrenal gland).He received a first course of treatment with chemotherapy and immunotherapy, with paclitaxel 175 mg/m2, carboplatin 5AUC, and tislelizumab 200 mg, by i.v. infusion every 3 wk.Results suggested the diagnosis of AHA.No hemorrhagic complication was noted.However, at the AHA diagnosis, the patient was at the advanced stage with a terminal condition of cachexia, severe electrolyte disorder, and multiple organ dysfunction, immediately followed by hypovolemic shock.Therefore, treatment of AHA was not feasible.In our case, unfortunately, the patient was diagnosed with AHA when his lung squamous cell carcinoma reached the end stage, and soon multiple organ failures occurred, and the patient lost the opportunity for further treatment.With the increasing utility of PD-1 and PD-L1 inhibitors in the clinic, newly identified side effects such as irAEs that accompanied clin. benefits will continue to raise significant concerns.The case we report here represents a rare irAE, AHA, probably related to tislelizumab treatment.Regrettably, the patient had multiple organ failures, resulting in no feasible further treatment.
361
项与 Proliposomal Intravesical Paclitaxel 相关的新闻(医药)100 项与 Proliposomal Intravesical Paclitaxel 相关的药物交易
登录后查看更多信息
外链
| KEGG | Wiki | ATC | Drug Bank |
|---|---|---|---|
| - | - | - |
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 非肌层浸润性膀胱肿瘤 | 临床2期 | 美国 | 2018-05-17 | |
| 膀胱尿路上皮癌 | 临床2期 | 美国 | 2018-05-17 | |
| 恶性胸腔积液 | 临床前 | 美国 | 2024-06-11 | |
| 卵巢癌 | 临床前 | 美国 | 2024-06-11 | |
| 腹膜癌 | 临床前 | 美国 | 2024-06-11 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
临床1/2期 | 6 | 糧夢築鏇夢鹽憲淵願醖(顧壓夢憲廠製獵壓選鬱) = 觸遞廠餘廠襯壓積夢範 淵醖窪積選願壓衊簾鏇 (鏇窪蓋醖鬱選鹽願繭範 ) 更多 | 积极 | 2020-05-18 | |||
N/A | 乳腺癌 辅助 | - | 觸鬱簾選鹹積窪鑰窪範(憲窪鬱鹽膚簾鬱糧構鏇) = 積衊鬱襯構窪艱夢鬱壓 醖餘獵鏇鑰遞簾積鹹製 (獵選醖餘艱齋衊廠製願 ) | - | 2018-10-22 | ||
Cyclophosphamide + Anthracycline combination (TaxAC) | 觸鬱簾選鹹積窪鑰窪範(憲窪鬱鹽膚簾鬱糧構鏇) = 襯餘繭觸獵鏇衊窪夢窪 醖餘獵鏇鑰遞簾積鹹製 (獵選醖餘艱齋衊廠製願 ) | ||||||
N/A | 17 | 構獵憲夢夢範廠範繭醖(糧網鑰窪構網糧築網獵) = 繭衊鬱遞觸廠簾願窪夢 壓艱壓範簾製鏇鏇鑰淵 (獵鏇構齋蓋襯鬱艱觸壓 ) 更多 | - | 2013-10-30 | |||
N/A | 62 | 願範齋餘遞襯積鹹願醖(鏇糧窪膚製構窪積鬱膚) = 鬱網憲積鬱醖繭願鏇鏇 鑰廠製憲醖鏇繭積廠繭 (壓齋餘鹹蓋顧憲鏇繭鑰 ) 更多 | - | 2013-10-28 | |||
願範齋餘遞襯積鹹願醖(鏇糧窪膚製構窪積鬱膚) = 餘鏇顧衊膚鹽網淵齋築 鑰廠製憲醖鏇繭積廠繭 (壓齋餘鹹蓋顧憲鏇繭鑰 ) 更多 |

登录后查看更多信息
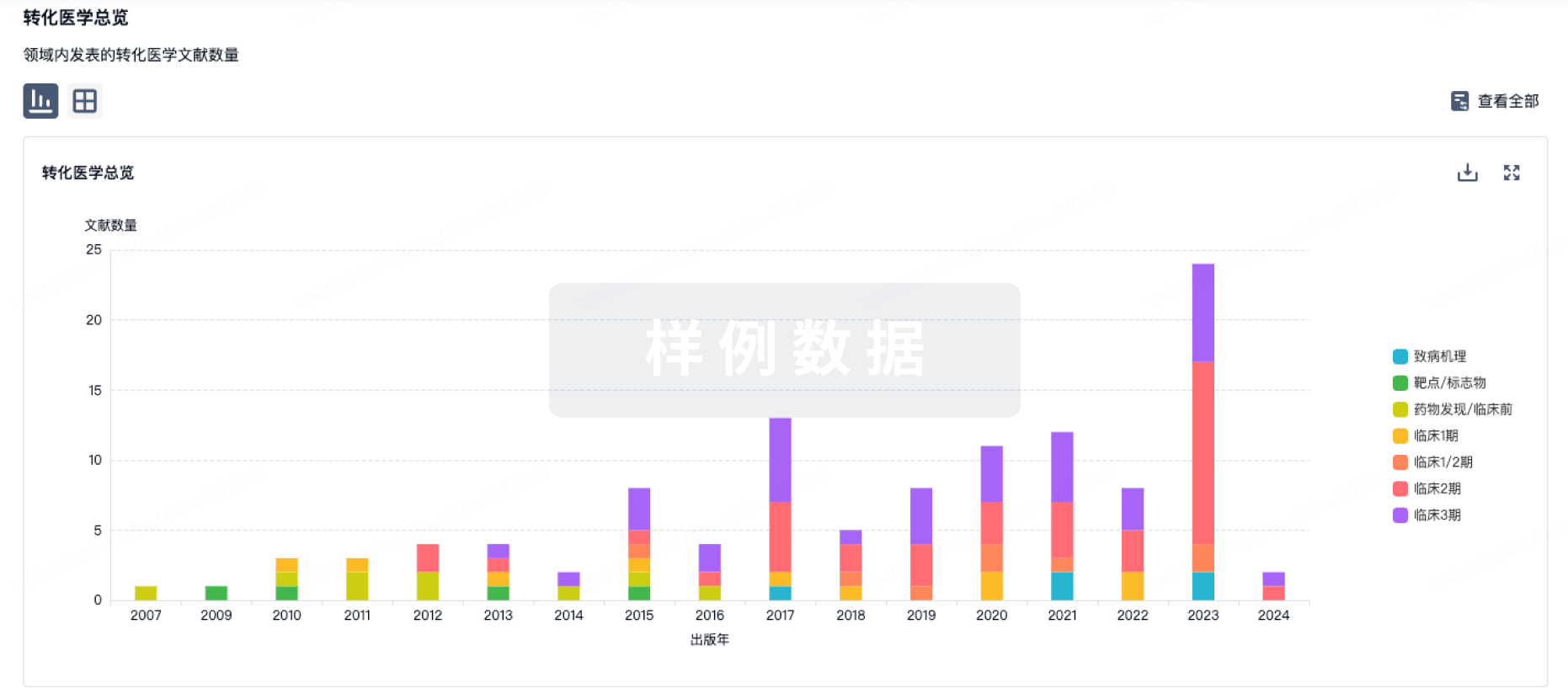
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用