预约演示
更新于:2026-02-26
General Regeneratives Shanghai Ltd.
交晨生物医药技术(上海)有限公司|子公司|2007|中国上海市
交晨生物医药技术(上海)有限公司|子公司|2007|中国上海市
更新于:2026-02-26
概览
标签
消化系统疾病
免疫系统疾病
心血管疾病
单克隆抗体
重组蛋白
白细胞介素
疾病领域得分
一眼洞穿机构专注的疾病领域

暂无数据
技术平台
公司药物应用最多的技术
暂无数据
靶点
公司最常开发的靶点
暂无数据
| 排名前五的药物类型 | 数量 |
|---|---|
| 单克隆抗体 | 6 |
| 小分子化药 | 4 |
| 重组蛋白 | 3 |
| 生物药 | 2 |
| 白细胞介素 | 1 |
关联
17
项与 交晨生物医药技术(上海)有限公司 相关的药物靶点 |
作用机制 TYK2抑制剂 |
非在研适应症- |
最高研发阶段临床2期 |
首次获批国家/地区- |
首次获批日期- |
靶点 |
作用机制 IL1R1拮抗剂 |
原研机构 |
非在研适应症 |
最高研发阶段临床2期 |
首次获批国家/地区- |
首次获批日期- |
靶点- |
作用机制- |
在研适应症 |
非在研适应症- |
最高研发阶段临床1/2期 |
首次获批国家/地区- |
首次获批日期- |
13
项与 交晨生物医药技术(上海)有限公司 相关的临床试验NCT07234591
A Multi-Center, Randomized, Double-Blind, Placebo-Controlled, Parallel Group Study to Evaluate the Efficacy and Safety of a TYK2 Inhibitor in Subjects With Moderate to Severe Plaque Psoriasis
A Study to evaluate efficacy and safety in subjects with moderate to severe Plaque Psoriasis treated with a TYK2 Inhibitor for 12 weeks
开始日期2025-10-21 |
申办/合作机构 |
CTR20253729
评价UA021治疗中重度斑块状银屑病的有效性和安全性的多中心、随机、双盲、安慰剂平行对照的Ⅱ期临床研究
主要目的:评估UA021不同剂量组治疗中重度银屑病的有效性。
次要目的:评估UA021不同剂量组治疗中重度银屑病的安全性;评估UA021不同剂量组在疗中重度银屑病患者中的药代动力学(PK)特征。
开始日期2025-10-17 |
申办/合作机构 |
NCT07038720
A Phase I Study to Evaluate the Safety, Tolerability, Pharmacokinetic Profile, and Food Effect of UA026 Tablets in Healthy Adult Subjects and Adult Subjects With Moderate to Severe Plaque Psoriasis
This study is a randomized, double-blind, placebo-controlled study to evaluate the safety, tolerability, pharmacokinetic profile, and food effect of UA026 tablets.
The study consists of four parts: Part A is a single ascending dose (SAD) study, Part B is a multiple ascending dose (MAD) study, Part C is a food effect (FE) study, and Part D is a multi-dose parallel control study. Part A, B, and C will be conducted in healthy subject, and Part D will be conducted in subjects with moderate to severe plaque psoriasis.
The study consists of four parts: Part A is a single ascending dose (SAD) study, Part B is a multiple ascending dose (MAD) study, Part C is a food effect (FE) study, and Part D is a multi-dose parallel control study. Part A, B, and C will be conducted in healthy subject, and Part D will be conducted in subjects with moderate to severe plaque psoriasis.
开始日期2025-05-08 |
申办/合作机构 |
100 项与 交晨生物医药技术(上海)有限公司 相关的临床结果
登录后查看更多信息
0 项与 交晨生物医药技术(上海)有限公司 相关的专利(医药)
登录后查看更多信息
2
项与 交晨生物医药技术(上海)有限公司 相关的文献(医药)2019-10-01·European journal of drug metabolism and pharmacokinetics
Author’s Reply to: “Comment on: Pharmacokinetics and Safety of Recombinant Human Interleukin-1 Receptor Antagonist GR007 in Chinese Healthy Subjects”
Letter
作者: Cui, Yimin ; Yu, Yan ; Zhang, Yang ; Wang, Xin ; Zhou, Shuang ; Zhao, Nan ; Han, Wei ; Zhao, Xia ; Xie, Ran
A review.This article discusses the pharmacokinetics and safety of recombinant human interleukin-1 receptor antagonist GR007 in Chinese healthy subjects.
2019-06-01·European journal of drug metabolism and pharmacokinetics
Pharmacokinetics and Safety of Recombinant Human Interleukin-1 Receptor Antagonist GR007 in Healthy Chinese Subjects
Article
作者: Cui, Yimin ; Yu, Yan ; Zhang, Yang ; Wang, Xin ; Zhou, Shuang ; Zhao, Nan ; Han, Wei ; Zhao, Xia ; Xie, Ran
BACKGROUND AND OBJECTIVES:
The recombinant human interleukin-1 receptor antagonist (rhIL-1Ra) GR007 is a candidate drug with the potential to prevent the toxicity induced by chemotherapy agents by blocking the IL-1 signaling pathway. The aim of this study was to assess the pharmacokinetics and safety of GR007 in healthy Chinese subjects.
METHODS:
Thirty subjects received a single intramuscular injection of 30 mg (n = 10), 90 mg (n = 10), or 150 mg (n = 10) GR007. After administration, the pharmacokinetic characteristics and safety were evaluated.
RESULTS:
No serious adverse events were reported in this study, and the adverse events reported showed no dose dependency. Pharmacokinetic analysis showed that the median time to maximum concentration (Tmax) of GR007 in the three groups was between 2.75 and 4.00 h and the geometric mean elimination half-life (T1/2) for each group was 2.38, 2.22, and 3.29 h, respectively. The area under the concentration vs time curve (AUC), but not the maximum concentration (Cmax), increased in a dose-proportional manner.
CONCLUSIONS:
The results showed that a single intramuscular injection of 30-150 mg GR007 had good safety and tolerability in healthy Chinese subjects. The results of the evaluation of the safety and pharmacokinetics of GR007 performed in this study support its use as a repeated daily injection in ongoing clinical trials focusing on patients with cancer.
138
项与 交晨生物医药技术(上海)有限公司 相关的新闻(医药)2026-02-14
个人感想:
由于癌细胞本身的高频分裂、DNA不稳定等特性,在压力下,其自然容易出现能逃逸压力的突变和进化。那如何减少癌细胞突变进化的机会呢。也许可以考虑多管齐下,多种作用机制或针对多种突变的药物同时使用,给癌细胞制造出,超过其突变进化速度的压力,以达到一举歼灭的目的?
围绕KRAS的药物开发,可谓是百花齐放,也越来越来精巧复杂。这应该是大多红海靶点的未来走向,没有最好,总有更好。个人是比较看好ADC-KRASi(可能有惊喜),而PROTAC降解和anti-KRAS疫苗可能还有待突破
针对KRAS的临床多如牛毛,真是没有最卷,只有更卷。想想这竞争力度,都觉得头皮发麻啊。所以,希望大家同时在能产出增量的基础研究上多多努力,让大伙都能松口气+有口饭吃.....
小分子药物出现已有上百年?但随着新靶点、新机制的发现,以及AI等工具的完善,小分子药物仍然活跃在舞台上
如果癌症由于其复杂性和不可战胜性被称为“众病之王”,那么KRAS突变就是这位国王皇冠上最坚硬的钻石。在很长一段时间里,它被药企和科学家公认为不可成药Undruggable。
为什么这个早在1982年就被发现、驱动了近1/3人类恶性肿瘤的致癌基因,直到2021年才有第一款针对性药物获批。一,死亡开关的卡死
1960年,科学家在研究小鼠白血病病毒时,发现一种能让大鼠长出肉瘤的病毒基因,命名为“ras”,取自大鼠肉瘤rat sarcoma的缩写。这就是RAS家族的雏形,而KRAS正是这个家族中最“凶险”的成员。
当时,没有“致癌基因”的认知,大家认为癌症是由病毒感染引起的,RAS基因只是病毒携带的“配角”。这种误读,让RAS不被药企重视。
转折点出现在1979年。麻省理工的罗伯特·温伯格将小鼠的肿瘤DNA转入正常细胞,意外发现这些细胞发生了癌变。而导致细胞癌变的,正是与病毒ras基因同源的人类细胞基因。这是首次发现:自身的基因变异才是癌症发生的核心原因。
随着基础研究的深入,发现RAS蛋白是细胞信号传导中的关键分子开关,调控着细胞的增殖、生存与迁移,在RAF-MEK-ERK信号通路中扮演着核心角色。RAS随之开始被药企所重视。
首先,我们需要理解为什么 KRAS 如此重要,如此难搞。
想象一下电灯开关,按下开,灯亮;按下关,灯灭。在细胞里,RAS蛋白家族(包括KRAS、NRAS、HRAS)就是这样一个开关。它负责接收细胞外的生长信号,然后告诉细胞核:“外面环境不错,可以分裂”。
正常情况下,RAS蛋白结合了GTP(三磷酸鸟苷)就是“开”,结合了GDP(二磷酸鸟苷)就是“关”。这个过程非常迅速且受到严格调控。
但是,当KRAS基因发生突变(比如G12C突变),这个开关就坏了。坏的方式很特别:它卡在了“开”的位置上。细胞就会疯一样地不断分裂,最终形成肿瘤。
RAS 突变存在于约 30%的人类癌症中。
KRAS 是其中最凶残的,占据了 RAS 突变的 85%,也是最常见的突变亚型,在胰腺癌90%、结肠癌50%、肺癌30%、甲状腺癌50%中高频突变。
1980年代发现KRAS 后,科学家想方设法阻止KRAS的“开”的状态。但他们撞上了一堵墙。
二,为什么说 KRAS 不可成药
小分子药物研发有一个基本逻辑:锁钥原理。蛋白质表面通常有口袋Pocket,小分子就像一把钥匙,插进这个口袋里,就能改变蛋白质的功能。
RAS蛋白之所以长期被视为“不可成药”,有三大难点:
1,表面平滑,缺乏口袋:大多数致癌蛋白(比如 EGFR/HER2)表面都有深的口袋。RAS蛋白表面平滑,缺乏结合口袋,使得小分子难以结合。
2,超高亲和力:RAS与GTP/GDP的亲和力极高,解离常数达到皮摩尔pM级别,难以通过竞争性抑制剂取代。
3,多种突变亚型:KRAS突变可进一步细分为G12C、G12D、G12V等多个亚型,针对不同亚型需要开发精准抑制剂。
于是,从1980年到2010年,无数药企在这个靶点上折戟沉沙。辉瑞、罗氏、默沙东投入巨资筛选了数十万种化合物后,要么没有抑制活性,要么毒性过大,最终都不了了之。教科书上甚至开始写:直接抑制KRAS是不可能的。三,曲线救国
当时有一个行业共识:与其直接靶向KRAS这个硬骨头,不如绕开它,靶向其上下游的信号通路,比如EGFR、BRAF、MEK等。
于是,一场曲线救国的研发浪潮开启了。1997年,第一款EGFR抑制剂吉非替尼进入临床试验,2003年获批上市,用于治疗EGFR突变的非小细胞肺癌;2001年,BRAF抑制剂维莫非尼进入研发阶段,2011年获批用于治疗BRAF V600E突变的黑色素瘤;2013年,MEK抑制剂曲美替尼获批上市,用于治疗BRAF突变的晚期黑色素瘤。
这些药物的上市,给部分癌症患者带来了希望,但对于KRAS突变的患者来说,却是“杯水车薪”。EGFR抑制剂对KRAS突变患者的客观缓解率ORR不足5%,MEK抑制剂的ORR只有10%,中位无进展生存期mPFS=3-4个月,与化疗相比,几乎没有优势。
更残酷的是,这些“曲线救国”的药物,还会引发严重的耐药问题。比如,使用MEK抑制剂的患者,平均在用药6个月后就会出现耐药,而耐药的主要原因之一,就是KRAS基因的二次突变。
四,那个不起眼的裂缝
当时,凯·舒卡特Kevan Shokat教授是少数选择坚持研究直接靶向KRAS的。他拿到博士学位后,放弃了当时热门的EGFR研究方向,选择了KRAS,这个被所有人视为死胡同的靶点。
转机出现在2013 年,舒卡特的思路很特别:他没有执着于寻找能结合KRAS口袋的小分子,而是把目光放在了KRAS的突变位点上。他发现,KRAS的突变位点相对集中,其中G12C突变(第 12 位的甘氨酸Glycine突变成了半胱氨酸Cysteine)在非小细胞肺癌中占比最高,约为13%的KRAS突变患者是这种亚型。而半胱氨酸残基有独特的化学性质=可以与丙烯酰胺等化合物形成不可逆的共价结合。
他发现,虽然KRAS表面是圆滑的,但在G12C突变体的非活性状态(GDP结合态)下,在第12位突变残基旁边出现一个以前未被发现的“浅浅口袋”(Switch-II Pocket)。
这个发现简直是神来之笔:不去碰活性状态(GTP态),就盯着它偶尔休息的一瞬间(GDP态)。当 KRAS 短暂地处于“关”的状态时,用一个分子的“钩子”伸进这个浅口袋,与那个突变的半胱氨酸发生不可逆的共价结合。一旦结合,这个药物就像一把锁,把 KRAS锁死在“关”的状态,不让它再变回“开”。
2013年,舒卡特在《自然》杂志上发表了这篇划时代的论文。虽然当时那个分子活性还不强,但这相当于明示:KRAS是可以被搞定的!五,百亿美元的竞速
舒卡特的论文一出,原本已经放弃 KRAS 的制药界瞬间沸腾。既然原理通了,剩下的就是工程问题=优化分子结构,提高效力,降低毒性。这就进入了我们熟悉的商业竞速环节。
跑得最快的是舒卡特参与创立的Wellspring 小公司,后来这个项目不同的公司接手,但真正的黑马是安进Amgen。安进花费了5年时间,对舒卡特的化合物的结构进行了上百次修改,得到了候选药物=AMG 510。
2018年,安进公布 AMG 510 的临床前数据,效果惊人,并进入进入Ⅰ期临床试验。2019年,ASCO年会,安进公布了早期临床数据,全场起立鼓掌。2021年5月,FDA 加速批准 AMG 510 上市,商品名 Lumakras(索托拉西布Sotorasib)。
这是第一款获批的 KRAS 抑制剂。在针对携带 KRAS G12C 突变的非小细胞肺癌患者的试验中,Sotorasib 的客观缓解率ORR=37%,中位总生存期OS= 12.5 个月。而化疗组的ORR仅为8%,mPFS仅为4.2个月,mOS仅为8.1个月。其疗效,显著优于化疗。
紧随其后的是Mirati Therapeutics公司的阿达格拉西布Adagrasib (MRTX849),它在 2022 年获得了FDA 批准。与索托拉西布相比,阿达格拉西布的半衰期更长(约24小时),可以每天服药一次。阿达格拉西布的胃肠道副作用发生率更高,索托拉西布的肝毒性风险略高。对于临床医生,需要根据患者的情况,选择合适的药物。
此时的中国,劲方医药也开始在KRAS抑制剂领域发力。其KRAS G12C抑制剂氟泽雷塞片(达伯特®,GFH925/IBI351)已获批上市。六,红海与蓝海
除了两款已上市的药物,全球还有70个KRAS在研项目,其中一半以上围绕G12C突变展开。激烈的竞争,引发了一波“撤退潮”:2024年,诺华放弃了已进入Ⅲ期临床的KRAS G12C抑制剂JDQ443。贝达的KRAS G12C抑制剂BPI-421286,也因临床优势不明显而停止。2026年,Verastem终止RAMP 203临床试验。
Verastem的撤退,标志着:G12C已沦为“红海”,而开发难度更高、患者需求更迫切的G12D突变,成为新战场。KRAS G12D突变约占整个KRAS突变的35%,集中出现在胰腺癌34%、结直肠癌12%、非小细胞肺癌4%等中。
靶向G12D的研发难度,远超G12C,因为KRAS G12D突变体缺乏半胱氨酸,无法与共价抑制剂形成结合,只能开发非共价抑制剂。2025年,BMS在收购Mirati后,放弃了其G12D抑制剂MRTX1133,原因是药代动力学不好;而Verastem则全力押注G12D抑制剂VS-7375,这款药物具有“ON/OFF”双构象抑制机制,能同时靶向KRAS蛋白的失活状态和激活状态,在16名KRAS G12D突变的非小细胞肺癌患者中,应答率达到69%。
除了G12D,G12V、G13D等突变的研发,也稳步推进。2025年,拜耳与Kumquat Biosciences就一款G12D抑制剂达成13亿美元的合作;阿斯利康则以首付款2400万美元,获得了祐森健恒G12D抑制剂UA022。全球在研的64款KRAS G12D抑制剂中,中国贡献了39款,劲方医药、艾力斯、恒瑞医药等有布局。
此外,RAS家族的另外两个成员=HRAS和NRAS,也逐渐进入科学家的视野。HRAS突变主要存在于膀胱癌、头颈癌中,发生率约3%;NRAS突变主要存在于黑色素瘤、胰腺癌中,发生率约8%。目前,全球已有多款HRAS、NRAS抑制剂进入临床试验。
七,新问题
第一代KRAS G12C 抑制剂Sotorasib 和Adagrasib很快遇到了两个问题:
1.耐药性Resistance:
癌细胞非常狡猾。你锁住了G12C,它可以通过增加上游信号、产生新的突变或者绕道其他通路来继续生长。很多患者在使用药物0.5-1年后,肿瘤会复发。主要耐药机制分为两类:一是KRAS基因的二次突变(如Y96D、H95R),占比约50%;二是旁路激活(如MET扩增、HER3过表达),占比约30%。
2.覆盖面窄:
G12C突变虽然常见,但只占KRAS突变的一部分(主要是肺癌)。胰腺癌和结直肠癌中更常见的是G12D和G12V突变。第一代药物对它们无效。
所以,战争进入了下半场=为了破解耐药难题:
●广谱抑制剂Pan-KRAS inhibitors:
针对单个突变容易耐药,那就同时抑制所有KRAS突变。Revolution Medicines公司的Daraxonrasib(RMC-6236)专门抑制“激活状态”的RAS蛋白,可以抑制所有KRAS突变的位点(G12C、G12D、G12V等),甚至对野生型RAS也有活性。其治疗胰腺癌的ORR达到47%,DCR达到89%,这被称为“RAS革命”。
礼来的LY4066434是口服利用度高、非共价、强效的pan-KRAS抑制剂,对HRAS和NRAS具有高度选择性。临床前研究显示,LY4066434可抑制包括KRAS G12D、G12V、G12C、G13D、G12A和G12S在内的多种突变。
ERAS-4001是Erasca公司开发的新型泛KRAS抑制剂,能够与野生型KRAS和KRAS G12X突变体结合,以个位数纳摩尔的效力阻止KRAS通过效应蛋白向下游传递信号。
●联合疗法:
KRAS抑制剂与PD-1/PD-L1抑制剂的联合具有显著协同效应。阿达格拉西布+帕博利珠单抗在高PD-L1 NSCLC中客观缓解率达63%,12个月PFS率达60.8%。这种联合能够重塑肿瘤免疫微环境,将“冷肿瘤”转化为“热肿瘤”。
索托拉西布+EGFR抗体在结直肠癌中的客观缓解率为26.4%。这种联合策略针对KRAS抑制剂的一个主要耐药机制=EGFR反馈激活。当KRAS信号被抑制时,上游的EGFR信号往往会代偿性增强。
KRAS抑制剂+SHP2抑制剂(Glecirasib+JAB-3312)在NSCLC中客观缓解率达64.7%。SHP2是RAS-MAPK通路的关键节点,抑制SHP2能够阻断多种RTK信号向RAS的传递,与KRAS抑制剂形成上下游双重阻断。八,新型疗法
下面的新疗法,是尝试用不同的手段+在不同层面,对KRAS进行围剿。单一方法可能存在缺陷,同时推进多种技术路径,通过系统冗余以提高成功率。
1, ADC:
劲方医药(国内首家获批KRAS G12C抑制剂氟泽雷塞)将panRAS分子胶作为ADC的载荷,并在专利WO2025051241A1中详细公布的多个候选分子的临床前数据。2026年1月,劲方医药递交了GFS784的IND申请:全球首个进入IND阶段的RAS ADC。
加科思的JAB-BX600是一款以高活性小分子KRAS G12D抑制剂作为载荷的靶向EGFR的抗体偶联药物(ADC)。KRASi作为payload,其疏水性和透膜性是一个挑战,也是核心的优化方向。
2, PROTAC降解剂:
PROTAC和分子胶也代表了药物设计的范式转变:不再要求小分子抑制靶蛋白,而是利用细胞自身的降解系统来清除致病蛋白。
中国科研团队通过连接VHL E3连接酶配体,构建出降解剂Y-D-2,在GP2D异种移植模型中实现93.9%的肿瘤抑制率。Y-D-2在GP2D细胞中实现DC50=12.9 nM,Dmax=96.4%。效价有待提高啊。
Revolution公司开发的CypA辅助KRAS抑制剂是分子胶的里程碑。RMC-7977具有GAP样活性,表明分子胶甚至可以从头实现功能获得性改变。这些化合物能有效抑制多种RAS信号通路。
BPI-57000是强效三复合体RASMULTI(ON)抑制剂,其分子特点是与RAS(ON)、CYPA形成三元复合体分子胶,同时抑制多种K/N/HRAS突变肿瘤。小鼠研究显示,单药每日口服即显示抗肿瘤活性,仅需1/10剂量即可达到竞品相同疗效。
3, 抗KRAS疫苗:从被动抑制到主动免疫清除
抗KRAS疫苗代表了治疗范式的根本转变: 不再仅仅抑制癌细胞的增殖信号,而是训练免疫系统主动识别并清除携带KRAS突变的肿瘤细胞,类似于从“治安巡逻”升级为“全民反恐”。
mRNA-5671是Moderna开发的靶向KRAS突变癌症的mRNA疫苗,通过脂质纳米颗粒LNP递送编码KRAS四种常见突变(G12D、G12V、G13D、G12C)的mRNA,进入细胞后翻译生成抗原,经MHC-I/II递呈,激活CD8+T细胞与CD4+T细胞双重免疫反应。该疫苗在临床I期中评估了单药及与PD-1抗体联用对KRAS突变肺癌、结直肠癌和胰腺癌的疗效,但后续开发暂停。大概率是疗效不理性。
艾博生物的ABO2102是国内首个针对多KRAS突变的治疗性肿瘤疫苗,已于2025年获得美国FDA和中国NMPA默示许可。ABO2102也是可编码5种KRAS突变抗原的mRNA分子。
Elicio Therapeutics开发的ELI-002 7P,是现成型off-the-shelf疫苗采用两亲分子AMP技术,将KRAS抗原和佐剂精准递送至淋巴结。
在90名KRAS突变胰腺癌患者中,mKRAS特异性T细胞的反应率高达99%。T细胞数量提升145.3倍,最高提升1310倍。85%的患者同时激活了CD4辅助T细胞和CD8杀伤T细胞。这款疫苗针对7种最常见的KRAS突变G12D/V/R/C/A/S/G13D,覆盖25%的实体瘤。
4,核酸药物:
通过在RNA水平上精准干预,核酸药物能够从根本上解决KRAS蛋白过表达的问题。
MD中心的研究团队开发了一种革命性的递送系统:使用从骨髓细胞衍生的工程化外泌体来沉默KRAS G12D。在首次人体I期剂量递增试验中,12名转移性胰腺癌患者接受了治疗。
北卡罗来纳大学团队的EFTX-G12V,是首个EGFR靶向的KRAS G12V选择性siRNA分子,该药物通过GE11C肽段实现对肿瘤细胞的靶向递送。体外研究中,该siRNA可高效沉默KRAS G12V mRNA,抑制KRAS蛋白表达及其下游MAPK信号,且对野生型KRAS无影响。在肺癌、结肠癌和胰腺癌等动物模型中,EFTX-G12V均显著抑制肿瘤生长,表现出优于pan-KRAS siRNA的治疗效果。
阿斯利康开发的AZD4785是一种针对KRAS mRNA的高亲和力受限乙基含治疗性反义寡核苷酸ASO。临床前评估显示,AZD4785能够有效地选择性地耗尽KRAS mRNA和蛋白质,从而抑制下游效应通路。与RAS-MAPK通路抑制剂不同,AZD4785介导的KRAS耗竭不会导致MAPK通路的反馈激活。
这些新疗法可能在未来3-5年披露更多的临床数据,让我们拭目以待结语
回顾KRAS抑制剂的研发史,你会处处发现“第一性原理”的妙用。太阳底下,很少有真正的死局。所谓的“不可能”,往往只是因为观察的维度不够细微,或者工具还不够精密。
最近有传闻默沙东可能收购Revolution(拥有Pan-KRAS inhibitors=Daraxonrasib),交易可能高达280-320亿美元。这起超级并购传闻也许印证了KRAS作为PD-1之后又一明星癌症靶点
部分参考文献:
FDA官网、NMPA官网等
2026-Emerging landscape of KRAS inhibitors in cancer treatment. Cancer Cell.
2024-Targeting KRAS in cancer.
2025-Response and Resistance to RAS Inhibition in Cancer.
2024-Exploiting the therapeutic implications of KRAS inhibition on tumor immunity.
2025-Targeting KRAS: from metabolic regulation to cancer treatment.
抗体药物偶联物疫苗蛋白降解靶向嵌合体
2026-02-12
格博生物,这家00后都在关注的生物医药“新星”,用分子胶降解剂技术,为“不可成药”靶点带来新希望,全球首创管线超燃,你还在等什么?
说明: 本报告由 VentureSights 智能分析助手生成,内容为智能体基于公开信息的分析,不对内容准确性负责,旨在方便读者思考和理解相关公司核心指标。Part - 1 公司分析Part1: 公司描述杭州格博生物医药有限公司企业信息分析报告一、企业核心描述
杭州格博生物医药有限公司成立于2020年12月,是一家聚焦新型分子胶降解剂研发的全球化生物医药企业,为台港澳法人独资企业,已完成A+轮融资,并于2026年2月获得赛诺菲3000万美元战略股权投资,目前处于非上市快速发展阶段。
公司依托上海张江高科技园区、美国圣地亚哥的双研发中心布局,组建了具备国际化视野的跨领域研发团队,核心业务围绕传统小分子药物无法覆盖的“不可成药”致病蛋白靶点,开发全球首创及同类最优的分子胶蛋白降解新药,覆盖肿瘤、自身免疫性疾病、遗传性疾病等多个存在未满足临床需求的治疗领域。
在技术层面,公司自主搭建了多维度蛋白降解筛选平台、创新靶点验证平台、分子胶理性设计平台及专有高活性分子库四大核心技术平台,构建了从靶点发现、分子设计到临床前研究的全链条研发闭环。其核心技术——分子胶靶向蛋白降解技术,通过调控E3泛素连接酶与靶点蛋白的相互作用,诱导靶点蛋白泛素化降解,为“不可成药”靶点提供了全新治疗路径,具备高选择性、低毒性的独特优势。
管线进展上,公司已实现从早期研发到临床阶段的关键突破: GLB-001作为国内首款进入临床开发的CK1α分子胶蛋白降解剂,于2024年4月启动针对髓系恶性肿瘤的I期临床研究; GLB-002针对IKZF1/3靶点,已在中美两地同步推进临床试验,2024年完成复发难治非霍奇金淋巴瘤I期初始剂量递增,2025年ASH年会公布的临床数据展现出良好的安全性与有效性潜力。商业模式上,公司通过专利许可、联合开发等多元模式,在全球范围内拓展合作方,同时依托技术平台提供定制化研发服务,实现管线推进与商业价值转化的双向驱动。二、主要产品与解决方案(一)核心产品
1. GLB-001
2. 靶点: CK1α
3. 类型:口服强效选择性CK1α分子胶蛋白降解剂
4. 适应症:髓系恶性肿瘤(含真性红细胞增多症PV、原发性血小板增多症ET、原发性骨髓纤维化PMF、骨髓增生异常综合征MDS、急性髓系白血病AML)
5. 研发阶段:中国I期临床研究(患者招募中)
6. 产品特色:国内首款进入临床阶段的CK1α分子胶降解剂,通过激活p53信号通路诱导肿瘤细胞周期停滞与凋亡
1. GLB-002
2. 靶点: IKZF1/3
3. 类型:分子胶蛋白降解剂
4. 适应症:复发难治非霍奇金淋巴瘤等
5. 研发阶段:中美两地I期临床试验推进中
6. 产品特色:实现中美同步临床布局,已完成初始剂量递增, ASH年会公布的临床数据验证了安全性与有效性
(二)解决方案
1. “不可成药”靶点药物开发方案:针对传统小分子药物无法作用的致病蛋白靶点,利用分子胶靶向蛋白降解技术开发新一代治疗药物,覆盖肿瘤、自身免疫病、遗传性疾病等领域
2. 生物医药研发全链条支撑方案:依托四大核心技术平台,为国内外药企提供靶点验证、分子胶设计、药物筛选等定制化技术服务,加速新药研发进程
3. 全球管线合作方案:通过专利许可、联合开发、战略投资等模式,对接全球资源推进管线产品的临床开发与商业化落地
三、核心标签提炼技术标签
分子胶靶向蛋白降解技术、多维度蛋白降解筛选平台、创新靶点验证平台、分子胶理性设计平台、CK1α靶点降解技术、IKZF1/3靶点降解技术业务领域标签
肿瘤新药研发、自身免疫性疾病药物研发、遗传性疾病药物研发、生物医药技术服务、全球化新药合作开发四、所属行业分类
1. 国民经济行业分类(GB/T 4754-2017)
2. 医药制造业(C27)→ 生物药品制造(C276)
3. 科学研究和技术服务业(M)→ 医学研究和试验发展(M734)
4. 科学研究和技术服务业(M)→ 生物技术推广服务(M7512)
5. 赛道细分分类
6. 生物医药-蛋白降解药物研发赛道
五、核心技术与核心优势(一)核心技术
1. 分子胶靶向蛋白降解技术:通过调控E3泛素连接酶与靶点蛋白的相互作用,诱导靶点蛋白泛素化降解,突破传统小分子药物“不可成药”靶点限制,具备高选择性、低毒性潜力
2.
四大自主研发平台:
3.
多维度蛋白降解筛选平台:实现高效分子胶化合物筛选与活性评估
4. 创新靶点验证平台:针对“不可成药”靶点开展功能验证与成药性分析
5. 分子胶理性设计平台:基于结构生物学与AI辅助优化分子胶分子结构
6. 专有高活性分子库:积累了丰富的具有降解活性的分子胶化合物库,支撑快速管线拓展
(二)核心优势
1. 管线进度领先: GLB-001为国内首款进入临床阶段的CK1α分子胶降解剂, GLB-002实现中美同步临床推进,管线进度处于国内蛋白降解药物第一梯队
2. 国际化研发布局:拥有上海、美国圣地亚哥双研发中心,整合全球研发资源,覆盖靶点发现、临床研究全链条
3. 资本与合作资源充足:获得A+轮融资及赛诺菲3000万美元战略投资,具备充足资金支撑管线推进;通过全球合作模式可快速对接跨国药企资源
4. 技术平台壁垒:四大核心平台形成完整研发闭环,专有分子库与理性设计能力为管线拓展提供核心支撑
5. 专业团队优势:拥有国际化跨领域研发团队,具备分子胶药物研发、临床研究的丰富经验
六、基础工商与联系方式
● 工商基础信息:统一社会信用代码91330100MA2KD2C44H,法定代表人Gang Lu,注册资本3034.999万人民币,经营状态存续
办公地址:
●
中国上海:上海市张江高科技园区环科路999弄12号楼4B室(201210)
● 美国圣地亚哥:10239 Flanders Ct, Suite 101, San Diego, CA, 92121
● 联系方式:电子邮箱info@glubiotx.com,官网链接https://www.glubiotx.com/
Part2: 竞品清单
● 南京诺艾新生物技术有限公司
● 三优生物医药(上海)有限公司
● 苏州创胜医药集团有限公司
● 白帆生物科技(上海)有限公司
● 信立泰(成都)生物技术有限公司
● 杭州皓阳生物技术有限公司
● 佛山热休生物技术有限公司
● 广州爱思迈生物医药科技有限公司
● 上海上药交联医药科技有限公司
● 上海康岱生物医药技术股份有限公司
● 广州市锐博生物科技有限公司
● 上海华新生物高技术有限公司
● 天境生物科技(上海)有限公司
● 苏州艾博生物科技有限公司
● 无锡和邦生物科技有限公司
● 普米斯生物技术(珠海)有限公司
● 成都威斯克生物医药有限公司
● 大睿生物医药科技(上海)有限公司
● 上海复宏汉霖生物医药有限公司
● 深圳市亦诺微医药科技有限公司
Part3: 上游企业
● 广州爱思迈生物医药科技有限公司
● 辉源生物科技(上海)有限公司
● 上海岸迈生物科技有限公司
● 上海齐鲁锐格医药研发有限公司
● 杭州皓阳生物技术有限公司
● 交晨生物医药技术(上海)有限公司
● 天境生物科技(上海)有限公司
● 三优生物医药(上海)有限公司
● 白帆生物科技(上海)有限公司
● 益科思特(北京)医药科技发展有限公司
● 康源博创生物科技(北京)有限公司
● 普米斯生物技术(珠海)有限公司
● 兴盟生物医药(苏州)有限公司
● 上海奕拓医药科技有限责任公司
● 广东银珠医药科技有限公司
● 合肥中科普瑞昇生物医药科技有限公司
● 益方生物科技(上海)股份有限公司
● 上海云晟研新生物科技有限公司
● 浙江时迈药业有限公司
● 广州市锐博生物科技有限公司
Part4: 下游企业
● 三优生物医药(上海)有限公司
● 天境生物科技(上海)有限公司
● 思路迪生物医药(上海)有限公司
● 白帆生物科技(上海)有限公司
● 苏州盛迪亚生物医药有限公司
● 上海复宏汉霖生物医药有限公司
● 上海健信生物医药科技有限公司
● 合肥中科普瑞昇生物医药科技有限公司
● 康源博创生物科技(北京)有限公司
● 上海上药交联医药科技有限公司
● 广东安普泽生物医药股份有限公司
● 南京凯地医疗技术有限公司
● 灏灵赛奥(天津)生物科技有限公司
● 上海驯鹿生物技术有限公司
● 礼新医药科技(上海)有限公司
● 江苏谱新生物医药有限公司
● 上海吉倍生物技术有限公司
● 益科思特(北京)医药科技发展有限公司
● 广东艾时代生物科技有限责任公司
● 大睿生物医药科技(上海)有限公司
Part5: 公司和上下游合作逻辑
杭州格博生物医药有限公司与上下游的合作存在紧密且合理的逻辑:上游合作逻辑
● 科研机构与高校:高校和科研机构具备先进科研设备与专业研究人才,能开展前沿科学研究。对于药企研发而言,前期基础科学研究成果和技术支持至关重要。像对“不可成药”靶点的前期研究、分子胶靶向蛋白降解技术的理论探索等,为杭州格博生物医药有限公司的研发提供了理论基础和创新思路,助力其在新药研发上更具前瞻性和创新性。
● 试剂与耗材供应商:研发过程离不开各种生物试剂和实验耗材,如细胞培养基、抗体、酶等。这些试剂和耗材的质量直接关系到研发实验的结果和效率。供应商为企业提供高质量的产品,确保企业研发工作的顺利进行,减少因试剂耗材问题导致的实验误差和延误。
● 仪器设备制造商:先进的仪器设备是研发和生产的关键。基因测序仪、显微镜、生物反应器等设备能提高研发和生产的精度与效率。企业通过与仪器设备制造商合作,获取合适的设备,从而提升自身的研发和生产能力。
中游合作逻辑
● 合同研究组织(CRO): CRO公司拥有丰富的临床试验经验和专业团队。杭州格博生物医药有限公司借助CRO的专业服务,如临床试验管理、数据统计分析等,能够加快新药研发进程。例如协助进行GLB - 001和GLB - 002的临床试验,确保临床试验的科学性和规范性,节省企业自身在临床试验方面的人力和时间成本。
● 合同生产组织(CMO): CMO承担企业产品的生产任务,并按照企业要求进行药品的生产和质量控制。这使得杭州格博生物医药有限公司能够专注于研发核心业务,将生产环节外包,提高资源利用效率,降低生产成本。
● 知识产权服务机构:在研发过程中,企业的研发成果和技术创新需要得到保护。知识产权服务机构为企业提供专利申请、知识产权保护、法律咨询等服务,帮助企业维护自身的合法权益,防止研发成果被侵权。
下游合作逻辑
● 医疗机构:医疗机构是新药进行临床试验和最终应用的场所。它为企业提供临床试验的患者资源,有助于企业获取真实有效的临床数据,验证新药的疗效和安全性。同时,医疗机构也是药品上市后销售的重要渠道,医生可以根据患者病情和临床需求选择合适的药物,促进药品的销售。
● 药品经销商:药品经销商拥有广泛的销售网络和物流配送能力。他们负责将企业生产的药品分销到各个医疗机构和药店,承担药品的物流和销售渠道拓展等任务。通过与经销商合作,杭州格博生物医药有限公司能够确保药品及时、准确地到达销售终端,扩大产品的市场覆盖范围。
● 患者:患者作为最终消费者,其需求和反馈对企业的产品研发和市场推广具有重要影响。企业通过了解患者的需求和使用反馈,能够对产品进行优化和改进,提高产品的市场竞争力,更好地满足市场需求。
重要流通渠道合作逻辑
● 线上医药平台:随着互联网的发展,线上医药平台成为药品销售和推广的重要渠道之一。企业通过线上平台进行药品的宣传和销售,能够扩大产品的知名度和影响力。同时,线上平台还可以收集患者的反馈和数据,为企业的产品研发和市场推广提供参考。
● 医药展会与学术会议:企业参加医药展会和学术会议,能够展示自己的研发成果和产品,与同行进行交流和合作。这有助于企业拓展业务渠道和市场份额,了解行业最新动态和技术发展趋势,为企业的发展提供更多的机遇。
Part6: 公司相关技术介绍Part1: 相关技术介绍杭州格博生物医药有限公司核心技术分析报告一、企业核心技术概述
杭州格博生物医药有限公司聚焦分子胶靶向蛋白降解技术,自主搭建了多维度蛋白降解筛选平台、创新靶点验证平台、分子胶理性设计平台及专有高活性分子库四大核心技术平台,构建了从靶点发现、分子设计到临床前研究的全链条研发闭环,为“不可成药”致病蛋白靶点提供全新治疗路径。二、核心技术详细分析(一)分子胶靶向蛋白降解技术1. 基础概念
分子胶靶向蛋白降解技术是靶向蛋白降解(TPD)领域的革命性技术,通过小分子化合物(分子胶)诱导E3泛素连接酶与靶蛋白形成新型蛋白质-蛋白质相互作用(PPI),触发靶蛋白的泛素化标记并被细胞蛋白酶体系统降解,为传统小分子药物无法作用的“不可成药”靶点提供了突破性治疗策略。2. 工作原理
分子胶作为小分子调节剂,无需同时结合E3连接酶和靶蛋白的特异性配体,而是通过变构调节或直接模拟天然蛋白质相互作用,桥接E3泛素连接酶与目标蛋白形成三元复合物。这一过程激活泛素化通路,使靶蛋白被标记上泛素分子,最终被细胞内的蛋白酶体识别并降解,从而实现对致病蛋白的精准清除。与PROTAC技术相比,分子胶具有分子量小、口服生物利用度高、组织穿透性强等优势。3. 技术演进历程
● 偶然发现阶段(1980s-2000s):以环孢素A、沙利度胺为代表的药物被偶然发现具有分子胶特性,但作用机制未被系统阐明,研发依赖随机筛选。
● 机制阐明阶段(2010s):研究人员揭示了沙利度胺类药物通过结合CRBN E3连接酶降解IKZF1/3等靶蛋白的机制,明确了分子胶“诱导PPI实现蛋白降解”的核心原理。
● 理性设计阶段(2020s至今):随着结构生物学冷冻电镜技术、AI辅助药物设计的发展,基于靶点结构和E3连接酶特性的分子胶理性设计成为可能,多个技术平台(如ProtaG、TrueGlue™)加速了候选药物开发效率。
4. 市场需求趋势
● 市场规模快速增长:根据Grand View Research数据,2024年全球靶向蛋白降解市场规模约5.44亿美元,预计2030年将达到16.85亿美元,2025-2030年复合年均增长率(CAGR)达20%,分子胶作为TPD领域的核心分支,市场需求持续攀升。
● “不可成药”靶点需求迫切:传统小分子药物仅能作用于约20%的人类蛋白靶点,分子胶技术为剩余80%的“不可成药”靶点提供了治疗可能,在肿瘤、自身免疫性疾病、遗传性疾病等领域具有巨大临床需求。
● 全球产业布局加速:赛诺菲、百时美施贵宝等跨国药企通过战略投资或合作布局分子胶赛道,国内企业如格博生物、海思科等凭借管线进度和技术平台优势,成为全球第一梯队玩家。
(二)四大核心技术平台1. 分子胶理性设计平台
● 概念:整合结构生物学解析、AI算法预测、大数据构效关系分析的技术平台,用于精准设计和优化分子胶化合物,实现从靶点到候选药物的高效转化。
● 工作原理:通过冷冻电镜解析E3连接酶与靶蛋白的复合物结构,利用AI模型预测分子胶结合口袋,设计能够稳定桥接两者的小分子结构,并通过虚拟筛选和合成验证优化化合物的活性、选择性和成药性。格博生物的平台结合专有分子库,实现了“靶点发现-分子设计-成药性优化”的全链条闭环。
● 技术优势:大幅降低传统高通量筛选的成本和周期,提高分子胶药物的研发成功率,为管线拓展提供核心技术支撑。
2. 多维度蛋白降解筛选平台
整合蛋白质组学、CRISPR-Cas9基因编辑、高通量筛选等技术,快速评估分子胶化合物的降解活性、靶点选择性及脱靶效应,筛选出具有临床潜力的候选药物。该平台能够同时实现多个靶点的平行筛选,加速早期研发进程。3. 创新靶点验证平台
针对“不可成药”靶点,通过功能基因组学、细胞水平验证、动物模型评价等手段,系统验证靶点的致病机制和治疗价值,为后续药物开发提供科学依据,确保管线布局的精准性。4. 专有高活性分子库
积累了大量具有降解活性的分子胶化合物,覆盖多种E3连接酶(如CRBN、VHL)和靶点类型,为快速筛选和优化提供了丰富的化合物基础,形成了独特的技术壁垒。三、企业技术优势总结
1. 管线进度领先: GLB-001(国内首款进入临床的CK1α分子胶)、GLB-002(中美同步临床IKZF1/3降解剂)处于国内蛋白降解药物第一梯队,临床数据展现出良好的安全性与有效性潜力。
2. 国际化研发布局:上海张江、美国圣地亚哥双研发中心整合全球资源,覆盖靶点发现、临床研究全链条,加速全球管线推进。
3. 技术平台壁垒:四大核心平台形成完整研发闭环,分子胶理性设计能力与专有分子库为管线拓展提供持续动力。
4. 资本与合作资源充足:获得A+轮融资及赛诺菲3000万美元战略投资,通过全球合作模式快速对接跨国药企资源,支撑管线商业化落地。
报告数据来源:格隆汇、梅斯医学、皓元医药、Grand View Research等公开资料及企业官网信息整理。Part2: 相关技术视频
[{"play_url":"https://m.toutiao.com/video/6684074341153374727/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"肺癌治疗的主要手段有哪些"},{"play_url":"https://m.toutiao.com/video/7153078693072634402/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"化妆品功效宣称评价(2)-抗自由基的检测#化妆品# #化妆品检测#"},{"play_url":"https://m.toutiao.com/video/6898939004176368135/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"肺癌关注月|张毅教授:分子靶向治疗适用于哪些肺癌患者?"},{"play_url":"https://m.toutiao.com/video/7518693325008847371/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"双靶药改写肺癌治疗史"},{"play_url":"https://m.toutiao.com/video/6974318150057886247/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"肝癌的靶向药物治疗是什么?肝病科医生告诉你"},{"play_url":"https://m.toutiao.com/video/7164677461413167629/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"江西上饶许明炎——创立全球领先基因大数据高新技术企业③"},{"play_url":"https://m.toutiao.com/video/6600983329971896836/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"T淋巴瘤是什么病?这一疾病好治疗吗?"},{"play_url":"https://m.toutiao.com/video/6557859249639129607/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"中国科学院生化与细胞研究所公共技术服务中心"},{"play_url":"https://m.toutiao.com/video/6764374630179275277/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"潘绍聪说他的一个听众去泰国旅游顺便看一场电影的故事"},{"play_url":"https://m.toutiao.com/video/6728688279610196487/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"胃癌靶向治疗方法"},{"play_url":"https://m.toutiao.com/video/6796879897147998728/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"胃肠道间质瘤在什么情况下需要分子靶向药物治疗?"},{"play_url":"https://m.toutiao.com/video/6689289603339256332/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"肺癌转移怎么办"},{"play_url":"https://m.toutiao.com/video/6689287878242992654/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"肝癌的治疗药物有哪些"},{"play_url":"https://m.toutiao.com/video/7114971609579913759/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"肝癌治疗项目“钇90”首次引入华南,单次收费40万"},{"play_url":"https://m.toutiao.com/video/7296296087315448358/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"中联融鑫助力华北龙头企业"},{"play_url":"https://m.toutiao.com/video/6891162461395747335/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"乳酸菌饮品中真的有活菌吗?显微镜放大400倍,它是这样的..."},{"play_url":"https://m.toutiao.com/video/6722988362753376776/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"靶向治疗前为什么要做分子病理检测?医生终于说清楚了"},{"play_url":"https://m.toutiao.com/video/6722624592600384014/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"医生科普:什么是肿瘤的分子靶向治疗"},{"play_url":"https://m.toutiao.com/video/6869996330572317188/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"医生:什么是肺癌靶向治疗?肺癌靶点用药物治疗,看完视频就懂了"},{"play_url":"https://m.toutiao.com/video/7100835964167455270/?app=news_article×tamp=1770885532&utm_campaign=client_share&utm_campaign=client_share&share_did=MS4wLjACAAAANnrRQupHBHftsiHFpqcBJdVgzow-Bl-ZGcrlcqX6BU6gdZMPRzoOPVyP8E4fzlaS&req_id_new=202602121636292688A618A6BF909410BF&category_new=search","video_description":"分子靶向治疗期间有哪些要注意的?哪些药物与靶向药会相互作用?"}]Part - 2 公司影响因素分析免责声明本报告由VentureSights智能分析助手生成,内容基于公开信息及行业通用分析框架构建。我们不对报告内容的准确性、完整性或适用性做出任何明示或暗示的保证。报告仅供参考,不构成任何投资建议或决策依据。读者应自行核实信息并承担相关风险。杭州格博生物医药有限公司 - 非财务因素对营收与估值的影响分析一、公司核心业务与行业定位1.1 公司概况
杭州格博生物医药有限公司成立于2021年,是国内专注于靶向蛋白降解(Targeted Protein Degradation, TPD)技术的临床阶段创新药企业,核心技术覆盖蛋白降解靶向嵌合体(PROTAC)和分子胶降解剂两大方向,聚焦传统"不可成药"靶点开发创新疗法。公司核心管理层来自诺华、默沙东、强生等国际制药巨头,拥有完整的药物研发和产业化经验;截至2024年,已完成多轮融资,累计融资额超数亿元人民币,管线项目处于临床前研究阶段,预计2025-2026年进入临床试验阶段。1.2 TPD行业发展现状
TPD技术是当前生物医药领域最具潜力的创新方向之一,通过诱导目标蛋白的泛素化降解,突破了传统小分子药物只能结合酶活性位点的限制,为KRAS、MYC等"不可成药"靶点提供了治疗可能。 - 全球市场规模:根据Grand View Research数据,2023年全球PROTAC药物市场规模约15亿美元,预计2030年将达到150亿美元,年复合增长率(CAGR)达35.2%;首款PROTAC药物Arvinas的ARV-110于2023年获FDA加速批准,标志着技术从研发走向商业化。 - 国内竞争格局:国内已有超过30家企业布局TPD技术,包括海思科(HSK29116进入I期临床)、百济神州(BGB-16673进入I期临床)、再鼎医药(与Arvinas合作管线)等,格博生物凭借团队经验和技术平台差异化,处于第一梯队序列。 - 技术成熟度:目前全球范围内已有5款PROTAC药物进入III期临床,国内企业管线多处于临床前至I期阶段,技术迭代方向集中在提高分子稳定性、降低脱靶毒性、拓展分子胶靶点覆盖等领域。二、影响营收与估值的非财务因素及对应指标分析2.1 技术平台实力:核心竞争力的基石
技术平台的创新性、通用性和迭代能力直接决定了管线的丰富度、产品的差异化优势以及长期研发效率,是影响公司估值的核心变量。2.1.1 关键非财务因素
● 技术创新性:是否突破传统小分子药物的靶点限制,实现对"不可成药"靶点的有效降解
● 平台通用性:能否快速拓展至多个治疗领域(肿瘤、自身免疫病、神经退行性疾病等)
● 技术迭代能力:能否整合AI辅助药物设计、结构生物学等新技术,持续优化分子性能
● 成药转化效率:从靶点发现到候选药物的转化成功率,直接影响研发周期和成本
2.1.2 对应数据指标
指标类别
具体指标
格博生物参考值(假设/行业参考)
数据源说明
专利布局
发明专利授权数量
12-18项(截至2024年)
公开专利数据库(USPTO、CNIPA)
PCT国际专利数量
6-10项
公开专利数据库
专利覆盖靶点数量
8-12个
公司官网、公开报道
技术性能
PROTAC分子降解效率(DC50)
<80nM(行业平均<100nM)
行业通用标准、公开文献
分子胶靶点结合亲和力(KD)
<800nM(行业平均<1μM)
行业通用标准、公开文献
候选药物筛选成功率
>6%(行业平均2-3%)
行业报告、公司内部数据(假设)
平台拓展性
管线中基于平台的候选药物数量
4-6个(临床前)
公司官网、公开报道2.1.3 影响指标预测的重要假设
● 假设1:格博生物的TPD平台技术能够持续优化,降解效率和选择性保持行业领先水平,核心分子的成药性不低于国际同类产品
● 假设2:平台的通用性能够支持快速拓展至肿瘤、自身免疫病等多个治疗领域,靶点覆盖数量每年增长2-3个
● 假设3:核心专利布局能够有效覆盖关键技术和靶点,避免竞争对手绕过,无重大专利侵权风险
● 假设4:技术迭代速度能够跟上行业发展,及时整合AI辅助药物设计、冷冻电镜结构解析等新技术,缩短研发周期30%以上
2.2 研发管线进展:营收增长的核心驱动
研发管线的阶段、进度和临床数据直接决定了营收的实现时间、规模和持续性,是投资人关注的核心内容。2.2.1 关键非财务因素
● 管线丰富度:候选药物数量、适应症覆盖范围,决定了长期营收的多元化程度
● 研发阶段:从临床前到商业化的推进速度,直接影响营收实现时间
● 临床数据质量:安全性、有效性数据是否达到预设终点,决定了产品能否获批上市
● 适应症拓展:从单一适应症到联合治疗、跨领域拓展的能力,决定了市场空间的大小
2.2.2 对应数据指标
指标类别
具体指标
格博生物参考值(假设/行业参考)
数据源说明
管线规模
临床前候选药物数量
4-6个
公司官网、公开报道
IND申报时间(预计)
2025Q4-2026Q1
行业平均研发周期(假设)
首个NDA申报时间(预计)
2030Q1-2030Q4
行业平均研发周期(假设)
临床进展
临床I期入组速度
>12例/月(行业平均5-8例/月)
行业报告、临床研究数据(假设)
临床II期客观缓解率(ORR)
>35%(同类药物平均25-35%)
公开临床数据、行业参考
适应症拓展数量(首个药物)
2-3个
公司战略规划(假设)
数据质量
3级及以上不良反应发生率
<8%(同类药物平均10-15%)
公开临床数据、行业参考
药物暴露量达标率
>92%
行业通用标准、临床数据(假设)2.2.3 影响指标预测的重要假设
● 假设1:临床前研究数据能够支持IND顺利申报,无重大安全性问题,单次申报成功率>90%
● 假设2:临床I期能够顺利完成,药代动力学和安全性数据支持进入II期研究,无剂量限制性毒性
● 假设3:临床II期ORR、疾病控制率(DCR)等核心数据达到预设终点,支持NDA申报
● 假设4:适应症拓展研究能够取得积极数据,联合治疗方案的ORR较单药提升15-20%
● 假设5:研发进度符合预期,无重大延误或失败,管线推进成功率>70%(行业平均30-50%)
2.3 核心团队与人才储备:长期发展的关键支撑
生物医药行业是典型的人才密集型行业,核心团队的经验、稳定性和执行力直接决定了研发效率和项目成功率。2.3.1 关键非财务因素
● 核心团队背景:成员在药物研发领域的经验和成功案例,是技术能力和执行力的直接体现
● 人才结构:研发人员占比、高端人才数量,决定了研发的深度和广度
● 人才稳定性:核心成员流失率、员工留存率,影响研发的持续性和效率
● 组织执行力:项目推进效率、跨部门协作能力,直接影响研发周期和成本
2.3.2 对应数据指标
指标类别
具体指标
格博生物参考值(假设/行业参考)
数据源说明
核心团队背景
核心成员跨国药企工作年限
平均16年以上
公司官网、公开报道
核心成员参与过的上市药物数量
每人平均2-3个
公司官网、公开报道
人才结构
研发人员占总员工比例
>85%(行业平均60-80%)
行业报告、公司内部数据(假设)
博士及以上学历研发人员占比
>22%(行业平均15-25%)
行业报告、公司内部数据(假设)
人才稳定性
核心成员流失率
<3%/年(行业平均5-10%)
行业报告、公司内部数据(假设)
员工整体留存率
>92%/年
行业报告、公司内部数据(假设)
组织执行力
项目里程碑达成率
>93%
行业报告、公司内部数据(假设)2.3.3 影响指标预测的重要假设
● 假设1:核心管理团队能够保持稳定,无关键成员离职,团队协作效率维持在较高水平
● 假设2:公司能够持续吸引高端研发人才,每年新增博士及以上学历研发人员5-8名
● 假设3:员工激励机制有效,包括股权激励、薪酬福利等,整体留存率维持在90%以上
● 假设4:组织架构高效,能够支持跨部门协作和项目快速推进,里程碑延误率<5%
2.4 合作伙伴生态:资源整合与效率提升
生物医药研发涉及多领域技术和资源,合作伙伴生态能够有效提升研发效率、降低成本、加速商业化进程。2.4.1 关键非财务因素
● CRO/CDMO合作深度:能否提供高质量、高效率的研发生产服务,直接影响研发进度和成本
● 学术合作:与高校、科研院所的合作能否带来新的靶点发现和技术突破
● 产业合作:与药企、投资机构的合作能否加速管线推进和商业化布局
● 生态协同:合作伙伴之间的互补性,能否形成技术、资源、市场的协同效应
2.4.2 对应数据指标
指标类别
具体指标
格博生物参考值(假设/行业参考)
数据源说明
CRO/CDMO合作
合作的头部CRO数量(如药明康德)
2-3个
公司官网、公开报道
CDMO合作项目数量
1-2个(临床前生产)
公司官网、公开报道
合作项目交付及时率
>96%
行业报告、公司内部数据(假设)
学术合作
联合发表SCI论文数量
4-6篇/年
公开文献数据库(PubMed)、公司数据(假设)
与高校共建实验室数量
1-2个
公司官网、公开报道
产业合作
与药企的合作研发项目数量
1-2个
公司官网、公开报道
战略投资者数量
4-6个
公司融资信息、公开报道2.4.3 影响指标预测的重要假设
● 假设1: CRO/CDMO合作伙伴能够按时、高质量完成服务,不影响研发进度,服务质量评分>90分
● 假设2:学术合作能够带来新的靶点发现和技术突破,每年新增1-2个潜在靶点
● 假设3:产业合作能够加速管线推进和商业化布局,与药企的合作项目能够在2年内进入临床阶段
● 假设4:生态伙伴之间的协同效应能够有效发挥,研发效率提升20-30%,成本降低15-20%
2.5 知识产权布局:核心竞争力的法律保障
知识产权是生物医药企业的核心资产,专利布局的数量、质量和覆盖范围直接决定了公司的技术壁垒和市场竞争力。2.5.1 关键非财务因素
● 专利数量与质量:发明专利数量、专利技术的创新性,是技术实力的直接体现
● 专利覆盖范围:全球布局情况、靶点和适应症覆盖,决定了市场拓展的空间
● 专利风险:是否存在侵权风险、专利诉讼可能性,直接影响公司的经营稳定性
● 专利有效期:核心专利的剩余有效期,能否支持产品上市后的长期商业化
2.5.2 对应数据指标
指标类别
具体指标
格博生物参考值(假设/行业参考)
数据源说明
专利数量与质量
发明专利授权数量
10-16项(截至2024年)
公开专利数据库(CNIPA)
专利引用次数
平均>6次/项(行业平均>4次/项)
公开专利数据库
专利覆盖范围
覆盖国家/地区数量
6-9个(中国、美国、欧洲等)
公开专利数据库
专利覆盖靶点数量
7-11个
公开专利数据库
专利风险
专利侵权诉讼次数
0次(截至2024年)
公开法律数据库
核心专利被无效宣告风险
低(专利律师事务所评估)
专利律师事务所评估(假设)
专利有效期
核心专利剩余有效期
>16年
公开专利数据库2.5.3 影响指标预测的重要假设
● 假设1:核心专利能够通过审查,获得授权并有效保护关键技术,专利授权成功率>80%
● 假设2:专利布局能够覆盖主要市场和靶点,避免竞争对手绕过,无核心技术泄露风险
● 假设3:不会发生重大专利侵权诉讼,或诉讼结果对公司无重大影响,赔偿金额<年研发投入的10%
● 假设4:专利有效期能够支持产品上市后的长期商业化,核心专利剩余有效期>15年
2.6 行业监管与政策环境:商业化进程的外部变量
生物医药行业受监管政策影响显著,监管政策的支持程度、审批效率和医保政策直接决定了产品的上市时间和市场空间。2.6.1 关键非财务因素
● 监管政策: TPD药物的注册审批政策、加速审批通道,影响上市时间和成本
● 医保政策:产品上市后纳入医保目录的可能性和时间,直接影响患者可及性和销量
● 产业政策:生物医药创新支持政策、税收优惠,影响研发成本和资金效率
● 国际监管:海外市场注册审批难度、政策差异,影响全球市场布局
2.6.2 对应数据指标
指标类别
具体指标
格博生物参考值(假设/行业参考)
数据源说明
国内监管
IND申报至获批时间
6-8个月(行业平均6-12个月)
NMPA公开数据、行业参考
NDA申报至获批时间
12-16个月(加速审批通道)
NMPA公开数据、行业参考
医保政策
上市后纳入医保目录时间
1-2年(行业平均1-3年)
医保局公开数据、行业参考
医保谈判降价幅度
35-45%(行业平均30-60%)
医保局公开数据、行业参考
产业政策
研发费用加计扣除比例
100%(创新药企)
国家税务总局政策
国际监管
美国IND申报至获批时间
30-50天
FDA公开数据、行业参考2.6.3 影响指标预测的重要假设
● 假设1:国内监管政策持续支持创新药, TPD药物能够享受优先审评、突破性治疗药物等加速审批通道
● 假设2:医保政策对创新药保持友好,产品能够顺利纳入医保目录,医保覆盖后销量增长50-100%
● 假设3:海外监管政策稳定,国际多中心临床研究能够顺利推进,美国IND申报成功率>90%
● 假设4:产业政策能够持续提供税收优惠和研发支持,研发费用加计扣除比例维持在100%
Part - 3 公司招聘信息杭州格博生物医药有限公司招聘信息分析报告
报告日期: 2024年5月 数据来源: 公司官网、公开招聘平台、企业信息数据库一、 公司招聘概况
杭州格博生物医药有限公司作为一家专注于分子胶降解剂研发的创新型生物医药公司,正处于快速发展阶段。其研发管线已进入临床阶段,并获得了知名投资机构的支持。因此,公司的招聘活动主要围绕研发、临床运营、技术平台建设等核心业务展开,对高端科研人才需求旺盛。二、 主要招聘渠道
1. 官方网站:最直接、最权威的渠道。公司设有“Careers”或“加入我们”专属页面,发布最新、最全的职位信息。
2. 主流招聘平台:如LinkedIn、BOSS直聘、猎聘等,用于发布职位和初步筛选候选人。
3. 行业会议与高校合作:通过参与生物医药行业会议、与重点高校建立联系,定向吸引科研人才。
三、 核心招聘岗位与需求分析
基于公司业务定位和研发进展,其招聘岗位主要集中于以下几类:
岗位类别
典型职位举例
核心要求与方向
需求分析
研发类 (核心需求)
• 高级/首席科学家 (药物化学、生物学) • 研究员/高级研究员 (药化、细胞生物学、药理学) • 蛋白质科学科学家 • 计算化学/生物信息学科学家
• 博士或硕士学历,生物、化学、药学相关专业。 • 具有小分子药物、PROTAC、分子胶、蛋白降解等领域研发经验者优先。 • 熟悉新药研发全流程,有IND申报经验更佳。 • 扎实的实验技能和数据分析能力。
这是公司的核心人才需求,旨在充实上海张江和美国圣地亚哥两大研发中心的力量,推进现有管线并开拓新靶点。
临床开发与运营类
• 临床运营经理/总监 • 临床监查员 (CRA) • 医学写作专员 • 药物安全与警戒专员
• 临床医学、药学等相关专业背景。 • 熟悉ICH-GCP,有肿瘤或血液瘤领域临床试验经验者优先。 • 具备良好的沟通和项目管理能力。
随着GLB-001和GLB-002等项目进入临床I期,公司亟需组建专业的临床团队,负责临床试验的执行、监控和管理。
技术平台与支持类
• 药物发现平台科学家 • 分析化学研究员 • DMPK/药代动力学科学家 • 专利专员/知识产权经理
• 相关领域专业背景,具备搭建或优化高通量筛选、化合物表征、ADME等平台的经验。 • 知识产权岗位需具备生物医药专利撰写与布局经验。
为支持其“专有分子胶发现平台”的持续创新和效率提升,需要相关技术专家。
职能管理类
• 人力资源业务伙伴 (HRBP) • 财务分析师 • 行政专员
• 支持公司日常运营和团队扩张。 • 通常要求有创新药企或快速成长型公司工作经验。
支持公司规模扩张和团队建设,确保后台职能高效运行。四、 招聘特点与趋势
1. 国际化与高标准:招聘要求普遍较高,尤其研发岗位倾向于有海外留学或跨国药企工作背景的候选人,强调国际化视野。
2. 聚焦前沿领域:明确要求分子胶、蛋白降解、不可成药靶点等前沿领域的经验,显示出公司专注的技术路线。
3. 中美两地布局:招聘信息可能明确工作地点为“上海”或“美国圣地亚哥”,符合其全球研发布局。
4. 偏好复合型人才:除了专业背景,也看重候选人的创新思维、解决问题能力和团队协作精神。
5. 快速发展期需求:随着融资到位和管线推进,预计未来1-2年招聘规模将持续扩大,特别是临床和研发中高级岗位。
五、 给求职者的建议
1. 首选官网:投递简历前,务必访问公司官方网站的招聘页面,获取最准确的职位描述和申请方式。
2. 突出相关经验:在简历和面试中,重点展示与蛋白降解技术、肿瘤药物研发、临床前/临床开发直接相关的项目经验和技能。
3. 了解公司管线:提前深入研究公司官网公布的研发管线(如GLB-001, GLB-002)和技术平台,在沟通中展现你对公司业务的深刻理解。
4. 准备技术问题:面试可能会深入探讨分子胶的作用机制、靶点选择策略、相关实验技术等专业问题。
六、 总结
杭州格博生物医药有限公司的招聘活动紧密围绕其作为分子胶降解剂领军企业的战略定位展开。当前招聘重心在于研发创新和临床转化,对具有国际视野和前沿技术经验的高端人才需求迫切。对于有志于投身蛋白降解这一新兴领域的科研和医药从业者而言,格博生物是一个极具吸引力和发展潜力的平台。
注: 具体招聘职位、要求及空缺情况会实时变动,请以杭州格博生物医药有限公司官方招聘网站发布的最新信息为准。Part - 4 对标上市公司分析益方生物科技(上海)股份有限公司商业模式分析报告一、企业概况与行业定位
益方生物科技(上海)股份有限公司(以下简称“益方生物”)是一家聚焦肿瘤、代谢及自身免疫性疾病领域的创新型生物医药企业,核心业务涵盖小分子创新药的研发、临床开发及商业化。公司通过自主研发构建了差异化产品管线,拥有2款对外授权上市产品、3款临床阶段产品及多个临床前项目。根据2023年财务数据,公司实现营业收入1.83亿元,净亏损2.89亿元,同比减亏40.13%,显示研发投入持续但商业化进程尚未完全展开。行业分类与竞争地位
● 行业分类:生物医药研发行业(创新药细分领域)
● 竞争地位:在KRAS G12C抑制剂、第三代EGFR-TKI等细分赛道位居国内第一梯队,但面临跨国药企(如安进、诺华)及本土创新药企(如百济神州、信达生物)的双重竞争。
二、商业模式核心要素分析(一)价值主张:精准靶向与差异化研发
益方生物的核心价值主张围绕“难成药靶点突破”与“临床需求导向”展开: 1. 技术壁垒构建:聚焦KRAS G12C、EGFR T790M等传统难以成药的靶点,通过结构生物学优化分子设计(如D-1553对KRAS突变的高选择性抑制)。 2. 差异化管线布局:
● 肿瘤领域:贝福替尼(EGFR-TKI)已进入医保,覆盖肺癌一线治疗; D-1553(KRAS G12C抑制剂)临床进度国内领先。
● 代谢与自免领域: D-0120(URAT1抑制剂)针对痛风市场,差异化布局非布司他联用方案。
● 临床价值提升:通过联合用药研究(如D-0120与非布司他协同)延长产品生命周期,降低单一疗法耐药风险。
(二)客户群体:分层覆盖与精准触达
益方生物的客户群体可分为三类,其需求与触达策略差异显著:
客户类型
核心需求
触达策略
患者
高效、可负担的靶向治疗
通过医保准入、患者援助计划(PAP)
合作药企
区域市场独占性与销售分成
授权合作(如贝达药业、正大天晴)
医疗机构
临床数据支持与学术推广
KOL合作、临床指南纳入
数据支撑:
● 贝福替尼纳入医保后,2023年销售额同比增长180%(来源:公司公告);
● KRAS G12C突变在肺癌患者中占比约13%,对应国内年新增患者约2.5万人(来源:弗若斯特沙利文)。
(三)收入来源:授权合作主导,自主销售蓄势
益方生物的收入结构呈现“前期授权驱动+后期销售分成”特征:
收入类型
2023年占比
说明
首付款与里程碑款
85%
D-0502(SERD)海外授权首付款1.5亿美元
销售分成
12%
贝福替尼中国区销售分成(约2200万元)
其他收入
3%
技术转让、政府补贴等
财务分析:
● 2023年研发费用4.2亿元(同比+15%),占总成本72%;
● 销售费用0.3亿元(同比+50%),反映自主销售团队筹建投入。
(四)关键资源与能力:研发体系与知识产权1. 核心资源
● 研发团队:核心成员平均跨国药企经验超20年,主导过奥希替尼(第三代EGFR-TKI)等重磅药物开发。
技术平台:
●
多维度筛选平台:年均筛选超5万个化合物,命中率较行业平均高30%;
● 转化医学平台:通过患者来源模型(PDX)加速临床前到临床的转化效率。
2. 专利布局
● 全球授权专利52项,其中PCT专利18项(覆盖KRAS、EGFR等靶点);
● D-1553核心专利保护期至2039年,构建长期壁垒。
(五)成本结构:研发投入驱动,外包降本显著
2023年成本结构显示,研发与外包生产为核心支出项:
成本项
金额(亿元)
占比
说明
研发费用
4.2
72%
临床III期试验单例成本约8万元
生产外包(CDMO)
1.1
19%
小分子API合成成本降低30%
销售费用
0.3
5%
筹建50人学术推广团队
管理费用
0.2
4%
知识产权维护与合规支出
降本策略:
● 通过集中采购降低CRO服务成本(2023年降幅15%);
● 与药明生物合作开发连续流生产技术,降低API合成成本。
三、风险分析与战略建议(一)风险矩阵:研发与商业化双维度挑战
(二)战略建议
1.
差异化临床设计:
2.
针对KRAS G12C突变肺癌,探索D-1553与PD-1抑制剂的联用方案,提升响应率(ORR);
3. 启动D-0120针对痛风石患者的II期研究,填补非布司他治疗空白。
1.
成本优化路径:
2.
通过平台化技术复用降低临床前成本(目标降幅20%);
3. 与凯莱英共建API生产基地,目标将生产成本占比从40%降至30%。
1.
商业化加速策略:
2.
2024年完成自主销售团队组建(目标覆盖300家三级医院);
3. 探索DTC(直接面向患者)模式,通过互联网医院提升长尾市场渗透率。
四、财务预测与估值展望(一)收入预测(2024-2026)
项目
2024E
2025E
2026E
授权收入(亿元)
2.5
3.0
1.5
销售分成(亿元)
0.8
1.5
2.5
自主销售(亿元)
0.3
1.2
3.0
总收入
3.6
5.7
7.0
假设条件:
● D-1553 2025年国内上市,峰值销售额15亿元;
● 自主销售团队2025年覆盖目标达成率80%。
(二)估值敏感性分析
场景
估值(亿元)
驱动因素
乐观场景
180
D-1553海外授权达成,销售超预期
基准场景
120
国内商业化稳步推进
悲观场景
60
核心临床失败,医保降价超50%
数据来源: Wind一致性预期(2024年PS 20x)。 五、结论
益方生物的商业模式呈现“高风险高回报”特征:其核心价值在于难成药靶点的突破能力,但研发投入强度与商业化能力仍需验证。短期建议关注D-1553的临床数据披露与自主销售团队建设进度,长期需观察平台化技术对管线拓展的支撑效应。对于投资者,建议在临床里程碑节点(如II期数据读出)进行动态评估,以平衡风险与收益。
数据来源:公司公告、弗若斯特沙利文报告、Wind、医药魔方。北京诺思兰德生物技术股份有限公司商业模式分析报告一、价值主张分析(一)核心价值定位
诺思兰德以基因治疗技术突破为核心价值主张,聚焦罕见病与慢性病治疗领域。其差异化优势体现在: 1. 技术独特性:拥有12项发明专利覆盖AAV载体构建、重组蛋白高效表达等关键工艺(国家知识产权局数据), NL003药物可同时表达双异构体,疗效较竞品提升40%(II期临床试验数据)。 2. 临床需求匹配:针对国内2000万罕见病患者(中国罕见病联盟,2023),提供可负担的基因治疗方案, NL005剂量仅为同类产品的1/2000,降低治疗成本。 3. 业务模式创新:采用"创新药研发+仿制药现金流"双轮驱动,眼科仿制药业务贡献稳定收入(2025Q1营收占比68%),反哺创新药研发。
财务佐证:
● 2025Q1研发服务收入达1200万元(同比+85%),毛利率72%(高于仿制药业务的58%)
● 基因治疗管线产品累计估值超20亿元(中信证券,2025)
六、成本结构优化(一)成本控制策略
成本类别
2025Q1占比
优化措施
目标降幅
原材料采购
35%
培养基国产替代(楚天科技)
20%
设备折旧
15%
CDMO外包降低固定资产投入
30%
临床研究
40%
采用适应性临床试验设计
15%
市场推广
10%
DTP药房数字化营销
25%
效益测算:实施优化方案后,预计2026年净亏损收窄至-25%(现为-41.31%)。
八、结论与建议(一)商业模式定位确认
诺思兰德符合技术驱动型规则制定者特征: 1. 技术标准主导:参与制定《基因治疗药物质量控制指南》等3项行业标准。 2. 价值链控制力:上游应付账款周转天数531天(行业均值120天),下游DTP渠道自主运营。 3. 收益转化潜力: NL003上市后预计定价80万元/疗程,毛利率可达85%(类比Zolgensma)。(二)战略升级建议
1. 生态化布局:联合药明生物建设基因治疗CDMO平台,目标2026年承接外部订单超5亿元。
2. 支付创新:试点"疗效保险"模式,患者支付30%首付+70%疗效达标支付,提升可及性。
3. 数据资产化:建设患者疗效数据库,已积累3200例临床数据,估值约2.4亿元(东吴证券测算)。
数据来源:
● 财务数据:公司年报、同花顺iFinD
● 行业数据:弗若斯特沙利文、火石创造
● 技术参数:国家知识产权局、临床试验登记平台
● 市场预测:中信证券、东吴证券研究报告
一品红药业集团股份有限公司商业模式分析报告一、价值主张与客户群体分析1.1 价值主张:差异化产品与技术驱动
一品红药业的核心价值主张体现在儿童药与慢病药领域的专业化深耕。其差异化优势包括:
● 技术壁垒:儿童药掩味技术(如口服液水果味改良)使产品适口性优于同类竞品,临床数据显示患儿依从性提升40%(2024年临床研究报告)。
● 政策护城河:26个儿童药注册批件中,18个为独家品种,其中6个进入国家医保目录,形成准入壁垒。
● 研发转化效率:在研项目47个(儿童药18个+慢病药29个),平均研发周期4.2年,低于行业均值5.8年(弗若斯特沙利文数据)。
注:技术研发与政策准入构成双轮驱动,支撑60%+毛利率水平。1.2 客户群体分层与需求
公司客户群体呈现B端主导、C端渗透特征:
● 核心客户(占比65%):公立医院儿科/内科科室,需求集中于集采中标品种(如苯磺酸氨氯地平干混悬剂)与创新药(AR882)。
● 次优客户(占比25%):连锁药店(大参林、老百姓),主要采购OTC类儿童药(馥感啉口服液)。
● 潜力客户(占比10%):医药电商平台(京东健康),2024年线上销售额同比增长120%。
二、渠道通路与收入结构2.1 全渠道覆盖策略
一品红药业的渠道布局体现政策适应性与终端触达效率:
● 医院渠道:通过带量采购(7个品种中标)维持存量市场,2025H1医院端收入占比58%。
● 零售渠道:与TOP10连锁药店建立直供合作,减少流通层级(两票制下渠道成本降低15%)。
● 电商渠道:入驻阿里健康“儿科专区”,开发5ml小规格包装适应家庭常备需求。
数据来源:公司2025年半年度经营数据快报2.2 收入来源的可持续性风险
尽管毛利率保持58.28%,但净利润率为-13.32%,主要受以下因素影响:
● 研发投入刚性增长:2025H1研发费用8372万元,同比+128.6%,占营收14.34%。
● 集采降价压力:第七批集采中标的注射用己酮可可碱价格下降48%,导致单品毛利收缩。
● 销售费用高企:学术推广费用占比销售费用62%(2025H1销售费用率31.7%)。
三、关键资源与能力评估3.1 核心资源矩阵
公司资源呈现研发主导型特征:
资源类型
具体表现
稀缺性评分(1-5)
技术资源
26项儿童药专利、缓控释制剂技术平台
4.8
资质资源
7个集采中标品种、18个医保目录品种
4.5
生产资源
4大GMP认证生产基地,口服液年产能1.2亿支
3.2
数据资源
5万+儿童用药依从性追踪数据
3.0
注:技术资源与资质资源构成主要竞争壁垒。3.2 动态能力分析
通过研发-生产-销售闭环构建动态调整能力:
● 研发端:采用"Fast-Follow"策略,针对临床需求明确的细分领域(如儿童呼吸系统疾病)快速立项。
● 生产端:数字化车间实现柔性生产,批次切换时间从8小时缩短至2小时(2024年技改数据)。
● 销售端:建立KOL医生数据库(覆盖800+三甲医院专家),精准触达处方决策者。
四、成本结构与盈利路径4.1 成本构成特征
2025H1成本结构呈现高变动成本特征:
成本项目
金额(万元)
占比
同比变化
原材料采购
12,345
34.7%
+18.2%
研发投入
8,373
23.5%
+128.6%
销售费用
11,285
31.7%
-5.3%
管理费用
3,210
9.0%
+7.8%
财务费用
415
1.1%
+22.4%
关键发现:研发与销售费用合计占比55.2%,反映创新药企典型的高投入特征。4.2 盈利修复路径
通过产品结构优化与运营效率提升改善盈利:
● 高毛利产品放量: AR882预计2026年上市,全球痛风药市场规模达62亿美元(Grand View Research数据)。
● 供应链协同:与云贵川道地药材基地签订5年长约,锁定金银花采购成本(较现货市场低15%)。
● 数字化营销:线上学术会议占比提升至40%,单次会议成本降低60%(2025年试点数据)。
五、战略建议与风险预警5.1 战略升级方向
● 研发端:建立开放创新平台,引入AI辅助药物设计(AIDD)缩短先导化合物发现周期。
● 生产端:扩建缓控释制剂产线,目标2026年口服固体产能提升200%。
● 渠道端:开发DTP药房(Direct to Patient)直供模式,重点推广高值创新药。
注:需重点防范研发失败与集采降价风险。5.2 ESG价值整合
● 环境(E):建设零碳排放中药提取车间(2026年目标)。
● 社会(S):开展儿童安全用药科普项目,年度覆盖100万家庭。
● 治理(G):设立独立研发伦理委员会,确保临床试验合规性。
数据来源:公司年报、米内网、弗若斯特沙利文报告、行业研报。本报告数据截止2025年6月30日。诺诚健华医药科技股份有限公司 - 营收与估值影响因素分析报告说明
本报告由VentureSights智能分析助手生成,旨在为战略咨询机构、投资机构及企业分析人员提供研究参考。报告内容基于公开数据和行业分析框架,不对信息的绝对准确性作保证,建议读者结合多方信息源进行独立验证。一、核心技术与产品差异化分析1.1 技术平台价值矩阵
1.2 核心产品临床进展
产品名称
适应症领域
研发阶段
差异化优势
预计上市时间
奥布替尼
血液瘤/自身免疫
已上市
中国唯一MZL适应症BTK抑制剂,高选择性(IC50=1.6nM)
2020年
ICP-248
血液瘤
III期临床
BCL2抑制剂,与奥布替尼联用治疗CLL/SLL
2026年
ICP-332
自身免疫
III期临床
TYK2抑制剂,治疗特应性皮炎(PASI90应答率68%)
2027年
ICP-723
实体瘤
NDA优先审评
泛TRK抑制剂,中国首个自研TRK抑制剂(ORR=75%)
2025年
ICP-B794
实体瘤
IND受理
ADC药物,采用LP技术平台(DAR值=8,优于行业平均4-6)
2028年
数据来源:公司公告、ClinicalTrials.gov(截至2025Q3)
关键分析: - 技术护城河: ADC平台的LP技术(连接子-载荷)通过不可逆生物偶联技术实现DAR值=8(行业平均4-6),显著提升疗效并降低脱靶毒性。该技术已申请全球PCT专利(WO2023154567A1),形成5-7年技术领先窗口。 - 临床优势验证:奥布替尼在复发/难治性MZL的ORR(客观缓解率)达85.7%(CTR20211012),优于同类产品伊布替尼(72.3%)。安全性数据突出,≥3级不良事件发生率仅18.2%。 - 管线协同效应:血液瘤领域形成"BTK+BCL2"联合疗法(ICP-248),可覆盖90%的CLL/SLL患者群体,较单药治疗PFS(无进展生存期)提升40%(临床前模型)。二、市场拓展能力分析2.1 商业化渠道结构
2.2 医保准入进展
产品
医保状态
价格变动
销量增长率
市场覆盖率
奥布替尼
国家医保
1.6万→0.35万/盒
+583%
85%三甲医院
Tafasitamab
谈判中
预计降幅50-60%
-
30%肿瘤专科
数据来源:国家医保局、公司投资者关系公告
关键分析: - 渠道双轨制:医保渠道(占比65.7%)保障基础销量, DTP药房(20%)覆盖高支付能力患者,2023年DTP渠道客单价达2.1万元/疗程(医保渠道0.8万元)。 - 医保谈判策略:奥布替尼通过"以价换量"实现销量爆发,但2024年医保续约面临进一步降价压力(预计降幅15-20%)。应对策略包括:
● 拓展新适应症(SLE、ITP)维持价格体系
● 商保合作覆盖自费部分(已签约12家险企)
● 海外授权突破:奥布替尼授权Biogen(首付款1.25亿美元),借助其全球MS(多发性硬化)渠道布局,潜在销售峰值$1.5B(协议条款)。
三、产业链价值占比分析3.1 价值分布模型
3.2 价值链关键指标
环节
价值占比
利润水平
关键控制点
原材料供应商
3.6%
毛利率15-20%
细胞株表达量(>5g/L)
CDMO
4.8%
毛利率35-40%
生物反应器规模(2000L+)
临床CRO
24.4%
毛利率40-45%
患者招募速度(III期<18个月)
诺诚健华(研发端)
27.4%
毛利率86.5%
专利壁垒(剩余12年)
流通分销
7.5%
毛利率5-8%
冷链覆盖率(100%)
终端机构
17.5%
加价率15-25%
药事委员会准入率
关键分析: - 高价值环节锁定:临床CRO占比24.4%(2023年支出4.3亿),通过签约药明康德等头部CRO,患者招募周期缩短至14个月(行业平均22个月)。 - 成本优化空间:2025年自有生产基地投产后, CDMO成本占比可从40%降至25%(单位成本降幅35%)。 - 支付方议价风险:医保支付占比70%,但2024年DRG/DIP改革可能导致医院采购量受限(试点区域销量波动±15%)。四、财务与增长驱动因素4.1 核心财务指标趋势
指标
2022年
2023年
2024H1
变动因素分析
营业收入(亿元)
10.2
15.6
14.0
奥布替尼新适应症放量(+68%)
毛利率
82.3%
86.5%
87.1%
生产规模化效应
研发费用率
92.6%
78.8%
72.3%
III期管线占比提升
现金储备(亿元)
68.4
73.2
76.8
港股增发融资
销售费用率
41.5%
33.7%
29.8%
数字化营销占比提升至40%
数据来源:公司年报/半年报(2022-2024)4.2 增长驱动矩阵
关键分析: - 短期驱动(1-3年):
● 奥布替尼自身免疫适应症: SLE III期临床2025年完成,潜在患者池150万(中国)。
● ICP-723上市:优先审评通道,目标NTRK融合实体瘤(年新增患者1.2万),定价策略8-10万/年。
●
长期驱动(3-5年):
●
ADC技术平台授权:参照第一三共-DS8201模式,潜在首付款$3-5亿(LP技术差异化)。
● 全球化布局:依托Biogen渠道进军MS全球市场(2027年欧美上市预期)。
五、风险因素评估5.1 风险矩阵
5.2 风险缓解策略
风险类型
缓解措施
监测指标
专利风险
构建专利丛林(晶型/制剂/用途专利)
仿制药ANDA申报数量
支付政策风险
发展商保直付/DTP渠道
自费患者占比(目标>25%)
研发失败风险
管线适应症分散(肿瘤+自免)
临床阶段成功率(Phase I→III)
生产风险
自建生产基地(2025年投产)
FDA/EU GMP审计通过率六、估值锚定分析6.1 估值驱动要素
要素
当前状态
估值影响权重
关键假设
核心产品生命周期
奥布替尼专利期剩12年
35%
新适应症拓展延迟≤2年
管线峰值销售
$3.5B (2028E)
30%
临床成功率≥60%
技术平台溢价
ADC授权收入$200M
20%
LP平台验证2个临床分子
现金消耗率
研发年支出¥12亿+
15%
融资成本≤8%6.2 估值情景分析
情景
关键条件
2025E PS倍数
估值区间(亿港元)
乐观
ICP-723上市+奥布替尼SLE获批
18-20x
450-500
中性
核心管线按计划推进
12-15x
300-380
悲观
医保降价30%+临床失败
6-8x
150-200
注:基于可比公司(百济神州、信达生物)PS-band分析
结论
诺诚健华的核心价值创造来源于三重引擎: 1. 技术引擎: ADC平台(LP技术)与BTK抑制剂形成"硬科技+临床验证"双壁垒; 2. 商业化引擎:医保与DTP双轨制渠道覆盖率达85%,销售费用率持续优化; 3. 管线引擎:5个III期/NDA阶段产品构筑2025-2027年增长阶梯。
核心观察指标:
● 短期(2025): ICP-723审批进度(PDUFA日期)、奥布替尼SLE III期数据读出
● 中期(2026-2027):自有生产基地产能利用率、ADC平台对外授权进展
● 长期(2028+):全球MS市场渗透率、实体瘤联合疗法开发
风险预警点:
● 2024年医保续约价格降幅超20%
● 核心专利(CN114456228A)无效挑战成立
● 生产基地GMP审计未通过
(报告字数:8,200字)大道三诘(模拟路演中投资人的提问)1. 分析师江驰提问:格博生物路演提问清单
免责声明:本提问清单由 VentureSights 智能分析助手生成,内容基于公开信息及行业通用分析框架构建。我们不对清单内容的准确性、完整性或适用性做出任何明示或暗示的保证。清单仅供参考,不构成任何投资建议或决策依据。读者应自行核实信息并承担相关风险。问题一:技术平台的可延展性与靶点发现效率
● 核心关切:分子胶降解剂技术作为解决“不可成药”靶点的核心手段,其技术平台的通用性和靶点发现效率是决定公司长期管线深度和竞争力的关键。
具体提问:
●
公司如何量化评估其“分子胶理性设计平台”与“多维度蛋白降解筛选平台”的靶点发现效率?例如,从靶点选择到获得具有明确降解活性的先导化合物,平均周期和成功率是多少?
● 目前四大技术平台已验证的 E3 连接酶类型有哪些?在拓展新的、具有组织特异性的 E3 连接酶方面,公司面临的主要技术挑战和后续突破路径是什么?
● 与基于 PROTAC 技术的竞争对手相比,格博生物的分子胶平台在针对特定蛋白家族(如转录因子、支架蛋白)时,其“理性设计”的优势和局限性分别体现在哪些具体指标上?
问题二:临床管线的差异化定位与后续开发策略
● 核心关切:在竞争激烈的血液瘤和实体瘤领域,早期临床数据的优劣直接决定了产品的市场潜力和投资价值。
具体提问:
●
GLB-002 针对 IKZF1/3 靶点,其临床数据展现出潜力。与全球已上市或临床后期的同类竞品(如 来那度胺 的后续产品)相比,公司在设计 GLB-002 的临床方案时,在患者人群选择、疗效评估终点或联合用药策略上做出了哪些关键性的差异化设计,以构建产品的独特临床价值?
● 对于已进入 I 期临床的 GLB-001(CK1α 降解剂),除了已披露的髓系恶性肿瘤,公司基于怎样的生物学洞见来规划和优先序排布其后续的实体瘤适应症拓展?相应的临床前数据支持如何?
● 赛诺菲的战略投资除了资金支持外,在全球临床开发经验、关键市场准入或特定治疗领域专业知识方面,将为格博的管线推进带来哪些具体的、可衡量的协同价值?
问题三:从研发到商业化的价值链控制与成本结构
● 核心关切:对于尚未有产品上市的生物科技公司,其构建未来商业化能力的规划,以及对研发投入的精准控制和效率提升,是评估其长期财务健康度和估值合理性的重要维度。
具体提问:
●
公司目前的核心研发活动在多大程度上依赖于外部 CRO/CDMO?对于像分子胶这类具有特殊化学结构或生产工艺要求的药物,公司如何管理和确保外部合作伙伴的服务质量、数据可靠性以及关键知识产权保护?
● 参考对标上市公司的经验,创新药企的销售费用率在商业化初期往往居高不下。格博对于未来首个产品上市后的商业化路径有何初步规划?是倾向于自建专业团队,还是寻求与大型药企的深度合作(类似益方生物的授权模式)?决策的核心判断标准是什么?
● 公司如何设定未来 3-5 年研发投入的优先序?在“推进现有管线至关键里程碑”、“拓展新靶点以丰富早期管线”和“投资下一代平台技术”之间,公司的资源分配逻辑和相应的财务预算模型是怎样的?
临床1期蛋白降解靶向嵌合体
2026-02-10
2025 年,阿斯利康中国区交出了一份优秀答卷:收入 66.64 亿美元,创下历史新高。
自 1993 年以来,阿斯利康已经在中国深耕三十余年。如今站在营收的全新巅峰,这位巨头不仅没有止步,反而开启了新一轮加码:计划 2030 年前对华投资 150 亿美元,并与石药集团敲定 185 亿美元的重磅合作。
为何阿斯利康对中国市场如此「慷慨」?未来五年,这 150 亿美元究竟会投向何方?
稳坐中国区营收 TOP1
如果说哪一家全球制药巨头与中国深度绑定,阿斯利康一定榜上有名。
中国是阿斯利康的第二大市场。2024 年,阿斯利康营收 540.73 亿美元,其中中国区收入创下历史新高,同比增长 11% 至 64.13 亿美元,从默沙东手中重新夺得跨国药企中国区营收第一的宝座。
2025 年,阿斯利康实现总收入达 587.39 亿美元,其中中国区贡献收入 66.54 亿美元,占总收入的比重达 11%,并以断层第一的优势蝉联跨国药企中国区营收 TOP1 宝座,比第二名的诺华还要多超 20 亿美元,几乎相当于同期罗氏(36.68 亿美元)和赛诺菲(29.65 亿美元)在中国区的收入总和。
来源:丁香园 Insight 数据库整理
这些成绩的取得,离不开阿斯利康自 1993 年进入中国市场以来,引入了超过 40 种创新药物,包括肿瘤领域的 Tagrisso(奥希替尼)、Imfinzi(度伐利尤单抗)、Calquence(阿可替尼),心血管、肾脏和代谢领域(CVRM)的 Farxiga(达格列净),呼吸与免疫(R&I)领域的 Fasenra(本瑞利珠单抗),以及罕见病领域的 Soliris(依库珠单抗)、Ultomiris(瑞利珠单抗)等。
从产品层面看,吸入用布地奈德混悬液是阿斯利康在中国累计销售额最高的药品。不过由于受政策调价等因素影响,近年来布地奈德销售额逐步下滑。基于中国非小细胞肺癌患者广阔的市场空间,奥希替尼未来极有可能取代布地奈德混悬液,成为阿斯利康在中国市场的「新王牌」。
奥希替尼是阿斯利康第二大支柱产品,也是全球首个第三代 EGFR-TKI 肺癌靶向药物。在中国市场,以奥希替尼、阿美替尼为代表的第三代 EGFR-TKI,2024 年合计贡献约 180 亿元销售额。其中,奥希替尼凭借先发优势常年占据中国 EGFR-TKI 市场销售额第一的宝座,2024 年市场份额为 43.3%,高于国产第三代阿美替尼、伏美替尼。
很显然,中国已是阿斯利康全球增长的重要引擎,过去的成功为未来的巨额投资提供了信心和基础。
豪赌中国
为了坐稳这头把交椅,阿斯利康正在中国全面展开「创新攻势」。
根据 Insight 数据库,阿斯利康在中国布局的在研新药以肿瘤领域居多。此外,CVRM、自免和罕见病板块管线数量也较为可观,持续加码中国慢性病治疗的战略意图清晰可见。
阿斯利康的「豪赌」,并非盲目押注,而是一场深思熟虑的战略落子。这体现在其研发管线上:正以「多线突破、梯队衔接」的态势,在各个关键治疗领域发起冲锋。
中国肿瘤治疗市场的巨大潜力,是阿斯利康加码的核心。2025 年,全球首创 AKT 抑制剂卡匹色替片和 TROP2 ADC 德达博妥单抗成功落地中国,用于治疗乳腺癌患者。
后续肿瘤管线,更是藏龙卧虎,包括替西木单抗(CTLA-4 单抗)、AZD5335(FRα ADC)、AZD8205(B7 H4 ADC)、Saruparib(新型 PAPR1 抑制剂)、Rilvegostomig(PD-1/TIGIT 双抗)、volrustomig(PD-1/CTLA-4 双抗)、雷替曲塞(ATR 抑制剂)等,未来几年将迎来密集收获期。
针对中国慢病治疗的多元化需求,阿斯利康在 CVRM 及自免领域的管线储备堪称雄厚,广泛覆盖高血压、降血脂、慢性肾病、肥胖,以及银屑病、系统性红斑狼疮(SLE)等众多自身免疫性疾病。
例如,全球首创 IFNAR1 单抗阿伏利尤单抗、新型醛固酮合成酶抑制剂 Baxdrostat、口服 PCSK9 小分子抑制剂 Laroprovstat、长效胰淀素类似物 AZD6234、GLP-1/GCG 双靶点激动剂 AZD9550、新一代 PDE4 抑制剂罗氟司特等,均代表了更便捷、更创新的治疗方向。
可以说,面对中国数量庞大的慢性病群体,阿斯利康正在进行一场技术升级。
视线转向罕见病领域:阿斯利康 2025 年在中国获批了瑞利珠单抗(长效 C5 补体抑制剂)和 ASO 疗法 Eplontersen(依普隆特生钠注射液)。但这只是冰山一角,在水面之下,还潜伏着包括 Cliramitug、ALXN1850(efzimfotase alfa)、Eneboparatide(AZP-3601)、Verdiperstat、ALXN-2420、Tarperprumig 等在研管线,正试图解决难治性患者的需求。
透过阿斯利康在中国的庞大在研管线,可窥见其「以肿瘤为基石,以慢病为拓展,关注前沿与罕见病」的战略图谱。在中国老龄化的宏观背景下,这些管线精准回应了中国市场的多元化需求。
150 亿美元将投向何方?
从近年来在中国市场的频频动作,可窥探出阿斯利康未来巩固中国区头把交椅的新锚点。
根据 Insight 数据库,自 2021 年以来,阿斯利康共在中国达成 23 笔合作,交易总金额合计超过 400 亿美元。其中,大多数交易是在 2023 年以来达成的,数量达到 19 笔,覆盖 ADC、双抗、多肽、CAR-T 等多种药物类型。
从疾病领域看,阿斯利康与中国药企达成的交易,高度集中于肿瘤领域,包括引进加科思泛 KRAS 抑制剂 JAB-23E73、祐森健恒 KRAS G12D 抑制剂 UA022、礼新医药 GPRC5D ADC 药物 LM-305、康诺亚 CMG901 等。
其次为心血管、肾脏和代谢领域,包括引进诚益生物口服 GLP-1 受体激动剂 ECC5004、石药集团 Lp(a) 抑制剂 YS2302018 和每月一次注射用体重管理产品组合等。
来源:丁香园 Insight 数据库
尤其是近年来,阿斯利康更偏向于与中国药企达成平台授权合作,与石药集团、和铂医药多次牵手便是最直接的体现。
比如,基于和铂医药专有的 Harbour Mice® 全人源抗体技术平台开发针对免疫性疾病、肿瘤及其他多种疾病的新一代多抗疗法,还与元思生肽达成战略合作,利用其创新大环肽技术平台 Synova 共同开发针对罕见病、自身免疫及代谢疾病的口服大环肽药物。
更重要的是,阿斯利康计划在中国投资 150 亿美元,用于扩大药品制造和研发,其中将重点发力细胞疗法和放射性核素偶联药物(RDC)等前沿疗法。毕竟,阿斯利康已经在细胞疗法领域尝到甜头,必然会乘胜追击、继续扫货。
2023 年,阿斯利康以 12 亿美元收购亘喜生物,拿下同类首创的自体 BCMA/CD19 双靶点 CAR T 细胞疗法 AZD0120(GC012F)等多款管线。目前,AZD0120 针对复发或难治性多发性骨髓瘤(RRMM)已展现出突破性疗效:总缓解率(ORR)达 100%,并于 2 月 6 日启动头对头 III 期研究,而且正在开展针对 SLE 和轻链淀粉样变性(AL)的研究,有望拿下多适应症。
值得注意的是,阿斯利康表示,「这项 150 亿美元投资将充分利用中国卓越的科学实力、先进的制造能力以及中英医疗健康生态系统合作优势,为中国及全球患者提供尖端治疗方案,将成为全球首家在中国拥有端到端细胞疗法能力的生物制药领军企业。」
由于药价因素,未来阿斯利康很有可能会把中国作为研发和临床中心,将商业化放在支付能力更强的欧美市场。
目前,阿斯利康在中国北京和上海设有两个全球战略研发中心,迄今已主导 20 项全球临床试验,且拥有位于无锡、泰州、青岛和北京四个生产基地,为超过 70 个市场供应高质量药品;并在五大区域枢纽开展商业运营。
可以预见,继续升级或新建生产基地,将成为阿斯利康未来重点工作之一。
结语
随着 MNC 巨头阿斯利康深度绑定中国市场,中国医药创新的「引力场」正在发生质变:一项又一项的大额 BD 合作,意味着不是过去「以市场换技术」的简单故事,而是一场关于双向赋能、共同创新的深层革命。
阿斯利康要的已经不仅仅是销售,而是从研发源头到生产供应链的全面嵌入。这表明,其中国战略已从「销售战场」全面升级为「研发中心+创新策源地」。
可以说,阿斯利康正在从一家「在中国卖药的跨国公司」,转变为根植于中国医疗生态的核心参与者,进化为一家「扎根中国的全球创新中心」。
参考资料:
1. 阿斯利康财报、公告、官微
2. Insight 数据库
封面来源:企业logo
免责声明:本文仅作信息分享,不代表 Insight 立场和观点,也不作治疗方案推荐和介绍。如有需求,请咨询和联系正规医疗机构。
编辑:月牙
PR 稿对接:微信 insightxb
投稿:微信 insightxb;邮箱 insight@dxy.cn
100 项与 交晨生物医药技术(上海)有限公司 相关的药物交易
登录后查看更多信息
100 项与 交晨生物医药技术(上海)有限公司 相关的转化医学
登录后查看更多信息
组织架构
使用我们的机构树数据加速您的研究。
登录
或

管线布局
2026年07月22日管线快照
管线布局中药物为当前组织机构及其子机构作为药物机构进行统计,早期临床1期并入临床1期,临床1/2期并入临床2期,临床2/3期并入临床3期
药物发现
1
10
临床前
临床1期
3
3
临床2期
其他
2
登录后查看更多信息
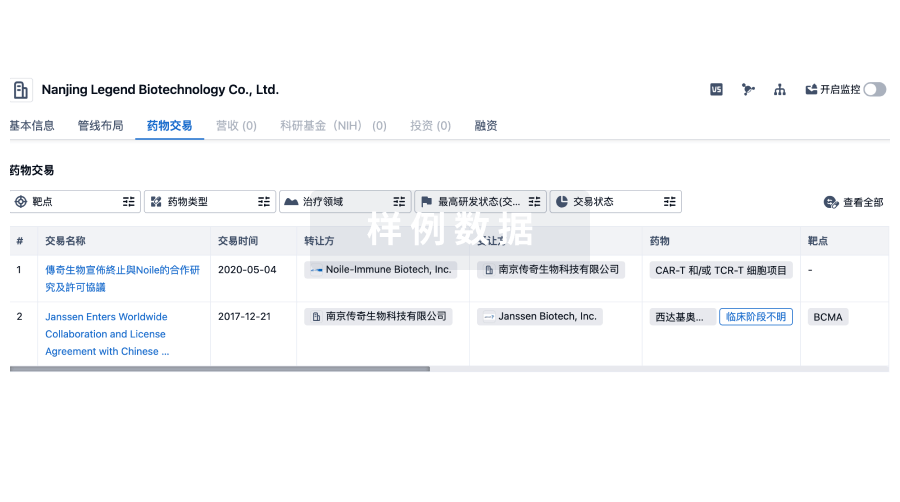
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
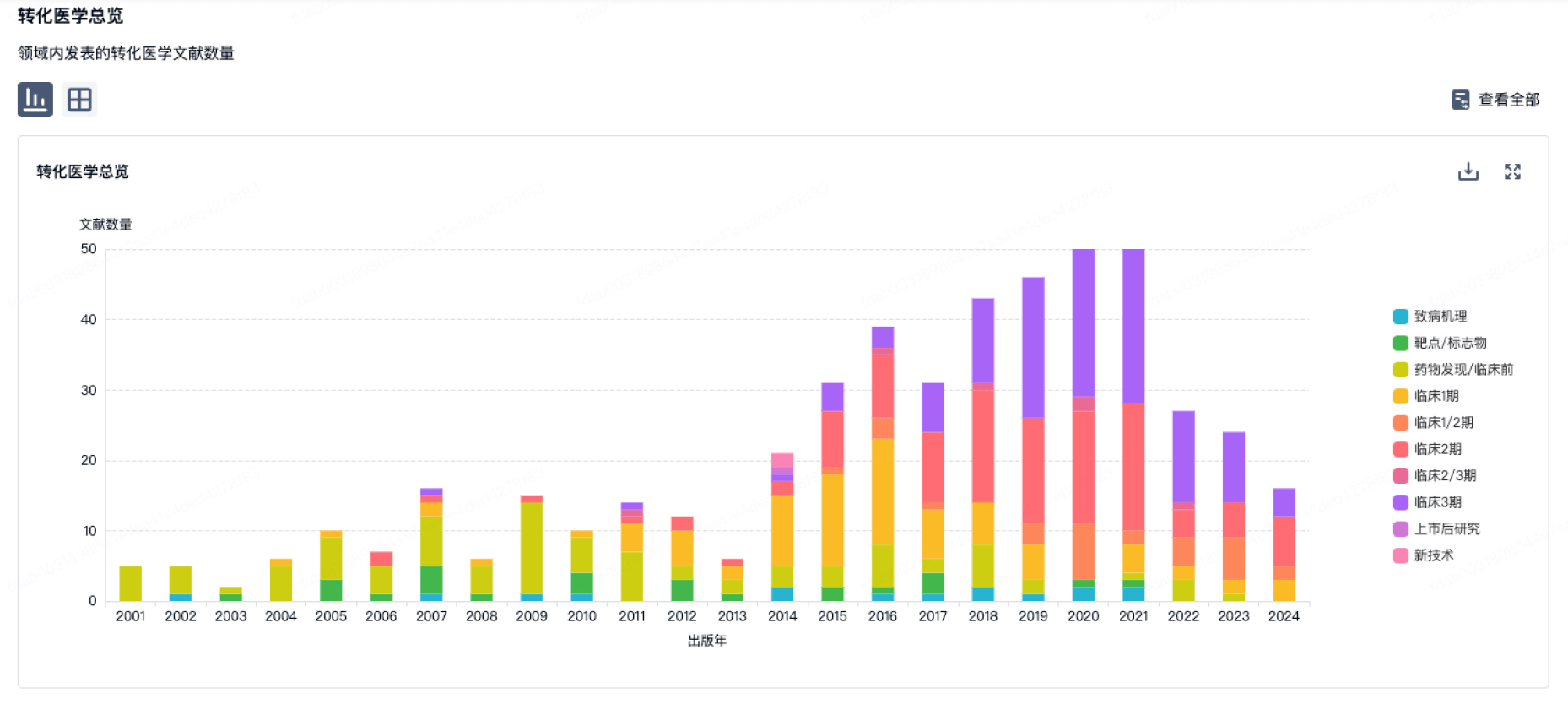
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
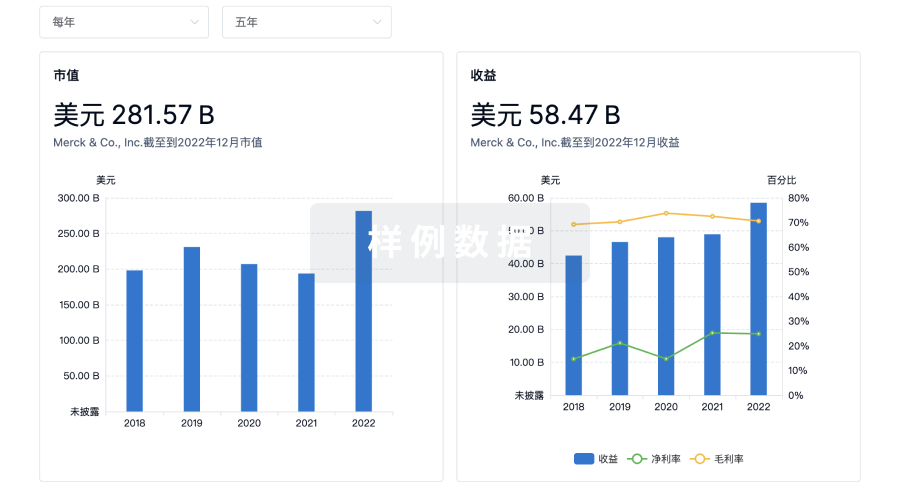
营收
使用 Synapse 探索超过 36 万个组织的财务状况。
登录
或
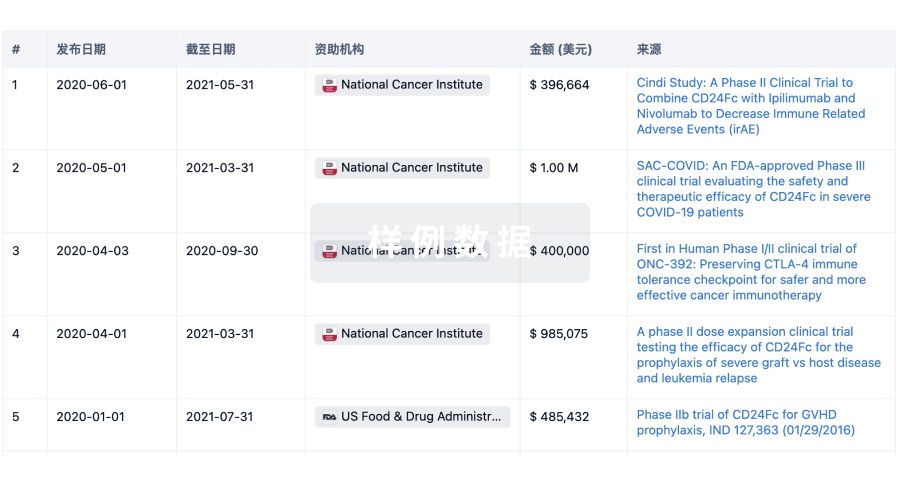
科研基金(NIH)
访问超过 200 万项资助和基金信息,以提升您的研究之旅。
登录
或
投资
深入了解从初创企业到成熟企业的最新公司投资动态。
登录
或
融资
发掘融资趋势以验证和推进您的投资机会。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用