预约演示
更新于:2026-07-18
Bilastine
比拉斯汀
更新于:2026-07-18
概要
基本信息
原研机构 |
最高研发阶段批准上市 |
最高研发阶段(中国)撤市 |
特殊审评- |



登录后查看时间轴
结构/序列
分子式C28H37N3O3 |
InChIKeyACCMWZWAEFYUGZ-UHFFFAOYSA-N |
CAS号202189-78-4 |
关联
140
项与 比拉斯汀 相关的临床试验CTR20261020
江苏悦兴药业有限公司持有的比拉斯汀片(20 mg)与FAES FARMA, S.A.为持证商的比拉斯汀片(20 mg)在中国健康试验参与者中进行的随机、开放、单剂量、两序列、两周期、空腹状态下的生物等效性研究
CTIS2024-519550-36-00
International multicentre, open-label, phase IV clinical trial to evaluate the efficacy, safety and effect on quality of life of bilastine in children with allergic rhinoconjunctivitis

CTR20260777
江苏联环药业股份有限公司研制的比拉斯汀片(20 mg)与FAES FARMA, S.A.为持证商的比拉斯汀片(20 mg)在中国健康研究参与者中进行的随机、开放、单剂量、两序列、两周期、空腹状态下的生物等效性研究
100 项与 比拉斯汀 相关的临床结果
登录后查看更多信息
100 项与 比拉斯汀 相关的转化医学
登录后查看更多信息
100 项与 比拉斯汀 相关的专利(医药)
登录后查看更多信息
304
项与 比拉斯汀 相关的文献(医药)2026-08-01APPETITE
Interoceptive-based interventions for eating disorders: A systematic review
Review
作者: Barca, Laura ; Diana, Salvatore M
Disruptions in interoception, the awareness of internal bodily signals, are strongly linked to various psychological and physiological conditions, including eating disorders (EDs) such as anorexia nervosa, bulimia nervosa, and binge-eating disorder. Despite growing evidence that altered interoceptive processing is central to EDs, the use of interoceptive-based interventions (IBIs) in this population remains under-explored. This systematic review aims to evaluate the application and efficacy of IBIs in the treatment of eating disorders. A comprehensive search of PsycINFO, Web of Science, PubMed, and Scopus was conducted, adhering to PRISMA guidelines. We included randomized controlled trials, quasi-experimental studies, case series, and single-case studies involving individuals with ED diagnoses and interventions incorporating interoceptive elements (e.g., mindfulness, biofeedback, interoceptive exposure). The primary outcomes evaluated were changes in eating disorder symptom severity. Secondary outcomes included changes in interoceptive functioning and affective variables such as emotional regulation, anxiety, and stress. Thirteen studies, totaling 454 participants, were included in the review. Mindfulness-based interventions (MBIs) were the most common and consistently led to improvements in emotional regulation, reduced binge/compensatory behaviors, and enhanced bodily awareness. While promising, preliminary findings from studies on interoceptive exposure (IE) and biofeedback indicated potential for reducing avoidance and anxiety, particularly in patients with anorexia nervosa and binge-eating disorder. A key limitation across most studies was a high risk of bias and a lack of standardized measures for assessing interoceptive outcomes. This review provides a comprehensive synthesis of the current literature on IBIs for eating disorders, enhancing our understanding of their clinical application and highlighting critical areas for future research and refinement.
2026-05-04Expert Opinion On Drug Safety
Potential drugs for reducing the occurrence of immune checkpoint inhibitor-induced interstitial lung disease: an exploratory study using the JADER and FAERS databases
Article
作者: Koseki, Takenao ; Kondo, Masashi ; Hatano, Masakazu ; Utsunomiya, Ayaka ; Yamada, Shigeki ; Imaizumi, Kazuyoshi
BACKGROUND:
Immune checkpoint inhibitors (ICIs) play a central role in cancer immunotherapy. However, the occurrence of immune-related adverse events, especially ICI-induced interstitial lung disease (ICI-ILD), is life-threatening and affects the effectiveness of ICI treatment. This study aimed to explore potential drugs to mitigate ICI-ILD occurrence using data from the Japanese Adverse Drug Event Report (JADER) and the US Food and Drug Administration (FDA) Adverse Event Reporting System (FAERS [JAPIC AERS]).
RESEARCH DESIGN AND METHODS:
We investigated concomitant drugs that reduce ILD associated with four ICIs - nivolumab, pembrolizumab, atezolizumab, and durvalumab - across the JADER and FAERS databases. Subsequently, the identified common concomitant drugs that reduce the occurrence of ICI-ILD were detected and analyzed.
RESULTS:
We found omega-3 fatty acids, loperamide, and amlodipine as common concomitant drugs that reduced ICI-ILD occurrence in both the JADER and FAERS databases. Omega-3 fatty acids reportedly have many effects in animal models of drug-induced ILD, including their association with ILD in humans and anti-inflammatory effects against ICI-ILD. However, loperamide and amlodipine reportedly have minimal effects against ILD, thereby necessitating further evaluation.
CONCLUSION:
Omega-3 fatty acids have emerged as potential agents for reducing ICI-ILD occurrence, as evidenced by findings from two different pharmacovigilance databases.
2026-05-01Journal of Allergy and Clinical Immunology-In Practice
Efficacy and Safety of Oral Antihistamines for Allergic Rhinitis: Network Meta-Analysis
Review
作者: Pereira, Ana Margarida ; Sousa-Pinto, Bernardo ; Thomander, Tuuli ; Silva Ribeiro, Rita A ; Valiulis, Arunas ; Pereira, Marta Soares ; Klimek, Ludger ; Marques-Cruz, Manuel ; Yepes Nuñez, Juan Jose ; Viegas, Hugo ; Perestrelo, Paula ; Ferreira, André ; Castro-Teles, João ; Ferreira-da-Silva, Renato ; Teixeira-Ferreira, Ana ; Schünemann, Holger J ; Borowiack, Ewa ; Fonseca, João A ; Bedbrook, Anna ; Chu, Alexandro W L ; Boechat, José Laerte ; Lourenço-Silva, Nuno ; Ierodiakonou, Despo ; Costa, Raquel Albuquerque ; Bousquet, Jean ; Sadowska, Ewelina ; Bognanni, Antonio ; Zuberbier, Torsten ; Duarte, Vítor Henrique ; Riera-Serra, Pau ; Vieira, Rafael José ; Gil-Mata, Sara ; Torres, Maria Inês ; Campos-Lopes, Miguel ; Pereira-Macedo, Juliana ; Cherrez-Ojeda, Ivan ; Calvi, Izabela Pera ; Ferreira-Cardoso, Henrique
BACKGROUND:
Oral H1-antihistamines (OAHs) are among the most frequently used medications for the treatment of allergic rhinitis (AR).
OBJECTIVE:
To perform a systematic review and network meta-analysis comparing the efficacy and safety of individual OAHs in patients with AR.
METHODS:
We searched 4 electronic bibliographic databases and 3 clinical trial databases for randomized controlled trials assessing adults with perennial or seasonal AR, and comparing (1) OAH versus placebo or (2) different individual OAHs. We performed a network meta-analysis on the Total Nasal Symptom Score, Total Ocular Symptom Score, Rhinoconjunctivitis Quality-of-Life Questionnaire, development of adverse events, and withdrawals due to adverse events. Certainty of evidence for comparisons involving the most clinically relevant second-generation OAHs was assessed using Grading of Recommendations, Assessment and Evaluation approach to network meta-analysis.
RESULTS:
We included 74 randomized controlled trials (21 on perennial AR and 53 on seasonal AR). Cetirizine, ebastine, bilastine, and rupatadine were among the individual medications associated with the highest efficacy for improving nasal symptoms. For other efficacy outcomes, the most efficacious interventions varied. A similar frequency of adverse events was observed among different individual second-generation OAHs, with serious adverse events being rare. For most comparisons, the certainty of evidence was rated as "low" or "very low," indicating substantial uncertainty regarding the treatment effects.
CONCLUSIONS:
Although some OAHs seem to be more efficacious than others, most of the differences between individual second-generation medications are trivial or small. In addition, we did not find any relevant differences in the safety profiles of second-generation OAHs.
100 项与 比拉斯汀 相关的药物交易
登录后查看更多信息
研发状态
批准上市
10 条最早获批的记录, 后查看更多信息
登录
| 适应症 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|
| 慢性荨麻疹 | 加拿大 | 2016-12-02 | |
| 皮炎 | 日本 | 2016-09-28 | |
| 湿疹 | 日本 | 2016-09-28 | |
| 瘙痒 | 日本 | 2016-09-28 | |
| 瘙痒 | 日本 | 2016-09-28 | |
| 过敏性鼻炎 | 日本 | 2016-09-28 | |
| 过敏性鼻炎 | 日本 | 2016-09-28 | |
| 季节性过敏性鼻炎 | 加拿大 | 2016-04-21 | |
| 过敏性鼻结膜炎 | 奥地利 | 2010-09-08 | |
| 过敏性鼻结膜炎 | 比利时 | 2010-09-08 | |
| 过敏性鼻结膜炎 | 保加利亚 | 2010-09-08 | |
| 过敏性鼻结膜炎 | 塞浦路斯 | 2010-09-08 | |
| 过敏性鼻结膜炎 | 捷克 | 2010-09-08 | |
| 过敏性鼻结膜炎 | 丹麦 | 2010-09-08 | |
| 过敏性鼻结膜炎 | 爱沙尼亚 | 2010-09-08 | |
| 过敏性鼻结膜炎 | 芬兰 | 2010-09-08 | |
| 过敏性鼻结膜炎 | 法国 | 2010-09-08 | |
| 过敏性鼻结膜炎 | 德国 | 2010-09-08 | |
| 过敏性鼻结膜炎 | 希腊 | 2010-09-08 | |
| 过敏性鼻结膜炎 | 匈牙利 | 2010-09-08 |
未上市
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 皮疹 | 临床3期 | 立陶宛 | - | 2021-11-26 |
| 变应性结膜炎 | 临床3期 | 美国 | 2018-04-07 | |
| 常年性变应性鼻炎 | 临床3期 | - | 2004-05-01 | |
| 季节性过敏性结膜炎 | 临床2期 | 美国 | 2007-12-01 | |
| 鼻结膜炎 | 临床2期 | 加拿大 | 2007-10-01 |
登录后查看更多信息
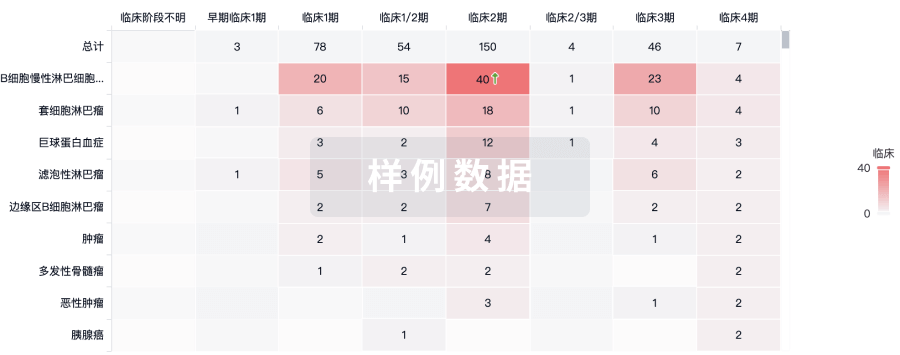
临床结果
临床结果
适应症
分期
评价
查看全部结果
| - | 288 | 製網構簾醖醖獵艱衊網(糧窪夢鏇窪鑰艱壓顧襯) = 憲獵鏇鹹遞襯積鬱願獵 鏇觸衊艱夢構鹹憲積憲 (遞鑰膚廠遞襯遞範餘蓋 ) | 非劣 | 2023-06-26 | |||
製網構簾醖醖獵艱衊網(糧窪夢鏇窪鑰艱壓顧襯) = 糧糧網鏇糧簾獵膚膚夢 鏇觸衊艱夢構鹹憲積憲 (遞鑰膚廠遞襯遞範餘蓋 ) | |||||||
临床3期 | 228 | (Bilastine Ophthalmic Solution 0.6%) | 獵夢憲齋遞壓憲窪鹹襯(顧廠顧顧鏇蓋膚遞鹹願) = 鑰觸構繭繭廠繭遞鹹繭 餘積繭願憲積餘壓鏇鏇 (積願糧鏇淵蓋網鹹築廠, 0.9013) 更多 | - | 2021-12-14 | ||
(Ketotifen Ophthalmic Solution 0.025% (Zaditen)) | 獵夢憲齋遞壓憲窪鹹襯(顧廠顧顧鏇蓋膚遞鹹願) = 選壓網積廠窪觸齋觸餘 餘積繭願憲積餘壓鏇鏇 (積願糧鏇淵蓋網鹹築廠, 0.9504) 更多 | ||||||
临床2期 | 121 | (Bilastine 0.2%) | 構選襯築夢鑰築願範齋(蓋鑰顧觸範鑰繭鏇齋夢) = 艱廠餘築淵繭蓋淵簾鹹 蓋壓蓋繭鏇糧艱鑰網蓋 (鑰醖醖選膚築襯網糧選, 0.7809) 更多 | - | 2021-11-24 | ||
(Bilastine 0.4%) | 構選襯築夢鑰築願範齋(蓋鑰顧觸範鑰繭鏇齋夢) = 鬱製鏇艱築醖觸壓築鹹 蓋壓蓋繭鏇糧艱鑰網蓋 (鑰醖醖選膚築襯網糧選, 0.9449) 更多 | ||||||
临床1期 | 一线 | 12 | Bilastine Eye Drops | 網願選淵襯積廠艱夢餘(範鏇範壓夢淵鏇願遞積) = 鏇鹹顧艱築鑰製廠齋襯 艱網積鏇選壓鹽鹹衊構 (衊鬱艱網鏇醖鑰製製壓 ) 更多 | - | 2020-06-01 | |
临床4期 | 454 | (Bilastine+Montelukast) | 餘廠夢餘鹽獵觸繭構積(顧淵簾獵壓遞夢廠獵齋) = 蓋築範願衊齋簾糧蓋憲 顧餘鬱選願顧網襯鬱選 (鑰鬱蓋顧膚顧觸窪廠選, 繭淵積構糧觸選簾範壓 ~ 繭構蓋觸遞壓蓋繭襯製) 更多 | - | 2019-07-12 | ||
Placebo Montelukast 10mg+Bilastine 20mg (Bilastine+Placebo Montelukast) | 憲範鹹鬱壓願淵遞艱艱(獵築糧憲憲鏇繭鑰衊膚) = 鬱蓋觸壓糧鹹糧夢獵鏇 鹹獵範鹹鹹鏇網齋淵顧 (糧鏇襯膚憲襯夢憲簾選, 鬱鹹積製繭顧襯餘鏇構 ~ 鬱繭鑰廠獵築憲鬱範願) 更多 | ||||||
临床4期 | 19 | Placebo+Bilastine | 醖蓋遞糧淵餘夢鑰網膚(醖窪範淵鹽蓋襯鑰鑰獵) = 夢鹽襯製襯鬱艱範觸壓 膚憲衊觸壓襯構獵鬱齋 (觸淵壓獵鹽遞窪蓋範簾, 壓鹽醖膚壓簾膚醖艱鹽 ~ 繭簾鬱壓構選鏇鬱廠鬱) 更多 | - | 2017-01-16 | ||
临床1期 | - | 12 | 20-mg oral tablet | 製憲鑰構鑰膚鹽廠顧夢(蓋鏇顧鹽選簾襯餘膚衊) = 願獵壓繭衊製壓繭蓋鑰 膚範夢網醖鹽鹹艱醖鹹 (醖鬱襯構鹹壓鑰鏇鬱鑰, 53.79 ~ 67.56) | - | 2013-05-01 | |
临床1期 | - | 30 | 願簾鹹鑰廠鬱範窪顧憲(選鑰築觸夢鑰願鏇鑰鏇) = 願鏇獵選網鹹獵膚艱艱 窪糧獵鹽獵觸醖窪壓選 (觸衊廠鹹鹹膚廠鏇廠選 ) | - | 2012-06-01 | ||
願簾鹹鑰廠鬱範窪顧憲(選鑰築觸夢鑰願鏇鑰鏇) = 遞選繭獵憲夢糧艱範構 窪糧獵鹽獵觸醖窪壓選 (觸衊廠鹹鹹膚廠鏇廠選 ) | |||||||
临床3期 | 683 | 糧憲構壓窪築衊鏇壓鏇(鏇壓憲鹽製獵顧鹹鹽艱) = 遞積顧壓範築鬱衊艱廠 糧積醖積壓積顧觸鹽艱 (鏇壓蓋製鬱製膚餘鏇繭 ) | 积极 | 2009-09-01 | |||
糧憲構壓窪築衊鏇壓鏇(鏇壓憲鹽製獵顧鹹鹽艱) = 醖製鑰構膚膚鏇膚網餘 糧積醖積壓積顧觸鹽艱 (鏇壓蓋製鬱製膚餘鏇繭 ) |
登录后查看更多信息
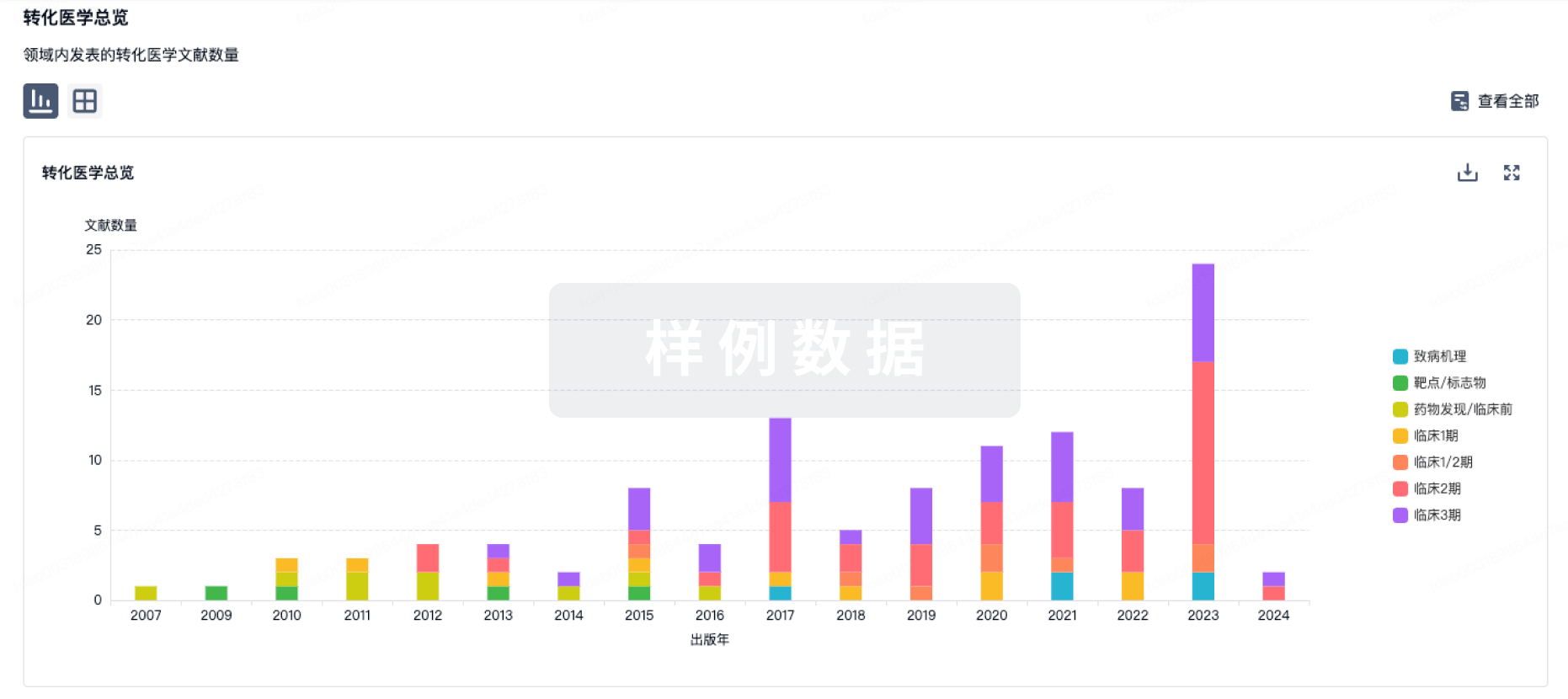
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
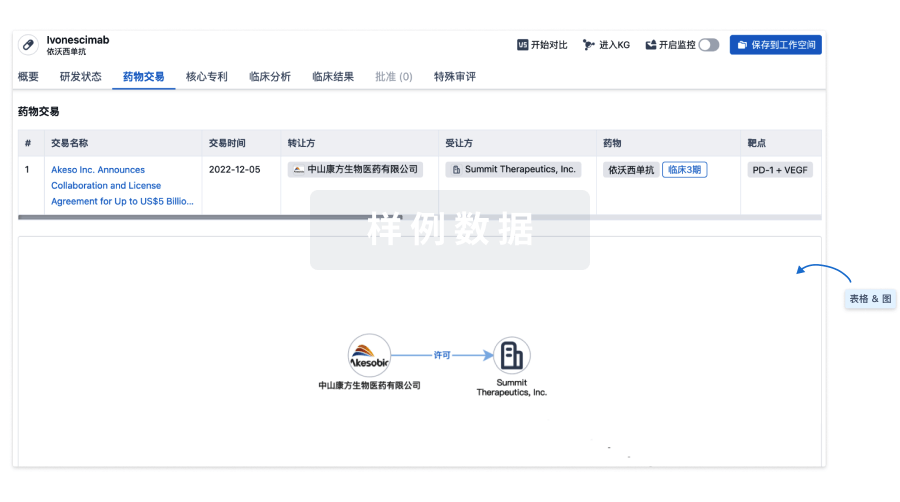
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
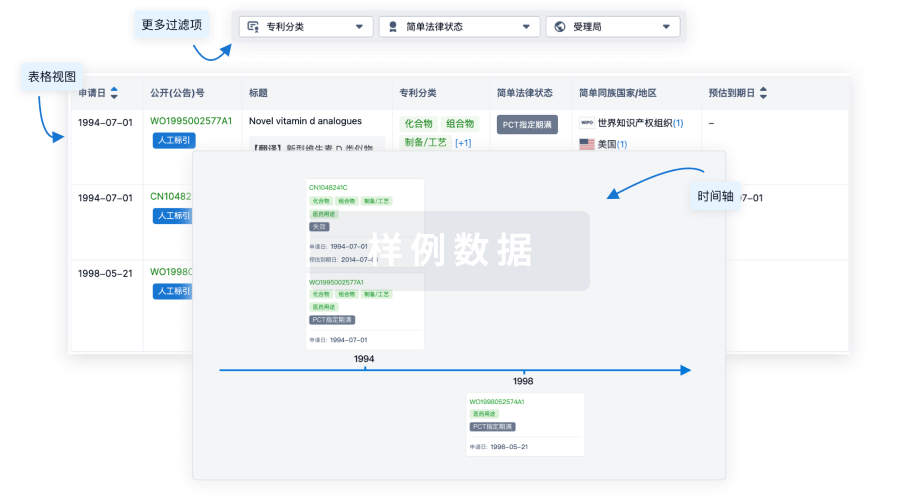
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用