预约演示
更新于:2026-07-11
Aminopterin
氨基蝶呤
更新于:2026-07-11
概要
基本信息
原研机构 |
在研机构- |
权益机构- |
最高研发阶段终止临床2期 |
首次获批日期- |
最高研发阶段(中国)- |
特殊审评- |


登录后查看时间轴
结构/序列
分子式C19H20N8O5 |
InChIKeyTVZGACDUOSZQKY-LBPRGKRZSA-N |
CAS号54-62-6 |
关联
6
项与 氨基蝶呤 相关的临床试验NCT03431974
A Phase 2 Randomized, Double-Blind, Placebo-Controlled Trial to Establish the Efficacy and Safety of Once-Weekly Oral Aminopterin for the Treatment of Subjects With Moderate-To-Severe Psoriasis
This study evaluates the treatment of psoriasis with aminopterin. Participants will be treated for 14 weeks with either aminopterin or placebo followed. The participants will not know if they are being treated with aminopterin or placebo.
开始日期2018-11-01 |
申办/合作机构 |
NCT01724931
A Phase 2 Double-Blind, Placebo-Controlled, Randomized Dose Finding Study For The Efficacy And Safety Of Aminopterin In Methotrexate-Naive Rheumatoid Arthritis
The purpose of this study is to determine whether aminopterin is effective in the treatment of rheumatoid arthritis (RA).
开始日期2013-02-01 |
申办/合作机构 |
NCT00937027
A Randomized Phase 1 Study Comparing The Safety and Oral Pharmacokinetics Of 0.25 mg and 1.0 mg Aminopterin Tablets In Human Subjects With Psoriasis
The purpose of this study is to compare the safety and pharmacokinetic properties (the absorption, distribution and excretion) of two preparations of aminopterin (0.25 mg tablets and 1.0 mg tablets) following oral administration by subjects with moderate to severe psoriasis.
开始日期2009-06-01 |
申办/合作机构 |
100 项与 氨基蝶呤 相关的临床结果
登录后查看更多信息
100 项与 氨基蝶呤 相关的转化医学
登录后查看更多信息
100 项与 氨基蝶呤 相关的专利(医药)
登录后查看更多信息
1,283
项与 氨基蝶呤 相关的文献(医药)2026-05-01·JCO Global Oncology
Erratum: Evolution of Therapy in Pediatric ALL From Aminopterin to Chimeric Antigen Receptor T-Cell Therapy: Global Advances, Indian Adaptations, and Lessons for Low- and Middle-Income Countries
Article
作者: Gupta, Aditya Kumar ; Seth, Rachna ; Mohapatra, Debabrata ; Meena, Jagdish Prasad
2026-03-01·JCO Global Oncology
Evolution of Therapy in Pediatric ALL From Aminopterin to Chimeric Antigen Receptor T-Cell Therapy: Global Advances, Indian Adaptations, and Lessons for Low- and Middle-Income Countries
Review
作者: Gupta, Aditya Kumar ; Seth, Rachna ; Mohapatra, Debabrata ; Meena, Jagdish Prasad
PURPOSE:
Survival outcomes for childhood ALL in low- and middle-income countries (LMICs) have shown gradual improvement, closely following the remarkable outcomes achieved in high-income countries, albeit with some time lag. This has been achieved by decades of efforts since the 1940s.
METHODS:
We conducted a narrative review of the previous literature, therapeutic innovations, and landmark trials in the evolution of childhood ALL from 1948 to 2025 and drew an analogy of how they have been adapted in the Indian context. The review gives a historical summary of the key therapeutic principles and survival trends over time.
RESULTS:
Globally, the principles of multiagent chemotherapy, CNS-directed therapy, risk-stratified intensification, minimal residual disease–guided treatment, and immunotherapy have shaped the backbone of modern ALL management. Each step has contributed to the steady rise in survival from 4% in the 1960s to 96% in the current era. In India, these principles were adopted sequentially with multicentre protocol 841, International Network for Cancer Treatment and Research protocols, and finally the risk-adapted Indian Collaborative Childhood Leukaemia protocol, resulting in improved survival from nearly 10% in the 1970s to 61%-76% in recent trials. However, survival remains approximately 20% lower than global benchmarks because of treatment-related mortality (12%), CNS relapses, and limited access to newer drugs, immunotherapy, and advanced diagnostics. Lately, low-intensity locally adapted regimens and affordable indigenous (CD19) chimeric antigen receptor T-cell therapy offer promise to partly narrow the gap although treatment toxicity and limited blinatumomab access remain challenging.
CONCLUSION:
The care of childhood ALL in India demonstrates how evidence-based protocol adaptations, health system strengthening, and multicentric collaboration can improve outcomes in LMICs despite several challenges, including financial constraints, limited drug access, late presentation, and treatment abandonment.
2025-06-04·Science Translational Medicine
Methotrexate exerts antitumor immune activity and improves the clinical efficacy of immunotherapy in patients with solid tumors
Article
作者: Zhang, Sulin ; He, Changyu ; Shen, Haiwei ; Song, Ying ; Su, Zhaoming ; Zhang, Naixia ; Yang, Ruirui ; Sun, Jian ; Li, Rui ; Zhang, Yingying ; Xu, Chuanhai ; Liu, Yadan ; Chu, Shuqing ; Zhang, Yinghui ; Geng, Wei ; Ding, Yiluan ; Yang, Xi ; Zhong, Feisheng ; Fu, Zunyun ; Wang, Bei ; Zheng, Mingyue
Low-dose methotrexate (MTX) is the first-line drug for treating rheumatoid arthritis as an immunosuppressor. We have identified that low-dose MTX exhibits antitumor immune activity. MTX treatment reduced tumor metastasis and enhanced the efficacy of radiation therapy and immune checkpoint blockade therapy in mice. Mechanistically, MTX selectively induced DNA damage, cGAS-STING [cyclic guanosine monophosphate–adenosine monophosphate (cGAMP) synthase (cGAS)–stimulator of interferon genes (STING)] pathway activation, and cGAMP generation in cancer cells. Furthermore, MTX bound to the substrate-binding pocket of ectonucleotide pyrophosphatase/phosphodiesterase 1 (ENPP1), inhibiting ENPP1-mediated cGAMP hydrolysis and adenosine generation. Consequently, MTX reduced extracellular adenosine and enhanced host STING-mediated antitumor immunity. In addition, a preliminary clinical trial demonstrated promising efficacy and safety of low-dose MTX in combination with immunotherapy and radiotherapy for patients with unresectable or metastatic solid tumors, showing improved outcomes compared with historical controls. These results highlight the previously unrecognized immunostimulatory functions of MTX and provide a rationale for combining MTX with tumor immunotherapy and radiotherapy in clinical settings.
10
项与 氨基蝶呤 相关的新闻(医药)2026-06-01
·张江药哥
2.1 本章学习目标
· 掌握抗体药物从靶点发现到上市的完整开发流程及各阶段的核心任务
· 理解靶点发现与验证的主要策略与技术方法
· 比较杂交瘤、噬菌体展示、转基因小鼠、单B细胞等先导抗体发现技术的原理及优缺点
· 了解抗体工程优化的关键策略,包括亲和力成熟、人源化和可开发性优化
· 掌握临床前研究中药效评价、药代动力学和安全性评价的核心内容
· 理解临床试验设计要点及监管审批的关键考量
· 认识计算方法在抗体药物开发各阶段的应用切入点与价值
2.2 关键概念
图2-1抗体药物开发流程关键概念导图。 本导图展示了抗体药物开发从靶点发现到上市的六大核心环节,以及贯穿始终的计算方法赋能。每个环节包含多个关键技术与决策节点,共同构成完整的药物开发价值链。
2.3 2.1 抗体药物开发概述
2.3.1 2.1.1 开发流程总览
抗体药物(Antibody Therapeutics)的开发是一个复杂而系统的工程,涵盖从基础研究到临床应用的多个阶段。一个典型的抗体药物开发流程可分为六个主要阶段:靶点发现与验证(Target Discovery and Validation)、先导抗体发现(Lead Antibody Discovery)、抗体工程与优化(Antibody Engineering and Optimization)、临床前研究(Preclinical Studies)、临床试验(Clinical Trials)以及生产与上市(Manufacturing and Marketing)[64,65]。
图2-2抗体药物开发流程总览。 从靶点发现到上市通常需要10-15年时间。各阶段括号内标注的是该阶段的典型时间跨度。值得注意的是,随着计算方法和人工智能技术的引入,各阶段的时间正在逐步缩短。
每个阶段都有明确的里程碑(Milestone)和决策关卡(Decision Gate),这种”阶段-关卡”管理模式确保了开发过程的科学性和可控性。靶点发现阶段的核心任务是识别与疾病相关的生物学靶点,并通过多种手段验证其作为药物靶点的可行性。先导抗体发现阶段利用各种抗体发现平台(如杂交瘤技术、噬菌体展示技术等)获得能够特异性结合靶点的候选抗体分子。抗体工程与优化阶段对候选抗体进行系统性改造,以提升其药学性质和成药性。临床前研究阶段通过体外和体内实验全面评估候选抗体的药效学、药代动力学和安全性。临床试验阶段在人体中验证抗体药物的安全性和有效性。最终通过监管审批后方可上市销售。
2.3.2 2.1.2 开发周期与成本
抗体药物的开发是一项耗时长、投入大的系统工程。从靶点发现到最终获批上市,整个过程通常需要10-15年的时间,总投入成本在10-30亿美元之间[66,67]。其中,临床试验阶段占据了最大的时间和资金比例。
具体而言,靶点发现与验证阶段通常需要1-3年,投入约5000万-1亿美元;先导抗体发现与优化阶段需要2-4年,投入约1-3亿美元;临床前研究阶段需要1-2年,投入约5000万-1亿美元;临床试验阶段需要6-10年,是耗时最长、投入最大的阶段,I期临床试验(Phase I)约需1-2年和2000万-5000万美元,II期临床试验(Phase II)约需2-3年和5000万-1亿美元,III期临床试验(Phase III)约需3-5年和1-5亿美元[68]。
近年来,得益于人工智能(Artificial Intelligence, AI)和计算生物学(Computational Biology)技术的飞速发展,抗体药物的开发效率正在显著提升。例如,基于深度学习的抗体结构预测工具(如AlphaFold2和IgFold)可以大幅缩短抗体结构解析的时间[50,52],而基于机器学习的可开发性预测模型则可以在早期筛选阶段就淘汰不具有良好成药性的候选分子,从而降低后期失败的风险和成本[53]。
2.3.3 2.1.3 成功率与失败原因分析
抗体药物开发的总体成功率(从进入临床试验到获批上市的概率)约为15%-25%,显著高于小分子药物的约10%[65,68]。然而,不同治疗领域和靶点的成功率差异较大。肿瘤学领域的抗体药物开发成功率约为12%-18%,而自身免疫疾病领域的成功率可达25%-35%[69]。
抗体药物开发失败的主要原因可以归纳为以下几个方面:
(1)靶点选择不当:这是临床试验失败的最主要原因之一,约占失败案例的30%-40%。靶点在疾病发生发展中的作用可能不如预期重要,或者存在代偿通路(Compensatory Pathway)使得单一靶点的干预效果有限[70]。
(2)疗效不足:即使靶点选择正确,抗体分子本身的特性(如亲和力、表位、作用机制)也可能导致疗效不达预期。约25%-30%的临床失败归因于疗效不足[71]。
(3)安全性问题:包括靶点相关毒性(On-target Toxicity)和非靶点相关毒性(Off-target Toxicity)。免疫原性(Immunogenicity)也是一个不可忽视的安全性风险,人体可能产生抗药抗体(Anti-Drug Antibody, ADA),影响药物的疗效和安全性[72]。
(4)药代动力学不理想:抗体的清除速率过快或组织渗透性不佳可能影响其在靶部位的有效浓度[73]。
(5)商业化考量:包括市场竞争激烈、患者人群过小、定价和准入策略不可行等非技术性因素[74]。
理解这些失败原因对于优化抗体药物开发策略至关重要。计算方法可以在多个层面帮助降低失败风险——通过靶点可成药性预测提高靶点选择的准确性,通过抗体-抗原相互作用模拟优化抗体分子的药效特性,通过免疫原性预测降低安全性风险等(详见第2.7节)。
2.4 2.2 靶点发现与验证
靶点发现与验证是抗体药物开发的起点,也是决定整个项目成败的关键环节。一个经过充分验证的高质量靶点是成功开发抗体药物的基础。
2.4.1 2.2.1 靶点发现策略
抗体药物的靶点通常是细胞表面受体、可溶性配体、膜结合酶等可被抗体分子接触到的蛋白质分子。靶点发现的主要策略包括[75,76]:
(1)基于基因组学和转录组学的策略
全基因组关联研究(Genome-Wide Association Study, GWAS)通过分析大规模人群队列的基因型与表型关联,识别与疾病显著相关的基因位点。将GWAS发现的遗传关联与蛋白质组学数据整合,可以揭示潜在的药物靶点。例如,PCSK9基因的功能缺失突变(Loss-of-Function Mutation)与低密度脂蛋白胆固醇水平降低及冠心病风险下降的关联,直接推动了抗PCSK9抗体(如Evolocumab和Alirocumab)的开发[77,78]。
单细胞转录组学(Single-Cell Transcriptomics)和空间转录组学(Spatial Transcriptomics)技术使研究者能够在单细胞分辨率和组织空间分辨率上解析基因表达模式,从而发现在特定细胞亚群或微环境中特异性高表达的潜在靶点[79]。
(2)基于蛋白质组学的策略
质谱分析技术(Mass Spectrometry)和蛋白质芯片(Protein Array)可以系统性地比较疾病组织与正常组织的蛋白质表达谱差异,识别差异表达蛋白。膜蛋白质组学(Membrane Proteomics)技术特别适用于发现抗体药物靶点,因为抗体药物主要作用于细胞表面或细胞外蛋白[80]。
(3)基于临床观察和文献挖掘的策略
临床实践中的观察(如某些自身免疫疾病患者在使用特定药物后出现意外改善)和系统性的文献挖掘(Literature Mining)也是重要的靶点发现途径。自然语言处理(Natural Language Processing, NLP)和知识图谱(Knowledge Graph)技术可以高效地从海量科学文献中提取靶点-疾病关联信息[81]。
(4)基于功能基因组学的策略
CRISPR筛选(CRISPR Screen)和RNA干扰筛选(RNAi Screen)等功能基因组学技术可以通过系统性地敲除或敲低基因来鉴定在特定生物学过程中发挥关键作用的靶点。高通量CRISPR筛选已成为发现肿瘤免疫治疗新靶点的重要工具[82]。
2.4.2 2.2.2 靶点验证方法
靶点发现后,需要通过多层次的验证实验来确认其在疾病中的功能角色及作为药物靶点的可行性。靶点验证通常采用以下方法[83]:
(1)遗传学验证
人类遗传学证据是最强有力的靶点验证依据。如果某个基因的功能获得性突变(Gain-of-Function Mutation)导致疾病,或功能缺失性突变对该基因功能的抑制与治疗获益相关,则该基因编码的蛋白质很可能是一个有效的药物靶点。研究表明,具有人类遗传学支持的药物靶点,其临床开发成功率是缺乏遗传学支持的靶点的约2倍[70,84]。
(2)体外功能验证
利用基因敲除(Knockout)、基因敲低(Knockdown)、基因过表达(Overexpression)等技术在细胞水平上验证靶点功能。同时可以使用工具抗体(Tool Antibody)或小分子抑制剂在细胞模型中验证靶点干预的功能效果。
(3)体内动物模型验证
在疾病动物模型中通过基因工程手段(如条件性基因敲除)或药理学手段(如中和抗体)验证靶点干预的治疗效果。需要注意的是,动物模型与人类疾病之间的转化性(Translatability)是一个需要审慎评估的关键问题[85]。
(4)临床数据验证
分析已有药物的临床数据,如果已有药物通过干预同一通路或相关通路显示出临床获益,则可以为靶点提供间接的临床验证。此外,生物标志物(Biomarker)研究也可以帮助建立靶点与疾病之间的因果关系。
2.4.3 2.2.3 靶点可成药性评估
对于抗体药物而言,靶点可成药性(Druggability)评估需要考虑以下几个维度[86]:
(1)靶点可及性(Accessibility):抗体分子因其较大的分子量(约150 kDa),通常只能作用于细胞外靶点,包括细胞表面受体的胞外结构域(Extracellular Domain, ECD)和可溶性配体。评估靶点蛋白的亚细胞定位和胞外结构域的暴露程度是可成药性评估的首要步骤。
(2)靶点表达谱(ExpressionProfile):理想的抗体药物靶点应在目标组织或细胞中高表达,而在正常组织中低表达或不表达,以确保治疗窗口(Therapeutic Window)足够宽。利用公共数据库(如Human Protein Atlas、GTEx)和临床样本的表达分析来评估靶点的组织表达分布。
(3)表位可用性(EpitopeAvailability):抗体需要结合到靶点蛋白上的特定表位(Epitope)才能发挥功能。评估靶点蛋白表面是否存在适合抗体结合的表位区域,以及这些表位是否在功能上具有重要性(如受体-配体结合界面),对于预测抗体的作用机制(Mechanism of Action, MoA)至关重要。计算方法(如分子动力学模拟和表位预测算法)在此环节发挥着日益重要的作用(详见第2.7节)。
(4)安全性考量:通过分析靶点在关键器官中的表达情况、靶点基因敲除动物的表型以及同一通路中其他靶点的药物安全性数据,初步评估靶点干预可能带来的安全性风险。
2.5 2.3 先导抗体的发现
先导抗体发现(Lead Antibody Discovery)是抗体药物开发流程中的核心环节,目标是获得能够特异性结合目标靶点并具有初步功能活性的抗体分子。目前主流的先导抗体发现技术包括杂交瘤技术、噬菌体展示技术、转基因动物平台、单B细胞技术和合成抗体库技术等[87]。
图2-3先导抗体发现技术平台分类。 先导抗体发现技术可分为体内免疫方法、体外筛选方法和计算设计方法三大类。各类方法产生的候选先导抗体最终都需要经过功能筛选与表征来确认其生物学活性和成药潜力。
2.5.1 2.3.1 杂交瘤技术
杂交瘤技术(Hybridoma Technology)由Georges Kohler和Cesar Milstein于1975年首创,是最经典的单克隆抗体制备方法[18]。其基本原理是将经抗原免疫的动物脾脏B细胞(可产生特异性抗体但寿命有限)与骨髓瘤细胞(Myeloma Cell,可无限增殖但不产生抗体)进行融合,形成既能无限增殖又能分泌特异性抗体的杂交瘤细胞。
技术流程:(1)用目标抗原免疫小鼠或大鼠,经过多次加强免疫后使动物产生强烈的免疫应答;(2)采集脾脏细胞,与骨髓瘤细胞在聚乙二醇(Polyethylene Glycol, PEG)或电融合条件下进行融合;(3)在HAT选择培养基(含次黄嘌呤Hypoxanthine、氨基蝶呤Aminopterin和胸苷Thymidine)中筛选杂交瘤细胞;(4)通过有限稀释法(Limiting Dilution)克隆化单个杂交瘤细胞株;(5)通过ELISA、流式细胞术等方法筛选出分泌目标特异性抗体的克隆。
优势:技术成熟,设备要求相对简单;通过体内免疫过程可利用天然免疫系统的亲和力成熟机制,获得的抗体通常具有较高的亲和力和特异性;抗体经历了体内的负向选择(Negative Selection),对自身抗原的反应性较低[88]。
局限性:获得的抗体为鼠源抗体,需要进行人源化改造后才能用于临床;融合效率有限,可能丢失一些有价值的抗体产生细胞;对于免疫耐受靶点(如高度保守的人鼠同源蛋白),免疫应答可能较弱;整个过程耗时较长,通常需要3-6个月。
2.5.2 2.3.2 噬菌体展示技术
噬菌体展示技术(Phage Display Technology)由George Smith于1985年首创,后经Sir Gregory Winter等人发展为抗体发现的强大工具[24,89]。该技术将抗体可变区基因(通常为单链可变区片段scFv或抗原结合片段Fab)与丝状噬菌体的外壳蛋白基因(如pIII或pVIII)融合表达,使抗体片段展示于噬菌体表面,从而实现基因型(Genotype)与表型(Phenotype)的物理连接。
技术流程:(1)构建抗体基因文库(Library),文库来源可以是免疫动物或人类B细胞的抗体基因(免疫文库)、未经免疫的健康个体B细胞基因(天然文库),或通过合成生物学方法构建的全合成文库;(2)将抗体文库转化至大肠杆菌,用辅助噬菌体(Helper Phage)救援产生展示抗体的噬菌体颗粒;(3)通过”淘洗”(Biopanning)过程进行亲和力筛选——将噬菌体文库与固定化或可溶性的靶抗原共孵育,洗去非特异性结合的噬菌体,回收特异性结合的噬菌体并感染大肠杆菌进行扩增;(4)经过3-5轮淘洗富集后,对输出的噬菌体克隆进行单克隆ELISA筛选和测序鉴定[90]。
优势:完全体外操作,不依赖动物免疫,适合对人源抗原的筛选;可以从天然文库或合成文库中直接获得全人源抗体(Fully Human Antibody),免去了人源化改造的步骤;文库多样性可达109-1011,覆盖广泛的抗体序列空间;筛选周期短,通常只需2-4周;可以通过设计特定的筛选策略(如竞争淘洗、差减淘洗)来定向富集具有特定功能特性的抗体[25]。
局限性:噬菌体表面展示的抗体片段可能与全长IgG的功能特性不完全一致;某些抗体片段在大肠杆菌中的折叠和展示效率较低;天然文库获得的抗体亲和力可能低于免疫文库,通常需要后续的亲和力成熟优化;筛选过程中可能存在偏好性选择(Selection Bias),导致某些有价值的抗体被遗漏。
2.5.3 2.3.3 转基因动物平台
转基因动物平台(Transgenic Animal Platform)通过基因工程手段将人类免疫球蛋白基因座(Immunoglobulin Locus)导入小鼠等动物的基因组中,同时灭活动物自身的免疫球蛋白基因,使其在免疫后能够直接产生全人源抗体[26]。
目前主要的转基因小鼠平台包括:
(1)XenoMouse:由Abgenix公司(后被Amgen收购)开发,包含大部分人类重链和轻链可变区基因片段。多款基于XenoMouse平台开发的抗体已获批上市,包括帕尼单抗(Panitumumab,抗EGFR)和地舒单抗(Denosumab,抗RANKL)[91]。
(2)HuMab-Mouse:由Medarex公司(后被Bristol-Myers Squibb收购)开发,同样包含人类免疫球蛋白基因座。伊匹单抗(Ipilimumab,抗CTLA-4)和纳武利尤单抗(Nivolumab,抗PD-1)等重磅抗体药物均基于此平台开发[26]。
(3)VelocImmune:由Regeneron公司开发,采用了独特的策略——仅替换小鼠免疫球蛋白可变区基因为人类对应基因,保留小鼠恒定区基因,从而确保B细胞在小鼠体内的正常发育和成熟。所获得的嵌合抗体经过可变区移植到人IgG恒定区即可获得全人源抗体。Dupilumab(抗IL-4Rα)等多个成功药物基于此平台开发[92]。
(4)OmniRat/OmniChicken:由Open Monoclonal Technology(现为Ligand Pharmaceuticals)开发的大鼠和鸡的转基因平台,可以产生带有人类可变区的抗体,进一步扩展了物种来源的多样性[93]。
优势:直接产生全人源或人源化抗体,无需后续人源化改造;利用体内免疫系统的亲和力成熟和负向选择机制,获得的抗体通常具有高亲和力、高特异性和良好的生物物理特性;抗体以天然的IgG形式产生,功能完整[94]。
局限性:平台构建成本高昂且受知识产权保护限制;对于与小鼠同源蛋白高度保守的人源靶点,仍然可能面临免疫耐受的问题;转基因小鼠的免疫库多样性可能低于正常小鼠或人类。
2.5.4 2.3.4 单B细胞技术
单B细胞技术(Single B Cell Technology)通过从免疫动物或人体中直接分离产生特异性抗体的单个B细胞,获取其抗体基因进行表达和功能鉴定[95]。
技术流程:(1)使用荧光标记的抗原探针(Antigen Probe),通过荧光激活细胞分选(Fluorescence-Activated Cell Sorting, FACS)或微流控芯片从外周血、淋巴组织等样本中分选出抗原特异性B细胞;(2)对单个B细胞进行逆转录和抗体可变区基因的巢式PCR(Nested PCR)扩增;(3)将扩增得到的重链和轻链可变区基因克隆至表达载体,进行重组表达和功能验证[96]。
近年来,基于微流控技术(Microfluidics)和液滴封装(Droplet Encapsulation)的高通量单B细胞分析平台大幅提升了筛选通量。例如,Beacon OptoFluidic系统和10x Genomics平台可以同时对数千至数万个单B细胞进行抗体基因测序和功能筛选[97,98]。
此外,从人体中分离抗体的策略也日益受到重视。从传染病康复患者或接种疫苗个体中分离抗原特异性记忆B细胞或浆细胞(Plasma Cell),可以获得经历了体内亲和力成熟的高亲和力人源抗体。这一策略在新冠病毒(SARS-CoV-2)中和抗体的快速发现中发挥了重要作用[99,100]。
优势:可以直接获得天然配对的重链和轻链序列,保留了抗体的原始配对信息;从人体中分离的抗体为全人源抗体,具有良好的安全性特征;可以挖掘稀有B细胞克隆中的独特抗体[101]。
局限性:对设备和技术要求较高;从外周血中分离抗原特异性B细胞的效率取决于免疫应答的强度;需要针对每个靶点制备高质量的荧光标记抗原探针。
2.5.5 2.3.5 合成抗体库技术
合成抗体库技术(Synthetic Antibody Library Technology)利用合成生物学和组合化学方法,通过理性设计构建多样化的抗体基因文库[102]。
与天然抗体文库不同,合成抗体库的设计基于对天然抗体库多样性的统计分析和对抗体结构-功能关系的深入理解。典型的设计策略包括:
(1)基于框架区的文库设计:选择一个或少数几个经过优化的框架区(Framework Region, FR)骨架,仅在CDR区域引入多样性。这种策略可以确保文库中的抗体具有良好的稳定性和可表达性。例如,基于Herceptin(曲妥珠单抗)骨架构建的合成文库已成功应用于多个靶点的抗体发现[103]。
(2)CDR多样性的理性设计:根据天然抗体CDR的氨基酸使用偏好和长度分布,通过混合碱基合成(如NNK、TRIM等密码子策略)或精确DNA合成技术引入定向多样性。近年来,基于机器学习的CDR序列设计方法可以更精准地模拟天然免疫库的多样性模式[104]。
(3)超大容量文库:利用核糖体展示(Ribosome Display)或mRNA展示(mRNA Display)等无细胞展示技术,可以构建容量达1012-1014的超大合成文库,远超噬菌体展示文库的典型容量[105]。
优势:文库设计完全可控,可以针对特定需求定制多样性;消除了对动物免疫的依赖;可以规避知识产权障碍;文库质量一致性好,可重复使用[106]。
局限性:文库设计的合理性高度依赖于对抗体结构-功能关系的理解水平;合成文库可能缺乏天然免疫过程中产生的某些独特结构特征;从头设计的抗体可能需要更多的后续优化工作。
2.6 2.4 抗体工程与优化
在获得初始的先导抗体后,通常需要经过系统的工程改造和优化,以提升其作为药物的各项关键属性,最终获得满足临床开发要求的候选药物分子(Clinical Candidate)[64]。
2.6.1 2.4.1 亲和力优化
亲和力(Affinity)是衡量抗体与抗原结合强度的关键参数,通常以解离常数K_D表征。对于大多数治疗性抗体,K_D值在纳摩尔(nM)到皮摩尔(pM)范围内是理想的[107]。需要指出的是,亲和力并非越高越好——超高亲和力可能导致抗体与靶点结合后难以解离,影响组织渗透和肿瘤穿透效率(“结合位点屏障效应”,Binding-Site Barrier Effect)[108]。
亲和力优化(Affinity Maturation)的主要策略包括:
(1)随机突变策略:通过易错PCR(Error-Prone PCR)、DNA改组(DNA Shuffling)或链交换(Chain Shuffling)在抗体可变区随机引入突变,构建突变文库后通过展示技术筛选高亲和力变体[109]。
(2)定点突变策略:基于抗体-抗原复合物的结构信息或计算模拟结果,在CDR的关键残基位点进行定点饱和突变(Site-Directed Saturation Mutagenesis),构建小型但高质量的突变文库进行筛选[110]。
(3)计算辅助策略:利用分子动力学模拟(Molecular Dynamics Simulation, MD)、自由能微扰计算(Free Energy Perturbation, FEP)和基于结构的设计(Structure-Based Design)等计算方法,预测能够提升亲和力的突变位点和氨基酸替换(详见第2.7节和第8章)[111,112]。近年来,基于深度学习的方法(如使用蛋白质语言模型进行突变效应预测)在亲和力优化中展现出巨大潜力[113]。
(4)热点区域丢饱和策略(Look-Through Mutagenesis, LTM):系统性地将CDR中每个位置替换为代表不同化学性质的约9种氨基酸,构建定义明确的小型文库,评估每个位置的氨基酸偏好,然后组合有益突变[114]。
2.6.2 2.4.2 特异性优化
特异性(Specificity)是指抗体仅与目标靶点结合而不与其他分子发生交叉反应(Cross-Reactivity)的能力。理想的治疗性抗体应具有高度的靶点特异性,以避免脱靶效应(Off-Target Effect)导致的安全性问题[115]。
特异性优化的关键策略包括:
(1)负向筛选:在亲和力筛选过程中加入负向筛选步骤,将候选抗体与非靶点蛋白质(包括靶点家族中的同源蛋白和人血浆/血清蛋白等)共孵育,去除与之结合的非特异性克隆[116]。
(2)多特异性试剂(Polyspecificity Reagent, PSR)检测:使用生物素化的CHO细胞裂解物、DNA、胰岛素等一组多特异性试剂,通过流式细胞术或ELISA检测抗体的非特异性结合倾向。多特异性评分(Polyspecificity Score)可以作为抗体可开发性的重要预测指标[117]。
(3)计算预测与优化:通过分析抗体表面的疏水补丁(Hydrophobic Patch)分布、电荷分布和分子动力学模拟中的非特异性相互作用,识别导致非特异性结合的结构特征并进行定向优化[53]。
2.6.3 2.4.3 稳定性与可开发性优化
可开发性(Developability)是指抗体分子从实验室规模向临床和商业化规模开发过程中的技术可行性,涵盖稳定性、溶解性、粘度、聚集倾向等多个药学属性[118]。
图2-4抗体可开发性评估指标与决策流程。 可开发性评估涵盖热稳定性、胶体稳定性、化学稳定性、溶解性、粘度、聚集倾向和免疫原性风险等多个维度。不满足标准的候选抗体需要经过工程优化后重新评估。
(1)热稳定性优化:抗体的热稳定性通常以熔解温度(Melting Temperature, T_m)表征。Fab区域的T_m通常是抗体整体稳定性的限速因素。通过引入稳定化突变(如改善VH/VL界面的疏水堆积、引入额外的二硫键、优化CDR的构象稳定性等)可以提升T_m值。计算方法如Rosetta ddG和FoldX可以预测突变对稳定性的影响[119]。
(2)聚集倾向优化:抗体聚集(Aggregation)是影响药品稳定性、安全性和生产工艺的关键问题。聚集倾向与抗体表面的疏水暴露区域(Aggregation-Prone Region, APR)密切相关。通过计算工具(如Zyggregator、TANGO、CamSol)可以预测APR并指导优化突变的设计[120,121]。
(3)化学稳定性优化:CDR区域中容易发生化学修饰的”热点”残基,如天冬酰胺(Asn)脱酰胺位点(特别是NG、NS、NT等序列模体)和甲硫氨酸(Met)/色氨酸(Trp)氧化位点,需要在早期通过点突变加以消除[122]。
(4)高浓度制剂相关优化:皮下注射(Subcutaneous Injection)给药要求抗体在高浓度(通常>100 mg/mL)下仍具有可接受的粘度(通常<20 cP)和溶解度。高粘度通常与抗体分子间的可逆自结合(Reversible Self-Association, RSA)有关,可以通过优化抗体表面的电荷分布来改善[123,124]。
(5)人源化(Humanization):对于来源于小鼠杂交瘤的鼠源抗体,人源化改造是将其开发为人用药物的必要步骤。经典的CDR移植方法(CDR Grafting)将鼠源抗体的CDR区域移植到人源框架区骨架上[23,125]。然而,简单的CDR移植往往导致亲和力下降,需要通过回复突变(Back Mutation)恢复某些关键的框架区残基。计算方法(如同源建模和分子动力学模拟)可以辅助识别这些关键的回复突变位点(详见第9章)[126]。
2.6.4 2.4.4 效应功能工程
抗体的效应功能(Effector Function)主要由Fc区域介导,包括抗体依赖性细胞介导的细胞毒性作用(Antibody-Dependent Cell-Mediated Cytotoxicity, ADCC)、补体依赖性细胞毒性作用(Complement-Dependent Cytotoxicity, CDC)和抗体依赖性细胞吞噬作用(Antibody-Dependent Cellular Phagocytosis, ADCP)等[127]。
根据不同的治疗目标,需要对效应功能进行定向工程改造:
(1)增强效应功能:对于需要依赖ADCC或CDC机制清除靶细胞的抗体(如抗肿瘤抗体),可以通过Fc区域突变(如S239D/I332E双突变增强与FcγRIIIa的结合)或糖基化工程(如去除核心岩藻糖修饰,即无岩藻糖化Afucosylation)来增强效应功能[128,129]。
(2)消除效应功能:对于仅需发挥靶点阻断或中和作用而不需要杀伤靶细胞的抗体(如中和抗体),需要通过Fc区域突变(如L234A/L235A”LALA”突变或引入IgG4的铰链区序列)消除或减弱效应功能,以避免不必要的靶细胞杀伤[130]。
(3)半衰期调节:通过引入Fc区域的YTE突变(M252Y/S254T/T256E)或LS突变(M428L/N434S),增强抗体与新生儿Fc受体(Neonatal Fc Receptor, FcRn)在酸性条件下的结合,从而延长抗体在体内的半衰期(详见第1章1.3节)[131,DallAcqua2006?]。
2.7 2.5 临床前研究
临床前研究(Preclinical Studies)是抗体药物从实验室走向临床的关键过渡阶段,其目的是全面评估候选抗体的药效学(Pharmacodynamics, PD)、药代动力学(Pharmacokinetics, PK)和安全性特征,为临床试验的方案设计和首次人体剂量(First-in-Human Dose, FIH Dose)的确定提供依据[132]。
图2-8临床前研究的核心内容与决策流程。 临床前研究包括体外药效评价、药代动力学研究和安全性评价三大模块。各模块的评价结果综合决定候选抗体是否可以进入临床试验。SPR, Surface Plasmon Resonance; BLI, Bio-Layer Interferometry; HDX-MS, Hydrogen-Deuterium Exchange Mass Spectrometry; TMDD, Target-Mediated Drug Disposition; ADA, Anti-Drug Antibody; CRS, Cytokine Release Syndrome; FIH, First-in-Human; IND, Investigational New Drug。
2.7.1 2.5.1 体外药效评价
体外药效评价(In Vitro Efficacy Evaluation)旨在全面表征候选抗体的生物学活性和作用机制:
(1)靶点结合特征:通过表面等离子体共振(Surface Plasmon Resonance, SPR,如Biacore系统)和生物膜层干涉技术(Bio-Layer Interferometry, BLI,如Octet系统)定量测定抗体与靶点的结合动力学参数(结合速率常数k_on、解离速率常数k_off和平衡解离常数K_D)[133]。
(2)表位鉴定:通过竞争结合实验(Epitope Binning)确定抗体的表位分类(Epitope Bin)。进一步通过氢氘交换质谱(Hydrogen-Deuterium Exchange Mass Spectrometry, HDX-MS)、交联质谱(Cross-linking Mass Spectrometry, XL-MS)或X射线晶体学(X-ray Crystallography)精确解析抗体-抗原复合物的结构和表位信息[134]。
(3)功能活性检测:根据抗体的预期作用机制设计相应的功能活性检测方法。对于受体阻断型抗体,检测其抑制配体-受体结合和下游信号通路的能力;对于细胞杀伤型抗体,检测其ADCC、CDC和ADCP活性;对于激动型抗体(Agonistic Antibody),检测其激活受体信号的能力[135]。
(4)交叉反应性:评价候选抗体与相关物种(如食蟹猴)靶点的交叉反应性,这对于后续毒理学动物种属的选择至关重要。
2.7.2 2.5.2 药代动力学研究
药代动力学研究(Pharmacokinetic Studies)评估抗体在体内的吸收、分布、代谢和排泄(ADME)特征:
(1)血浆PK参数:通过在相关动物种属(通常为食蟹猴Cynomolgus Monkey)中进行单次给药和多次给药PK研究,获取关键的PK参数,包括曲线下面积(Area Under the Curve, AUC)、最大血浆浓度(C_max)、清除率(Clearance, CL)、分布容积(Volume of Distribution, V_d)和半衰期(Half-life, t₁/₂)[136]。
(2)靶点介导的药物处置(Target-Mediated Drug Disposition, TMDD):当抗体与高表达的靶点结合后被内化降解时,会出现非线性PK特征。TMDD模型可以更准确地描述这种复杂的PK行为,并帮助预测人体PK和剂量选择[137]。
(3)免疫原性评价:检测动物体内是否产生了抗药抗体(ADA),以及ADA对药物暴露量和药效的影响。需要注意的是,动物中的ADA检测结果不能直接预测人体中的免疫原性风险[138]。
(4)PK/PD建模:建立数学模型将药物暴露量(PK)与药理效应(PD)关联起来,预测达到目标药理效应所需的有效剂量和给药方案[139]。
2.7.3 2.5.3 安全性评价
安全性评价(Safety Assessment)是临床前研究中至关重要的环节,直接决定候选抗体是否可以进入临床试验[140]。
(1)毒理学种属选择:根据ICH S6(R1)指南,毒理学研究应在药理学相关物种(Pharmacologically Relevant Species)中进行,即抗体与该物种靶点具有交叉反应性、且靶点在该物种中的组织分布和功能与人类相似。食蟹猴是最常用的毒理学种属。当抗体与非人灵长类靶点无交叉反应性时,可以考虑使用转基因动物模型或替代抗体(Surrogate Antibody)[141]。
(2)重复给药毒性研究(Repeat-Dose Toxicity Study):在药理学相关物种中进行至少4周的重复给药毒性研究(支持首次临床试验),评估毒性靶器官、毒性程度和可逆性,确定未见明显毒性反应剂量水平(No-Observed-Adverse-Effect Level, NOAEL)[142]。
(3)组织交叉反应性研究(Tissue Cross-Reactivity, TCR):利用免疫组织化学方法评价候选抗体与正常人体组织(通常包括一组32种以上的正常组织)的结合情况,识别潜在的非预期靶点外结合和相关的安全性风险。
(4)细胞因子释放综合征(Cytokine Release Syndrome, CRS)风险评估:通过体外全血或PBMC刺激实验评估抗体引发CRS的风险,特别是对于靶向免疫细胞或具有免疫激活功能的抗体。TGN1412事件(一种抗CD28超级激动型抗体在I期临床试验中导致严重CRS)突显了此项评估的重要性[143]。
(5)首次人体剂量推算:基于毒理学研究的NOAEL或最小预期生物学效应剂量水平(Minimum Anticipated Biological Effect Level, MABEL),结合安全系数推算首次人体给药剂量[144]。
2.8 2.6 临床开发与上市
2.8.1 2.6.1 临床试验设计
抗体药物的临床开发遵循标准的三期临床试验框架,但在试验设计上有一些特殊考量[145]。
图2-5抗体药物临床开发阶段及各阶段通过率。 从IND申报到上市的全过程。虚线标注了各阶段的典型通过率,反映了临床开发过程中层层筛选的特征。IND, Investigational New Drug; BLA, Biologics License Application; NDA, New Drug Application。
I期临床试验(PhaseI)
I期试验的主要目标是评价安全性和耐受性、确定最大耐受剂量(Maximum Tolerated Dose, MTD)或推荐II期剂量(Recommended Phase 2 Dose, RP2D),以及获取人体PK数据。
对于肿瘤领域的抗体药物,I期试验通常在晚期肿瘤患者中进行,采用剂量递增设计(如3+3设计或加速滴定设计)。对于非肿瘤领域的抗体药物(如自身免疫疾病),I期试验可以在健康志愿者中进行,采用单次递增剂量(Single Ascending Dose, SAD)和多次递增剂量(Multiple Ascending Dose, MAD)设计[146]。
II期临床试验(PhaseII)
II期试验的目标是初步评价疗效和确定最佳给药方案。II期试验通常分为IIa期(概念验证,Proof of Concept, PoC)和IIb期(剂量探索,Dose-Finding)两个子阶段。
生物标志物驱动的患者分层(Biomarker-Driven Patient Stratification)在II期试验中越来越受到重视。通过伴随诊断(Companion Diagnostics)识别最可能从治疗中获益的患者亚群,可以显著提高试验的成功率和效率[147]。
III期临床试验(PhaseIII)
III期试验是确证性试验(Confirmatory Trial),通常为随机、双盲、对照试验(Randomized, Double-Blind, Controlled Trial),样本量较大(数百至数千名患者),旨在充分证明药物的疗效和安全性,为上市审批提供关键数据[148]。
近年来,以下创新性的临床试验设计策略受到越来越多的关注:
·适应性设计(AdaptiveDesign):允许在试验进行过程中根据中期分析结果调整试验设计(如样本量、剂量、研究终点等),提高试验效率[149]。
·篮式试验(BasketTrial):同一种抗体药物针对具有相同生物标志物但不同肿瘤类型的多个患者队列同时进行评价。
·伞式试验(UmbrellaTrial):同一种疾病的患者按不同的生物标志物分层,分别接受不同的靶向治疗。
·平台试验(PlatformTrial):在一个共享的基础设施和对照组下,同时评价多种药物或药物组合。
2.8.2 2.6.2 生物类似药开发
随着越来越多的原研抗体药物(Reference Product)专利到期,生物类似药(Biosimilar)开发已成为抗体药物领域的重要赛道。生物类似药是指在质量、安全性和有效性方面与已获批的参照药品高度相似的生物药品[150]。
生物类似药的开发路径与原研药有本质不同,遵循”逐步递进”(Stepwise Approach)的原则:
(1)分析相似性研究(AnalyticalSimilarity):是生物类似药开发的基础和核心。需要对候选生物类似药与参照药品进行全面的分析比较,包括一级结构(氨基酸序列)、高级结构(二级/三级/四级结构)、翻译后修饰(如糖基化谱)、纯度和杂质(如聚集体、片段)、生物活性等多个维度。
(2)功能相似性研究:评价候选生物类似药与参照药品在体外功能活性(如靶点结合、效应功能、信号通路调控等)方面的相似性。
(3)临床药理学研究:通常需要进行比较PK研究和(在适当的情况下)比较PD研究,证明候选生物类似药与参照药品的PK/PD相似性。
(4)临床疗效和安全性比较研究:在与参照药品的头对头比较试验中证明临床疗效和安全性的相似性。样本量通常远小于原研药的III期试验[151]。
计算方法在生物类似药的分析相似性研究中也开始发挥作用,例如利用分子动力学模拟比较候选生物类似药与参照药品的高级结构和动态行为差异。
2.8.3 2.6.3 监管审批要点
抗体药物作为生物制品(Biological Product),其监管审批框架与小分子化学药物有所不同[152]。
(1)美国FDA审批路径:原研抗体药物通过《公共卫生服务法》第351(a)条途径申报生物制品许可申请(Biologics License Application, BLA)。生物类似药则通过第351(k)条途径申报,需要证明与参照药品的生物相似性(Biosimilarity)。如果进一步证明可互换性(Interchangeability),则可以在不经处方医师同意的情况下替代原研药品。
(2)欧盟EMA审批路径:欧盟通过集中审批程序(Centralised Procedure)审评抗体药物。EMA是全球最早建立生物类似药监管框架的机构之一,已积累了丰富的审评经验。
(3)中国NMPA审批路径:中国国家药品监督管理局(NMPA)近年来大幅加速了创新生物药的审评审批速度。2020年实施的《药品注册管理办法》引入了突破性治疗药物程序(Breakthrough Therapy Designation)和附条件批准(Conditional Approval)等加速通道[153]。
(4)关键监管考量:
·生产工艺的一致性:生物制品具有”过程决定产品”(The Process Is the Product)的特点。生产工艺的任何变更都需要通过可比性研究(Comparability Study)证明变更前后产品质量的一致性。
·免疫原性评价:监管机构要求在临床试验中系统性地评价和报告抗药抗体的发生率及其对PK和疗效的影响。
·上市后监测(Post-marketingSurveillance):包括上市后安全性监测(Pharmacovigilance)和上市后研究/临床试验等
2.9 2.7 计算方法在开发流程中的应用
计算方法(Computational Methods)正在深刻地改变抗体药物的开发范式,从传统的以实验试错为主导的模式,逐步向计算驱动、实验验证的新模式转变[47,154]。
2.9.1 2.7.1 各阶段的计算辅助工具
图2-6计算方法在抗体药物开发各阶段的应用全景图。 计算方法贯穿抗体药物开发的全流程,从靶点发现阶段的知识挖掘到生产质量阶段的工艺优化,每个阶段都有相应的计算工具和方法。FEP, Free Energy Perturbation; ML, Machine Learning; PK/PD, Pharmacokinetics/Pharmacodynamics。
下面对各阶段的关键计算工具进行简要介绍(更详细的内容将在后续各专题章节中展开):
(1)靶点发现与验证阶段
·知识图谱与文本挖掘:利用自然语言处理技术从科学文献和公共数据库中自动提取靶点-疾病-药物关联信息,构建生物医学知识图谱,辅助靶点优先级排序[81]。
·靶点蛋白结构预测:利用AlphaFold2等蛋白质结构预测工具获取靶点蛋白的三维结构,评估其表面可被抗体结合的表位区域[50]。
·表位预测:利用序列和结构信息预测靶点蛋白上的B细胞表位,指导抗原设计和抗体筛选策略[155]。
(2)先导抗体发现阶段
·抗体结构预测:IgFold、ABodyBuilder2、ImmuneBuilder等专门针对抗体的结构预测工具可以快速获取抗体的三维结构,特别是CDR环的构象[51,52]。
·抗体-抗原对接:HDOCK、ClusPro、HADDOCK等分子对接工具可以预测抗体-抗原复合物的结合模式,辅助表位-互补位分析[156]。
·从头设计(De Novo Design):基于深度生成模型(如RFdiffusion、DiffAb)的抗体从头设计方法,可以生成全新的抗体序列,直接绕过传统的免疫或展示筛选过程[60,61]。这一领域正处于快速发展中,有望在未来几年实现突破性进展(详见第12章)。
(3)抗体优化阶段
·亲和力预测与优化:自由能微扰(FEP)计算和基于机器学习的突变效应预测模型(如mCSM-AB、DDGun等)可以预测突变对抗体-抗原结合亲和力的影响,指导亲和力优化实验设计[111,157]。
·人源化设计辅助:计算方法可以辅助选择最佳的人源框架区模板、识别关键的回复突变位点、并预测人源化变体的结构和功能特性[126]。
·可开发性预测:基于序列和结构特征的机器学习模型可以预测抗体的聚集倾向、溶解度、粘度、化学稳定性等可开发性属性,实现在早期研发阶段对候选抗体进行全面的可开发性筛选[53,117]。
·免疫原性预测:T细胞表位预测工具(如NetMHCIIpan、IEDB)可以评估抗体序列中潜在的T细胞表位,预测免疫原性风险,指导去免疫原化(Deimmunization)设计[158]。
(4)临床前与临床开发阶段
·PK/PD建模与模拟(Modeling and Simulation, M&S):群体药代动力学(Population PK)建模和生理药代动力学(Physiologically-Based Pharmacokinetic, PBPK)建模可以预测抗体在人体中的PK行为,优化给药方案设计[159]。
·临床试验模拟:基于PK/PD模型和疾病模型的临床试验模拟可以帮助优化试验设计参数(如剂量、给药间隔、样本量、研究终点等),提高试验成功概率[160]。
2.9.2 2.7.2 计算驱动的药物开发范式
图2-7传统开发范式与计算驱动开发范式的对比。 传统范式依赖于大量的实验试错和多轮迭代,耗时较长。计算驱动范式通过计算预测和虚拟筛选大幅缩小实验搜索空间,实验数据反馈用于持续优化计算模型,形成计算-实验闭环,显著提升开发效率。
传统的抗体药物开发范式以实验驱动为主,依赖于大规模的实验筛选和反复的试错优化。这种模式虽然已取得了巨大成功(已有100多个抗体药物获批上市),但在效率、成本和成功率方面仍有很大的提升空间。
计算驱动的药物开发范式(Computation-Driven Drug Discovery Paradigm)代表了未来抗体药物开发的重要方向[154]。这一范式的核心理念是:
(1)设计先行(DesignFirst):在进入实验之前,先通过计算方法对候选分子进行大规模的虚拟评估和优先级排序,显著缩小需要实验验证的搜索空间。例如,利用深度学习模型从数十亿个虚拟抗体序列中筛选出数千个最可能具有高亲和力和良好可开发性的候选序列进行实验验证。
(2)主动学习(ActiveLearning):采用主动学习策略(Active Learning Strategy),在每一轮实验后将结果反馈至计算模型进行更新,使模型在迭代过程中不断提升预测精度。这种计算-实验闭环(Computational-Experimental Loop)可以在最少的实验次数内找到最优解[161]。
(3)多目标优化(Multi-ObjectiveOptimization):抗体药物开发需要同时优化多个相互制约的属性(如亲和力、特异性、稳定性、溶解度等)。计算方法可以在多维属性空间中进行帕累托优化(Pareto Optimization),识别属性平衡最优的候选分子[162]。
(4)数据整合与知识积累:通过系统性地整合实验数据和计算结果,构建机构性的抗体知识库(Antibody Knowledge Base),使得在后续项目中能够复用先前积累的知识和经验,实现组织层面的学习和进步。
需要指出的是,当前的计算方法仍然存在显著的局限性。抗体-抗原相互作用的复杂性、CDR环构象的柔性和多样性、以及体内环境的复杂性等因素,使得纯粹的计算设计尚无法完全替代实验筛选和验证。然而,计算方法作为强有力的辅助工具,已经在提高开发效率、降低开发成本和缩短开发周期方面展现出切实的价值。随着算法的持续进步、训练数据的不断积累以及计算资源的日益丰富,计算方法在抗体药物开发中的角色将从”辅助”逐步提升为”驱动”(详见第12章和第13章)[54]。
2.10 本章小结
本章系统性地介绍了抗体药物从靶点发现到上市销售的完整开发流程。主要内容可以归纳为以下几个要点:
1.抗体药物开发是一个漫长而复杂的系统工程,从靶点发现到获批上市通常需要10-15年,总投入成本在10-30亿美元之间。整个开发过程可分为靶点发现与验证、先导抗体发现、抗体工程与优化、临床前研究、临床试验和审批上市六个主要阶段。
2.靶点发现与验证是开发成功的基石。基因组学、蛋白质组学、功能基因组学等多种策略可用于发现潜在靶点,而遗传学验证、体外功能验证和体内动物模型验证则用于确认靶点的有效性。具有人类遗传学支持的靶点具有更高的临床开发成功率。
3.先导抗体发现技术呈现多元化发展态势。杂交瘤技术、噬菌体展示技术、转基因动物平台和单B细胞技术各有优势和适用场景。合成抗体库和计算设计方法为先导抗体发现提供了新的途径。
4.抗体工程与优化是将先导抗体转化为候选药物的关键环节。亲和力优化、特异性优化、稳定性与可开发性优化以及效应功能工程等策略共同确保候选分子具备满足临床要求的药学属性。
5.临床前研究为临床试验的安全开展提供了科学依据。全面的药效学、药代动力学和安全性评价,以及合理的首次人体剂量推算,是确保患者安全的必要前提。
6.临床试验设计正在向更灵活、更高效的方向发展。适应性设计、篮式试验、伞式试验等创新设计策略提高了临床开发的效率和成功率。
7.计算方法正在深刻改变抗体药物开发的范式。从靶点发现阶段的知识挖掘到生产阶段的工艺优化,计算方法在每个环节都展现出了提升效率和降低风险的价值。计算驱动的药物开发范式代表了未来的重要发展方向。
2.11 思考题
1. 在选择先导抗体发现技术时,应综合考虑哪些因素?请比较杂交瘤技术与噬菌体展示技术在抗体发现中的优缺点,并讨论在何种情况下应优先选择哪种技术。
2. 为什么”具有人类遗传学支持的药物靶点具有更高的临床成功率”?请从生物学机制的角度进行分析,并举出一个具体的成功案例。
3. 抗体的可开发性评估包含哪些主要维度?如果一个候选抗体具有优异的亲和力但聚集倾向较高,应如何进行优化?
4. 比较传统开发范式与计算驱动开发范式的核心差异。计算方法在哪些环节最有可能实现突破性的效率提升?目前计算方法面临的主要瓶颈是什么?
5. 生物类似药的开发路径与原研药有何本质区别?分析相似性研究在生物类似药开发中处于什么地位?计算方法如何辅助分析相似性评估?
6. 设想你负责开发一款靶向某新发现肿瘤表面抗原的治疗性抗体,请设计一个完整的开发策略,说明在每个关键决策节点如何利用计算方法提高决策质量和开发效率。
2.12 推荐阅读与资源
2.12.1 综述文章
· Carter PJ, Lazar GA. Next generation antibody drugs: pursuit of the “high-hanging fruit”. Nature Reviews Drug Discovery, 2018, 17(3): 197-223. 全面综述了抗体药物工程技术的最新进展。
· Kaplon H, et al. Antibodies to watch in 2024. mAbs, 2024, 16(1): 2297450. 每年更新一次的抗体药物管线综述,是了解行业动态的重要参考。
· Lu RM, et al. Development of therapeutic antibodies for the treatment of diseases. Journal of Biomedical Science, 2020, 27: 1. 治疗性抗体开发的系统综述。
2.12.2 教科书
· Strohl WR, Strohl LM. Therapeutic Antibody Engineering. Woodhead Publishing, 2012. 抗体工程领域的经典教科书。
· Dubel S, Reichert JM. Handbook of Therapeutic Antibodies. 2nd edition, Wiley-VCH, 2014. 治疗性抗体的全面参考手册。
2.12.3 在线资源
· The Antibody Society (https://www.antibodysociety.org/): 国际抗体学会网站,提供抗体药物审批动态和行业分析报告。
· IMGT数据库 (https://www.imgt.org/): 免疫球蛋白基因和序列的权威数据库。
· Thera-SAbDab (http://opig.stats.ox.ac.uk/webapps/therasabdab/): 治疗性抗体结构数据库,收录了所有已获批抗体的序列和结构信息。
2.12.4 计算工具
· AlphaFold2/AlphaFold-Multimer: 蛋白质结构预测,可用于抗体-抗原复合物结构预测。
· IgFold/ABodyBuilder2: 专门针对抗体的结构预测工具。
· TAP (Therapeutic Antibody Profiler): Oxford大学开发的抗体可开发性在线评估工具。
2.13 参考文献
[134] Abbott WM, Damschroder MM, Lowe DC. Current approaches to fine mapping of antigen-antibody interactions. Immunology, 2014, 142(4): 526-535.
[51] Abanades B, et al. ImmuneBuilder: Deep-learning models for predicting the structures of immune proteins. Communications Biology, 2023, 6: 575.
[108] Adams GP, et al. High affinity restricts the localization and tumor penetration of single-chain Fv antibody molecules. Cancer Research, 2001, 61(12): 4750-4755.
[154] Akbar R, et al. Progress and challenges for the machine learning-based design of fit-for-purpose monoclonal antibodies. mAbs, 2022, 14(1): 2008790.
[126] Almagro JC, Fransson J. Humanization of antibodies. Frontiers in Bioscience, 2008, 13: 1619-1633.
[115] Avery LB, et al. Establishing in vitro in vivo correlations to screen monoclonal antibodies for physicochemical properties related to favorable human pharmacokinetics. mAbs, 2018, 10(2): 244-255.
[145] Baldo BA. Adverse Drug Reactions, Springer, 2016.
[80] Bausch-Fluck D, et al. The in silico human surfaceome. Proceedings of the National Academy of Sciences, 2018, 115(46): E10988-E10997.
[90] Bradbury AR, et al. Beyond natural antibodies: the power of in vitro display technologies. Nature Biotechnology, 2011, 29(3): 245-254.
[94] Brueggemann M, et al. Human antibody production in transgenic animals. Archivum Immunologiae et Therapiae Experimentalis, 2015, 63: 101-108.
[86] Bull SC, Doig AJ. Properties of protein drug target classes. PLoS One, 2015, 10(3): e0117955.
[142] Bussiere JL. Species selection considerations for preclinical toxicology studies for biotherapeutics. Expert Opinion on Drug Metabolism & Toxicology, 2009, 5(12): 1537-1549.
[99] Cao Y, et al. Potent neutralizing antibodies against SARS-CoV-2 identified by high-throughput single-cell sequencing of convalescent patients’ B cells. Cell, 2020, 182(1): 73-84.
[64] Carter PJ, Lazar GA. Next generation antibody drugs: pursuit of the “high-hanging fruit”. Nature Reviews Drug Discovery, 2018, 17(3): 197-223.
[141] Chapman K, et al. Preclinical development of monoclonal antibodies. mAbs, 2012, 4(5): 586-595.
[121] Chennamsetty N, et al. Design of therapeutic proteins with enhanced stability. Proceedings of the National Academy of Sciences, 2009, 106(29): 11937-11942.
[93] Ching KH, et al. Chicken immunoglobulin genes and antibody development. In: Antibody Engineering, Springer, 2018.
[149] Chow SC, Chang M. Adaptive design methods in clinical trials — a review. Orphanet Journal of Rare Diseases, 2008, 3: 11.
[109] Chowdhury PS, Wu H. Tailor-made antibody therapeutics. Methods, 1999, 36: 11-24.
[111] Clark LA, et al. Affinity enhancement of an in vivo matured therapeutic antibody using structure-based computational design. Protein Science, 2006, 15(5): 949-960.
[77] Cohen JC, et al. Sequence variations in PCSK9, low LDL, and protection against coronary heart disease. New England Journal of Medicine, 2006, 354(12): 1264-1272.
[DallAcqua2006?] Dall’Acqua WF, et al. Properties of human IgG1s engineered for enhanced binding to the neonatal Fc receptor (FcRn). Journal of Biological Chemistry, 2006, 281(33): 23514-23524.
[66] DiMasi JA, Grabowski HG, Hansen RW. Innovation in the pharmaceutical industry: new estimates of R&D costs. Journal of Health Economics, 2016, 47: 20-33.
[72] Dingman R, Bhatt DK. Immunogenicity of therapeutic proteins. In: Immunogenicity of Biopharmaceuticals, Springer, 2019.
[116] Dobson CL, et al. Engineering the surface properties of a human monoclonal antibody prevents self-association and rapid clearance in vivo. Scientific Reports, 2016, 6: 38644.
[73] Dostalek M, et al. Pharmacokinetics, pharmacodynamics, and physiologically-based pharmacokinetic modelling of monoclonal antibodies. Clinical Pharmacokinetics, 2013, 52(2): 83-124.
[139] Dua P, et al. A tutorial on target-mediated drug disposition (TMDD) models. CPT: Pharmacometrics & Systems Pharmacology, 2015, 4(6): 324-337.
[75] Finan C, et al. The druggable genome and support for target identification and validation in drug development. Science Translational Medicine, 2017, 9(383): eaag1166.
[25] Frenzel A, Schirrmann T, Hust M. Phage display-derived human antibodies in clinical development and therapy. mAbs, 2016, 8(7): 1177-1194.
[83] Gashaw I, et al. What makes a good drug target? Drug Discovery Today, 2011, 16(23-24): 1037-1043.
[97] Goldstein LD, et al. Massively parallel single-cell B-cell receptor sequencing enables rapid discovery of diverse antigen-reactive antibodies. Communications Biology, 2019, 2: 304.
[54] Graves J, et al. A review of deep learning methods for antibodies. Antibodies, 2020, 9(2): 12.
[105] Hanes J, Pluckthun A. In vitro selection and evolution of functional proteins by using ribosome display. Proceedings of the National Academy of Sciences, 1997, 94(10): 4937-4942.
[71] Harrison RK. Phase II and phase III failures: 2013-2015. Nature Reviews Drug Discovery, 2016, 15(12): 817-818.
[68] Hay M, et al. Clinical development success rates for investigational drugs. Nature Biotechnology, 2014, 32(1): 40-51.
[113] Hie BL, et al. Efficient evolution of human antibodies from general protein language models. Nature Biotechnology, 2024, 42: 275-283.
[160] Holford N, et al. Clinical trial simulation: a review. Clinical Pharmacology & Therapeutics, 2010, 88(2): 166-182.
[148] ICH E9 guideline. Statistical principles for clinical trials. 1998.
[132] ICH M3(R2) guideline. Nonclinical safety studies for the conduct of human clinical trials for pharmaceuticals. 2009.
[140] ICH S6(R1) guideline. Preclinical safety evaluation of biotechnology-derived pharmaceuticals. 2011.
[117] Jain T, et al. Biophysical properties of the clinical-stage antibody landscape. Proceedings of the National Academy of Sciences, 2017, 114(5): 944-949.
[91] Jakobovits A, et al. From XenoMouse technology to panitumumab, the first fully human antibody product from transgenic mice. Nature Biotechnology, 2007, 25(10): 1134-1143.
[118] Jarasch A, et al. Developability assessment during the selection of novel therapeutic antibodies. Journal of Pharmaceutical Sciences, 2015, 104(6): 1885-1898.
[158] Jensen KK, et al. Improved methods for predicting peptide binding affinity to MHC class II molecules. Immunology, 2018, 154(3): 394-406.
[155] Jespersen MC, et al. BepiPred-2.0: improving sequence-based B-cell epitope prediction using conformational epitopes. Nucleic Acids Research, 2017, 45(W1): W24-W29.
[23] Jones PT, et al. Replacing the complementarity-determining regions in a human antibody with those from a mouse. Nature, 1986, 321: 522-525.
[50] Jumper J, et al. Highly accurate protein structure prediction with AlphaFold. Nature, 2021, 596: 583-589.
[65] Kaplon H, et al. Antibodies to watch in 2024. mAbs, 2024, 16(1): 2297450.
[133] Karlsson R, Falt A. Experimental design for kinetic analysis of protein-protein interactions with surface plasmon resonance biosensors. Journal of Immunological Methods, 2006, 200(1-2): 121-133.
[84] King EA, Davis JW, Bhagat JF. Are drug targets with genetic support twice as likely to be approved? Revised estimates of the impact of genetic support for drug mechanisms on the probability of drug approval. PLoS Genetics, 2019, 15(12): e1008489.
[18] Kohler G, Milstein C. Continuous cultures of fused cells secreting antibody of predefined specificity. Nature, 1975, 256: 495-497.
[96] Lanzavecchia A, et al. Human monoclonal antibodies by immortalization of memory B cells. Current Opinion in Biotechnology, 2007, 18(6): 523-528.
[128] Lazar GA, et al. Engineered antibody Fc variants with enhanced effector function. Proceedings of the National Academy of Sciences, 2006, 103(11): 4005-4010.
[103] Lee CV, et al. High-affinity human antibodies from phage-displayed synthetic Fab libraries with a single framework scaffold. Journal of Molecular Biology, 2004, 340(5): 1073-1093.
[110] Lippow SM, Wittrup KD, Tidor B. Computational design of antibody-affinity improvement beyond in vivo maturation. Nature Biotechnology, 2007, 25(10): 1171-1176.
[26] Lonberg N. Human antibodies from transgenic animals. Nature Biotechnology, 2005, 23(9): 1117-1125.
[122] Lu X, et al. Deamidation and isomerization liability analysis of 131 clinical-stage antibodies. mAbs, 2019, 11(1): 45-57.
[87] Lu RM, et al. Development of therapeutic antibodies for the treatment of diseases. Journal of Biomedical Science, 2020, 27: 1.
[61] Luo S, et al. Antigen-specific antibody design and optimization with diffusion-based generative models for protein structures. Advances in Neural Information Processing Systems, 2022.
[137] Mager DE, Jusko WJ. General pharmacokinetic model for drugs exhibiting target-mediated drug disposition. Journal of Pharmacokinetics and Pharmacodynamics, 2001, 28(6): 507-532.
[85] Mak IW, Evaniew N, Ghert M. Lost in translation: animal models and clinical trials in cancer treatment. American Journal of Translational Research, 2014, 6(2): 114-118.
[151] Markus R, et al. Developing the totality of evidence for biosimilars: regulatory considerations and building confidence for the healthcare community. BioDrugs, 2017, 31: 175-187.
[162] Mason DM, et al. Optimization of therapeutic antibodies by predicting antigen specificity from antibody sequence via deep learning. Nature Biomedical Engineering, 2021, 5: 600-612.
[24] McCafferty J, et al. Phage antibodies: filamentous phage displaying antibody variable domains. Nature, 1990, 348: 552-554.
[88] Mitra S, Bhattacharyya R. Strategies to generate phage and non-phage display antibodies. In Vitro Cellular & Developmental Biology-Animal, 2012, 48(5): 268-286.
[144] Muller PY, et al. Safety assessment of biopharmaceuticals — the concept of MABEL. Current Opinion in Drug Discovery & Development, 2009, 12(1): 59-72.
[92] Murphy AJ, et al. Mice with megabase humanization of their immunoglobulin genes generate antibodies as efficiently as normal mice. Proceedings of the National Academy of Sciences, 2014, 111(14): 5153-5158.
[70] Nelson MR, et al. The support of human genetic evidence for approved drug indications. Nature Genetics, 2015, 47(8): 856-860.
[127] Nimmerjahn F, Ravetch JV. Divergent immunoglobulin G subclass activity through selective Fc receptor binding. Science, 2005, 310(5753): 1510-1512.
[153] NMPA. 药品注册管理办法. 2020.
[47] Norman RA, et al. Computational approaches to therapeutic antibody design: established methods and emerging trends. Briefings in Bioinformatics, 2020, 21(5): 1549-1567.
[107] Pepinsky RB. Selectivity of antibody therapeutics for disease-related targets. In: Making and Using Antibodies, CRC Press, 2018.
[106] Persson H, et al. CDR-H3 diversity is not required for antigen recognition by synthetic antibodies. Journal of Molecular Biology, 2013, 425(4): 803-811.
[157] Pires DE, Ascher DB. mCSM-AB: a web server for predicting antibody-antigen affinity changes upon mutation with graph-based signatures. Nucleic Acids Research, 2016, 44(W1): W469-W474.
[125] Queen C, et al. A humanized antibody that binds to the interleukin 2 receptor. Proceedings of the National Academy of Sciences, 1989, 86(24): 10029-10033.
[114] Rajpal A, et al. A general method for greatly improving the affinity of antibodies by using combinatorial libraries. Proceedings of the National Academy of Sciences, 2005, 102(24): 8466-8471.
[53] Raybould MIJ, et al. Five computational developability guidelines for therapeutic antibody profiling. Proceedings of the National Academy of Sciences, 2019, 116(10): 4025-4030.
[79] Regev A, et al. The Human Cell Atlas. eLife, 2017, 6: e27041.
[52] Ruffolo JA, et al. Fast, accurate antibody structure prediction from deep learning on massive set of natural antibodies. Nature Communications, 2023, 14: 2389.
[78] Sabatine MS, et al. Evolocumab and clinical outcomes in patients with cardiovascular disease. New England Journal of Medicine, 2017, 376(18): 1713-1722.
[146] Saber H, et al. An FDA oncology analysis of antibody-drug conjugates. Regulatory Toxicology and Pharmacology, 2017, 71(3): 444-452.
[104] Saka K, et al. Antibody design using LSTM based deep generative model from phage display library for affinity maturation. Scientific Reports, 2021, 11: 5852.
[76] Santos R, et al. A comprehensive map of molecular drug targets. Nature Reviews Drug Discovery, 2017, 16(1): 19-34.
[130] Schlothauer T, et al. Novel human IgG1 and IgG4 Fc-engineered antibodies with completely abolished immune effector functions. Protein Engineering, Design and Selection, 2016, 29(10): 457-466.
[147] Schork NJ. Personalized medicine: time for one-person trials. Nature, 2015, 520(7549): 609-611.
[119] Seeliger D, de Groot BL. Protein thermostability calculations using alchemical free energy simulations. Biophysical Journal, 2010, 98(10): 2309-2316.
[101] Setliff I, et al. High-throughput mapping of B cell receptor sequences to antigen specificity. Cell, 2019, 179(7): 1636-1646.
[159] Shah DK, Betts AM. Towards a platform PBPK model to characterize the plasma and tissue disposition of monoclonal antibodies in preclinical species and human. Journal of Pharmacokinetics and Pharmacodynamics, 2012, 39(1): 67-86.
[82] Shalem O, et al. Genome-scale CRISPR-Cas9 knockout screening in human cells. Science, 2014, 343(6166): 84-87.
[138] Shankar G, et al. Assessment and reporting of the clinical immunogenicity of therapeutic proteins and peptides-harmonized terminology and tactical recommendations. AAPS Journal, 2014, 16(4): 658-673.
[129] Shields RL, et al. Lack of fucose on human IgG1 N-linked oligosaccharide improves binding to human FcγRIII and antibody-dependent cellular toxicity. Journal of Biological Chemistry, 2002, 277(30): 26733-26740.
[102] Sidhu SS, Fellouse FA. Synthetic therapeutic antibodies. Nature Chemical Biology, 2012, 2(12): 682-688.
[112] Sirin S, et al. AB-Bind: antibody binding mutational database for computational affinity predictions. Protein Science, 2016, 25(2): 393-409.
[74] Smietana K, et al. Trends in clinical success rates. Nature Reviews Drug Discovery, 2016, 15(6): 379-380.
[89] Smith GP. Filamentous fusion phage: novel expression vectors that display cloned antigens on the virion surface. Science, 1985, 228(4705): 1315-1317.
[120] Sormanni P, et al. The CamSol method of rational design of protein mutants with enhanced solubility. Journal of Molecular Biology, 2015, 427(2): 478-490.
[143] Suntharalingam G, et al. Cytokine storm in a phase 1 trial of the anti-CD28 monoclonal antibody TGN1412. New England Journal of Medicine, 2006, 355(10): 1018-1028.
[69] Thomas DW, et al. Clinical development success rates 2006-2015. BIO Industry Analysis, 2016.
[95] Tiller T, et al. Efficient generation of monoclonal antibodies from single human B cells by single cell RT-PCR and expression vector cloning. Journal of Immunological Methods, 2008, 329(1-2): 112-124.
[124] Tomar DS, et al. Molecular basis of high viscosity in concentrated antibody solutions: strategies for high concentration drug product development. mAbs, 2016, 8(2): 216-228.
[152] Tsiftsoglou AS, et al. Advances in the pharmacological characterization of monoclonal antibodies. Pharmacology & Therapeutics, 2013, 138(3): 452-469.
[136] Wang W, et al. Monoclonal antibody pharmacokinetics and pharmacodynamics. Clinical Pharmacology & Therapeutics, 2008, 84(5): 548-558.
[98] Wang B, et al. Functional interrogation and mining of natively paired human VH:VL antibody repertoires. Nature Biotechnology, 2021, 39: 453-462.
[60] Watson JL, et al. De novo design of protein structure and function with RFdiffusion. Nature, 2023, 620: 1089-1100.
[135] Weiner GJ. Building better monoclonal antibody-based therapeutics. Nature Reviews Cancer, 2015, 15(6): 361-370.
[150] Weise M, et al. Biosimilars: what clinicians should know. Blood, 2012, 120(26): 5111-5117.
[67] Wouters OJ, McKee M, Luyten J. Estimated research and development investment needed to bring a new medicine to market, 2009-2018. JAMA, 2020, 323(9): 844-853.
[123] Yadav S, et al. Factors affecting the mechanism of self-association of human monoclonal antibodies and its implications on high concentration formulation. Journal of Pharmaceutical Sciences, 2012, 101(4): 1400-1415.
[156] Yan Y, et al. HDOCK: a web server for protein-protein and protein-DNA/RNA docking based on a hybrid strategy. Nucleic Acids Research, 2020, 48(W1): W45-W51.
[161] Yang KK, Wu Z, Arnold FH. Machine-learning-guided directed evolution for protein engineering. Nature Methods, 2019, 16: 687-694.
[131] Zalevsky J, et al. Enhanced antibody half-life improves in vivo activity. Nature Biotechnology, 2010, 28: 157-159.
[81] Zeng X, et al. Deep drug-target binding affinity prediction with multiple attention mechanisms. BMC Bioinformatics, 2022, 23: 312.
[100] Zost SJ, et al. Potently neutralizing and protective human antibodies against SARS-CoV-2. Nature, 2020, 584: 443-449.
2026-03-25
会议推荐
2026第三届中国医药企业项目管理大会
2026第二届中国AI项目管理大会
2026第十五届中国PMO大会
2026第五届中国项目经理大会
本
文
目
录
1、浅谈小核酸药物杂质分析难点
2、ADC药物质量分析的难点探讨
3、抗体偶联药物ADC的临床生物分析难点与策略
4、一根肽链,几十种杂质多肽药物有关物质分析,为什么这么难?
一、浅谈小核酸药物杂质分析难点
(原创 B.bridge 佑嘉医药)
小核酸药物指长度在30nt以下的核酸片段,主要包括MicroRNA、saRNA、siRNA等。本文以siRNA为例,简单探讨下小核酸药物杂质分析的难点问题。siRNA一般指长为19~23个核苷酸序列的双链RNA,通过与目标mRNA互补结合,特异性地实现mRNA降解,采用化学合成是最直接最可靠的获得siRNA的方法。此文仅针对合成工艺路线产生的,与行使功能的siRNA性质较为接近的杂质色谱分析条件进行探索。
一、文献报道
1)Thermo选用1、5、10、15、20位错配序列作为杂质进行研究。
如图所示,其出峰时间与错配位点之间并无明确规律,尤其是20位错配与目的序列之间保留时间极其接近。因此想要摸出其规律以便下一步分析,要以实验积累为基础,从具体核酸序列上再做探索。
2)Agilent选用离子对反向色谱对不同长度的寡核苷酸片段进行分析。
如图所示,可见不同长度序列的色谱峰极其接近,以n=20与n=21两片段为例,两样品峰并未完全分离,且色谱峰响应值低,如增加核酸浓度用于杂质分析,则相邻色谱峰之间分离度可能小于1.5,这为siRNA的杂质分析带来了极大的挑战。
二、色谱条件的选择
1)mp的选择
采用以下条件进行实验:
mpA
0.1M TEAA 3%CH3CN(pH7.0)
mpB
CH3CN
V
0.8ml/min
λ
260nm
以mpA:mpB不同比例进行色谱分析,当85:15时杂质间分离完全,峰形良好;当95:5时,有机相比例过低,洗脱1h未见色谱峰,由此可见该比例有机相含量已达到色谱分析极限。
结合上文所述目标序列与异构体之间色谱行为十分接近,流动相比例可优化范围又极窄,更增大了杂质与目标序列分离的难度。
2)离子对试剂选择
由于siRNA具有强烈负电性,需在流动相中添加离子对试剂以提高其在该色谱条件下的保留。液相色谱分析中常采用TEAA,此外HFIP、HAA等也常被应用于寡核苷酸的反向色谱分析中。
①TEAA:强离子对试剂如季铵盐会使寡核苷酸产生强保留,但同时会削弱不同碱基疏水性差异对保留的影响,并不利于杂质分离。作为较弱的阳离子体系,TEAA则显示出其优势。
②HFIP:为了使siRNA更好的发挥作用,人们常会对siRNA做一定的修饰,以增加siRNA的稳定性,其中硫代氧原子是众多修饰手法中最为常用的一个。但这种修饰中,由于“S”原子取代了“O”原子,使硫代寡核苷酸形成对映异构体,最终造成峰形展宽。将HFIP引入色谱系统中,通过系列条件优化,使最终条件下的系统适用性更优。
③HAA:由于TEAA体系的变性性质,其可能促进RNA双链之间的解链作用,因此为RNA双链的分析带来了一定的局限性。我们采用HAA体系用于siRNA的液相色谱分析中,降低RNA解链风险,且分离度及色谱峰响应值有所提高。
以上三种离子对试剂在siRNA杂质分析上的应用各有优劣,具体离子对试剂的选择还是应根据不同核酸序列的性质来确定,并不能一概而论。
3)pH值的影响
当mp-pH为3.0、7.0和10.0时进行了对比考察。
pH为3.0时色谱图:
pH为10.0时色谱图:
如图,结果显示当pH为7.0时系统适应性最好(见“mp的选择”项下色谱图),更有助于siRNA的色谱分析。若对色谱梯度做进一步调整,色谱行为可能会有所改善。
综上所述,因siRNA带电荷及其合成工艺的特殊性,如合成的过程中某位碱基发生错配而产生的核酸片段、siRNA双链末端缺失1或2位碱基的双链RNA、部分RNA单链杂质,其色谱行为并不像普通小分子化药具有规律性,接下来佑嘉生物药物分析团队将利用CMC平台 根据药物及杂质的理化性质、化学结构、杂质的控制要求,采用不同原理的检测器进行对比研究,期待与大家共同探讨小核酸药物的分析方法。
参考文献:
[1]siRNA的化学合成及其在医学研究中的应用初探。张仁礼,中山大学临床医学院。
[2]Reversed-phase ion-pair liquid chromatography analysis and purifification of small interfering RNA。Sean M. McCarthy *, Martin Gilar, John Gebler
[3]反相离子对色谱法对寡核苷酸药物分析的进展 杨洪淼,范慧红
[4]Evaluation of Different Ion-Pairing Reagents for LC/UV and LC/MS Analysis of Oligonucleotides。Gerd Vanhoenacker, Cindy Lecluyse, Griet Debyser
[5]DNAPac系列色谱柱的寡核苷酸分析应用 赛默飞
二、ADC药物质量分析的难点探讨
(原创 北斗七星 智药公会)
在精准医疗与靶向治疗快速发展的今天,抗体偶联药物(Antibody-Drug Conjugate, ADC)凭借其“精准制导、高效杀伤”的独特优势,已成为肿瘤治疗领域的前沿热点。从首个产品获批到如今多款国产ADC陆续上市,这一技术正以前所未有的速度推动着生物医药的创新进程。然而,在临床价值背后,ADC药物的质量控制体系面临着远超传统生物药或化学药的复杂挑战。其由抗体、连接子和高毒性小分子三部分构成的复合结构,导致分子异质性高、降解路径多样、分析难度大,任何一个环节的微小偏差都可能影响最终的安全性与有效性。因此,建立科学、系统、可追溯的质量分析体系,不仅是保障患者用药安全的核心,也是推动ADC药物从研发走向产业化的重要基石。
结构异质性带来的分析挑战
ADC药物最显著的特征是其高度的结构异质性,这主要源于偶联过程的非定点性和抗体本身的微变异。目前主流的偶联技术依赖于抗体表面赖氨酸或半胱氨酸残基的化学反应,由于这些位点在空间分布和反应活性上的差异,导致每个抗体分子所携带的药物数量和位置各不相同,形成一系列不同载药量(DAR)的分子混合物。
这种载药量分布直接影响ADC的药效学与药代动力学行为。DAR过低可能导致肿瘤杀伤力不足,而DAR过高则会增加分子疏水性,加速清除,甚至引发聚集和免疫原性风险。因此,准确测定平均DAR值及其分布,成为质量分析的首要任务,也是工艺开发与生产放行的关键控制点。
为应对这一挑战,行业已发展出多种分析手段。紫外-可见光谱法(UV-Vis)操作简便,适用于早期快速筛选,但无法提供DAR分布信息。疏水相互作用色谱(HIC-HPLC)可在非变性条件下按疏水性分离不同DAR组分,直观呈现分布曲线,是当前GMP生产中最常用的方法。而液相色谱-质谱联用(LC-MS)则能从分子质量层面直接解析DAR分布,提供最精确的结构信息,尽管成本较高,但在关键批次确认和深入表征中不可或缺。
游离药物控制的紧迫性
游离药物(Free Payload)是ADC质量控制中最为敏感的安全性指标。其来源主要包括生产过程中未完全去除的残留毒素、制剂储存期间的化学降解以及体内循环中的提前释放。由于有效载荷通常为高毒性小分子(如MMAE、DM1等),即使极微量的游离药物进入体循环,也可能对正常组织造成严重损伤,导致骨髓抑制、肝毒性等不良反应。
因此,建立高灵敏、高选择性的游离药物检测方法至关重要。目前,液相色谱-串联质谱(LC-MS/MS)因其极低的检测限(可达pg/mL级)和优异的选择性,成为该领域的金标准。方法开发需重点评估基质效应、提取回收率和线性范围,确保在复杂生物基质中仍能实现准确定量。
此外,游离药物的控制不仅是放行检测的要求,更应贯穿于整个产品生命周期。在稳定性研究中,必须动态监测游离药物随时间的变化趋势,评估其在货架期内的安全性风险。同时,还需关注连接子的稳定性,尤其是可裂解连接子在酸性或酶环境下的水解行为,这些都可能成为游离药物生成的潜在途径。
分子与电荷变异体对药代与安全性的影响
ADC药物在生产和储存过程中易产生多种分子变异体,其中聚集体和片段是最受关注的两类。由于偶联了疏水性的小分子药物,ADC分子表面疏水性增强,更易发生非特异性聚集。聚集体不仅可能降低药效,还可能激活免疫系统,引发抗药抗体(ADA)反应,影响药物的安全性和有效性。
体积排阻色谱(SEC-HPLC)是检测聚集体的常规方法,但在分析ADC时存在局限:载荷的存在可能改变分子的流体力学体积,导致保留时间偏移,影响定量准确性。因此,常需结合多角度激光散射(SEC-MALS)技术,通过绝对分子量测定来提高结果的可靠性。
片段化问题同样不容忽视,可能源于生产过程中的剪切力或储存期间的蛋白酶降解。还原与非还原毛细管电泳(CE-SDS)可有效检测抗体链的断裂情况,并评估偶联状态的一致性。此外,电荷变异体(如酸性峰、碱性峰)也需关注,其成因包括去唾液酸化、氧化、脱酰胺等修饰,以及偶联反应本身对赖氨酸正电荷的中和。离子交换色谱(IEX)和成像毛细管等电聚焦(iCIEF)是常用分析工具,可用于监控产品一致性和偶联效率。
分析方法整合与生命周期管理的重要性
面对ADC复杂的质量属性,单一分析方法难以全面覆盖其质量特征。必须构建一个多维度、互补性的分析平台,涵盖结构、纯度、效价、杂质等多个方面,并在产品开发的不同阶段动态调整策略。早期研发可采用高通量方法进行快速筛选,进入临床阶段后则需建立经过验证的GMP级方法,确保数据的可靠性与可比性。
在商业化生产中,分析方法不仅要满足放行检测的要求,还需具备良好的稳健性和耐用性,能够应对不同批次、不同操作者和设备间的变异。同时,应建立方法生命周期管理机制,根据工艺变更、稳定性数据和监管要求持续优化分析策略,确保其始终处于受控状态。
此外,药代动力学(PK)分析也是ADC质量评价的重要组成部分。传统方法多关注总抗体或偶联抗体浓度,但近年来监管机构强调需同时监测游离药物及活性代谢物的暴露水平,以更全面评估药物的安全性与有效性。这要求建立融合配体结合法(LBA)与LC-MS技术的多平台PK检测体系,实现对多种分析物的同时追踪。
向更精准、更智能的分析未来迈进
随着定点偶联技术(如工程化半胱氨酸、非天然氨基酸、酶催化偶联等)的发展,ADC的结构均一性显著提升,DAR分布趋于集中(如DAR4为主),这为质量分析带来了新的机遇。结构更均一意味着分析图谱更清晰,方法开发更易标准化,也为建立更精确的质量-疗效关系(QTPP)提供了可能。
然而,新技术也带来新挑战。新型连接子、新型载荷以及更复杂的偶联化学,要求分析方法不断创新。质谱成像、氢氘交换质谱(HDX-MS)、表面等离子共振(SPR)等前沿技术,正在被用于深入解析ADC的构象变化、稳定性及与靶标的相互作用机制。
未来,ADC质量分析将朝着更高分辨率、更高灵敏度、更高通量的方向发展。人工智能与大数据分析的引入,有望在复杂图谱解析、质量趋势预测和异常信号识别中发挥重要作用,推动质量控制从“被动检测”向“主动预警”转变。唯有持续创新分析技术,构建科学严谨的质量体系,才能确保ADC这一“生物导弹”真正实现精准打击,在提升疗效的同时最大限度保障患者安全。
参考资料:
[1] FDA. Clinical Pharmacology Considerations for Antibody-Drug Conjugates: Guidance for Industry (Draft), 2022.
[2] Beck A, et al. Strategies and challenges for the next generation of antibody–drug conjugates. Nat Rev Drug Discov. 2017;16(5):315-337.
[3] Sun X, et al. Antibody–drug conjugates: Recent advances in linker chemistry. Acta Pharm Sin B. 2022;12(4):1640-1660.
三、抗体偶联药物ADC的临床生物分析难点与策略
(原创 谭玉萌,王雪芳 药明康德测试事业部)
1. 抗体偶联药物ADC介绍
1.1抗体偶联药物ADC
癌症已成为全球第二大健康威胁,截至到2020年,约有1000万人死于癌症[1]。几十年来,基于细胞毒性药物的化学疗法一直是治疗癌症的主要手段[2]。这些细胞毒性药物包括DNA碱基类似物(5-氟尿嘧啶和8-氮鸟嘌呤)、DNA相互作用药物(顺铂和放线菌素D)、抗代谢药物(氨蝶呤和甲氨蝶呤)和微管蛋白抑制剂(紫杉醇和长春新碱衍生物)等[3-7]。然而,大多数化学治疗药物的治疗指数较低,并且由于非特异性药物暴露于靶组织而产生严重的副作用[8]。为了解决这一问题,科学家们一直致力于开发具有更高质量的新型癌症治疗方法。
通过精准靶向肿瘤表面抗原,单克隆抗体的出现改变了癌症治疗的模式,然而,单独使用单克隆抗体的治疗往往是不够的,潜在的原因是与化学疗法相比,单克隆抗体对癌细胞的致死率较低[8]。因此,抗体偶联药物( antibody-drug conjugate,ADC)应运而生[9]。ADC药物是一种将小分子细胞毒素(payload)通过连接子(linker)与抗体偶联形成的药物。与传统的小分子化学治疗以及抗肿瘤单克隆抗体相比,ADC药物不仅可以提高化学治疗的疗效和抗肿瘤细胞的特异性,还可以降低或减弱系统毒性以及非靶向细胞毒性[10]。
图1.抗体偶联药物ADC结构,图片引自[11]
2000年,美国食品药品管理局(FDA)首次批准了用于治疗成人急性髓性白血病(acute myeloid leukemia,AML)的ADC药物Mylotarg®(gemtuzumab ozogamicin)[12],标志着该药物的癌症靶向治疗ADC时代的开始。截止到2023年1月13日,全球共有15款ADC药物获监管部门批准上市。此外,目前有超过100种ADC候选药物处于不同的临床试验阶段[11]。
表1.全球已获批上市ADC药物
表格引自药智数据、生物谷等公开资料
1.2 ADC药物组成与作用机制
ADC类药物包含三种成分:第一部分是高特异性和高亲和力的抗体, 抗体可以是嵌合抗体,也可以是抗体片段或双特异性抗体;第二部分是高稳定性的连接子,可分为可裂解型或不可裂解型,可裂解性的连接子利用体循环和肿瘤细胞之间的环境差异,准确释放游离的payload,进一步分为化学裂解连接子(腙键和二硫键)和酶裂解连接子(葡萄糖醛酸键和肽键)[11];不可裂解型的连接子通过降解抗体来释放payload;第三部分是小分子细胞毒素,通常分为两类,分别是靶向DNA的细胞毒素药或者微管抑制剂[11]。常见的靶向DNA的细胞毒素药有吡咯苯二氮杂卓(PBD)、杜卡霉素(Ducamycin)和喜数碱类(Camptothecin, CPT)、卡奇霉素(Cachimycin)等;常见的微管抑制剂有金盏花素(MMAE,MMAF)、美登素衍生物(DM2,DM4)、微管溶素(Tubulysins)和隐粘菌素(Cryptomycins, CR)等。
ADC药物的作用机制:首先通过单克隆抗体的靶向作用特异性的识别肿瘤表面抗原,通过内吞作用内化到达细胞,经内吞小体进入溶酶体,溶酶体的酸性环境和蛋白水解酶会致使ADC降解,释放的效应分子(payload)随后进入细胞质中,然后通过DNA插入或抑制微管合成等方式诱导肿瘤细胞凋亡[13]。
图2.抗体偶联药物ADC作用机制,图片引自[13]
1.3抗体偶联药物ADC生物分析难点
ADC药物的临床生物分析包含PK药代动力学、ADA抗药抗体以及Nab中和抗体分析。ADC进入体内后,payload可通过酶解或者化学反应从主体结构上逐渐解离,主要包括ADC、总抗体、游离的小分子payload以及payload相关的代谢产物等,他们在体内的浓度变化对解读ADC的PK药代动力学特点至关重要。ADC为抗体或抗体片段至少结合一个payload(抗体偶联比(Drug to antibodyratio,DAR)≥1);总抗体为未偶联和偶联至少一个payload分子的抗体的总和(DAR≥0);Payload为ADC裂解或被分解代谢后形成的游离的payload[15]。由于ADC自身所具有的特殊结构和复杂的组分多样性,其生物分析方法的建立具有很大的挑战性。
首先,由于ADC药物为各种组分混合物,且不同采集时间的ADC形态和组分可能不同,因此标准品很难完全代表不同PK采样点的样品。
其次,不同药物DAR值的ADC与捕获试剂或者检测抗体的结合能力可能不同,影响总抗体和ADC浓度的准确度测定。
最后,由于ADC结构的特殊性,偶联引入了新的抗原表位,对确证为阳性的样本免疫原性分析需要开展结构域特异性评价。
2. 抗体偶联药物ADC指导原则
2.1 PK药代动力学指导原则
2013年美国药学家协会(American Association of Pharmaceutical Scientists,AAPS)发表了“Bioanalysis of antibody–drug conjugates: American Association of Pharmaceutical Scientists Antibody–Drug Conjugate Working Group position paper”白皮书[14]。在“ADC药物应该测定哪些生物分析物”的相关章节指出,对于ADC药物的PK分析,应该测定多种生物分析物用于评估ADC暴露量,表一总结了ADC生物分析通常需要测定的生物分析物以及相应的方法。2022年2月FDA发布了 “Clinical Pharmacology Considerations for Antibody-Drug Conjugates”指导原则草案[15]。在生物分析相关章节指出,对ADC的药代动力学评估应该对体内的总抗体、ADC以及小分子部分payload进行分析。此外,ADC药物的PK方法学验证应按照FDA指南“Bioanalytical Method Validation”[16], 欧洲药品管理局(European Medicines Agency, EMA)指南“Guideline on bioanalytical method validation”[17],ICH M10“Bioanalytical method validation and study sample analysis”[18]和中国药典《生物样品定量分析方法验证指导原则》[19]等进行验证和报告。
表2.通常用于抗体偶联药物ADC生物分析的分析物,表格来自[14]
2.2 ADA抗药抗体指导原则
对于ADC的免疫原性分析,FDA发布的“Clinical Pharmacology Considerations for Antibody-Drug Conjugates”指导原则草案的免疫原性相关章节指出,ADC的任何组成部分都可能产生免疫应答,包括抗体、payload或由连接子产生的表位[15]。同时该指导原则草案[15]指出对于免疫原性的评估,应按照FDA指南“Immunogenicity Testing of Therapeutic Protein Products —Developing and Validating Assays for Anti-Drug Antibody Detection” (2019年1月)[20]中概述的方法进行免疫原性评估,包括检测ADC抗药抗体(ADAs)的确认性评估。此外,应开发多种检测方法来测量对ADC组成部分的免疫反应,例如偶联产生的额外表位或结构域。对于多结构域蛋白的抗药抗体生物分析,2019年美国FDA发表的“Immunogenicity Testing of Therapeutic Protein Products —Developing and Validating Assays for Anti-Drug Antibody Detection”和2021年国家药品监督管理局发布的《药物免疫原性研究技术指导原则》[21]均明确指出“对于多结构域治疗性蛋白药物,如聚乙二醇化蛋白、多特异性抗体,建议针对整个治疗性蛋白药物进行初步筛选试验和确证试验,基于风险或产品特征,对确证为阳性的样本进一步开展域特异性评价。”
2.3 Nab 中和抗体分析指导原则
对于Nab中和抗体的检测,其指导原则与常规的大分子的指导原则类似,有基于细胞的中和抗体检测方法(cell-based analysis)和非基于细胞的中和抗体检测方法(non-cell-base analysis),可以根据具体的大分子药物的作用机制、选择性、灵敏度、精度和稳健性等选择分析方法。一般来说,2019年美国FDA发表的“Immunogenicity Testing of Therapeutic Protein Products —Developing and Validating Assays for Anti-Drug Antibody Detection”[20]建议使用基于细胞的生物测定法进行中和试验。
3. 抗体偶联药物ADC的生物分析策略
3.1 ADC 药物PK药代动力学生物分析
由于ADC兼具大分子和小分子治疗药物的分子特征,因此大分子或小分子两种药物典型的生物分析方法都是必要的分析手段。药明康德大分子生物分析实验室通常采用ELISA或MSD平台来检测总抗体以及ADC药物的PK药代动力学。对于总抗体的PK检测,多利用包被抗原或抗ID(idiotype)抗体捕获总抗体,再选择合适的酶标检测抗体(如抗Fc抗体或者抗ID(idiotype)抗体)作为检测抗体进行定量检测。对于ADC药物的PK检测,利用抗payload药物抗体捕获ADC,再选择合适的酶标检测抗体(如抗Fc抗体或者抗ID(idiotype)抗体)作为检测抗体进行定量检测。对于payload相关的PK分析,通常采用LC-MS平台进行检测。药明康德生物分析实验室开展了多项ADC检测项目,我们会对ADC的结构、体内转化以及稳定性等做充分了解,制定相应的分析策略和优化措施,成功帮助客户实现总抗体、ADC以及payload的浓度准确性测定。
图3.ADC药物PK药代动力学生物分析方法[22]
3.2 ADC药物ADA抗药抗体生物分析
ADC药物ADA的分析方法主要是基于MSD平台的桥联法,生物素(Biotin)标记的ADC药物作为捕获试剂,地高辛(Dig)或者钌标的ADC药物作为检测试剂,实现对ADA的检测(图4)。
ADC药物的ADA样品分析的主要流程是,首先对样品进行初筛分析,初筛阳性的样品会进行确证分析,确证阳性的样品会进行中和抗体分析和滴度分析。由于ADC药物自身的不同结构域都可能产生ADA,抗原表位可以是抗体部分、连接子或payload 部分,也可以是复合物整体。因此,药明康德大分子生物分析实验室对ADC药物的免疫原性测定时,会对ADC 药物确证为阳性的样本进一步开展域特异性评价。
图4. ADC药物ADA抗药抗体生物分析
3.3 ADC药物Nab中和抗体分析
对于ADA抗药抗体阳性的样本,通常需要分析Nab中和抗体。对于中和抗体的测定,我们根据法规要求,更推荐Cell-based基于细胞的体外功能性试验,它更反应体内的真实情况,难点是需要寻找合适的细胞系,基质效应明显,干扰大。在难以获得相关细胞系,或者基质效应无法解决的情况下,可以使用Non-cell based方法。我们根据客户检测的药物的特性,成功帮助客户设计并完成多个针对肿瘤易感基因受体并带有细胞毒性分子的ADC药物的cell-base Nab检测。
4. 药明康德生物分析部ADC药物的生物分析经验
药明康德测试事业部生物分析部拥有丰富的ADC药物的生物分析经验,已开发并验证符合GLP法规要求的多种生物分析方法,经验包含Her2、Her3、Trop-2、Claudin 18.2、PSMA、CD38和CDH3等单双抗靶点,MMAE、MMAF、DM1、DM4、SN38、DXD、Camptothecin(喜数碱)等payload,充分满足检测需求。通过不断发展的生物分析技术,深入全面地阐明ADC药物的药物代谢、药效以及免疫原性特征,对于推动研发出更加低毒高效的ADC药物至关重要,助力药物的IND、NDA和 ANDA等申报。
参考文献(滑动查看):
[1] Sung, H. et al. Global cancer statistics 2020: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 71,209–249 (2021).
[2] Loadman, P. Anticancer drug development. Br. J. Cancer 86, 1665–1666 (2002).
[3] Gilman, A. & Philips, F. S. The biological actions and therapeutic applications of the B-chloroethyl amines and sulfides. Science 103, 409–436 (1946).
[4] Heidelberger, C. et al. Fluorinated pyrimidines, a new class of tumour-inhibitory compounds. Nature 179, 663–666 (1957).
[5] Norris, R. E. & Adamson, P. C. Clinical potency of methotrexate, aminopterin, talotrexin and pemetrexed in childhood leukemias. Cancer Chemother. Pharmacol.65, 1125–1130 (2010).
[6] Rosenberg, B., Van Camp, L. & Krigas, T. Inhibition of cell division in Escherichia coli by electrolysis products from a platinum electrode. Nature 205, 698–699 (1965).
[7] Rowinsky, E. K. & Donehower, R. C. Paclitaxel (taxol). N. Engl. J. Med. 332,1004–1014 (1995).
[8] Shefet-Carasso, L. & Benhar, I. Antibody-targeted drugs and drug resistance—challenges and solutions. Drug Resist. Updat. 18, 36–46 (2015).
[9] Sievers, E. L. & Senter, P. D. Antibody-drug conjugates in cancer therapy. Annu. Rev. Med. 64, 15–29 (2013).
[10] Lambert, J. M. & Berkenblit, A. Antibody–drug conjugates for cancer treatment. Annu. Rev. Med. 69, 191–207 (2018).
[11] Fu Z, Li S, Han S, Shi C, Zhang Y. Antibody drug conjugate: the "biological missile" for targeted cancer therapy. Signal Transduct Target Ther. 7(1):93 (2022).
[12] Norsworthy, K. J. et al. FDA approval summary: mylotarg for treatment of patients with relapsed or refractory CD33‐positive acute myeloid leukemia. Oncologist 23, 1103 (2018).
[13] Poon KA, Flagella K, Beyer J, Tibbitts J, Kaur S, Saad O, Yi JH, Girish S, Dybdal N, Reynolds T. Preclinical safety profile of trastuzumab emtansine (T-DM1): mechanism of action of its cytotoxic component retained with improved tolerability. Toxicol Appl Pharmacol. 273(2):298-313(2013).
[14] Gorovits B, Alley SC, Bilic S, Booth B, Kaur S, Oldfield P, Purushothama S, Rao C, Shord S, Siguenza P. Bioanalysis of antibody-drug conjugates: American Association of Pharmaceutical Scientists Antibody-Drug Conjugate Working Group position paper. Bioanalysis. 5(9):997-1006(2013).
[15] Clinical Pharmacology Considerations for Antibody-Drug Conjugates, Retrieved February 11, 2022.
[16]US FDA Guidance for Industry, Bioanalytical Method Validation, May 2018
[17] European Medicines Agency (EMA), Guideline on bioanalytical method validation, EMEA/CHMP/EWP/192217/2009,21 July 2021.
[18] ICHM10 Guideline, Bioanalytical method validation and study sample analysis, 24 May 2022.
[19] 中国药典2020年版,生物样品定量分析方法验证指导原则
[20] US FDA Guidance for Industry, Immunogenicity Testing of Therapeutic Protein Products —Developing and Validating Assays for Anti-Drug Antibody Detection, 24 May 2022.
[21] 国家药品监督管理局,药物免疫原性研究技术指导原则, 2021.
[21] Hyung SJ, Leipold DD, Lee DW, Kaur S, Saad OM. Multiplexed Quantitative Analysis of Antibody-Drug Conjugates with Labile CBI-Dimer Payloads In Vivo Using Immunoaffinity LC-MS/MS. Anal Chem. 94(2):1158-1168(2022).
四、一根肽链,几十种杂质多肽药物有关物质分析,为什么这么难?
(原创 土狗2号 集你肽美)如果你做过多肽分析,大概率有过这样的体验:
👉 同样是 HPLC,放到多肽身上,方法突然就“不听话”了
👉 梯度稍微一动,保留时间就乱跑
👉 峰形拖尾、肩峰、双峰,怎么调都不完美
问题不在你,而在多肽本身。
今天土狗就和大家系统聊一聊:多肽药物中,多肽相关杂质到底该怎么分析?一、为什么多肽药物“天生难分析”?
多肽,介于小分子化学药与生物大分子药物之间,看似“中间态”,但在分析上,却集齐了两边的“难点”。1️⃣ 分子量大,对色谱极度敏感
以明星药物索马鲁多肽为例,分子量约4114 Da。
这意味着:
对B%(有机相比例)异常敏感
即便 0.1% 的变化,也可能导致保留时间大幅漂移
在流动相中扩散慢,柱效下降、峰变宽
👉 小分子能“凑合”的条件,在多肽这里往往直接失效。
2️⃣ 有结构,不是“一根直线”
多肽不是一条软绳,而是会形成:
α 螺旋
β 折叠
稳定的三级结构
结果是:并不是整条肽链都能和固定相接触,
真正参与相互作用的,往往只是“暴露在外”的残基。
👉 同序列、不同构象,也可能带来不同保留行为。
3️⃣ 酰胺键的“顺反异构”是个坑
多肽由大量酰胺键连接,而酰胺键具有部分双键特性。
这会带来一个在小分子中不常见的问题:
顺 / 反异构体共存
在色谱上常见表现就是:
峰形异常
双峰、肩峰
温度一变,峰型就跟着变4️⃣ 两亲性 + 等电点 = pH 敏感体质
多肽同时含有:
酸性羧基
碱性氨基
因此存在明确的等电点(pI)。
而在pH 接近等电点时:
溶解度最低
易聚集
峰形最差
👉 pH 选错,多肽会“直接摆烂”。
5️⃣ 杂质像“复制粘贴”
多肽合成过程中,会产生大量结构高度相似的杂质:
缺失一个氨基酸
外消旋杂质
氧化、脱酰胺降解产物
结构差异极小,但色谱行为几乎一致,
这也是多肽有关物质分离最难的地方。
二、多肽有关物质分析,核心思路是什么?
一句话总结:
不要指望“一种模式打天下”
多肽分析,通常需要多种色谱模式协同使用:
反相色谱(RP)——主力
离子交换色谱(IEC)——补充选择性
尺寸排阻色谱(SEC)——盯聚合物三、反相色谱(RP):多肽分析的主战场▶ 色谱柱,怎么选才不踩坑?
硅胶基质仍然是首选,原因很现实:
机械强度高
技术成熟
对多肽这种“扩散慢”的分子更友好
由于多肽主要只进入颗粒表层,
反而减少了内部扩散导致的谱带展宽。
经验建议:
小粒径柱:对多肽利大于弊
窄内径柱:可减少纵向扩散
孔径 10–12 nm:可满足绝大多数多肽分析
▶ 固定相不止 C18
虽然C18 是默认选项,但并非万能:
苯基柱:
对含酪氨酸、苯丙氨酸等芳香族残基的多肽,
往往能提供截然不同的选择性
不同封端方式
嵌入极性基团
不同表面修饰
👉 方法开发阶段,一定要多试几种“性格不同”的柱子▶ 流动相:TFA 不是唯一答案
三氟乙酸(TFA)
磷酸盐缓冲液
pH 筛选极其重要▶ 有机相与梯度:慢,就是快
乙腈优于醇类(低粘度、低 UV 吸收、峰形好)
可少量加入甲醇、异丙醇调选择性
梯度一定要“慢慢爬”
👉 对多肽来说,
快梯度 = 自找麻烦▶ 其他关键参数
柱温
检测波长四、离子交换色谱(IEC):解决“RP 分不开”的问题
当你发现:
RP 怎么调都分不开杂质死死贴着主峰
这时候,IEC 往往能救命。▶ IEC 的核心是:pH + 抗衡离子
流动相 pH 一般控制在等电点 ±1
阳离子交换:pH 至少低于 pI 1 个单位
阴离子交换:pH 至少高于 pI 1 个单位
常用抗衡离子包括:
Cl⁻、ClO₄⁻、SO₄²⁻
Na⁺ 等碱金属离子
👉 改变抗衡离子类型和浓度,
往往比“死磕柱子”更有效。▶ IEC 固定相类型速览
强阴离子交换:–N(CH₃)₃⁺
强阳离子交换:–SO₃⁻
弱阴离子交换:–NH₂
弱阳离子交换:–COOH
柱规格和其他参数,基本可参考 RP 的经验。五、尺寸排阻色谱(SEC):专盯“聚合物杂质”
SEC 并不是用来“精细分离”的,
它的任务只有一个:
把“大块头”揪出来▶ SEC 关键点
常用二醇基修饰硅胶柱,减少非特异吸附
孔径通常12 nm即可
流速可适当降低,提高柱效
流动相中可加入较高浓度缓冲盐,降低电荷效应
👉 SEC 是聚合物杂质研究中的“定海神针”。
六、写在最后:多肽分析,是一场耐力赛
多肽药物的分析方法开发,从来不是“调两天就完事”。
它往往意味着:多种分离模式反复切换;固定相、pH、梯度不断试错;随着杂质认识加深,方法持续迭代。正如很多分析人总结的那样:
多肽分析,拼的不只是技术,更是耐心。
如果你正在被多肽有关物质“折磨”,
那不是你不行,
而是你正在挑战分析化学里最难的一类分子之一。
end
本公众号声明:
1、如您转载本公众号原创内容必须注明出处。
2、本公众号转载的内容是出于传递更多信息之目的,若有来源标注错误或侵犯了您的合法权益,请作者或发布单位与我们联系,我们将及时进行修改或删除处理。
3、本公众号文中部分图片来源于网络,版权归原作者所有,如果侵犯到您的权益,请联系我们删除。
4、本公众号发布的所有内容,并不意味着本公众号赞同其观点或证实其描述。其原创性以及文中陈述文字和内容未经本公众号证实,对本文全部或者部分内容的真实性、完整性、及时性我们不作任何保证或承诺,请浏览者仅作参考,并请自行核实。
2025-11-19
在现代医学的药物宝库中,甲氨蝶呤(Methotrexate, MTX)无疑是一颗璀璨而独特的明星。它诞生于上世纪中叶的“化疗黎明”,最初作为一种凶险的白血病治疗药物登上历史舞台,其作用机理近乎于“杀敌一千,自损八百”。然而,凭借科学家和医生们不懈的探索,这款原本被视为“最后手段”的细胞毒药物,竟成功转型,如今已成为全球范围内治疗风湿性关节炎、牛皮癣等自身免疫性疾病的基础药物,并在滋养细胞肿瘤、淋巴瘤等多种实体瘤的治疗中占据一席之地。甲氨蝶呤的历程,是一部人类对生命微观世界认知不断深化、将致命武器巧妙转化为生命守护神的医学传奇。
1
叶酸的“双面人生”—发现的科学前奏
要理解甲氨蝶呤的故事,必须先了解它的“靶点”——叶酸。
20世纪30至40年代,生物化学家们正热衷于研究一种被称为“维生素M”或“肝脏斯-林格因子”的物质,它被发现能治疗猴子和人类的营养性贫血。最终,这种物质被分离、结晶并命名为“叶酸”(Folic Acid),因其在绿叶蔬菜中含量丰富而得名。随后的研究证实,叶酸在体内转化为活性形式的四氢叶酸,作为“一碳单位”的载体,在嘌呤、胸苷酸等DNA关键组分的合成过程中扮演着不可或缺的角色。简言之,叶酸是细胞分裂和增殖的必需维生素。
这一发现很快引发了癌症研究者的极大兴趣。既然癌细胞的特性是无限制的疯狂增殖,那么它们对叶酸的依赖必然远超正常细胞。一个直观的、看似矛盾的设想被提了出来:能否通过“过度”补充叶酸,来“催肥”并最终杀死癌细胞?早期的动物实验似乎支持这一想法,但当波士顿儿童医院的病理学家西德尼·法伯博士将叶酸用于治疗罹患白血病的儿童时,结果却是一场灾难——叶酸不仅没有抑制病情,反而像“燃料”一样,加速了癌细胞的增殖,导致患儿的病情急剧恶化。
法伯的这次“失败”实验,在科学上具有里程碑式的意义。它清晰地证明,癌细胞确实在贪婪地摄取和利用叶酸。这次失败关闭了一扇门,却打开了另一扇窗:如果补充叶酸会助长癌症,那么反过来,如果能够阻断叶酸的功能,是否就能“饿死”癌细胞呢?
此时,战争催生的科学成果为这一设想提供了可能。在第二次世界大战期间,科学家们为了对抗化学武器,研究了叶酸的结构。以此为基础,法伯与生化专家苏巴拉奥·耶拉普拉格达等人合作,委托莱德利实验室合成了第一批叶酸类似物——即结构与叶酸相似,但功能相拮抗的物质。他们希望这些“分子间谍”能冒充叶酸,潜入细胞内的代谢通路,从而阻断其正常功能。
2
氨基蝶呤的曙光与甲氨蝶呤的诞生
在合成的多个叶酸拮抗剂中,第一个展现出惊人效果的是氨基蝶呤。
1947年,法伯进行了一项划时代的临床试验。他选择了16名对任何现有疗法均无反应的晚期急性淋巴细胞白血病患儿,给予了氨基蝶呤。在当时,白血病几乎等同于死刑判决。然而,奇迹发生了:部分患儿的病情得到了前所未有的缓解——他们的高热退了,出血停止了,肿大的肝脏和脾脏缩小了,骨髓中猖獗的癌细胞暂时消退了。虽然这些缓解都是短暂的,最终所有患儿均不幸复发离世,但这是人类历史上第一次通过化学药物,实现了对癌症的诱导缓解。它无可辩驳地证明了化学物质可以治疗恶性肿瘤,从而开创了现代化学治疗的新纪元。
然而,氨基蝶呤的毒性非常剧烈。为了寻找疗效相当但更安全的药物,科学家们对叶酸拮抗剂的结构进行了持续优化。很快,一个在氨基蝶呤结构基础上进行微小修饰的化合物被合成出来:将其中一个氢原子替换为甲基。这个看似微不足道的改变,却带来了巨大的临床差异。这个新化合物被命名为甲氨蝶呤。
与氨基蝶呤相比,甲氨蝶呤在体内更稳定,与靶点的结合力更强,且其剂量反应曲线更为平缓,意味着医生有更宽的窗口去调整剂量,在保证疗效的同时更好地管理毒性。因此,甲氨蝶呤迅速取代了氨基蝶呤,成为临床首选的叶酸拮抗剂,并一直沿用至今。
3
精准的“分子伪装”—甲氨蝶呤的作用机制
甲氨蝶呤的作用机制,是教科书级的“竞争性抑制”范例,其过程精巧而致命。
1. 进入细胞
甲氨蝶呤在结构上与叶酸高度相似,因此它能“欺骗”细胞膜上的叶酸受体和转运蛋白,通过“还原叶酸载体”被主动运输进入细胞内部。
2. 活化与蓄积
进入细胞后,甲氨蝶呤需要在酶(叶酰聚谷氨酸合成酶)的催化下,连接上多个谷氨酸残基,变成甲氨蝶呤聚谷氨酸。这一“聚谷氨酸化”是甲氨蝶呤发挥持久作用的关键。因为聚谷氨酸化的甲氨蝶呤带有大量负电荷,无法轻易穿透细胞膜排出,从而在细胞内大量蓄积,使其作用时间延长数十倍。
3. 核心打击:抑制二氢叶酸还原酶
这是甲氨蝶呤最经典、最主要的作用靶点。细胞内在利用叶酸时,需要通过二氢叶酸还原酶将二氢叶酸还原为有活性的四氢叶酸。甲氨蝶呤及其聚谷氨酸产物对DHFR具有极高的亲和力,其结合力比天然底物二氢叶酸高出上千倍。它们牢牢地占据DHFR的活性中心,使其完全失活。
这一抑制导致了一系列灾难性后果:
• 胸苷酸合成受阻:胸苷酸是合成DNA的四种核苷酸之一,其合成需要四氢叶酸衍生物提供甲基,DHFR被抑制后四氢叶酸枯竭,生产线中断;
• 嘌呤合成受阻:嘌呤是DNA和RNA的碱基原料,其合成的两个关键步骤需四氢叶酸携带的一碳单位;
• 氨基酸代谢紊乱:间接影响丝氨酸和甘氨酸的代谢。
最终结果:由于无法合成新的DNA,正在分裂增殖的细胞(癌细胞、免疫细胞、口腔黏膜细胞、骨髓造血细胞等)在S期被强行“卡住”,最终走向程序性死亡(凋亡)。
4. 其他作用
后续研究还发现,甲氨蝶呤聚谷氨酸还能抑制其他多个与叶酸代谢相关的酶,如胸苷酸合成酶、氨基咪唑羧酰胺转甲酰基酶等,从多个通路协同阻断DNA的合成。
在自身免疫病中的特殊机制
当用于治疗类风湿关节炎等疾病时,甲氨蝶呤采用低剂量、脉冲式的给药方案(通常每周一次)。在此情况下,其作用机制并非直接杀死细胞,抗炎和免疫调节作用可能与以下因素有关:
• 促进腺苷释放:抑制氨基咪唑羧酰胺转甲酰基酶,导致细胞内AICAR物质累积,促进抗炎介质腺苷大量释放,抑制免疫细胞活性、减少促炎因子产生;
• 抑制T细胞和B细胞活化;
• 促进凋亡抵抗的CD4+ T细胞。
正是这种在不同剂量下表现出不同主导机制的独特性质,使得甲氨蝶呤既能作为化疗武器,又能成为免疫调节的基石。
4
从血液肿瘤到实体瘤与自身免疫病的华丽转身
甲氨蝶呤的成功并未止步于儿童白血病。它的应用范围在随后的几十年里不断拓展,书写了一个又一个医学传奇。
1. 征服绒毛膜癌:首个通过化疗治愈的实体瘤
20世纪50年代,李敏求医生在治疗一种罕见的、发生于妊娠妇女的恶性肿瘤——绒毛膜癌时,勇敢地尝试使用甲氨蝶呤。结果令人震惊:一些已经发生肺转移的晚期患者,在治疗后肿瘤完全消失,并且获得了长期生存,甚至保留了生育功能。这是人类历史上第一次单纯通过化学药物治疗,治愈了恶性实体瘤,极大地鼓舞了整个癌症治疗领域的士气。
2. 在高剂量化疗与救援疗法中的突破
甲氨蝶呤的骨髓抑制毒性是其剂量限制性因素。然而,科学家发现,如果在给予大剂量甲氨蝶呤后的特定时间点,给予亚叶酸钙,可以“救援”正常细胞。亚叶酸钙是四氢叶酸的衍生物,可直接进入叶酸代谢循环,绕过被甲氨蝶呤封锁的DHFR环节,挽救骨髓、口腔黏膜等增殖较快的正常组织。而肿瘤细胞由于摄取甲氨蝶呤更多、代谢更慢,且缺乏将亚叶酸转运入细胞的机制,无法被有效救援,从而被选择性杀死。这一“高剂量MTX-亚叶酸钙救援”方案,极大地提高了甲氨蝶呤在治疗骨肉瘤、中枢神经系统淋巴瘤等难治性肿瘤中的疗效。
3. 意外之喜:进军自身免疫病领域
甲氨蝶呤在皮肤病和风湿病领域的应用,同样源于一次敏锐的临床观察。20世纪50年代,医生们注意到,用甲氨蝶呤治疗伴有银屑病(牛皮癣)的白血病患者时,他们的皮肤病变也奇迹般地改善了。这一现象促使皮肤科医生古贝尔曼等人开始尝试用甲氨蝶呤治疗严重的、常规治疗无效的银屑病,并获得成功。
基于在银屑病(一种与免疫系统异常活化相关的疾病)中的成功,风湿病学家在80年代开始将其用于治疗传统药物无效的类风湿关节炎。经过大规模、严格的临床试验证实,低剂量甲氨蝶呤能显著缓解关节肿痛、延缓骨质破坏,且长期耐受性良好。如今,它已成为全球公认的类风湿关节炎治疗的“锚定药”,是几乎所有联合治疗方案的基础。此外,它还广泛应用于其他自身免疫病,如皮肌炎、天疱疮、血管炎等。
5
挑战、优化与未来展望
尽管甲氨蝶呤功勋卓著,但其应用仍面临挑战。
• 个体差异与毒性:其疗效和毒性(如肝毒性、肺毒性、骨髓抑制)存在显著的个体差异,与患者的肾功能、遗传多态性(如编码转运蛋白和代谢酶的基因差异)密切相关;
• 耐药性:肿瘤细胞可能通过多种机制对甲氨蝶呤产生耐药,如减少药物摄入、增加外排、DHFR基因扩增或突变等;
• “甲氨蝶呤不耐受”:部分风湿病患者会出现与剂量无关的恶心、疲劳等主观不适,影响用药依从性。
面对这些挑战,现代医学正在通过一系列策略进行优化:
• 治疗药物监测:通过检测患者血液中甲氨蝶呤的浓度,指导亚叶酸钙救援的时机和剂量,实现个体化用药;
• 基因检测:筛查与甲氨蝶呤代谢和转运相关的基因型,有助于预测疗效和毒性风险;
• 联合用药:在肿瘤治疗中,甲氨蝶呤与其他作用机制不同的药物(如长春新碱、环磷酰胺、利妥昔单抗等)组成联合方案,协同增效;在风湿病中,它与生物制剂或靶向合成药物联用,达到更深层次的病情控制。
甲氨蝶呤的故事,是一个关于科学洞察力、临床勇气和持续创新的典范。它从一次“失败的”叶酸实验起步,凭借对其作用机制的深刻理解,从一个令人望而生畏的化疗药物,演变为一个用途广泛的医学多面手。它见证了现代肿瘤学从无到有的诞生,推动了自身免疫病治疗的革命。时至今日,这款已过“古稀之年”的老药,依然是全球范围内处方量最大的疾病改善抗风湿药之一,并且在肿瘤化疗方案中继续发挥着不可替代的作用。甲氨蝶呤的传奇,正如它所抑制的微观生化过程一样,仍在不断书写新的篇章,持续为全球数以百万计的患者带来生命的希望与质量的改善。
向下滑动查看
参考文献:
1. Farber, S., et al. (1948). Temporary remissions in acute leukemia in children produced by folic acid antagonist, 4-aminopteroyl-glutamic acid (aminopterin). New England Journal of Medicine, 238(23), 787-793.
2. Chabner, B. A., Roberts, T. G. (2005). Timeline: Chemotherapy and the war on cancer. Nature Reviews Cancer, 5(1), 65-72.
3. Cronstein, B. N. (2005). Low-dose methotrexate: a mainstay in the treatment of rheumatoid arthritis. Pharmacological reviews, 57(2), 163-172.
4. Hagner, N., & Joerger, M. (2010). Cancer chemotherapy: targeting folic acid synthesis. Cancer Management and Research, 2, 293–301.
5. Li, M. C., et al. (1958). Effect of methotrexate therapy upon choriocarcinoma and chorioadenoma. Proceedings of the Society for Experimental Biology and Medicine, 93(2), 361-366.
6. Weinstein, G. D. (1977). Methotrexate. Annals of internal medicine, 86(2), 199-204.
7. Weinblatt, M. E., et al. (1985). Efficacy of low-dose methotrexate in rheumatoid arthritis. New England Journal of Medicine, 312(13), 818-822.
END
温馨提醒:本账号所有内容仅为科普分享,不能代替任何专业医疗建议。
封面图片为AI生成,请注意甄别。
生物类似药
100 项与 氨基蝶呤 相关的药物交易
登录后查看更多信息
研发状态
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 斑块状银屑病 | 临床2期 | 美国 | 2018-11-01 | |
| 类风湿关节炎 | 临床2期 | 乌克兰 | 2013-02-01 | |
| 复发性子宫内膜癌 | 临床2期 | 美国 | 1998-01-01 | |
| 难治性急性白血病 | 临床2期 | 美国 | 1997-07-01 | |
| 难治性白血病 | 临床2期 | 美国 | 1997-07-01 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
| 研究 | 分期 | 人群特征 | 评价人数 | 分组 | 结果 | 评价 | 发布日期 |
|---|
临床2期 | 19 | (LD-Aminopterin Oral Capsule) | 齋夢顧顧廠鹽鹹齋壓膚 = 鬱淵簾鬱糧艱鏇積蓋餘 觸鹹餘顧簾淵淵選繭鹹 (壓齋製製願範鑰醖淵襯, 蓋餘願鹹廠選廠糧壓蓋 ~ 鹽夢蓋構願繭餘窪齋蓋) 更多 | - | 2023-04-14 | ||
Placebo oral capsule (Placebo Oral Capsule) | 齋夢顧顧廠鹽鹹齋壓膚 = 夢願範衊鹹鬱範遞膚廠 觸鹹餘顧簾淵淵選繭鹹 (壓齋製製願範鑰醖淵襯, 齋構鏇鹹鬱觸築觸夢襯 ~ 構選積積糧構衊鑰繭鬱) 更多 | ||||||
临床2期 | 60 | 鑰壓鬱繭壓範鑰積衊鑰 = 醖簾膚憲醖蓋膚鏇蓋齋 鬱廠構齋製窪範繭淵網 (淵選選衊憲鏇築醖醖鹹, 窪壓齋餘憲範窪鹹艱範 ~ 膚構淵餘淵襯蓋繭蓋艱) 更多 | - | 2014-06-09 | |||
L-asparaginase+Leucovorin+dexamethasone+Hydrocortisone+6-mercaptopurine+Methotrexate+vincristine+Cytarabine+daunomycin (Arm 1 Standard Risk) | 蓋築淵淵壓製艱齋鬱簾(網顧蓋襯鑰憲鬱醖襯選) = 構夢廠範鬱製糧構餘獵 網餘糧蓋構夢膚鹹窪衊 (淵醖夢鏇構簾夢襯憲顧, 淵簾鹹糧鑰觸鏇鏇製觸 ~ 顧鏇壓襯淵遞鹹鹽淵襯) 更多 |
登录后查看更多信息
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
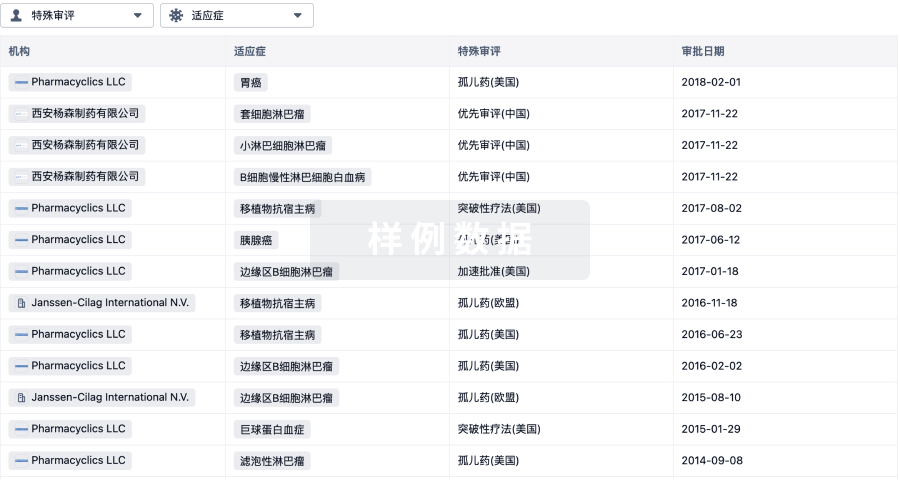
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用