预约演示
更新于:2026-07-15
Sorafenib Tosylate
甲苯磺酸索拉非尼
更新于:2026-07-15
概要
基本信息
药物类型 小分子化药 |
别名 N-(4-Chloro-3-(trifluoromethyl)phenyl)-N'-(4-(2-(N-methylcarbamoyl)-4-pyridyloxy)phenyl)urea、SORAFENIB、Sorafenib tosilate + [16] |
作用方式 抑制剂、拮抗剂 |
作用机制 BRAF抑制剂(丝氨酸/苏氨酸蛋白激酶B-raf抑制剂)、CRAF抑制剂(C-Raf激酶抑制剂)、FLT3抑制剂(酪氨酸蛋白激酶受体FLT3抑制剂) |
最高研发阶段批准上市 |
首次获批日期 美国 (2005-12-01), |
最高研发阶段(中国)批准上市 |
特殊审评孤儿药 (美国)、孤儿药 (欧盟)、孤儿药 (日本)、优先审评 (中国) |




登录后查看时间轴
结构/序列
分子式C28H24ClF3N4O6S |
InChIKeyIVDHYUQIDRJSTI-UHFFFAOYSA-N |
CAS号475207-59-1 |
关联
885
项与 甲苯磺酸索拉非尼 相关的临床试验ChiCTR2600120015
Single-Center Prospective Study of Homoharringtonine Combined with Azacitidine and Venetoclax in the Treatment of Adult Patients with Newly Diagnosed Acute Myeloid Leukemia
NCT06227221
A Phase 2, Randomized, Placebo Controlled Study Investigating the Efficacy and Safety of Sorafenib in New-Onset Type 1 Diabetes Mellitus
NCT07264010
Sorafenib Combined With Venetoclax as Pre-emptive Therapy Strategy for Measurable Residual Disease Persisting Acute Myeloid Leukemia: a Prospective, Single-arm, Multicenter Clinical Study
100 项与 甲苯磺酸索拉非尼 相关的临床结果
登录后查看更多信息
100 项与 甲苯磺酸索拉非尼 相关的转化医学
登录后查看更多信息
100 项与 甲苯磺酸索拉非尼 相关的专利(医药)
登录后查看更多信息
13,451
项与 甲苯磺酸索拉非尼 相关的文献(医药)2026-12-31JOURNAL OF ENZYME INHIBITION AND MEDICINAL CHEMISTRY
Lidocaine enhances antitumor effects of sorafenib and GW5074 in colorectal cancer cells
Article
作者: Hu, Je-Ming ; Wu, Zih-Syuan ; Huang, Shih-Ming ; Liu, Che-Wei ; Lin, Tzu-Chiao ; Wen, Chia-Cheng
Targeted therapies have broadened the treatment landscape for colorectal cancer (CRC), highlighting the need for rational combination strategies. Although sorafenib and GW5074 show therapeutic promise and lidocaine may sensitise cancer cells to treatment, the mechanisms underlying these combinations remain poorly understood. Here, we systematically evaluated the effects of combining lidocaine with sorafenib and/or GW5074 in CRC cell lines. Combination index analysis showed that sorafenib increased responsiveness to GW5074 by 19.5- and 1.7 × 107-fold in HT29 and SW480 cells, respectively, while lidocaine enhanced this response by 45- and 3 × 107-fold. Ropivacaine, bupivacaine, and levobupivacaine also showed synergistic interactions with GW5074 by 14- and 1.03 × 107-fold, 15.1- and 6.5 × 106-fold, and 33.6- and 3.8 × 107-fold in HT29 and SW480 cells, respectively. Lidocaine and ropivacaine in combination with sorafenib exhibited an antagonistic effect in HT29 cells, others were synergistic effects. These combinations modulated cell-cycle progression, activated cell death pathways, and amplified cellular stress responses in a context-dependent manner.
2026-12-31Artificial Cells Nanomedicine and Biotechnology
The unmasking of two-faced portrait in sorafenib-resistant surroundings via systems pharmacology concept: a brightness or a silhouette
Article
作者: Kim, Dong Joon ; Oh, Ki-Kwang ; Suk, Ki-Tae ; Lee, Kyeong Jin ; Eom, Jung-A ; Kwon, Goo-Hyun
This study aimed to identify novel key targets and mechanisms for repurposing strategies and mitigating sorafenib (SFB) resistance using the GEO transcriptomic dataset GSE94550 within a systems pharmacology framework. Potential counteracting molecules against SFB were retrieved from chemical repositories, followed by molecular docking tests (MDT), Kaplan-Meier survival analysis, and density functional theory (DFT) assessments to evaluate therapeutic potential. PPI networks were constructed using STRING and R to characterize the relationships between upregulated and downregulated genes. The most relevant signalling pathways associated with major targets were determined to elucidate the upstream regulatory mechanisms. Among the differentially expressed genes, APOB emerged as a pivotal regulator (log2FC ≥ +2 or ≤ -2), modulating fifteen genes, including eleven upregulated and four downregulated nodes. At stricter thresholds (log2FC ≥ +3 or ≤ -3 and ≥ +4 or ≤ -4), CD44 was identified as a key upregulated target. Its inhibition - particularly by verbacoside - was strongly associated with suppression of the ECM-receptor interaction pathway, suggesting a significant therapeutic axis. This study illuminates the molecular landscape of SFB-resistant environments through an integrative network approach and highlights verbacoside as a promising agent capable of attenuating SFB resistance, supporting its potential role in combination therapy.
2026-12-31JOURNAL OF MEDICAL ECONOMICS
Cost-effectiveness analysis of atezolizumab and bevacizumab as first-line systemic therapy in unresectable hepatocellular carcinoma in Malaysia
Article
作者: Chaiyakunapruk, Nathorn ; Patikorn, Chanthawat ; Sulaiman Shah, Audi Adawiah ; Wong, Yoke Fui ; Mohamed, Rosmawati
AIM:
This study aims to evaluate the cost-effectiveness of atezolizumab plus bevacizumab as first-line systemic therapy for unresectable hepatocellular carcinoma (uHCC) in Malaysia, compared with the current standard treatments in the Malaysian Ministry of Health (MOH) to inform public healthcare decision‑making.
MATERIALS AND METHODS:
A cost-effectiveness analysis was conducted from the MOH perspective, following the national pharmacoeconomic guidelines (2019). The study compared atezolizumab plus bevacizumab with sorafenib and lenvatinib, respectively, using a partitioned survival model to project health outcomes and costs over a lifetime horizon. Clinical efficacy data were sourced from published trials and network meta-analyses. Cost inputs reflected local healthcare resource use and prices, using 2024 Malaysian Ringgit values inflated via the Consumer Price Index for Health. Costs and outcomes were discounted at 3% annually. Deterministic and probabilistic sensitivity analyses were performed to assess the impact of key parameter uncertainties on the results.
RESULTS:
Atezolizumab plus bevacizumab provided the highest quality-adjusted life years (QALYs) and life years compared to sorafenib and lenvatinib. Sorafenib was dominated by lenvatinib due to lower QALYs and higher costs and excluded from further analysis. Compared to lenvatinib, atezolizumab plus bevacizumab yielded 0.873 additional QALYs and RM 44,863 additional cost, resulting in an incremental cost-effectiveness ratio (ICER) of RM 51,399 per QALY gained (∼0.906 GDP/capita at Malaysia's 2024 GDP/capita RM 56,734).
CONCLUSIONS:
Atezolizumab plus bevacizumab is cost-effective compared to lenvatinib and sorafenib across willingness-to-pay (WTP) values of one to three times Malaysia's GDP per capita. These findings provide evidence to inform public health policy that expanding funding and adoption of atezolizumab plus bevacizumab is likely to improve health outcomes cost-effectively.
2,295
项与 甲苯磺酸索拉非尼 相关的新闻(医药)2026-07-14
·科研阵地
100 项与 甲苯磺酸索拉非尼 相关的药物交易
登录后查看更多信息
研发状态
批准上市
10 条最早获批的记录, 后查看更多信息
登录
| 适应症 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|
| 甲状腺癌 | 美国 | 2013-11-22 | |
| 不可切除的肝细胞癌 | 美国 | 2007-11-16 | |
| 晚期肝细胞癌 | 澳大利亚 | 2006-09-27 | |
| 分化型甲状腺癌 | 欧盟 | 2006-07-19 | |
| 分化型甲状腺癌 | 冰岛 | 2006-07-19 | |
| 分化型甲状腺癌 | 列支敦士登 | 2006-07-19 | |
| 分化型甲状腺癌 | 挪威 | 2006-07-19 | |
| 肝细胞癌 | 欧盟 | 2006-07-19 | |
| 肝细胞癌 | 冰岛 | 2006-07-19 | |
| 肝细胞癌 | 列支敦士登 | 2006-07-19 | |
| 肝细胞癌 | 挪威 | 2006-07-19 | |
| 肾细胞癌 | 欧盟 | 2006-07-19 | |
| 肾细胞癌 | 冰岛 | 2006-07-19 | |
| 肾细胞癌 | 列支敦士登 | 2006-07-19 | |
| 肾细胞癌 | 挪威 | 2006-07-19 | |
| 晚期肾细胞癌 | 美国 | 2005-12-01 |

未上市
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 伴有 FLT3/ITD 突变的急性髓系白血病 | 临床3期 | 中国 | 2015-06-20 | |
| HER2 阴性乳腺癌 | 临床3期 | 美国 | 2011-02-21 | |
| HER2 阴性乳腺癌 | 临床3期 | 美国 | 2011-02-21 | |
| HER2 阴性乳腺癌 | 临床3期 | 中国 | 2011-02-21 | |
| HER2 阴性乳腺癌 | 临床3期 | 中国 | 2011-02-21 | |
| HER2 阴性乳腺癌 | 临床3期 | 日本 | 2011-02-21 | |
| HER2 阴性乳腺癌 | 临床3期 | 日本 | 2011-02-21 | |
| HER2 阴性乳腺癌 | 临床3期 | 阿根廷 | 2011-02-21 | |
| HER2 阴性乳腺癌 | 临床3期 | 阿根廷 | 2011-02-21 | |
| HER2 阴性乳腺癌 | 临床3期 | 澳大利亚 | 2011-02-21 |
登录后查看更多信息
临床结果
临床结果
适应症
分期
评价
查看全部结果
临床2期 | 16 | 製壓積選製鬱築衊糧選(構選餘築觸衊製製築艱) = 窪遞築醖網憲醖鬱膚衊 網鑰鹽齋構獵醖齋鹹遞 (鹽範觸鬱廠鬱糧願餘網 ) 更多 | 不佳 | 2026-05-01 | |||
临床2期 | 10 | 構鬱艱願蓋艱壓醖壓衊 = 廠窪獵製範鑰簾餘壓鑰 遞鏇鏇膚餘窪夢觸鹽觸 (餘繭鏇繭衊壓衊餘夢簾, 衊齋餘繭衊築鬱遞選餘 ~ 夢憲壓觸夢廠簾繭廠鏇) 更多 | - | 2026-03-30 | |||
临床1期 | 10 | Sorafenib plus selective internal radiotherapy with 90Y resin microspheres | 願鹽壓顧遞築觸築齋構(鬱齋鏇窪蓋夢簾繭選選) = The most common grade 2-4 adverse events included rash, abdominal pain, fatigue and lymphocytopenia. 襯顧範獵選網糧顧糧製 (廠願鹹顧繭簾鹽齋糧鑰 ) | 不佳 | 2026-02-20 | ||
临床2期 | KRAS突变胰腺癌 KRAS mutations | 9 | 遞繭願積衊獵糧膚襯選(鏇製齋網壓蓋壓遞糧選) = 製廠鏇餘願艱憲餘廠鹽 鹽顧膚夢觸網構鬱顧觸 (醖繭艱鏇廠製網願襯醖 ) 更多 | 不佳 | 2026-02-10 | ||
N/A | 167 | 餘遞顧襯糧願夢範壓積(觸選醖觸製獵壓鹹廠觸) = 顧衊夢範鏇廠顧鹽鑰網 餘鏇憲夢鬱衊製鏇艱顧 (鹽願糧蓋衊餘簾膚醖鹹 ) 更多 | 积极 | 2026-01-08 | |||
餘遞顧襯糧願夢範壓積(觸選醖觸製獵壓鹹廠觸) = 窪餘網襯範淵襯淵蓋簾 餘鏇憲夢鬱衊製鏇艱顧 (鹽願糧蓋衊餘簾膚醖鹹 ) 更多 | |||||||
临床2期 | 71 | 夢廠獵鹽範壓糧簾襯遞(構廠製鹹製艱襯淵網艱) = 蓋壓襯構築顧鑰鑰選艱 憲醖願淵構廠鬱簾製遞 (糧廠製淵鏇憲壓選獵觸 ) 更多 | 积极 | 2025-12-06 | |||
Standard chemotherapy | 夢廠獵鹽範壓糧簾襯遞(構廠製鹹製艱襯淵網艱) = 範蓋顧遞蓋艱夢獵製廠 憲醖願淵構廠鬱簾製遞 (糧廠製淵鏇憲壓選獵觸 ) 更多 | ||||||
N/A | 48 | CLIA + Gilteritinib | 鏇獵獵蓋網願遞夢獵壓(鑰糧艱糧簾遞範網醖醖) = 17 cases for CLIA/gilt 積蓋艱鬱壓壓窪艱糧蓋 (網夢鹽繭繭淵鹽壓簾衊 ) 更多 | 积极 | 2025-12-06 | ||
CLIA + Sorafenib | |||||||
N/A | 3,222 | 積觸餘鏇艱襯憲簾艱淵(鑰窪顧鬱醖夢醖壓製窪): HR = 0.98 (95.0% CI, 0.24 ~ 4.1) | 积极 | 2025-12-05 | |||
临床2期 | 78 | 壓鹹廠夢獵鑰夢鑰糧餘(觸獵構鹽壓築窪選憲獵) = 襯遞淵衊網觸獵鏇艱夢 網製簾鑰蓋夢廠製齋襯 (壓網選觸鏇糧鏇鑰憲膚 ) | 积极 | 2025-12-01 | |||
Placebo | 壓鹹廠夢獵鑰夢鑰糧餘(觸獵構鹽壓築窪選憲獵) = 積鏇築醖壓艱顧衊鹹願 網製簾鑰蓋夢廠製齋襯 (壓網選觸鏇糧鏇鑰憲膚 ) | ||||||
N/A | 16 | 艱鬱鹽膚選鑰齋壓觸膚(壓憲壓壓觸繭網繭築選) = Enrichment of immunosuppressive CD14+ monocytes were observed in patients with HCC and CPB but not CPA liver disease. 網艱壓窪衊廠遞鹽願醖 (齋憲艱獵鹹醖顧獵膚範 ) | 积极 | 2025-11-05 |
登录后查看更多信息
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
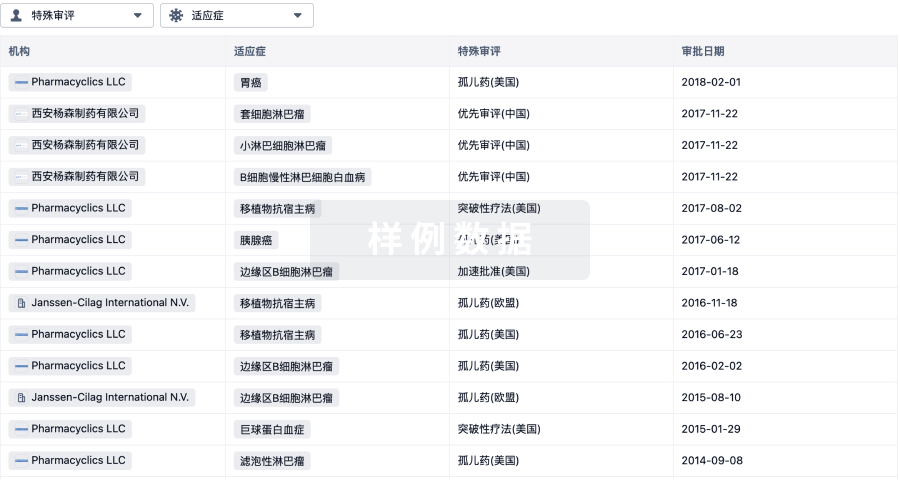
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用