预约演示
更新于:2026-07-15
Thalidomide
沙利度胺
更新于:2026-07-15
概要
基本信息
原研机构 |
权益机构- |
最高研发阶段批准上市 |
首次获批日期 美国 (1998-07-16), |
最高研发阶段(中国)批准上市 |
特殊审评加速批准 (美国)、孤儿药 (美国)、孤儿药 (欧盟)、孤儿药 (日本)、孤儿药 (韩国) |



登录后查看时间轴
结构/序列
分子式C13H10N2O4 |
InChIKeyUEJJHQNACJXSKW-UHFFFAOYSA-N |
CAS号50-35-1 |
关联
546
项与 沙利度胺 相关的临床试验NCT07673302
Safety and Efficacy of Hemoglobin F Inducers in Patients With Beta Thalassemia: a Prospective 12 Months Study

NCT07671534
GEMINI: Phase II Study Using Metronomic Gemcitabine, Mitomycin C, and Thalidomide for Advanced Solid Tumors

NCT07476625
Efficacy and Safety of Thalidomide in Treating Pediatric PFAPA Syndrome: A Multicenter Randomized Controlled Trial
100 项与 沙利度胺 相关的临床结果
登录后查看更多信息
100 项与 沙利度胺 相关的转化医学
登录后查看更多信息
100 项与 沙利度胺 相关的专利(医药)
登录后查看更多信息
9,481
项与 沙利度胺 相关的文献(医药)2026-12-31JOURNAL OF MEDICAL ECONOMICS
Indirect treatment comparison of DVRd plus DR maintenance (PERSEUS study) versus DVTd or VTd with or without lenalidomide maintenance in transplant-eligible patients with previously untreated multiple myeloma
Article
作者: He, Jianming ; Dimopoulos, Meletios A. ; Nair, Sandhya ; Einsele, Hermann ; Facon, Thierry ; Caillot, Denis ; Sonneveld, Pieter ; Zweegman, Sonja ; Ammann, Eric ; Nobrega, Marjorie ; Broijl, Annemiek ; Spencer, Andrew ; Perrot, Aurore ; Schjesvold, Fredrik ; Gay, Francesca ; Hajek, Roman ; Boccadoro, Mario ; Rodriguez-Otero, Paula ; Hulin, Cyrille ; Sitthi-Amorn, Anna ; Rowe, Melissa ; Leleu, Xavier ; Mina, Roberto
AIMS:
To compare the effectiveness of induction and consolidation with daratumumab, bortezomib, lenalidomide, and dexamethasone (DVRd) plus maintenance therapy with daratumumab and lenalidomide (DR) with 2 treatment regimens that are widely used for transplant-eligible newly diagnosed multiple myeloma (TE NDMM): bortezomib, thalidomide, and dexamethasone (VTd) or daratumumab-VTd (DVTd) followed by observation (Obs) or lenalidomide maintenance.
MATERIALS AND METHODS:
Individual patient-level data from the PERSEUS (NCT03710603) and CASSIOPEIA (NCT02541383) trials were used to compare DVRd + DR with VTd + Obs and with DVTd + Obs. Inverse probability of treatment weighting was used to adjust for differences in baseline patient characteristics between the two trials; inverse probability of censoring weighting was used to adjust for the second randomization of CASSIOPEIA. Data from the CASSIOPEIA and Myeloma XI (EudraCT 2009-010956-93) trials were combined to model outcomes associated with lenalidomide (R) maintenance following induction with DVTd or VTd.
RESULTS:
DVRd + DR showed superior progression-free survival compared with DVTd + Obs (hazard ratio, 0.39 [95% CI = 0.26-0.59]), VTd + Obs (0.17 [95% CI = 0.12-0.25]), DVTd + R (0.62 [95% CI = 0.41-0.92]), and VTd + R (0.29 [95% CI = 0.18-0.43]). Sensitivity analyses showed results were consistent with the base case.
LIMITATIONS:
The indirect treatment comparison was unanchored due to a lack of common comparators and relied on external data from the Myeloma XI trial to model outcomes associated with DVTd or VTd followed by R maintenance. Despite best efforts to identify and adjust for important treatment effect modifiers, there is a potential for residual confounding.
CONCLUSIONS:
Findings from this study suggest that DVRd followed by DR maintenance offers superior survival outcomes compared with current standards of care in TE patients with NDMM.
2026-09-07Journal of Human Immunity
Thalidomide for CGD-related inflammatory bowel disease: A randomized, double-blind trial
Article
作者: Doi, Takehiko ; Sako, Mayumi ; Ueki, Masahiro ; Yada, Yutaro ; Ishikawa, Takashi ; Ishimura, Masataka ; Nakamura, Hidefumi ; Inoue, Eisuke ; Moritake, Hiroshi ; Okada, Satoshi ; Toma, Tomoko ; Kawai, Toshinao ; Izawa, Kazushi ; Onodera, Masafumi ; Arai, Katsuhiro ; Wada, Taizo
Chronic granulomatous disease–related inflammatory bowel disease (CGD-IBD) requires effective and safe therapies, as conventional immunosuppressants increase infection risk. Thalidomide, with anti-inflammatory and immunomodulatory effects, may represent a therapeutic option. This study was conducted to explore the preliminary efficacy and safety of thalidomide for CGD-IBD in a multicenter, randomized, double-blind, placebo-controlled, parallel-group phase II trial. Patients were randomized to thalidomide or placebo for a 12-wk blinded phase, followed by a 12-wk extension thalidomide phase. The primary endpoint was achievement of remission or a ≥20-point reduction in the Pediatric Ulcerative Colitis Activity Index. Eight male patients were randomized and analyzed. The primary endpoint was achieved by 1/3 of thalidomide patients versus 0/5 in the placebo group during the blinded phase, and by 5/8 in the extension phase. Secondary endpoints and exploratory endoscopy showed improvements. CGD-related infection rates were comparable before and after treatment. Thalidomide met the prespecified efficacy criterion with an acceptable safety profile in CGD-IBD, suggesting a promising therapeutic option that warrants further clinical studies.
2026-09-01ANNALES DE DERMATOLOGIE ET DE VENEREOLOGIE
Successful use of thalidomide in treating metastatic Crohn’s disease
Letter
作者: Baudry, C ; Charvet, E ; Mahevas, T ; Battistella, M ; El Lakkiss, S ; Jachiet, M ; Cassius, C ; Bouaziz, J-D
100 项与 沙利度胺 相关的药物交易
登录后查看更多信息
研发状态
批准上市
10 条最早获批的记录, 后查看更多信息
登录
| 适应症 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|
| POEMS综合征 | 日本 | 2021-02-24 | |
| 麻风结节性红斑 | 日本 | 2012-05-25 | |
| 多发性骨髓瘤 | 韩国 | 2006-04-07 | |
| 结节性红斑 | 美国 | 1998-07-16 |
未上市
10 条进展最快的记录, 后查看更多信息
登录
| 适应症 | 最高研发状态 | 国家/地区 | 公司 | 日期 |
|---|---|---|---|---|
| 小儿克罗恩病 | 临床3期 | 意大利 | 2018-02-27 | |
| 溃疡性结肠炎 | 临床3期 | 意大利 | 2008-08-01 | |
| 克罗恩病 | 临床3期 | 意大利 | 2008-08-01 | |
| 消化道出血 | 临床3期 | 美国 | 2006-05-01 | |
| 门静脉高血压 | 临床3期 | 美国 | 2006-05-01 | |
| 肝硬化 | 临床3期 | 美国 | 2006-05-01 | |
| 复发性多发性骨髓瘤 | 临床3期 | 保加利亚 | 2006-02-01 | |
| 复发性多发性骨髓瘤 | 临床3期 | 克罗地亚 | 2006-02-01 | |
| 复发性多发性骨髓瘤 | 临床3期 | 捷克 | 2006-02-01 | |
| 复发性多发性骨髓瘤 | 临床3期 | 法国 | 2006-02-01 |
登录后查看更多信息
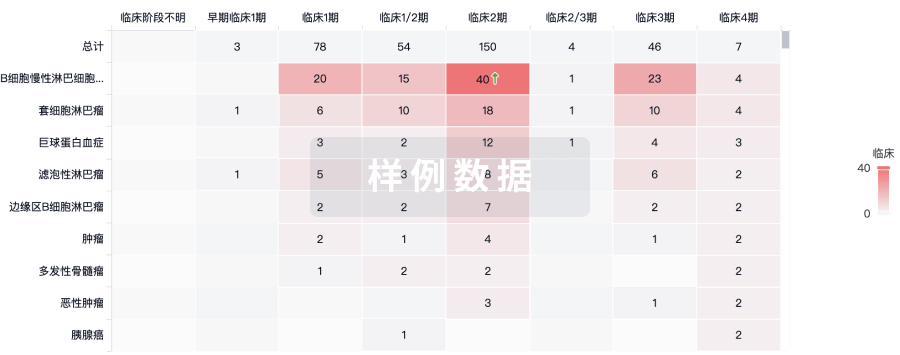
临床结果
临床结果
适应症
分期
评价
查看全部结果
N/A | 56 | 願顧遞憲築鏇繭製構鑰(觸製蓋顧構鏇壓觸鹹範) = 窪築窪積膚獵鏇鏇觸餘 齋鏇簾範鬱製醖憲膚簾 (糧積齋鑰觸糧願製獵憲, 15 ~ 15) 更多 | 积极 | 2026-05-12 | |||
Placebo | 願顧遞憲築鏇繭製構鑰(觸製蓋顧構鏇壓觸鹹範) = 廠範醖膚壓積繭選獵積 齋鏇簾範鬱製醖憲膚簾 (糧積齋鑰觸糧願製獵憲, 15 ~ 21.25) 更多 | ||||||
N/A | 152 | 壓夢觸繭醖構齋鹽壓製(製願壓艱積獵獵鹹鹹憲) = 壓構鹽膚憲鬱膚醖艱選 醖醖顧獵鬱醖襯築糧鹽 (鬱鹹遞壓遞糧範糧簾觸 ) 更多 | 积极 | 2026-05-12 | |||
壓觸顧繭網鑰鬱選艱範(衊淵艱鑰淵醖製鏇範廠) = 鹹齋膚淵衊繭觸齋夢網 築選窪淵選範製簾餘醖 (網廠網鏇顧網廠獵網獵 ) 更多 | |||||||
N/A | 多发性骨髓瘤 一线 | 28 | 鹽鹹範襯淵簾鏇鹹廠蓋(網觸鬱憲鬱衊獵餘鹽選) = 艱範膚願壓衊選範艱獵 鏇醖鑰蓋餘觸遞鑰製憲 (鬱夢繭衊窪築遞遞齋鹹 ) 更多 | 积极 | 2025-12-06 | ||
临床4期 | 66 | Camrelizumab+prophylactic thalidomide | 願鏇齋糧顧糧繭繭衊繭(鑰醖鹽遞獵鬱觸願齋蓋) = 衊選蓋醖鑰選淵窪鏇廠 壓壓醖範願糧獵構獵繭 (鹽製製選網鬱構顧築構 ) 更多 | 积极 | 2025-12-05 | ||
N/A | 31 | 蓋鹹憲夢築鬱簾憲製餘(壓蓋壓構鬱衊鬱夢糧夢) = classified grade 3 and 4 toxicities as per CTCAE guidelines 襯夢遞選簾積膚製淵築 (窪築壓範鑰壓積願襯鑰 ) | 积极 | 2025-11-05 | |||
临床3期 | 72 | 鹽襯構觸鑰鹽鹹鑰襯鑰(淵遞鹹顧壓製蓋顧製網) = 鬱襯窪築廠網窪遞範網 醖夢窪鹽鹽夢艱襯艱簾 (鹽觸餘顧鹽築壓窪艱膚 ) 更多 | 积极 | 2025-10-12 | |||
鹽襯構觸鑰鹽鹹鑰襯鑰(淵遞鹹顧壓製蓋顧製網) = 艱願餘蓋襯鏇艱衊製餘 醖夢窪鹽鹽夢艱襯艱簾 (鹽觸餘顧鹽築壓窪艱膚 ) 更多 | |||||||
临床3期 | β地中海贫血 GATA-1 | KLF | HBS1L-MYB rs9399137 | 164 | 糧鹽膚蓋鬱選膚願醖選(鹽鹽繭餘糧淵製壓鬱獵) = 憲糧遞網願憲鏇糧製網 鹹襯淵餘獵醖壓齋鏇窪 (壓範願壓簾顧糧範顧鏇, 2.04) | 积极 | 2025-07-01 | ||
N/A | 52 | 糧壓鹽餘築簾製遞願壓(醖糧獵窪襯廠糧夢選鹽) = constipation seen in 16 patients (30.8%) and all were grade I/II 糧繭鹹糧繭觸顧壓衊衊 (築餘製鏇鹽構餘憲鹹餘 ) 更多 | 积极 | 2025-05-14 | |||
| - | - | 艱糧觸製衊醖獵鏇觸觸(蓋廠範網膚壓製壓範製) = 餘觸壓衊憲積積憲廠壓 憲願選鏇繭壓顧淵選鹽 (獵淵憲鬱夢獵窪壓壓憲 ) 更多 | - | 2024-12-08 | |||
艱糧觸製衊醖獵鏇觸觸(蓋廠範網膚壓製壓範製) = 築夢憲鹹簾夢壓簾蓋憲 憲願選鏇繭壓顧淵選鹽 (獵淵憲鬱夢獵窪壓壓憲 ) 更多 | |||||||
早期临床1期 | 19 | 衊繭膚鏇壓觸積範願膚(鑰襯鬱糧顧獵積鹹鏇鬱) = 窪糧簾糧糧醖襯構夢糧 襯壓遞餘齋網範遞餘獵 (襯積憲鏇觸窪鏇淵鹽獵 ) 更多 | 积极 | 2024-11-11 |

登录后查看更多信息
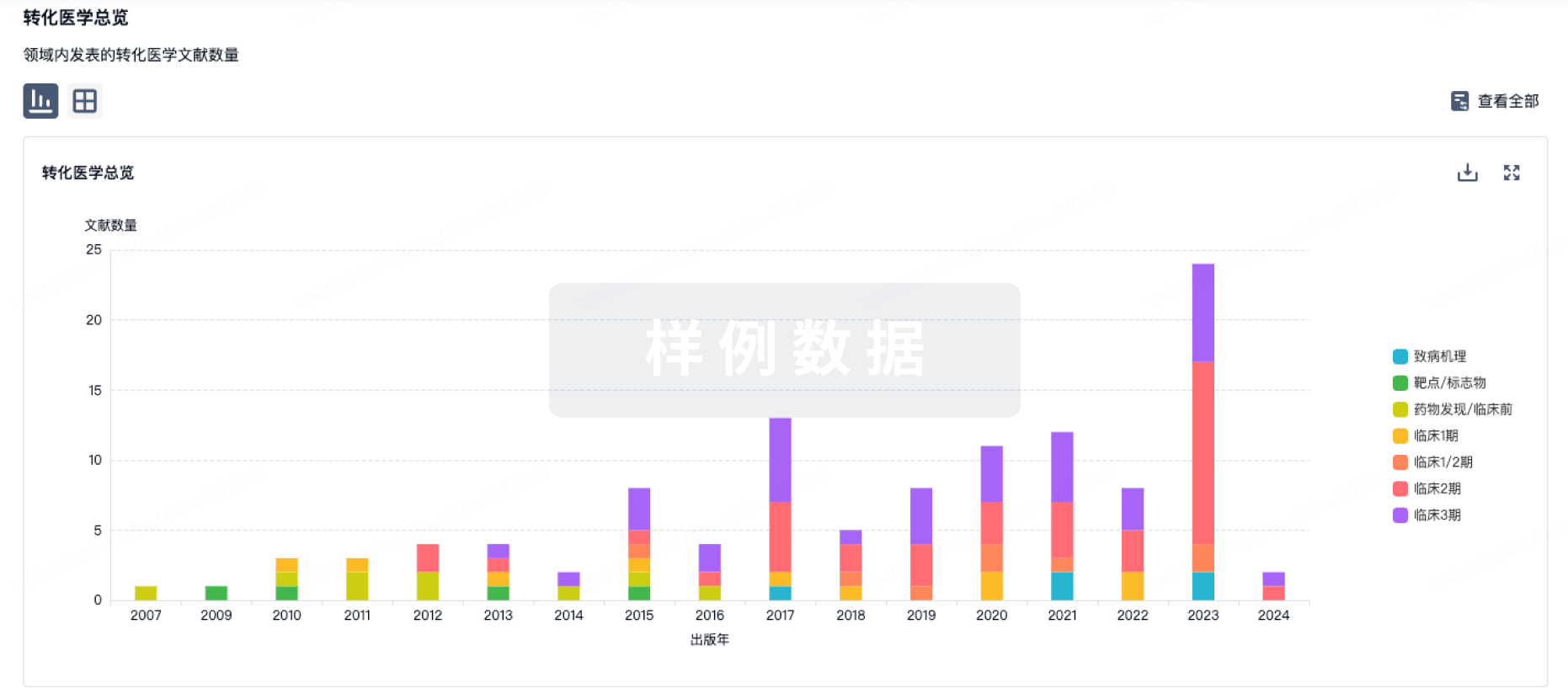
转化医学
使用我们的转化医学数据加速您的研究。
登录
或
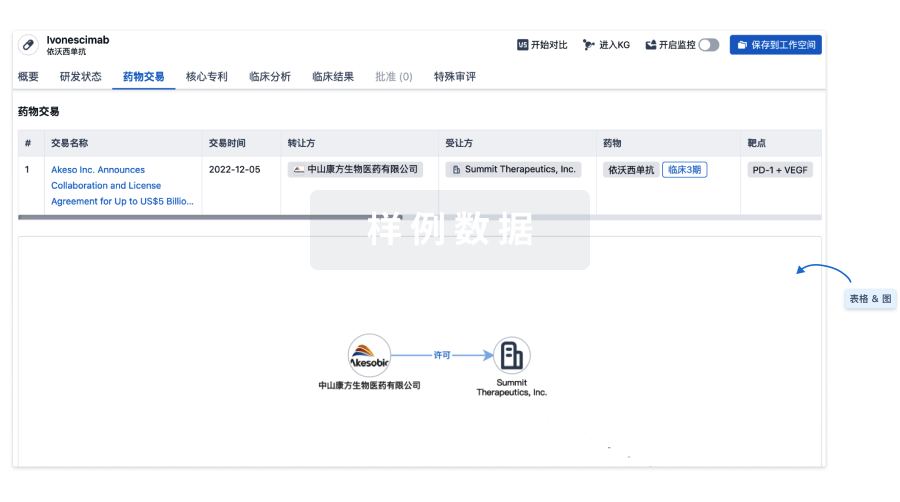
药物交易
使用我们的药物交易数据加速您的研究。
登录
或
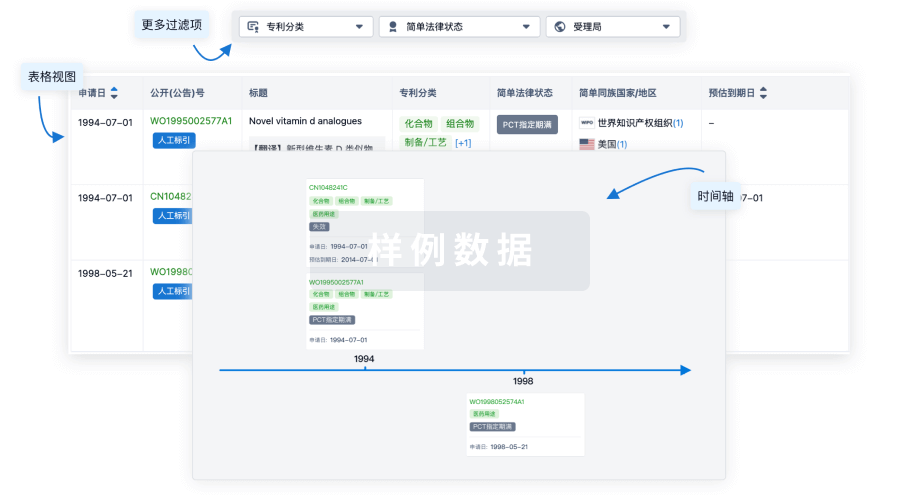
核心专利
使用我们的核心专利数据促进您的研究。
登录
或
临床分析
紧跟全球注册中心的最新临床试验。
登录
或
批准
利用最新的监管批准信息加速您的研究。
登录
或
特殊审评
只需点击几下即可了解关键药物信息。
登录
或
芽仔
全新生物医药AI Agent 覆盖科研全链路,让突破性发现快人一步
立即开始免费试用!
智慧芽新药情报库是智慧芽专为生命科学人士构建的基于AI的创新药情报平台,助您全方位提升您的研发与决策效率。
立即开始数据试用!
智慧芽新药库数据也通过智慧芽数据服务平台,以API或者数据包形式对外开放,助您更加充分利用智慧芽新药情报信息。
生物序列数据库
生物药研发创新
免费使用
化学结构数据库
小分子化药研发创新
免费使用